簡介
Hadoop分布式檔案系統(HDFS)是一種旨在在商品硬體上運行的分布式檔案系統,它與現有的分布式檔案系統有許多相似之處,但是,與其他分布式檔案系統的區別很明顯,HDFS具有高度的容錯能力,旨在部署在低成本硬體上,HDFS提供對應用程式資料的高吞吐量訪問,并且適用于具有大資料集的應用程式,HDFS放寬了一些POSIX要求,以實作對檔案系統資料的流式訪問,HDFS最初是作為Apache Nutch Web搜索引擎專案的基礎結構而構建的,HDFS是Apache Hadoop Core專案的一部分,
優點
-
高容錯性:資料自動保存多個副本,它通過增加副本的形式,提高容錯性,某一個副本丟失以后,它可以自動恢復,這是由 HDFS 內部機制實作的,我們不必關心,
-
適合批處理:它是通過移動計算而不是移動資料, 它會把資料位置暴露給計算框架,
-
適合大資料處理: 能夠處理資料規模達到 GB、TB、甚至PB級別的資料,能夠處理百萬規模以上的檔案數量,數量相當之大,
-
可構建在廉價機器上,通過多副本機制,提高可靠性,
缺點
-
不適合低延時資料訪問:比如毫秒級的來存盤資料,這是不行的,它做不到,適合高吞吐率的場景,就是在某一時間內寫入大量的資料,但是它在低延時的情況 下是不行的,比如毫秒級以內讀取資料,這樣它是很難做到的,
-
無法高效的對大量小檔案進行存盤:存盤大量小檔案的話,它會占用 NameNode大量的記憶體來存盤檔案、目錄和塊資訊,這樣是不可取的,因為NameNode的記憶體總是有限的,小檔案存盤的尋道時間會超過讀取時間,它違反了HDFS的設計目標,
-
不支持并發寫入、檔案隨機修改:一個檔案只能有一個寫,不允許多個執行緒同時寫,僅支持資料 append(追加),不支持檔案的隨機修改,
組成架構
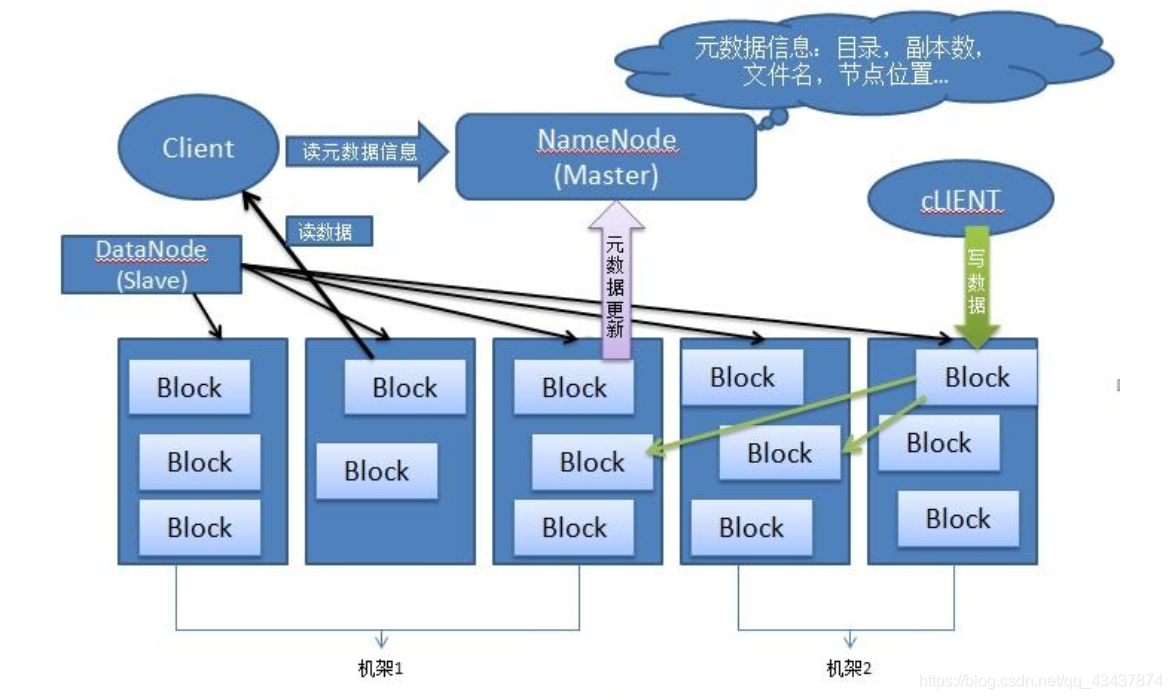
- NameNode:就是Master,它是一個管理者,管理HDFS的名稱空間;配置副本策略;管理資料塊(Block)映射資訊;處理客戶端讀寫請求,
- Secondary NameNode:并非NameNode的熱備,當NameNode掛掉的時候,它并不能馬上替換NameNode并提供服務,輔助NameNode,分擔其作業量,比如定期合并Fsimage和Edits,并推送給NameNode ;在緊急情況下,可輔助恢復NameNode,
- DataNode:就是Slave,NameNode下達命令,DataNode執行實際的操作,存盤實際的資料塊;執行資料塊的讀/寫操作,
