文章目錄
- 一、存盤系統分類
- 1.1 非結構化存盤
- 1.1.1 常見使用設備
- 1.2 半結構化存盤
- 1.3 結構化存盤
- 二、 ELK日志分析系統組成
- 2.3.1 ElasticSearch
- 2.3.2 Logstash和Filebeat
- 2.3.3 Kibana
- 三、ELK日志分析系統簡介
- 3.1Elasticsearch定義
- 3.2 Elasticsearch的用途
- 3.3ElasticSearch的原理
- 3.3.1 搜索引擎作業的程序
- 3.3.2 ElasticSearch 來源
- 3.3.3 ElasticSearch 基本概念
- 3.3.4 存盤ElasticSearch資料
- 3.4 ElasticSearch 分布式原理
- 3.4 ElasticSearch資料同步
- 3.5 Logstash
- 3.5.1 Logstash的簡介
- 3.5.1 Logstash的架構
- 3.5.1.1 Input輸入
- 3.5.1.2 filter過濾器
- 3.5.1.3 Output 輸出
- 3.5.1.3 Codecs 編解碼器
一、存盤系統分類
1.1 非結構化存盤
定義:指不定長或無固定格式的資料,如郵件,word檔案等
1.1.1 常見使用設備
①Block:需要磁區,格式化,不支持多個節點掛載使用,rbd(Ceph)
②Filesystem:NFS,HDFS(hadoop Filesystem),FastDFS(輕量級,適用于存盤圖片),輸出的API已經是檔案了,支持多個節點掛載使用
1.2 半結構化存盤
定義:非關系模型的、有基本固定結構模式的資料,例如日志檔案、XML檔案、JSON檔案、Email等
流派:
K/V存盤 :redis,TiKV(原生K/V存盤系統)
Document存盤:MongoDB,CahceDB,ElastcSearch:每個資料項自帶的欄位和值,可以后期添加欄位和值,還可以嵌套值,---> 檔案(Document)
Colume Family存盤:HBase (Hadoop Database)
GraphDB:圖式存盤:Neo4j
1.3 結構化存盤
定義:指具有固定格式或有限長度的資料,如資料庫,元資料等
特點:
① TiDB: 是一個分布式 NewSQL 資料庫,它支持水平彈性擴展、ACID 事務、標準 SQL、MySQL 語法和 MySQL 協議,具有資料強一致的高可用特性,是一個不僅適合 OLTP 場景還適OLAP 場景的混合資料庫
②shema要求嚴格
二、 ELK日志分析系統組成
2.3.1 ElasticSearch
ElasticSearch定義: Elasticsearch 是一個分布式、高擴展、高實時的搜索與資料分析引擎,
2.3.2 Logstash和Filebeat
Logstash定義: 集中、轉換和存盤資料
Filebeat定義: 輕量型日志采集器;從安全設備、云、容器、主機還是 OT 進行資料收集,Filebeat 都會提供一種輕量型方法,用于轉發和匯總日志與檔案
Filebeat是Beats中的一個組件,以下是Beats的介紹以及組件組件構成:
介紹: beats組件是一系列用于采集資料的輕量級代理程式,用于從服務端收集日志、網路、監控資料,并最侄訓總到elasticsearch,beats組件收集的資料即可以直接上報給elasticsearch,也可以通過logstash中轉處理后上報給elasticsearc,
beats根據功能劃分有多種組件:
PacketBeat:用于分析和收集服務器的網路包資料;
Heartbeat:主要是檢測服務或主機是否正常運行或存活,Heartbeat 能夠通過 ICMP、TCP 和 HTTP 進行 ping 檢測;
