目錄
- 一、5種基本資料結構
- 1.Redis簡介
- 1)Redis 的優點
- 2)Redis 的安裝
- 3) 測驗本地 Redis 性能
- 2.Redis五種基本資料結構
- 1)字串 string
- ①、SDS 與 C 字串的區別
- ②、對字串的基本操作
- ③、設定和獲取鍵值對
- ④、批量設定鍵值對
- ⑤、過期和 SET 命令擴展
- ⑥、計數
- ⑦、回傳原值的 GETSET 命令
- 2)串列list
- ①、鏈表的基本操作
- ②、list 實作佇列
- ③、list 實作堆疊
- 3)字典 hash
- ①、漸進式 rehash
- ②、擴縮容的條件
- ③、字典的基本操作
- 4)集合 set
- ①、集合 set 的基本使用
- 5)有序串列 zset
- ①、有序串列 zset 基礎操作
- 二、跳躍表
- 1.跳躍表簡介
- 1)為什么使用跳躍表
- 2)本質是解決查找問題
- 3)更進一步的跳躍表
- 2.跳躍表的實作
- 1)隨機層數
- 2)創建跳躍表
- 3)插入節點實作
- 第一部分:宣告需要存盤的變數
- 第二部分:搜索當前節點插入位置
- 第三部分:生成插入節點
- 第四部分:重排前向指標
- 第五部分:重排后向指標并回傳
- 4)節點洗掉實作
- 5)節點更新實作
- 6)元素排名的實作
一、5種基本資料結構
1.Redis簡介
“Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.” —— Redis是一個開放源代碼(BSD許可)的記憶體中資料結構存盤,用作資料庫,快取和訊息代理, (摘自官網)
Redis是一個開源,高級的鍵值存盤和一個適用的解決方案,用于構建高性能,可擴展的 Web 應用程式,Redis也被作者戲稱為資料結構服務器 ,這意味著使用者可以通過一些命令,基于帶有 TCP 套接字的簡單服務器-客戶端 協議來訪問一組可變資料結構 ,(在Redis中都采用鍵值對的方式,只不過對應的資料結構不一樣罷了)
1)Redis 的優點
以下是 Redis 的一些優點:
- 例外快 - Redis 非常快,每秒可執行大約 110000 次的設定(SET)操作,每秒大約可執行 81000 次的讀取/獲取(GET)操作,
- 支持豐富的資料型別 - Redis 支持開發人員常用的大多數資料型別,例如串列,集合,排序集和散列等等,這使得 Redis 很容易被用來解決各種問題,因為我們知道哪些問題可以更好使用地哪些資料型別來處理解決,
- 操作具有原子性 - 所有 Redis 操作都是原子操作,這確保如果兩個客戶端并發訪問,Redis 服務器能接收更新的值,
- 多實用工具 - Redis 是一個多實用工具,可用于多種用例,如:快取,訊息佇列(Redis 本地支持發布/訂閱),應用程式中的任何短期資料,例如,web應用程式中的會話,網頁命中計數等,
2)Redis 的安裝
這一步比較簡單,你可以在網上搜到許多滿意的教程,這里就不再贅述,
給一個菜鳥教程的安裝教程用作參考:https://www.runoob.com/redis/redis-install.html
3) 測驗本地 Redis 性能
當你安裝完成之后,你可以先執行 redis-server 讓 Redis 啟動起來,然后運行命令 redis- benchmark -n 100000 -q 來檢測本地同時執行 10 萬個請求時的性能:
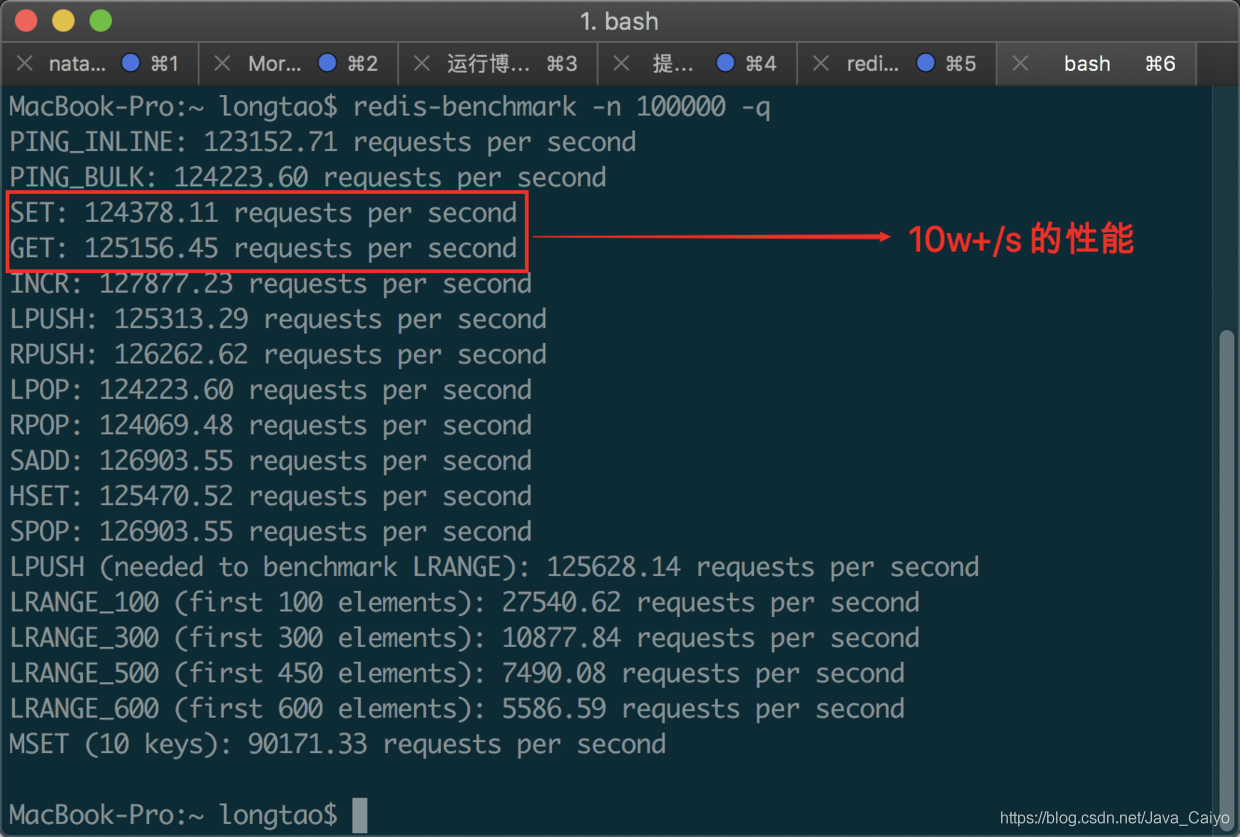
當然不同電腦之間由于各方面的原因會存在性能差距,這個測驗您可以權當是一種「樂趣」就好,
2.Redis五種基本資料結構
Redis有 5 種基礎資料結構,它們分別是:string(字串)、list(串列)、hash(字典)、set(集合) 和zset(有序集合),這 5 種是 Redis 相關知識中最基礎、最重要的部分,下面我們結合原始碼以及一些實踐來給大家分別講解一下,
注意:
每種資料結構都有自己底層的內部編碼實作,而且是多種實作,這樣Redis會在合適的場景選擇合適的內部編碼,
可以看到每種資料結構都有兩種以上的內部編碼實作,例如string資料結構就包含了raw、int和embstr三種內部編碼,
同時,有些內部編碼可以作為多種外部資料結構的內部實作,例如ziplist就是hash、list和zset共有的內部編碼,
1)字串 string
Redis 中的字串是一種 動態字串,這意味著使用者可以修改,它的底層實作有點類似于 Java 中的ArrayList,有一個字符陣列,從原始碼的 sds.h/sdshdr 檔案 中可以看到 Redis 底層對于字串的定義SDS,即 Simple Dynamic String 結構:
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
你會發現同樣一組結構 Redis 使用泛型定義了好多次,為什么不直接使用 int 型別呢?
