大家好!我是【AI 菌】,一枚愛彈吉他的程式員,我
熱愛AI、熱愛編程、熱愛分享! 這博客是我對學習的一點總結與思考,如果您也對深度學習、機器視覺、演算法、Python、C++感興趣,可以關注我的動態,我們一起學習,一起進步~
我的博客地址為:【AI 菌】的博客
我的Github專案地址是:【AI 菌】的Github

前言:這篇論文發表于機器學習國際頂級會議ICML2019,作者通過系統地研究發現,仔細平衡網路的深度、寬度和解析度可以帶來更好的性能,因此提出了一種新的縮放方法,即使用簡單而高效的復合系數來均勻縮放深度、寬度和解析度三個維度,從而使得模型效率大大提升,基于該項研究提出的EfficientNet-B7在ImageNet上達到了最先進的84.3%top-1精度,同時推理速度比最佳ConvNet還提高了6倍以上,
文章目錄
- 摘要
- 一、引言
- 二、相關研究
- 三、復合模型縮放
- 3.1 問題表述
- 3.2 縮放維度
- 3.3 復合縮放
- 四、高效網路架構
- 五、實驗
- 5.1 擴大MobileNets和ResNets
- 5.2 EfficientNet在ImageNet上的結果
- 5.3 EfficientNet遷移學習結果
- 六、討論
- 七、結論
Github開源地址: EfficientNets-TensorFlow
摘要
卷積神經網路(ConvNets)通常是在固定的資源預算下開發的,如果有更多資源可用,則可以通過擴大規模獲得更好的精度,在本文中,我們系統地研究了模型縮放,并確定仔細平衡網路的深度,寬度和解析度可以帶來更好的性能,基于此,我們提出了一種新的縮放方法,該方法使用簡單而高效的復合系數來均勻縮放深度/寬度/解析度三個維度,我們證明了該方法在MobileNets和ResNet上的有效性,
EfficientNets不會像傳統的方法那樣任意縮放網路的維度,而是采用基于神經結構搜索的技識訓得最優的一組引數(復合系數),該模型系列比以前的ConvNets具有更高的準確性和效率,特別地,EfficientNet-B7在ImageNet上達到了最先進的84.3%top-1精度,同時它的模型比現有的最佳ConvNet縮小了8.4倍,推理速度提高了6.1倍,
一、引言
擴大ConvNets的規模被廣泛使用以實作更高的準確性,例如,2016年何愷明通過使用跳層連接的思想將ResNet從ResNet-18擴展到ResNet-200,最近(2018年),GPipe通過擴大至四倍的基線模型在ImageNet上實作了84.3% top-1的精確度,
但是,對ConvNets擴展的程序從未得到很好的理解,目前有很多方法可以做到這一點,最常見的方法是按深度(何愷明,2016)或寬度(Zagoruyko等人,2016)擴大ConvNets的規模,另一種不常見但越來越流行的方法是通過影像解析度放大模型(Huang等人,2018),在以前的作業中,通常僅縮放三個維度之一(深度,寬度或影像大小),盡管可以任意縮放兩個或三個維度,但是任意縮放需要繁瑣的手動調整,并且仍然經常得不到最優的精度和效率,
