文章目錄
- 前言
- 1.NoSQL概述
- 2.NoSQL適用場景
- 3.NoSQL不適用場景
- 4.NoSQL有哪些?
- 5.Redis簡介
- 6.應用場景
- 7.Redis命令
- 8.Redis相關知識
- 9.Redis五大數型別
- 10.Redis事務
- 11.Redis的持久化
- 12.RDB
- 13.AOF
- 14.RDB 和 AOF 如何選擇?
- 15.Redis主從復制
- 16.集群模式
- 17.集群的Jedis開發
- 18.官方鏈接
- 總結
前言
本文分享本菜鳥的Redis學習筆記,稍微有點亂,
?Redis是一個開源的key-value存盤系統,資料都在記憶體中,支持持久化,支持存盤的value型別相對更多,包括string(字串)、list(鏈表)、set(集合)、zset(sorted set --有序集合)和hash(哈希型別),
本菜鳥QQ:599903582
一起學習,共同進步,
比心心 ~
提示:以下是本篇文章正文內容,下面案例可供參考
1.NoSQL概述
?NoSQL, 泛指非關系型資料庫,NoSQL 不依賴業務邏輯方式存盤,是以簡單的 key-value模式存盤,因此大大的增加了資料庫的擴展能力,不遵守SQL標準,不支持ACID,遠超于SQL的性能,
2.NoSQL適用場景
?對資料高并發的讀寫,
?海量資料的讀寫,
?對資料高擴展性的,
3.NoSQL不適用場景
?需要事務支持,
?基于SQL的結構化查詢存盤,處理復雜的關系,需要即席查詢,
注意:用不著SQL的和用了SQL也不行的情況下,考慮NoSQL,
4.NoSQL有哪些?
快取資料庫:
-
Memcached: 資料都在記憶體中,一般不支持持久化,簡單的k-v型別,一般作為快取資料庫輔助持久化資料庫;
-
Redis:資料都在記憶體中,支持持久化,只要做備份恢復,支持多種資料型別:list、set、hash、zset等,一般作為快取資料庫輔助持久化的資料庫;
檔案資料庫:
- MongoDB:資料在記憶體中,記憶體不足情況下把不常用的資料保存到硬碟,k-v型別,但是對于value提供了豐富的查詢功能,可以根據資料的特點替代RDBMS,成為獨立的資料庫,或者配合RDBMS,存盤特定的資料,
列式資料庫:
- HBase:用于需要對大量的資料進行隨機、實時的讀寫操作的場景,目標就是處理資料量非常龐大的表,可以用普通的計算機處理超過10億行資料,還可以處理有數百列元素的資料表,
- Cssandra:海量資料集(數量級通常達到PB級別)
- Neo4j:主要應用:社會關系、公共交通網路、地圖及網路拓普等,類似于網狀結構,
5.Redis簡介
?Redis是一個開源的key-value存盤系統,
