實驗八 查找
實驗目的
基于教材內容,從順序查找、二分查找、基于BST的查找和哈希中任選兩種查找演算法,實作并比較性能,
基本要求
(1)對實作的查找演算法進行實驗比較,在不同資料規模(N)下執行100次成功查找,以表格形式記錄最小、最大和平均查找時間;在不同資料規模(N)下執行100次不成功查找,以表格形式記錄最小、最大和平均查找時間,
(2)查找演算法要基于教材,測驗輸入的整數資料檔案(5個,檔案中資料規模N分別是100,1K,10K,100K和1M),每次查找的比較次數和時間也要輸出到檔案中,
(3)提交最終實驗作業,用附件的形式,提交兩個檔案:一個壓縮包(包含原始碼和5個用于查找測驗的資料檔案);一個pdf檔案(檔案中包含實驗日志和一個根據基本要求(1)記錄實驗結果的表格,然后進行適當的實驗結果分析),
本次實驗的重點在于加強對順序查找、二分查找、基于BST的查找和哈希等查找演算法的認識和性能的分析,(在此次實驗中我選擇了順序查找和哈希查找,所以以下日志內容主要是本人對兩種查找演算法的認識)
- 順序查找:
顧名思義,順序查找即依次從前向后查找,是一種易于理解、易于實作,但耗時較多的查找方式,
-
查找程序
首先,將待查找資料與表內的第一個資料進行比對,如果相同則表明查找成功,如果不相同,則與第二個資料進行對比,重復以上程序,直到找到匹配的資料,使查找成功,或直到查找到表的最后一位依舊不匹配,此時表明該資料不存在,查找不成功,
-
演算法要求
必須采用順序存盤結構,
-
比較次數
當順序表有n個關鍵字時:
查找失敗時,比較max次關鍵字;查找成功時,比較n次關鍵字(n即為回圈次序),
-
演算法復雜度
順序查找的基本思想是一次向后查找,若找到就停止,若一直到最后都未找到,則表明查找失敗,
時間復雜度是O(n)
-
Hash查找
哈希查找是通過計算資料元素的存盤地址進行查找的一種方法,
-
定義
哈希查找的操作步驟:
⑴用給定的哈希函式構造哈希表;
⑵根據選擇的沖突處理方法解決地址沖突;
⑶在哈希表的基礎上執行哈希查找
-
操作步驟
step1
取資料元素的關鍵字key,計算其哈希函式值,若該地址對應的存盤空間還沒有被占用,則將該元素存入;否則執行step2解決沖突,
step2
根據選擇的沖突處理方法,計算關鍵字key的下一個存盤地址,若下一個存盤地址仍被占用,則繼續執行step2,直到找到能用的存盤地址為止,哈希查找步驟為:
設哈希表為HST[0~M-1],哈希函式取H(key),解決沖突的方法為R(x);
Step1 對給定k值,計算哈希地址 Di=H(k);若HST為空,則查找失敗;
若HST=k,則查找成功;否則,執行step2(處理沖突),
Step2 重復計算處理沖突的下一個存盤地址 Dk=R(Dk-1),直到HST[Dk]為
空,或HST[Dk]=k為止,若HST[Dk]=K,則查找成功,否則查找失敗,
哈希查找的本質是先將資料映射成它的哈希值,哈希查找的核心是構造一個哈希函式,它將原來直觀、整潔的資料映射為看上去似乎是隨機的一些整數,
哈希查找的產生有這樣一種背景——有些資料本身是無法排序的(如影像),有些資料是很難比較的(如影像),如果資料本身是無法排序的,就不能對它們進行比較查找,如果資料是很難比較的,即使采用折半查找,要比較的次數也是非常多的,因此,哈希查找并不查找資料本身,而是先將資料映射為一個整數(它的哈希值),并將哈希值相同的資料存放在同一個位置一即以哈希值為索引構造一個陣列,
在哈希查找的程序中,只需先將要查找的資料映射為它的哈希值,然后查找具有這個哈希值的資料,這就大大減少了查找次數,如果構造哈希函式的引數經過精心設計,記憶體空間也足以存放哈希表,查找一個資料元素所需的比較次數基本上就接近于一次,