因為當字串比較短的時候,len 和 alloc 可以使用 byte 和 short 來表示,Redis 為了對記憶體做極致的優化,不同長度的字串使用不同的結構體來表示,
①、SDS 與 C 字串的區別
為什么不考慮直接使用 C 語言的字串呢?因為 C 語言這種簡單的字串表示方式 不符合 Redis 對字串在安全性、效率以及功能方面的要求,我們知道,C 語言使用了一個長度為 N+1 的字符陣列來表示長度為 N 的字串,并且字符陣列最后一個元素總是 '\0' ,(下圖就展示了 C 語言中值為 “Redis” 的一 個字符陣列)

這樣簡單的資料結構可能會造成以下一些問題:
- 獲取字串長度為 O(N) 級別的操作 → 因為 C 不保存陣列的長度,每次都需要遍歷一遍整個陣列;
- 不能很好的杜絕 緩沖區溢位/記憶體泄漏 的問題 → 跟上述問題原因一樣,如果執行拼接 or 縮短字串的操作,如果操作不當就很容易造成上述問題;
- C 字串 只能保存文本資料 → 因為 C 語言中的字串必須符合某種編碼(比如 ASCII),例如中間出現的 ‘\0’ 可能會被判定為提前結束的字串而識別不了;
我們以追加字串的操作舉例,Redis 原始碼如下:
/* Append the specified binary-safe string pointed by 't' of 'len' bytes to the
* end of the specified sds string 's'.
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call. */
sds sdscatlen(sds s, const void *t, size_t len) {
// 獲取原字串的長度
size_t curlen = sdslen(s);
// 按需調整空間,如果容量不夠容納追加的內容,就會重新分配位元組陣列并復制原字串的內容到新陣列中
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL; // 記憶體不足
memcpy(s+curlen, t, len); // 追加目標字串到位元組陣列中
sdssetlen(s, curlen+len); // 設定追加后的長度
s[curlen+len] = '\0'; // 讓字串以 \0 結尾,便于除錯列印
return s;
}
- 注:Redis 規定了字串的長度不得超過 512 MB,
②、對字串的基本操作
安裝好 Redis,我們可以使用 redis-cli 來對 Redis 進行命令列的操作,當然 Redis 官方也提供了在線的除錯器,你也可以在里面敲入命令進行操作:http://try.redis.io/#run
③、設定和獲取鍵值對
> SET key value
OK
> GET key
"value"
正如你看到的,我們通常使用 SET 和 GET 來設定和獲取字串值,
值可以是任何種類的字串(包括二進制資料),例如你可以在一個鍵下保存一張 .jpeg 圖片,只需要注意不要超過 512 MB 的最大限度就好了,
當 key 存在時, SET 命令會覆寫掉你上一次設定的值:
> SET key newValue
OK
> GET key
"newValue"
另外你還可以使用 EXISTS 和 DEL 關鍵字來查詢是否存在和洗掉鍵值對:
> EXISTS key
(integer) 1
> DEL key
(integer) 1
> GET key
(nil)
④、批量設定鍵值對
> SET key1 value1
OK
> SET key2 value2
OK
> MGET key1 key2 key3 # 回傳一個串列
1) "value1"
2) "value2"
3) (nil)
> MSET key1 value1 key2 value2
> MGET key1 key2
1) "value1"
2) "value2"
⑤、過期和 SET 命令擴展
可以對 key 設定過期時間,到時間會被自動洗掉,這個功能常用來控制快取的失效時間,(過期可以是 任意資料結構)
> SET key value1
> GET key
"value1"
> EXPIRE name 5 # 5s 后過期
... # 等待 5s
> GET key
(nil)
等價于 SET + EXPIRE 的 SETEX 命令:
> SETEX key 5 value1
... # 等待 5s 后獲取
> GET key
(nil)
> SETNX key value1 # 如果 key 不存在則 SET 成功
(integer) 1
> SETNX key value1 # 如果 key 存在則 SET 失敗
(integer) 0
> GET key
> "value" # 沒有改變
⑥、計數
如果 value 是一個整數,還可以對它使用 INCR 命令進行 原子性 的自增操作,這意味著及時多個客戶對同一個 key 進行操作,也決不會導致競爭的情況:
> SET counter 100
> INCR counter
(integer) 101
> INCRBY counter 50
(integer) 151
⑦、回傳原值的 GETSET 命令
對字串,還有一個GETSET比較讓人覺得有意思,它的功能跟它名字一樣:為 key 設定一個值并回傳原值:
> SET key value
> GETSET key value1
"value"
這可以對于某一些需要隔一段時間就統計的 key 很方便的設定和查看,例如:系統每當由用戶進入的時候你就是用 INCR 命令操作一個 key,當需要統計時候你就把這個 key 使用 GETSET 命令重新賦值為0,這樣就達到了統計的目的,
2)串列list
Redis 的串列相當于 Java 語言中的 LinkedList,注意它是鏈表而不是陣列,這意味著 list 的插入和洗掉操作非常快,時間復雜度為 O(1),但是索引定位很慢,時間復雜度為 O(n),
我們可以從原始碼的 adlist.h/listNode 來看到對其的定義:
小插曲:
更多阿里、騰訊、美團、京東等一線互聯網大廠Java面試真題;包含:基礎、并發、鎖、JVM、設計模式、資料結構、反射/IO、資料庫、Redis、Spring、訊息佇列、分布式、Zookeeper、Dubbo、Mybatis、Maven、面經等,
更多Java程式員技術進階小技巧;例如高效學習(如何學習和閱讀代碼、面對枯燥和量大的知識)高效溝通(溝通方式及技巧、溝通技術)
更多Java大牛分享的一些職業生涯分享檔案
請點擊這里添加》》》》》》》》》社群,免費獲取
比你優秀的對手在學習,你的仇人在磨刀,你的閨蜜在減肥,隔壁老王在練腰, 我們必須不斷學習,否則我們將被學習者超越!
趁年輕,使勁拼,給未來的自己一個交代!
