

線性表
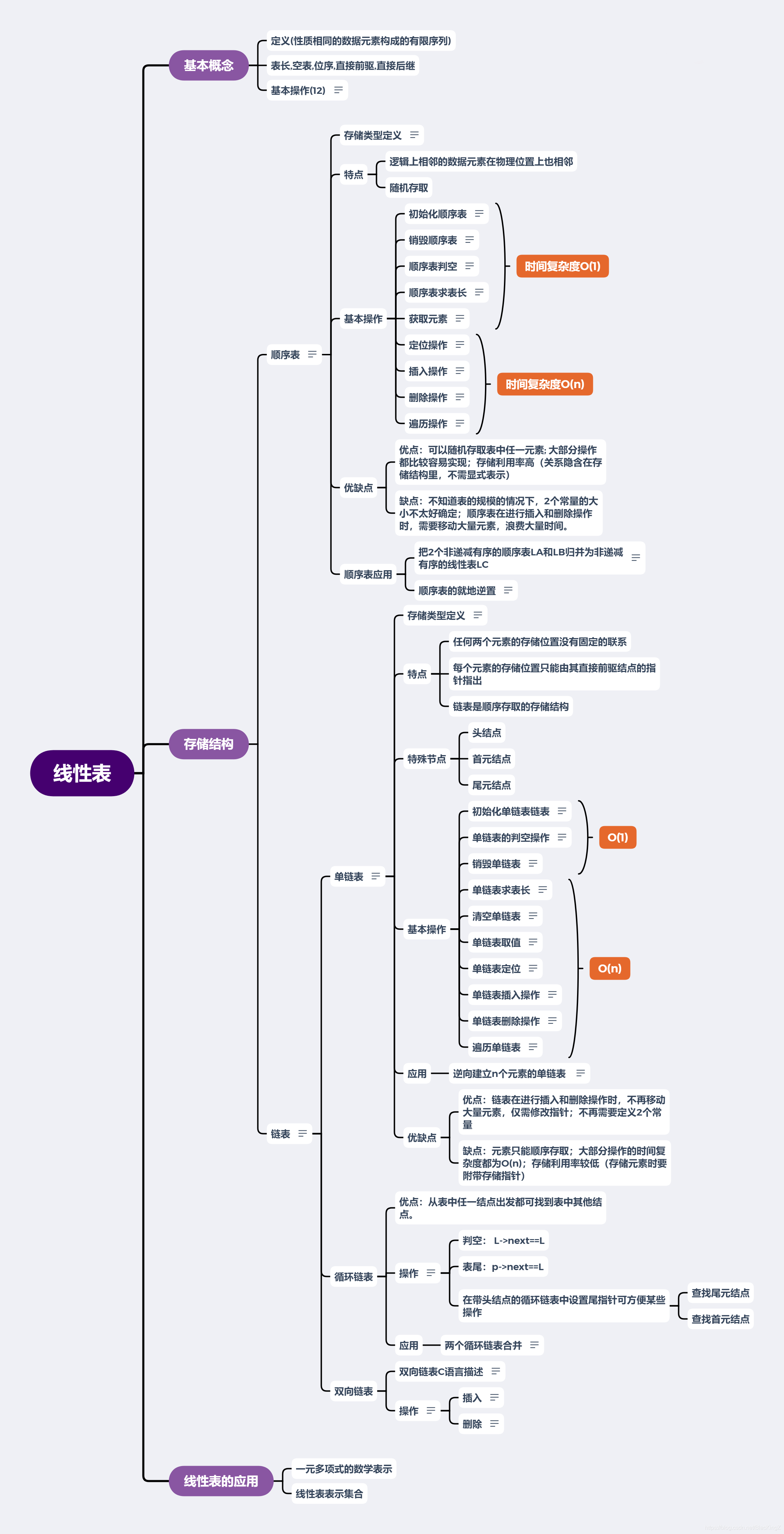
基本概念
定義(性質相同的資料元素構成的有限序列)
表長,空表,位序,直接前驅,直接后繼
基本操作(12)
InitList(&L); //構造一個空的線性表L
ListEmpty(L); //判斷線性表L是否是空表,若是,則回傳TRUE,否則回傳FALSE
ListLength(L); //回傳線性表L的長度
GetElem(L,i,&e) ; //用e回傳線性表L的第i個資料元素的值
LocateElem(L,e,compare());//在線性表L中查找第一個和元素e滿足compare關系//的元素,若找到則回傳其位序;否則回傳0
PriorElem(L,e, &pre_e); //用pre_e回傳線性表L中元素e的直接前驅
NextElem(L, e, &next_e); //用next_e回傳線性表L中元素e的直接后繼
ListInsert(&L,i,e) ; //將資料元素e插入到線性表L的第i個資料元素之前
ListDelete(&L,i,&e); //洗掉線性表L的第i個資料元素,并將其值用e回傳
ListTraverse(L,visit()); //依次對線性表L中的每個元素呼叫visit進行訪問
ClearList(&L); //重置線性表L為空表
DestroyList(&L); //銷毀線性表L,可能的話釋放其空間
存盤結構
順序表
用一組地址連續的存盤單元依次存盤線性表的資料元素,用順序存盤結構表示的線性表又稱為順序表,
- 存盤型別定義
#define LIST_INIT_SIZE 100 //順序表存盤空間的初始分配量
#define LISTINCREMENT 10 //順序表存盤空間的分配增量
typedef struct
{ ElemType *elem; //存盤空間的基地址
int length; //順序表的當前長度
int listsize; //陣列存盤空間的長度
}SqList;
-
特點
- 邏輯上相鄰的資料元素在物理位置上也相鄰
- 隨機存取
-
基本操作
- 初始化順序表
Status InitSqList(SqList& L) //順序表初始化
{
L.elem = (ElemType*)malloc(LIST_INIT_SIZE * sizeof(ElemType));//申請初始分配空間
if (L.elem == NULL) exit(OVERFLOW);//分配失敗,回傳OVERFLOW
L.length = 0;//初始化表長為零
L.listsize = LIST_INIT_SIZE;//初始化陣列存盤空間為初始分配空間
return OK;//分配成功回傳OK
}
- 銷毀順序表
void DestroySqList(SqList& L)//銷毀順序表
{
if (L.elem != NULL)//如果順序表存在
free(L.elem);//釋放存盤空間
L.elem = NULL;//存盤空間基址置空
}
- 順序表判空
Status SqListEmpty(SqList L)//順序表的判空操作
{
if (L.length == 0)
return TRUE;//表長為零為空表
else
return FALSE;//表長非零不為空
}
- 順序表求表長
int SqListLength(SqList L)//順序表求表長
{
return L.length;
}
- 獲取元素
Status GetSqElem(SqList L, int i, ElemType& e)//取第i個元素,用第三個引數e回傳
{
if (i<1 || i>L.length)//判斷索引是否有效
return ERROR;//無效報錯
else
{
e = L.elem[i - 1];//有效則回傳元素
return OK;
}
}
- 定位操作
int SqLocateElem(SqList L, ElemType e)//定位元素e,回傳元素位序,若元素不存在則回傳零
{
int i;
for (i = 1; i <= L.length; i++)//遍歷陣列
{
if (L.elem[i - 1] == e);//找到元素跳出回圈
break;
}
if (i <= L.length)//判斷是否溢位
return i;
else
return 0;
}
- 插入操作
Status SqListInsert(SqList& L, int i, ElemType e)//順序表插入操作,在位序i上插入元素e
{
if (i<1 || i>L.length)//判斷位序是否有效
return ERROR;
if (L.length == L.listsize)//判斷是否溢位,如果溢位,重新分配空間
{
L.elem = (ElemType*)realloc(L.elem, (L.listsize + LISTINCREMENT) * sizeof(ElemType));
if (!L.elem) exit(OVERFLOW);
L.listsize += LISTINCREMENT;
}
ElemType* q;
q = &L.elem[i - 1];
for (ElemType* p = &L.elem[L.length - 1]; p >= q; p--)//從后向前移動元素
{
*(p + 1) = *p;
}
*q = e;
L.length++;//更新表長
