七、共享存盤原理
1、Volumes介紹
1)、Pod Volumes

首先來看一下Pod Volumes的使用場景:
- 場景一:如果pod中的某一個容器在運行時例外退出,被kubelet重新拉起之后,如何保證之前容器產生的重要資料沒有丟失?
- 場景二:如果同一個pod中的多個容器想要共享資料,應該如何去做?
以上兩個場景,其實都可以借助Volumes來很好地解決,接下來首先看一下Pod Volumes的常見型別:
- 本地存盤,常用的有emptydir/hostpath
- 網路存盤:網路存盤當前的實作方式有兩種,一種是in-tree,它的實作的代碼是放在K8s代碼倉庫中的,隨著K8s對存盤型別支持的增多,這種方式會給K8s本身的維護和發展帶來很大的負擔;而第二種實作方式是out-of-tree,它的實作其實是給K8s本身解耦的,通過抽象介面將不同存盤的driver實作從K8s代碼倉庫中剝離
- Projected Volumes:它其實是將一些配置資訊,如secret/configmap用卷的形式掛載在容器中,讓容器中的程式可以通過POSIX介面來訪問配置資料
- PV與PVC
2)、PV

既然已經有了Pod Volumes,為什么又要引入PV呢?Pod中宣告的volume生命周期與Pod相同的,以下有幾種常見的場景:
- 場景一:pod重建銷毀,如用Deployment管理的pod,在做鏡像升級的程序中,會產生新的pod并且洗掉舊的pod,那新舊pod之間如何復用資料?
- 場景二:宿主機宕機的時候,要把上面的pod遷移,這個時候StatefulSet管理的pod,其實已經實作了帶卷遷移的語意,這時通過Pod Volumes顯然是做不到的
- 場景三:多個pod之間,如果想要共享資料,應該如何去宣告呢?我們知道,同一個pod中多個容器想共享資料,可以借助Pod Volumes來解決;當多個pod想共享資料時,Pod Volumes就很難去表達這種語意
- 場景四:如果要想對資料卷做一些功能擴展性,如:snapshot、resize這些功能,又應該如何去做呢?
以上場景中,通過Pod Volumes很難準確地表達它的復用/共享語意,對它的擴展也比較困難,因此K8s中又引入了Persistent Volumes概念,它可以將存盤和計算分離,通過不同的組件來管理存盤資源和計算資源,然后解耦pod和Volume之間生命周期的關聯,這樣,當把pod洗掉之后,它使用的PV仍然存在,還可以被新建的pod復用
3)、PVC