- Client:(客戶端)代表用戶通過與nameNode和datanode互動來訪問整個檔案系統,HDFS對外開放檔案命名空間并允許用戶資料以檔案形式存盤,用戶通過客戶端(Client)與HDFS進行通訊互動,檔案上傳HDFS的時候,Client將檔案切分成一個一個的Block,然后進行上傳;與NameNode互動,獲取檔案的位置資訊;與DataNode互動,讀取或者寫入資料;Client提供一些命令來管理HDFS,比如NameNode格式化;Client可以通過一些命令來訪問HDFS,比如對HDFS增刪查改操作;
檔案塊
與一般檔案系統一樣,HDFS也有塊(block)的概念,HDFS上的檔案也被劃分為塊大小的多個分塊作為獨立的存盤單元,在組態檔hdfs-default.xml中,默認配置為134217728K,Hadoop2.x版本中是128M,老版本中是64M,
HDFS檔案塊的大小不能設定太大,也不能設定太小,尋址時間若為10ms,即查找到目標block的時間為10ms,尋址時間為傳輸時間的1%時,為最佳狀態,那么傳輸時間=10ms/1%=1000ms=1s,目前市面上磁盤普通傳輸速率100MB/s,那block設定為128MB,
常用命令
/opt/soft/hadoop-2.9.2/bin
# 語法
Usage: hdfs dfs -appendToFile <localsrc> ... <dst>
# 查看某個命令幫助
hadoop fs -help put
# 1. HDFS上查看目錄
hdfs dfs -ls /
# 2. HDFS上創建目錄
hdfs dfs -mkdir -p /data/mysql
# 3. 從本地移動到HDFS
hdfs dfs -moveFromLocal ./aaa.txt /data/mysql
# 4. 追加一個檔案到已經存在的檔案末尾
echo "zhangsan" > bbb.txt
hdfs dfs -appendToFile ./bbb.txt /data/mysql/aaa.txt
# 5. 顯示檔案內容
hdfs dfs -cat /data/mysql/aaa.txt
# 6. 修改檔案所屬權限(-chgrp 、-chmod、-chown)
hdfs dfs -chmod 777 /data/mysql/aaa.tx
# 7. 從本地檔案系統中拷貝檔案到HDFS
hdfs dfs -copyFromLocal ./bbb.txt /data/mysql
hdfs dfs -put a.txt /data
# 8. 從HDFS拷貝到本地
hdfs dfs -copyToLocal /data/mysql/aaa.txt ./
hdfs dfs -get /data/aaa.txt ./
