讓我們把時間推回到28年前那個風雨交加的夜晚,在一個小破屋里,幾個老男人搗鼓出了人類歷史上第一個推薦系統——Tepestry[1]

這個成立于1970年的小破屋并不簡單,在這里誕生了很多有趣的玩意,比如激光列印機、圖形用戶界面、以太網、數字視頻、文字處理等等,今天要介紹的推薦系統,也許是他們覺得最微不足道的發明之一,
這個小破屋的全名是Xerox Palo Alto Research Center,簡稱PARC,翻譯成中文是“濕了公司怕啦熬禿研究中心”,聽名字就很geek.
1992年,PARC的Goldberg、Nichols、Oki、Terry一行四人在《Communications of the ACM》上發表了一篇論文《Using Collaborative Filtering to Weave an Information Tapestry》,從此開啟了推薦系統28年的歷史行程,
下面主要介紹這篇論文:
Motivation
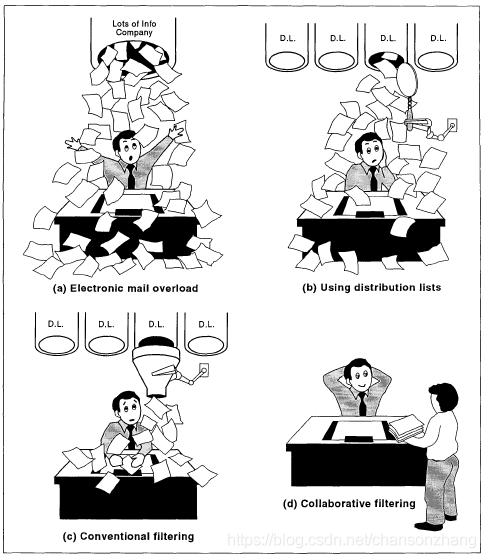
上世紀90年代,隨著電子郵件的廣泛普及,美帝的人們開始被資訊爆炸的問題困擾,為了解決這個問題,Tapestry應運而生,Tapestry允許你基于檔案的內容以及其他用戶對檔案的反應來進行搜索,比如你可以搜索包含“松果彈抖閃電鞭”并且隔壁老王看了覺得很棒的內容,
這種做法基于這樣的信念:人的參與可以使資訊過濾更高效,
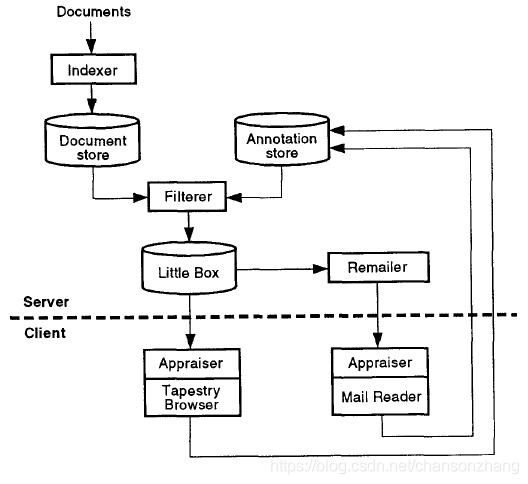
系統架構
下圖是Tapestry的架構圖,主要包括8個組件,分別為
- Indexer
- Document Store
- Annotation Store
- Filter
- Little box
- Remailer
- Appraiser
- Reader/Browser
后面會逐一進行介紹,
Indexer
Indexer主要是從外部源讀取檔案、對檔案進行決議、提取相關的欄位、創建相關的索引并存入Document Store.