return OK;
}
- 洗掉操作
Status SqListDelete(SqList& L, int i)//洗掉順序表第i個元素
{
if (i<1 || i>L.length) //判斷引數是否溢位
return ERROR;
int j;
for (j = i; j < L.length; j++)//從第i+1個元素開始到最后一個元素遍歷
{
L.elem[j - 1] = L.elem[j];//每個元素向前移
}
L.length--;
return OK;
}
- 遍歷操作
Status SqListTraverse(SqList L, Status(*visit)(ElemType))//順序表遍歷操作
{
int i;
for (i = 0; i < L.length; i++)//回圈遍歷順序表
if (visit(L.elem[i])==FALSE) //遍歷例外退出
return ERROR;
return OK;
}
定義比較函式:
Status equal(ElemType a,ElemType b){
if(a==b) return TRUE;
else return FALSE;
}
-
優缺點
- 優點:可以隨機存取表中任一元素; 大部分操作都比較容易實作;存盤利用率高(關系隱含在存盤結構里,不需顯式表示)
- 缺點:不知道表的規模的情況下,2個常量的大小不太好確定;順序表在進行插入和洗掉操作時,需要移動大量元素,浪費大量時間,
-
順序表應用
- 把2個非遞減有序的順序表LA和LB歸并為非遞減有序的線性表LC
void MergeList_Sq(SqList la,SqList lb,SqList &lc){//演算法2.7
pa=la.elem; pb=lb.elem;
lc.listsize=lc.length=la.length+lb.length;
pc=lc.elem = new ElemType[lc.listsize];
pa_last=la.elem+la.length-1; pb_last=lb.elem+lb.length-1;
while(pa<=pa_last && pb<=pb_last) {
if(*pa<=*pb) *pc++=*pa++;
else *pc++=*pb++;
}
while(pa<=pa_last) *pc++=*pa++;
while(pb<=pb_last) *pc++=*pb++;
}
- 順序表的就地逆置
void reverse1(Sqlist &A)
{
for(i=0,j=A.length-1;i<j;i++,j--)
A.elem[i]<->A.elem[j];
}//reverse1
鏈表
用一組任意的存盤單元(可連續可不連續)存盤線性表中的資料元素,
-
單鏈表
線性單鏈表:n個結點(每個結點只包含一個指標域)鏈接而成的鏈表,
- 存盤型別定義
typedef struct LNode {
ElemType data; //資料域
struct LNode* next; //指標域
}LNode, * LinkList;
- 特點
- 任何兩個元素的存盤位置沒有固定的聯系
- 每個元素的存盤位置只能由其直接前驅結點的指標指出
- 鏈表是順序存取的存盤結構
- 特殊節點
- 頭結點
- 首元結點
- 尾元結點
- 基本操作
- 初始化單鏈表鏈表
Status InitLinkList(LinkList& L) //初始化鏈表
{
L = (LinkList)malloc(sizeof(LNode));//申請頭節點
if (L == NULL) exit(OVERFLOW);//申請失敗回傳例外
L->next = NULL;//頭節點置空
return OK;
}
- 單鏈表的判空操作
Status LinkListEmpty(LinkList L) //單鏈表的判空操作
{
if (L->next == NULL)//判斷頭指標是否為空
return TRUE;
else
return FALSE;
}
- 銷毀單鏈表
void DestroyLinkList(LinkList& L) //銷毀單鏈表
{
LinkList p;//新建節點指標
while (L != NULL)//頭指標非空
{
p = L->next;//p指標保留將要釋放的節點指標域
free(L);//釋放節點
L = p;//更新頭節點
}
}
- 單鏈表求表長
int LinkListLength(LinkList L) //單鏈表求表長操作
{
LinkList p;
int n = 0;
for (p = L->next; p != NULL; p = p->next, n++);//從首元節點遍歷單鏈表并計數
return n;
}
- 清空單鏈表
void ClearLinkList(LinkList L) //清空單鏈表
{
LinkList p;
for (p = L->next; p != NULL; p = L->next)//從首元節點遍歷釋放節點空間
{
L->next = p->next;//更新頭節點指標
free(p);//釋放首元節點
}
}
- 單鏈表取值
Status GetLinkElem(LinkList L, int i, ElemType& e) //單鏈表取第i個值,由e回傳
{
int count;//計數變數
LinkList p = L;//遍歷指標初始為頭指標