/*
Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
可以看到,多個 listNode 可以通過 prev 和 next 指標組成雙向鏈表:
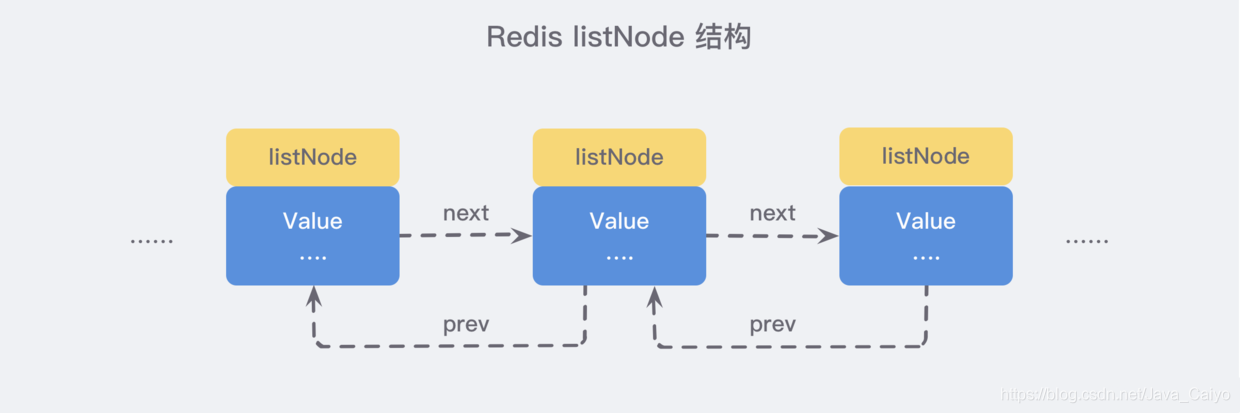
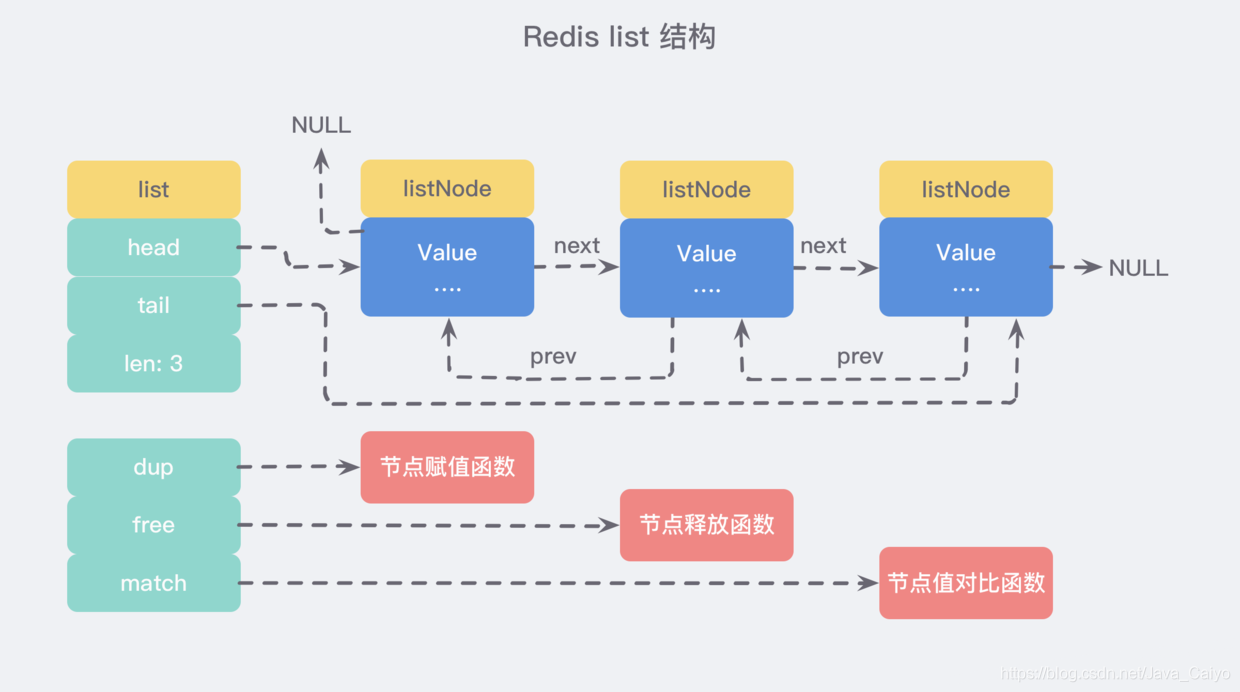
雖然僅僅使用多個 listNode 結構就可以組成鏈表,但是使用 adlist.h/list 結構來持有鏈表的話,操作起來會更加方便:
①、鏈表的基本操作
LPUSH和RPUSH分別可以向 list 的左邊(頭部)和右邊(尾部)添加一個新元素;LRANGE命令可以從 list 中取出一定范圍的元素;LINDEX命令可以從 list 中取出指定下表的元素,相當于 Java 鏈表操作中的get(int index)操作;
示范:
> rpush mylist A
(integer) 1
> rpush mylist B
(integer) 2
> lpush mylist first
(integer) 3
> lrange mylist 0 -1 # -1 表示倒數第一個元素, 這里表示從第一個元素到最后一個元素,即所有
1) "first"
2) "A"
3) "B"
②、list 實作佇列
佇列是先進先出的資料結構,常用于訊息排隊和異步邏輯處理,它會確保元素的訪問順序:
> RPUSH books python java golang
(integer) 3
> LPOP books
"python"
> LPOP books
"java"
> LPOP books
"golang"
> LPOP books
(nil)
③、list 實作堆疊
堆疊是先進后出的資料結構,跟佇列正好相反:
> RPUSH books python java golang
> RPOP books
"golang"
> RPOP books
"java"
> RPOP books
"python"
> RPOP books
(nil)
3)字典 hash
Redis 中的字典相當于 Java 中的HashMap,內部實作也差不多類似,都是通過 "陣列 + 鏈表"的鏈地址法來解區域分哈希沖突,同時這樣的結構也吸收了兩種不同資料結構的優點,原始碼定義如dict.h/dictht定義:
typedef struct dictht {
// 哈希表陣列
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩碼,用于計算索引值,總是等于size - 1
unsigned long sizemask;
// 該哈希表已有節點的數量
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
// 內部有兩個dictht結構
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
table 屬性是一個陣列,陣列中的每個元素都是一個指向dict.h/dictEntry 結構的指標,而每個dictEntry結構保存著一個鍵值對:
typedef struct dictEntry {
// 鍵
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 指向下個哈希表節點,形成鏈表
struct dictEntry *next;
} dictEntry;
可以從上面的原始碼中看到,實際上字典結構的內部包含兩個 hashtable,通常情況下只有一個hashtable 是有值的,但是在字典擴容縮容時,需要分配新的 hashtable,然后進行 漸進式搬遷 (下面說原因),
①、漸進式 rehash
大字典的擴容是比較耗時間的,需要重新申請新的陣列,然后將舊字典所有鏈表中的元素重新掛接到新的陣列下面,這是一個O(n) 級別的操作,作為單執行緒的Redis很難承受這樣耗時的程序,所以 Redis使用漸進式 rehash小步搬遷:
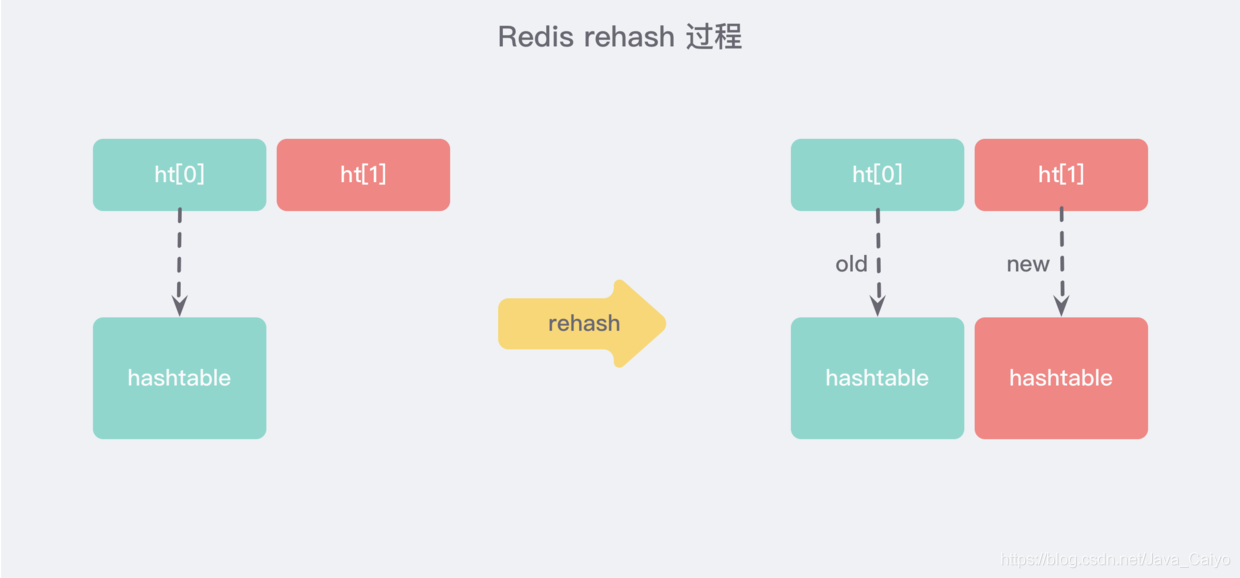