Document Store
提供檔案及索引長期持久存盤的資料庫,限制為append-only,這個約束主要是為了連續查詢的效率考慮,詳見他們的另一篇論文Continuous Queries over Append-Only Databases[4]
Annotation Store
主要存盤用戶對檔案的標注,也是append-only
之所以將Annotation與Document分開存盤,主要是出于以下兩個考慮:
- 由于過濾器要求檔案是不可變的(immutable),annotation是在檔案之后到達,將其作為檔案的欄位存盤會違反檔案的不可變約束,
- Annotation本身的結果也可能會比較復雜,將其獨立存盤并參考對應的檔案是更簡潔的方案,
Filterer
執行用戶提供的查詢,將符合要求的檔案放入用戶的Little Box中,其中過濾器使用他們專門為這個系統提出的TQL語言撰寫,后面會有詳細介紹,
Little Box
存放用戶感興趣的檔案,每個用戶都有一個專屬小盒子,檔案由過濾執行器放入,由Reader洗掉,
Remailer
周期性地將用戶Little Box中的檔案通過郵件推送給用戶
Appraiser
根據用戶的個性化設定為小盒子中的檔案設定優先級及分類等
Filter只是一個二元篩選,即一個檔案要么通過過濾器,要么被過濾掉
Appraiser可以根據檔案的重要性為其設定優先級,例如會議通知比促銷資訊有更高的優先級,Appraiser還需要支持優先級的調整,比如會議更新通知(如更換會議室)會使原來的會議通知優先權降低,但不能刪掉,因為原來的郵件里可能有更新郵件中沒有的資訊,
將Appraiser和Filterer分開主要是基于性能的考慮,如果直接對所有檔案使用Appraiser進行打分,性能將會非常低下,因此先使用Filterer對檔案進行二元過濾,只有很少一部分檔案會通過過濾器而被放入用戶的小盒子中,然后再對小盒子中的檔案使用Appraiser進行打分將會大大降低計算量,
Tapestry中的Appraiser的作用類似于現代推薦系統當中的rank階段,與rank不同的是,Appraiser是運行在客戶端的,
Appraiser在完成對LittleBox中的檔案打分之后,會記錄下這些檔案的id,然后將Little Box中的對應檔案洗掉,
Reader/Browser
提供基于客戶端或者瀏覽器的UI,用戶添加、洗掉、編輯過濾器,獲取和展示little box中的新檔案,將檔案歸入不同的檔案夾、對檔案進行標注以及提供臨時的查詢功能,
對于不愿與使用Tapestry專用客戶端或者瀏覽器界面的用戶,可以直接使用他們的郵箱與Tapestry互動,上面提到的Remailer會定期地將用戶感興趣的檔案推送到用戶的郵箱中,用戶也可以通過郵件向Tapestry系統發送相關指令,例如新增過濾器,添加標注,運行臨時查詢等等,
臨時查詢(ad hoc queries)的功能有點類似于Filter,區別在于Filter設定后會周期性地執行,而臨時查詢是用戶臨時起意的查詢,一般只執行一次,
由于Tapestry提供了檔案的持久化存盤,客戶端在洗掉對應的檔案后,依然可以通過構建一個臨時查詢來從Document Store中檢索出需要的檔案,
臨時查詢的一個好處時可以利用private fields,例如檔案是否已讀、檔案被放在哪個目錄下等,這些資訊只存盤在客戶端,因而在服務端周期運行的Filter無法利用這些資訊,而臨時查詢既可以利用服務端的檔案資訊,也可以利用客戶端保存的這些私有資訊,
TQL(Tepastry Query Language)
motivation
為什么不用SQL?
SQL的優點是通用,而且使用SQL可以簡化系統的實作,
但SQL的最大缺點是復雜,畢竟這個系統是給普通用戶(而非程式員)用的,
程式員的基本職業操守就是“方便用戶,惡心自己”,況且這個系統支持的功能很簡單,因此他們決定自己搞一個專用且簡單的DSL
有些系統設計者/開發者可能會抱怨:
“這玩意已經這么簡單了你告訴我你**不會用?”