-
解決沖突
影響哈希查找效率的一個重要因素是哈希函式本身,當兩個不同的資料元素的哈希值相同時,就會發生沖突,為減少發生沖突的可能性,哈希函式應該將資料盡可能分散地映射到哈希表的每一個表項中,解決沖突的方法有以下兩種:
(1) 開放地址法
如果兩個資料元素的哈希值相同,則在哈希表中為后插入的資料元素另外選擇一個表項,
當程式查找哈希表時,如果沒有在第一個對應的哈希表項中找到符合查找要求的資料元素,程式就會繼續往后查找,直到找到一個符合查找要求的資料元素,或者遇到一個空的表項,
(2) 鏈地址法
將哈希值相同的資料元素存放在一個鏈表中,在查找哈希表的程序中,當查找到這個鏈表時,必須采用線性查找方法,
-
查找結果
| 查找演算法 | Hash查找(成功) | ||||
|---|---|---|---|---|---|
| 資料規模 | 100 | 1k | 10k | 100k | 1M |
| 最小查找時間(單位:ms) | 0 | 0 | 0 | 0 | 0 |
| 最大查找時間(單位:ms) | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
| 平均查找時間(單位:ms) | 2e-005 | 1.4e-005 | 1e-005 | 2.2e-005 | 1.3e-005 |
| 查找演算法 | Hash查找(失敗) | ||||
| 資料規模 | 100 | 1k | 10k | 100k | 1M |
| 最小查找時間(單位:ms) | 0 | 0 | 0 | 0 | 0 |
| 最大查找時間(單位:ms) | 0.0001 | 0.0001 | 0.0001 | 0.0002 | 0.0001 |
| 平均查找時間(單位:ms) | 2.5e-005 | 1.8e-005 | 2.6e-005 | 2.7e-005 | 1.9e-005 |
| 查找演算法 | 順序查找(成功) | ||||
| 資料規模 | 100 | 1k | 10k | 100k | 1M |
| 最小查找時間(單位:ms) | 0 | 0.0001 | 0.0001 | 0.0011 | 0.043 |
| 最大查找時間(單位:ms) | 0.0014 | 0.0131 | 0.0299 | 0.6088 | 2.5673 |
| 平均查找時間(單位:ms) | 0.000224 | 0.001744 | 0.012086 | 0.1256 | 1.24673 |
| 查找演算法 | 順序查找(失敗) | ||||
| 資料規模 | 100 | 1k | 10k | 100k | 1M |
| 最小查找時間(單位:ms) | 2.0865 | 2.0858 | 2.0813 | 2.08311 | 2.0834 |
| 最大查找時間(單位:ms) | 3.4584 | 2.9283 | 3.0102 | 2.7519 | 3.2602 |
| 平均查找時間(單位:ms) | 2.26678 | 2.23546 | 2.23569 | 2.21732 | 2.21285 |
實驗結果分析:
Hash查詢時間幾乎為0,所花時間基本上是在建立hash表時,hash查找較順序查找的優勢體資料量越大越明顯.從理論上來看,hash查找的時間復雜度為O(1),順序查找的則為O(n);hash查找的劣勢是建hash表花時間過多,當然這也跟hash表的設計有關;
從實驗來看,hash查找用于資料量巨大,查詢頻繁的情況下.
