前景引入
最近Python很火,確實很火,好像一直都比較火,哈哈哈哈,如果你也覺得很火,那么就請看完這篇文章吧,看看Python的熱度到底能不能使我這篇文章火起來,
那么作為后起之秀的編程語言——Python,它到底能夠做些什么了,網上一直在“炒作”Python:一鍵化辦公,學好Python薪資翻一番,讓你的生活多一點money,讓你的老板對你刮目相看,讓你從此找到自信!這不是吹捧,也不是浮夸,從云計算、大資料到人工智能,Python無處不在,百度、阿里巴巴、騰訊等一系列大公司都在使用Python完成各種任務,讓Python越來越接地氣了,它的功能也不用我說了,它的優勢和特點我也不再贅述了,畢竟本篇是一個技術文章,話不多說,開干!
如果你是科研黨,請看完文章!文末有驚喜喲!
原始碼點擊這里下載,直接可以運行
專案簡介
近期收到CSDN上的小粉私信,說之前一篇文章Python爬取網站小說并可視化分析,那個網站比較的好,說想要這個網站的所有書籍,自己拿去好好地研讀,出于對粉絲的關心,再加上我個人也是比較喜歡文學作品的,無聊閑暇之余,看一本書陶冶一下自己的情操也不是不可的,哈哈哈,收到請求之后,我馬上就開始架構思路了,我通過觀察網頁結構發現了它的特點,最后我加上自己的設計思路,增加詞云分析這個功能,多次測驗,最終達到了一鍵化!!!!!!!
專案思路與功能介紹
1.用戶輸入該網站里面的任何一本書籍的網頁鏈接,輸入儲存路徑回車即可,后臺及運行爬蟲,之后再去運行智能分詞,最后利用強大的pyecharts庫,來展示詞云圖,
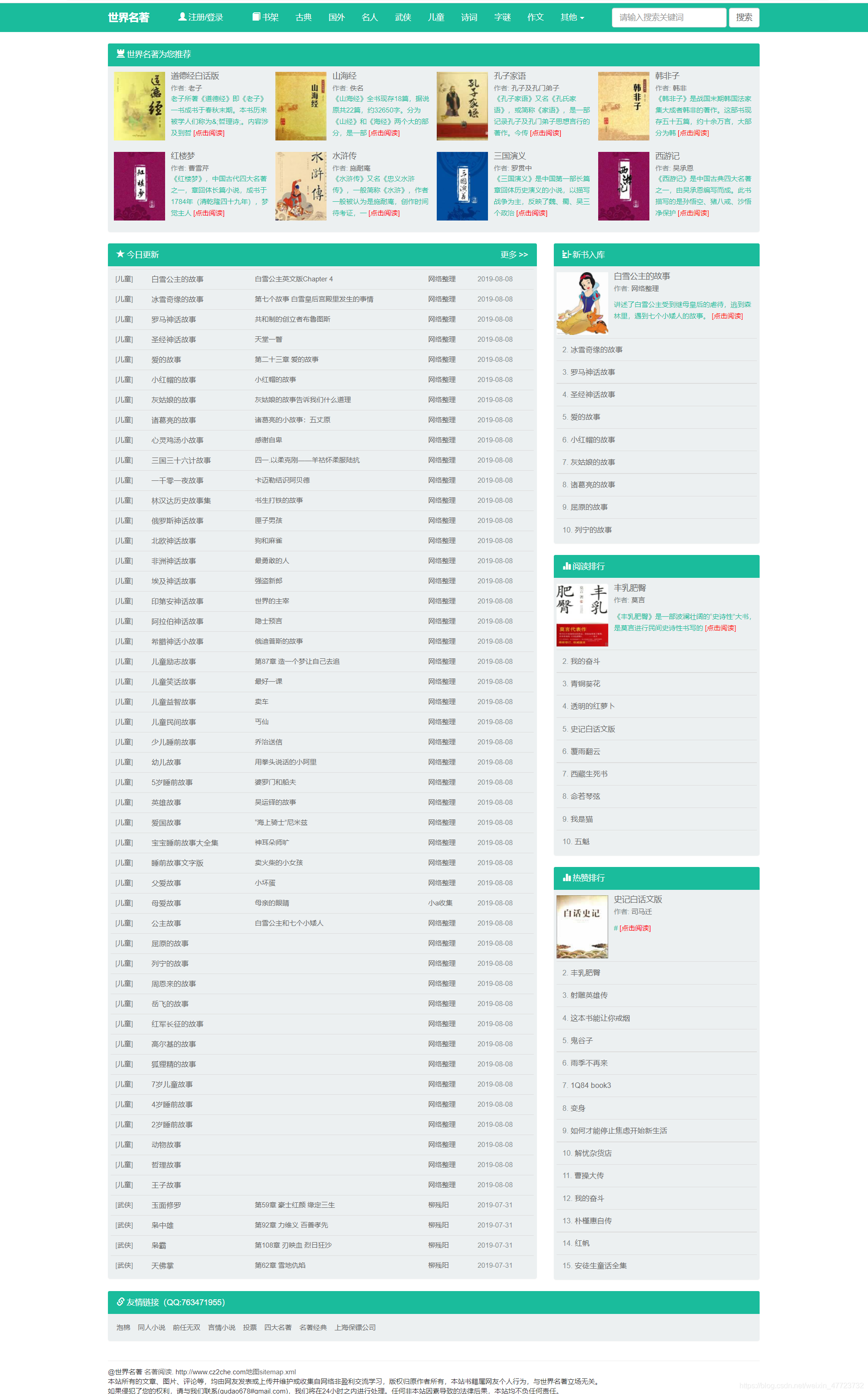
2.這么多的書籍,夠你看了吧,如果你不想看,想知道這本書主要講的是什么,出現哪些高頻詞,最終也會幫助你理解和了解這篇文章的主要內容,
3.本期專案依靠資料分析庫和Python原生態的庫,進行文本分詞,智能切割,智能詞云演算法和智能爬蟲演算法,有反爬技術的書寫,也有資料分析的亮點,
專案實作
1.首先你必須要安裝好這幾個庫
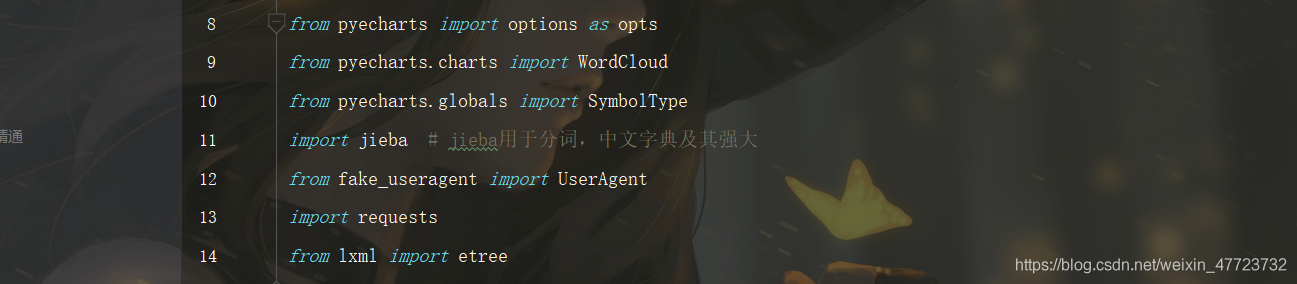
不會的請看這篇文章,有詳細的介紹,要是看不懂我給你安裝!絕對可以安裝好的~
2.實作爬蟲演算法
提前定義好全域變數