在本文中,我們想研究和重新考慮擴展ConvNets的程序,特別地,我們調查了一個中心問題:是否存在一種原則上的方法來擴展ConvNets,以實作更高的準確性和效率? 我們的經驗研究表明,平衡網路寬度/深度/解析度的所有維度至關重要,而令人驚訝的是,可以通過簡單地以恒定比率縮放每個維度來實作這種平衡,基于此觀察,我們提出了一種簡單而有效的復合縮放方法,與傳統做法隨意縮放這些因素不同,我們的方法通過采用一組固定的縮放系數統一縮放網路寬度,深度和影像解析度,
例如,如果要使用2N倍的計算資源,則可以簡單地將網路深度增加αN,將寬度增加βN,將影像大小增加γN,其中α,β,γ是通過在原始的小模型上進行小網格搜索確定的常數系數,圖2說明了縮放方法與常規方法之間的區別,
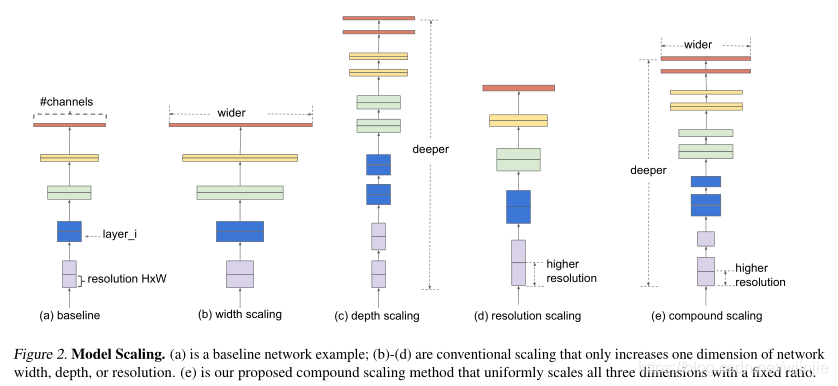
直觀上,復合縮放方法是有意義的,因為如果輸入影像更大,則網路需要更多的層來增大感受野,并且需要更多的通道來捕獲更大的影像上的更細粒度的圖案,實際上,先前的理論和經驗結果都表明網路寬度和深度之間存在一定關系,但據我們所知,我們率先通過經驗量化網路寬度,深度和解析度這三個維度之間的關系,
我們證明了我們的縮放方法可以在現有MobileNets和ResNet上能很好地作業,值得注意的是,模型擴展的有效性在很大程度上取決于基線網路,要走得更遠,我們使用神經體系結構搜索開發了新的基準網路,并將其擴展以獲得稱為EfficientNets的一系列模型,
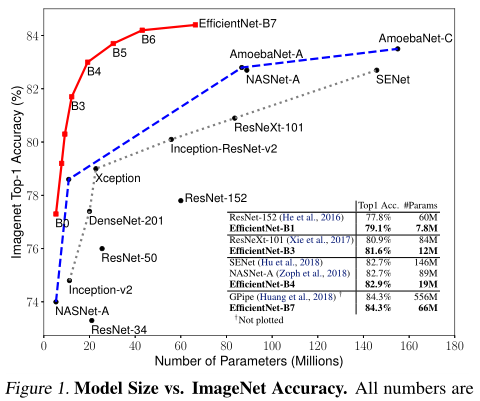
圖1展示了EfficientNets系列模型在ImageNet上的分類性能,其中EfficientNets明顯優于其他ConvNets,特別是,EfficientNet-B7超越了現有的最佳精度模型GPipe,但使用的引數減少了8.4倍,推理速度提高了6.1倍,與廣泛使用的ResNet-50相比,我們的EfficientNet-B4在FLOPS相似的情況下將top-1的準確性從76.3%提高到83.0%,
二、相關研究
ConvNet準確性:自從AlexNet贏得2012年ImageNet競賽以來,ConvNets變得越來越準確,模型越來越大,2014年ImageNet冠軍GoogleNet達到74.8%的top-1準確性,大約有6.8 M個引數,2017年ImageNet獲獎者SENet以1.45億個引數達到了82.7%的top-1精度,2018年,GPipe使用557M引數將最新的ImageNet top-1驗證準確性進一步提高到84.3%,盡管更高的精度對于許多應用至關重要,但是我們已經達到了硬體記憶體的極限,因此,進一步提高精度需要更高的效率,
ConvNet效率: 最近,神經體系結構搜索(Tan等人,2019; Cai等人,2019)在設計有效的輕量級ConvNets中變得越來越流行,并且通過廣泛地調整網路的寬度,深度來實作比手工設計的輕量級ConvNets更好的效率,但是,尚不清楚如何將這些技術應用于設計空間更大且調整成本更高的大型模型,在本文中,我們旨在研究超大型ConvNet的模型效率,該效率超過了SOTA準確性,為了實作此目標,我們訴諸模型縮放,