?支持存盤的value型別相對更多,包括string(字串)、list(鏈表)、set(集合)、zset(sorted set --有序集合)和hash(哈希型別),這些資料型別都支持push/pop、add/remove及取交集并集和差集及更豐富的操作,而且這些操作都是原子性的,在此基礎上,Redis支持各種不同方式的排序,與memcached一樣,為了保證效率,資料都是快取在記憶體中,區別的是Redis會周期性的把更新的資料寫入磁盤或者把修改操作寫入追加的記錄檔案,并且在此基礎上實作了master-slave(主從)同步,
6.應用場景
-
配合關系型資料庫做高速快取,
?高頻次,熱門訪問的資料,減低資料庫IO,
?分布式架構,做Session共享, -
由于其具有持久化能力,利用其多樣的資料結構存盤特定的資料,能夠實作相關的業務,
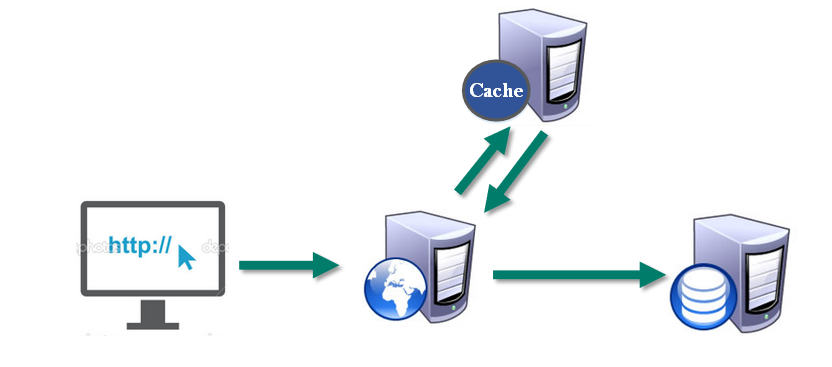
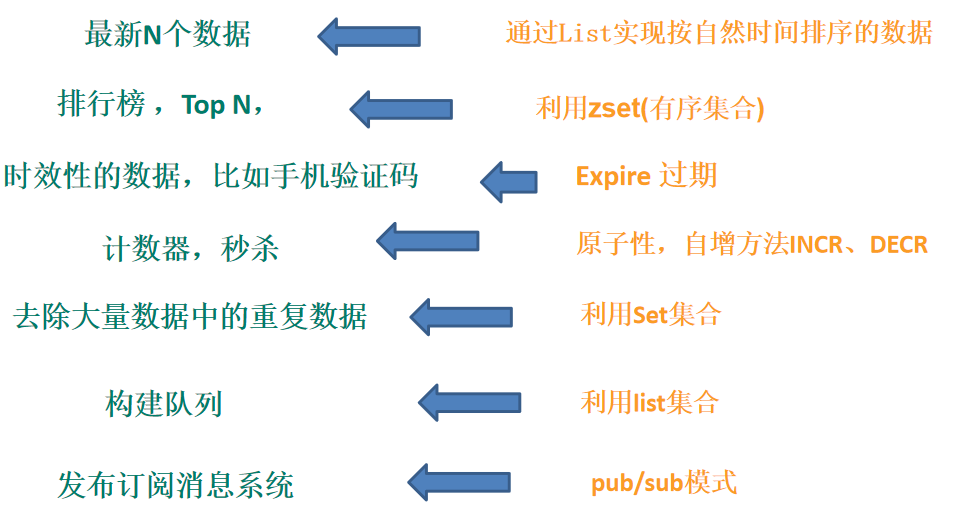
7.Redis命令
1.開啟服務:
bin/redis-server /root/myredis/redis.conf
2.客戶端訪問:
bin/redis-cli
bin/redis-cli -p 6379
3.測驗
redis-cli連接后,輸入 ping 輸出 pong
4.關閉
bin/redis-cli shutdonw 或 進入 redis-cli 然后 shutdown
5.多實體關閉
bin/redis-cli -p 6379 shutdown
8.Redis相關知識
埠6379
?默認16個資料庫,類似陣列下標從0開始,初始默認使用0號庫,使用命令 select 來切換資料庫,如: select 8
統一密碼管理,所有庫都是同樣密碼,要么都OK要么一個也連接不上,
Redis是單執行緒+多路IO復用技術
多路復用:
?多路復用是指使用一個執行緒來檢查多個檔案描述符(Socket)的就緒狀態,比如呼叫select和poll函式,傳入多個檔案描述符,如果有一個檔案描述符就緒,則回傳,否則阻塞直到超時,得到就緒狀態后進行真正的操作可以在同一個執行緒里執行,也可以啟動執行緒執行(比如使用執行緒池),
9.Redis五大數型別
key+ string
set
list
hash
zset
key
keys * : 查詢當前庫的所有鍵
exists <key> :判斷某個鍵是否存在
type <key> :判斷鍵對應的資料型別
del <key> :洗掉某個鍵
expire <key> <seconds> :為鍵值設計過期時間
ttl <key> : 查看還有躲閃秒過期, -1代表永不過期 , -2 代表已過期
dbsize :查看當前資料庫的key數量
flushdb : 清空資料庫
flushall:通殺所有資料庫
String:
get <key> : 查詢對應鍵值
set <key> <value>:添加鍵值對
append <key> <value> : 將給定的value追加到原值的末尾