for (count = 0; count < i && p != NULL; count++)//計數器置零,遍歷到第i個,指標為空例外退出
{
p = p->next;
}
if (i > count)//判斷是否例外退出
return ERROR;
else//正常退出回傳OK
{
e = p->data;
return OK;
}
}
- 單鏈表定位
LinkList LinkLocateElem(LinkList L, ElemType e, Status(*compare)(ElemType, ElemType))
//單鏈表定位操作,回傳第一個滿足關系的節點指標,若無滿足關系的元素,回傳空指標
{
LinkList p = L->next;//從首元節點遍歷鏈表
while (p!=NULL && compare(p->data, e)==FALSE) //直到滿足關系或遍歷結束停止遍歷
p = p->next;
return p;//回傳指標
}
- 單鏈表插入操作
Status LinkListInsert(LinkList& L, int i, ElemType e)//單鏈表插入操作
{
int count;//計數變數
LinkList p;//回圈指標
for (count = 0, p = L; count < i - 1 && p != NULL; p = p->next, count++);//定位第i-1個節點
if (i < 0 || count < i - 1) //判斷i取值是否合理
return ERROR;
else
{
LinkList q;
q = (LinkList)malloc(sizeof(LNode));//創建待插入節點空間
q->data = e;
q->next = p->next;//插入節點指向其后繼
p->next = q;//連接其前驅節點
}
return OK;
}
- 單鏈表洗掉操作
Status LinkListDelete(LinkList& L, int i)
{
int count;//計數變數
LinkList p;//回圈指標
for (count = 0, p = L; count < i - 1 && p != NULL; p = p->next, count++);//定位第i-1個節點
if (i < 0 || count < i - 1) //判斷i取值是否合理
return ERROR;
else
{
LinkList q = p->next;//指向待洗掉節點
p->next = q->next;//前驅節點指標域更新
free(q);//洗掉節點
}
return OK;
}
- 遍歷單鏈表
Status LinkListTraverse(LinkList L,Status(*visit)(ElemType)) //遍歷單鏈表
{
LinkList p;
for (p = L->next; p; p = p->next)
if (!visit(p->data)) return ERROR;
return OK;
}
- 應用
- 逆向建立n個元素的單鏈表
void CreateList_backward(LinkList &L,int n)
{ //逆向建立n個元素的單鏈表
L=( LinkList) malloc(sizeof(LNode));
L->next=NULL;
for(i=0; i<n; i++)
{ p=( LinkList) malloc(sizeof(LNode));
scanf(&p->data);
p->next=L->next;
L->next=p;
}//for
}// CreateList_backward
- 優缺點
- 優點:鏈表在進行插入和洗掉操作時,不再移動大量元素,僅需修改指標;不再需要定義2個常量
- 缺點:元素只能順序存取;大部分操作的時間復雜度都為O(n);存盤利用率較低(存盤元素時要附帶存盤指標)
-
回圈鏈表
-
優點:從表中任一結點出發都可找到表中其他結點,
-
操作
和線性鏈表基本一致,差別在于判空和判表尾條件
-
判空: L->next==L
-
表尾:p->next==L
-
在帶頭結點的回圈鏈表中設定尾指標可方便某些操作
- 查找尾元結點
- 查找首元結點
-
-
應用
-
兩個回圈鏈表合并
僅設尾指標的回圈鏈表
p=LA->next;
LA->next=LB->next->next;
free(LB->next);
LB->next=p;
LA=LB;
-
-
-
雙向鏈表
- 雙向鏈表C語言描述
typedef struct DulNode{
ElemType data;
Struct DulNode *prior;//指向其直接前驅的指標域
Struct DulNode *next; //指向其直接后繼的指標域
}DulNode,*DuLinkList;
- 操作
某些操作演算法與線性單鏈表的操作相同;
插入、洗掉等操作需同時修改兩個方向的指標
- 插入
Status ListInsert_Dul(DuLinklist &L,int i,ElemType e)
{
if(!(p=GetElem_DuL(L,i)))
return ERROR;
if(!(s=(DuLinkList)malloc(sizeof(DuLNode))))
return ERROR;
s->data=e;
① s->prior=p->prior;