漸進式 rehash 會在 rehash 的同時,保留新舊兩個 hash 結構,如上圖所示,查詢時會同時查詢兩個hash結構,然后在后續的定時任務以及 hash 操作指令中,循序漸進的把舊字典的內容遷移到新字典中,當搬遷完成了,就會使用新的 hash 結構取而代之,
②、擴縮容的條件
正常情況下,當 hash 表中 元素的個數等于第一維陣列的長度時,就會開始擴容,擴容的新陣列是 原陣列大小的 2 倍,不過如果 Redis 正在做 bgsave(持久化命令),為了減少記憶體也得過多分離,Redis 盡量不去擴容,但是如果 hash 表非常滿了,達到了第一維陣列長度的 5 倍了,這個時候就會 強制擴容,
當 hash 表因為元素逐漸被洗掉變得越來越稀疏時,Redis 會對 hash 表進行縮容來減少 hash 表的第一維陣列空間占用,所用的條件是元素個數低于陣列長度的 10%,縮容不會考慮 Redis 是否在做bgsave,
③、字典的基本操作
hash 也有缺點,hash 結構的存盤消耗要高于單個字串,所以到底該使用 hash 還是字串,需要根據實際情況再三權衡:
> HSET books java "think in java" # 命令列的字串如果包含空格則需要使用引號包裹
(integer) 1
> HSET books python "python cookbook"
(integer) 1
> HGETALL books # key 和 value 間隔出現
1) "java"
2) "think in java"
3) "python"
4) "python cookbook"
> HGET books java
"think in java"
> HSET books java "head first java"
(integer) 0 # 因為是更新操作,所以回傳 0
> HMSET books java "effetive java" python "learning python" # 批量操作 OK
4)集合 set
Redis 的集合相當于 Java 語言中的 HashSet,它內部的鍵值對是無序、唯一的,它的內部實作相當于一個特殊的字典,字典中所有的 value 都是一個值 NULL,
①、集合 set 的基本使用
由于該結構比較簡單,我們直接來看看是如何使用的:
> SADD books java
(integer) 1
> SADD books java # 重復
(integer) 0
> SADD books python golang
(integer) 2
> SMEMBERS books # 注意順序,set 是無序的
1) "java"
2) "python"
3) "golang"
> SISMEMBER books java # 查詢某個 value 是否存在,相當于 contains
(integer) 1
> SCARD books # 獲取長度
(integer) 3
> SPOP books # 彈出一個
"java"
5)有序串列 zset
這可能使 Redis 最具特色的一個資料結構了,它類似于 Java 中 SortedSet 和 HashMap 的結合體,一方面它是一個 set,保證了內部 value 的唯一性,另一方面它可以為每個 value 賦予一個 score 值,用來代表排序的權重,
它的內部實作用的是一種叫做 「跳躍表」 的資料結構,由于比較復雜,所以在這里簡單提一下原理就好了:
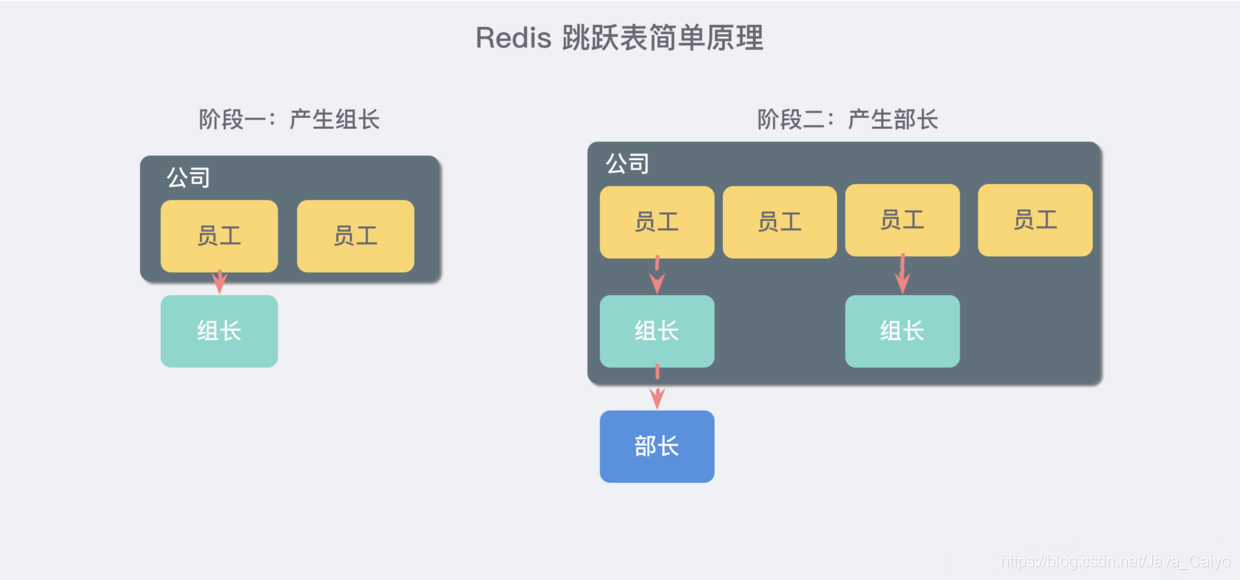
想象你是一家創業公司的老板,剛開始只有幾個人,大家都平起平坐,后來隨著公司的發展,人數越來越多,團隊溝通成本逐漸增加,漸漸地引入了組長制,對團隊進行劃分,于是有一些人又是員工又有組長的身份,
再后來,公司規模進一步擴大,公司需要再進入一個層級:部門,于是每個部門又會從組長中推舉一位選出部長,
跳躍表就類似于這樣的機制,最下面一層所有的元素都會串起來,都是員工,然后每隔幾個元素就會挑選出一個代表,再把這幾個代表使用另外一級指標串起來,然后再在這些代表里面挑出二級代表,再串起來,最終形成了一個金字塔的結構,
想一下你目前所在的地理位置:亞洲 > 中國 > 某省 > 某市 > …,就是這樣一個結構!
