千萬級流量框架設計
一:網站峰值QPS計算公式
峰值QPS=(日總PV數*80%)/(日總秒殺*20%)
即:一天中80%的流量集中在20%的時間內發生,
例如:pv=10000000;
則峰值QPS=(10000000*0.8)/(24*3600*0.2)=463.
理論上:如果一臺服務器每秒能處理100個請求,那日pv千萬的流量也只需要分布式5臺服務器就能抗住,
二:核心的架構策略
架構演進的程序:單機混沌狀態--各自獨立--集群化--分布式--多集群部署--異地部署
集群:多個人干活,每個人干的活都一樣,例如:三個廚師都需要干洗菜切菜炒菜的活,
分布式:把活拆開一組人去做,大家協同完成,例如:一個人洗菜一個人切菜一個人燒菜,
核心:拆分--佇列--快取--降級--限流
2.1:拆分
拆分維度:系統維度,功能維度和讀寫維度,
系統維度:商品系統,購物車系統,訂單系統,優惠券系統,
功能維度:例如優惠券系統,可以拆分為建券服務,領券服務和用券服務,
讀寫維度:讀的量非常大,比寫的多的多,
2.2:佇列
核心:異步,平緩的處理
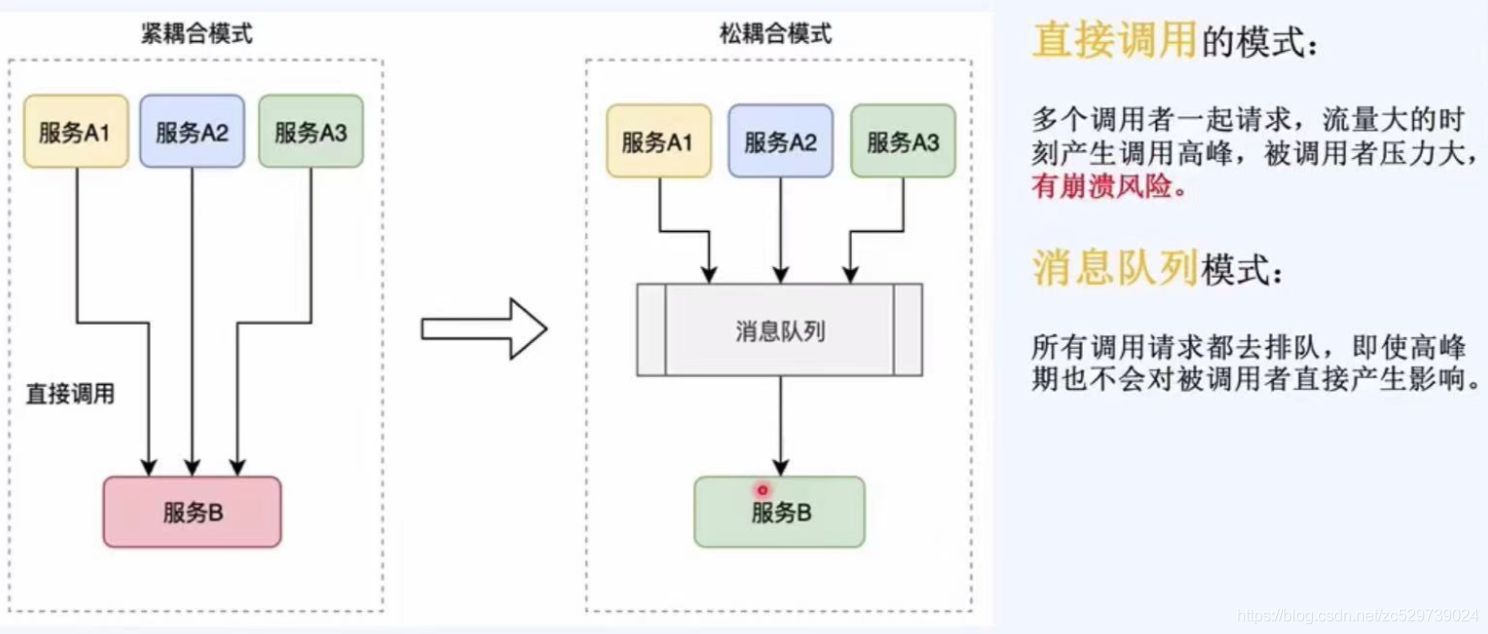
2.2.1:佇列案例1--流量削峰
流量削峰的由來:瞬間流量巨大,例如幾萬人搶購100件商品,就像洪水涌入,
流量削峰的目的:讓服務處理請求更佳平緩,波阿虎服務器資源,
直接呼叫模式:多個呼叫者一起請求,流量大的時候產生呼叫高峰,被呼叫者壓力大,有崩潰風險,
訊息佇列模式:所有呼叫請求都去排隊,即使高峰期也不會對被呼叫者直接產生影響,
流量大的情況下核心轉變思想:轉變為異步的佇列處理模式,
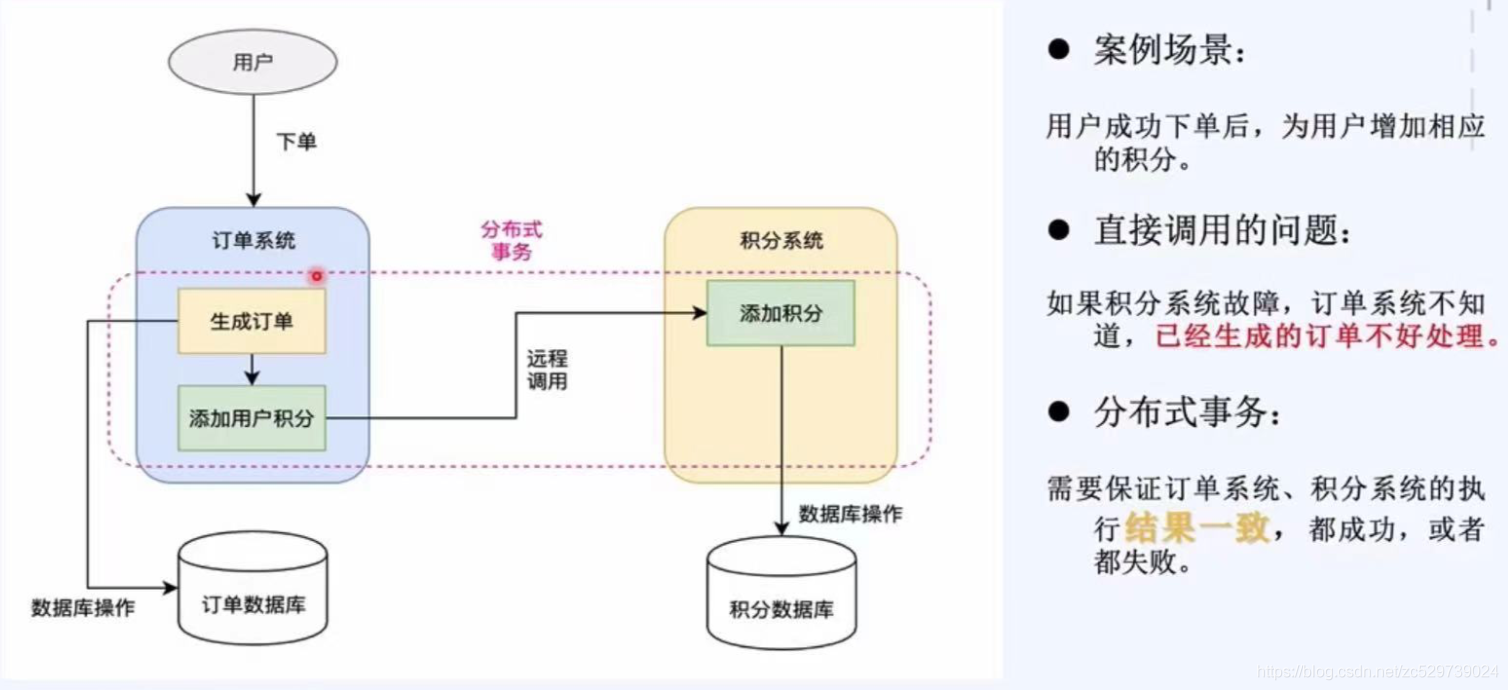
2.2.2:佇列案例2--分布式事務(可靠訊息模式)
案例場景:用戶成功下單后,為用戶增加相應的積分,
直接呼叫的問題:如果積分系統故障,訂單系統不知道,已經生成的訂單不好處理,
分布式事務:需要保證訂單系統,積分系統的執行結果一致,都成功,或者都失敗,
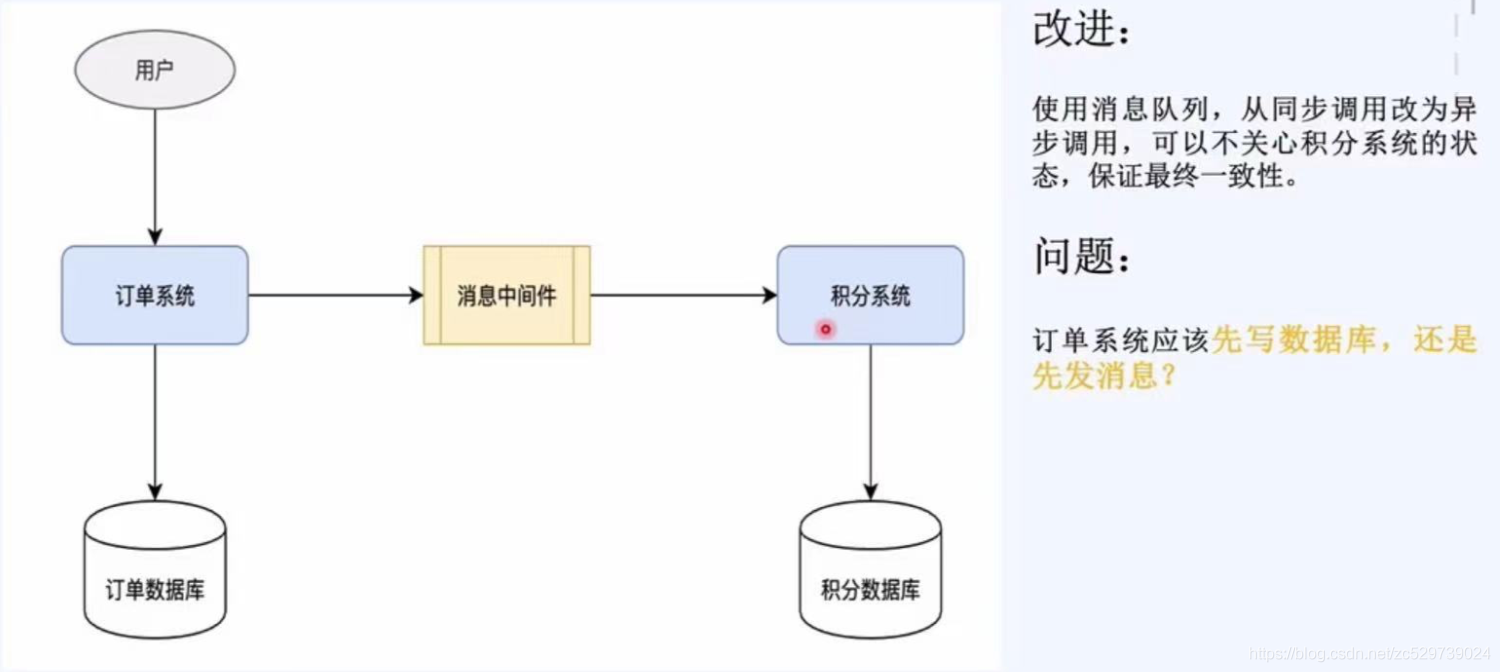
改進:
使用訊息佇列,從同步呼叫改為異步呼叫,可以不關心積分系統的狀態,保證最終一致性,
問題:訂單系統應該是先寫資料庫還是先發訊息?