這其實是一種知識詛咒(The Curse of Knowledge),有過輔導孩子寫作業的經歷之后就會深有體會,
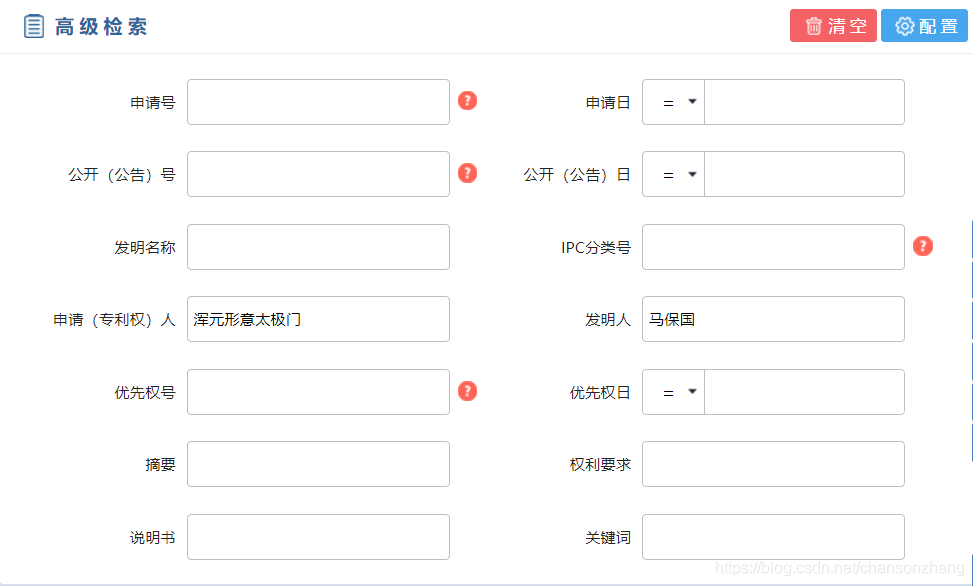
使用簡化版的查詢語言可以降低系統的使用門檻,時至今日,依然有系統這樣做,例如中國國家知識產權局開發的專利檢索與分析系統, 他們的查詢查詢陳述句如下圖所示:
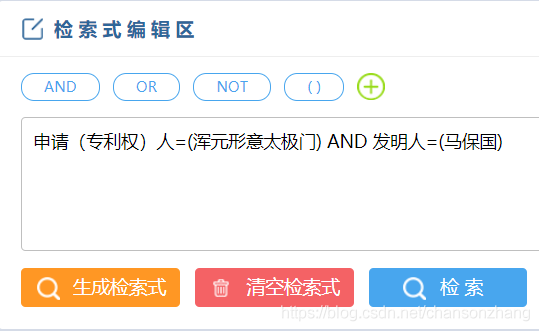
我敢打賭現在有相當一部分程式員其實SQL都寫不利索(特別是在他們用了MyBatis之后),就更別說普通用戶了,但是上面這種簡化的查詢陳述句就顯得老少咸宜了,
除了學習成本高之外,SQL還有一個問題就是它的Schema相對比較固定,而檔案的結構不太固定,又有各種集合查詢之類的騷操作,因而想用SQL撰寫這樣的查詢顯然不太優雅,當然如果那會有MongoDB的話這就不是個問題了,可惜MongoDB直到15年后的2007年才誕生,即便是我們現在常用的關系型資料庫mysql也是直到1996年才發布了1.0版本,而當時卻是茹毛飲血的1992年.
值得注意的一點是,雖然TQL已經很簡單了,但這其實還是提供給高級用戶的功能,大部分普通用戶其實是不會用的,普通用戶需要的是更加傻瓜式的操作,最好點點點就能完成任務,為此Tapestry中提供了很多常用的預定義查詢,用戶只要提供相應的引數就能輕而易舉地構建出想要的查詢陳述句,這一點同樣在專利檢索與分析系統中得到了體現,
基本語法
TQL的語法基本類似于一階謂詞,另外還增加了對集合的操作,
TQL其實是一個布爾運算式,主要包括以下三種元素:
- 原子運算式(atomic formulas)
- 布爾運算子 (boolean operators)
- 限定詞(qualifiers)
最簡單的TQL查詢是一個原子運算式,包含=,>,<,LIKE等算子
比如下面的運算式會篩選出主題為馬保國的內容
m.subject = '馬保國'
稍微復雜的一點就是原子運算式加上布爾運算子,例如:
m.sender = '一個朋友'
AND m.subject LIKE '%馬老師發生什么事了%'
TQL還支持集合查詢:
m.to = {'英國大力士', LIKE ‘%小伙子%’}
協同查詢需要用到量化變數,例如下面的查詢找到所有得到馬老師回復的檔案
EXISTS (m1: m1.send = '馬老師'
AND m1.in-reply-to = {m})
最后,一個用戶的query可以參考另外一個用戶的query,