①、有序串列 zset 基礎操作
> ZADD books 9.0 "think in java"
> ZADD books 8.9 "java concurrency"
> ZADD books 8.6 "java cookbook"
> ZRANGE books 0 -1 # 按 score 排序列出,引數區間為排名范圍
1) "java cookbook"
2) "java concurrency"
3) "think in java"
> ZREVRANGE books 0 -1 # 按 score 逆序列出,引數區間為排名范圍
1) "think in java"
2) "java concurrency"
3) "java cookbook"
> ZCARD books # 相當于 count()
(integer) 3
> ZSCORE books "java concurrency" # 獲取指定 value 的 score
"8.9000000000000004" # 內部 score 使用 double 型別進行存盤,所以存在小數點精度問題
> ZRANK books "java concurrency" # 排名
(integer) 1
> ZRANGEBYSCORE books 0 8.91 # 根據分值區間遍歷 zset
1) "java cookbook"
2) "java concurrency"
> ZRANGEBYSCORE books -inf 8.91 withscores # 根據分值區間 (-∞, 8.91] 遍歷 zset,同時回傳分值,inf 代表 infinite,無窮大的意思,
1) "java cookbook"
2) "8.5999999999999996"
3) "java concurrency"
4) "8.9000000000000004"
> ZREM books "java concurrency" # 洗掉 value
(integer) 1
> ZRANGE books 0 -1
1) "java cookbook"
2) "think in java"
二、跳躍表
1.跳躍表簡介
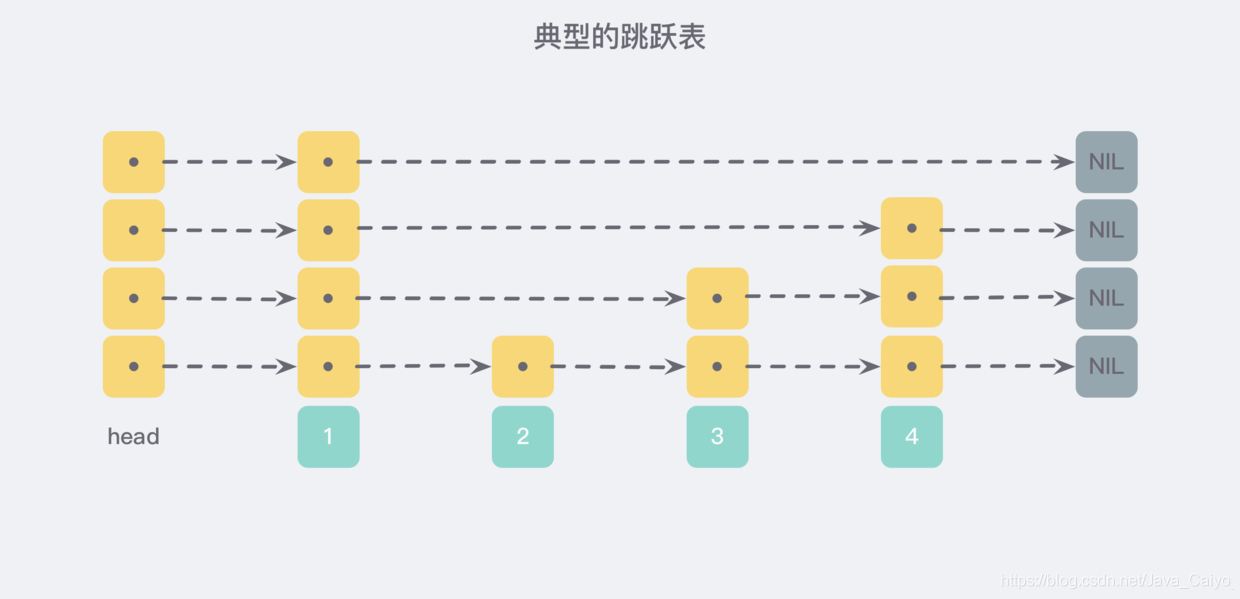
跳躍表(skiplist)是一種隨機化的資料結構,由 William Pugh 在論文《Skip lists: a probabilistic alternative to balanced trees》中提出,是一種可以于平衡樹媲美的層次化鏈表結構——查找、洗掉、添加等操作都可以在對數期望時間下完成,以下是一個典型的跳躍表例子:
小插曲:
更多阿里、騰訊、美團、京東等一線互聯網大廠Java面試真題;包含:基礎、并發、鎖、JVM、設計模式、資料結構、反射/IO、資料庫、Redis、Spring、訊息佇列、分布式、Zookeeper、Dubbo、Mybatis、Maven、面經等,
更多Java程式員技術進階小技巧;例如高效學習(如何學習和閱讀代碼、面對枯燥和量大的知識)高效溝通(溝通方式及技巧、溝通技術)
更多Java大牛分享的一些職業生涯分享檔案
請點擊這里添加》》》》》》》》》社群,免費獲取
比你優秀的對手在學習,你的仇人在磨刀,你的閨蜜在減肥,隔壁老王在練腰, 我們必須不斷學習,否則我們將被學習者超越!
趁年輕,使勁拼,給未來的自己一個交代!
我們在上一篇中提到了 Redis 的五種基本結構中,有一個叫做 有序串列 zset 的資料結構,它類似于Java中的 SortedSet 和 HashMap 的結合體,一方面它是一個 set 保證了內部 value 的唯一性,另一方面又可以給每個 value 賦予一個排序的權重值 score,來達到 排序 的目的,
它的內部實作就依賴了一種叫做**「跳躍串列」**的資料結構,
1)為什么使用跳躍表
首先,因為 zset 要支持隨機的插入和洗掉,所以它 不宜使用陣列來實作,關于排序問題,我們也很容易就想到 紅黑樹/ 平衡樹 這樣的樹形結構,為什么 Redis 不使用這樣一些結構呢?