strlen <key> :獲得值的長度
setnx <key> :只有在key不存在時設定key的值
incr <key> :將key中存盤的數字值增1,如果為空,新增值為1
decr <key> :將key中存盤的數字值減1,如果為空,新增值為-1
incrby / decrby <key> <步長> :自定義步長
mset <key1> <value1> <key2> <value2> : 同時設定一個或多個
mget <key1> <key2> <key3>:同時獲得多個
msetnx <key1> <value1> <key2> <value2>:key都不存在時
getrange <key> <起始位置><結束位置> :獲得值的范圍
setrange <key> <起始位置> <value> :從<開始位置>開始覆寫
setex <key> <過期時間><value>:設定鍵的同時,設定過期時間
getset <key> : 以舊換新,設定新值的同時獲取舊值
List:
lpush/rpush <key> <value1><value2><value3>:從左邊、右邊插入一個或多個值
lpop/rpop <key> : 從左邊或右邊吐出一個值,值亡鍵亡
rpoplpush<key1><key2>:從key1右邊吐出一個值,插到key2左邊
lrange<key><start><stop>:按照索引下標獲得元素(從左到右)
lindex<key><index>:根據索引下標獲取元素(從左到右)
llen <key> :獲取串列長度
linsert <key> before <value> <newvalue>:在value的前面插入newvalue
lrem <key> <n> <value>:從左邊洗掉n個value (從左到右)
Set:
sadd <key> <value1> <value2>:將一個或多個member元素加入到集合key中,已經存在的member元素被忽略
smember <key>:取出該集合的所有值
sismember <key> <value>:判斷集合是否存在value,有1,無0
scard <key>:回傳該集合的元素個數
srem <key> <value1> <calue2>:洗掉元素的某個元素
spop <key> <n>:隨機從集合中吐出一個或多個值
srandmember <key> <n>:隨機從集合中取出n個值,不洗掉
sinter <key1> <key2>:集合交集
sunion <key1> <key2>:集合并集
sdiff <key1> <key2>:集合差集
Hash:
hset <key> <field> <value>:給集合中的<field>賦值
hget <key> <field>:從集合中取出field
hmset <key> <field1> <value1> <f2><v2>:批量設定hash的值