例如下面的查詢可以找到隔壁老王的funnyQuery中包含‘松果糖豆閃電鞭’的檔案
m IN OldWang.funnyQuery
AND m.words = {'松果糖豆閃電鞭'}
Annotations
包含annotation的查詢例子如下:
a.type = 'vote'
AND a.owner = 'weiser'
AND a.msg = m
這個查詢會找出所有被weiser這個人投過票的檔案
注意,這個系統最開始是針對郵件系統的,所以用的欄位是msg,而不是我們現在常見的document
上面這個查詢其實暗含了上面提到的EXISTS關鍵字,完整寫法是:
EXISTS (a: a.type = 'vote'
AND a.owner = 'weiser'
AND a.msg = m)
下面這個查詢會找出優先級為10的檔案:
a.type = 'priority'
AND a.value = 10
AND a.msg = 'm'
過濾查詢
對于用戶設定的過濾器,最直觀的方法是定時執行所有過濾器查詢,不過有兩個問題需要考慮
- 多查
- 漏查
多查:當前查詢的結果包含了上次查詢結果,需要將這部分重復的檔案剔除
關于漏查詢的問題舉個栗子:
假設定時任務每小時執行一次,現在要查詢所有未被回復的檔案,某檔案 m 在 08:15到達,08::45被回復
如果定時任務是每個整點執行,那么結果中永遠不會包含m,因為08:00執行查詢的時候還沒有檔案m,09:00執行查詢的時候檔案m被回復了已經不滿足條件了(下圖a)
如果定時任務是每個半點執行,那么結果中就會包含m,因為08:30執行查詢的時候m滿足條件,(下圖b)
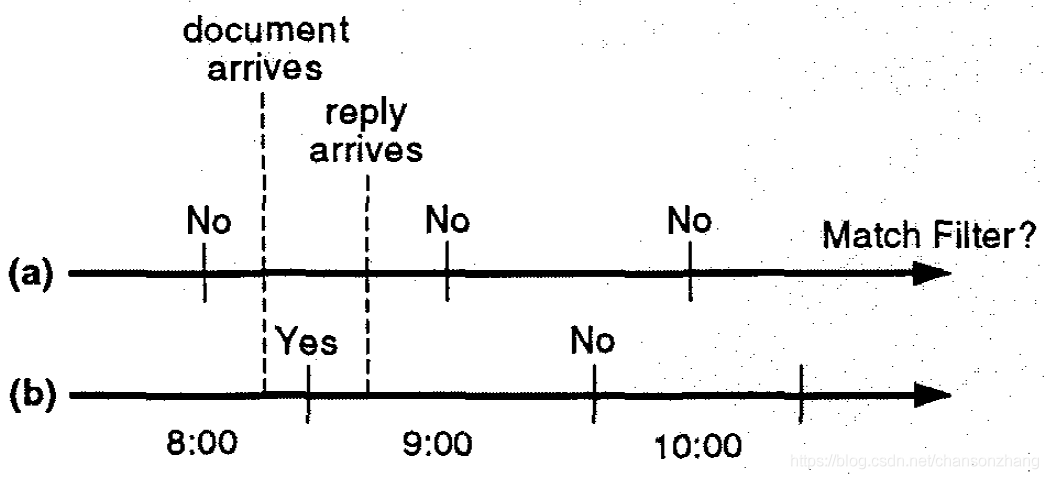
這相當于讓查詢變成了薛定諤的貓,就像你在微信里發出的每一條訊息都是薛定諤的訊息,你永遠無法知道這條訊息是否已被微信屏蔽了,
為了解決這種問題,Tapestry要求查詢遵循連續語意(continuous semantics)
連續語意
假設 Q ( t ) Q(t) Q(t)表示在時間 t t t 執行查詢 Q Q Q 的結果,那么在連續語意下在 t t t 時刻執行查詢 Q Q Q 的結果為 ? s ≤ t Q ( s ) \bigcup_{s\le t}Q(s) ?s≤t?Q(s)
這種語意雖然避免了漏查,但是對于上面的查詢“找出所有未被回復的檔案”依然無能為力,因為所有的檔案在剛到達時都是未被回復的,按照這種語意將會回傳所有檔案,
這顯然不是用戶想要的!