模型縮放:盡管先前的研究表明網路深度和寬度對于ConvNets的表達能力都很重要,但是如何有效擴展ConvNet以獲得更高的效率和準確性仍然是未解決的問題,我們的作業針對網路寬度,深度和解析度的所有三個維度系統地和經驗地研究了ConvNet縮放,
三、復合模型縮放
在本節中,我們將闡述縮放問題,研究不同的方法,并提出我們的新縮放方法,
3.1 問題表述
我們將整個卷積網路稱為 N,它的第 i 個卷積層可以表示為:

整個卷積網路由 k 個卷積層組成,可以表示為:
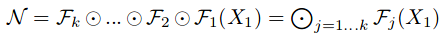
但是在實際中,通常會將多個結構相同的卷積層稱為一個 stage,例如 ResNet 有5 個 stage,每個 stage 中的卷積層結構相同(除了第一層為降采樣層),以 stage 為單位可以將卷積網路 N 表示為:
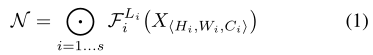
其中,
X
(
H
i
,
W
i
,
C
i
)
X_{(H_{i}, W_{i}, C_{i})}
X(Hi?,Wi?,Ci?)? 代表第i層的輸入張量的維度,下標 i (1…s) 表示的是 stage 的序號,
F
i
L
i
F_{i}^{L_{i}}
FiLi?? 表示第 i 個 stage ,它由卷積層
F
i
F_{i}
Fi? 重復
L
i
L_{i}
Li? 次構成,
與通常的ConvNet設計不同,通常的ConvNet設計主要關注尋找最佳的網路層 F i F_{i} Fi? ,模型縮放嘗試擴展網路長度 L i L_{i} Li?、 C i C_{i} Ci? 或解析度 H i , W i H_{i}, W_{i} Hi?,Wi?,而不改變基線網路中預定義的 F i F_{i} Fi?,
所以,優化目標就是在資源有限的情況下,要最大化精確度, 優化目標的公式表達如下:

其中w,d,r是縮放網路寬度,深度和解析度的系數;
L
i
^
\hat{L_{i}}
Li?^?、
C
i
^
\hat{C_{i}}
Ci?^?、
H
i
^
\hat{H_{i}}
Hi?^? 、
W
i
^
\hat{W_{i}}
Wi?^?、
F
i
^
\hat{F_{i}}
Fi?^?是基準網路中的預定義引數,
3.2 縮放維度
上述優化問題主要困難在于,最佳d,w,r相互依賴,并且值在不同的資源約束下會發生變化,由于這一困難,常規方法通常會在d,w,r維度之一中擴展ConvNets,
作者發現,具有較大寬度,深度或解析度的網路往往會實作較高的精度,但是精度增益在達到80%后會迅速飽和,這說明了只對單一維度進行擴張具有局限性,表1中描述了這種規律:
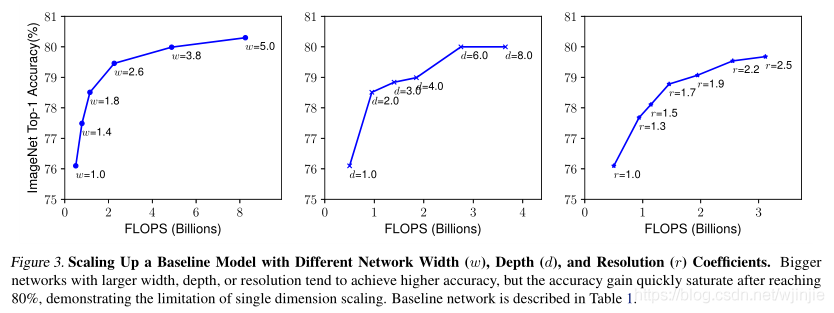
3.3 復合縮放
作者指出,模型擴張的各個維度之間并不是完全獨立的,比如說,對于更大的解析度影像,應該使用更深、更寬的網路,這就意味著需要平衡各個擴張維度,而不是在單一維度張擴張,
