目錄
- 一、分布式鎖深入探究
- 1.分布式鎖簡介
- 1)為何需要分布式鎖
- 2)Java中實作的常見方式
- 3)Redis 分布式鎖的問題
- ①、鎖超時
- ②、單點/多點問題
- 二、Redis 分布式鎖的實作
- 1)代碼實作
- 二、Redlock分布式鎖
- 1.什么是 RedLock
- 2.怎么在單節點上實作分布式鎖
- 3.Redlock 演算法
- 4.失敗重試
- 5.放鎖
- 6.性能、崩潰恢復和 fsync
- 三、如何做可靠的分布式鎖,Redlock真的可行么
- 1.用鎖保護資源
- 2.使用Fencing(柵欄)使得鎖變安全
- 3.使用時間來解決一致性
- 4.用不可靠的時間打破 Redlock
- 5.Redlock 的同步性假設
- 6.結論
- 四、神奇的HyperLoglog解決統計問題
- 1.HyperLogLog 簡介
- 1)關于基數統計
- 2)基數統計的常用方法
- ①、第一種:B 樹
- ②、第二種:bitmap
- 3)概率演算法
- 2.HyperLogLog 原理
- 1)代碼實驗
- 2)更近一步:分桶平均
- 3)真實的 HyperLogLog
- ①、為什么要統計 Hash 值中第一個 1 出現的位置?
- ②、PF 的記憶體占用為什么是 12 KB?
- 3.Redis 中的 HyperLogLog 實作
- 1)密集型存盤結構
- 2)稀疏存盤結構
- 3)物件頭
- 4.HyperLogLog的使用
一、分布式鎖深入探究
1.分布式鎖簡介
鎖是一種用來解決多個執行執行緒訪問共享資源錯誤或資料不一致問題的工具,
如果 把一臺服務器比作一個房子,那么執行緒就好比里面的住戶,當他們想要共同訪問一個共享資源,例如廁所的時候,如果廁所門上沒有鎖…更甚者廁所沒裝門…這是會出原則性的問題的…
裝上了鎖,大家用起來就安心多了,本質也就是同一時間只允許一個住戶使用,
而隨著互聯網世界的發展,單體應用已經越來越無法滿足復雜互聯網的高并發需求,轉而慢慢朝著分布式方向發展,慢慢進化成了更大一些的住戶,所以同樣,我們需要引入分布式鎖來解決分布式應用之間訪問共享資源的并發問題,
1)為何需要分布式鎖
一般情況下,我們使用分布式鎖主要有兩個場景:
- 避免不同節點重復相同的作業:比如用戶執行了某個操作有可能不同節點會發送多封郵件;
- 避免破壞資料的正確性:如果兩個節點在同一條資料上同時進行操作,可能會造成資料錯誤或不一致的情況出現;
2)Java中實作的常見方式
上面我們用簡單的比喻說明了鎖的本質:同一時間只允許一個用戶操作,所以理論上,能夠滿足這個需求的工具我們都能夠使用 (就是其他應用能幫我們加鎖的):
- 基于 MySQL 中的鎖:MySQL 本身有自帶的悲觀鎖
for update關鍵字,也可以自己實作悲觀/樂觀鎖來達到目的; - 基于 Zookeeper 有序節點:Zookeeper 允許臨時創建有序的子節點,這樣客戶端獲取節點串列時,就能夠當前子節點串列中的序號判斷是否能夠獲得鎖;
- 基于 Redis 的單執行緒:由于 Redis 是單執行緒,所以命令會以串行的方式執行,并且本身提供了像
SETNX(set if not exists)這樣的指令,本身具有互斥性;
每個方案都有各自的優缺點,例如 MySQL 雖然直觀理解容易,但是實作起來卻需要額外考慮 鎖超時、加事務 等,并且性能局限于資料庫,諸如此類我們在此不作討論,重點關注 Redis,
3)Redis 分布式鎖的問題
①、鎖超時
假設現在我們有兩臺平行的服務 A B,其中 A 服務在獲取鎖之后由于未知神秘力量突然掛了,那么B服務就永遠無法獲取到鎖了:
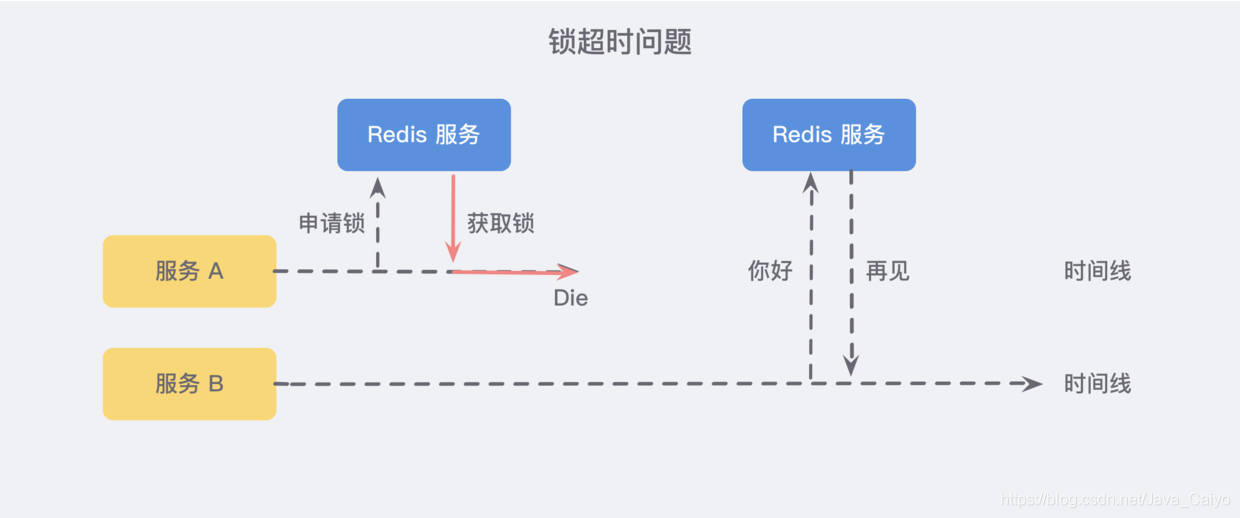
所以我們需要額外設定一個超時時間,來保證服務的可用性,
但是另一個問題隨即而來:如果在加鎖和釋放鎖之間的邏輯執行得太長,以至于超出了鎖的超時限制,也會出現問題,因為這時候第一個執行緒持有鎖過期了,而臨界區的邏輯還沒有執行完,與此同時第二個執行緒就提前擁有了這把鎖,導致臨界區的代碼不能得到嚴格的串行執行,
為了避免這個問題,Redis分布式鎖不要用于較長時間的任務,如果真的偶爾出現了問題,造成的資料小錯亂可能就需要人工的干預,
有一個稍微安全一點的方案是 將鎖的 value 值設定為一個亂數,釋放鎖時先匹配亂數是否一致,然后再洗掉 key,這是為了 確保當前執行緒占有的鎖不會被其他執行緒釋放,除非這個鎖是因為過期了而被服務器自動釋放的,
但是匹配 value 和洗掉 key 在 Redis 中并不是一個原子性的操作,也沒有類似保證原子性的指令,所以可能需要使用像 Lua 這樣的腳本來處理了,因為 Lua 腳本可以 保證多個指令的原子性執行,
延伸的討論:GC 可能引發的安全問題
Martin Kleppmann 曾與 Redis 之父 Antirez 就 Redis 實作分布式鎖的安全性問題進行過深入的討論,其中有一個問題就涉及到 GC,
熟悉 Java 的同學肯定對 GC 不陌生,在 GC 的時候會發生 STW(Stop-The-World),這本身是為了保障垃圾回收器的正常執行,但可能會引發如下的問題:
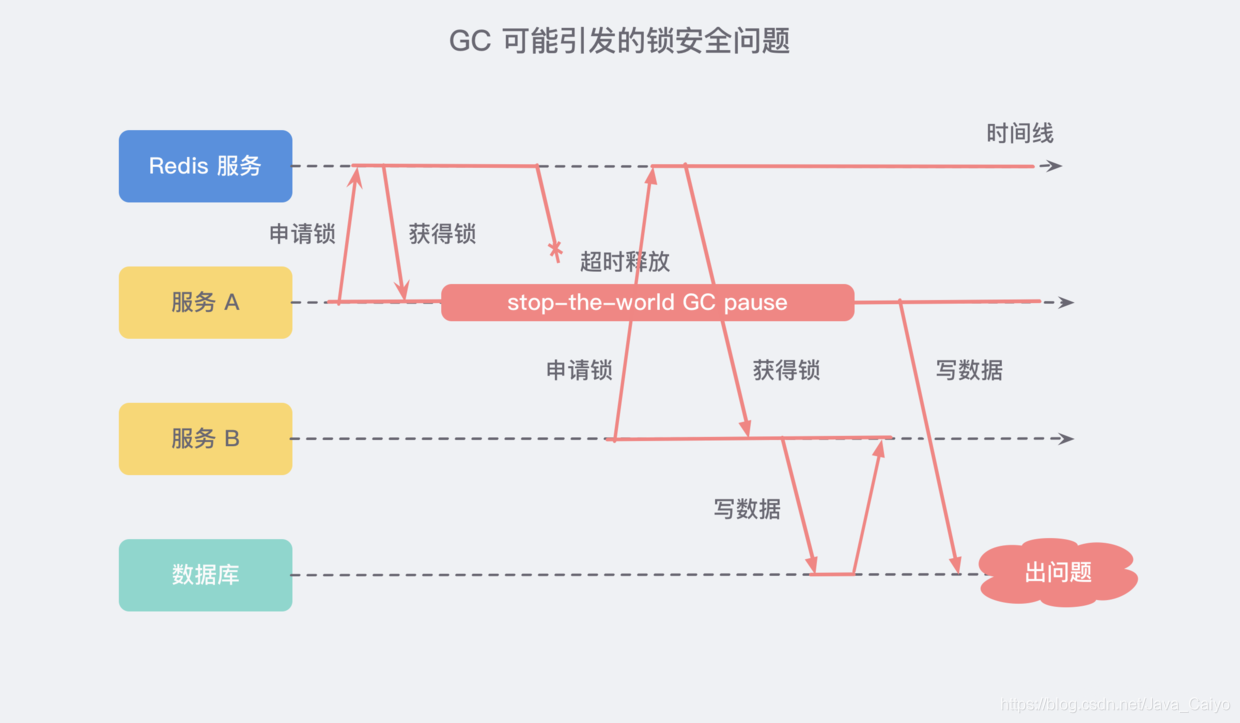