② p->prior->next=s;
③ s->next=p;
④ p->prior=s;
return OK;
}
- 洗掉
Status ListDelete_Dul(DuLinklist &L,int i,ElemType &e)
{
if(!(p=GetElem_DuL(L,i)))
return ERROR;
e=p->data;
① p->prior->next=p->next ;
② p->next->prior=p->prior;
③ free(p);
return OK;
}
堆疊和佇列
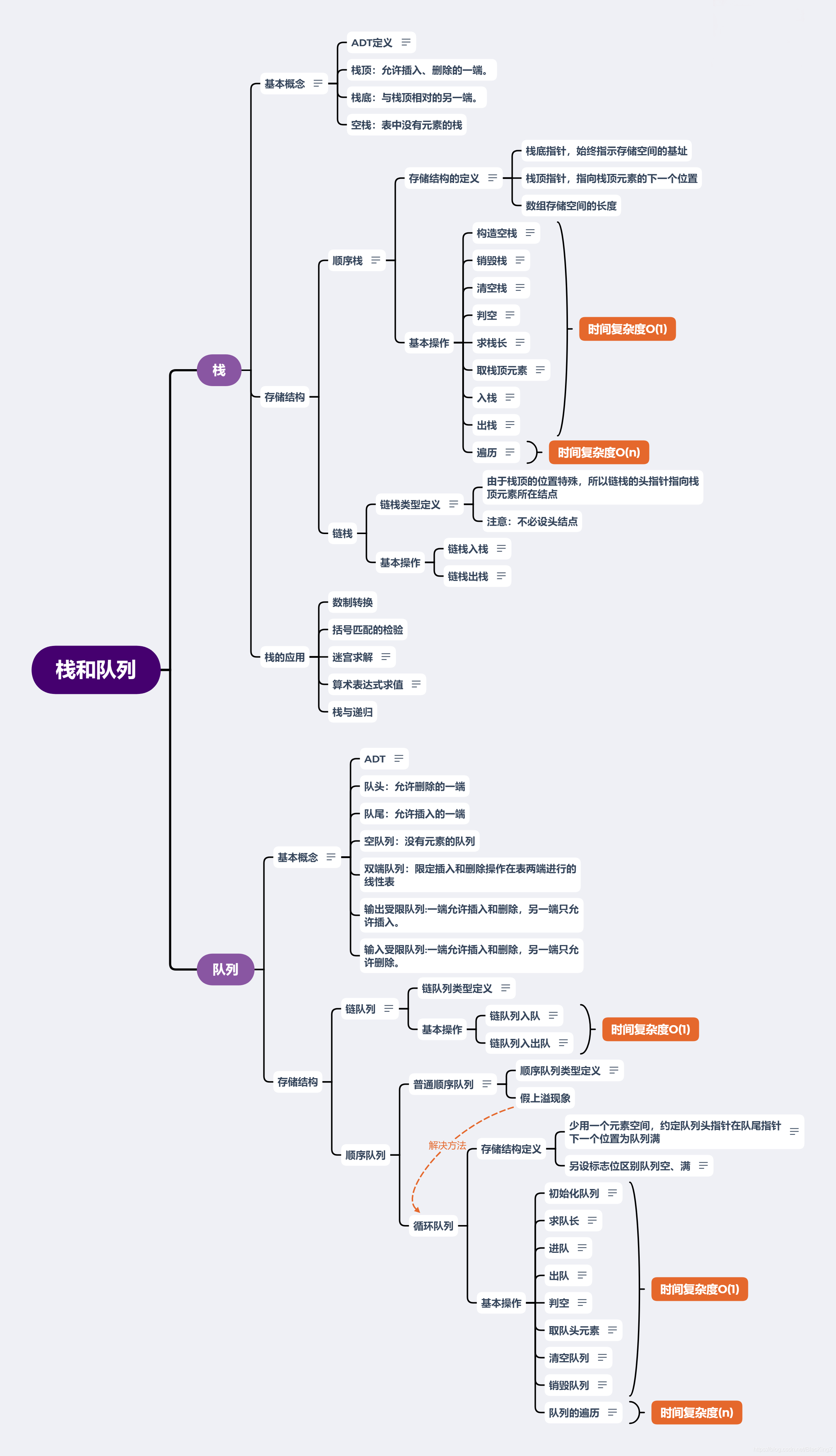
堆疊
基本概念
堆疊:限制僅在表的一端進行插入和洗掉的線性表
-
ADT定義
ADT Stack {
資料物件:D={ai| ai ? ElemSet, i=1,2,…,n, n?0}
資料關系:R={< ai-1, ai >| ai-1,ai ?D,i=2,…,n}
約定an端為堆疊頂, a1端為堆疊底
基本操作:InitStack(&S); StackEmpty(S);
StackLength(&S); GetTop(S, &e);
Push(&S, e); Pop(&S, &e);
ClearStack(&S);
StackTraverse(S, visit());
DestroyStack(&S);
} ADT Stack -
堆疊頂:允許插入、洗掉的一端,
-
堆疊底:與堆疊頂相對的另一端,
-
空堆疊:表中沒有元素的堆疊
存盤結構
-
順序堆疊
特點:用一組地址連續的存盤單元依次存放自堆疊底到堆疊頂的資料元素
堆疊中元素可動態增刪,即堆疊長是可變的,因此和順序表一樣,用動態分配的一維陣列來表示順序堆疊- 存盤結構的定義
#define STACK_INIT_SIZE 100 //順序堆疊存盤空間的初始分配量
#define STACKINCREMENT 10 //順序堆疊存盤空間的分配增量
typedef struct
{
SElemType* base; //堆疊底指標,始終指示存盤空間的基址
SElemType* top; //堆疊頂指標,指向堆疊頂元素的下一個位置
int stacksize; //陣列存盤空間的長度
}SqStack;//順序堆疊定義
- 堆疊底指標,始終指示存盤空間的基址
- 堆疊頂指標,指向堆疊頂元素的下一個位置
- 陣列存盤空間的長度
- 基本操作
- 構造空堆疊
Status InitSqStack(SqStack& S)
{
S.base = (SElemType*)malloc((STACK_INIT_SIZE) * sizeof(SElemType));// 堆疊的連續空間分配
if (!S.base)
{
exit(OVERFLOW);
}
S.top = S.base; //空堆疊,初始化堆疊頂指標
S.stacksize = STACK_INIT_SIZE;
return OK;
}//構造一個空堆疊,該堆疊由指標S指示
- 銷毀堆疊
Status DestroySqStack(SqStack& S)
{
if (S.base) //堆疊底指標非空
free(S.base);
S.base = NULL;
return OK;
}//銷毀堆疊
- 清空堆疊
Status ClearSqStack(SqStack& S)
{
S.top = S.base;
return OK;
}//清除堆疊
- 判空
Status SqStackEmpty(SqStack S)
{
return S.top == S.base;
}//堆疊的判空操作
- 求堆疊長
int SqStackLength(SqStack S)
{
return S.top - S.base;
}//求堆疊長
- 取堆疊頂元素
Status GetTopSq(SqStack S, SElemType& e)
{
if (S.top == S.base) return ERROR;
e = *(S.top - 1);
return OK;
} //用指標e帶回堆疊頂元素
- 入堆疊
Status SqPush(SqStack& S, SElemType e)
{//入堆疊,插入元素e為新的堆疊頂元素
if (S.top - S.base == S.stacksize)//堆疊滿
{
S.base = (SElemType*)realloc(S.base, (S.stacksize + STACKINCREMENT) * sizeof(SElemType));
if (!S.base) exit(OVERFLOW);
S.top = S.base + S.stacksize;
S.stacksize += STACKINCREMENT;
}//重新分配更大的連續空間
*S.top++ = e;
return OK;
}//Push
- 出堆疊
Status SqPop(SqStack& S, SElemType& e)
{
if (S.top == S.base) //堆疊空
return ERROR;
--S.top;
e = *S.top;
return OK;
}//出堆疊,洗掉的堆疊頂元素用指標e指示
- 遍歷
Status SqStackTraverse(SqStack S, Status(*visit)(SElemType))
{//從堆疊底到堆疊頂依次對堆疊S中的每個資料元素呼叫visit