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
import jieba # jieba用于分詞,中文字典及其強大
from fake_useragent import UserAgent
import requests
from lxml import etree
import time
ll = []
lg = []
lk = []
lj = []
lp = []
li = []
d = {} # 定義好相應的存盤變數
def get_data(title,page,url,num):#title代表檔案路徑 page代表爬取的章節數 url為修訂后網址 num為標簽頁數
with open(r"{}.txt".format(title), "w", encoding="utf-8") as file:
ua = UserAgent() # 解決了我們平時自己設定偽裝頭的繁瑣,此庫自動為我們彈出一個可用的模擬瀏覽器
def get_page(url):
headers = {"User-Agent": ua.random}
res = requests.get(url=url, headers=headers)
res.encoding = 'GBK'
html = res.text
html_ = etree.HTML(html)
text = html_.xpath('//div[@class="panel-body content-body content-ext"]//text()')
num = len(text)
for s in range(num):
file.write(text[s] + '\n')
for i in range(page):
# time.sleep(2)
file.write("第{}章".format(i + 1))#寫入文本資料
get_page(url+"{}.html".format(num + i))#爬蟲標簽頁移動,資料輸出爬取程序
print("正在爬取第{}章!".format(i + 1))
print("爬取完畢!!!!")
3.實作智能分詞
我自己寫了一個智能詞云演算法,包括各種小功能的實作,設計不易,拒絕白嫖喲,有需要的可以私信我或者自己下載!!!