用戶在使用PV時其實是通過PVC,為什么有了PV又設計了PVC呢?主要原因是為了簡化K8s用戶對存盤的使用方式,做到職責分離,通常用戶在使用存盤的時候,只用宣告所需的存盤大小以及訪問模式
訪問模式是什么?其實就是:我要使用的存盤是可以被多個node共享還是只能單node獨占訪問(注意是node level而不是pod level)?只讀還是讀寫訪問?用戶只用關心這些東西,與存盤相關的實作細節是不需要關心的
通過PVC和PV的概念,將用戶需求和實作細節解耦開,用戶只用通過PVC宣告自己的存盤需求,PV是有集群管理員和存盤相關團隊來統一運維和管控,這樣的話,就簡化了用戶使用存盤的方式
既然PV是由集群管理員統一管控的,接下來就看一下PV這個物件是怎么產生的
4)、Static Volume Provisioning
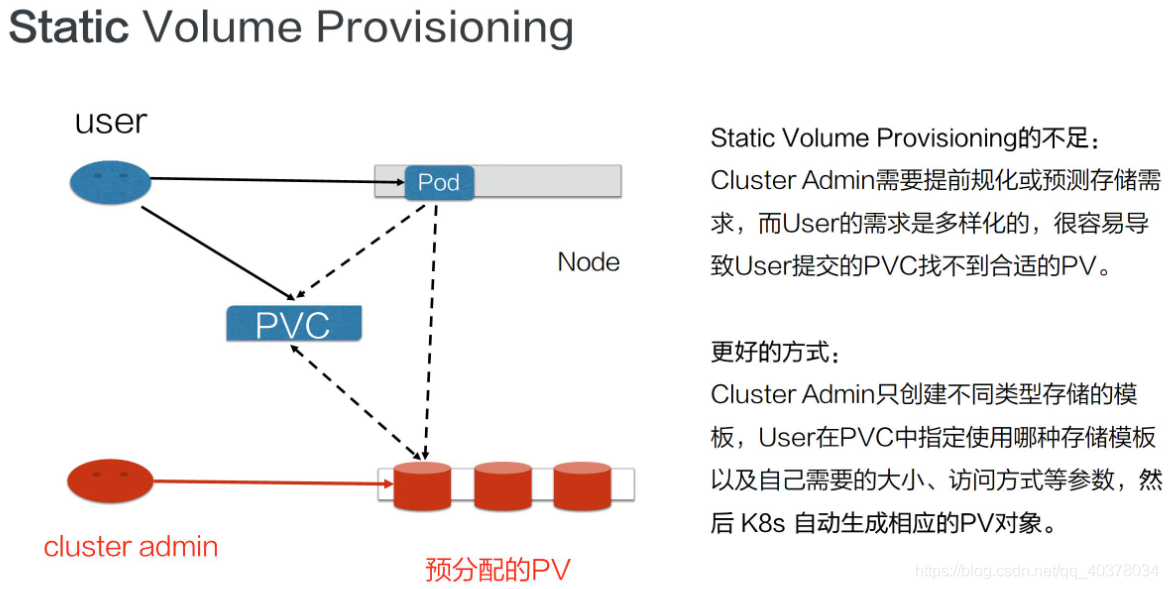
靜態產生方式(靜態Provisioning):由集群管理員事先去規劃這個集群中的用戶會怎樣使用存盤,它會先預分配一些存盤,也就是預先創建一些PV;然后用戶在提交自己的存盤需求(也就是PVC)的時候,K8s內部相關組件會幫助它把PVC和PV做系結;之后用戶再通過pod去使用存盤的時候,就可以通過PVC找到相應的PV,它就可以使用了
靜態產生方式有什么不足呢?可以看到,首先需要集群管理員預分配,預分配其實是很難預測用戶真實需求的,舉一個最簡單的例子:如果用戶需要的是20G,然而集群管理員在分配的時候可能有80G 、100G的,但沒有20G的,這樣就很難滿足用戶的真實需求,也會造成資源浪費
5)、Dynamic Volume Provisioning
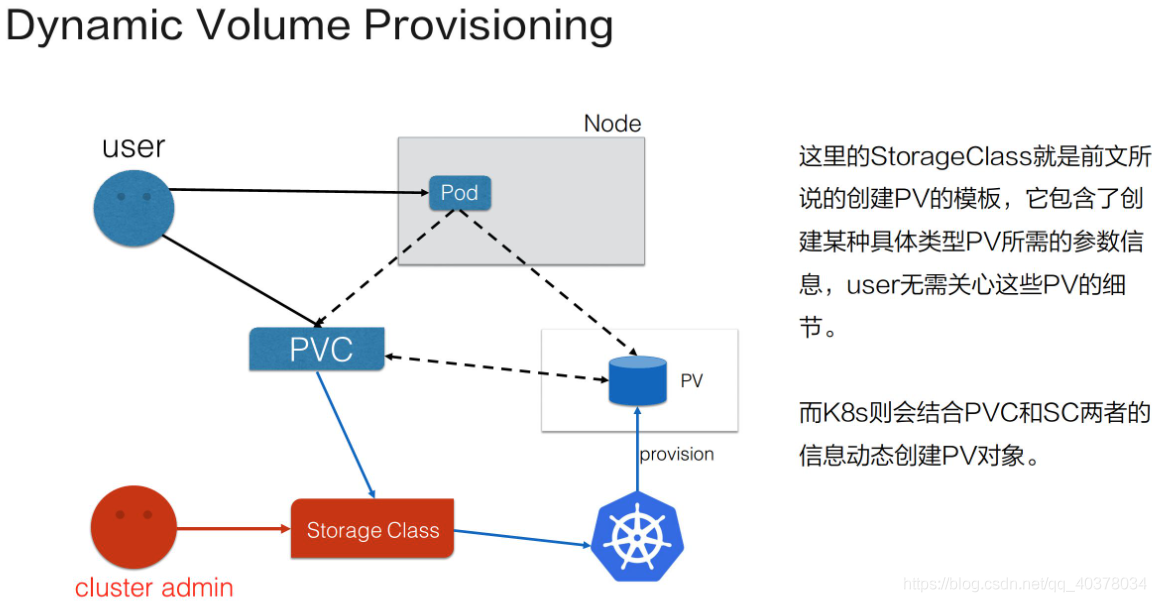
動態供給:就是說現在集群管理員不預分配PV,他寫了一個模板檔案,這個模板檔案是用來表示創建某一型別存盤(塊存盤、檔案存盤等)所需的一些引數,這些引數是用戶不關心的,給存盤本身實作有關的引數,用戶只需要提交自身的存盤需求,也就是PVC檔案,并在PVC中指定使用的存盤模板(StorageClass)
K8s集群中的管控組件,會結合PVC和StorageClass的資訊動態,生成用戶所需要的存盤(PV),將PVC和PV進行系結后,pod就可以使用PV了,通過StorageClass配置生成存盤所需要的存盤模板,再結合用戶的需求動態創建PV物件,做到按需分配,在沒有增加用戶使用難度的同時也解放了集群管理員的運維作業
2、用例解讀
1)、Pod Volumes的使用