不過問題不在于連續語意,而在于查詢本身,
用戶的真實意圖既不可能是查詢所有“未在第一時間回復”的檔案(包含所有檔案),也不可能是查詢“永遠未被回復的檔案”,因為要判斷一個檔案是否永遠未被回復,系統就需要永遠的等下去以探究竟,不過系統只要等待一個較短的時間就能獲取后者的近似結果,因為絕大部分郵件都會在一個較短的時間內被回復,否則將永遠不會被回復,
因此,一個更有意義的查詢應該類似于 “找出未在兩周內被回復的檔案”,
當然如果用戶就是要查詢“當前未被回復”的檔案怎么辦呢?畢竟用戶是大爺嘛,
顯然這種查詢并不適合作為filter query被周期性執行的,不過用戶可以選擇使用前面提到的ad hoc query進行這樣的查詢,
那么連續語意如何實作呢?
顯然按照連續語意的定義那樣在每一個時刻去執行查詢是不可能的,(也許量子計算機會給我們帶來驚喜)
他們在一篇更早的論文[4]中提供了一種在append-only的資料庫上更高效地實作連續語意的方法,
高效地實作連續語意的關鍵在于下面這樣一個事實:
只要一個查詢的結果集隨時間不減,那么只要周期性地執行這個查詢就能實作連續語意,
這也就解釋了前面提到的查詢“找出沒有被回復的郵件”在被周期執行時不能滿足連續語意了,因為當一個郵件被回復,它就不會再出現在結果集中,
同時也解釋了為什么“未在兩周內被回復”這個查詢在周期執行時可以滿足連續語意,因為“未在兩周內被回復”這個事實一旦成立,就永遠不會被時間改變了,
基于以上觀察,Tapestry通過對用戶的filter query進行兩階段改寫以實作連續語意:
兩階段改寫
階段1:改寫為單調形式
階段2:改寫為增量模式
單調形式
結果集隨時間不減的查詢稱為單調查詢(monotone query), 單調查詢滿足:
Q
M
(
t
1
)
?
Q
M
(
t
2
)
,
t
1
<
t
2
Q^M(t_1)\subseteq Q^M(t_2), t_1<t_2
QM(t1?)?QM(t2?),t1?<t2?
這種查詢在時刻
t
t
t 執行時會回傳當前及過去滿足原始查詢的所有檔案,即
Q
M
(
t
)
=
?
s
≤
t
Q
(
s
)
Q^M(t)=\bigcup_{s\le t}Q(s)
QM(t)=?s≤t?Q(s)
假設同樣的過濾查詢在時間
τ
\tau
τ 已經執行過一次,結果集為
Q
M
(
τ
)
Q^M(\tau)
QM(τ)
因為
Q
M
(
τ
)
Q^M(\tau)
QM(τ)已經回傳給用戶了,因此當前查詢只需要回傳
Q
M
(
t
)
?
Q
M
(
τ
)
Q^M(t)-Q^M(\tau)
QM(t)?QM(τ) 即可
直接計算
Q
M
(
t
)
?
