oracle DG
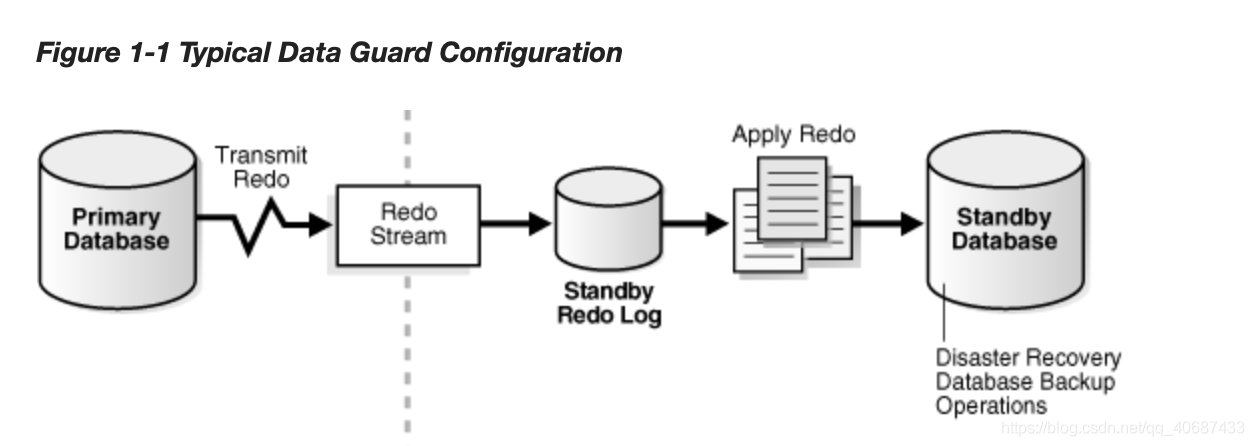
ORACLE主備就是DATAGUARD,也就是DG,主庫叫primary,備庫叫standby
ORACLE的只讀庫:ADG,ACTIVE DATAGUARD,oracle 11g開始支持,可以將備庫打開為readonly狀態,可以分攤IO讀的業務壓力,也就是說備庫沒有打開為readonly稱為DG,打開為readonly稱為ADG,
ADG架構
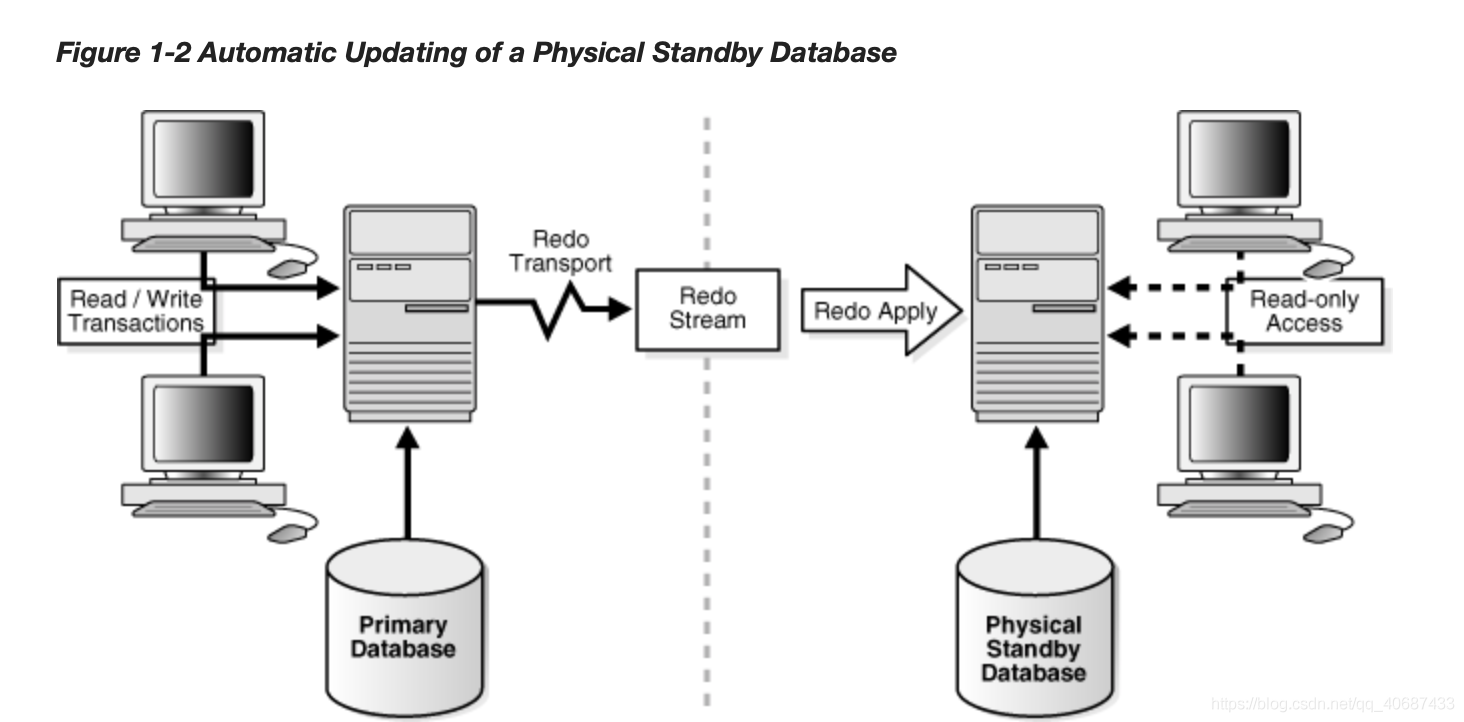
oracle的同步方式:物理備庫和邏輯備庫,
物理備庫:將redo直接應用到備庫上,將block塊進行覆寫,是block物理層面的復制,跟sql無關,
邏輯備庫:將redo決議成sql,通過sql在備庫上重演完成備庫同步,
物理備庫和邏輯備庫的優劣
物理備庫的優勢:
1.高效性,從底層block同步,與上層sql無關,資料同步具有高效性,比如主庫一個sql執行10s,更改1000個塊,物理備庫僅需要更改這個1000個塊即可,不需要管sql本身的執行計劃,對于sql執行較長,最終更改1、2行資料的情況,物理備庫的同步效率會更高,
2.資料一致性,物理備庫與上層sql無關,只要沒有延時,就不會出現資料不一致的情況,redo本身就是物理形態,由主庫生成,通過網路傳播到備庫去應用,中間對redo沒有任何轉換,模式簡單沒有坑,邏輯備庫的表必須有主鍵才能保證資料一致性,備庫在應用時必須將物理redo決議成邏輯sql,理論上資料會一致,即時這樣資料一致性也沒有物理備庫那樣的強一致優勢,如果邏輯備庫上因某些原因某行資料不一致,這個小“污點”不易發現,還很有可能會擴大,不一致的資料會越來越多,修復起來也特別困難,
邏輯備庫的優勢:
1.靈活性,邏輯備庫可以處于打開狀態,業務允許修改非同步資料甚至同步資料(不建議),靈活定制資料,
2.壞塊的處理,物理備庫直接使用redo覆寫block,主庫物理壞塊備庫也會壞塊,邏輯備庫主備物理層block構造不一樣,sql可以執行說明sql在備庫是可用的,對壞塊是一種保護,
oracle物理備庫和邏輯備庫的選擇:
簡單粗暴:物理備庫,傳統行業幾乎沒有邏輯備庫的應用,物理備庫的資料一致性和可靠性對傳統行業來說非常香,oracle物理備庫的應用已經非常廣泛,物理DG架構已經非常成熟,業內認證,我們在討論oracle的備庫時一般指的dg物理備庫,就是邏輯備庫可能會踩坑,如果真的要邏輯備庫,為啥不上mysql等開源庫,更加靈活,而且for free~
oracle的保護模式