知道了上面這些后,我們就開始寫代碼
(1)首先是亂數檔案的生成,方法有很多,額外創建success和fail的txt檔案,用于對亂數的成功和失敗的查找,
如下
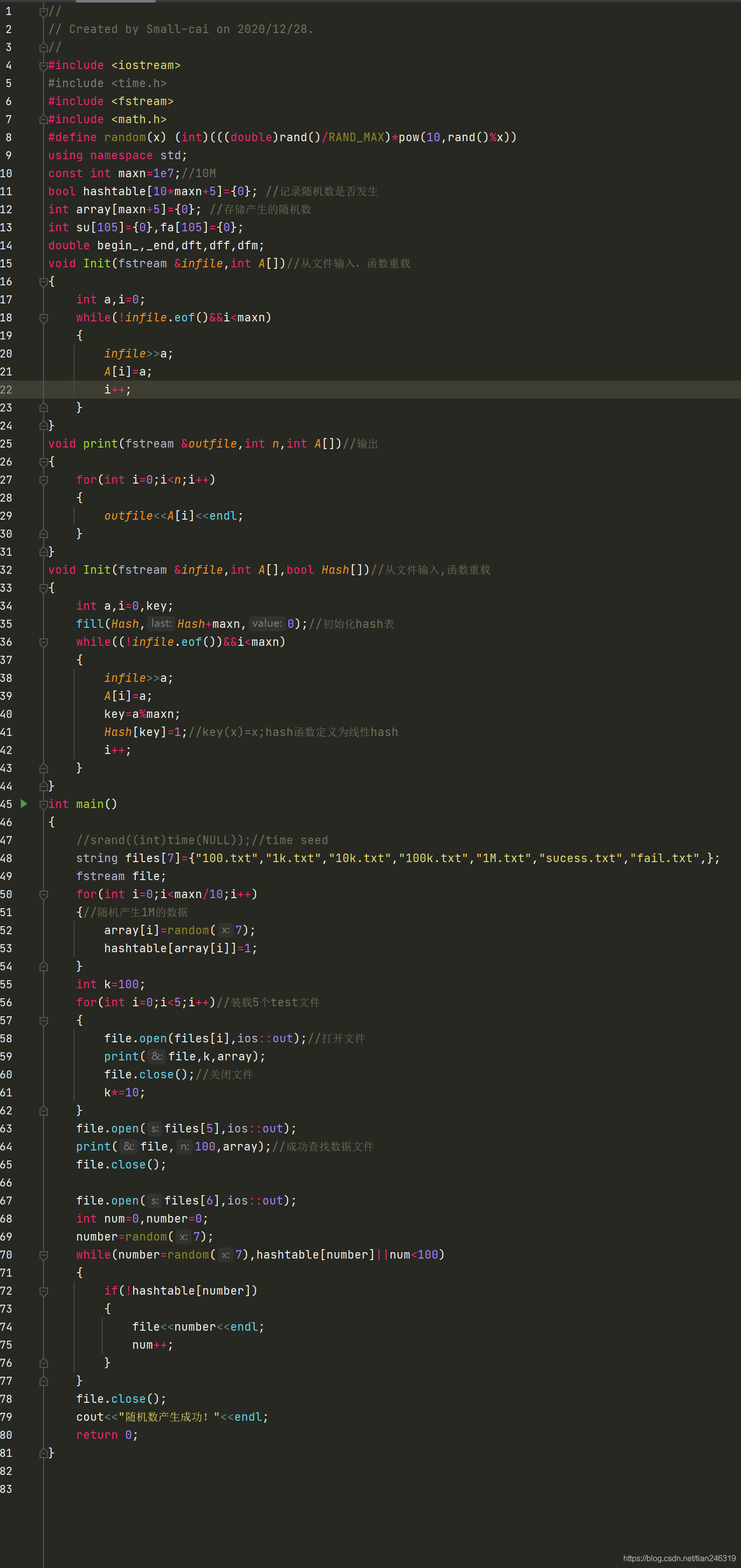
生成后的檔案如下圖所示


(2)接下來是對每一組測驗資料分別進行100次成功和失敗查找
/*
Created by Small-cai
Data: 12/28 12:56
*/
#include <iostream>
#include <time.h>
#include <iomanip>
#include <windows.h>
#include <fstream>
#include <algorithm>
using namespace std;
LARGE_INTEGER frequency;
int S[105]={0},F[105]={0};
const int maxn=1000000;
int A[maxn+5]={0},B[maxn+5]={0};
double dff,begin_,_end,dfm,dft;
void Init(ifstream &infile,int M[maxn])
{
int a,i=0;
while(!infile.eof()&&i<maxn)
{
infile>>a;
M[i]=a;
i++;
}
}
void Init(ifstream &infile,int M[maxn],int N[maxn])
{
int a,i=0,key;
fill(N,N+maxn,-1);
while(!infile.eof()&&i<maxn)
{
infile>>a;
M[i]=a;
key=a%maxn;
N[key]=a;//key(x)=x;hash函式定義為線性hash
i++;
}
}
void search_sequential(ofstream& outfile,int A[maxn],int n)//順序查找
{
sort(A,A+n);//升序排列
int x;
int num=0;//中間值和比較次數
double mints=100,maxts=0,averages=0;
double mintf=100,maxtf=0,averagef=0;
bool flag;
cout<<"-----------------順序查找成功------------------\n";outfile<<"-----------------順序查找成功------------------\n";
for(int i=0;i<100;i++)//100次成功查找
{
x=S[i];//確定待查找的數x
num=0;//初始化查找次數為0
flag=0;
QueryPerformanceCounter(&frequency);
begin_=frequency.QuadPart;//獲得初始值
int j=0;
while(j<maxn+5)//順序查找
{
num++;
if(A[j]==x)
{
flag=1;//查找成功
break;
}
else j++;
}
QueryPerformanceCounter(&frequency);
_end=frequency.QuadPart;//獲得終止值
dfm=(double)(_end-begin_);//差值
dft=dfm/dff;//差值除以頻率得到時間
if(flag)//查找成功
{
cout<<"順序查找記錄->"<<x<<"->成功 "<<"查找次數: "<<num<<"次";
outfile<<"順序查找記錄:"<<x<<"->成功 "<<"查找次數: "<<num<<"次";
}
else
{
cout<<"順序查找記錄->"<<x<<"->失敗 "<<"查找次數: "<<num<<"次";
outfile<<"順序查找記錄:"<<x<<"->失敗 "<<"查找次數: "<<num<<"次";
}
cout<<"查找時間: "<<dft*1000<<"ms"<<endl;
outfile<<"查找時間: "<<dft*1000<<"ms"<<endl;
mints=min(mints,dft*1000);//最小時間
maxts=max(maxts,dft*1000);//最大時間