hexists <key> <field>:查看哈希表key中,field是否存在
hkeys <key>:列出該集合中所有的field
hvals <key>:列出集合中的所有value
hincrby <key> <field> <increment>:給field值加上increament
hsetnx <key> <field> <value>:為field設值,當field不存在的時候
Zset:
zadd <key> <score1> <value1> <score2> <calue2>:將一個或多個member元素及其score值加入到有序集key中
zrange <key> <start> <stop> [withscores]:回傳有序集key中,下標在<start><stop>之間的元素,可以讓分數一起回傳
zrangebyscore <key> min max[withscores]:回傳有序集 key 中,所有 score 值介于 min 和 max 之間(包括等于 min 或 max )的成員,有序集成員按 score 值遞增(從小到大)次序排列,
zrevrangebyscore key max min [withscores]:從大到小
zincrby <key> <increment> <value> :為元素的score加上增量
zrem <key> <value>:洗掉該集合下,指定值的元素
zcount <key> <min> <max>:統計該集合,分數區間內的元素個數
zrank <key> <value> : 回傳該值在集合中的排名,從0開始
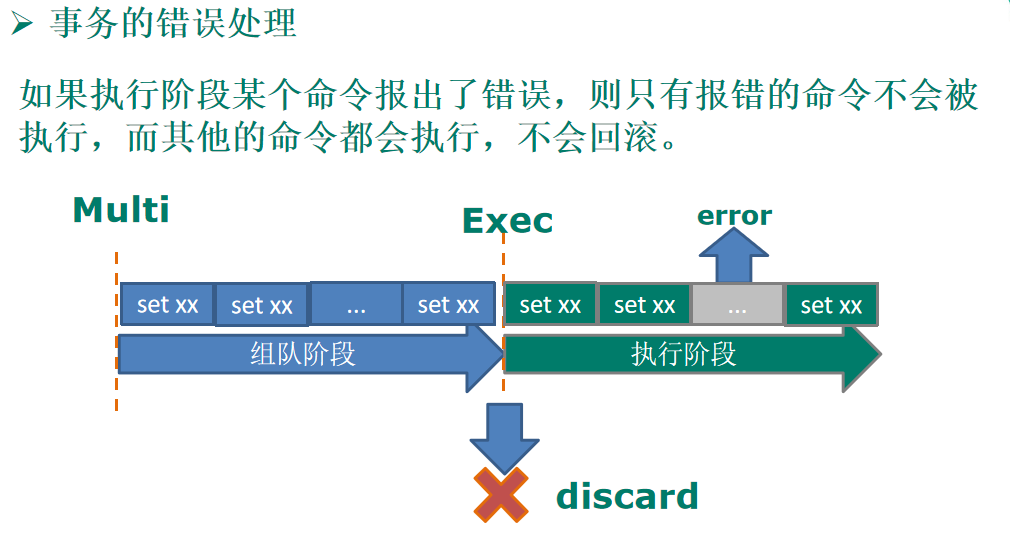
10.Redis事務
?Redis事務是一個單獨的隔離操作:
?事務中的所有命令都會序列化、按順序地執行,
?事務在執行的程序中,不會被其他客戶端發送來的命令請求所打斷,
Redis事務的主要作用就是串聯多個命令防止別的命令插隊,
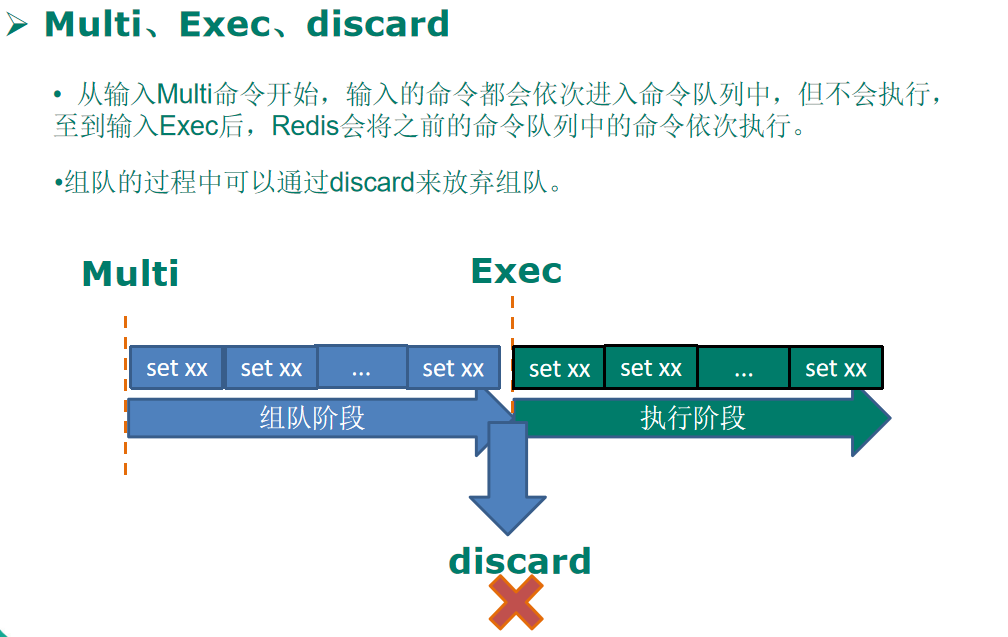
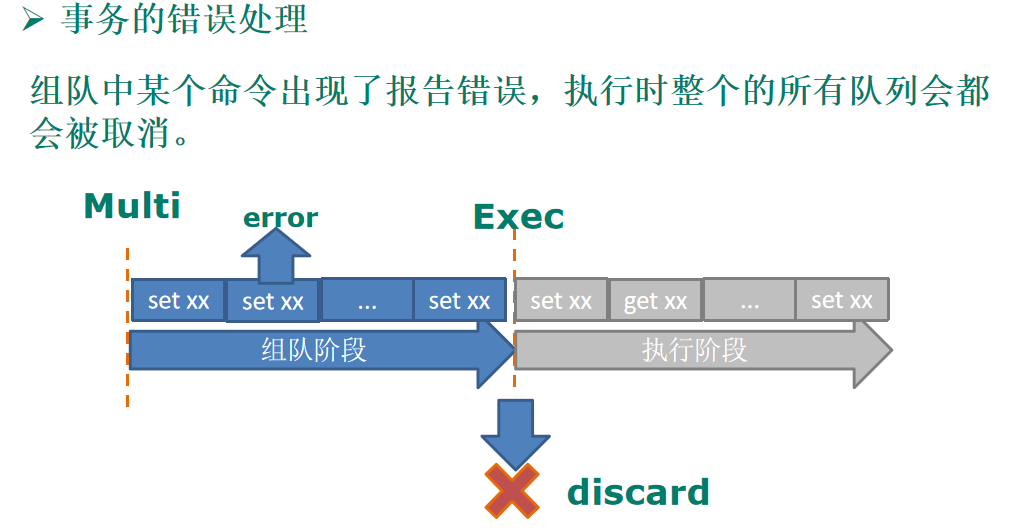




11.Redis的持久化
兩種持久化方式:
-
RDB:在指定的時間間隔內將記憶體中的資料集快照寫入磁盤,也就是行話講的Snapshot快照,它恢復時是將快照檔案直接讀到記憶體里,
-
AOF:以日志的形式來記錄每個寫操作,將Redis執行過的所有寫指令記錄下來(讀操作不記錄),只許追加檔案但不可以改寫檔案,Redis啟動之扯訓讀取該檔案重新構建資料,換言之,Redis重啟的話就根據日志檔案的內容將寫指令從前到后執行一次以完成資料的恢復作業,
12.RDB
RDB:在指定的時間間隔內將記憶體中的資料集快照寫入磁盤,也就是行話講的Snapshot快照,它恢復時是將快照檔案直接讀到記憶體里,
備份是如何執行的?