Q
M
(
τ
)
Q^M(t)-Q^M(\tau)
QM(t)?QM(τ) 是低效的,因此需要階段2的改寫,將查詢改為增量形式
增量形式
這一階段主要是將查詢改為 Q I ( t , τ ) Q^I(t,\tau) QI(t,τ), 作為 Q M ( t ) ? Q M ( τ ) Q^M(t)-Q^M(\tau) QM(t)?QM(τ) 的近似,可以看出經過兩階段改寫后的查詢,其執行周期只會影響每個批次的結果集,而不會影響整體的結果集,這就解決了前面提到了“薛定諤的查詢”問題,
示例
例如對于查詢
m.sender = 'Joe'
這一查詢已經是單調形式(發件人永遠不會隨著時間改變),因此無需階段1的改寫,直接進行階段2的改寫,將其改寫為以下形式:
m.sender = 'Joe'
AND (m.ts > τ AND m.ts ≤ t)
其中 ts 是每個檔案到達的時間戳, τ 是上次執行的時間,t 是當前執行的時間
我們再來看一個復雜一點的例子,對于查詢“兩周前的還未被回復的bug”
m.to = 'BugReports'
AND m.ts + [2 weeks] < now()
AND NOT EXISTS (
mreply: mreply.in_reply_to = {m}
)
這個查詢不是單調的,原因是回復狀態會隨著時間改變,首先進行階段1的改寫,將其改寫為單調形式:
m.to = 'BugReports'
AND m.ts + [2 weeks] < now()
AND NOT EXISTS (
mreply: mreply.in_reply_to = {m}
AND mreply.ts < m.ts + [2 weeks]
)
這個查詢表示“未在兩周內被回復的bug”,這個查詢就是單調的了,
值得注意的一點是,為了滿足連續語意,這個改寫后的查詢與原始查詢的意義略有差別,這一點在前面已經有過討論,
然后這個查詢還要經過階段2的改寫,將其改寫為增量形式:
m.to = 'BugReports'
AND m.ts + [2 weeks] > τ
AND m.ts + [2 weeks] ≤ t
AND NOT EXISTS (
mreply: mreply.in_reply_to = {m}
AND mreply.ts < m.ts + [2 weeks]
)
整體流程
當用戶通過TQL語言撰寫了過濾查詢之后,Tapestry對用戶的原始查詢進行上述的兩階段改寫使其滿足連續語意,然后周期性的執行這些過濾查詢,一旦某個檔案滿足了某個過濾器的條件(比如被添加了特定的annotation),這個檔案就會被推送給用戶,
這個程序的偽代碼如下:

系統實作
存盤模塊
由于沒有非關系型資料庫可用,只能強行把復雜的資料結構塞進關系型資料庫Sybase
檔案的公共欄位被放入一張表,每個檔案占一行
檔案的其他欄位被放入另外一張表,每個檔案可能會占多行
集合單獨存放在一張表中,集合中的每個value占一行
annotation類似,也需要多張表來存盤
從這里可以看出,讓用戶用SQL去查詢這么復雜的表結果簡直是失了智,因此Tapestry才決定引入TQL以屏蔽資料結構的復雜性
Tapestry中檔案的存盤形式為append-only,即不允許洗掉檔案,原因是如果檔案可以被洗掉,那同一個query,在檔案洗掉前和洗掉后查詢,就會得到不同的結果,這樣就不符合連續語意了,
索引模塊
Indexer負責理解給定的檔案,從中抽取相關的欄位塞入資料庫中,
每種特定的檔案對應一種索引實作,增加一種新的檔案型別,只需要增加一種新的索引實作即可,到這里我們不得不驚嘆,1992年的系統設計者竟然已經懂得了設計模式的開閉原則
以NetNews訊息為例,對應的索引程式會將訊息頭中欄位全部轉換為對應的Tapestry欄位,然后將正文中的詞去掉停用詞之后全部塞入words欄位,并且單詞在被加入索引之前會做詞干提取和詞形還原處理,比如ran會被處理為run.