服務 A 獲取了鎖并設定了超時時間,但是服務 A 出現了 STW 且時間較長,導致了分布式鎖進行了超時釋放,在這個期間服務 B 獲取到了鎖,待服務 A STW 結束之后又恢復了鎖,這就導致了 服務 A 和服務B 同時獲取到了鎖,這個時候分布式鎖就不安全了,
不僅僅局限于Redis,Zookeeper和MySQL有同樣的問題,
②、單點/多點問題
如果 Redis 采用單機部署模式,那就意味著當 Redis 故障了,就會導致整個服務不可用,
而如果采用主從模式部署,我們想象一個這樣的場景:服務 A 申請到一把鎖之后,如果作為主機的Redis宕機了,那么 服務 B 在申請鎖的時候就會從從機那里獲取到這把鎖,為了解決這個問題,Redis作者提出了一種 RedLock 紅鎖 的演算法 (Redission 同 Jedis):
// 三個 Redis 集群
RLock lock1 = redissionInstance1.getLock("lock1");
RLock lock2 = redissionInstance2.getLock("lock2");
RLock lock3 = redissionInstance3.getLock("lock3");
RedissionRedLock lock = new RedissionLock(lock1, lock2, lock2);
lock.lock();
// do something....
lock.unlock();
二、Redis 分布式鎖的實作
分布式鎖類似于 “占坑”,而SETNX(SET if Not eXists)指令就是這樣的一個操作,只允許被一個客戶端占有,我們來看看 原始碼(t_string.c/setGenericCommand) 吧:
// SET/ SETEX/ SETTEX/ SETNX 最底層實作
void setGenericCommand(client *c, int flags, robj *key, robj *val, robj *expire,
int unit, robj *ok_reply, robj *abort_reply) {
long long milliseconds = 0; /* initialized to avoid any harmness warning */
// 如果定義了 key 的過期時間則保存到上面定義的變數中
// 如果過期時間設定錯誤則回傳錯誤資訊
if (expire) {
if (getLongLongFromObjectOrReply(c, expire, &milliseconds, NULL) != C_OK)
return;
if (milliseconds <= 0) {
addReplyErrorFormat(c,"invalid expire time in %s",c->cmd->name);
return;
}
if (unit == UNIT_SECONDS) milliseconds *= 1000;
}
// lookupKeyWrite 函式是為執行寫操作而取出 key 的值物件
// 這里的判斷條件是:
// 1.如果設定了 NX(不存在),并且在資料庫中找到了 key 值
// 2.或者設定了 XX(存在),并且在資料庫中沒有找到該 key
// => 那么回復 abort_reply 給客戶端
if ((flags & OBJ_SET_NX && lookupKeyWrite(c->db,key) != NULL) ||
(flags & OBJ_SET_XX && lookupKeyWrite(c->db,key) == NULL))
{
addReply(c, abort_reply ? abort_reply : shared.null[c->resp]);
return;
}
// 在當前的資料庫中設定鍵為 key 值為 value 的資料
genericSetKey(c->db,key,val,flags & OBJ_SET_KEEPTTL);
// 服務器每修改一個 key 后都會修改 dirty 值
server.dirty++;
if (expire) setExpire(c,c->db,key,mstime()+milliseconds);
notifyKeyspaceEvent(NOTIFY_STRING,"set",key,c->db->id);
if (expire) notifyKeyspaceEvent(NOTIFY_GENERIC,
"expire",key,c->db->id);
addReply(c, ok_reply ? ok_reply : shared.ok);
}
就像上面介紹的那樣,其實在之前版本的 Redis 中,由于SETNX和EXPIRE并不是原子指令,所以在一起執行會出現問題,
也許你會想到使用 Redis 事務來解決,但在這里不行,因為EXPIRE命令依賴于SETNX的執行結果,而事務中沒有if-else的分支邏輯,如果 SETNX 沒有搶到鎖,EXPIRE就不應該執行,
為了解決這個疑難問題,Redis 開源社區涌現了許多分布式鎖的 library,為了治理這個亂象,后來在Redis 2.8 的版本中,加入了 SET 指令的擴展引數,使得 SETNX 可以和 EXPIRE 指令一起執行了:
> SET lock:test true ex 5 nx
OK
... do something critical ...