FileBeat:主要用于轉發和集中日志資料,Filebeat作為代理安裝在服務器上,監視您指定的日志檔案或位置,收集日志事件,并將它們轉發到ElasticSearch或Logstash進行索引;
MetricBeat:定期收集作業系統、軟體或服務的指標資料,支持收集的module非常多,常用的有docker、kafka、mysql、nginx、redis、zookeeper等等
Packetbeat:是一款輕量型網路資料包分析器,Packetbeat的作業原理是捕獲應用程式服務器之間的網路流量,解碼應用程式層協議(HTTP,MySQL,Redis等)
Auditbeat 允許您在 Linux、macOS 和 Windows 平臺上仔細監控任何您感興趣的檔案目錄,檔案改變會被實時發送到 Elasticsearch,每條訊息都包含元資料和檔案內容的加密哈希資訊,以便后續進一步分析;
Topbeat:搜集系統,行程和檔案系統級別的CPU和記憶體使用情況,已經被Metricbeat取代;
WinlogBeat:用于收集windows系統的event log;
2.3.3 Kibana
定義: Kibana 是為 Elasticsearch設計的開源分析和可視化平臺
三、ELK日志分析系統簡介
3.1Elasticsearch定義
Elasticsearch是一個分布式的開源搜索和分析引擎,適用于所有型別的資料,包括文本、數字、地理空間、結構化和非結構化資料,Elasticsearch在Apache Lucene的基礎上開發而成,由Elasticsearch N.V.(即現在的Elastic)于2010年首次發布,Elasticsearch以其簡單的REST風格API、分布式特性、速度和可擴展性而聞名,是Elastic Stack的核心組件; Elastic Stack 是適用于資料采集、充實、存盤、分析和可視化的一組開源工具,人們通常將Elastic Stack稱為ELK Stack(代指Elasticsearch、Logstash和Kibana),目前Elastic Stack 包括一系列豐富的輕量型資料采集代理,這些代理統稱為Beats,可用來向Elasticsearch 發送資料,
3.2 Elasticsearch的用途
Elasticsearch在速度和可擴展性方面都表現出色,而且還能夠索引多種型別的內容,這意味著其可用于多種用例:
應用程式搜索
網站搜索
企業搜索
日志處理和分析
基礎設施指標和容器監測
應用程式性能監測
地理空間資料分析和可視化
安全分析
業務分析
3.3ElasticSearch的原理
3.3.1 搜索引擎作業的程序
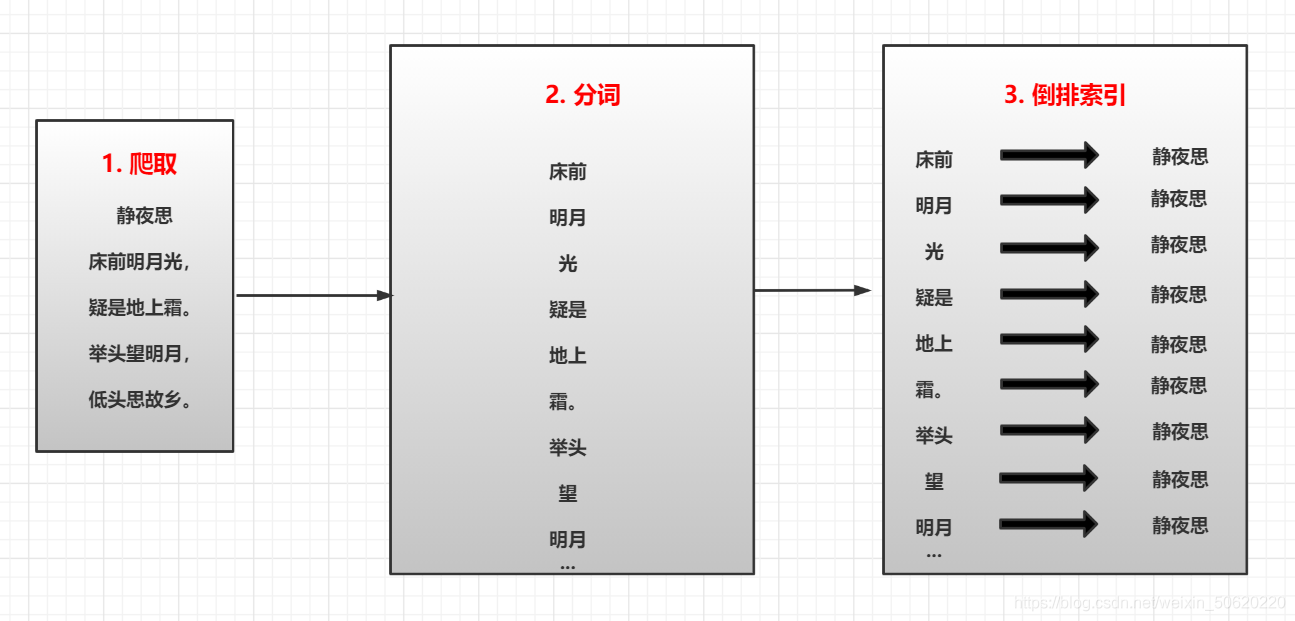
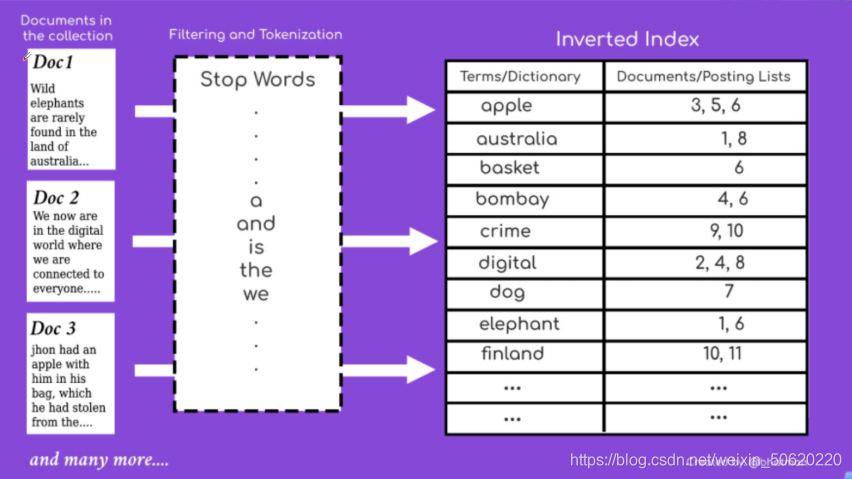
爬取內容、進行分詞、建立反向索引(倒排索引)
爬取內容:網頁爬取資料,所謂的爬蟲;
進行分詞:對爬取到資料進行切片;
🙄注意:資料中沒有意義的字,例如“的、而 、和…”,這些詞本身是沒有意義的,認為是停頓詞,所以這些詞沒必要建立索引的,
倒排索引:根據分詞搜索爬取的完整內容
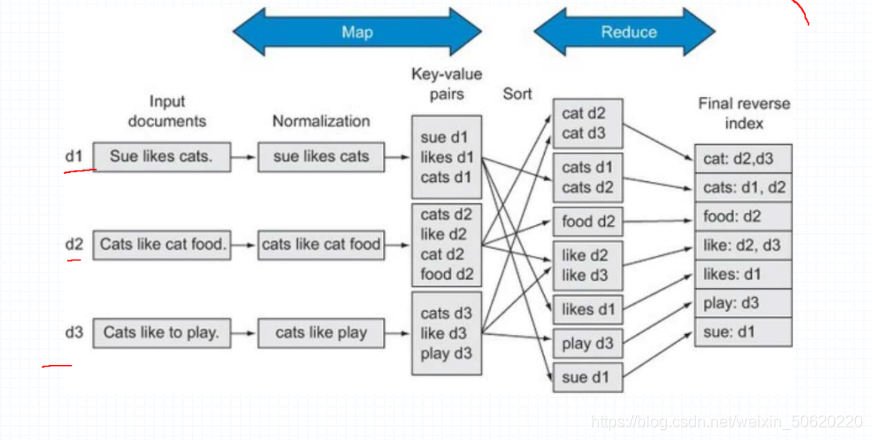 Map:映射
Map:映射
input document:讀入檔案
Noemalization:全部統一化(同義詞替換、統一大小寫…)
Reduce:折疊
Key-alue pairs:鍵值對:每個詞出現檔案的編號
final reverse index:倒排索引,資料縮減
3.3.2 ElasticSearch 來源
ElasticSearch的之前是一個叫做Lucene的庫,必要懂一些搜索引擎原理的人才會使用,所有有人基于Lucene進行封裝,就成了今天我們看到的ElasticSearch,