//指向的函式進行訪問
SElemType* p;
for (p = S.base; p < S.top; p++)
if (!visit(*p)) return ERROR;
return OK;
}// 堆疊的遍歷
-
鏈堆疊
- 鏈堆疊型別定義
typedef struct SNode{
SElemType data; //資料域
struct SNode *next; //指標域
}SNode,*LinkStack;
- 由于堆疊頂的位置特殊,所以鏈堆疊的頭指標指向堆疊頂元素所在結點
- 注意:不必設頭結點
- 基本操作
- 鏈堆疊入堆疊
Status Push(LinkStack &S, SElemType e)
{//插入e到堆疊S中使之成為新的堆疊頂元素
p=( LinkStack)malloc(sizeof(SNode));
if(!p)
exit(OVERFLOW);
p->data=e;
p->next=S;
S=p;
return OK;
}//Push
- 鏈堆疊出堆疊
Status Pop(LinkStack &S, SElemType &e)
{//若堆疊不空則出堆疊,洗掉的堆疊頂元素用e指示
if(!S)
return ERROR; //堆疊空
p=S;
S=S->next;
e=p->data;
free(p);
return OK;
}//Pop
堆疊的應用
- 數制轉換
- 括號匹配的檢驗
- 迷宮求解
Typedef struct { //堆疊的元素型別定義
int ord; //通道塊在路徑上的“序號”
PosTpye seat ; //通道塊在迷宮中的“坐標位置”
int di; //從此通道塊走向下一通道塊的“方向”
}SElemType;
Status MazePath(MazeType maze, PosType start, PosType end){
InitStack(s); curpos=start; //設定當前位置為入口位置
curstep =1;
do{
if(Pass(curpos)) { //當前位置可通
FootPrint(curpos); //留下足跡
e=(curstep, curpos, 1);
push(s,e); //加入路徑
if(curpos==end) return(TRUE); //到達終點
curpos= NextPos(curpos, 1);
//下一位置是當前位置的東鄰
curstep++; //探索下一步
}//if
else { //當前位置不能通過
if (!StackEmpty(S)) {
Pop(S,e);
while(e.di==4 && !StackEmpty(s)){
MarkPrint(e.seat); Pop(s,e);
//留下不能//通過的標記,并退回一步
}//while
if (e.di<4){
e.di++; Push(S,e); //換下一方向搜索
curpos=NextPos(e.seat, e.di);
//設定當前位置是該新方向上的相鄰塊
}//if
}//if
}//else
} while(!StackEmpty(S));
return(FALSE);
}// MazePath
- 算術運算式求值
OperandType EvaluateExpression(){
InitStack(OPTR); Push(OPTR, '#');
InitStack(OPND); c=getchar();
while(c!= '#' || GetTop(OPTR)!= '#'){
if (!In(c,OP)) {Push(OPND,c); c=getchar();}
else
switch(Precede(GetTop(OPTR),c)){
case '<': Push(OPTR,c); c=getchar(); break;
case '=': Pop(OPTR,x); c=getchar(); break;
case '>': Pop(OPTR,theta);
Pop(OPND,b); Pop(OPND,a);
Push(OPND,Operate(a,theta,b)); break;
}//switch
}//while
return GetTop(OPND);
}// EvaluateExpression
- 堆疊與遞回
佇列
基本概念
只允許在表的一端進行插入,而在另一端進行洗掉的線性表,
-
ADT
ADT Queue {
資料物件:D={ai | ai ? ElemSet, i=1,2,…,n, n>=0}
資料關系:R={< ai-1, ai > | ai-1, ai ?D, i=2,3,…,n}
約定a1端為隊頭,an端為隊尾
基本操作:InitQueue(&Q); QueueEmpty(Q);
QueueLength(Q); GetHead(Q, &e);
EnQueue(&Q, e); DeQueue(&Q, &e);
ClearQueue(&Q);
QueueTraverse(Q, Visit());
DestroyQueue(&Q);
}ADT Queue -
隊頭:允許洗掉的一端
-
隊尾:允許插入的一端
-
空佇列:沒有元素的佇列
-
雙端佇列:限定插入和洗掉操作在表兩端進行的線性表
-
輸出受限佇列:一端允許插入和洗掉,另一端只允許插入,
-
輸入受限佇列:一端允許插入和洗掉,另一端只允許洗掉,
存盤結構
-
鏈佇列
使用二個指標分別記錄隊頭和隊尾的當前位置