> del lock:test
你只需要符合 SET key value [EX seconds | PX milliseconds] [NX | XX] [KEEPTTL] 這樣的格式就好了,
另外,官方檔案也在 SETNX 檔案中提到了這樣一種思路:把 SETNX 對應 key 的 value 設定為<current Unix time + lock timeout + 1>,這樣在其他客戶端訪問時就能夠自己判斷是否能夠獲取下一個 value 為上述格式的鎖了,
1)代碼實作
下面用 Jedis 來模擬實作以下,關鍵代碼如下:
private static final String LOCK_SUCCESS = "OK";
private static final Long RELEASE_SUCCESS = 1L;
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
@Override
public String acquire() {
try {
// 獲取鎖的超時時間,超過這個時間則放棄獲取鎖
long end = System.currentTimeMillis() + acquireTimeout;
// 隨機生成一個 value
String requireToken = UUID.randomUUID().toString();
while (System.currentTimeMillis() < end) {
String result = jedis
.set(lockKey, requireToken, SET_IF_NOT_EXIST,
SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return requireToken;
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
} catch (Exception e) {
log.error("acquire lock due to error", e);
}
return null;
}
@Override
public boolean release(String identify) {
if (identify == null) {
return false;
}
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return
redis.call('del', KEYS[1]) else return 0 end";
Object result = new Object();
try {
result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(identify));
if (RELEASE_SUCCESS.equals(result)) {
log.info("release lock success, requestToken:{}", identify);
return true;
}
} catch (Exception e) {
log.error("release lock due to error", e);
} finally {
if (jedis != null) {
jedis.close();
}
}
log.info("release lock failed, requestToken:{}, result:{}", identify, result);
return false;
}
小插曲:
更多阿里、騰訊、美團、京東等一線互聯網大廠Java面試真題;包含:基礎、并發、鎖、JVM、設計模式、資料結構、反射/IO、資料庫、Redis、Spring、訊息佇列、分布式、Zookeeper、Dubbo、Mybatis、Maven、面經等,
更多Java程式員技術進階小技巧;例如高效學習(如何學習和閱讀代碼、面對枯燥和量大的知識)高效溝通(溝通方式及技巧、溝通技術)
更多Java大牛分享的一些職業生涯分享檔案
請點擊這里添加》》》》》》》》》社群,免費獲取
比你優秀的對手在學習,你的仇人在磨刀,你的閨蜜在減肥,隔壁老王在練腰, 我們必須不斷學習,否則我們將被學習者超越!
趁年輕,使勁拼,給未來的自己一個交代!
二、Redlock分布式鎖
1.什么是 RedLock
Redis 官方站這篇文章提出了一種權威的基于 Redis 實作分布式鎖的方式名叫 Redlock,此種方式比原先的單節點的方法更安全,它可以保證以下特性:
- 安全特性:互斥訪問,即永遠只有一個 client 能拿到鎖
- 避免死鎖:最終 client 都可能拿到鎖,不會出現死鎖的情況,即使原本鎖住某資源的 client crash了或者出現了網路磁區
- 容錯性:只要大部分 Redis 節點存活就可以正常提供服務
2.怎么在單節點上實作分布式鎖
SET resource_name my_random_value NX PX 30000
主要依靠上述命令,該命令僅當 Key 不存在時(NX保證)set 值,并且設定過期時間 3000ms (PX保證),值 my_random_value 必須是所有 client 和所有鎖請求發生期間唯一的,釋放鎖的邏輯是:
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
上述實作可以避免釋放另一個client創建的鎖,如果只有 del 命令的話,那么如果 client1 拿到 lock1 之后因為某些操作阻塞了很長時間,此時 Redis 端 lock1 已經過期了并且已經被重新分配給了 client2,那么 client1 此時再去釋放這把鎖就會造成 client2 原本獲取到的鎖被 client1 無故釋放了,但現在為每個 client 分配一個 unique 的 string 值可以避免這個問題,至于如何去生成這個 unique string,方法很多隨意選擇一種就行了,
3.Redlock 演算法
演算法很易懂,起 5 個 master 節點,分布在不同的機房盡量保證可用性,為了獲得鎖,client 會進行如下操作:
- 得到當前的時間,微秒單位
- 嘗試順序地在 5 個實體上申請鎖,當然需要使用相同的 key 和 random value,這里一個 client 需要合理設定與 master 節點溝通的 timeout 大小,避免長時間和一個 fail 了的節點浪費時間
- 當 client 在大于等于 3 個 master 上成功申請到鎖的時候,且它會計算申請鎖消耗了多少時間,這部分消耗的時間采用獲得鎖的當下時間減去第一步獲得的時間戳得到,如果鎖的持續時長(lockvalidity time)比流逝的時間多的話,那么鎖就真正獲取到了,
