作者:小小明
大家好,我是小小明,今天我要給大家分享一個我自己用VBA撰寫的神器,讓你的Excel能夠直接支持正則,
Pandas里支持正則替換比較舒服,但是Excel卻沒有一個可以支持正則的函式,但是借助VBA我們就可以在Excel實作正則的抽取、搜索和替換,
先看看效果吧:
正則抽取
對于一列資料:
中樓層(共9層)|2007年建|1室1廳|24.78平米|北
地下室|2014年建|1室0廳|39.52平米|東
底層(共2層)5室3廳|326.56平米|東南西北
我們想提取出其中的 層、樓層數、建筑年份、戶型、大小和方向,我們可以選中一排的六個單元格,然后輸入公式:
=re_extract(A1,"([^|(]+)(?:\(共(\d+)層\))?(?:\|(\d{4})年建\|)?(\d室\d廳)\|([\d.]+)平米\|([東南西北]+)")
然后按下Ctrl+shift+Enter(表示陣列公式),即可得到如下結果:
中樓層 9 2007 1室1廳 24.78 北
地下室 0 2014 1室0廳 39.52 東
底層 2 0 5室3廳 326.56 東南西北
效果如下:

?:表示當前括號內部是非捕獲組,
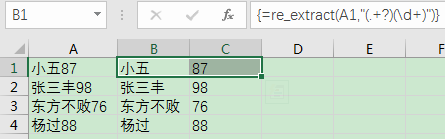
再看一個簡單的例子,對于一列資料:
小五87
張三豐98
東方不敗76
楊過88
我們想將姓名和成績分開,可以選中一排的二個單元格,然后輸入公式:
=re_extract(A1,"(.+?)(\d+)")
然后按下Ctrl+shift+Enter(表示陣列公式),即可得到如下結果,
效果:
正則搜索
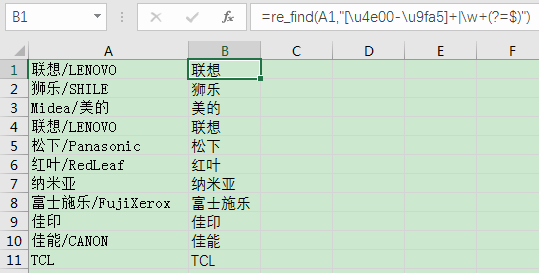
對于一列資料:
聯想/LENOVO
獅樂/SHILE
Midea/美的
聯想/LENOVO
松下/Panasonic
紅葉/RedLeaf
納米亞
富士施樂/FujiXerox
佳印
佳能/CANON
TCL
我們想提取其中的中文品牌,對于沒有中文的才用英文,可以輸入公式:
=re_find(A1,"[\u4e00-\u9fa5]+|^\w+$")
最終結果:
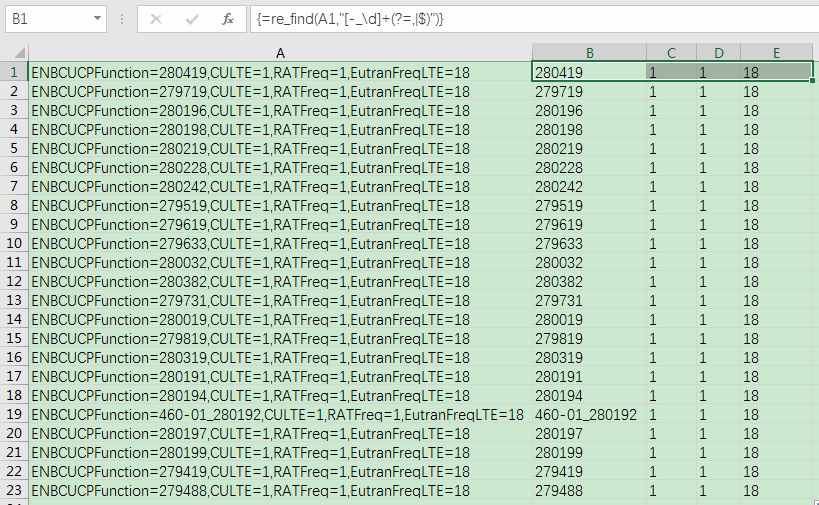
當然正則搜索也支持陣列公式,再看一個例子,對于下面一列資料:
ENBCUCPFunction=280419,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279719,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280196,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280198,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280219,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280228,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280242,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279519,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279619,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279633,