4.主函式
def main():
try:
print("\t\t本小程式只針對:<https://www.cz2che.com/>網址有效,里面有大量的古今中外名著小說!!!\n\n")
print("C:\\Users\\48125\\Desktop\\")
title = input("請輸入儲存文本的路徑及名稱如桌面:(C:\\Users\\48125\\Desktop\\文本)不需要加.txt!\n")
urll = str(input("請輸入您要爬取的網站(請將鍵盤游標移動到網址前面在回車!):"))
url = str(urll[:urll.rindex('/') + 1])
num = int(urll[urll.rindex('/') + 1:len(urll) - 5])
print(url,num)
page = int(input("請輸入本次您要爬取的章節數:\n"))
get_data(title,page,url,num)
Open(title)
print("\n分詞完畢!")
print('''\n\n\t\t一鍵詞云演算法生成器
\t0--退出詞云系統
\t1--生成一詞組的詞云圖
\t2--生成二詞組的詞云圖
\t3--生成三詞組的詞云圖
\t4--生成四詞組的詞云圖
\t5--生成大于1詞組的詞云圖(研究常用)
\t6--生成全部詞組的詞云圖(包含所有型別的詞組)
''')
num = int(input("請輸入本次展示的詞語數量(最好不超過100):"))
data = sort()[:num]
Str = input("請輸入這個詞云圖的標題:")
print("詞云圖已經生成完畢,請查收!")
print("感謝您對本程式的使用,歡迎下次光臨!!")
c = (
WordCloud()
.add(
"",
data, # 資料集
word_size_range=[20, 100], # 單詞字體大小范圍
shape=SymbolType.DIAMOND) # 詞云圖輪廓,有以下的輪廓選擇,但是對于這個版本的好像只有在提示里面選
# circl,cardioid,diamond,triangle-forward,triangle,start,pentagon
.set_global_opts(title_opts=opts.TitleOpts(title="{}".format(Str)),
toolbox_opts=opts.ToolboxOpts()) # 工具選項
.render("{}詞云制作{}詞組.html".format(title, choice))
)
return c
except:
print("無法找到,請檢查你的輸入!")
專案實作
1.輸入網址和保存路徑,以及爬取的章節數
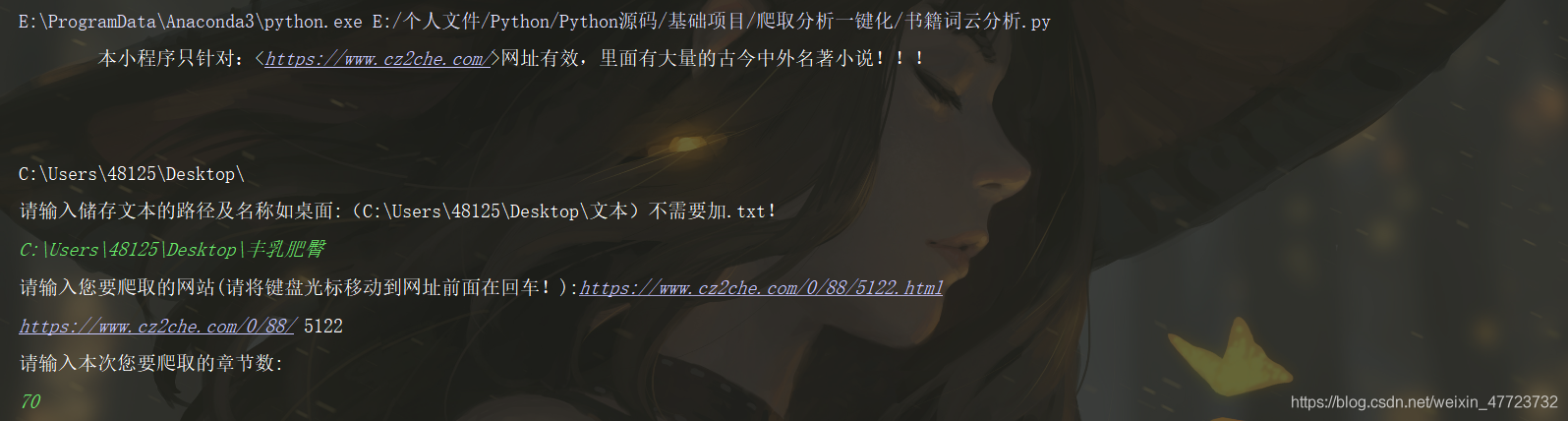 2.智能爬蟲開啟運行
2.智能爬蟲開啟運行


3.智能演算法開啟


4.效果展示
桌面自動出現,點擊網頁HTML即可展示詞云,還可以自己下載,這就是pyecharts庫的特點



看起來還不錯吧,我也覺得效果還可以,主要是這個一鍵化太讓我省心了,以后還可以做知網上面的,幫助科研人員做科研方面的研究,還有各個電商網站的評論,來解決老板對商品的評估,這樣的一鍵化可以幫助我們減少浪費的時間,當然老板也會喜歡的,
原始碼私信我!!!!設計著實不易!!!