?Redis會單獨創建(fork)一個子行程來進行持久化,會先將資料寫入到一個臨時檔案中,待持久化程序都結束了,再用這個臨時檔案替換上次持久化好的檔案,整個程序中,主行程是不進行任何IO操作的,這就確保了極高的性能.如果需要進行大規模資料的恢復,且對于資料恢復的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效,
RDB的缺點是最后一次持久化后的資料可能丟失,
fork:
?在Linux程式中,fork()會產生一個和父行程完全相同的子行程,但子行程在此后多會exec系統呼叫,出于效率考慮,Linux中引入了“寫時復制技術”,一般情況父行程和子行程會共用同一段物理記憶體,只有行程空間的各段的內容要發生變化時,才會將父行程的內容復制一份給子行程.
在redis.conf中組態檔名稱,默認為dump.rdb
dbfilename dump.rdb
rdb檔案的保存路徑,也可以修改,默認為Redis啟動時命令列所在的目錄下
dir ./
stop-writes-on-bgsave-error yes
?當Redis無法寫入磁盤的話,直接關掉Redis的寫操作
rdbcompression yes
?進行rdb保存時,將檔案壓縮
rdbchecksum yes
? 在存盤快照后,還可以讓Redis使用CRC64演算法來進行資料校驗,但是這樣做會增加大約10%的性能消耗,如果希望獲取到最大的性能提升,可以關閉此功能.
rdb的備份
?先通過config get dir 查詢rdb檔案的目錄
?將*.rdb的檔案拷貝到別的地方
rdb的恢復
?關閉Redis
?先把備份的檔案拷貝到作業目錄下
?啟動Redis, 備份資料會直接加載
rdb的優點
?節省磁盤空間
?恢復速度快
rdb的缺點
?雖然Redis在fork時使用了寫時拷貝技術,但是如果資料龐大時還是比較消耗性能,在備份周期在一定間隔時間做一次備份,所以如果Redis意外down掉的話,就會丟失最后一次快照后的所有修改,

13.AOF
AOF:
?以日志的形式來記錄每個寫操作,將Redis執行過的所有寫指令記錄下來(讀操作不記錄)只許追加檔案但不可以改寫檔案,Redis啟動之扯訓讀取該檔案重新構建資料,換言之,Redis重啟的話就根據日志檔案的內容將寫指令從前到后執行一次以完成資料的恢復作業,
AOF默認不開啟,需要手動在組態檔中配置
appendonly no
可以在redis.conf中設定檔案名稱,默認為appendonly.aof
appendfilename "appendonly.aof"
AOF檔案的保存路徑和RDB的路徑一致,
AOF和RDB同時開啟,redis聽誰的?
?AOF和RDB同時開啟,系統默認取AOF的資料
AOF檔案故障備份
?AOF的備份機制和性能雖然和RDB不同, 但是備份和恢復的操作同RDB一樣,都是拷貝備份檔案,需要恢復時再拷貝到Redis作業目錄下,啟動系統即加載,
AOF檔案故障恢復
?AOF檔案的保存路徑,同RDB的路徑一致,
?如遇到AOF檔案損壞,可通過 redis-check-aof --fix appendonly.aof 進行恢復
Rewrite
?AOF采用檔案追加方式,檔案會越來越大為避免出現此種情況,新增了重寫機制,當AOF檔案的大小超過所設定的閾值時,Redis就會啟動AOF檔案的內容壓縮,只保留可以恢復資料的最小指令集.可以使用命令bgrewriteaof,
Redis如何實作重寫?