# 9. 從HDFS的一個路徑拷貝到HDFS的另一個路徑
hdfs dfs -cp /data/mysql/aaa.txt /
# 10. 在HDFS目錄中移動檔案
hdfs dfs -mv /data/mysql/aaa.txt /data
# 11. 合并下載多個檔案
hdfs dfs -getmerge /include/* a.txt
# 12. 顯示一個檔案的末尾
hdfs dfs -tail /data/mysql/bbb.txt
# 13. 洗掉檔案或檔案夾
hdfs dfs -rm /data/mysql/bbb.txt
# 14. 洗掉空目錄
hdfs dfs -rmdir /data/mysql/
# 15. 統計檔案夾的大小資訊
hdfs dfs -du /data
# 16. 設定HDFS中檔案的副本數量,因為目前只有3臺設備,最多也就3個副本,只有節點數的增加到4臺時,副本數才能達到4
hdfs dfs -setrep 4 /data/
寫入資料流程
-
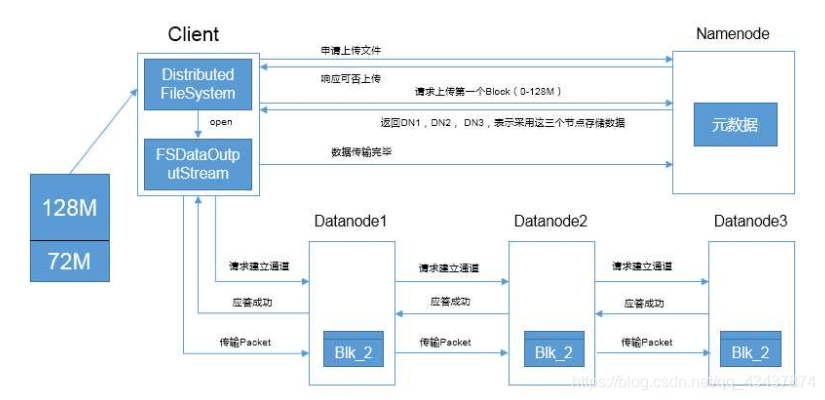
客戶端通過fs模塊向NameNode申請檔案上傳,NameNode檢查請求是否合法,如用戶權限,目標檔案是否已存在,父目錄是否存在等等
-
NameNode回傳是否可以上傳,如果是的話,建立連接通道
-
客戶端通過FSDataOutputStream模塊請求上傳block,NameNode根據網路拓撲距離計算回傳的節點,dn1,dn2,dn3
-
客戶端與dn1建立連接通道,dn1收到請求后會向dn2發起連接請求,dn2收到請求后會向dn3發起請求.請求通道全部打通后,會從后逐次向前應答,最后應答到客戶端,通道建立成功
-
客戶端開始上傳block,block以packet為單位進行傳輸,大小為64k,dn1接收到packet后,將packet放入buffer緩沖中,一邊往本地磁盤寫,一邊發送給dn2,dn2接收到后,以同樣的方式進行處理和傳輸給dn3,dn3也進行同樣的處理
-
等到block發送完畢后,本次傳輸結束
讀取資料流程
-
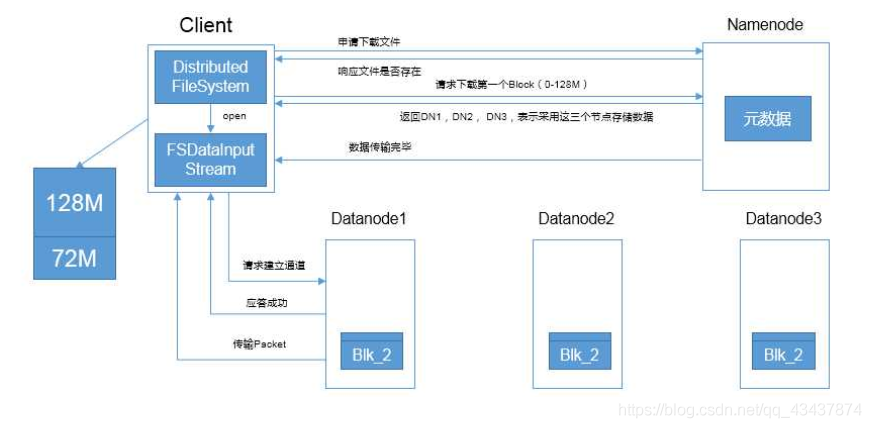
客戶端向NameNode申請檔案下載,NameNode檢查請求的合法性.如果請求合法,回傳可以下載的相應,建立連接通道
-
客戶端請求下載檔案,NameNode查詢元資料,回傳DataNode節點,DataNode節點以拓撲距離排序
-
客戶端請求連接第一個DataNode,應答成功后,DataNode開始以Packet傳輸資料.
-
客戶端接收Packet,邊接收邊寫入磁盤.
-
檔案傳輸完成,關閉連接.