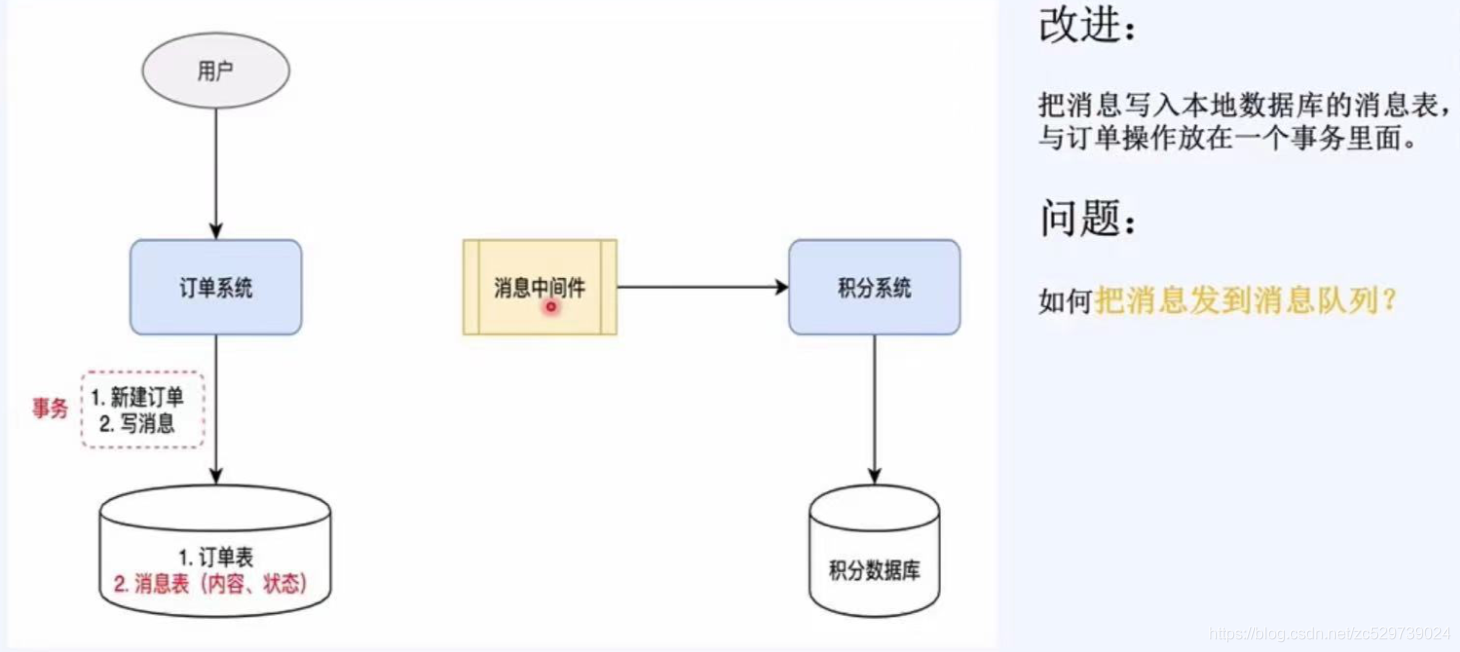
改進:
將寫訊息和創建訂單放在同一個事務中,把訊息寫入本地資料庫的“訊息表”中,這樣保證了創建訂單和創建訊息的一致性,
問題:如何把訊息發送到訊息佇列?
改進:
通過一個后臺程式“定時任務”去發送訊息,并修改“訊息表”中的資料狀態,
問題:訊息會不會重發?訊息重發了怎么辦?(此時需要積分系統負責保證冪等性)
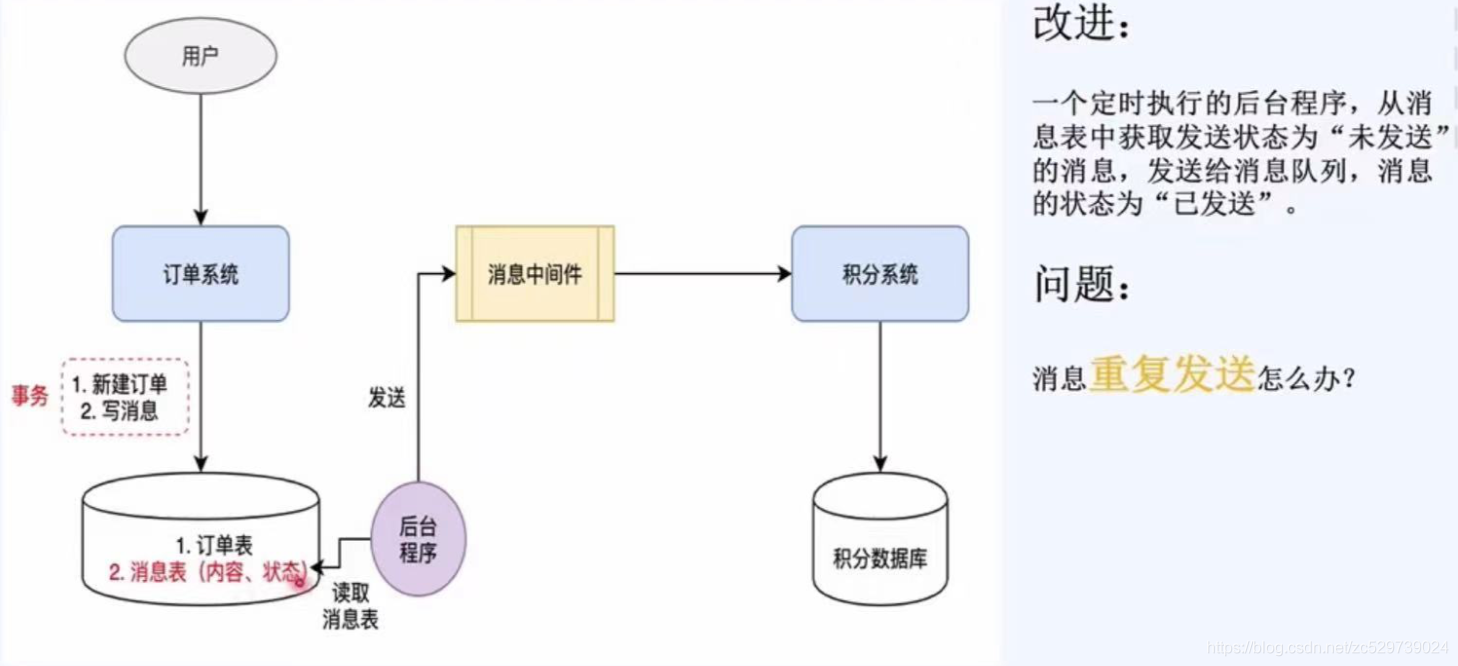 改進(最終方案):
改進(最終方案):
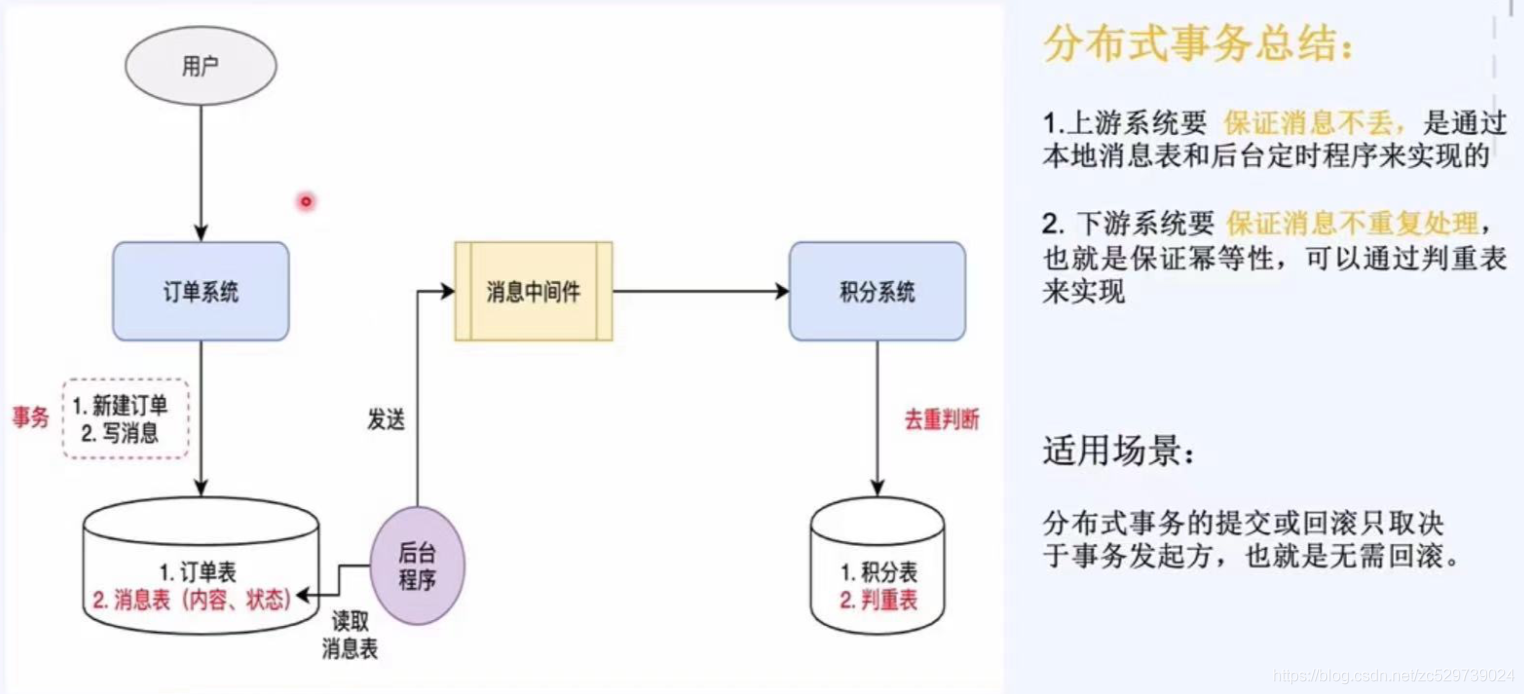
1:上游(訂單)系統要保證資訊不丟,是通過本地訊息表和后臺定時程式來實作的,
2:下游(積分)系統要保證訊息不重復處理,也就是保證冪等性,可以通過判重表來實作,
(冪等:多次呼叫同一請求同一引數的處理的結果一樣)
適用場景:
分布式事務的提交或者回滾只取決于事務的發起方,也就是無需回滾,
2.3:快取
型別:
客戶端快取:瀏覽器/app客戶端
網路快取:CDN