averages+=dft*10;//平均時間
}
cout<<"\n-----------------順序查找失敗------------------\n";outfile<<"-----------------順序查找失敗------------------\n";
for(int i=0;i<100;i++)//100次失敗查找
{
x=F[i];//確定待查找的數x
num=0;//初始化查找次數為0
flag=0;
QueryPerformanceCounter(&frequency);
begin_=frequency.QuadPart;//獲得初始值
int j=0;
while(j<maxn+5)//順序查找
{
num++;
if(A[j]==x)
{
flag=1;//查找成功
break;
}
else j++;
}
QueryPerformanceCounter(&frequency);
_end=frequency.QuadPart;//獲得終止值
dfm=(double)(_end-begin_);//差值
dft=dfm/dff;//差值除以頻率得到時間
if(flag)//查找成功
{
cout<<"順序查找記錄->"<<x<<"->成功 "<<"查找次數: "<<num<<"次";
outfile<<"順序查找記錄:"<<x<<"->成功 "<<"查找次數: "<<num<<"次";
}
else
{
cout<<"順序查找記錄->"<<x<<"->失敗 "<<"查找次數: "<<num<<"次";
outfile<<"順序查找記錄:"<<x<<"->失敗 "<<"查找次數: "<<num<<"次";
}
cout<<"查找時間: "<<dft*1000<<"ms"<<endl;
outfile<<"查找時間: "<<dft*1000<<"ms"<<endl;
mintf=min(mintf,dft*1000);//最小時間
maxtf=max(maxtf,dft*1000);//最大時間
averagef+=dft*10;//平均時間
}
cout<<"順序查找成功:\n最小查找時間"<<mints<<"ms "<<"最大查找時間"<<maxts<<"ms "<<"平均查找時間"<<averages<<"ms\n查找結束\n";
outfile<<"順序查找成功:\n最小查找時間"<<mints<<"ms "<<"最大查找時間"<<maxts<<"ms "<<"平均查找時間"<<averages<<"ms\n查找結束\n";
cout<<"順序查找失敗:\n最小查找時間"<<mintf<<"ms "<<"最大查找時間"<<maxtf<<"ms "<<"平均查找時間"<<averagef<<"ms\n查找結束\n";
outfile<<"順序查找失敗:\n最小查找時間"<<mintf<<"ms "<<"最大查找時間"<<maxtf<<"ms "<<"平均查找時間"<<averagef<<"ms\n查找結束\n";
}
void search_hash(ofstream &outfile,int B[maxn])//hash散列查找
{
int x,num=1,key,y;
double mints=100,maxts=0,averages=0;
double mintf=100,maxtf=0,averagef=0;
bool flag;
cout<<"-----------------hash查找成功------------------\n";outfile<<"-----------------hash查找成功------------------\n";
for(int i=0;i<100;i++)//100次失敗查找
{
flag=0;
x=S[i],key=x%maxn,y=B[key];
QueryPerformanceCounter(&frequency);
begin_=frequency.QuadPart;//獲得初始值
if(y==x) flag=1;//查找成功
QueryPerformanceCounter(&frequency);
_end=frequency.QuadPart;//獲得終止值
dfm=(double)(_end-begin_);//差值
dft=dfm/dff;//差值除以頻率得到時間