網路拓撲-節點距離計算
在HDFS寫資料的程序中,NameNode會選擇距離待上傳資料最近距離的DataNode接收資料,
節點距離:兩個節點到達最近的路由器節點的距離總和
機架感知(副本存盤節點選擇)
為了最大程度地減少全域帶寬消耗和讀取延遲,HDFS嘗試滿足最接近讀取器的副本的讀取請求,如果在與讀取器節點相同的機架上存在一個副本,則首選該副本來滿足讀取請求,如果angg / HDFS群集跨越多個資料中心,則駐留在本地資料中心的副本優先于任何遠程副本,
NameNode和SecondaryNameNode
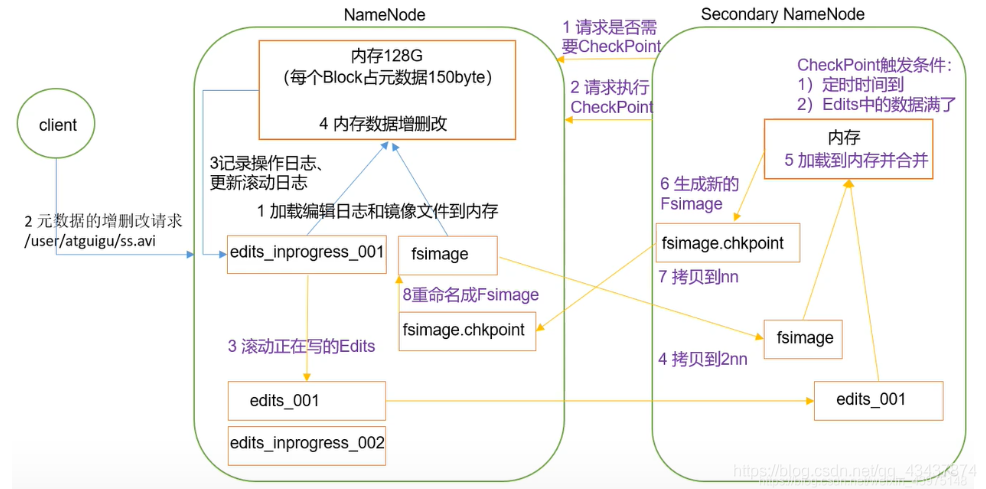
NameNode是如何存盤元資料:元資料存盤在fsiamge檔案(元資料的快照檔案)+edits(記錄所有寫操作的日志檔案)檔案中,SecondaryNamenode專門用于FsImage和Edits的合并,通常情況下,SecondaryNameNode每隔一小時執行一次CheckPoint,
NameNode作業機制:
集群安全模式
當啟動Namenode時,它不會立即開始向DataNode復制資料,NameNode首先自動進入稱為安全模式的特殊只讀操作狀態,在此模式下,NameNode不接受任何更改其命名空間的請求,因此,直到它離開安全模式之前,它避免復制甚至洗掉任何資料塊,
# 查看
bin/hdfs dfsadmin -safemode get
NameNode多目錄配置
NameNode的本地目錄可以配置成多個,且每個目錄存放內容相同,增加了可靠性,
# hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
DataNode
- DataNode作業機制:
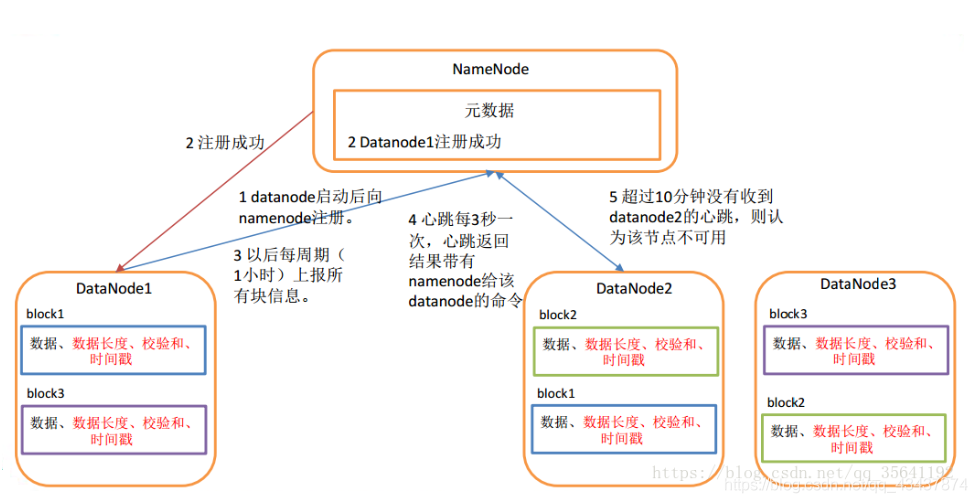
(1) 一個資料塊在 datanode 上以檔案形式存盤在磁盤上,包括兩個檔案,一個是資料本身,一個是元資料包括資料塊的長度,塊資料的校驗和,以及時間戳,
(2) DataNode 啟動后向 namenode 注冊, 通過后,周期性(1 小時) 的向 namenode 上報所有的塊資訊,
(3) 心跳是每 3 秒一次,心跳回傳結果帶有 namenode 給該 datanode 的命令如復制塊資料到另一臺機器,或洗掉某個資料塊, 如果超過 10 分鐘30秒沒有收到某個 datanode 的心跳,則認為該節點不可用,
(4) 集群運行中可以安全加入和退出一些機器, - 資料完整性:
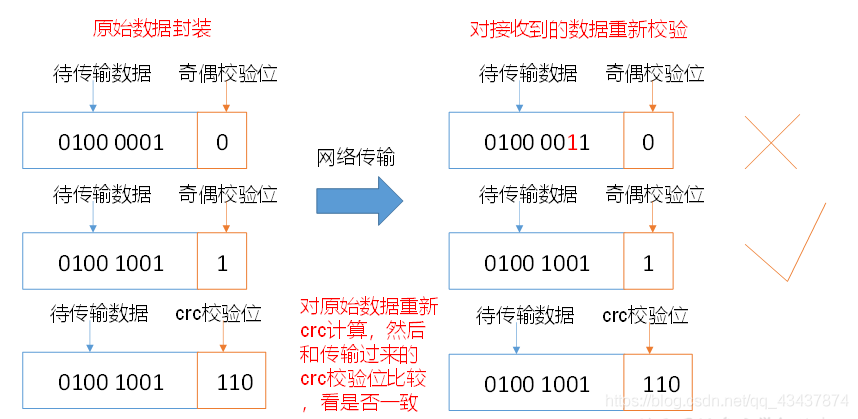
(1)當 DataNode 讀取 block 的時候,它會計算 checksum,
(2)如果計算后的 checksum,與 block 創建時值不一樣,說明 block 已經損壞,
(3)client 讀取其他 DataNode 上的 block,