如下圖所示,直線上的每個點表示具有不同寬度系數(w)的模型,第一個baseline(d=1.0,r=1.0)有18個卷積層,解析度224x224,而最后一個baseline(d=2.0,r=1.3)有36個卷積層,解析度299x299,
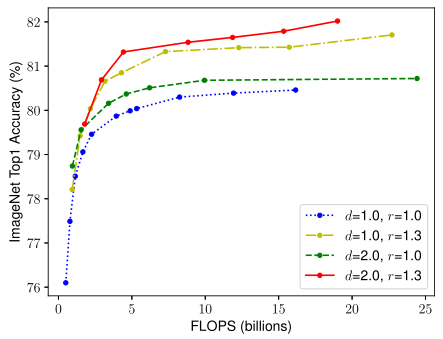
- 通過對比第一個baseline(藍色)和第二個baseline(黃色)可知,只增加輸入圖片的解析度?可提高準確度
- 通過對比第一個baseline(藍色)和第三個baseline(綠色)可知,只增加網路深度(d)可提高準確度
- 通過每個baseline橫向比較可知,只增加網路寬度(w)可提高準確度
- 通過橫向和縱向比較可知,當同時相應地調整r、d、w,才有可能得到最佳準確度,
因此,為了達到更好的精度和效率,在ConvNet縮放程序中平衡網路寬度、深度和解析度的所有維度是至關重要的,
因此,本文提出了一種新的復合擴張方法,這也是文章核心的地方,它使用復合系數φ原則上均勻地縮放網路的寬度,深度和解析度:
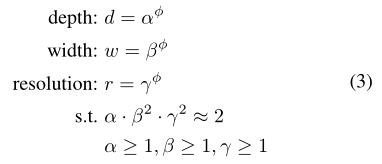
( α, β, γ )是我們需要求解的一組引數,如上圖公式,帶約束的最優引數求解,( α, β, γ ) 分別衡量著depth, width和 resolution的比重,其中 β、γ 在約束上會有平方,是因為如果增加寬度或解析度兩倍,其計算量是增加四倍;但是增加深度兩倍,其計算量只會增加兩倍,
最優引數求解方式:
- 固定公式中的φ=1,然后通過網格搜索(grid search)得出最優的α、β、γ,得出最基本的模型EfficientNet-B0,此時最佳值為:α= 1.2,β= 1.1,γ= 1.15,
- 固定α、β、γ的值,使用不同的φ,得到EfficientNet-B1, …, EfficientNet-B7
φ的大小對應著消耗資源的大小,相當于:
- 當φ=1時,得出了一個最小的最優基礎模型;
- 增大φ時,相當于對基模型三個維度同時擴展,模型變大,性能也會提升,資源消耗也變大,
四、高效網路架構
由于模型縮放不會改變基線網路中的層算符 F i ^ \hat{F_{i}} Fi?^?,因此擁有一個良好的基線網路也至關重要,我們將使用現有的ConvNets評估縮放方法,但是為了更好地展示縮放方法的有效性,我們還開發了一種新的mobile-size baseline,稱為EfficientNet,
其中,EfficientNet-B0的基準網路結構圖如下:
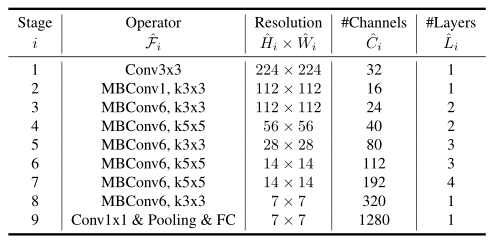
上表中每行代表著一個階段,一個階段存在著
L
i
^
\hat{L_{i}}
Li?^?個相同的網路層
F
i
^
\hat{F_{i}}
Fi?^?,每一個階段輸入的解析度為:
W
i
^
\hat{W_{i}}
Wi?^?,
H
i
^
\hat{H_{i}}
Hi?^?,輸出特征圖的通道數為:
C
i
^
\hat{C_{i}}
Ci?^?