接入層快取:NGINX代理快取,
應用層快取:redis,
快取的讀寫策略:
Cache Aside策略 and Read/Write Through策略:
先更新快取,還是先更新資料庫?
假設先更新資料庫:
現象:A先更新資料庫,由于網路等原因在還沒有更新快取成功的同時,B已經更新了資料庫和快取,此時A再更新快取,就導致資料庫和快取中的資料不一致, 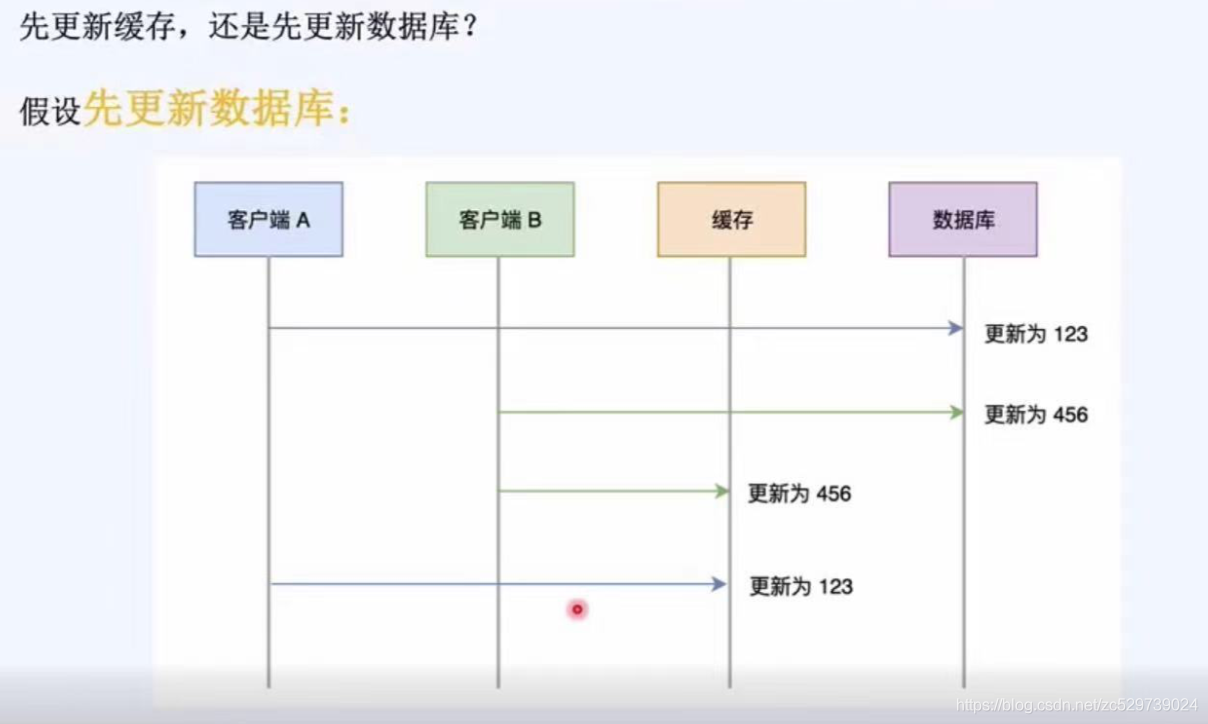
假設先更新快取:
現象:如果先更新快取,再更新資料庫,可能失敗回滾,導致資料庫和快取中的也不一致, 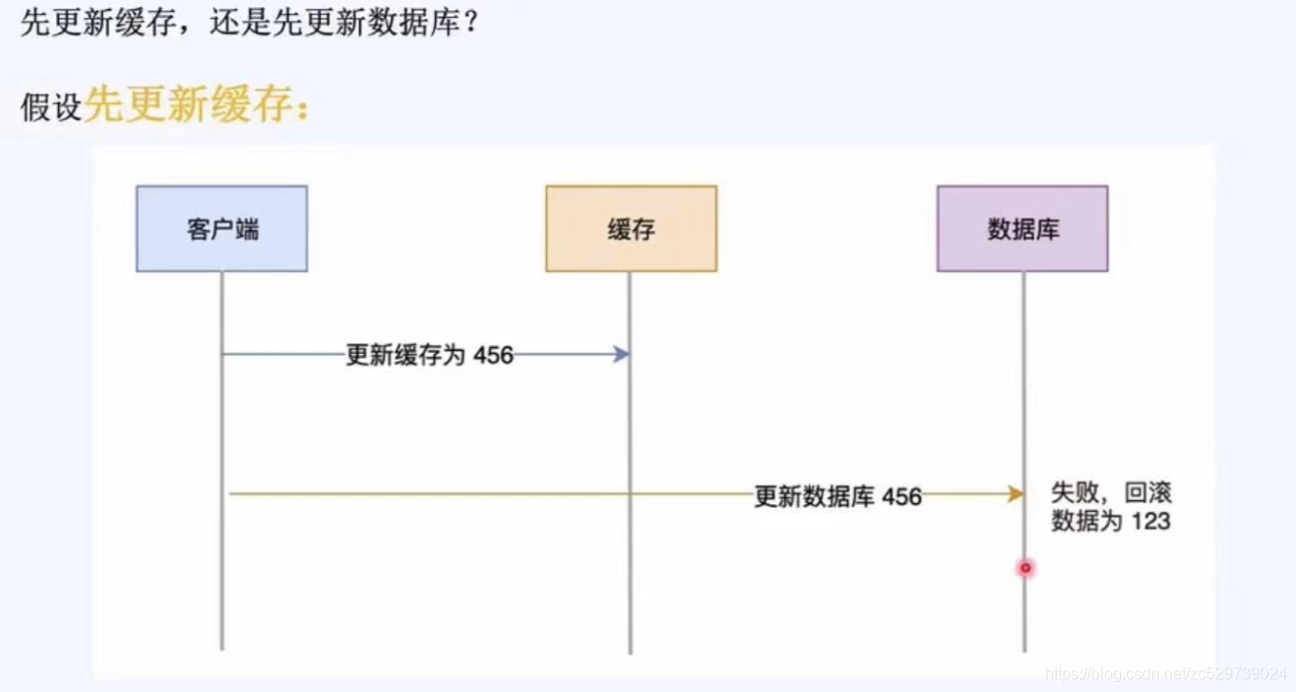
所以,綜上所述先更新誰都不妥,
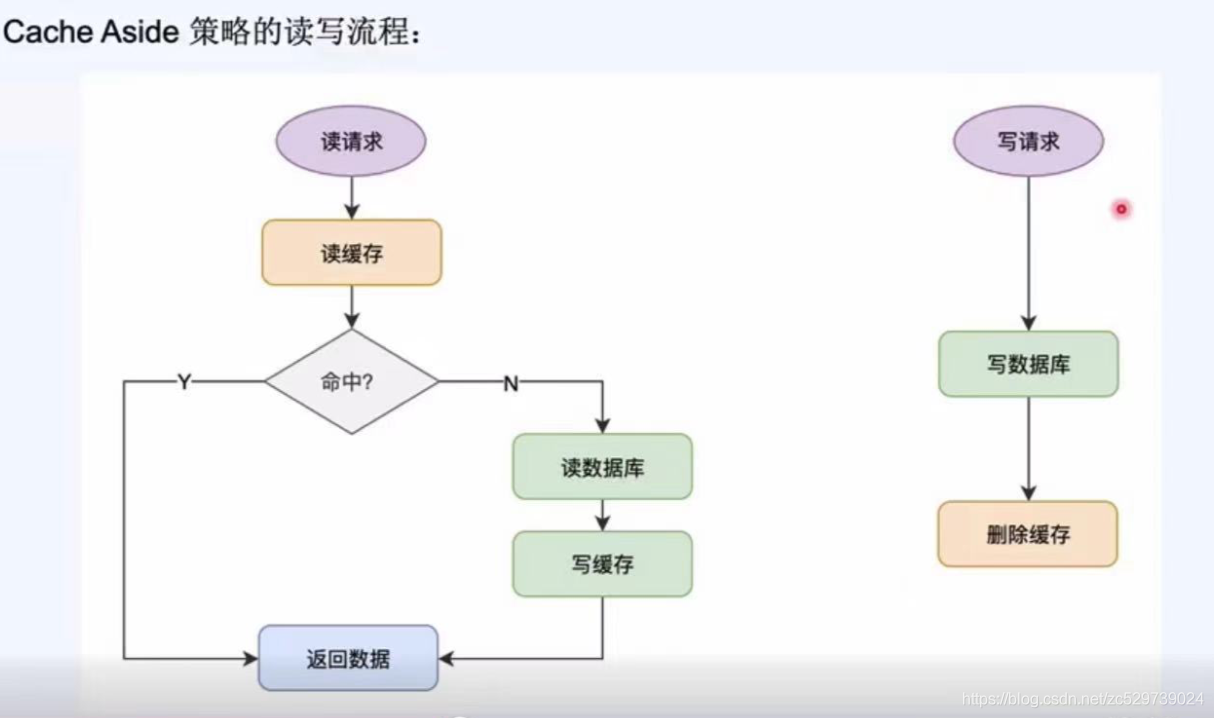
2.3.1:Cache Aside 策略:
更新資料時不更新快取,洗掉快取中的資料,
讀取資料時,如果快取中沒有資料,從資料庫中讀取,更新到快取中,
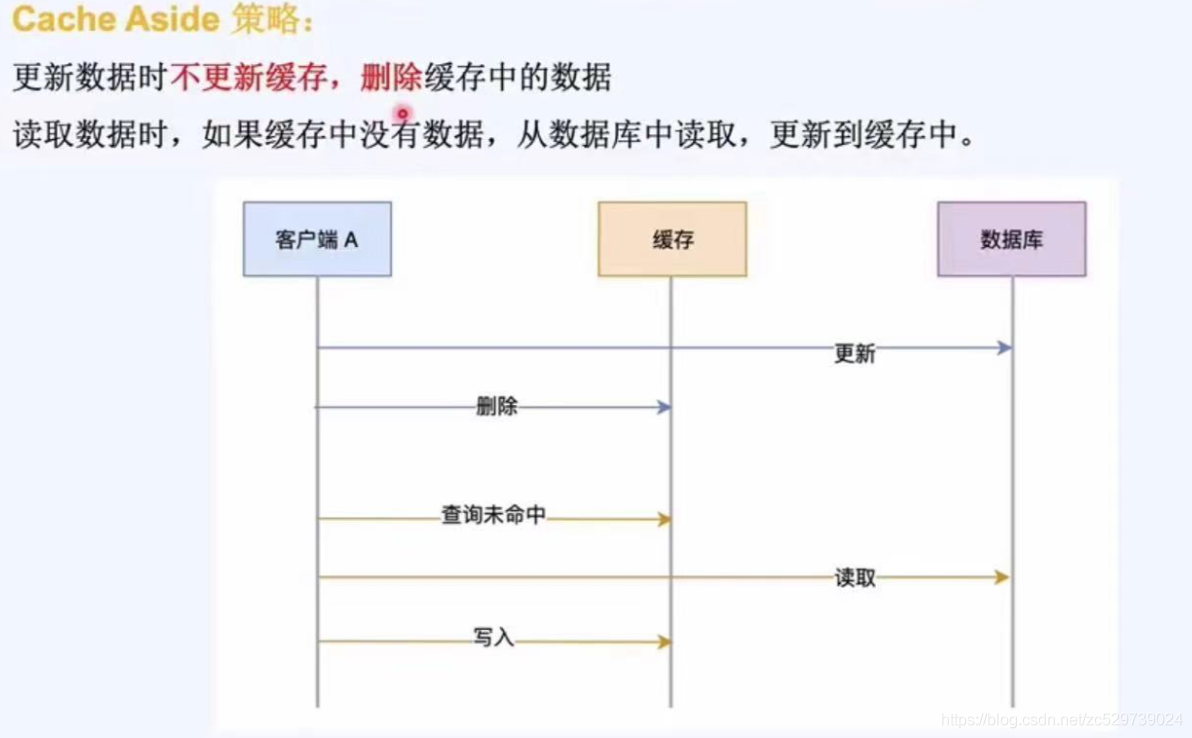
cache aside策略的讀寫流程:
讀:讀請求-先讀快取--如果命中,直接回傳資料---如果沒有命中,讀取資料庫,寫入快取,回傳資料,
寫:寫請求-先寫資料庫--再洗掉快取,
問題:在寫的時候可不可以先洗掉快取?不可以!(因為先刪快取,再更新資料庫,可能更新資料庫失敗,這樣后續的讀就增加了訪問資料庫的壓力)
2.3.2:Read/Write Through 策略:
核心原則:用戶只與快取打交道,由快取和資料庫通信,寫入或者讀取資料,
注意,這里有個關鍵角色,就是這個”快取組件“,有點像倉庫管理員,
read/write through 策略的讀寫流程:
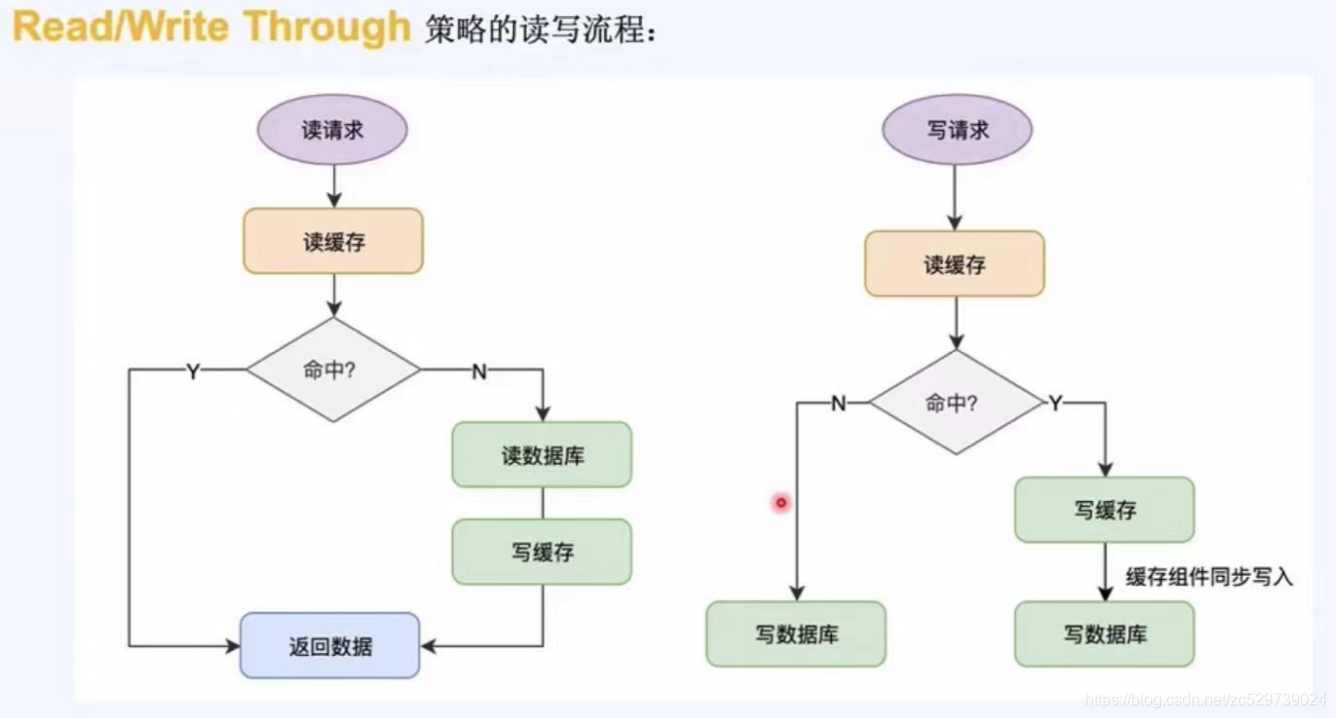
讀:讀請求--讀快取--如果命中,直接回傳資料--如果不命中,讀資料庫,寫快取,回傳資料,
寫:寫請求--讀快取--命中,直接寫資料庫--未命中,先寫快取,再由快取組件同步寫入資料庫,
2.3.3:快取的雪崩
快取的雪崩:大量資料同時失效 導致 資料庫壓力過大,
解決方案:
1.為有效期 增加隨機值
2.使用高可用 分布式快取
3. 熱點資料永遠 不過期,