- 性能考慮: 在高并發的情況下,樹形結構需要執行一些類似于 rebalance 這樣的可能涉及整棵樹的操作,相對來說跳躍表的變化只涉及區域 (下面詳細說);
- 實作考慮: 在復雜度與紅黑樹相同的情況下,跳躍表實作起來更簡單,看起來也更加直觀;
基于以上的一些考慮,Redis 基于 William Pugh 的論文做出一些改進后采用了 跳躍表 這樣的結構,
2)本質是解決查找問題
我們先來看一個普通的鏈表結構:
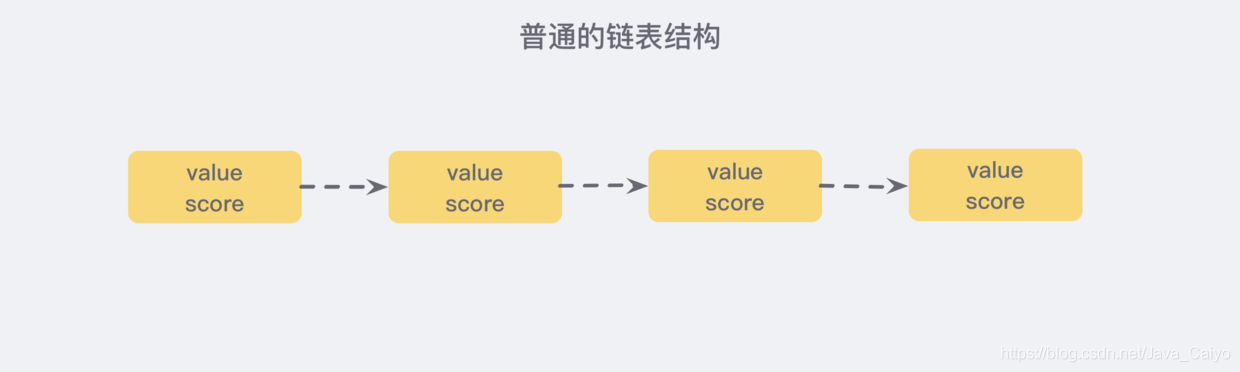
我們需要這個鏈表按照 score 值進行排序,這也就意味著,當我們需要添加新的元素時,我們需要定位到插入點,這樣才可以繼續保證鏈表是有序的,通常我們會使用 二分查找法,但二分查找是有序陣列的,鏈表沒辦法進行位置定位,我們除了遍歷整個找到第一個比給定資料大的節點為止 (時間復雜度O(n)) 似乎沒有更好的辦法,
但假如我們每相鄰兩個節點之間就增加一個指標,讓指標指向下一個節點,如下圖:
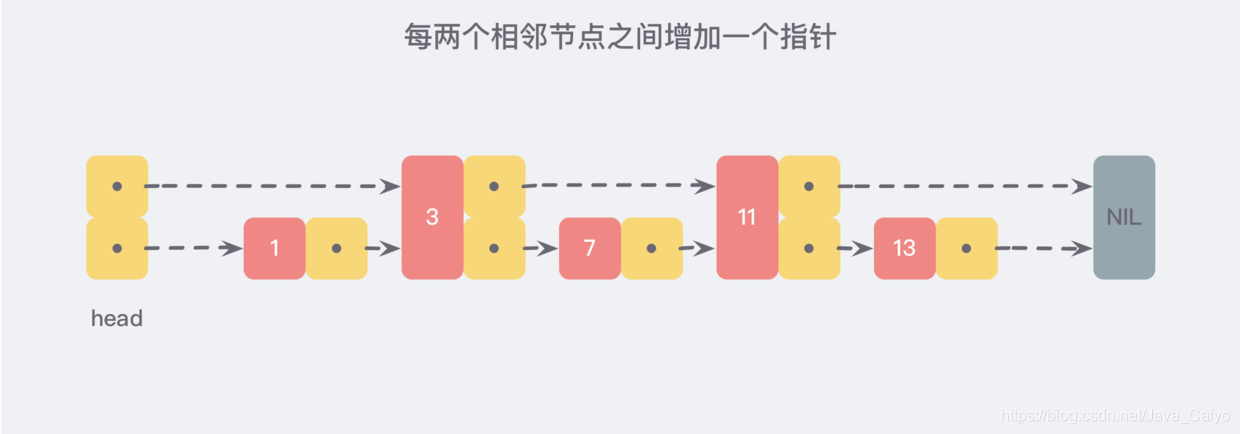
這樣所有新增的指標連成了一個新的鏈表,但它包含的資料卻只有原來的一半 (圖中的為 3,11),
現在假設我們想要查找資料時,可以根據這條新的鏈表查找,如果碰到比待查找資料大的節點時,再回到原來的鏈表中進行查找,比如,我們想要查找 7,查找的路徑則是沿著下圖中標注出的紅色指標所指向的方向進行的:
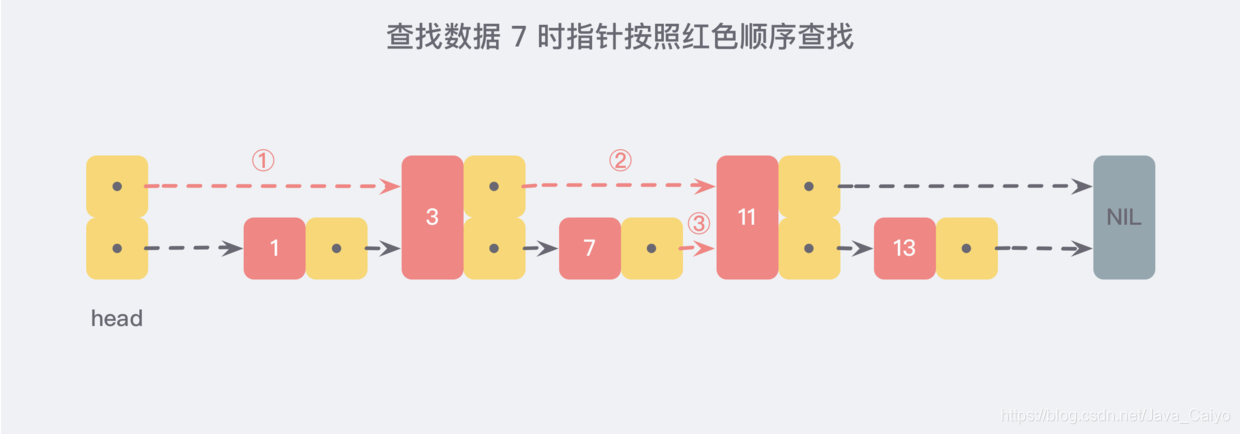
這是一個略微極端的例子,但我們仍然可以看到,通過新增加的指標查找,我們不再需要與鏈表上的每一個節點逐一進行比較,這樣改進之后需要比較的節點數大概只有原來的一半,
利用同樣的方式,我們可以在新產生的鏈表上,繼續為每兩個相鄰的節點增加一個指標,從而產生第三層鏈表:
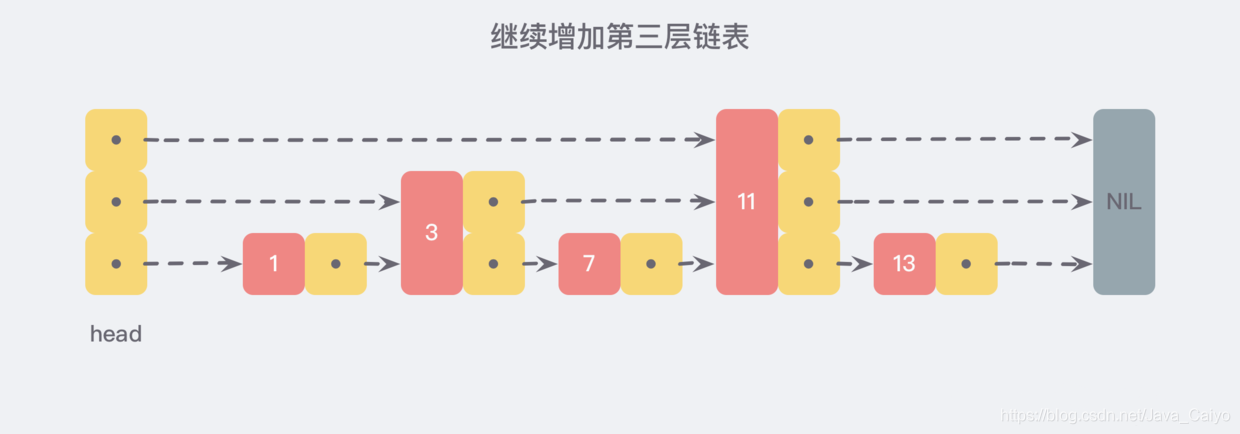
在這個新的三層鏈表結構中,我們試著 查找 13,那么沿著最上層鏈表首先比較的是 11,發現 11 比 13小,于是我們就知道只需要到 11 后面繼續查找,從而一下子跳過了 11 前面的所有節點,
可以想象,當鏈表足夠長,這樣的多層鏈表結構可以幫助我們跳過很多下層節點,從而加快查找的效率,
3)更進一步的跳躍表
跳躍表 skiplist 就是受到這種多層鏈表結構的啟發而設計出來的,按照上面生成鏈表的方式,上面每一層鏈表的節點個數,是下面一層的節點個數的一半,這樣查找程序就非常類似于一個二分查找,使得查找的時間復雜度可以降低到 O(logn),
但是,這種方法在插入資料的時候有很大的問題,新插入一個節點之后,就會打亂上下相鄰兩層鏈表上節點個數嚴格的 2:1 的對應關系,如果要維持這種對應關系,就必須把新插入的節點后面的所有節點(也包括新插入的節點) 重新進行調整,這會讓時間復雜度重新蛻化成 O(n),洗掉資料也有同樣的問題,
skiplist 為了避免這一問題,它不要求上下相鄰兩層鏈表之間的節點個數有嚴格的對應關系,而是 為每個節點隨機出一個層數(level),比如,一個節點隨機出的層數是 3,那么就把它鏈入到第 1 層到第 3 層這三層鏈表中,為了表達清楚,下圖展示了如何通過一步步的插入操作從而形成一個 skiplist 的程序:
小插曲:
更多阿里、騰訊、美團、京東等一線互聯網大廠Java面試真題;包含:基礎、并發、鎖、JVM、設計模式、資料結構、反射/IO、資料庫、Redis、Spring、訊息佇列、分布式、Zookeeper、Dubbo、Mybatis、Maven、面經等,
更多Java程式員技術進階小技巧;例如高效學習(如何學習和閱讀代碼、面對枯燥和量大的知識)高效溝通(溝通方式及技巧、溝通技術)
更多Java大牛分享的一些職業生涯分享檔案
請點擊這里添加》》》》》》》》》社群,免費獲取
比你優秀的對手在學習,你的仇人在磨刀,你的閨蜜在減肥,隔壁老王在練腰, 我們必須不斷學習,否則我們將被學習者超越!