在pod yaml檔案中的Volumes欄位中,宣告我們卷的名字以及卷的型別,宣告的兩個卷,一個是用的是emptyDir,另外一個用的是hostPath,這兩種都是本地卷
在容器中應該怎么去使用這個卷呢?它其實可以通過volumeMounts這個欄位,volumeMounts欄位里面指定的name其實就是它使用的哪個卷,mountPath就是容器中的掛載路徑
這里還有個subPath,subPath是什么?先看一下,這兩個容器都指定使用了同一個卷,就是這個cache-volume,那么,在多個容器共享同一個卷的時候,為了隔離資料,我們可以通過subPath來完成這個操作,它會在卷里面建立兩個子目錄,然后容器1往cache下面寫的資料其實都寫在子目錄cache1了,容器2往cache寫的目錄,其資料最侄訓落在這個卷里子目錄下面的cache2下
還有一個readOnly欄位,readOnly的意思其實就是只讀掛載,這個掛載你往掛載點下面實際上是沒有辦法去寫資料的
另外emptyDir、hostPath都是本地存盤,它們之間有什么細微的差別呢?emptyDir其實是在pod創建的程序中會臨時創建的一個目錄,這個目錄隨著pod洗掉也會被洗掉,里面的資料會被清空掉;hostPath顧名思義,其實就是宿主機上的一個路徑,在pod洗掉之后,這個目錄還是存在的,它的資料也不會被丟失,這就是它們兩者之間一個細微的差別
2)、靜態PV使用

靜態PV首先是由管理員來創建的,管理員我們這里以NAS,就是阿里云檔案存盤為例,我需要先在阿里云的檔案存盤控制臺上去創建NAS存盤,然后把NAS存盤的相關資訊要填到PV物件中,這個PV物件預創建出來后,用戶可以通過PVC來宣告自己的存盤需求,然后再去創建pod,創建pod還是通過我們剛才講解的欄位把存盤掛載到某一個容器中的某一個掛載點下面

剛剛創建的阿里云NAS檔案存盤對應的PV,有個比較重要的欄位:capacity,即創建的這個存盤的大小,accessModes,創建出來的這個存盤它的訪問方式
然后有個ReclaimPolicy(PV的回收策略):這塊存盤在被使用后,等它的使用方pod以及PVC被洗掉之后,這個PV是應該被刪掉還是被保留呢?
接下來看看用戶怎么去使用該PV物件,用戶在使用存盤的時候,需要先創建一個PVC物件,PVC物件里面,只需要指定存盤需求,不用關心存盤本身的具體實作細節,存盤需求包括哪些呢?首先是需要的大小,也就是resources.requests.storage;然后是它的訪問方式,即需要這個存盤的訪問方式,這里宣告為ReadWriteMany,也即支持多node讀寫訪問,這也是檔案存盤的典型特性

上圖中左側,可以看到這個宣告:它的size和access mode,跟我們剛才靜態創建這塊PV其實是匹配的,這樣的話,當用戶在提交PVC的時候,K8s集群相關的組件就會把PV的PVC bound到一起,之后,用戶在提交pod yaml的時候,可以在卷里面寫上PVC宣告,在PVC宣告里面可以通過claimName來宣告要用哪個PVC,這時,掛載方式其實跟前面講的一樣,當提交完yaml的時候,它可以通過PVC找到bound著的那個PV,然后就可以用那塊存盤了,這是靜態Provisioning到被pod使用的一個程序
3)、動態PV使用

這個模板檔案叫StorageClass,在StorageClass里面,我們需要填的重要資訊:第一個是provisioner,provisioner其實就是說創建PV和對應的存盤的時候,應該用哪個存盤插件來去創建
這些引數是通過K8s創建存盤的時候,需要指定的一些細節引數,對于這些引數,用戶是不需要關心的,像這里regionld、zoneld、fsType和它的型別,ReclaimPolicy就是動態創建出來的這塊PV,當使用方使用結束、Pod及PVC被洗掉后,這塊PV應該怎么處理,我們這個地方寫的是delete,意思就是說當使用方pod和PVC被洗掉之后,這個PV也會被洗掉掉
接下來看一下,集群管理員提交完 StorageClass,也就是提交創建PV的模板之后,用戶怎么用,首先還是需要寫一個PVC的檔案