if(flag)
{
cout<<"hash查找記錄:"<<x<<"->成功 "<<"查找次數:"<<num<<" 次";
outfile<<"hash查找記錄:"<<x<<"->成功 "<<"查找次數:"<<num<<" 次";
}
else
{
cout<<"hash查找記錄:"<<x<<"->失敗 "<<"查找次數:"<<num<<" 次";
outfile<<"hash查找記錄:"<<x<<"->失敗 "<<"查找次數:"<<num<<" 次";
}
cout<<"查找時間: "<<dft*1000<<"ms"<<endl;
outfile<<"查找時間: "<<dft*1000<<"ms"<<endl;
mints=min(mints,dft*1000);//最小時間
maxts=max(maxts,dft*1000);//最大時間
averages+=dft*10;//平均時間
}
cout<<"-----------------hash查找失敗------------------\n";outfile<<"-----------------hash查找失敗------------------\n";
for(int i=0;i<100;i++)//100次失敗查找
{
flag=0;
x=F[i],key=x%maxn,y=B[key];
QueryPerformanceCounter(&frequency);
begin_=frequency.QuadPart;//獲得初始值
if(y==x) flag=1; //查找成功
QueryPerformanceCounter(&frequency);
_end=frequency.QuadPart;//獲得終止值
dfm=(double)(_end-begin_);//差值
dft=dfm/dff;//差值除以頻率得到時間
if(flag)
{
cout<<"hash查找記錄:"<<x<<"->成功 "<<"查找次數:"<<num<<" 次";
outfile<<"hash查找記錄:"<<x<<"->成功 "<<"查找次數:"<<num<<" 次";
}
else
{
cout<<"hash查找記錄:"<<x<<"->失敗 "<<"查找次數:"<<num<<" 次";
outfile<<"hash查找記錄:"<<x<<"->失敗 "<<"查找次數:"<<num<<" 次";
}
cout<<"查找時間: "<<dft*1000<<"ms"<<endl;
outfile<<"查找時間: "<<dft*1000<<"ms"<<endl;
mintf=min(mintf,dft*1000);//最小時間
maxtf=max(maxtf,dft*1000);//最大時間
averagef+=dft*10;//平均時間
}
cout<<"hash查找成功:\n最小查找時間"<<mints<<"ms "<<"最大查找時間"<<maxts<<"ms "<<"平均查找時間"<<averages<<"ms\n查找結束\n";
outfile<<"hash查找成功:\n最小查找時間"<<mints<<"ms "<<"最大查找時間"<<maxts<<"ms "<<"平均查找時間"<<averages<<"ms\n查找結束\n";
cout<<"hash查找失敗:\n最小查找時間"<<mintf<<"ms "<<"最大查找時間"<<maxtf<<"ms "<<"平均查找時間"<<averagef<<"ms\n查找結束\n";
outfile<<"hash查找失敗:\n最小查找時間"<<mintf<<"ms "<<"最大查找時間"<<maxtf<<"ms "<<"平均查找時間"<<averagef<<"ms\n查找結束\n";
}
int main()
{
QueryPerformanceFrequency(&frequency);//獲得時鐘頻率
dff=(double)frequency.QuadPart;//取得頻率*/
ifstream in_100("100.txt"),in_1k("1k.txt"),in_10k("10k.txt"),in_100k("100k.txt"),in_1M("1M.txt");//輸入測驗資料檔案