?AOF檔案持續增長而過大時,會fork出一條新行程來將檔案重寫(也是先寫臨時檔案最后再rename),遍歷新行程的記憶體中資料,每條記錄有一條的Set陳述句,重寫aof檔案的操作,并沒有讀取舊的aof檔案,而是將整個記憶體中的資料庫內容用命令的方式重寫了一個新的aof檔案,這點和快照有點類似,
AOF的優點
?備份機制更穩健,丟失資料概率更低,
?可讀的日志文本,通過操作AOF穩健,可以處理誤操作,
AOF的缺點
?比起RDB占用更多的磁盤空間
?恢復備份速度要慢,
?每次讀寫都同步的話,有一定的性能壓力,
?存在個別Bug,造成恢復不能.


14.RDB 和 AOF 如何選擇?
?官方推薦兩個都啟用,
?如果對資料不敏感,可以選單獨用RDB,
?不建議單獨用 AOF,因為可能會出現Bug,
?如果只是做純記憶體快取,可以都不用,
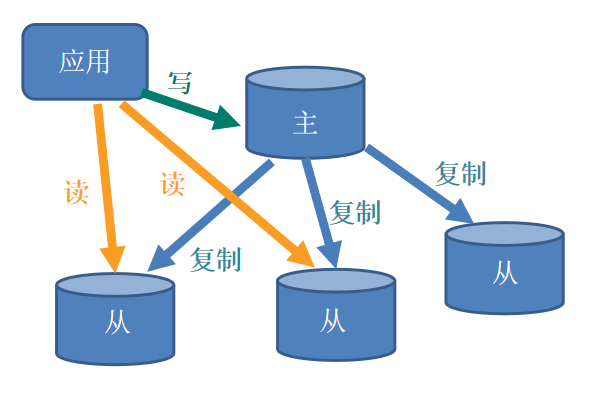
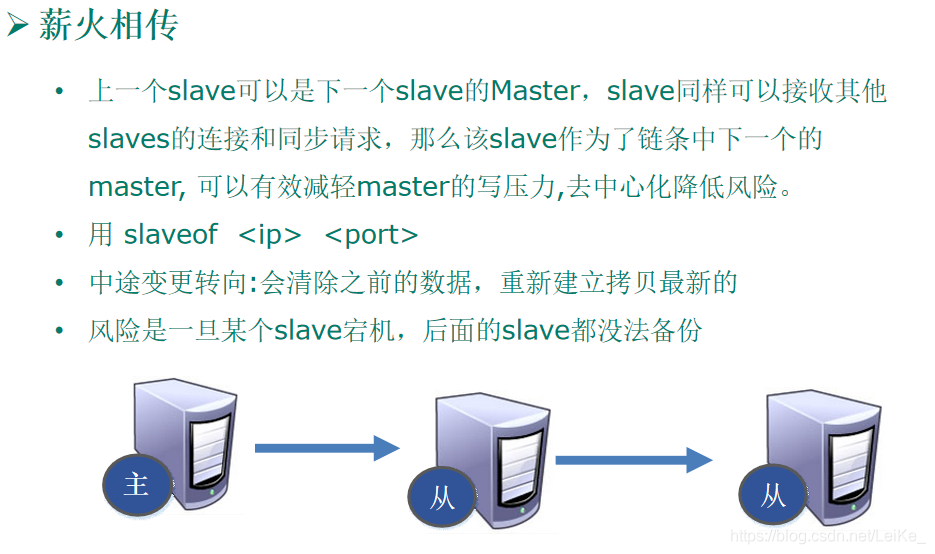
15.Redis主從復制
搭建教程:
主從復制,就是主機資料更新后根據配置和策略,自動同步到備機的master/slaver機制,Master以寫為主,Slave以讀為主,
用處:
?讀寫分離,性能擴展
?容災快速恢復

info replication : 列印主從復制的相關資訊
slaveof :成為某個實體的從服務器
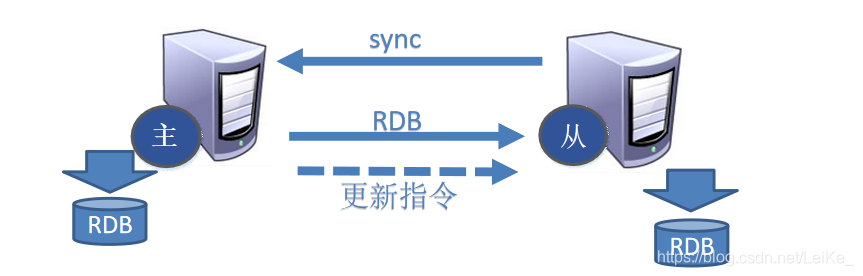
復制原理:
?每次從機聯通后,都會給主機發送sync指令,主機立刻進行存盤操作,發送RDB檔案,給從機,從機收到RDB檔案后,進行全盤加載,之后每次主機的寫操作,都會立刻發送給從機,從機執行相同的命令

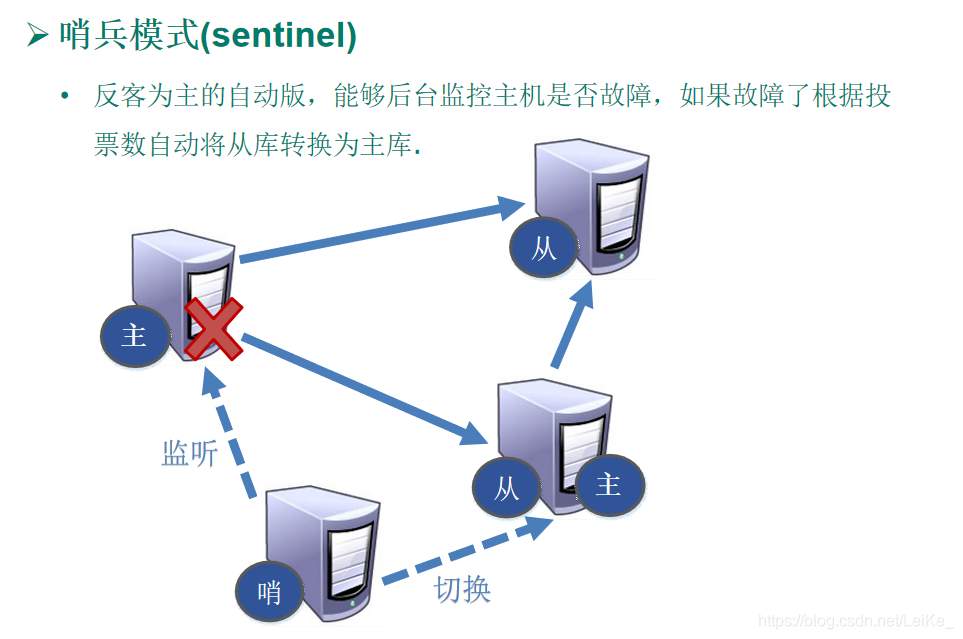
哨兵模式:
?redis目錄下新建sentinel.conf檔案
?在組態檔中填寫內容:
??sentinel monitor mymaster 127.0.0.1 6379 1