(4)datanode 在其檔案創建后周期驗證 checksum, - 掉線時限引數設定
datanode 行程死亡或者網路故障造成 datanode 無法與 namenode 通信, namenode 不會立即把該節點判定為死亡,要經過一段時間,這段時間暫稱作超時時長, HDFS 默認的超時時長為 10 分鐘+30 秒,如果定義超時時間為 timeout,則超時時長的計算公式為:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval
而默認的 dfs.namenode.heartbeat.recheck-interval 大小為 5 分鐘,dfs.heartbeat.interval 默認為 3 秒,需要注意的是 hdfs-site.xml 組態檔中的 heartbeat.recheck.interval 的單位為毫秒,dfs.heartbeat.interval 的單位為秒,
HDFS 2.X新特性
- 采用distcp命令實作兩個Hadoop集群之間的遞回資料復制
- 小檔案存檔:HAR是一個更高效的檔案存檔工具,它將檔案存入HDFS塊,在減少NameNode記憶體使用的同時,允許對檔案進行透明的訪問,
- 回收站:開啟回收站功能,可以將洗掉的檔案在不超時的情況下,恢復原資料,起到防止誤洗掉、備份等作用,
- 快照管理:快照相當于對目錄做一個備份,并不會立即復制所有檔案,而是記錄檔案變化,
Hadoop 3.x 新特性
-
最低Java版本要求從Java7變為Java8
-
HDFS支持糾刪碼(erasure coding)
-
YARN時間線服務 v.2(YARN Timeline Service v.2)
-
重寫Shell腳本
-
覆寫客戶端的jar(Shaded client jars)
-
支持Opportunistic Containers和Distributed Scheduling
-
MapReduce任務級本地優化
-
支持多余2個以上的NameNodes
-
修改了多重服務的默認埠
-
提供檔案系統連接器(filesystem connnector),支持Microsoft Azure Data Lake和Aliyun物件存盤系統
-
資料節點內置平衡器(Intra-datanode balancer)
-
重寫了守護行程和任務的堆管理機制
-
HDFS的基于路由器互聯(HDFS Router-Based Federation)
-
基于API配置的Capacity Scheduler queue configuration
-
Yarn資源模型已經被一般化,可以支持用戶自定義的可計算資源型別,而不僅僅是CPU和記憶體,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/240044.html
標籤:其他