- 如果鎖申請到了,那么鎖真正的 lock validity time 應該是 origin(lock validity time) - 申請鎖期間流逝的時間
- 如果 client 申請鎖失敗了,那么它就會在少部分申請成功鎖的 master 節點上執行釋放鎖的操作,重置狀態
4.失敗重試
如果一個 client 申請鎖失敗了,那么它需要稍等一會在重試避免多個 client 同時申請鎖的情況,最好的情況是一個 client 需要幾乎同時向 5 個 master 發起鎖申請,另外就是如果 client 申請鎖失敗了它需要盡快在它曾經申請到鎖的 master 上執行 unlock 操作,便于其他 client 獲得這把鎖,避免這些鎖過期造成的時間浪費,當然如果這時候網路磁區使得 client 無法聯系上這些 master,那么這種浪費就是不得不付出的代價了,
5.放鎖
放鎖操作很簡單,就是依次釋放所有節點上的鎖就行了
6.性能、崩潰恢復和 fsync
如果我們的節點沒有持久化機制,client 從 5 個 master 中的 3 個處獲得了鎖,然后其中一個重啟了,這是注意 整個環境中又出現了 3 個 master 可供另一個 client 申請同一把鎖! 違反了互斥性,如果我們開啟了 AOF 持久化那么情況會稍微好轉一些,因為 Redis 的過期機制是語意層面實作的,所以在server 掛了的時候時間依舊在流逝,重啟之后鎖狀態不會受到污染,但是考慮斷電之后呢,AOF部分命令沒來得及刷回磁盤直接丟失了,除非我們配置刷回策略為 fsnyc = always,但這會損傷性能,解決這個問題的方法是,當一個節點重啟之后,我們規定在 max TTL 期間它是不可用的,這樣它就不會干擾原本已經申請到的鎖,等到它 crash 前的那部分鎖都過期了,環境不存在歷史鎖了,那么再把這個節點加進來正常作業,
三、如何做可靠的分布式鎖,Redlock真的可行么
如果你只是為了性能,那沒必要用 Redlock,它成本高且復雜,你只用一個 Redis 實體也夠了,最多加個從防止主掛了,當然,你使用單節點的 Redis 那么斷電或者一些情況下,你會丟失鎖,但是你的目的只是加速性能且斷電這種事情不會經常發生,這并不是什么大問題,并且如果你使用了單節點 Redis,那么很顯然你這個應用需要的鎖粒度是很模糊粗糙的,也不會是什么重要的服務,
那么是否 Redlock 對于要求正確性的場景就合適呢?Martin 列舉了若干場景證明 Redlock 這種演算法是不可靠的,
1.用鎖保護資源
這節里 Martin 先將 Redlock 放在了一邊而是僅討論總體上一個分布式鎖是怎么作業的,在分布式環境下,鎖比 mutex 這類復雜,因為涉及到不同節點、網路通信并且他們隨時可能無征兆的 fail ,Martin假設了一個場景,一個 client 要修改一個檔案,它先申請得到鎖,然后修改檔案寫回,放鎖,另一個 client 再申請鎖 … 代碼流程如下:
// THIS CODE IS BROKEN
function writeData(filename, data) {
var lock = lockService.acquireLock(filename);
if (!lock) {
throw 'Failed to acquire lock';
}
try {
var file = storage.readFile(filename);
var updated = updateContents(file, data);
storage.writeFile(filename, updated);
} finally {
lock.release();
}
}
可惜即使你的鎖服務非常完美,上述代碼還是可能跪,下面的流程圖會告訴你為什么:
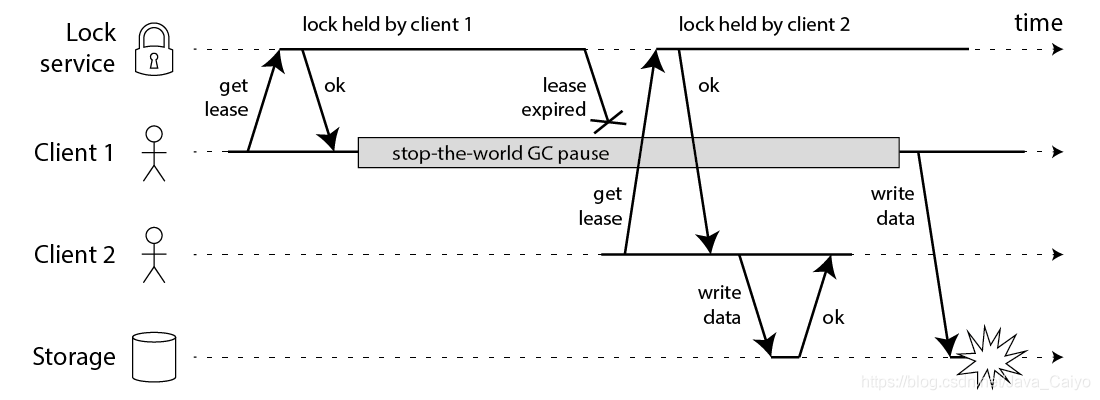
2.使用Fencing(柵欄)使得鎖變安全
修復問題的方法也很簡單:你需要在每次寫操作時加入一個 fencing token,這個場景下,fencing token 可以是一個遞增的數字(lock service 可以做到),每次有 client 申請鎖就遞增一次:
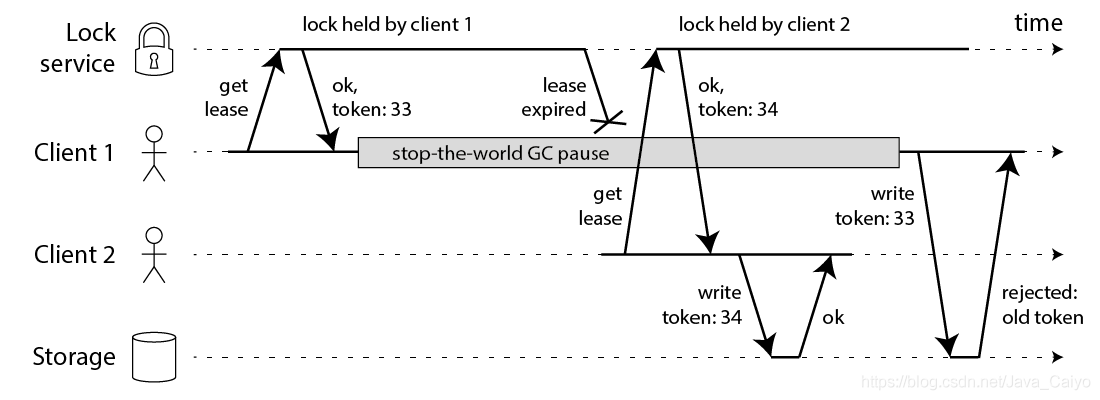
client1 申請鎖同時拿到 token33,然后它進入長時間的停頓鎖也過期了,client2 得到鎖和 token34 寫入資料,緊接著 client1 活過來之后嘗試寫入資料,自身 token33 比 34 小因此寫入操作被拒絕,注意這需要存盤層來檢查 token,但這并不難實作,如果你使用 Zookeeper 作為 lock service 的話那么你可以使用 zxid 作為遞增數字,
但是對于 Redlock 你要知道,沒什么生成 fencing token 的方式,并且怎么修改 Redlock 演算法使其能產生 fencing token 呢?好像并不那么顯而易見,因為產生 token 需要單調遞增,除非在單節點 Redis 上完成但是這又沒有高可靠性,你好像需要引進一致性協議來讓 Redlock 產生可靠的 fencing token,
3.使用時間來解決一致性
Redlock 無法產生 fencing token 早該成為在需求正確性的場景下棄用它的理由,但還有一些值得討論的地方,
學術界有個說法,演算法對時間不做假設:因為行程可能pause一段時間、資料包可能因為網路延遲延后到達、時鐘可能根本就是錯的,而可靠的演算法依舊要在上述假設下做正確的事情,
對于 failure detector 來說,timeout 只能作為猜測某個節點 fail 的依據,因為網路延遲、本地時鐘不正確等其他原因的限制,考慮到 Redis 使用 gettimeofday,而不是單調的時鐘,會受到系統時間的影響,可能會突然前進或者后退一段時間,這會導致一個 key 更快或更慢地過期,
可見,Redlock 依賴于許多時間假設,它假設所有 Redis 節點都能對同一個 Key 在其過期前持有差不多的時間、跟過期時間相比網路延遲很小、跟過期時間相比行程 pause 很短,
4.用不可靠的時間打破 Redlock
這節 Martin 舉了個因為時間問題,Redlock 不可靠的例子,
- client1 從 ABC 三個節點處申請到鎖,DE由于網路原因請求沒有到達
- C節點的時鐘往前推了,導致 lock 過期’
- client2 在CDE處獲得了鎖,AB由于網路原因請求未到達
- 此時 client1 和 client2 都獲得了鎖
在 Redlock 官方檔案中也提到了這個情況,不過是C崩潰的時候,Redlock 官方本身也是知道Redlock演算法不是完全可靠的,官方為了解決這種問題建議使用延時啟動,但是 Martin 這里分析得更加全面,指出延時啟動不也是依賴于時鐘的正確性的么?