設立一個頭結點,并令頭指標指向頭結點,頭結點的指標域指向隊頭元素所在的結點
鏈佇列的判空條件:頭指標和尾指標均指向頭結點- 鏈佇列型別定義
typedef struct QNode{
QElemType data;
struct QNode *next;
}QNode,*QueuePtr;
typedef struct {
QueuePtr front; //頭指標
QueuePtr rear; //尾指標
}LinkQueue;
- 基本操作
- 鏈佇列入隊
Status EnQueue(LinkQueue &Q, ElemType e)
{
p=(QueuePtr)malloc(sizeof(QNode));
if(!p) exit(OVERFLOW);
p->data=e; p->next=NULL;
Q.rear->next=p;
Q.rear=p; //尾指標指向新的尾結點
return OK;
}// EnQueue
- 鏈佇列入出隊
Status DeQueue(LinkQueue &Q, ElemType &e)
{
if(Q.rear == Q.front) return ERROR;
p=Q.front->next;
e=p->data;
Q.front->next=p->next;
if(Q.rear==p) Q.rear=Q.front;
//若隊頭元素是佇列中唯一的一個元素, 則洗掉該結點后//還需要修改尾指標,讓它指向頭結點
free(p);
return OK;
} // DeQueue
-
順序佇列
-
普通順序佇列
用一組地址連續的存盤單元依次存盤從隊頭到隊尾的資料元素,
- 順序佇列型別定義
-
#define MAXQSIZE 100
typedef struct {
QElemType *base; //存盤空間基地址
int front;//隊頭指標,指向隊頭元素
int rear;//隊尾指標,指向隊尾元素的下一個位置
}SqQueue;
- 假上溢現象
- 回圈佇列
- 存盤結構定義
- 少用一個元素空間,約定佇列頭指標在隊尾指標下一個位置為佇列滿
#define MAXQSIZE 100
typedef int QElemType;
typedef struct {
QElemType* base; //存盤空間基地址
int front;//隊頭指標,指向隊頭元素
int rear;//隊尾指標,指向隊尾元素的下一個位置
}SqQueue;
- 另設標志位區別佇列空、滿
typedef struct {
ElemType *base;
int front;
int rear;
int tag;
}SqQueue;
- 基本操作
- 初始化佇列
Status InitSqQueue(SqQueue& Q)//初始化佇列
{
Q.base = (QElemType*)malloc(MAXQSIZE * sizeof(QElemType));
if (Q.base == NULL)
exit(OVERFLOW);
Q.front = Q.rear = 0;//隊頭隊尾指標都指向0
return OK;
}
- 求隊長
int SqQueueLength(SqQueue Q)//求隊長
{
return(Q.rear - Q.front + MAXQSIZE) % MAXQSIZE;
}
- 進隊
Status EnSqQueue(SqQueue& Q, QElemType e)//進隊操作
{
if ((Q.rear + 1) % MAXQSIZE == Q.front) //佇列滿的判定條件(防止隊滿和隊空無法區分,留下一個位置不用
return ERROR; //隊滿直接報錯,不再申請更大的記憶體
else
{
Q.base[Q.rear] = e;
Q.rear = (Q.rear + 1) % MAXQSIZE;//隊尾指標后移,%MAXQSIZE使下標首尾相接
return OK;
}
}
- 出隊
Status DeQueue(SqQueue& Q, QElemType& e)//出隊操作
{
if (Q.front == Q.rear) //隊空的判定條件
return ERROR; //隊空報錯
else
{
e = Q.base[Q.front];
Q.front = (Q.front + 1) % MAXQSIZE;
return OK;
}
}
- 判空
Status SqQueueEmpty(SqQueue Q)//回圈佇列的判空操作
{
if (Q.rear == Q.front)
return TRUE;
else
return FALSE;
}
- 取隊頭元素
Status GetSqHead(SqQueue Q, QElemType& e)//取隊頭元素
{
if (Q.rear == Q.front)
return ERROR;
else
{
e = Q.base[Q.front];
return TRUE;
}
}
- 清空佇列
Status ClearSqQueue(SqQueue& Q)//清空佇列
{
Q.rear = Q.front;
return OK;
}
- 銷毀佇列
Status DestroySqQueue(SqQueue& Q)//銷毀佇列
{
free(Q.base);
Q.front = Q.rear = 0;
return OK;
}
- 佇列的遍歷