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280032,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280382,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279731,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280019,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279819,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280319,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280191,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280194,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=460-01_280192,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280197,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280199,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279419,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279488,CULTE=1,RATFreq=1,EutranFreqLTE=18
我們需要取出所有的ENBCUCPFunction/CULTE/RATFreq/EutranFreqLTE四個欄位對應的值,可以選中一排的四個單元格,然后輸入公式:
=re_find(A1,"[-_\d]+")
即可得到結果:
280419 1 1 18
279719 1 1 18
280196 1 1 18
280198 1 1 18
280219 1 1 18
280228 1 1 18
280242 1 1 18
279519 1 1 18
279619 1 1 18
279633 1 1 18
280032 1 1 18
280382 1 1 18
279731 1 1 18
280019 1 1 18
279819 1 1 18
280319 1 1 18
280191 1 1 18
280194 1 1 18
460-01_280192 1 1 18
280197 1 1 18
280199 1 1 18
279419 1 1 18
279488 1 1 18
效果:
正則替換
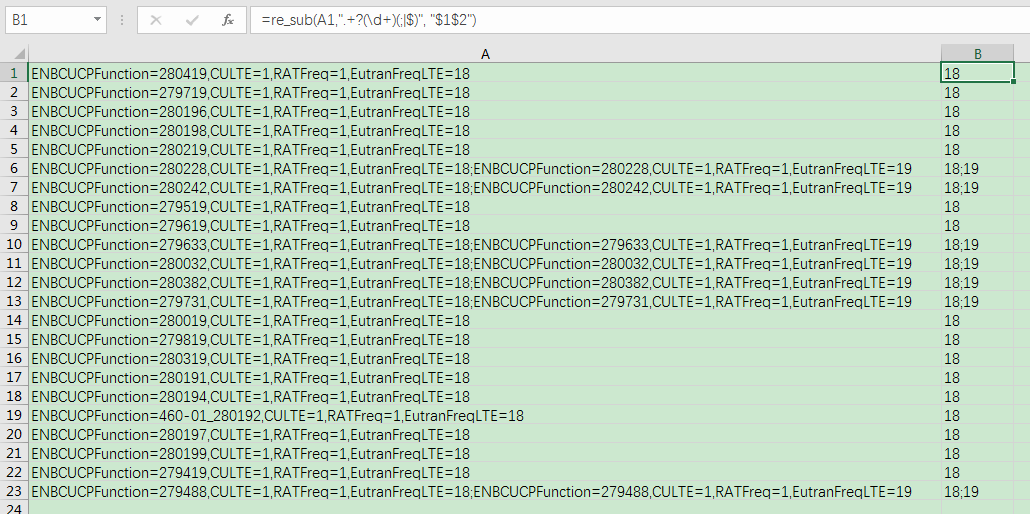
對于下面這列資料,我們希望僅保留EutranFreqLTE對應的值,多個值用;拼接:
ENBCUCPFunction=280419,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279719,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280196,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280198,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280219,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280228,CULTE=1,RATFreq=1,EutranFreqLTE=18;ENBCUCPFunction=280228,CULTE=1,RATFreq=1,EutranFreqLTE=19