最大保護模式:在Maximum protection下, 可以保證從庫和主庫資料完全一樣,做到zero data loss.事務同時在主從兩邊提交完成,才算事務完成,如果從庫宕機或者網路出現問題,主從庫不能通訊,主庫也立即宕機,在這種方式下,具有最高的保護等級,但是這種模式對主庫性能影響很大,要求高速的網路連接,
最大可用模式:在Maximum availability模式下,如果和從庫的連接正常,運行方式等同Maximum protection模式,事務也是主從庫同時提交,如果從庫和主庫失去聯系,則主庫自動切換到Maximum performance模式下運行,保證主庫具有最大的可用性,
最大性能模式:在Maximum performance,主庫把歸檔的 archived log通過arch行程傳遞給從庫,在這種方式下,主庫運行性能最高,但是不能保證資料不丟失,且丟失的資料受redo log的大小影響,在redo log過大的情況下,可能一天都沒有歸檔一個日志,可以通過手工切換日志的方式來減小資料的丟失,
保護模式的選擇
傳統行業大多數情況下都是最大性能模式,少數最大可用模式,最大保護模式幾乎沒有,主庫宕機背不起這鍋,
oracle DG的搭建
在物理DG搭建程序中,較為關鍵的環境就是全量資料的生成,拉全量資料有2種方式,一個是從主庫的備份中拉取,restore recover的程序,一個是duplicate(11g開始支持),直接從主庫復制全量資料到備庫,全量資料搞定后,資料庫處于基于某個時間點的一致性狀態,這時開啟同步追溯redolog觀察lag等資訊,DG就算搭建完成了,
oracle adg搭建手冊:
https://blog.csdn.net/qq_40687433/article/details/85625266
mysql主從
mysql的同步模式
異步復制(Asynchronous replication)
MySQL默認的復制即是異步的,主庫在執行完客戶端提交的事務后會立即將結果返給給客戶端,并不關心從庫是否已經接收并處理,這樣就會有一個問題,主如果crash掉了,此時主上已經提交的事務可能并沒有傳到從上,如果此時,強行將從提升為主,可能導致新主上的資料不完整,
全同步復制(Fully synchronous replication)
指當主庫執行完一個事務,所有的從庫都執行了該事務才回傳給客戶端,因為需要等待所有從庫執行完該事務才能回傳,所以全同步復制的性能必然會收到嚴重的影響,
半同步復制(Semisynchronous replication)