PVC的檔案里存盤的大小、訪問模式是不變的,現在需要新加一個欄位,叫StorageClassName,它的意思是指定動態創建PV的模板檔案的名字,這里StorageClassName填的就是上面宣告的csi-disk
在提交完PVC之后,K8s集群中的相關組件就會根據PVC以及對應的StorageClass動態生成這塊PV給這個PVC做一個系結,之后用戶在提交自己的yaml時,用法和接下來的流程和前面的靜態使用方式是一樣的,通過PVC找到我們動態創建的PV,然后把它掛載到相應的容器中就可以使用了
4)、PV Spec重要欄位決議

Capacity:存盤物件的大小
AccessModes使用這個PV的方式,它有三種使用方式:
- 一種是單node讀寫訪問
- 第二種是多個node只讀訪問,是常見的一種資料的共享方式
- 第三種是多個node上讀寫訪問
用戶在提交PVC的時候,最重要的兩個欄位:Capacity和AccessModes,在提交PVC后,K8s集群中的相關組件是如何去找到合適的PV呢?首先它是通過為PV建立的AccessModes索引找到所有能夠滿足用戶的PVC里面的AccessModes要求的PV list,然后根據PVC的Capacity、StorageClassName、Label Selector進一步篩選PV,如果滿足條件的PV有多個,選擇PV的size最小的,accessmodes串列最短的PV,也即最小適合原則
ReclaimPolicy:用戶方PV的PVC在洗掉之后,PV應該做如何處理?常見的有兩種方式
- 第一種方式delete,也就是說PVC被洗掉之后,PV也會被洗掉
- 第二種方式Retain,就是保留,保留之后,后面這個PV需要管理員來手動處理
StorageClassName:動態Provisioning時必須指定的一個欄位,就是說要指定到呼叫哪一個模板檔案來生成PV
NodeAffinity:就是說創建出來的PV,它能被哪些node去掛載使用,其實是有限制的,然后通過NodeAffinity來宣告對node的限制,這樣其實對使用該PV的pod調度也有限制,就是說pod必須要調度到這些能訪問PV的node上,才能使用這塊PV
5)、PV狀態流轉
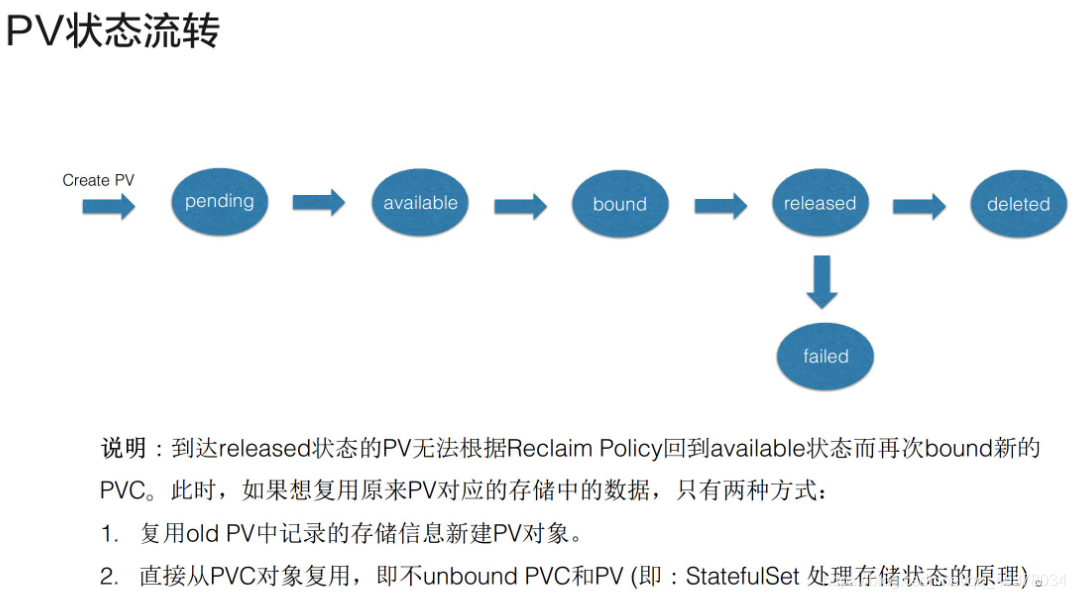
首先在創建PV物件后,它會處在短暫的pending狀態;等真正的PV創建好之后,它就處在available狀態
available狀態意思就是可以使用的狀態,用戶在提交PVC之后,被K8s相關組件做完bound(即:找到相應的PV),這個時候PV和PVC就結合到一起了,此時兩者都處在bound狀態,當用戶在使用完PVC,將其洗掉后,這個PV就處在released狀態,之后它應該被洗掉還是被保留呢?這個就會依賴ReclaimPolicy
這里有一個點需要特別說明一下:當PV已經處在released狀態下,它是沒有辦法直接回到available狀態,也就是說接下來無法被一個新的PVC去做系結
如果我們想把已經released的PV復用,我們這個時候通常應該怎么去做呢?第一種方式:我們可以新建一個PV物件,然后把之前的released的PV的相關欄位的資訊填到新的PV物件里面,這樣的話,這個PV就可以結合新的PVC了;第二種是在洗掉pod之后,不要去洗掉PVC物件,這樣給PV系結的PVC還是存在的,下次pod使用的時候,就可以直接通過PVC去復用,K8s中的StatefulSet管理的Pod帶存盤的遷移就是通過這種方式
八、可觀測性:你的應用健康嗎?
1、需求來源