ENBCUCPFunction=280242,CULTE=1,RATFreq=1,EutranFreqLTE=18;ENBCUCPFunction=280242,CULTE=1,RATFreq=1,EutranFreqLTE=19
ENBCUCPFunction=279519,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279619,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279633,CULTE=1,RATFreq=1,EutranFreqLTE=18;ENBCUCPFunction=279633,CULTE=1,RATFreq=1,EutranFreqLTE=19
ENBCUCPFunction=280032,CULTE=1,RATFreq=1,EutranFreqLTE=18;ENBCUCPFunction=280032,CULTE=1,RATFreq=1,EutranFreqLTE=19
ENBCUCPFunction=280382,CULTE=1,RATFreq=1,EutranFreqLTE=18;ENBCUCPFunction=280382,CULTE=1,RATFreq=1,EutranFreqLTE=19
ENBCUCPFunction=279731,CULTE=1,RATFreq=1,EutranFreqLTE=18;ENBCUCPFunction=279731,CULTE=1,RATFreq=1,EutranFreqLTE=19
ENBCUCPFunction=280019,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279819,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280319,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280191,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280194,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=460-01_280192,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280197,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=280199,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279419,CULTE=1,RATFreq=1,EutranFreqLTE=18
ENBCUCPFunction=279488,CULTE=1,RATFreq=1,EutranFreqLTE=18;ENBCUCPFunction=279488,CULTE=1,RATFreq=1,EutranFreqLTE=19
可以輸入公式:
=re_sub(A1,".+?(\d+)(;|$)", "$1$2")