??其中mymaster為監控物件起的服務器名稱, 1 為 至少有多少個哨兵同意遷移的數量
啟動哨兵
?? redis-sentinel /myredis/sentinel.conf
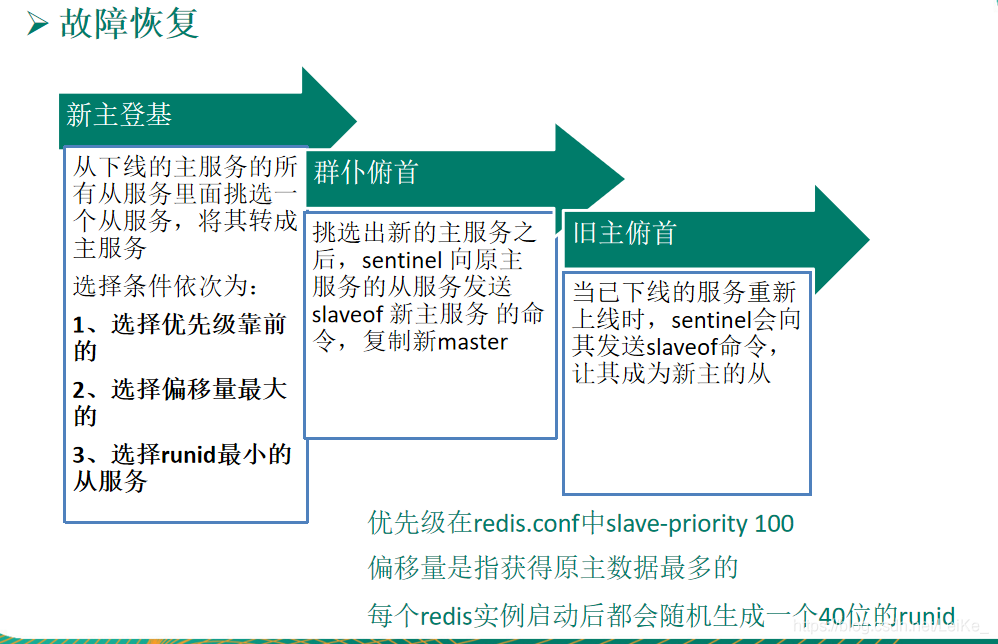
16.集群模式
搭建鏈接:
?Redis 集群實作了對Redis的水平擴容,即啟動N個redis節點,將整個資料庫分布存盤在這N個節點中,每個節點存盤總資料的1/N,
?Redis 集群通過磁區(partition)來提供一定程度的可用性(availability): 即使集群中有一部分節點失效或者無法進行通訊, 集群也可以繼續處理命令請求,
cluster nodes 查看集群訊息
?一個集群至少有三個主節點,加上三個從節點,一共需要六個節點,
分配原則盡量保證每個主資料庫運行在不同的IP地址,每個從庫和主庫不在一個IP地址上,
什么是slots:
? 一個 Redis 集群包含 16384 個插槽(hash slot), 資料庫中的每個鍵都屬于這 16384 個插槽的其中一個, 集群使用公式 CRC16(key) % 16384 來計算鍵 key 屬于哪個槽, 其中 CRC16(key) 陳述句用于計算鍵 key 的 CRC16 校驗和 ,集群中的每個節點負責處理一部分插槽,
?舉個例子, 如果一個集群可以有主節點, 其中:
??節點 A 負責處理 0 號至 5500 號插槽,
??節點 B 負責處理 5501 號至 11000 號插槽,
??節點 C 負責處理 11001 號至 16383 號插槽,
?在redis-cli每次錄入、查詢鍵值,redis都會計算出該key應該送往的插槽,如果不是該客戶端對應服務器的插槽,redis會報錯,并告知應前往的redis實體地址和埠,
redis-cli客戶端提供了 –c 引數實作自動重定向,如 redis-cli -c –p 6379 登入后,再錄入、查詢鍵值對可以自動重定向,
不在一個slot下的鍵值,是不能使用mget,mset等多鍵操作,
可以通過**{}來定義組的概念**,從而使key中{}內相同內容的鍵值對放到一個slot中去,