介于異步復制和全同步復制之間,主庫在執行完客戶端提交的事務后不是立刻回傳給客戶端,而是等待至少一個從庫接收到并寫到relay log中才回傳給客戶端,相對于異步復制,半同步復制提高了資料的安全性,同時它也造成了一定程度的延遲,這個延遲最少是一個TCP/IP往返的時間,所以,半同步復制最好在低延時的網路中使用,
oracle和mysql的模式區別
可以看出oracle的最大保護模式和mysql全同步是類似的,oracle的異步復制和mysql的最大性能模式是類似的,但是oracle的最大可用模式和mysql的半同步是不同的,半同步是針對整個主備集來定義的,備庫中只要一個備庫接收到binlog并寫入relay,主庫即可提交,而最大可用模式是針對主備的,是最大保護和最大性能的中間模式,平時處于最大保護模式,當判斷備庫不可用時,切換到最大性能模式,
mysql的同步方式
mysql的binlog
在解釋mysql的同步方式前,需要了解下mysql雙寫,雙寫既是redo和binlog同時寫,redo是物理資料頁redolog,mysql沒有歸檔的概念,binlog是邏輯資料變更日志(oracle只有redo,沒有binlog邏輯寫),binlog有3種模式,默認為row模式,它不是純sql,也不是物理塊,而是行的完整變化,
關于mysql雙寫的思考,mysql為什么有雙寫,oracle就沒有?
很多人說雙寫是為了保障資料的可恢復性,那為什么oracle就只需要redo,就沒人質疑它的可靠性呢?個人認為這跟設計架構有關系,oracle本身從設計之初就是一個整體,redo提前寫入落盤即可保證事務的持久性(ACID中的D持久性),而mysql的binlog是server層的,server層在設計的時候就需要考慮在無法預知存盤引擎架構的情況下,如何保證事務的持久性,那么就只能從server層寫入檔案系統,mysql的備庫就需要應用binlog(備庫的relay),redo是innodb存盤引擎層,存盤引擎在設計時必須考慮存盤引擎的可靠性,資料庫在崩潰時如何恢復?當redo日志寫入但是資料仍未落盤,資料庫start時就需要實體恢復,實體恢復就需要應用redo進行前滾,對于mysql來說,雙寫是有必要的,(這個雙寫的原因僅代表個人的思考)
binlog的GTID
GTID是binlog中的事物ID,沒有binlog就沒有GTID,GTID跟mysql的lsn號或oracle的scn號是有區別的,lsn和scn可以理解為資料庫內的時間線,GTID是存在于binlog中的事物ID號,備庫可以根據GTID去追蹤日志,GTID默認是關閉的,建議打開,
mysql的同步