2、Liveness與Readiness
1)、初識Liveness與Readiness
Readiness probe也叫就緒探針,用來判斷一個pod是否處在就緒狀態,當一個pod處在就緒狀態的時候,它才能夠對外提供相應的服務,也就是說接入層的流量才能打到相應的pod,當這個pod不處在就緒狀態的時候,接入層會把相應的流量從這個pod上面進行摘除
如下圖其實就是一個Readiness就緒的一個例子:
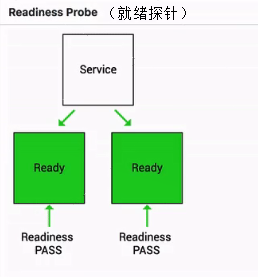
當這個pod指標判斷一直處在失敗狀態的時候,其實接入層的流量不會打到現在這個pod上
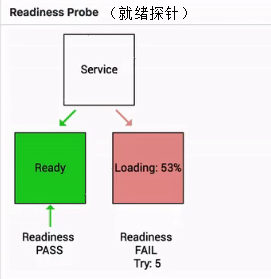
當這個pod的狀態從FAIL的狀態轉換成success的狀態時,它才能夠真實地承載這個流量
Liveness指標也是類似的,它是存活探針,用來判斷一個pod是否處在存活狀態
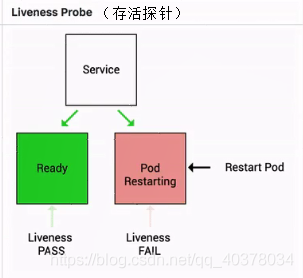
當一個pod處在不存活狀態時會由上層的判斷機制來判斷這個pod是否需要被重新拉起,那如果上層配置的重啟策略是restart always的話,那么此時這個pod會直接被重新拉起
2)、使用方式
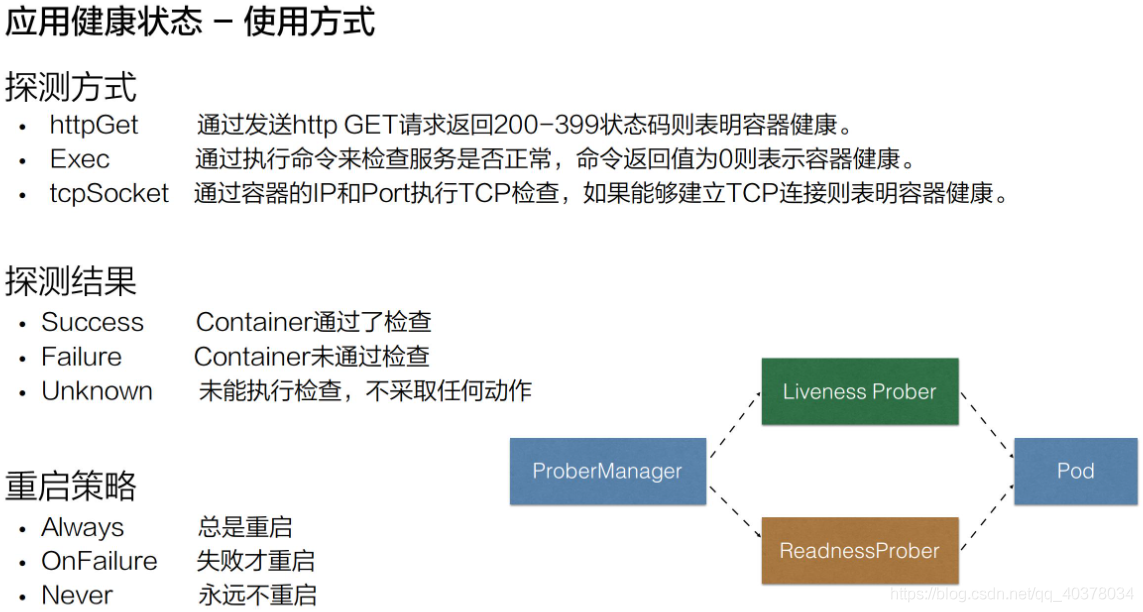
Liveness指標和Readiness指標支持三種不同的探測方式:
- httpGet:它是通過發送http Get請求來進行判斷的,當回傳碼是200-399之間的狀態碼時,標識這個應用是健康的
- Exec:它是通過執行容器中的一個命令來判斷當前的服務是否是正常的,當命令列的回傳結果是0,則標識容器是健康的
- tcpSocket:是通過探測容器的IP和Port進行TCP健康檢查,如果這個TCP的連接能夠正常被建立,那么標識當前這個容器是健康的
從探測結果來講主要分為三種:
- 第一種是success,當狀態是success的時候,表示container通過了健康檢查,也就是Liveness probe或Readiness probe是正常的一個狀態
- 第二種是Failure,Failure表示的是這個container沒有通過健康檢查,如果沒有通過健康檢查的話,那么此時就會進行相應的一個處理,那在Readiness處理的一個方式就是通過service,service層將沒有通過Readiness的pod進行摘除,而Liveness就是將這個 pod 進行重新拉起,或者是洗掉
- 第三種狀態是Unknown,Unknown是表示說當前的執行的機制沒有進行完整的一個執行,可能是因為類似像超時或者像一些腳本沒有及時回傳,那么此時Readiness probe或Liveness probe會不做任何的一個操作,會等待下一次的機制來進行檢驗
3)、Pod Probe Spec