查詢集群中的值:
?CLUSTER KEYSLOT 計算鍵 key 應該被放置在哪個槽上,
?CLUSTER COUNTKEYSINSLOT 回傳槽 slot 目前包含的鍵值對數量,
?CLUSTER GETKEYSINSLOT 回傳 count 個 slot 槽中的鍵,
Redis 集群提供了以下好處:
?實作擴容
?分攤壓力
?無中心配置相對簡單
Redis 集群的不足:
?多鍵操作是不被支持的
?多鍵的Redis事務是不被支持的,lua腳本不被支持,
?由于集群方案出現較晚,很多公司已經采用了其他的集群方案,而代理或者客戶端分片的方案想要遷移至redis cluster,
?需要整體遷移而不是逐步過渡,復雜度較大,
17.集群的Jedis開發
public class JedisClusterTest {
public static void main(String[] args) {
Set<HostAndPort> set =new HashSet<HostAndPort>();
set.add(new HostAndPort("192.168.1.100",6379));
JedisCluster jedisCluster=new JedisCluster(set);
jedisCluster.set("k1", "v1");
System.out.println(jedisCluster.get("k1"));
}
}
18.官方鏈接
https://www.redis.net.cn/
總結
本文分享了本菜鳥的Redis學習筆記,稍微有點亂,但是還能看,
本菜鳥QQ:599903582
笨鳥先飛,熟能生巧,
比心心 ~
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/239657.html
標籤:其他
上一篇:springcloud集成seata,nacos,sharding-jdbc,mybatis-plus,sentinel,gateway實踐
下一篇:OpenStack 系列文章