ElasticSearch對搜索引擎的操作都封裝成了restful的api,通過http的請求就能進行搜索操作,
#獲取指定主機上的test索引中_doc型別中的1檔案
curl -XGET '127.0.0.1:9200/test/_doc/1?pretty=true'
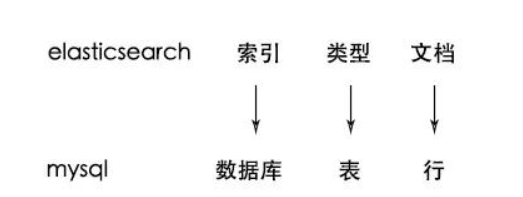
3.3.3 ElasticSearch 基本概念
索引、型別、檔案
為了方便理解與MySQL資料庫中的庫、表、行對應i起來
3.3.4 存盤ElasticSearch資料
比如一首詩,有詩題、作者、朝代、字數、詩內容等欄位,那么首先,我們可以建立一個名叫 Poems 的索引,然后創建一個名叫 Poem 的型別,型別是通過 Mapping 來定義每個欄位的型別,
比如詩題、作者、朝代都是 Keyword 型別,詩內容是 Text 型別,而字數是 Integer 型別,最后就是把資料組織成 Json 格式存放進去了,
索引
poems
型別
"poem": {
"properties": {
"title": {
"type":"keyword",
},
"author":{
"type": "keyword",
},
"dynasty": {
"type": "keyword"
},
"words": {
"type": "integer"
},
"content": {
"type": "text"
}
}
}
檔案
{
"title":"靜夜思",
"author":"李白",
"dynasty":"唐",
"words":"20",
"content":"床前明月光,疑是地上霜,舉頭望明月,低頭思故鄉,"
}
😶注意:keyword與text的區別
keyword 直接直接建立反向索引
test 先分詞 后建立反向索引
3.4 ElasticSearch 分布式原理
為了確保分布式環境的高可用,ElasticSearch也會對資料進行切分,同時會保存多個副本,
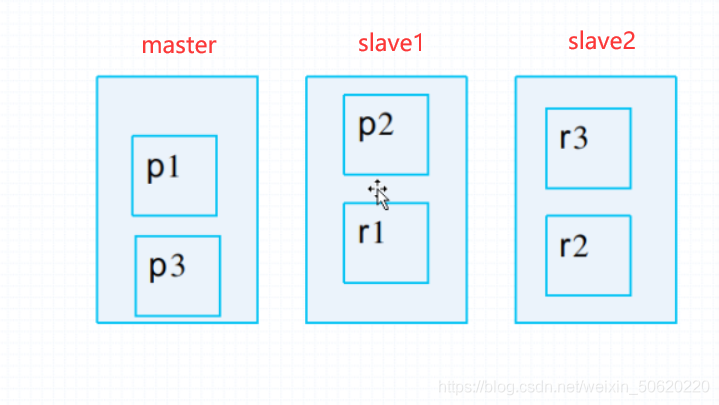
3.4 ElasticSearch資料同步
在 Elasticsearch 中,節點是對等的,節點間會通過自己的一些規則選取集群的 Master,Master 會負責集群狀態資訊的改變,并同步給其他節點
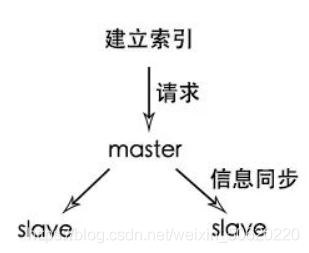
🙄注意:只有建立索引和型別需要經過 Master,資料的寫入有一個簡單的 Routing 規則,可以 Route 到集群中的任意節點,所以資料寫入壓力是分散在整個集群的,
ElasticSearch 總結:
- ElasticSearch 在Lucene的基礎上進行封裝,實作了分布式搜索引擎;
- ElasticSearch中資料存在索引、型別和檔案的概念,相當于MySQL中的資料庫、表、行;
- ElasticSearch 本身就是集群高可用應用,所以也存在master-slave架構,實作資料的分片和備份;
- ElasticSearch 的典型應用就是ELK的日志分析系統,
3.5 Logstash
3.5.1 Logstash的簡介
logstash是一個資料分析軟體,主要目的是分析log日志,整一套軟體可以當作一個MVC模型,logstash是controller層,Elasticsearch是一個model層,kibana是view層,首先將資料傳給logstash,它將資料進行過濾和格式化(轉成JSON格式),然后傳給Elasticsearch進行存盤、建搜索的索引,kibana提供前端的頁面再進行搜索和圖表可視化,它是呼叫Elasticsearch的介面回傳的資料進行可視化,
3.5.1 Logstash的架構