1)exec
如上圖所示,這是一個Liveness probe,它里面配置了一個exec的一個診斷,接下來,它又配置了一個command的欄位,這個command欄位里面通過cat一個具體的檔案來判斷當前Liveness probe的狀態,當這個檔案里面回傳的結果是0時,或者說這個命令回傳是0時,它會認為此時這個pod是處在健康的一個狀態
2)httpGet
httpGet里面有一個欄位是路徑,第二個欄位是port,第三個是headers,這個地方有時需要通過類似像header頭的一個機制做health的一個判斷時,需要配置這個header,通常情況下,可能只需要通過health和port的方式就可以了
3)tcpSocket
tcpSocket只需要設定一個檢測的埠,像這個例子里面使用的是8080埠,當這個8080埠tcp connect連接正常被建立的時候,那tecSocket Probe會認為是健康的一個狀態
4)此外還有如下的五個引數,是Global的引數
-
第一個引數叫initialDelaySeconds,它表示的是說這個pod啟動延遲多久進行一次檢查,比如說現在有一個Java的應用,它啟動的時間可能會比較長,所以前期,可能有一段時間是沒有辦法被檢測的,而這個時間又是可預期的,那這時可能要設定一下initialDelaySeconds
-
第二個是periodSeconds,它表示的是檢測的時間間隔,正常默認的這個值是10秒
-
第三個欄位是timeoutSeconds,它表示的是檢測的超時時間,當超時時間之內沒有檢測成功,那它會認為是失敗的一個狀態
-
第四個是successThreshold,它表示的是:當這個pod從探測失敗到再一次判斷探測成功,所需要的閾值次數,默認情況下是1次,表示原本是失敗的,那接下來探測這一次成功了,就會認為這個pod是處在一個探針狀態正常的一個狀態
-
最后一個引數是failureThreshold,它表示的是探測失敗的重試次數,默認值是3,表示的是當從一個健康的狀態連續探測3次失敗,那此時會判斷當前這個pod的狀態處在一個失敗的狀態
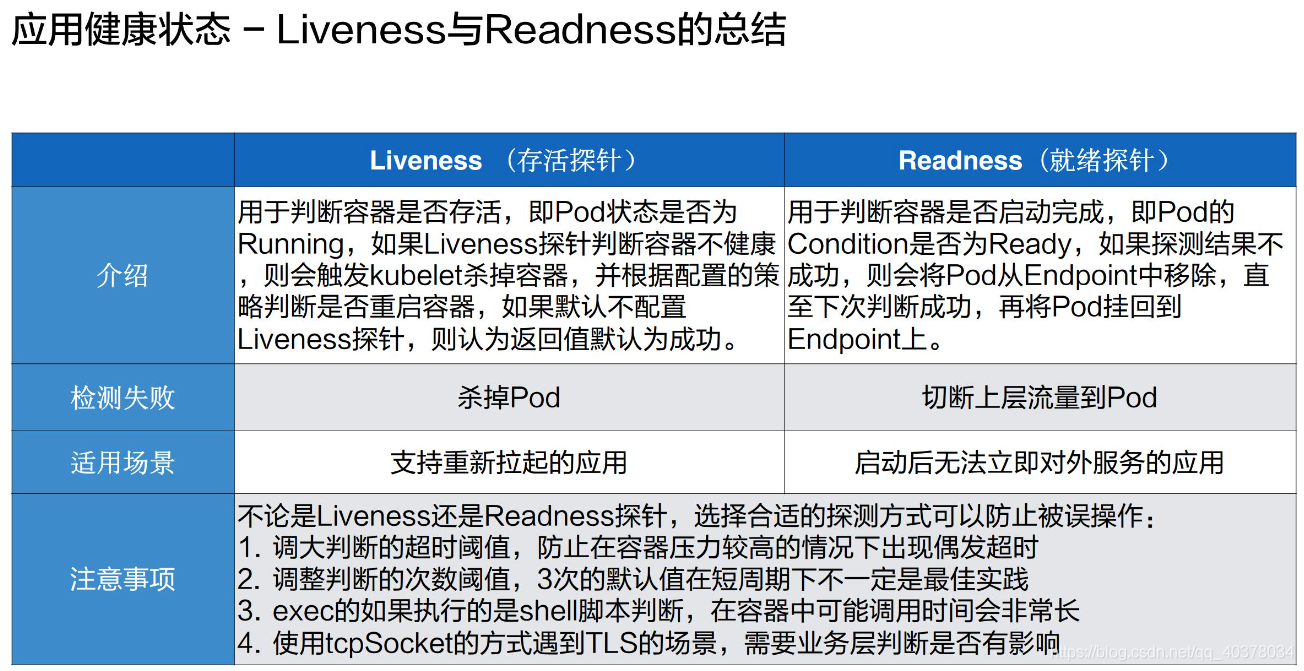
4)、Liveness與Readiness總結
3、問題診斷