得到結果:
18
18
18
18
18
18;19
18;19
18
18
18;19
18;19
18;19
18;19
18
18
18
18
18
18
18
18
18
18;19
效果:
再舉個例子,對于下面這列資料,想去掉所有的非中文字符和被括號括起來的字符:
中山-Z-古鎮華藝集團路口-280308-1-2-OF
中山-ZD-古鎮華藝集團路口-280308-2-1-OF
中山-Z-古鎮華藝集團路口-280308-2-2-OF
中山-ZD-橫欄富橫東路-280227-1-1-OF
中山-Z-橫欄富橫東路-280227-1-2-OF
中山-ZD-橫欄富橫東路-280227-2-1-OF
中山-Z-橫欄富橫東路-280227-2-2-OF
中山-ZD-橫欄富橫東路-280227-3-1-OF
中山-Z-橫欄富橫東路-280227-3-2-OF
中山-Z-三角電信營業廳(室分QCELL)-278903-1-1-MF
中山-Z-三角高平營業廳(室分QCELL)-278902-1-1-MF
中山-ZD-橫欄中藝重工-280009-1-1-OF
中山-ZD-橫欄中藝重工-280009-2-1-OF
中山-ZD-橫欄中藝重工-280009-3-1-OF
中山-Z-橫欄三沙商富路-279966-1-2-OF
中山-ZD-橫欄三沙商富路-279966-1-1-OF
中山-ZD-橫欄新豐物流-279974-1-1-OF
黃圃奧杰斯電器LTGX_3_F
輸入一下公式:
=re_sub(A1,"[A-Z0-9_\-]+|\(.*\)", "")
即可得到:
中山古鎮華藝集團路口
中山古鎮華藝集團路口
中山古鎮華藝集團路口
中山橫欄富橫東路
中山橫欄富橫東路
中山橫欄富橫東路
中山橫欄富橫東路
中山橫欄富橫東路
中山橫欄富橫東路
中山三角電信營業廳
中山三角高平營業廳
中山橫欄中藝重工
中山橫欄中藝重工
中山橫欄中藝重工
中山橫欄三沙商富路
中山橫欄三沙商富路
中山橫欄新豐物流
黃圃奧杰斯電器
效果:
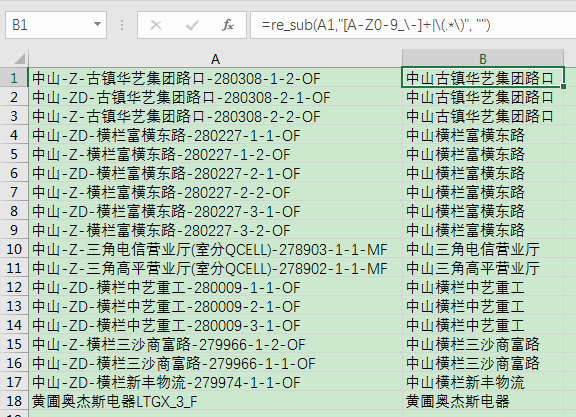
用VBA實作上面三個函式并讓其自動加載
好了,演示完效果,我們現在來看看如何開發這三個函式吧,
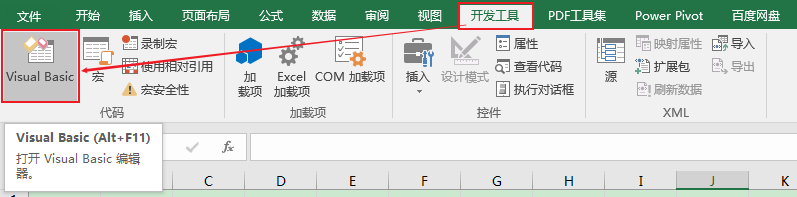
首先打開excel軟體,點擊開發工具->Visual Basic(或者直接按快捷鍵Alt+F11),打開VBA的編輯器:
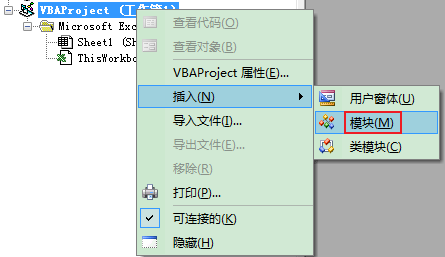
右鍵單擊當前作業薄物件插入模塊:
在模塊中插入以下代碼:
Option Explicit
Public Function re_sub(sText As String, pattern As String, repl As String)
Dim oRegExp As Object
Set oRegExp = CreateObject("vbscript.regexp")
With oRegExp
.Global = True 'True表示匹配所有, False表示僅匹配第一個符合項
.IgnoreCase = False '區分大小寫
.pattern = pattern
re_sub = .Replace(sText, repl)
End With
End Function
Public Function re_find(sText As String, pattern As String)
Dim oRegExp As Object, match As Object, matches As Object