接下來 Martin 又列舉了行程 Pause 時而不是時鐘不可靠時會發生的問題:
- client1從 ABCDE 處獲得了鎖
- 當獲得鎖的 response 還沒到達 client1 時 client1 進入 GC 停頓
- 停頓期間鎖已經過期了
- client2 在 ABCDE 處獲得了鎖
- client1 GC 完成收到了獲得鎖的 response,此時兩個 client 又拿到了同一把鎖
同時長時間的網路延遲也有可能導致同樣的問題,
5.Redlock 的同步性假設
這些例子說明了,僅有在你假設了一個同步性系統模型的基礎上,Redlock 才能正常作業,也就是系統能滿足以下屬性:
- 網路延時邊界,即假設資料包一定能在某個最大延時之內到達
- 行程停頓邊界,即行程停頓一定在某個最大時間之內
- 時鐘錯誤邊界,即不會從一個壞的 NTP 服務器處取得時間
6.結論
Martin 認為 Redlock 實在不是一個好的選擇,對于需求性能的分布式鎖應用它太重了且成本高;對于需求正確性的應用來說它不夠安全,因為它對高危的時鐘或者說其他上述列舉的情況進行了不可靠的假設,如果你的應用只需要高性能的分布式鎖不要求多高的正確性,那么單節點 Redis 夠了;如果你的應用想要保住正確性,那么不建議 Redlock,建議使用一個合適的一致性協調系統,例如 Zookeeper,且保證存在 fencing token,
小插曲:
更多阿里、騰訊、美團、京東等一線互聯網大廠Java面試真題;包含:基礎、并發、鎖、JVM、設計模式、資料結構、反射/IO、資料庫、Redis、Spring、訊息佇列、分布式、Zookeeper、Dubbo、Mybatis、Maven、面經等,
更多Java程式員技術進階小技巧;例如高效學習(如何學習和閱讀代碼、面對枯燥和量大的知識)高效溝通(溝通方式及技巧、溝通技術)
更多Java大牛分享的一些職業生涯分享檔案
請點擊這里添加》》》》》》》》》社群,免費獲取
比你優秀的對手在學習,你的仇人在磨刀,你的閨蜜在減肥,隔壁老王在練腰, 我們必須不斷學習,否則我們將被學習者超越!
趁年輕,使勁拼,給未來的自己一個交代!
四、神奇的HyperLoglog解決統計問題
1.HyperLogLog 簡介
HyperLogLog 是最早由Flajolet及其同事在 2007 年提出的一種 估算基數的近似最優演算法,但跟原版論文不同的是,好像很多書包括 Redis 作者都把它稱為一種 新的資料結構(new datastruct) (演算法實作確 實需要一種特定的資料結構來實作),
1)關于基數統計
基數統計(Cardinality Counting) 通常是用來統計一個集合中不重復的元素個數,
思考這樣的一個場景: 如果你負責開發維護一個大型的網站,有一天老板找產品經理要網站上每個網頁的 UV(獨立訪客,每個用戶每天只記錄一次),然后讓你來開發這個統計模塊,你會如何實作?
如果統計 PV(瀏覽量,用戶沒點一次記錄一次),那非常好辦,給每個頁面配置一個獨立的 Redis 計數器就可以了,把這個計數器的 key 后綴加上當天的日期,這樣每來一個請求,就執行 INCRBY 指令一次,最終就可以統計出所有的 PV 資料了,
但是 UV 不同,它要去重,同一個用戶一天之內的多次訪問請求只能計數一次,這就要求了每一個網頁請求都需要帶上用戶的 ID,無論是登錄用戶還是未登錄的用戶,都需要一個唯一 ID 來標識,
你也許馬上就想到了一個 簡單的解決方案:那就是 為每一個頁面設定一個獨立的 set 集合 來存盤所有當天訪問過此頁面的用戶 ID,但這樣的 問題 就是:
- 存盤空間巨大: 如果網站訪問量一大,你需要用來存盤的 set 集合就會非常大,如果頁面再一多…為了一個去重功能耗費的資源就可以直接讓你 老板打死你;
- 統計復雜: 這么多 set 集合如果要聚合統計一下,又是一個復雜的事情;
2)基數統計的常用方法
對于上述這樣需要 基數統計 的事情,通常來說有兩種比 set 集合更好的解決方案:
①、第一種:B 樹
B 樹最大的優勢就是插入和查找效率很高,如果用 B 樹存盤要統計的資料,可以快速判斷新來的資料是否存在,并快速將元素插入 B 樹,要計算基礎值,只需要計算 B 樹的節點個數就行了,
不過將 B 樹結構維護到記憶體中,能夠解決統計和計算的問題,但是 并沒有節省記憶體,
②、第二種:bitmap
bitmap 可以理解為通過一個 bit 陣列來存盤特定資料的一種資料結構,每一個 bit 位都能獨立包含資訊,bit 是資料的最小存盤單位,因此能大量節省空間,也可以將整個 bit 資料一次性 load 到記憶體計算,如果定義一個很大的 bit 陣列,基礎統計中 每一個元素對應到 bit 陣列中的一位,例如:

bitmap 還有一個明顯的優勢是 可以輕松合并多個統計結果,只需要對多個結果求異或就可以了,也可以大大減少存盤記憶體,可以簡單做一個計算,如果要統計 1 億 個資料的基數值,大約需要的記憶體: 100_000_000/ 8/ 1024/ 1024 ≈ 12 M ,如果用 32 bit 的 int 代表 每一個 統計的資料,大約需要記憶體: 32 * 100_000_000/ 8/ 1024/ 1024 ≈ 381 M
可以看到 bitmap 對于記憶體的節省顯而易見,但仍然不夠,統計一個物件的基數值就需要 12 M ,如果統計 1 萬個物件,就需要接近 120 G ,對于大資料的場景仍然不適用,
3)概率演算法
實際上目前還沒有發現更好的在 大資料場景 中 準確計算 基數的高效演算法,因此在不追求絕對精確的情況下,使用概率演算法算是一個不錯的解決方案,
概率演算法 不直接存盤 資料集合本身,通過一定的 概率統計方法預估基數值,這種方法可以大大節省記憶體,同時保證誤差控制在一定范圍內,目前用于基數計數的概率演算法包括:
- Linear Counting(LC):早期的基數估計演算法,LC 在空間復雜度方面并不算優秀,實際上 LC 的空間復雜度與上文中簡單 bitmap 方法是一樣的(但是有個常數項級別的降低),都是 O(Nmax)
- LogLog Counting(LLC):LogLog Counting 相比于 LC 更加節省記憶體,空間復雜度只有O(log2(log2(Nmax)))
- HyperLogLog Counting(HLL):HyperLogLog Counting 是基于 LLC 的優化和改進,在同樣空間復雜度情況下,能夠比 LLC 的基數估計誤差更小
其中,HyperLogLog 的表現是驚人的,上面我們簡單計算過用 bitmap 存盤 1 個億 統計資料大概需要12 M 記憶體,而在 HyperLoglog 中,只需要不到 1 K 記憶體就能夠做到!在 Redis 中實作的HyperLoglog也只需要 12 K 記憶體,在 標準誤差 0.81% 的前提下,能夠統計 264 個資料!