實際上是一個Pod的一個生命周期,剛開始它處在一個pending的狀態,那接下來可能會轉換到類似像running,也可能轉換到Unknown,甚至可以轉換到failed,然后,當running執行了一段時間之后,它可以轉換到類似像successded或者是failed,然后當出現在unknown這個狀態時,可能由于一些狀態的恢復,它會重新恢復到running或者successded或者是failed
其實K8s整體的一個狀態就是基于這種類似像狀態機的一個機制進行轉換的,而不同狀態之間的轉化都會在相應的K8s物件上面留下來類似像Status或者像Conditions的一些欄位來進行表示

九、可觀測性:監控與日志
1、監控
1)、監控型別

2)、Kubernetes的監控演進
在早期,也就是1.10以前的K8s版本,大家都會使用類似像Heapster這樣的組件來去進行監控的采集,Heapster的設計原理其實也比較簡單
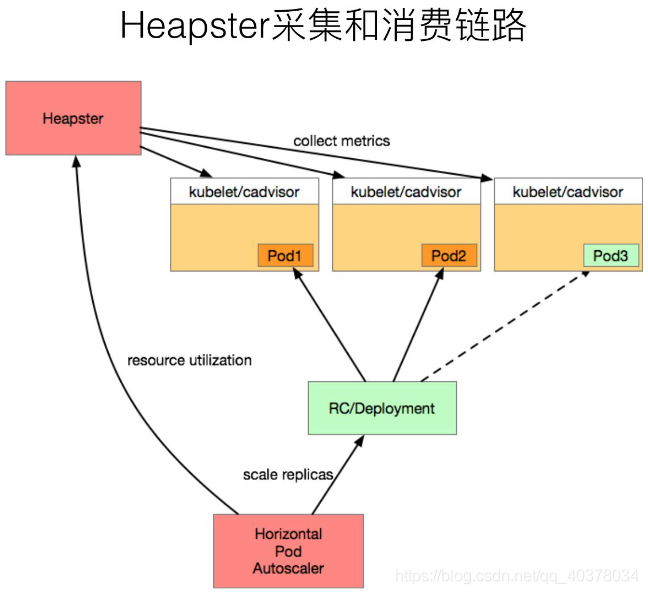
首先,在每一個Kubernetes上面有一個包裹好的cadvisor,這個cadvisor是負責資料采集的組件,當cadvisor把資料采集完成,Kubernetes會把cadvisor采集到的資料進行包裹,暴露成相應的API,在早期的時候,實際上是有三種不同的API:
- 第一種是summary介面
- 第二種是kubelet介面
- 第三種是Prometheus介面
這三種介面,其實對應的資料源都是cadvisor,只是資料格式有所不同,而在Heapster里面,其實支持了summary介面和kubelet兩種資料采集介面,Heapster會定期去每一個節點拉取資料,在自己的記憶體里面進行聚合,然后再暴露相應的service,供上層的消費者進行使用,在K8s中比較常見的消費者,類似像dashboard,或者是HPA-Controller,它通過呼叫service獲取相應的監控資料,來實作相應的彈性伸縮,以及監控資料的一個展示