4.在快取失效后,通過加鎖或者佇列來控制讀資料庫的執行緒數量,
2.3.4:快取的穿透
快取的穿透:快取中沒有,需要訪問資料庫,這樣是快取被穿透了,穿透后就需要查詢DB,量大的話就會壓垮資料庫,
解決方案:
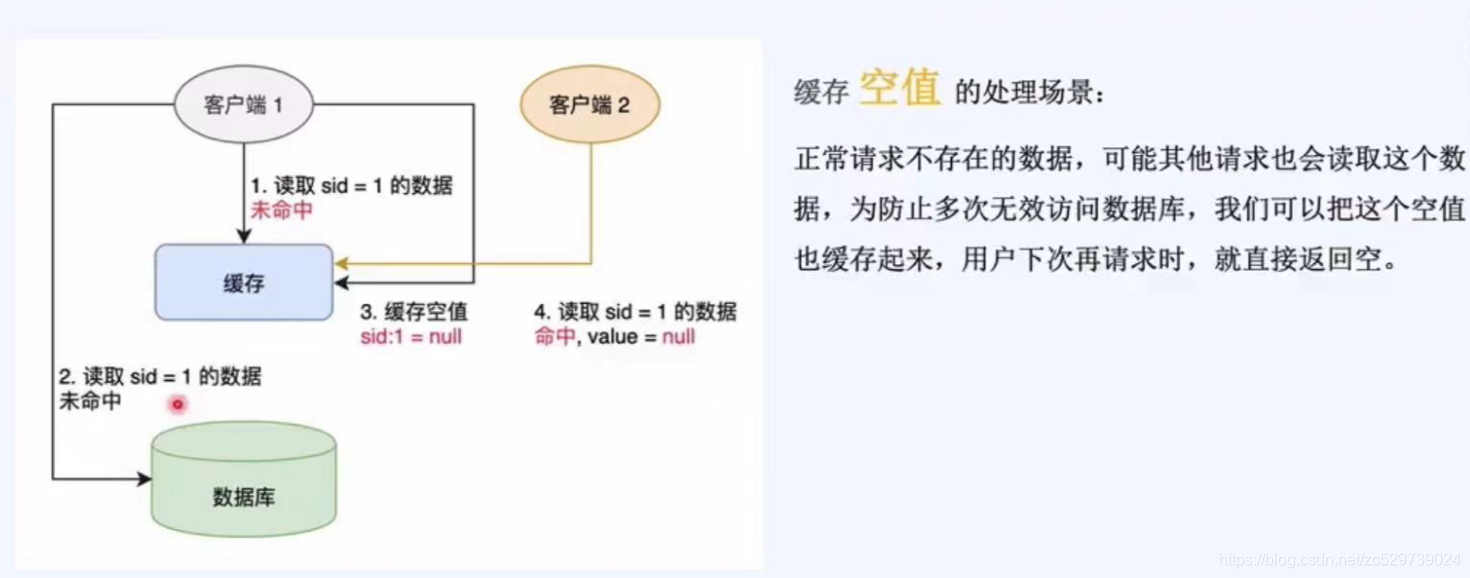
1.快取,空值
快取“空值”的處理場景(正常訪問的場景):
正常請求不存在的資料,可能其他請求也會讀取這個資料,為防止多次無效訪問資料庫,我們可以把這個空值也快取起來,用戶下次請求時,就直接回傳空,
2.采用布隆過濾器,
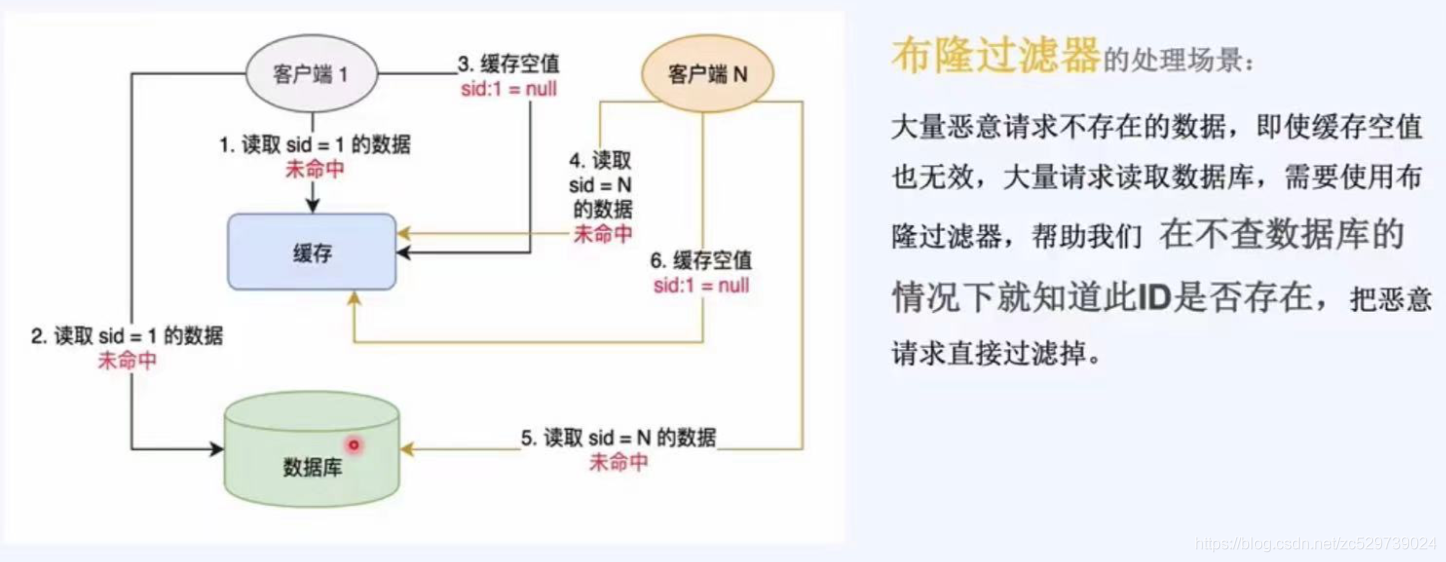
布隆過濾器的處理場景(惡意攻擊的場景):
大量惡意請求不存在的資料,即使快取空值也無效,大量請求讀取資料庫,需要使用布隆過濾器,幫助我們在不查資料庫的情況下就知道此ID是否存在,把惡 意請求直接過濾掉,
2.3.5:布隆過濾器
1970年布隆提出了一種過濾器的演算法,用來判斷一個元素是否在一個集合中,
這種演算法由一個二進制陣列和一個Hash演算法組成,
優勢:省空間,性能高!