這是怎么做到的?! 下面趕緊來了解一下!
2.HyperLogLog 原理
我們來思考一個拋硬幣的游戲:你連續擲 n 次硬幣,然后說出其中連續擲為正面的最大次數,我來猜你一共拋了多少次,
這很容易理解吧,例如:你說你這一次 最多連續出現了 2 次 正面,那么我就可以知道你這一次投擲的次數并不多,所以 我可能會猜是 5 或者是其他小一些的數字,但如果你說你這一次 最多連續出現了 20次 正面,雖然我覺得不可能,但我仍然知道你花了特別多的時間,所以 我說 GUN…,
這期間我可能會要求你重復實驗,然后我得到了更多的資料之后就會估計得更準,我們來把剛才的游戲換一種說法:

這張圖的意思是,我們給定一系列的隨機整數,記錄下低位連續零位的最大長度 K,即為圖中的maxbit,通過這個 K 值我們就可以估算出亂數的數量 N,
1)代碼實驗
我們可以簡單撰寫代碼做一個實驗,來探究一下 K 和 N 之間的關系:
public class PfTest {
static class BitKeeper {
private int maxbit;
public void random() {
long value = ThreadLocalRandom.current().nextLong(2L << 32);
int bit = lowZeros(value);
if (bit > this.maxbit) {
this.maxbit = bit;
}
}
private int lowZeros(long value) {
int i = 0;
for (; i < 32; i++) {
if (value >> i << i != value) {
break;
}
}
return i - 1;
}
}
static class Experiment {
private int n;
private BitKeeper keeper;
public Experiment(int n) {
this.n = n;
this.keeper = new BitKeeper();
}
public void work() {
for (int i = 0; i < n; i++) {
this.keeper.random();
}
}
public void debug() {
System.out
.printf("%d %.2f %d\n", this.n, Math.log(this.n) / Math.log(2), this.keeper.maxbit);
}
}
public static void main(String[] args) {
for (int i = 1000; i < 100000; i += 100) {
Experiment exp = new Experiment(i);
exp.work();
exp.debug();
}
}
}
跟上圖中的程序是一致的,話說為啥叫 PfTest 呢,包括 Redis 中的命令也一樣帶有一個 PF 前綴,還記得嘛,因為 HyperLogLog 的提出者上文提到過的,叫 Philippe Flajolet ,
截取部分輸出查看:
//n n/log2 maxbit
34000 15.05 13
35000 15.10 13
36000 15.14 16
37000 15.18 17
38000 15.21 14
39000 15.25 16
40000 15.29 14
41000 15.32 16
42000 15.36 18
會發現 K和 N 的對數之間存在顯著的線性相關性:N 約等于 2的k次方
2)更近一步:分桶平均

public class PfTest {
static class BitKeeper {
// 無變化, 代碼省略
}
static class Experiment {
private int n;
private int k;
private BitKeeper[] keepers;
public Experiment(int n) {
this(n, 1024);
}
public Experiment(int n, int k) {
this.n = n;
this.k = k;
this.keepers = new BitKeeper[k];
for (int i = 0; i < k; i++) {
this.keepers[i] = new BitKeeper();
}
}
public void work() {
for (int i = 0; i < this.n; i++) {
long m = ThreadLocalRandom.current().nextLong(1L << 32);
BitKeeper keeper = keepers[(int) (((m & 0xfff0000) >> 16) % keepers.length)];
keeper.random();
}
}
public double estimate() {
double sumbitsInverse = 0.0;
for (BitKeeper keeper : keepers) {
sumbitsInverse += 1.0 / (float) keeper.maxbit;
}
double avgBits = (float) keepers.length / sumbitsInverse;
return Math.pow(2, avgBits) * this.k;
}
}
public static void main(String[] args) {
for (int i = 100000; i < 1000000; i += 100000) {
Experiment exp = new Experiment(i);
exp.work();
double est = exp.estimate();
System.out.printf("%d %.2f %.2f\n", i, est, Math.abs(est - i) / i);
}
}
}