Set oRegExp = CreateObject("vbscript.regexp")
With oRegExp
.Global = True 'True表示匹配所有, False表示僅匹配第一個符合項
.IgnoreCase = True '不區分大小寫
.pattern = pattern
Set matches = .Execute(sText)
End With
Dim d As Object
Set d = CreateObject("Scripting.Dictionary")
For Each match In matches
d.Add match, Null
Next
re_find = d.keys
End Function
Public Function re_extract(sText As String, pattern As String)
Dim oRegExp As Object, match As Object, matches As Object, i As Integer
Set oRegExp = CreateObject("vbscript.regexp")
With oRegExp
.Global = True 'True表示匹配所有, False表示僅匹配第一個符合項
.IgnoreCase = True '不區分大小寫
.pattern = pattern
Set matches = .Execute(sText)(0).submatches
End With
Dim d As Object
Set d = CreateObject("Scripting.Dictionary")
For i = 0 To matches.Count - 1
d.Add matches(i), Null
Next
re_extract = d.keys
End Function
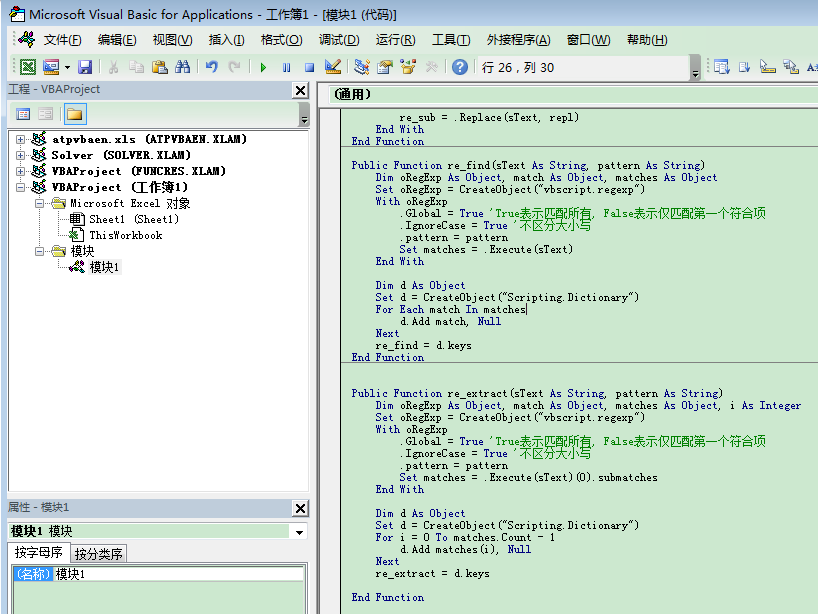
然后按下Ctrl+S保存:
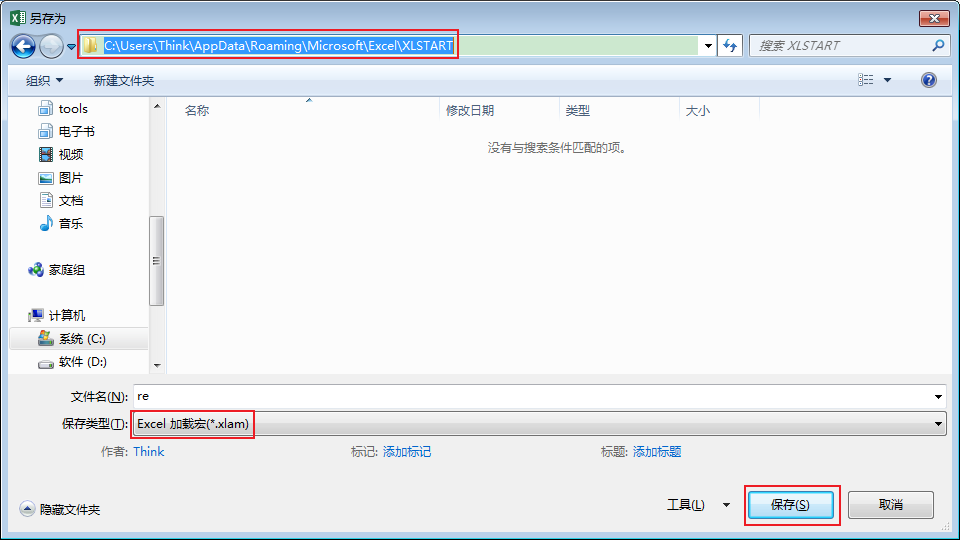
保存在個人宏作業簿:
C:\Users\{userName}\AppData\Roaming\Microsoft\Excel\XLSTART\
對于家庭和學生版2016,個人宏作業簿在:
C:\Users\{userName}\AppData\Local\Packages\Microsoft.Office.Desktop_8wekyb3d8bbwe\LocalCache\Roaming\Microsoft\Excel\XLSTART
{userName}表示你當前的用戶名,
格式為xlam,檔案名無所謂,
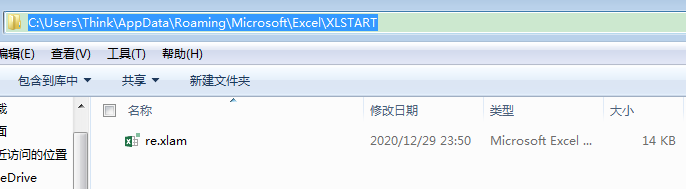
然后在這個電腦的任何時候,任何地方打開excel軟體都可以直接使用上面開發好的正則處理函式了!
正則高級語法相關資料
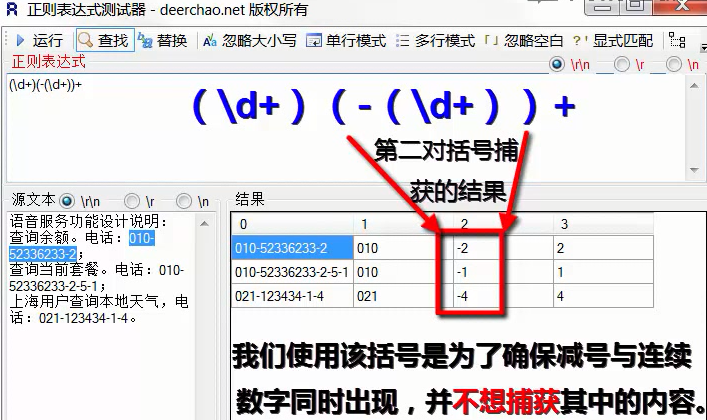
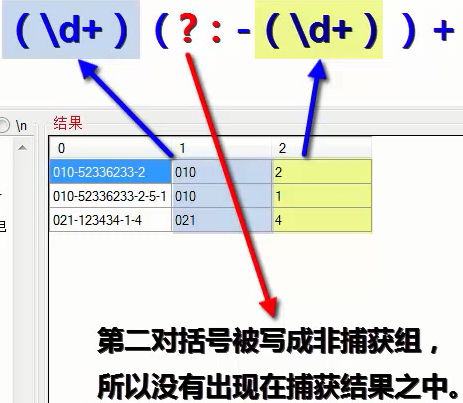
非捕獲組
功能:讓某個圓括號只用于分組,而不捕獲其中的內容,
方法:將(內容)改為(?:內容)
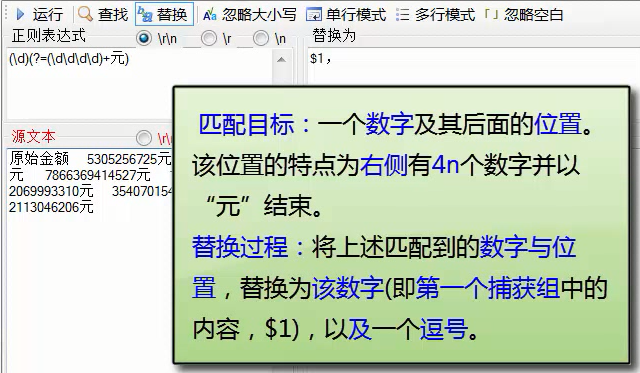
環視
(?=abc)是正則中表示位置的語法,用于表示一個位置,表示當前位置的右邊必須是abc字符而不會匹配abc本身,

獲取捕獲組
完結,撒花!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/242952.html
標籤:其他