Status SqQueueTraverse(SqQueue Q, Status (*visit)(QElemType))
{
int i;
for (i = Q.front; i != Q.rear; i = (i + 1) % MAXQSIZE)
{visit(Q.base[i]);}
return OK;
}
串
基本概念及術語
概念
-
串:由零個或多個字符組成的有限序列,記為:s= ‘a1 a2…an’ (n>=0)
-
串名: s
-
串值: a1a2a3……an
-
串長: n
-
空串:串長為0的串,用Φ表示
-
子串:串中任意個連續的字符組成的子序列
- 串是其自身的子串
- 空串是任意串的子串
-
主串:包含子串的串
-
字符在串中的位置:字符在串中的序號
-
子串在主串中的位置:子串的第1個字符在主串中的位置
-
空格串:由一個或多個空格組成的串,其長度為空格個數
-
串相等:兩個串長度相等且各個對應位置的字符也相等
ADT
ADT String {
資料物件:D={ai| ai ?CharacterSet, i=1,2,…,n, n?0}
資料關系:R1={< ai-1 ,ai >| ai-1 , ai ? D,i=2,3,…,n}
基本操作:
StrAssign(&T, chars); StrCopy(&T,S);
StrEmpty(S); StrCompare(S,T);
StrLength(S); ClearString(&S);
Concat(&T,S1,S2); Substring(&Sub, S, pos,len);
Index(S,T,pos); Replace(&S,T,V);
StrInsert(&S, pos, T); StrDelete(&S, pos, len);
DestroyString(&S);
}ADT String;
基本操作
最小操作子集
- 串賦值StrAssign
- 串比較StrCompare
- 求串長StrLength
- 串聯接Concat
- 求子串SubString
其他操作
- 串拷貝StrCopy
- 串判空StrEmpty
- 定位串Index
- 串替換Replace
- 串插入StrInsert
- 串洗掉StrDelete
- 串清空ClearString
- 銷毀串DestroyStr
串的表示方法
順序存盤結構
-
定長存盤結構
- 特點:用長度固定的連續單元依次存盤串值的字符序列
- 以下標為0的陣列分量存放實際串長——PASCAL
- 串值后加一個不計入串長的結束標記字符——C、C++中用‘\0’作串的結束標記
-
堆分配存盤結構
- 特點:采用動態字符陣列存放串值,此時不必為陣列預定義大小,以串長動態分配陣列空間
- 資料型別定義
typedef struct {
char *ch;
int length;
}HString;
鏈式存盤結構
-
塊鏈結構
- 資料型別定義
#define CHUNKSIZE 80 // 可由用戶定義的塊大小
typedef struct Chunk { // 結點結構
char ch[CUNKSIZE];
struct Chunk *next;
} Chunk;
typedef struct { // 串的鏈表結構
Chunk *head, *tail; //串的頭和尾指標,便于聯結操作
int curlen; // 串的當前長度
} LString;
串的應用
文本編輯
- 實質:修改字符資料的形式或格式
- 基本操作:輸入、查找、修改、洗掉、輸出
陣列和廣義表
陣列
陣列的定義
-
ADT
ADT Array {
資料物件:ji=0, …, bi – 1, i = 1, 2, …, n,
D={ | ∈ElemSet }
資料關系:R = {R1, R2, …, Rn}
Ri={ |0 ≤ jk ≤ bk–1, 1 ≤ k ≤n且
k!=i, 0 ≤ ji ≤ bi–2, ∈D, i=1,2,…,n}
基本操作:
InitArray(&A, n, bound1, …, boundn)
DestroyArray(&A)
Value(A, &e, index1, …, indexn)
Assign(&A, e, index1, …, indexn)
}ADT Array -
n維陣列是線性表的擴展
- 當n=1,n維陣列退化成順序表
- 當n>1,n維陣列可看成表中資料元素是n-1維陣列的線性表
陣列的順序表示
因為陣列一般不做插入/洗掉操作,所以用順序結構表示陣列是很自然的,
-
特點:用一組地址連續的存盤單元按照某種規則存放陣列中的資料元素,
-
2種順序(順序存盤方式)
- 以行序為主(低下標優先法)
- 以列序為主(高下標優先法)
-
元素地址的計算
-
要素
- ①陣列的起始地址(即基地址)
- ②陣列維數和各維的長度;
- ③陣列中每個元素所占的存盤單元
-
計算方法
-
二維
-
行主序:LOC(i,j) = LOC(0,0) + ( b2*i + j ) * L
-
列主序:LOC(i,j) = LOC(0,0) + ( b1*j + i ) * L
-
二維陣列元素地址的通式
-
行優先存盤時的地址公式為:
- LOC(aij)=LOC(ac1,c2)+[(i-c1)*(d2-c2+1)+j-c2)]*L
-
列優先存盤的通式為:
- LOC(aij)=LOC(ac1,c2)+[(j-c2)*(d1-c1+1)+i-c1)]*L
-
-
-
多維
- 設各維長度分別為b1, b2, b3, …, bn,每個元素占L個存盤單元, 起始地址是LOC(0,0,…,0)