專案拓展
我還自己設計另一個國家社科基金資料庫的詞云一鍵化分析
科研寶寶的最愛,有需要的可以直接私信我喲,把握好大家的研究方向才是開始最正確的選擇
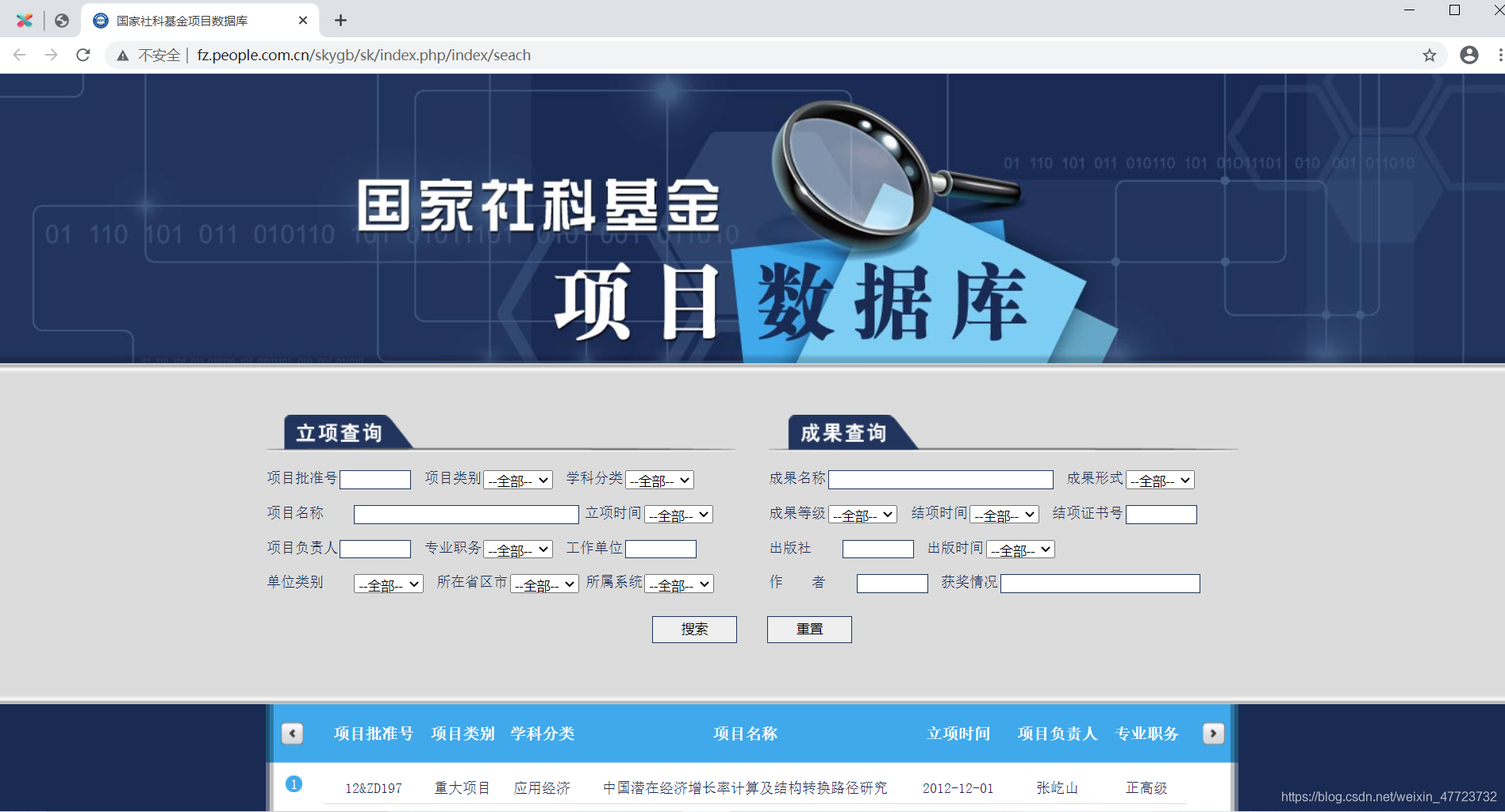 這個程式涉及到一個網頁解碼和轉碼的功能
這個程式涉及到一個網頁解碼和轉碼的功能




里面的輸入類別都可以自己設計的,所有的輸入框都可以自己設定篩選條件!!!!
如果你是科研黨,不要它可惜了,哈哈哈哈!!!!!!
每文一語
無法預測的未來,才會充滿期待
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/242421.html
標籤:其他