Logstash事件處理管道有三個階段:輸入(input)→過濾器(filter)→輸出(output),輸入生成事件,過濾器修改它們,然后輸出將它們發送到其他地方,輸入和輸出支持編解碼器,使你能夠在資料進入或離開管道時對其進行編碼或解碼,而無需使用單獨的過濾器,
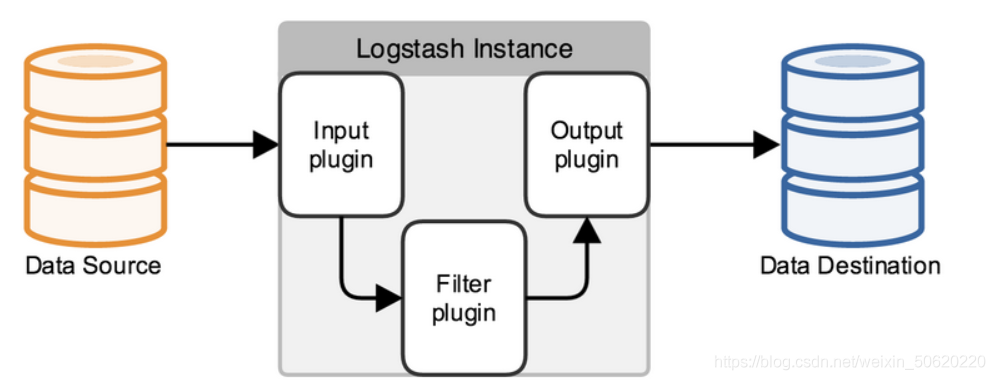
3.5.1.1 Input輸入
將資料收錄到Logstash中,一些比較常用的輸入是:
**- file:**從檔案系統上的檔案進行讀取,類似于UNIX命令tail -5f file.txt
- syslog: 在埠514上監聽syslog訊息并根據RFC3164格式進行決議
- redis: 從redis服務器讀取資料,同時使用Redis通道和Redis串列,Redis通常被用作集中式Logstash安裝中的“broker”,它將從遠程Logstash “shipper”中的Logstash事件排隊
- beats: 處理Beats發送的事件
- stdin: 模塊是用于標準輸入,就是從標準輸入讀取資料
范例:從標準輸入讀取資料
[10:15:42 root@localhost conf.d]#vim ./test4.conf
input {
stdin {
add_field => {"key" => "value"}
codec => "plain"
tags => ["add"]
type => "std"
}
}
output {
stdout {
codec => rubydebug
}
}
[10:16:28 root@localhost conf.d]#/usr/share/logstash/bin/logstash -f ./test4.conf
lulu #手動輸入
{
"host" => "localhost.localdomain",
"@timestamp" => 2020-12-31T02:19:18.620Z,
"type" => "std",
"key" => "value",
"tags" => [
[0] "add"
],
"message" => "lulu",
"@version" => "1"
}
3.5.1.2 filter過濾器
過濾器是Logstash管道中的中間處理設備,如果事件過濾器的條件,你可以將過濾器與條件陳述句組合在一起,對其執行操作,一些常用的過濾器包括:
- grok: 決議和構造任意文本,Grok是目前Logstash中決議非結構化日志資料到結構化和可查詢資料的最佳方式,內置有120種模式
- mutate: 對事件欄位執行一般的轉換,你可以重命名、洗掉、替換和修改事件中的欄位
- drop: 完全洗掉事件,例如debug事件
- clone: 復制事件,可能添加或洗掉欄位
- geoip: 添加關于IP地址地理位置的資訊
范例:GeoIP插件
GeoIP 是最常見的免費 IP 地址歸類查詢庫,同時也有收費版可以采購,GeoIP 庫可以根據 IP 地址提供對應的地域資訊,包括國別,省市,經緯度等,對于可視化地圖和區域統計
[20:59:10 root@localhost ~]#cd /etc/logstash/conf.d/
[20:59:29 root@localhost conf.d]#cat test3.conf
input {
stdin {
type => "std"
}
}
filter {
geoip {
source => "message"
}
}
output{stdout{codec=>rubydebug}}
[21:08:52 root@localhost ~]#/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test3.conf
183.60.92.253 #手動輸入IP地址進行分析
{