mysql通過傳遞binlog進行同步,binlog傳遞到備庫后叫relay log,備庫應用relay,在資料庫沒有打開GTID的情況下,備庫只有通過pos(position,位元組號)找到需要同步的開始時間點,pos同步可能會有問題,因為binlog和relay不一定是一一對應的,log號不一定對應,pos也不一定對應,但是如果開啟GTID同步,備庫中斷只需要找到GTID即可,在開啟同步時可以設定master_auto_postion=1,而pos同步需要指定binlog file和binlog pos,如:master_log_file='master-bin.000002',master_log_pos=154,
mysql主從搭建
如果開啟GTID,mysql主從同步是比較簡單的,使用change master命令開啟同步以后主庫傳遞binlog,備庫接受binlog并寫入relay,備庫應用relay,因為mysql從庫是邏輯備庫,全量資料拉取也比較靈活,從資料庫層來說,mysql拉全量資料有2種辦法:用三方工具xtrabackup(物理),mysqldump(邏輯),xtrabackup可以進行熱備份(僅鎖innodb元資料,不會鎖資料行),根據lsn號scan up log,并將lsn號以后的事務記錄下來,在prepare時進行recover(類似oracle的recover),xtrabackup在備份時會記錄pos并放在xtrabackup_binlog_pos_innodb,開啟主從時可如開啟GTID可直接指定auto position,未開啟GTID需要指定xtrabackup_binlog_pos_innodb中的pos值,mysqldump需要鎖表以保證資料的一致性,mysql從庫可以直接打開(建議從庫設定成readonly狀態),
mysql xtrabackup搭建主從:
https://blog.csdn.net/qq_40687433/article/details/108004966?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522160854502316780288280464%252522%25252C%252522scm%252522%25253A%25252220140713.130102334.pc%25255Fblog.%252522%25257D&request_id=160854502316780288280464&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-1-108004966.pc_v1_rank_blog_v1&utm_term=主從
mysql xtrabackup熱備和oracle rman熱備的區別:
https://blog.csdn.net/qq_40687433/article/details/107367562?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522160854402916780279192065%252522%25252C%252522scm%252522%25253A%25252220140713.130102334.pc%25255Fblog.%252522%25257D&request_id=160854402916780279192065&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-2-107367562.pc_v1_rank_blog_v1&utm_term=rman
mongodb主從
mongodb是檔案型資料庫,非關系型資料庫,mongodb的Master-Slaver主從架構已不推薦使用了,mongo的主流主從副本架構為Replica Set(副本集),
Replica Set副本集
mongodb建議最小架構為1主2從(詳看選舉機制就知道為啥最小是3個節點),主節點接收所有寫入操作,從節點異步復制和應用主節點oplog,oplog記錄資料庫上的所有變更操作,mongodb還沒有半同步或者保護模式的形式來保護資料的強可靠性,復制操作是異步的,
1主2從副本集:
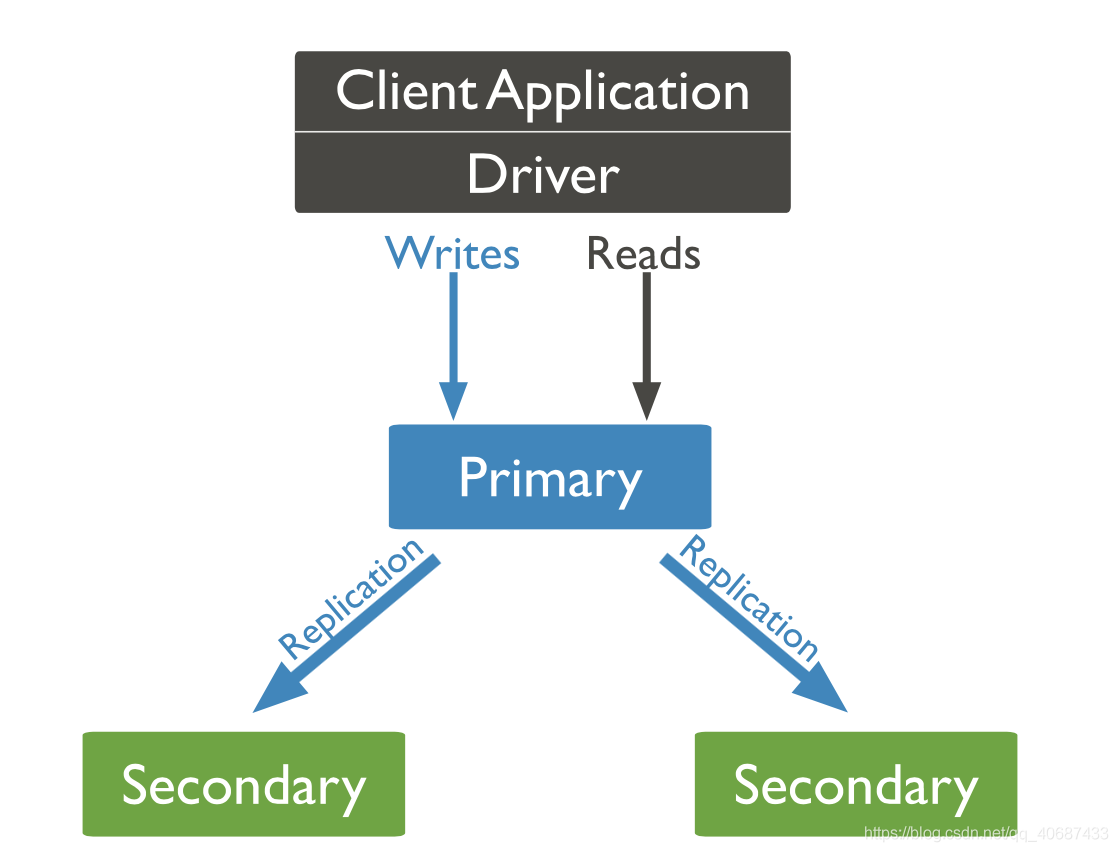
(secondary間也是有heardbeat的,以判斷節點的可用性)
選舉機制
heardbeat會判斷節點是否可用,當至少有n/2+1個節點都檢測到主節點不可用時,那么這幾個節點就需要選舉出最高領導者primary,已形成新的副本集服務,每個secondary會發起為自己成為primary的投票,這個時候每個贊成票可能為+1,但是每個反對票為較大的負數,比如-10000,(復制集最多只能有50個節點和7個選舉節點)所以只要有1個節點認為這個節點不能成為他的主節點,那么這個節點就不能成為主節點,比如當被選舉節點的資料更新慢于其他節點時,那么它就不能被選舉成為主節點,其他節點會投反對票,所以在n/2+1個節點中肯定會有一個節點是最新的,它會獲得n/2個贊成票,這個節點就選舉成為主節點,
選舉節點
選舉節點概念:arbiter為選舉節點,僅負責選舉,不負責復制存盤資料和提供對外服務
1主1從1選舉節點副本集:
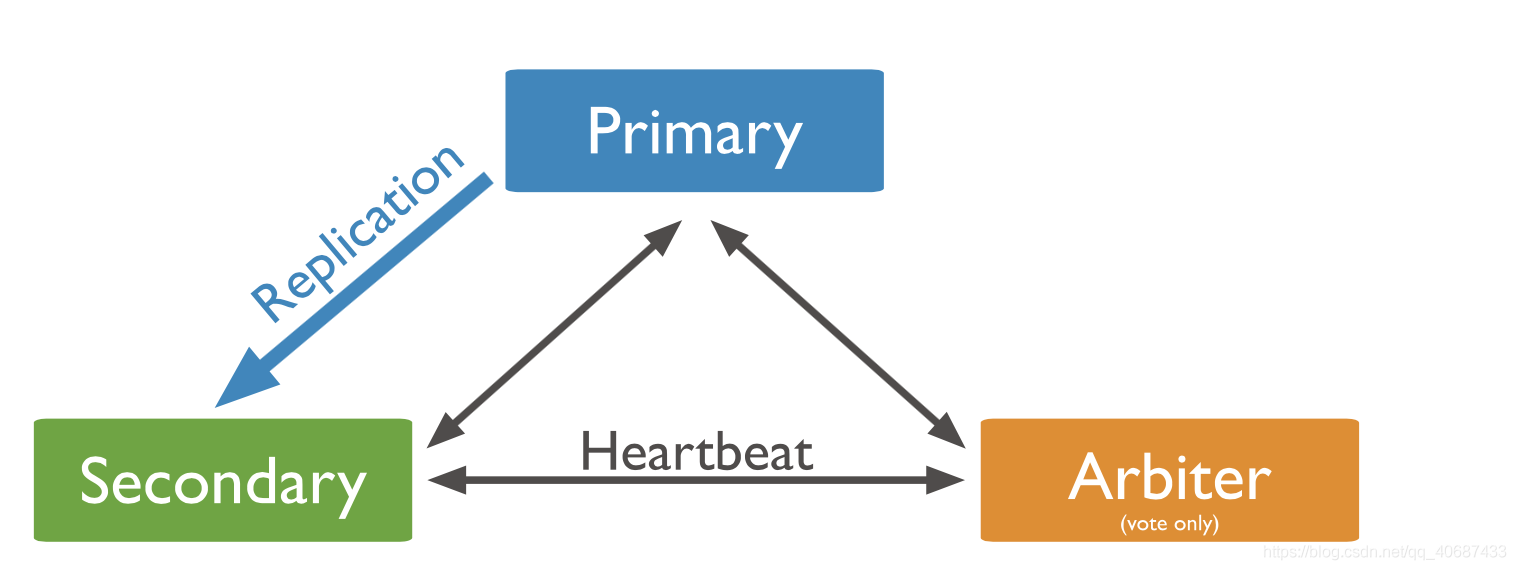