TQL2SQL translator
這個模塊的功能其實就是把TQL“編譯”為可以直接在Sybase上執行的SQL陳述句,
對于臨時查詢,不經改寫直接轉化為sql
對于filter中的查詢,先進行前面介紹的兩階段改寫,然后再轉化為SQL,并且保存為Sybase的存盤程序,
下圖是一個TQL查詢轉為SQL查詢的示例,可以看出TQL要比SQL簡單很多:

通過創建合適的資料庫索引和利用優秀的查詢優化器,可以使這種復雜的查詢高效的運行,大部分情況下,增量查詢的開銷與執行間隔內新增資料集而非整個資料集的大小成比例,
Remailer
Filter篩選出來的結果會被Remailer通過郵件推送給用戶,推送前會在郵件中添加額外的header標記對應的檔案是由哪個filter篩選出來的,有點類似埋點資訊,有利于后續的反饋、除錯和優化,
Appraiser
一些用戶使用卡內基梅隆大學研發的Andrew Message Reader[5],這種郵件閱讀器支持一種叫做“FLAMES”的語言,可以撰寫簡單的“appraiser”來自動地將符合條件的郵件放入指定的檔案夾,比如用戶可以通過郵件的header資訊,判斷郵件是否是Tapestry的推送,以及具體來自于哪個過濾器,并將歸入自定義的目錄,
Tapestry還在一個叫做Walnut[6]的郵件閱讀器中加入了appraiser支持,用戶可以定義一些規則并制定符合這個規則后的得分,如果一個郵件命中多個規則,則得分為這些命中的規則得分之和,Walnut支持將郵件歸類到不同的檔案夾下并按照得分排序,
總結
主要貢獻
這篇文章最大的貢獻是提出了協同過濾的思想,迄今為止,協同過濾依然活躍在各大公司的推薦系統當中,
協同過濾的主要思想是:在過去達成一致的用戶很可能在未來也會達成一致,基于這點,我們才可以通過分析用戶過去的行為來為其推薦未來可能喜歡的物品,
這有點像記憶體區域性原理,即記憶體訪問具有時間區域性和空間區域性,因此cache才有了用武之地,
Tapestry中的協同過濾依賴于用戶的標注,他們發現存在這樣兩類用戶:
- 饑渴用戶(eager readers)
- 佛系用戶(casual readers)
對于饑渴用戶來說,他們總是在第一時間閱讀最新的檔案,并按捺不住要給檔案打上標注,對于佛系用戶來說,他們會依賴于前者的評價來篩選檔案,這其實有點類似于豆瓣的設計思路,比如我就是一個重度豆瓣評分依賴者,不過我一般看完也會為“人肉標注”做出一點自己的貢獻,
與現代推薦系統對比
Tapestry和現在的推薦系統的不同之處在于,它的協同過濾是一個手動的程序,也相對透明,你必須自己設定符合你獨特偏好的過濾器,甚至可以選擇某個你認為和你臭味相投的人,直接使用他們的過濾器或者在其基礎上進一步優化,哪些資訊能夠通過過濾器是由你說了算的,甚至連打分規則你都可以自己定義,
相比之下,現在的推薦系統更像一個自動運行的黑盒,比如在User-Based協同過濾中,推薦系統會自動找出和你相似的用戶,然后將他們的打分做加權平均以預測你對物品的打分,你對打分規則一無所知,和哪些用戶相似也是演算法說了算,演算法就像獨裁的家長一樣替你做了所有決定(但卻不會替你付錢),
協同過濾經常面臨的一個問題是“冷啟動”,因為它需要使用大量用戶與系統的互動資訊作為推薦依據,因此也會造成“少者愈少,多者更多”的問題,在Tapestry中,就算檔案沒有任何標注,你依然可以根據檔案的元資料以及內容設定相應的過濾器,這在一定程度上緩解了冷啟動的問題,
寫在最后
協同過濾有時候會給你推薦一些新鮮的事物,這是好事,但也有可能恰恰相反,將你困在利基社區中,用扎克伯格的話來說就是——你院前奄奄一息的松鼠可能比掙扎在生死邊緣的非洲人民與你的興趣更加“相關”[3],
Eli Pariser在其分享[3]中提到兩個人同一時間使用Google搜索“埃及”這個關鍵詞,卻得到了完全不同的內容,其中一個人得到大量關于游行抗議的結果,而另一個人看到的卻是一片歌舞升平,
這種演算法用于網路媒體和搜索引擎會構建出一個什么樣的世界呢?也許是一個網路巴爾干化,偏見盛行的世界,那么,這到底是不是我們的“福報”呢?
參考文獻:
[1] Using Collaborative Filtering to Weave an Information Tepestry
[2] How recommender systems make their suggestions
[3] Beware Online Filter Bubbles
[4] Continuous Queries over Append-Only Databases
[5] An Overview of the Andrew Message System
[6] Browsing Electronic Mail: Experiences Interfacing a Mail System to a DBMS
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/241495.html
標籤:其他
上一篇:2020-09-22
下一篇:Vant主題定制修改顏色樣式