五、實驗
在本節中,我們將首先在現有的ConvNet和新提出的EfficientNets上評估縮放方法,
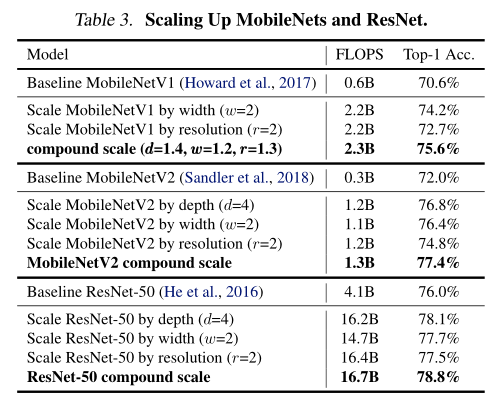
5.1 擴大MobileNets和ResNets
作為概念的證明,我們首先將縮放方法應用于廣泛使用的MobileNets和ResNet,表3顯示了在ImageNet資料集上以不同方式縮放三個維度(w, h, c)得到的結果,與只縮放一維的方法相比,我們的復合縮放方法提高了所有這些模型的準確性,這表明我們提出的縮放方法對于現有的一般ConvNets的有效性,
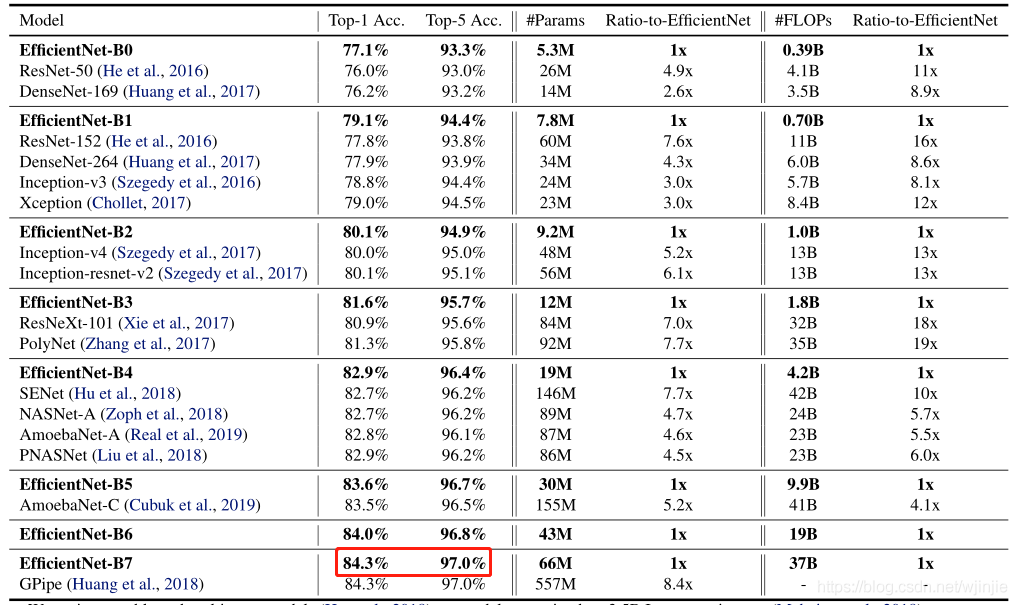
5.2 EfficientNet在ImageNet上的結果
通過對比EfficientNet、ResNet和DenseNet在ImageNet上的top-1和top-5精確度可以發現:經過擴展后的EfficientNet模型,在保持精確度不降低的情況下,引數和FLOPS都減少了一個數量級(其中,引數減少多達8.4倍,FLOPS減少多達16倍),
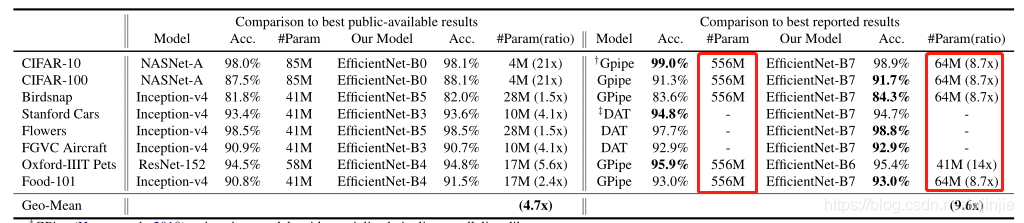
5.3 EfficientNet遷移學習結果
通過對比EfficientNet系列模型與當時的SOTA演算法在遷移學習資料集上的性能,可以看出:經過擴展后的EfficientNet模型在保證精確度的情況下,模型引數要少一個數量級,
六、討論
為了區分我們提出的縮放方法與EfficientNet體系結構的貢獻,下圖比較了采用不同縮放方法的EfficientNet-B0網路在ImageNet上的性能,
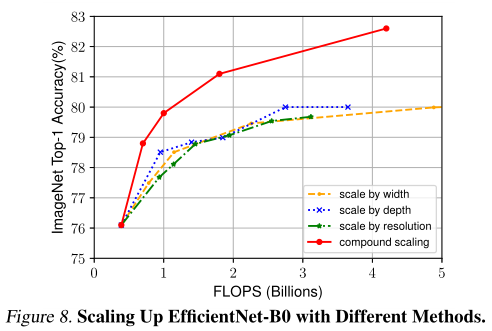