1:1架構的弊端:當搭建復制集時采用1主1從的架構,那么當2個節點間的網路不可用時,要不是primary繼續提供服務,不要是secondary提升為主節點提供服務,那么到底該選哪一個呢?在mongodb復制集架構中,當故障發生選舉時,必須有n/2+1個節點存活時,才可提供對外服務,所以在1:1的架構中只要網路不可用,2個節點都不可以成為主節點,以此類推,偶數個節點的復制集,當他們以55分為2個機房中,當2個機房網路不可用,那么這個復制集就不可用,無法提供對外服務,
這時如果我們讓復制集成為單數個,就可以解決這個問題,單數如果資源不夠用,沒有辦法再加入secondary怎么辦?這個時候就可以使用arbiter選舉節點,選舉節點不會存盤資料,沒有mongo server行程,它可消除選舉程序的偶數隱患,當選舉節點跟secondary一個機房,網路不可用時,primary節點成為備份節點,secondary和arbier成為新的可用復制集,建議應盡可能使用奇數個節點,且全部為資料節點,
ReplicaSet的同步
rs.initiate操作會掃描除了local庫外的所有資料庫的所有集合,并插入到secondary,secondary成員在初始化完成后立即開啟復制oplog,并應用oplog上的變更操作,mongo4.4開始,sync支持流復制oplog,
redis主從
redis是key-value記憶體型資料庫,
redis的持久化
redis不具備ACID中的durable持久性,redis是記憶體型資料庫,資料寫在記憶體中暫不寫入磁盤,且沒有redolog,一但發生主機崩潰等意外情況,redis的資料存在丟失風險,對于某些應用來說,redis資料這部分允許丟失部分資料,redis可以不優先考慮redo預寫和落盤,這也是為什么redis“快”的重要原因,記憶體型資料的重要模塊之一就是持久化(也就是資料落盤),redis也是有持久化的,redis持久化有2種手段:NDB和AOF,
RDB和AOF
redis有2種持久化方式,rdb持久化和aof持久化還有RDB+AOF的持久化
RDB基線全量持久化,全量持久化保留基線資料,rdb檔案存盤key鍵值,特定時間點觸發,save/bgsave手動觸發rdb持久化,save會阻塞所有操作,bgsave則不會,兩者都會將記憶體中的所有資料寫入RDB檔案當中,
AOF命令持久化,增量持久化保留變更命令,類似binlog,appendfsync打開時才啟用aof持久化,默認是關閉的,appendfsync有3種情況,always,everysec,no,
redis4開始支持RDB+AOF的持久化,此時aof僅做增量持久化,不會存盤全量日志,redis重啟時先加載rdb再加載aof
