何謂驚群問題?

場景1:6只小鳥停在電線上休息,都在等待食物,
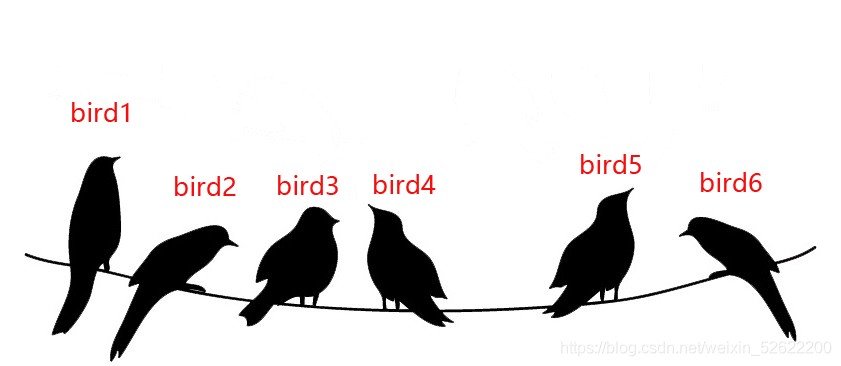
場景2:我們向鳥群投放一條小蟲,作為它們的食物,

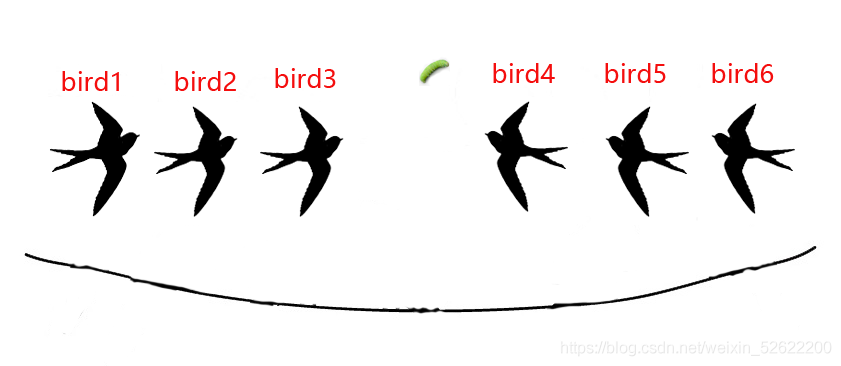
場景3:6只小鳥看到有食物到來,都停止休息,一起飛起來去搶奪食物,
場景4:最終只有一只小鳥(bird4)能夠吃到食物,其他小鳥無奈而又傷心的回到電線上繼續休息,
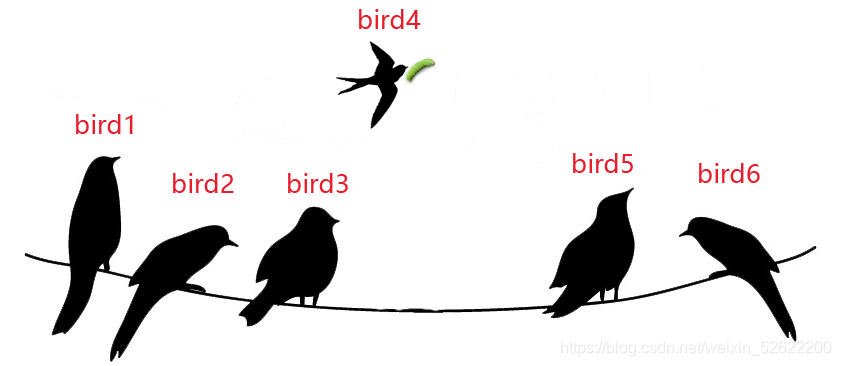
上面我們的小場景實際就是一個現實中的驚群問題,明明只有一條小蟲子子到來,6只小鳥卻都要停止休息去搶奪食物,除了搶到食物的小鳥,其他搶不到食物的小鳥又需要重新飛回去休息,對于這部分小鳥來說,無謂浪費了很多體力,
那么計算機中驚群又是什么樣呢?其實與上述場景類似,多個執行緒(或者行程)同時等待一個事件的到來并準備處理事件,當事件到達時,把所有等待該事件的執行緒(或行程)均喚醒,但是只能有一個執行緒最終可以獲得事件的處理權,其他所有執行緒又重新陷入睡眠等待下次事件到來,這種執行緒被頻繁喚醒卻又沒有真正處理事件導致CPU無謂浪費稱為計算機中的“驚群問題”,
驚群問題出現場景
Linux2.6內核版本之前系統API中的accept呼叫
在Linux2.6內核版本之前,當多個執行緒中的accept函式同時監聽同一個listenfd的時候,如果此listenfd變成可讀,則系統會喚醒所有使用accept函式等待listenfd的所有執行緒(或行程),但是最終只有一個執行緒可以accept呼叫回傳成功,其他執行緒的accept函式呼叫回傳EAGAIN錯誤,執行緒回到等待狀態,這就是accept函式產生的驚群問題,但是在Linux2.6版本之后,內核解決了accept函式的驚群問題,當內核收到一個連接之后,只會喚醒等待佇列上的第一個執行緒(或行程),從而避免了驚群問題,
epoll函式中的驚群問題
如果我們使用多執行緒epoll對同一個fd進行監控的時候,當fd事件到來時,內核會把所有epoll執行緒喚醒,因此產生驚群問題,為何內核不能像解決accept問題那樣解決epoll的驚群問題呢?內核可以解決accept呼叫中的驚群問題,是因為內核清楚的知道accept呼叫只可能一個執行緒呼叫成功,其他執行緒必然失敗,而對于epoll呼叫而言,內核不清楚到底有幾個執行緒需要對該事件進行處理,所以只能將所有執行緒全部喚醒,