趁年輕,使勁拼,給未來的自己一個交代!
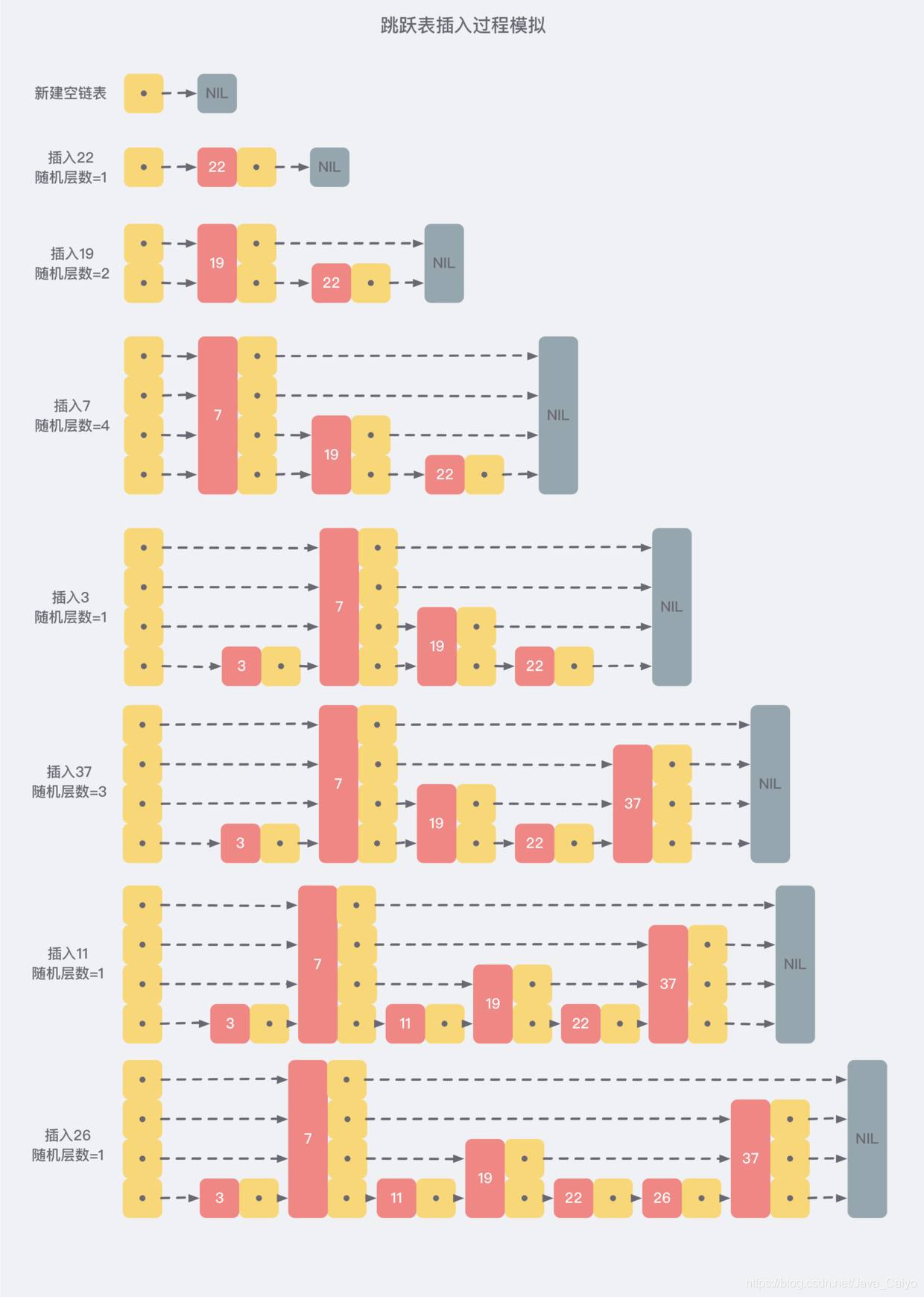
從上面的創建和插入的程序中可以看出,每一個節點的層數(level)是隨機出來的,而且新插入一個節點并不會影響到其他節點的層數,因此,插入操作只需要修改節點前后的指標,而不需要對多個節點都進行調整,這就降低了插入操作的復雜度,
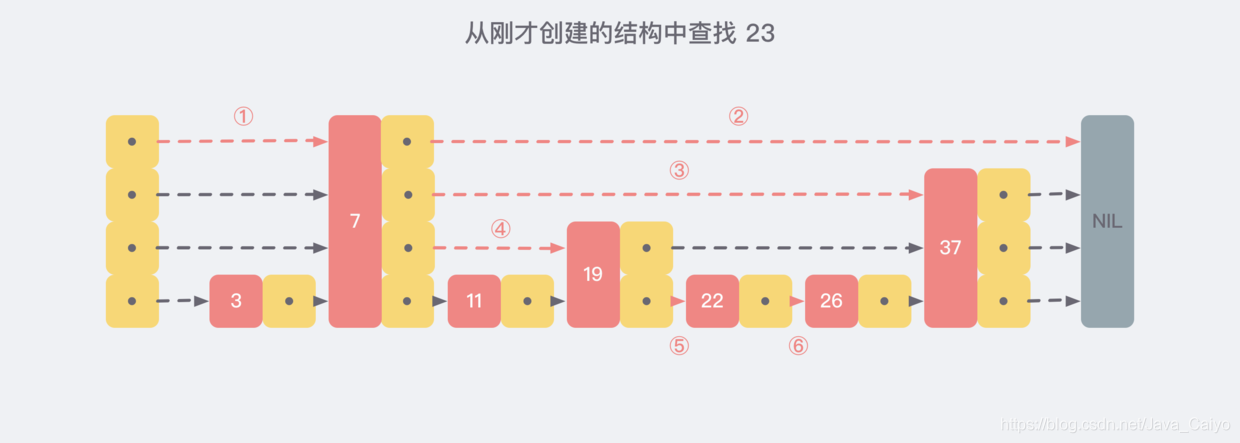
現在我們假設從我們剛才創建的這個結構中查找 23 這個不存在的數,那么查找路徑會如下圖:
2.跳躍表的實作
Redis 中的跳躍表由 server.h/zskiplistNode 和 server.h/zskiplist 兩個結構定義,前者為跳躍表節點,后者則保存了跳躍節點的相關資訊,同之前的 集合 list 結構類似,其實只有zskiplistNode 就可以實作了,但是引入后者是為了更加方便的操作:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
// value
sds ele;
// 分值
double score;
// 后退指標
struct zskiplistNode *backward;
// 層
struct zskiplistLevel {
// 前進指標
struct zskiplistNode *forward;
// 跨度
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
// 跳躍表頭指標
struct zskiplistNode *header, *tail;
// 表中節點的數量
unsigned long length;
// 表中層數最大的節點的層數
int level;
} zskiplist;
正如文章開頭畫出來的那張標準的跳躍表那樣,
1)隨機層數
對于每一個新插入的節點,都需要呼叫一個隨機演算法給它分配一個合理的層數,原始碼在t_zset.c/zslRandomLevel(void)中被定義:
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
直觀上期望的目標是 50% 的概率被分配到 Level 1 ,25% 的概率被分配到 Level 2 ,12.5% 的概率被分配到 Level 3,以此類推…有 2-63 的概率被分配到最頂層,因為這里每一層的晉升率都是 50%,
Redis 跳躍表默認允許最大的層數是 32,被原始碼中ZSKIPLIST_MAXLEVEL定義,當 Level[0]有 264個元素時,才能達到 32 層,所以定義 32 完全夠用了,
2)創建跳躍表
這個程序比較簡單,在原始碼中的 t_zset.c/zslCreate 中被定義:
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 申請記憶體空間
zsl = zmalloc(sizeof(*zsl));
// 初始化層數為 1
zsl->level = 1;
// 初始化長度為 0
zsl->length = 0;
// 創建一個層數為 32,分數為 0,沒有 value 值的跳躍表頭節點
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 跳躍表頭節點初始化
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
// 將跳躍表頭節點的所有前進指標 forward 設定為 NULL
zsl->header->level[j].forward = NULL;
// 將跳躍表頭節點的所有跨度 span 設定為 0
zsl->header->level[j].span = 0;
}
// 跳躍表頭節點的后退指標 backward 置為 NULL
zsl->header->backward = NULL;
// 表頭指向跳躍表尾節點的指標置為 NULL
zsl->tail = NULL;
return zsl;
}
即執行完之后創建了如下結構的初始化跳躍表:
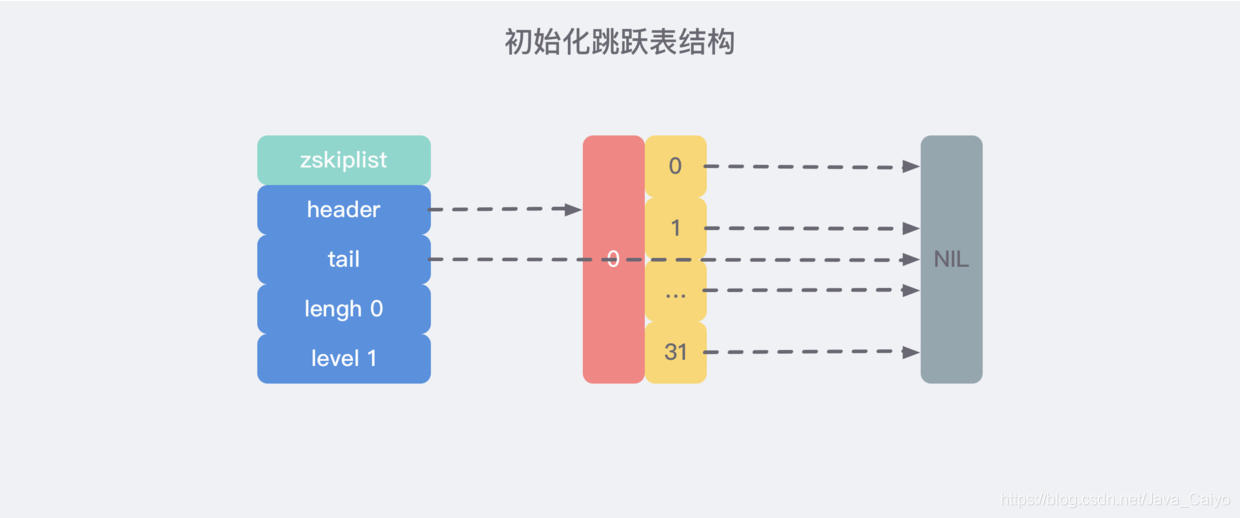
3)插入節點實作
這幾乎是最重要的一段代碼了,但總體思路也比較清晰簡單,如果理解了上面所說的跳躍表的原理,那么很容易理清楚插入節點時發生的幾個動作 (幾乎跟鏈表類似):
- 找到當前我需要插入的位置 (其中包括相同 score 時的處理);
- 創建新節點,調整前后的指標指向,完成插入;
為了方便閱讀,我把原始碼 t_zset.c/zslInsert 定義的插入函式拆成了幾個部分
第一部分:宣告需要存盤的變數
// 存盤搜索路徑
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
// 存盤經過的節點跨度
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
第二部分:搜索當前節點插入位置
serverAssert(!isnan(score));
x = zsl->header;
// 逐步降級尋找目標節點,得到 "搜索路徑"
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
// 如果 score 相等,還需要比較 value 值
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
// 記錄 "搜索路徑"
update[i] = x;
}
討論: 有一種極端的情況,就是跳躍表中的所有 score 值都是一樣,zset 的查找性能會不會退化為O(n) 呢?
從上面的原始碼中我們可以發現 zset 的排序元素不只是看 score 值,也會比較 value 值 (字串比較)
第三部分:生成插入節點
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
