現狀資料說明:

需求背景介紹:
1. 該檔案功能是以 .csv 后綴的檔案進行決議后,反查我方資料庫表,取出賬單后做具體的處理業務
2. 該檔案功能主要分為以下幾個環節
- 獲取URL并下載檔案
- 檔案決議并檢查檔案資料的有效性及資料去重
- 取出檔案中的具體業務欄位進行查詢我方的庫表
- 根據查詢出來的賬單做具體的業務處理
3. 處理百萬量級以上資料時,整體效率偏低,理想情況的是處理百萬量級的資料控制在一個小時左右
注:該檔案處理功能是在單執行緒的情況下執行,暫時不需要考慮太消耗性能來開多執行緒的處理方案
流程耗時分析:
檔案去重后以資產號查詢我方賬單集合,整體是從 7ms ~ 22ms 不等;理論上來說檔案資料有多少條就會查詢多少次庫表
結論:通過核實代碼邏輯,該功能檔案的執行檔案耗時,均為在查詢DB這塊占用耗時較多
如:對到170W+的資料量,需要耗時2個半小時左右執行完,現檔案執行流程耗時也算相應合理,也存在要提高檔案處理性能的必要性
問題點:
現SQL的查詢邏輯等同于
select * from postloan_#xx#_db.t_asset_bill_#y# where Fstatus=1 and Fasset_id=xxxx
1. 這里是回傳的整個賬單集合;如 asset_id 對應的資料有12條賬單資料,則回傳了12條記錄的一個list物件
2. 重新評估業務后,這樣的SQL查詢是可以進一步優化
3. 全量欄位查詢是沒有必要的,影響磁盤IO的處理效率
注:該庫表為百庫十庫,庫表欄位數量超過一百個欄位
設計方案:
優化思路:
1. 從查詢整個賬單集合回傳 --> 查詢最大期賬單回傳
2. 全欄位賬單資料回傳 --> 精簡需要欄位的回傳
業務邏輯優化:
1. 獲取檔案中資產號,通過資產號入參,回傳提前結清的賬單的最大期數賬單物件
2. 提供該 getSimpleLastTermBillByAssetId 查詢方法,mapper 檔案的查詢SQL同步調整欄位精簡回傳
-- 根據資產號查詢提前結清最大期數的賬單(欄位精簡版本)
select
Fid,Floan_channel_id,Fasset_id,Fbill_id,Fcus_order_id,Finsure_mode_no,Frepay_term,Freal_repay_data,Freal_repay_type
from
postloan_#xx#_db.t_asset_bill_#y#
where
Fstatus=1 and Fasset_id=xxxx and Floan_term=Frepay_term and freal_repay_type = 30 and Fpostloan_repay_source_type in (0,20)3. 獲取到我方提前結清的賬單物件后(已做欄位精簡),對符合退保的賬單進行組裝MQ發出 (現有的處理邏輯中退保校驗條件減少)
注:這里是將代碼邏輯中的一部分校驗條件前置到SQL查詢中實作,減少業務代碼邏輯
效率提升效果:
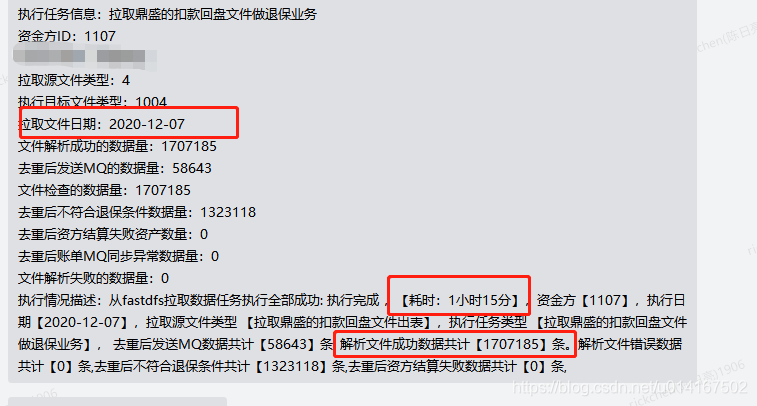
扣款回盤檔案退保性能提升需求(線上觀察)
a.整體檔案處理性能提升 100~110%
b.賬單查詢優化后由 7~22ms 下降到 2~6ms
優化總結:
1. 通常情況下程式中檔案處理效率低,都是在決議檔案的程序中有查詢DB的情況;若只是決議檔案做業務處理話,百萬量級的資料也就只是幾秒鐘程式就能跑完
2. 資料庫表查詢,若非必要,應當根據業務使用場景;第一優先選擇為需要欄位SQL查詢來提高查詢效率,減少磁盤IO與記憶體的消耗
參考資料:
MySQL:查詢欄位數量多少對查詢效率的影響 http://blog.itpub.net/7728585/viewspace-2668552/
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/240087.html
標籤:其他
上一篇:薪資被倒掛?是提升技術,還是另尋他路【建議大家收藏】
下一篇:2020 所思、所遇、所學、所悟