執行緒池中的驚群問題
在實際應用程式開發中,為了避免執行緒的頻繁創建銷毀,我們一般建立執行緒池去并發處理,而執行緒池最經典的模型就是生產者-消費者模型,包含一個任務佇列,當佇列不為空的時候,執行緒池中的執行緒從任務佇列中取出任務進行處理,一般使用條件變數進行處理,當我們往任務佇列中放入任務時,需要喚醒等待的執行緒來處理任務,如果我們使用C++標準庫中的函式notify_all()來喚醒執行緒,則會將所有的執行緒都喚醒,然后最終只有一個執行緒可以獲得任務的處理權,其他執行緒在此陷入睡眠,因此產生驚群問題,
驚群問題解決辦法
對于epll函式呼叫的驚群問題解決辦法可以參考Nginx的解決辦法,多個行程將listenfd加入到epoll之前,首先嘗試獲取一個全域的accept_mutex互斥鎖,只有獲得該鎖的行程才可以把listenfd加入到epoll中,當網路連接事件到來時,只有epoll中含有listenfd的執行緒才會被喚醒并處理網路連接事件,從而解決了epoll呼叫中的驚群問題,
對于執行緒池中的驚群問題,我們需要分情況看待,有時候業務需求就是需要喚醒所有執行緒,那么這時候使用notify_all()喚醒所有執行緒就不能稱為”驚群問題“,因為CPU并沒有無謂消耗,而對于只需要喚醒一個執行緒的情況,我們需要使用notify_one()函式代替notify_all()只喚醒一個執行緒,從而避免驚群問題,
最后小編推薦自己的Linux、C/C++技術交流群:【960994558】整理了一些個人覺得比較好的學習書籍、視頻資料共享在里面(包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒體,CDN,P2P,K8S,Docker,TCP/IP,協程,DPDK等等.),有需要的可以自行添加哦!~
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/238589.html
標籤:其他
下一篇:編譯原理-文法的定義與分類