"geoip" => {
"country_name" => "China",
"location" => {
"lon" => 113.25,
"lat" => 23.1167
},
"country_code2" => "CN",
"country_code3" => "CN",
"latitude" => 23.1167, #緯度
"ip" => "183.60.92.253",
"continent_code" => "AS",
"region_name" => "Guangdong",
"region_code" => "GD",
"longitude" => 113.25, #經度
"timezone" => "Asia/Shanghai"
},
"host" => "localhost.localdomain",
"@version" => "1",
"type" => "std",
"message" => "183.60.92.253",
"@timestamp" => 2020-12-30T13:06:41.614Z
}
范例:grok插件
#logstach中自帶grok插件
logstash擁有豐富的filter插件,它們擴展了進入過濾器的原始資料,進行復雜的邏輯處理,甚至可以無中生有的添加新的 logstash 事件到后續的流程中去!Grok 是 Logstash 最重要的插件之一,也是迄今為止使蹩腳的、無結構的日志結構化和可查詢的最好方式,Grok在決議 syslog logs、apache and other webserver logs、mysql logs等任意格式的檔案上表現完美,
[19:40:42 root@localhost ~]#cd /etc/logstash/conf.d/
#在test2.conf中插入grok插件
[19:41:25 root@localhost conf.d]#vim test2.conf
input {
stdin {}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}
}
remove_field => "message" #移除message欄位資訊
}
}
output {
stdout {
codec => rubydebug
}
}
[19:49:03 root@localhost conf.d]#/usr/share/logstash/bin/logstash -f ./test2.conf
10.0.0.18 - - [29/Dec/2020:17:47:56 +0800] "GET /test1.html HTTP/1.1" 200 11 "-" "curl/7.61.1" "-" #手動輸入nginx訪問資訊,因為該檔案加入了grok插件,所以將每個欄位詳細分解
{
"timestamp" => "29/Dec/2020:17:47:56 +0800",
"agent" => "\"curl/7.61.1\"",
"bytes" => "11",
"auth" => "-",
"clientip" => "10.0.0.18",
"host" => "localhost.localdomain",
"verb" => "GET",
"@timestamp" => 2020-12-29T11:50:18.000Z,
"httpversion" => "1.1",
"@version" => "1",
"ident" => "-",
"response" => "200",
"referrer" => "\"-\"",
"request" => "/test1.html"
}
3.5.1.3 Output 輸出
輸出是Logstash管道的最后階段,事件可以通過多種方式輸出,一旦所有的輸出處理完成,事件就結束了,