這個程序有點 類似于選秀節目里面的打分,一堆專業評委打分,但是有一些評委因為自己特別喜歡所以給高了,一些評委又打低了,所以一般都要 屏蔽最高分和最低分,然后 再計算平均值,這樣的出來的分數就差不多是公平公正的了,
上述代碼就有 1024 個 “評委”,并且在計算平均值的時候,采用了 調和平均數,也就是倒數的平均值,它能有效地平滑離群值的影響:
avg = (3 + 4 + 5 + 104) / 4 = 29
avg = 4 / (1/3 + 1/4 + 1/5 + 1/104) = 5.044
觀察腳本的輸出,誤差率百分比控制在個位數:
100000 94274.94 0.06
200000 194092.62 0.03
300000 277329.92 0.08
400000 373281.66 0.07
500000 501551.60 0.00
600000 596078.40 0.01
700000 687265.72 0.02
800000 828778.96 0.04
900000 944683.53 0.05
真實的 HyperLogLog 要比上面的示例代碼更加復雜一些,也更加精確一些,上面這個演算法在隨機次數很少的情況下會出現除零錯誤,因為 maxbit = 0 是不可以求倒數的,
3)真實的 HyperLogLog
有一個神奇的網站,可以動態地讓你觀察到 HyperLogLog 的演算法到底是怎么執行的:http://content.research.neustar.biz/blog/hll.html
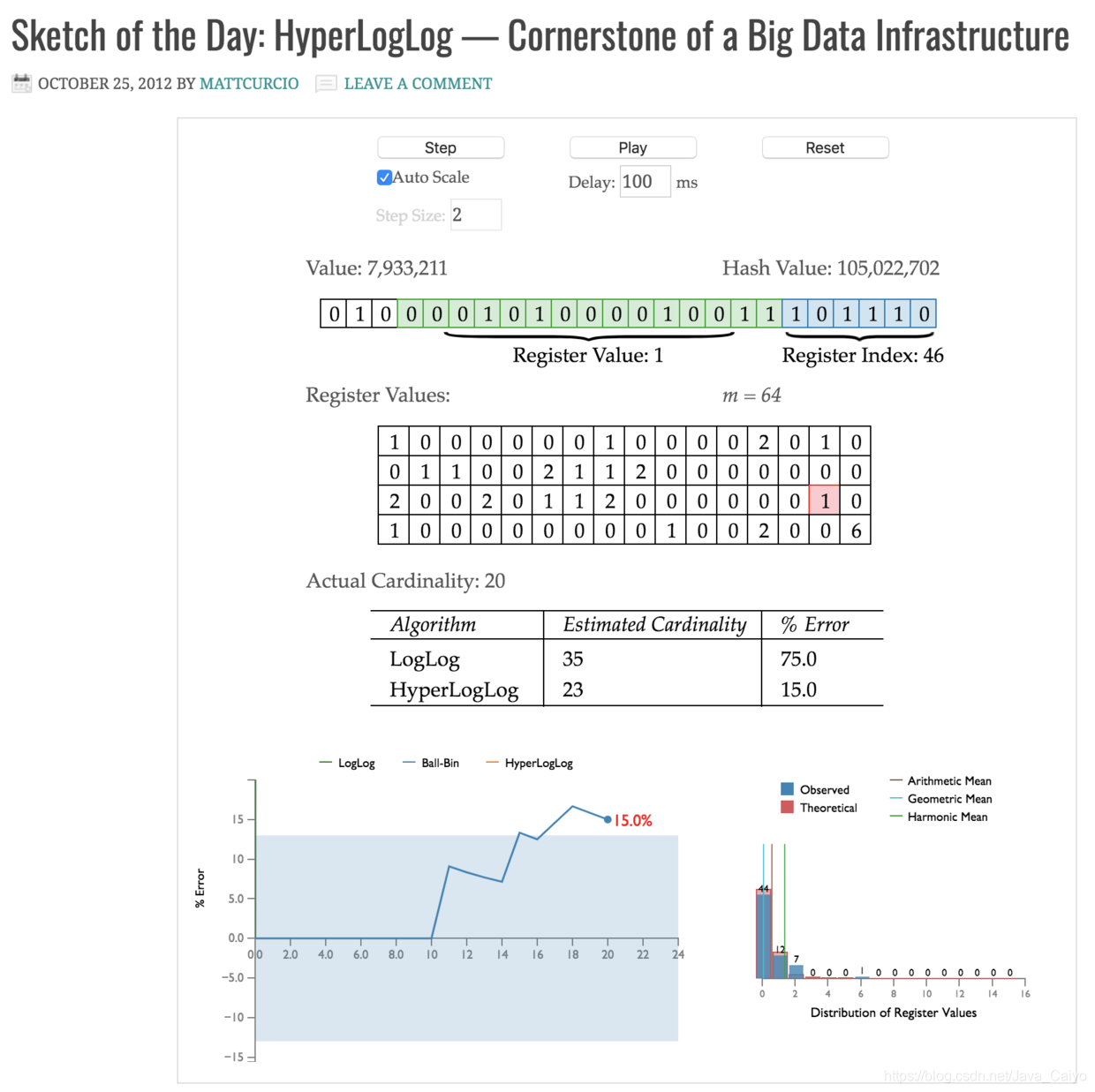
其中的一些概念這里稍微解釋一下,您就可以自行去點擊 step 來觀察了:
- m 表示分桶個數: 從圖中可以看到,這里分成了 64 個桶;
- 藍色的 bit 表示在桶中的位置: 例如圖中的
101110實則表示二進制的 46 ,所以該元素被統計在中間大表格Register Values中標紅的第 46 個桶之中; - 綠色的 bit 表示第一個 1 出現的位置: 從圖中可以看到標綠的 bit 中,從右往左數,第一位就是1,所以在
Register Values第 46 個桶中寫入 1; - 紅色 bit 表示綠色 bit 的值的累加: 下一個出現在第 46 個桶的元素值會被累加;
①、為什么要統計 Hash 值中第一個 1 出現的位置?

②、PF 的記憶體占用為什么是 12 KB?

3.Redis 中的 HyperLogLog 實作
從上面我們算是對 HyperLogLog 的演算法和思想有了一定的了解,并且知道了一個 HyperLogLog 實際占用的空間大約是 12 KB ,但 Redis 對于記憶體的優化非常變態,當 計數比較小 的時候,大多數桶的計數值都是 零,這個時候 Redis 就會適當節約空間,轉換成另外一種 稀疏存盤方式,與之相對的,正常的存盤模式叫做 密集存盤,這種方式會恒定地占用 12 KB ,
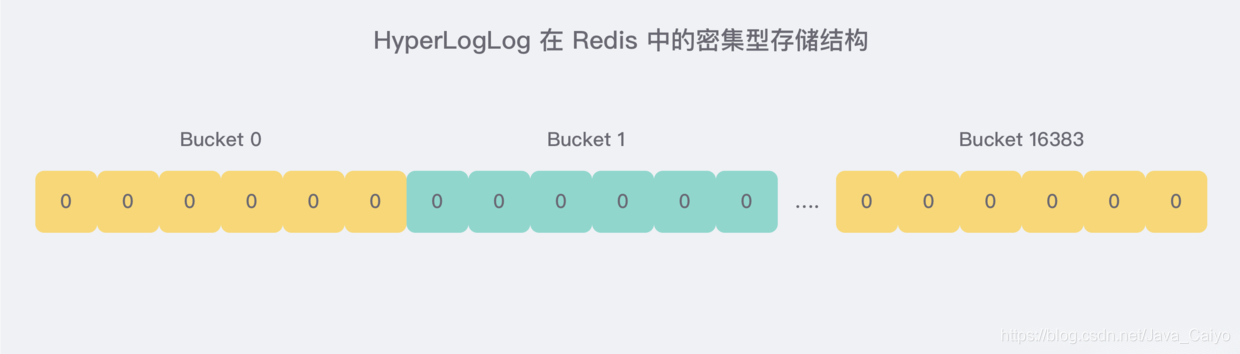
1)密集型存盤結構
密集型的存盤結構非常簡單,就是 16384 個 6 bit 連續串成 的字串位圖:
我們都知道,一個位元組是由 8 個 bit 組成的,這樣 6 bit 排列的結構就會導致,有一些桶會 跨越位元組邊界,我們需要 對這一個或者兩個位元組進行適當的移位拼接 才可以得到具體的計數值,
假設桶的編號為 index ,這個 6 bity 計數值的起始位元組偏移用 offset_bytes 表示,它在這個位元組的其實位元位置偏移用 offset_bits 表示,于是我們有:
offset_bytes = (index * 6) / 8
offset_bits = (index * 6) % 8
前者是商,后者是余數,比如 bucket 2 的位元組偏移是 1,也就是第 2 個位元組,它的位偏移是 4,也就是第 2 個位元組的第 5 個位開始是 bucket 2 的計數值,需要注意的是 位元組位序是左邊低位右邊高位,而通常我們使用的位元組都是左邊高位右邊低位,
這里就涉及到兩種情況,如果 offset_bits 小于等于 2,說明這 6 bit 在一個位元組的內部,可以直接使用下面的運算式得到計數值 val :
val = buffer[offset_bytes] >> offset_bits # 向右移位
如果 offset_bits 大于 2,那么就會涉及到 跨越位元組邊界,我們需要拼接兩個位元組的位片段:
# 低位值
low_val = buffer[offset_bytes] >> offset_bits
# 低位個數
low_bits = 8 - offset_bits
# 拼接,保留低6位
val = (high_val << low_bits | low_val) & 0b111111
不過下面 Redis 的原始碼要晦澀一點,看形式它似乎只考慮了跨越位元組邊界的情況,這是因為如果 6 bit在單個位元組內,上面代碼中的 high_val 的值是零,所以這一份代碼可以同時照顧單位元組和雙位元組:
// 獲取指定桶的計數值
#define HLL_DENSE_GET_REGISTER(target,p,regnum) do { \
uint8_t *_p = (uint8_t*) p; \
unsigned long _byte = regnum*HLL_BITS/8; \
unsigned long _fb = regnum*HLL_BITS&7; \ # %8 = &7
unsigned long _fb8 = 8 - _fb; \
unsigned long b0 = _p[_byte]; \
unsigned long b1 = _p[_byte+1]; \
target = ((b0 >> _fb) | (b1 << _fb8)) & HLL_REGISTER_MAX; \
} while(0)
// 設定指定桶的計數值
#define HLL_DENSE_SET_REGISTER(p,regnum,val) do { \
uint8_t *_p = (uint8_t*) p; \
unsigned long _byte = regnum*HLL_BITS/8; \