redis的ACID持久性
如果掉電,丟失的資料取決于持久化的策略,
如果是RDB持久化,那么一般來說肯定會有資料丟失(除非每個事物后都跟上SAVE或BGSAVE,這基本上不可能的)
如果是AOF持久化,appendfsync不為always,肯定會有資料丟失,但是如果是always,每個事物都會寫盤,會丟失一定的性能,RDB+AOF持久化同理,
redis主從原理
1.從服務器向主服務器發送SYNC命令
2.主服務器執行BGSAVE命令,生成RDB檔案,并使用一個緩沖區記錄從bgsave開始的所有寫命令
3.主服務器BGSAVE執行完后,將RDB發送給從服務器,從服務器載入RDB檔案,將自己的狀態更新至主服務器的BGSAVE時的狀態
4.主服務器將緩沖區的寫命令發送給從服務器,從服務器執行寫命令, 將從服務器更新為主服務器的當前態
復制緩沖區和中斷重連:
1 復制緩沖區是主服務器固定長度(默認1mb)先進先出佇列
2 主庫將寫入操作放在復制緩沖區,從庫斷開后,發送從庫的偏移量給主庫,主庫在復制緩沖區中找是否有這個偏移量,有就發送continue繼續從這個偏移量寫,沒有就重新初始化,
redis主從搭建
slaveof命令即可完成初始化和命令傳播的操作,一個命令即可,redis的主從同步也是異步的,
redis主從搭建:
https://blog.csdn.net/qq_40687433/article/details/108737408?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522160861988716780273321830%252522%25252C%252522scm%252522%25253A%25252220140713.130102334.pc%25255Fblog.%252522%25257D&request_id=160861988716780273321830&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v1~rank_blog_v1-5-108737408.pc_v1_rank_blog_v1&utm_term=redis
分布式資料庫OCEANBASE
ob最小搭建要求就需要3個節點,ob是準記憶體型資料庫,分布式資料庫
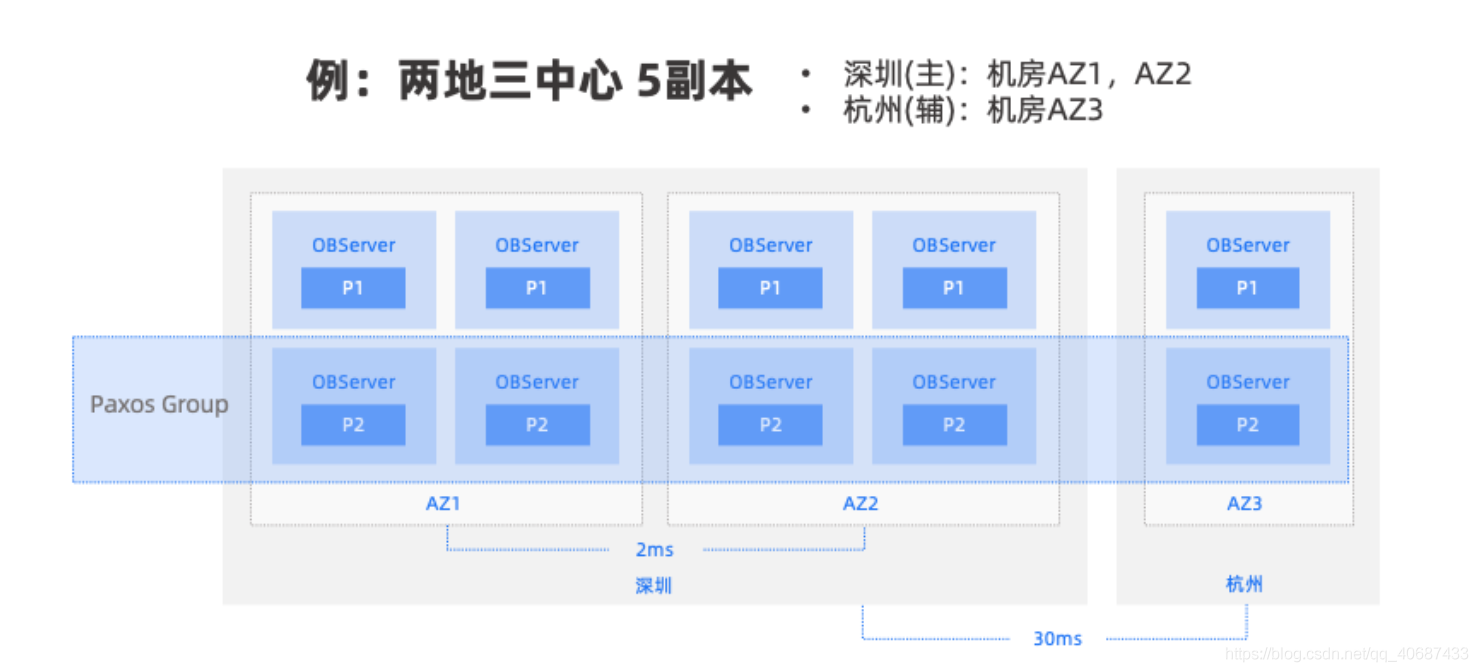
ob的持久性
ob是準記憶體型資料庫,當事務完成后不會立即寫入磁盤,只有當發生轉儲時才會寫入到磁盤,那么ob如何保持資料的持久性?在paxos協議中,事務只有當至少(n/2+1)個節點完成事務時,這個事務才真正完成,比如3個節點的ob,至少要2個節點完成事務,這個事務才真正的完成,就算一個節點宕機,就算有臟資料沒有寫入磁盤,事務也不會丟失,ob具備事務的持久性