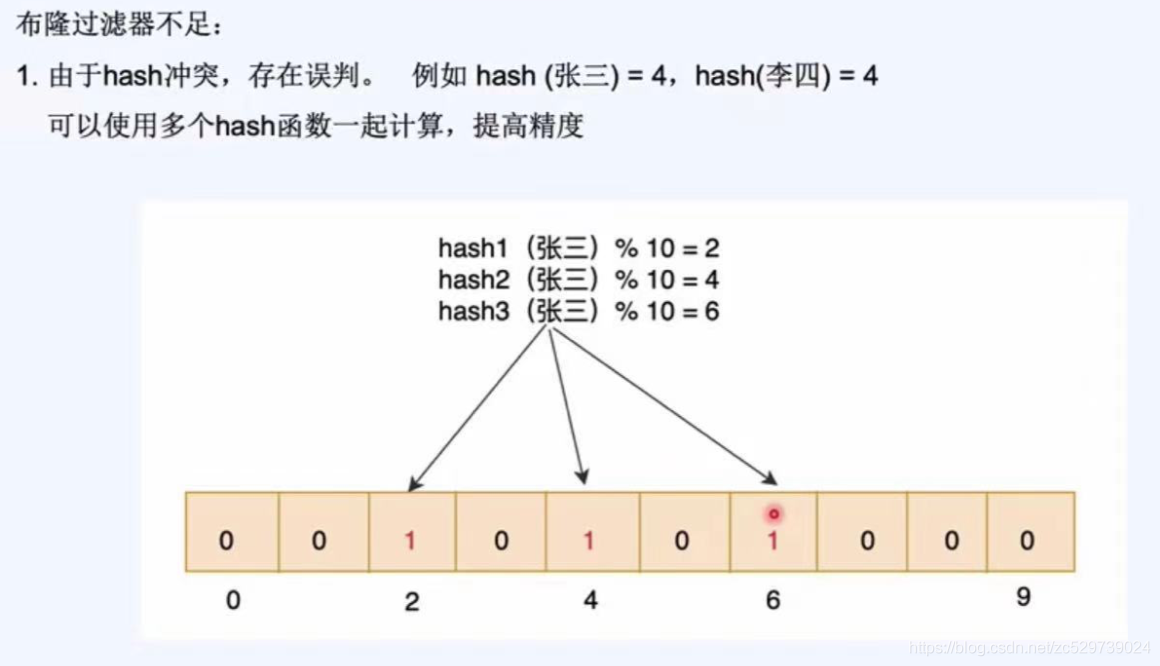
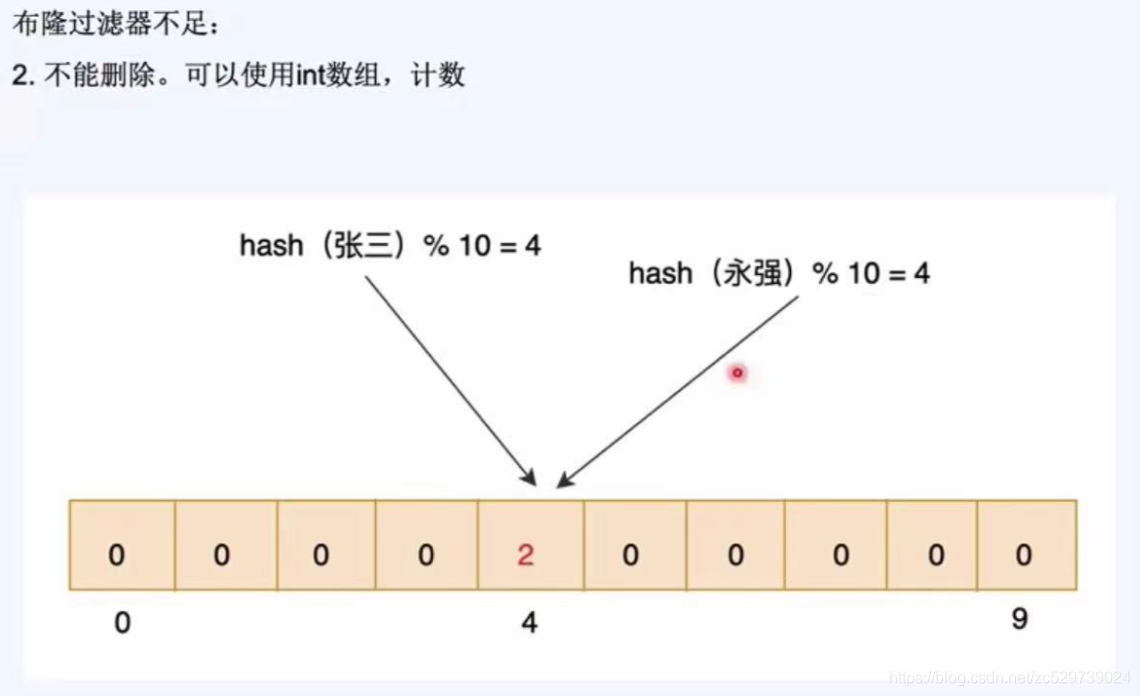
不足:有誤判,不能洗掉,
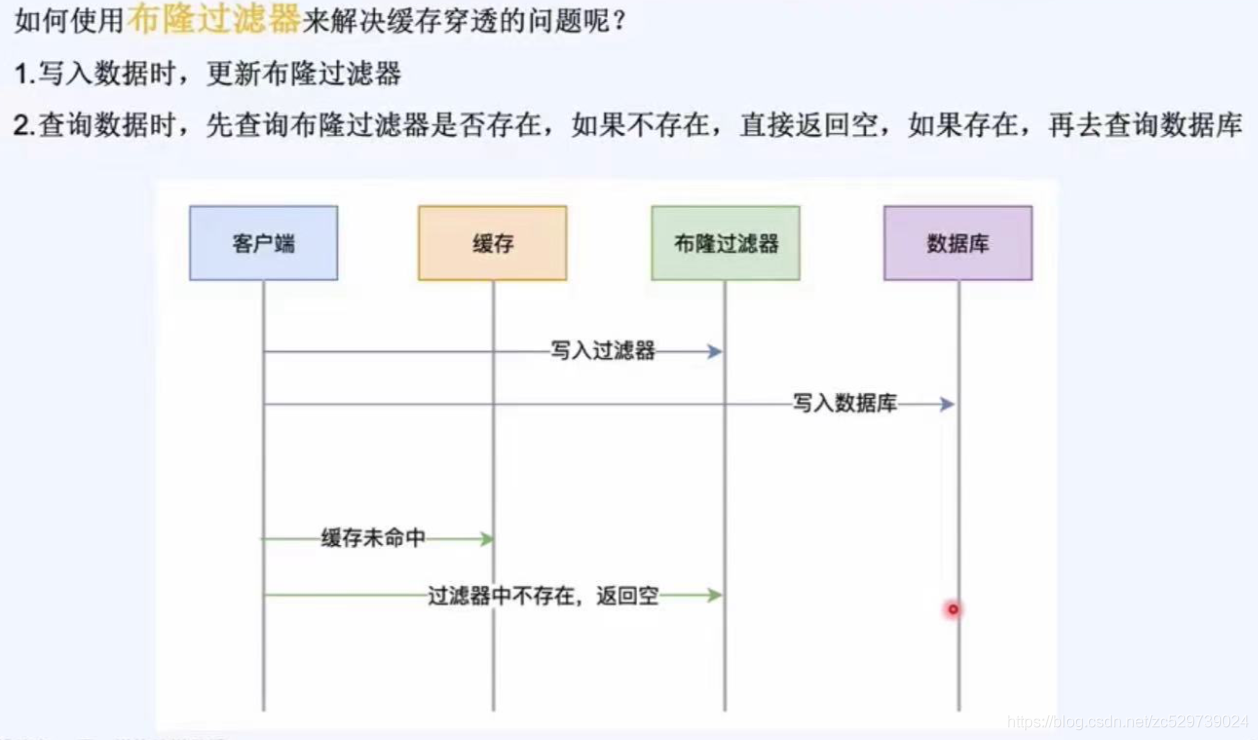
如何使用布隆過濾器來解決快取穿透的問題呢?