ifstream sucess("sucess.txt"),fail("fail.txt");//輸入查找資料
ofstream out_100("out_100.txt"),out_1k("out_1k.txt"),out_10k("out_10k.txt"),out_100k("out_100k.txt"),out_1M("out_1M.txt");
Init(sucess,S);//輸入查找資料
Init(fail,F);//輸入查找資料
Init(in_100,A,B);//初始化
cout<<"對規模為100的檔案進行查找:"<<endl;out_100<<"對規模為100的檔案進行查找:"<<endl;
cout<<"hash散列查找開始:\n";
search_hash(out_100,B);//順序查找
cout<<"-----------------------------------------\n";out_100<<"-----------------------------------------\n";
cout<<"順序查找開始:\n";
search_sequential(out_100,A,100);//順序查找
Init(in_1k,A,B);//初始化
cout<<"對規模為1k的檔案進行查找:"<<endl;out_1k<<"對規模為1k的檔案進行查找:"<<endl;
cout<<"hash散列查找開始:\n";
search_hash(out_1k,B);//順序查找
cout<<"-----------------------------------------\n";out_1k<<"-----------------------------------------\n";
cout<<"順序查找開始:\n";
search_sequential(out_1k,A,1024);//順序查找
Init(in_10k,A,B);//初始化
cout<<"對規模為10k的檔案進行查找:"<<endl;out_10k<<"對規模為10k的檔案進行查找:"<<endl;
cout<<"hash散列查找開始:\n";
search_hash(out_10k,B);//順序查找
cout<<"-----------------------------------------\n";out_10k<<"-----------------------------------------\n";
cout<<"順序查找開始:\n";
search_sequential(out_10k,A,10240);//順序查找
Init(in_100k,A,B);//初始化
cout<<"對規模為100k的檔案進行查找:"<<endl;out_100k<<"對規模為100k的檔案進行查找:"<<endl;
cout<<"hash散列查找開始:\n";
search_hash(out_100k,B);//順序查找
cout<<"-----------------------------------------\n";out_100k<<"-----------------------------------------\n";
cout<<"順序查找開始:\n";
search_sequential(out_100k,A,102400);//順序查找
Init(in_1M,A,B);//初始化
cout<<"對規模為1M的檔案進行查找:"<<endl;out_1M<<"對規模為1M的檔案進行查找:"<<endl;
cout<<"hash散列查找開始:\n";
search_hash(out_1M,B);//順序查找
cout<<"-----------------------------------------\n";out_1M<<"-----------------------------------------\n";
cout<<"順序查找開始:\n";
search_sequential(out_1M,A,1048576);//順序查找
return 0;
}
最后,檔案下多出

信安應憐兒和你一起努力~
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/241892.html
標籤:其他