- LOC (j1,j2,…,jn ) = LOC(0,0,…,0) + (b2b3…bn * j1+ b3b4*…bn * j2+ ……+ bnjn-1 + jn ) * L
-
-
隨機存盤結構
陣列元素的存盤位置是其下標的線性函式,由于計算各個元素存盤位置的時間相等,所以存盤陣列中任一元素的時間也相等,具有這一特點的存盤結構為隨機存盤結構,
-
-
實作
#define MAX_ARRAY_DIM 8
typedef struct {
ElemType *base; //存盤空間基址
int dim; //陣列維數
int *bounds; //陣列維界基址
int *constants; //陣列映象函式常量{Ci}基址
} Array;
矩陣的壓縮存盤
壓縮存盤:為多個值相同的元素只分配一個存盤空間,對零元素不分配空間,
-
特殊矩陣:值相同的元素或零元素在矩陣中分布有一定規律,如三角矩陣、對角矩陣,
-
對稱矩陣
n階矩陣A中元素滿足性質a[i][j]=a[j][i] (1 ≤i, j≤ n)
-
壓縮存盤
為每一對對稱元素分配 個存盤空間. n2 ?n(n+1)/2
用行主序的下(上)三角陣來存盤對稱矩陣的元素,
sa[k](0 ≤ k ≤ n(n+1)/2-1) 為對稱矩陣的壓縮存盤結構
-
-
上(下)三角陣
下(上)三角(不含對角線)元素為常數c或0的n階矩陣
-
壓縮存盤
存盤上(下)三角中的元素和常數c
用行主序存盤上(下)三角陣的元素
sak 為上(下)三角陣的壓縮存盤結構
-
-
對角矩陣
所有非零元素都集中在以主對角線為中心的帶狀區域,其他元素為0,
-
壓縮存盤
用行主序存盤帶狀區域的非0元素
-
-
-
稀疏矩陣:值相同的元素或零元素在矩陣中分布沒有一定規律,
-
稀疏因子
設m行n列的矩陣含t個非零元素,定義δ=t/(m*n)為稀疏因子,則? ? 0.05 的矩陣為稀疏矩陣,
-
稀疏矩陣的壓縮存盤
-
表示
-
三元組( i,j,aij )
- 三元組的C語言描述
-
-
typedef struct {
int i,j;
ElemType e;
}Triple;
- 三元組順序表的C語言描述
#define MAXSIZE 1250
typedef struct{
Triple data[MAXSIZE+1]; //data[0]未用
int mu,nu,tu;
}TSMatrix;
- 行邏輯鏈接的順序表
需求:隨機存取任意一行的非0元
方法:記住矩陣每一行第一個非0元在三元組順序表中的位置
設陣列rpos[1..n]:矩陣中每行第一個非零元素的起始位置
rpos[1]=1;
rpos[row]=rpos[row-1]+第row-1行的非零元素個數
第i行所有非0元在data中的位置:rpos[i]..rpos[i+1]-1
行邏輯鏈接順序表:在稀疏矩陣的三元組順序表中設定指示行資訊的輔助陣列rpos
typedef struct{
Triple data[MAXSIZE+1];
int rpos[MAXRC+1];//各行第1個非零元位置表,rpos[0]未用
int mu,nu,tu;
}RLSMatrix;
- 十字鏈表
- 轉置
- 稀疏矩陣轉置方法一
Status TransposeSMatrix(TSMatrix M,TSMatrix &T)
{ T.mu=M.nu;T.nu=M.mu;T.tu=M.tu;
if(T.tu)
{ q=1;
for(col=1;col<=M.nu;++col)
for(p=1;p<=M.tu;++p)
if(M.data[p].j==col){
T.data[q]=(M.data[p].j, M.data[p].i, M.data[p].e);
++q;}
} return OK;
}//TransposeSMatrix
- 稀疏矩陣轉置方法二
Status FastTransposeSMatrix(TSMatrix M,TSMatrix &T)
{ T.mu=M.nu;T.nu=M.mu;T.tu=M.tu;
if(T.tu)
{ for(col=1;col<=M.nu;++col) num[col]=0;
for(t=1;t<=M.tu;++t) ++num[M.data[t].j];
cpot[1]=1;
for(col=2;col<=M.nu;++col)
cpot[col]=cpot[col-1]+num[col-1];
for(p=1;p<=M.tu;++p) {
col=M.data[p].j; q=cpot[col];
T.data[q]=( M.data[p].j, M.data[p].i, M.data[p].e );
++cpot[col]; }//for
}//if
return OK;
}//FastTransposeSMatrix
廣義表
定義
廣義表(串列):n (?0)個元素組成的有限序列,記作
LS = (α1, α2, …, αn)
其中αi 可以是單個元素(原子),也可以是廣義表(子表)
- 表頭(head):n>0時,廣義表的第一個元素
- 表尾(tail):除第一個元素外的所有其它元素組成的表
- 空表:n = 0 的廣義表
- 廣義表長度:廣義表中元素的個數
- 廣義表深度:廣義表中括號的重數
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/243620.html
標籤:其他