1:寫入資料時,更新布隆過濾器
2:查詢資料時,先查詢布隆過濾器是否存在,如果不存在,直接回傳空,如果存在,再去查詢資料庫,
圖:
布隆過濾器的不足:
2.4:降級
功能降級:電商平臺很普遍的“推薦功能”,可以提升銷量,但不是購物核心流程,
在系統壓力大時,可以降級,改為默認內容,
寫服務降級:不更新資料庫,只更新快取,把要寫的資料放到訊息佇列,流量高峰過了以后,把訊息佇列里的資料回放到資料庫,
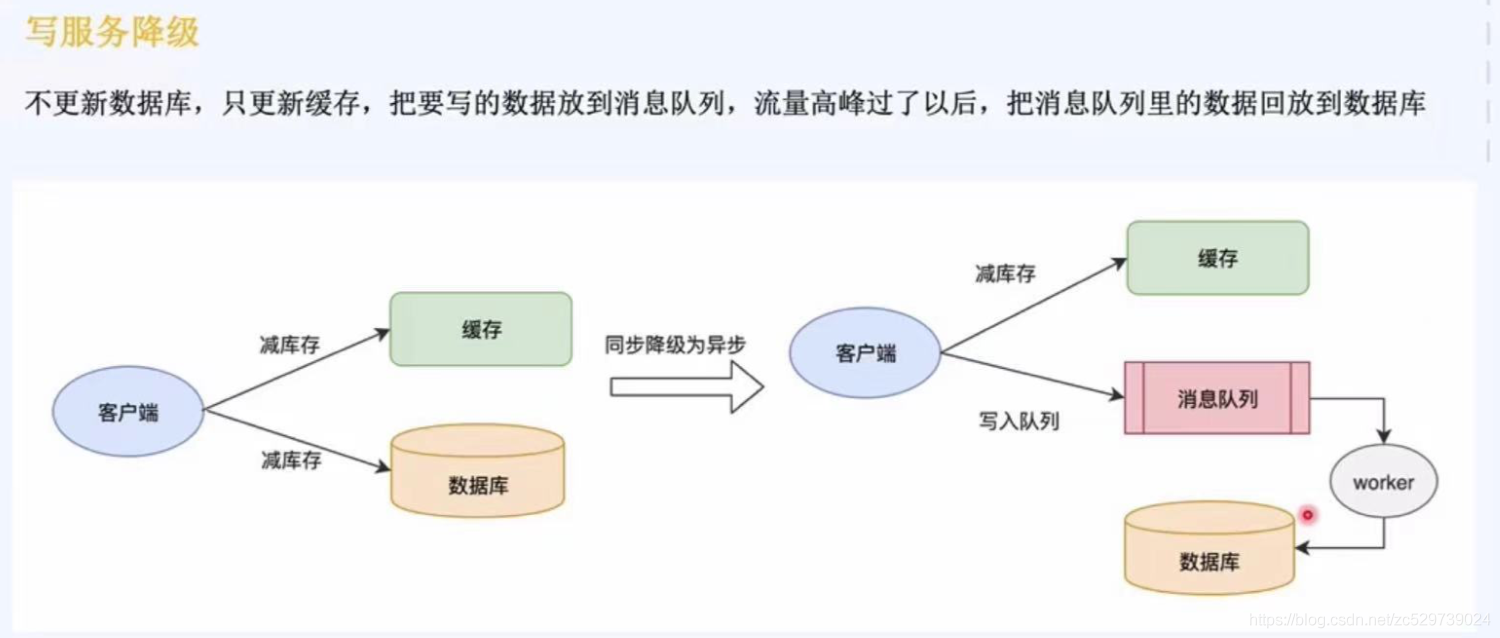
降級的定義:
整體負載,流量>閥值
為了保證重要的服務能正常運行,1:拒絕部分請求,2:延遲和暫停一些不重要的服務,任務,
降級的作用:
降級是系統保護的重要手段,保證系統的高可用,簡單理解降級就是“丟車保帥”,保證系統核心功能的正常,
降級的方式:
自動降級:
程式呼叫時發生問題時,自動降級,
超時降級:對于非核心服務,如果長時間回應慢,就可以自動降級,
限流降級:當觸發了限流閥值時,可以使用暫時屏蔽的方式進行降級,
統計失敗次數降級:在一個時間段內,呼叫失敗率超出閥值,自動降級,
手動降級:
使用開關配置,對系統中可降級的服務都設定好開關項,
組態檔實作開關配置:
適用于系統部署結構簡單的場景,
系統自動監控組態檔的變化
組態檔變化后重新載入,
配置中心實作開關配置:
適用于分布式系統,有統一配置中心,
服務開關在配置中心中定義
在配置中心界面修改相應引數,自動通知相應服務,
配置中心實作技術:zookeeper,redis,consul,etcd,
降級后的處理方案:
使用默認值;兜底資料;快取資料;排隊頁面;無貨通知;錯誤頁面,,,,
2.5:限流
對于系統,在應對高性能壓力的場景時,限流已經成為了標配技術解決方案,保證了系統的平穩運行,
限流就是對請求進行限制,例如某一個介面的請求限制為100個每秒,對超過限制的請求則不處理,