unsigned long _fb = regnum*HLL_BITS&7; \
unsigned long _fb8 = 8 - _fb; \
unsigned long _v = val; \
_p[_byte] &= ~(HLL_REGISTER_MAX << _fb); \
_p[_byte] |= _v << _fb; \
_p[_byte+1] &= ~(HLL_REGISTER_MAX >> _fb8); \
_p[_byte+1] |= _v >> _fb8; \
} while(0)
2)稀疏存盤結構
稀疏存盤適用于很多計數值都是零的情況,下圖表示了一般稀疏存盤計數值的狀態:

當 多個連續桶的計數值都是零 時,Redis 提供了幾種不同的表達形式:
00xxxxxx:前綴兩個零表示接下來的 6bit 整數值加 1 就是零值計數器的數量,注意這里要加 1是因為數量如果為零是沒有意義的,比如00010101表示連續22個零值計數器,01xxxxxx yyyyyyyy:6bit 最多只能表示連續 64 個零值計數器,這樣擴展出的 14bit 可以表示最多連續16384個零值計數器,這意味著 HyperLogLog 資料結構中16384個桶的初始狀態,所有的計數器都是零值,可以直接使用 2 個位元組來表示,1vvvvvxx:中間 5bit 表示計數值,尾部 2bit 表示連續幾個桶,它的意思是連續(xx +1)個計數值都是(vvvvv + 1),比如10101011表示連續4個計數值都是11,
注意 上面第三種方式 的計數值最大只能表示到 32 ,而 HyperLogLog 的密集存盤單個計數值用 6bit表示,最大可以表示到 63 ,當稀疏存盤的某個計數值需要調整到大于 32時,Redis 就會立即轉換HyperLogLog的存盤結構,將稀疏存盤轉換成密集存盤,
3)物件頭
HyperLogLog 除了需要存盤 16384 個桶的計數值之外,它還有一些附加的欄位需要存盤,比如總計數快取、存盤型別,所以它使用了一個額外的物件頭來表示:
struct hllhdr {
char magic[4]; /* 魔術字串"HYLL" */
uint8_t encoding; /* 存盤型別 HLL_DENSE or HLL_SPARSE. */
uint8_t notused[3]; /* 保留三個位元組未來可能會使用 */
uint8_t card[8]; /* 總計數快取 */
uint8_t registers[]; /* 所有桶的計數器 */
};
所以 HyperLogLog 整體的內部結構就是 HLL 物件頭 加上 16384 個桶的計數值位圖,它在 Redis 的內部結構表現就是一個字串位圖,你可以把 HyperLogLog 物件當成普通的字串來進行處理:
> PFADD codehole python java golang
(integer) 1
> GET codehole
"HYLL\x01\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80C\x03\x84MK\x80P\xb8\x80^\x f3"
但是 不可以 使用 HyperLogLog 指令來 操縱普通的字串,因為它需要檢查物件頭魔術字串是否是"HYLL",
4.HyperLogLog的使用
HyperLogLog 提供了兩個指令PFADD和PFCOUNT,字面意思就是一個是增加,另一個是獲取計數,PFADD 和 set 集合的 SADD 的用法是一樣的,來一個用戶 ID,就將用戶 ID 塞進去就是, PFCOUNT 和 SCARD 的用法是一致的,直接獲取計數值:
> PFADD codehole user1
(interger) 1
> PFCOUNT codehole
(integer) 1
> PFADD codehole user2
(integer) 1
> PFCOUNT codehole
(integer) 2
> PFADD codehole user3
(integer) 1
> PFCOUNT codehole
(integer) 3
> PFADD codehole user4 user 5
(integer) 1
> PFCOUNT codehole
(integer) 5
我們可以用 Java 撰寫一個腳本來試試 HyperLogLog 的準確性到底有多少:
public class JedisTest {
public static void main(String[] args) {
for (int i = 0; i < 100000; i++) {
jedis.pfadd("codehole", "user" + i);
}
long total = jedis.pfcount("codehole");
System.out.printf("%d %d\n", 100000, total);
jedis.close();
}
}
結果輸出如下:
100000 99723
發現 10 萬條資料只差了277 ,按照百分比誤差率是 0.277%,對于巨量的 UV 需求來說,這個誤差率真的不算高,
當然,除了上面的 PFADD 和 PFCOUNT 之外,還提供了第三個PFMEGER指令,用于將多個計數值累加在一起形成一個新的 pf 值:
> PFADD nosql "Redis" "MongoDB" "Memcached"
(integer) 1
> PFADD RDBMS "MySQL" "MSSQL" "PostgreSQL"
(integer) 1
> PFMERGE databases nosql RDBMS OK> PFCOUNT databases
(integer) 6
參考資料:《Java中高級核心知識全面決議》限量100份,有一些人已經通過我之前的文章獲取了哦!
名額有限先到先得!!!
有想要獲取這份學習資料的同學可以點擊這里免費獲取》》》》》》》
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/239089.html
標籤:其他
上一篇:網路協議TCP和UDP的基本原理