- elasticsearch: 發送事件資料到Elasticsearch,如果你打算以一種高效、方便、易于查詢的格式保存資料,那么使用Elasticsearch是可行的,
- file: 將事件資料寫入磁盤上的檔案
- graphite: 將事件資料發送到graphite,這是一種流行的用于存盤和繪制指標的開源工具,
- statsd: 發送事件到statsd,“監聽統計資訊(如計數器和計時器)、通過UDP發送聚合并將聚合發送到一個或多個可插拔后端服務”的服務
- stdout: 標準輸出
范例:將日志統一收集到指定檔案種
[10:37:13 root@localhost ~]#cat /etc/logstash/conf.d/test6.conf
input {
stdin{
type => "std"
}
}
output {
file {
path => "/tmp/%{+yyyy}-%{+MM}-%{+dd}-%{host}.log"
codec => line{format => "%{message}"}
}
}
[10:40:20 root@localhost conf.d]#/usr/share/logstash/bin/logstash -f ./test6.conf
...
i love linux #手動輸入
[INFO ] 2020-12-31 10:38:35.822 [[main]>worker0] file - Closing file /tmp/2020-12-31-localhost.localdomain.log #手動輸入的內容收集到 /tmp/2020-12-31-localhost.localdomain.log 檔案中
#日志檔案內容驗證
[10:38:37 root@localhost ~]#cat /tmp/2020-12-31-localhost.localdomain.log
i love linux
3.5.1.3 Codecs 編解碼器
Codecs可以作為輸入或輸出的一部分進行操作,Codecs使用戶能夠輕松地將訊息的傳輸與序列化程序分開, 形成input | decode | filter | encode | output 的資料流,流行的codecs包括json、msgpack和plain(text)
范例:
默認情況下,logstash只支持純文本形式的輸入,然后在過濾器filter種將資料加工成指定格式,現在可以在input指定資料型別,全部是因為有了codecs的設定,
[10:07:54 root@localhost ~]#cat /etc/logstash/conf.d/test4.conf
input {
stdin {
add_field => {"key" => "value" }
codec => "json"
type => "std"
}
}
output {
stdout {
codec => rubydebug
}
}
[09:54:45 root@localhost ~]#/usr/share/logstash/bin/logstash -f
...
/etc/logstash/conf.d/test4.conf
{"name":"lulu"} #手動輸入json格式的鍵值對
{
"name" => "lulu",
"host" => "localhost.localdomain",
"@timestamp" => 2020-12-31T02:06:20.998Z,
"key" => "value",
"@version" => "1",
"type" => "std"
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/242859.html
標籤:其他