// 如果隨機生成的 level 超過了當前最大 level 需要更新跳躍表的資訊
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
// 創建新節點
x = zslCreateNode(level,score,ele);
第四部分:重排前向指標
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
第五部分:重排后向指標并回傳
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
4)節點洗掉實作
洗掉程序由原始碼中的t_zset.c/zslDeleteNode定義,和插入程序類似,都需要先把這個 "搜索路徑"找出來,然后對于每個層的相關節點重排一下前向后向指標,同時還要注意更新一下最高層數maxLevel,直接放原始碼 (如果理解了插入這里還是很容易理解的):
/* Internal function used by zslDelete, zslDeleteByScore and zslDeleteByRank */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL) zsl->level--;
zsl->length--;
}
/* Delete an element with matching score/element from the skiplist.
* The function returns 1 if the node was found and deleted, otherwise
* 0 is returned.
*
* If 'node' is NULL the deleted node is freed by zslFreeNode(), otherwise
* it is not freed (but just unlinked) and *node is set to the node pointer,
* so that it is possible for the caller to reuse the node (including the
* referenced SDS string at node->ele). */
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
5)節點更新實作
當我們呼叫 ZADD 方法時,如果對應的 value 不存在,那就是插入程序,如果這個 value 已經存在,只是調整一下 score 的值,那就需要走一個更新流程,
假設這個新的 score 值并不會帶來排序上的變化,那么就不需要調整位置,直接修改元素的 score 值就可以了,但是如果排序位置改變了,那就需要調整位置,該如何調整呢?
從原始碼 t_zset.c/zsetAdd 函式 1350行左右可以看到,Redis 采用了一個非常簡單的策略:
/* Remove and re-insert when score changed. */
if (score != curscore) {
zobj->ptr = zzlDelete(zobj->ptr,eptr);
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
*flags |= ZADD_UPDATED;
}
把這個元素洗掉再插入這個,需要經過兩次路徑搜索,從這一點上來看,Redis 的 ZADD 代碼似憾訓有進一步優化的空間,
6)元素排名的實作
跳躍表本身是有序的,Redis 在 skiplist 的 forward 指標上進行了優化,給每一個 forward 指標都增加了 span 屬性,用來 表示從前一個節點沿著當前層的 forward 指標跳到當前這個節點中間會跳過多少個節點,在上面的原始碼中我們也可以看到Redis在插入、洗掉操作時都會小心翼翼地更新span值的大小,
所以,沿著 “搜索路徑”,把所有經過節點的跨度 span 值進行累加就可以算出當前元素的最終 rank 值了:
/* Find the rank for an element by both score and key.
* Returns 0 when the element cannot be found, rank otherwise.
* Note that the rank is 1-based due to the span of zsl->header to the
* first element. */
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x;
unsigned long rank = 0;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) <= 0))) {
// span 累加
rank += x->level[i].span;
x = x->level[i].forward;
}
/* x might be equal to zsl->header, so test if obj is non-NULL */
if (x->ele && sdscmp(x->ele,ele) == 0) {
return rank;
}
}
return 0;
}
參考資料:《Java中高級核心知識全面決議》限量100份,有一些人已經通過我之前的文章獲取了哦!
名額有限先到先得!!!
有想要獲取這份學習資料的同學可以點擊這里免費獲取》》》》》》》
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/239205.html
標籤:其他
上一篇:Java中高級核心知識全面決議——Redis(分布式鎖【簡介、實作】、Redlock分布式鎖、HyperLoglog【簡介、原理、實作、使用】)2
下一篇:Java開發者必備常用工具