保護系統的手段:
快取:提升系統的訪問速度,增大系統處理能力,
降級:暫時屏蔽,過后打開,
限流:對稀缺資源限制請求量,限速,拒絕服務,
四個常用的限流演算法:
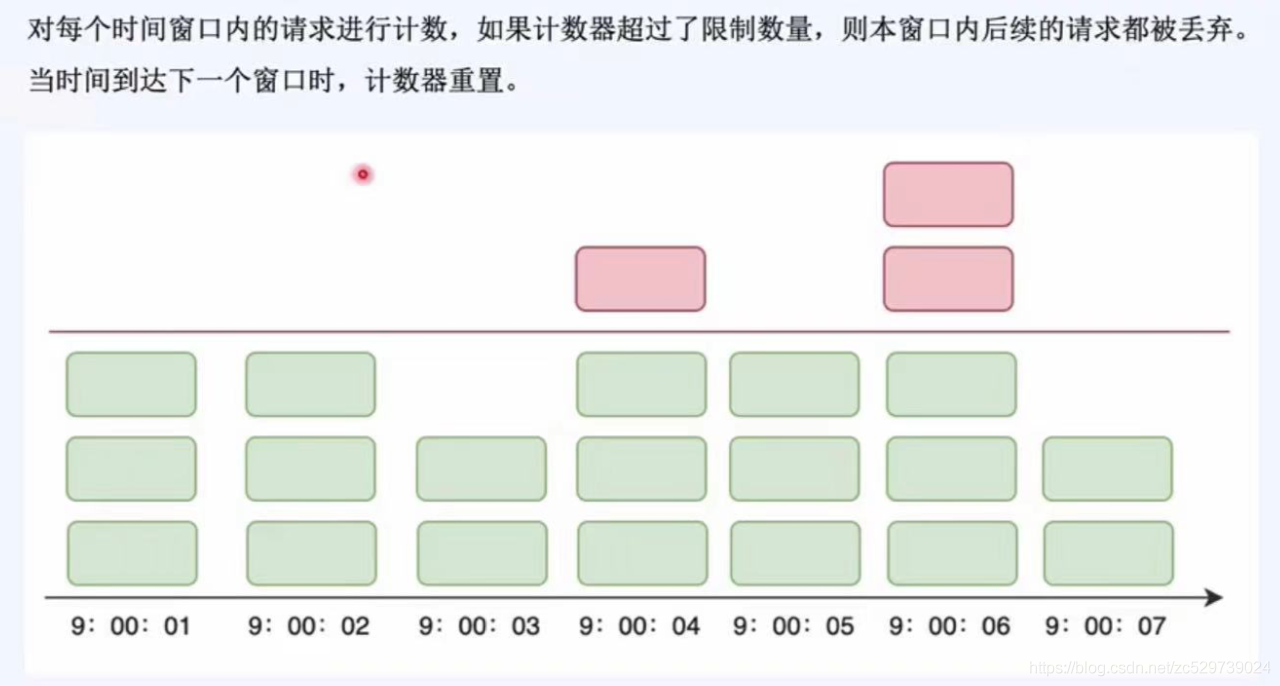
1.固定時間視窗:
對每個時間視窗內的請求進行計數,如果計算器超過了限制數量,則本視窗內后續的請求都被丟棄,當時間達到下一個視窗時,計數器重置,
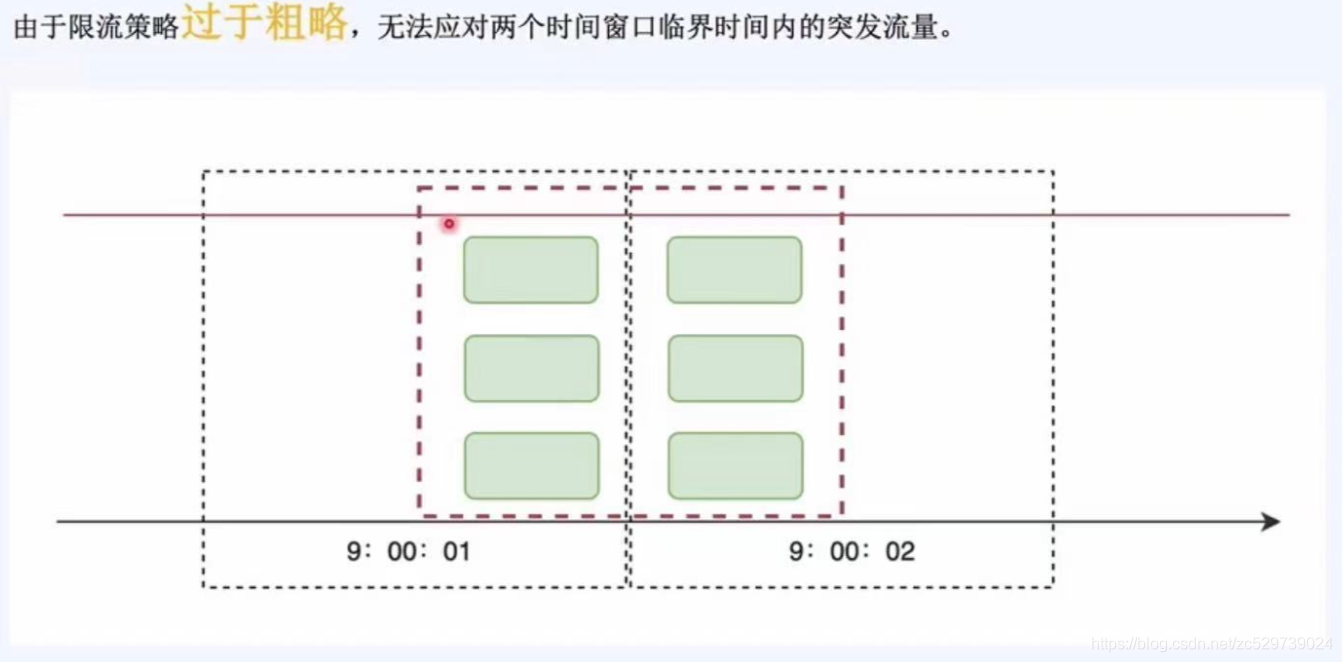
缺點:由于限流過于粗糙,無法應對兩個時間視窗臨界時間內的突發流量,例如:例如每秒限流3個請求,但前一秒內3個請求是在后半秒來的和后一秒內3個請求是在前半秒內來的,此時無法應對兩個時間視窗臨界時間內的突發流量【實際在這后半秒+前半秒的一秒時間內,請求數超過了3個達到了6個,】
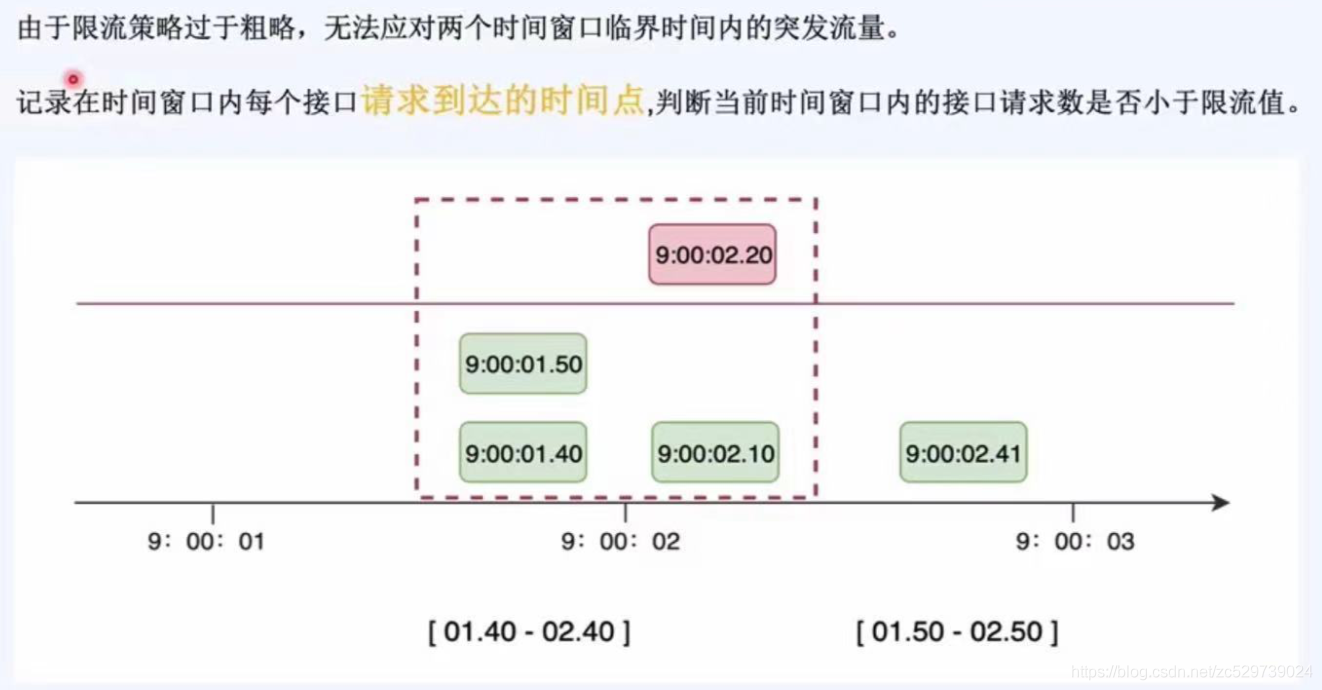
2:滑動時間視窗
記錄在時間視窗內每個介面請求達到的時間點,判斷當前時間視窗內的介面請求數是否小于限流值,
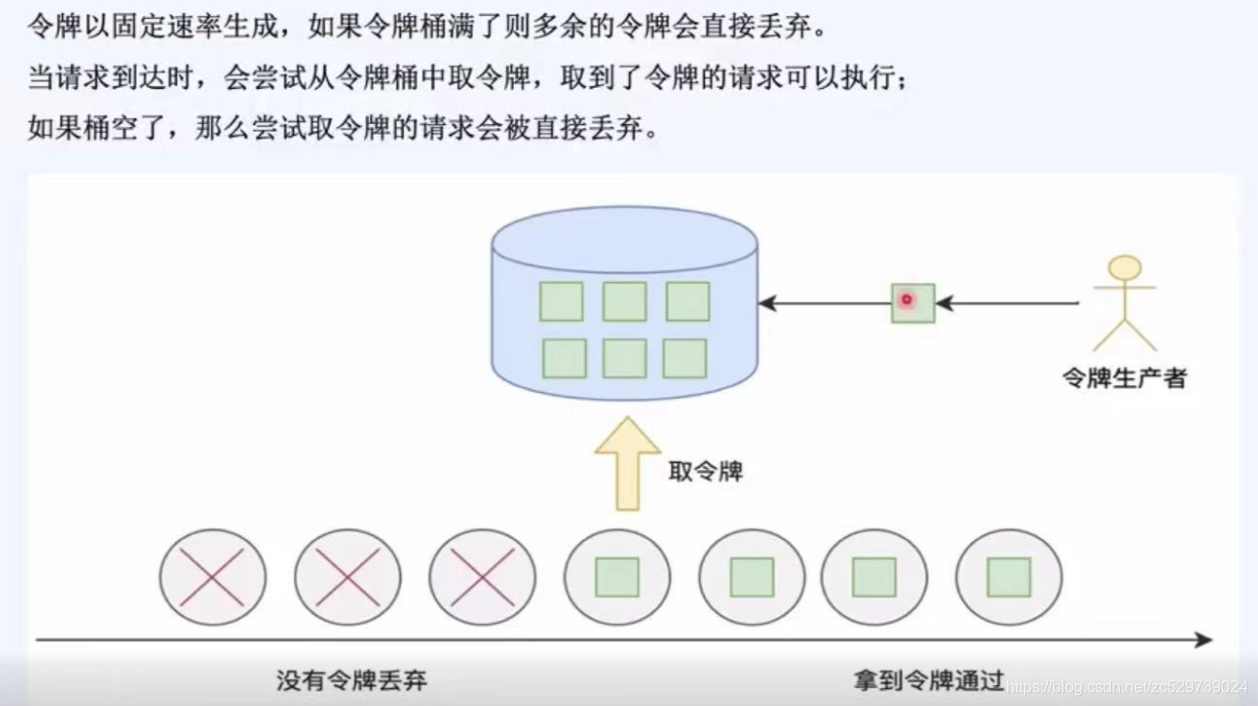
3:令牌桶
令牌以固定速率生成,如果令牌桶滿了則多余的令牌直接丟棄,
當請求達到時,會嘗試從令牌桶中去令牌,取到了令牌的請求可以執行,
如果桶空了,那么嘗試去令牌的請求會被直接丟棄,
4:漏桶演算法
漏桶容量固定,按照固定速率流出請求
可以任意速率流入請求
如果流入過快,會溢位對其請求,

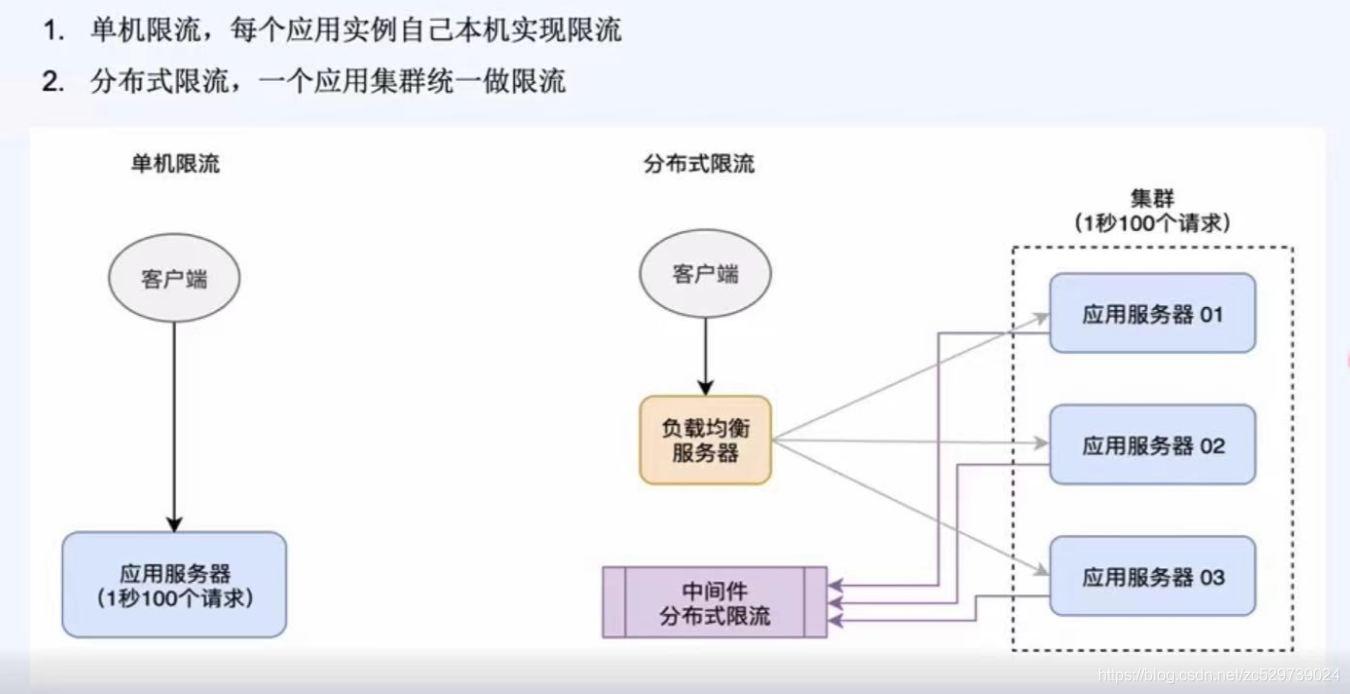
限流形式:
1:單機限流,每個應用實體自己本機實作限流,
2:分布式限流,一個應用集群統一做限流,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/243554.html
標籤:其他