ob的持久化——轉儲與合并
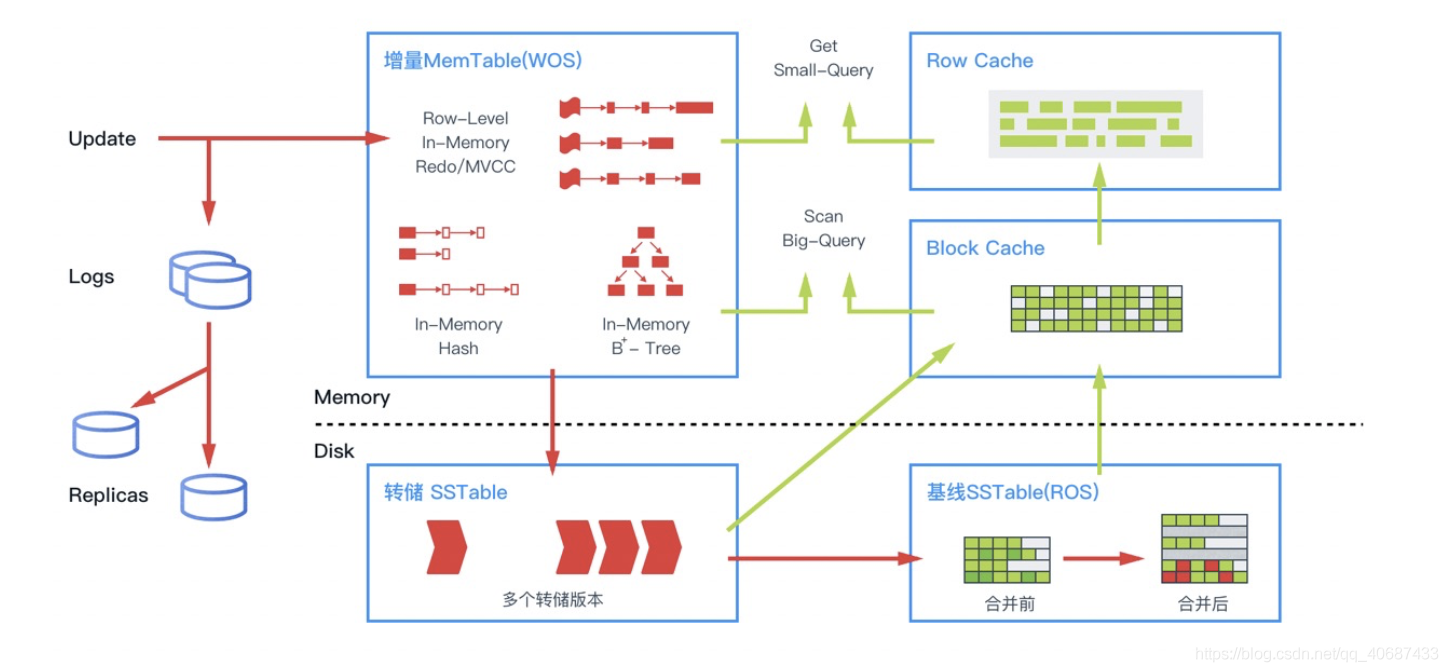
轉儲是將記憶體資料順序存盤到磁盤上
合并是將基線和記憶體資料離散的存盤到磁盤上
合并的寫入代價更改,合并會將基線資料讀出并跟記憶體資料進行合并,然后再回傳寫入到磁盤原來的位置,
轉儲也會讀取基線資料,將增量資料涉及的表全部讀取并順序的寫入到磁盤中,
基線資料是順序存盤在磁盤上的,讀取記憶體后會形成b+樹,資料在記憶體中不會直接被修改,而是以事務鏈表的形式存盤變更資料,它可能只會更改一個列,但是不會讀取整個資料塊到記憶體中,只有當發生轉儲或合并時,才會寫入到磁盤,
ob不適合大量資料讀取或者寫入,更適合高并發少量的資料讀取或者寫入,
總結
mongodb的ReplicaSet跟ob有些類似,他們都把副本集看成一個整體,但是mongodb沒有paxos協議支撐主副本資料一致,ob資料更新時不落盤的特性跟redis又有些類似,他們都是舍棄掉了像oracle和mysql這樣的實時落盤操作,以大幅提升性能,而redis又不像ob那樣從架構上去保證資料不會丟失,而ob的轉儲和合并又導致ob不適合大資料量的查詢和更新,ob對于高并發和結果只影響少量資料的操作是非常適合的,
每個資料庫都有其特點,比如oracle的目標就是集所有功能于一身,功能非常強大,當然成本也非常高,mysql同樣是關系型資料,聚簇索引的結構也適合于檢索資料,對于資料量較少,壓力不大的應用是非常適合的,大部分存盤在mysql的應用僅需要“存盤”功能,mysql是非常合適的,redis和mongo就更加具有針對性,對于資料安全要求沒有特別高,但是資料回應極高的場景,就適合使用redis,可能很多開發都不會把他當成資料庫來使用,mongodb是非關系型資料庫,資料存盤非常靈活,mongodb也有鍵的概念,一個檔案可以有多個鍵,使用起來要比redis復雜許多,oceanbase在雙十一的應用相信不會有人質疑其實力,ob很適合高并發低結果集的場景,它的資料鏡像架構有別于傳統資料庫,多數節點寫入的前提可以保證其資料不丟失,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/239194.html
標籤:其他
上一篇:AXI總線 詳細整理
下一篇:Java中高級核心知識全面決議——Redis(分布式鎖【簡介、實作】、Redlock分布式鎖、HyperLoglog【簡介、原理、實作、使用】)2