通常,所有擴展方法都以更高的FLOPS成本來提高精度,但是我們的復合縮放方法可以比其他只擴展一維的縮放方法進一步提高精度達2.5%,這表明我們建議的復合縮放的重要性,
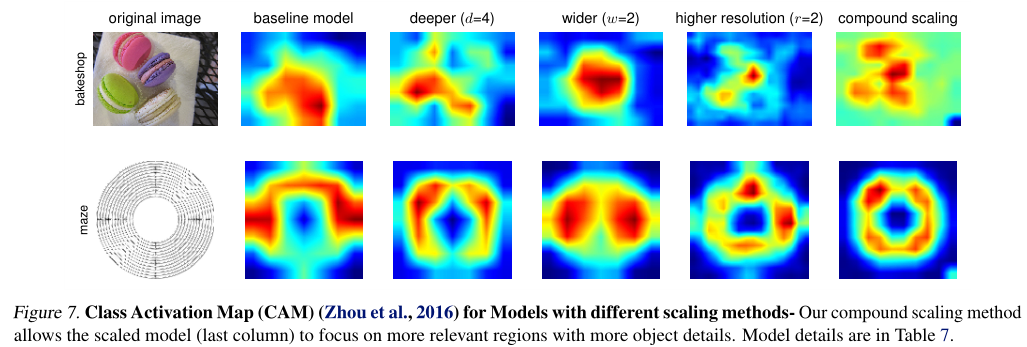
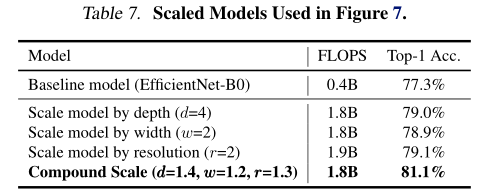
為了進一步理解為什么我們的復合縮放方法比其他方法更好,圖7比較了幾種具有不同縮放方法的代表性模型的類激活圖(Zhou等,2016),所有這些模型都是從同一基線縮放的,其統計資訊如表7所示,影像是從ImageNet驗證集中隨機選取的,如圖所示,具有復合縮放比例的模型傾向于集中在具有更多物件細節的更相關區域上,而其他模型則缺少物件細節或無法捕獲影像中的所有物件,
七、結論
在本文中,我們系統地研究了ConvNet的縮放比例,并確定了仔細平衡網路的寬度,深度和解析度是重要但缺少的一環,從而妨礙了我們提高準確性和效率,為了解決此問題,我們提出了一種簡單而高效的復合縮放方法,該方法使我們能夠以更原則的方式輕松地將基線ConvNet縮放到任何目標資源約束,同時保持模型效率,在這種復合縮放方法的支持下,我們證明了在ImageNet和五個常用的遷移學習資料集上,可變尺寸的EfficientNet模型可以非常有效地按比例縮放,以少的數量級引數和FLOPS,超過了最新模型的準確性,
 CSDN認證博客專家
博客專家
CSDN合作伙伴
演算法實習僧
CSDN認證博客專家
博客專家
CSDN合作伙伴
演算法實習僧
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/240521.html
標籤:其他