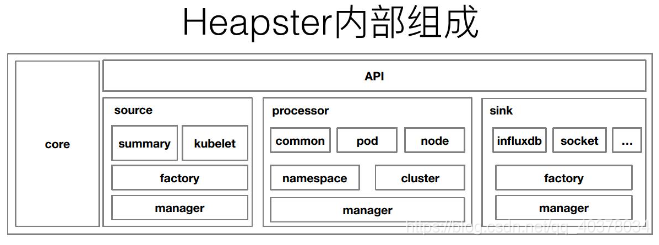
上圖是Heapster內部的一個架構,分為幾個部分,第一個部分是core部分,然后上層是有一個通過標準的http或者https暴露的這個API,然后中間是source的部分,source部分相當于是采集資料暴露的不同的介面,然后processor的部分是進行資料轉換以及資料聚合的部分,最后是sink部分,sink部分是負責資料離線的,這個是早期的Heapster的一個應用的架構,那到后期的時候呢,K8s做了這個監控介面的一個標準化,逐漸就把Heapster進行了裁剪,轉化成了metrics-server
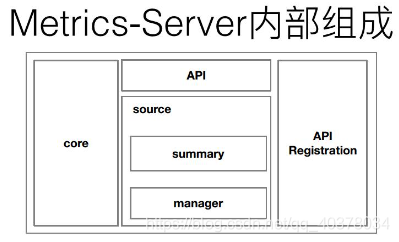
目前0.3.1版本的metrics-server大致的一個結構就變成了上圖這樣,是非常簡單的:有一個core層、中間的source層,以及簡單的API層,額外增加了API Registration這層,這層的作用就是它可以把相應的資料介面注冊到K8s的API server之上,以后客戶不再需要通過這個API層去訪問metrics-server,而是可以通過這個API注冊層,通過API server訪問API注冊層,再到metrics-server,這樣的話,真正的資料消費方可能感知到的并不是一個metrics-server,而是說感知到的是實作了這樣一個API的具體的實作,而這個實作是metrics-server,這個就是metrics-server改動最大的一個地方
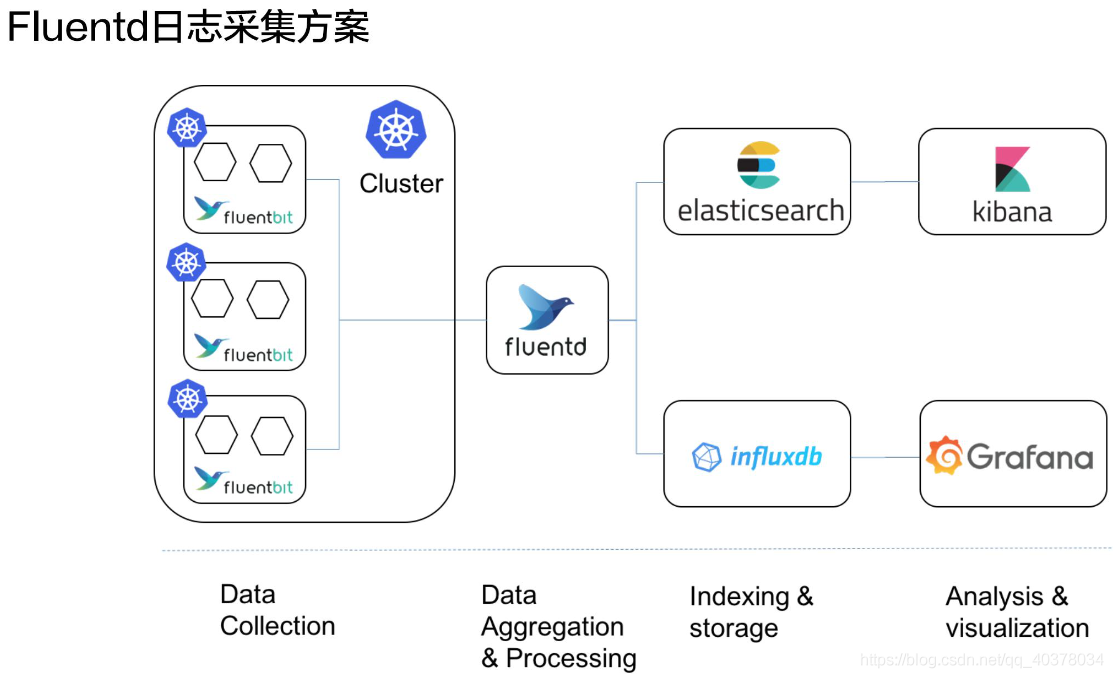
2、日志

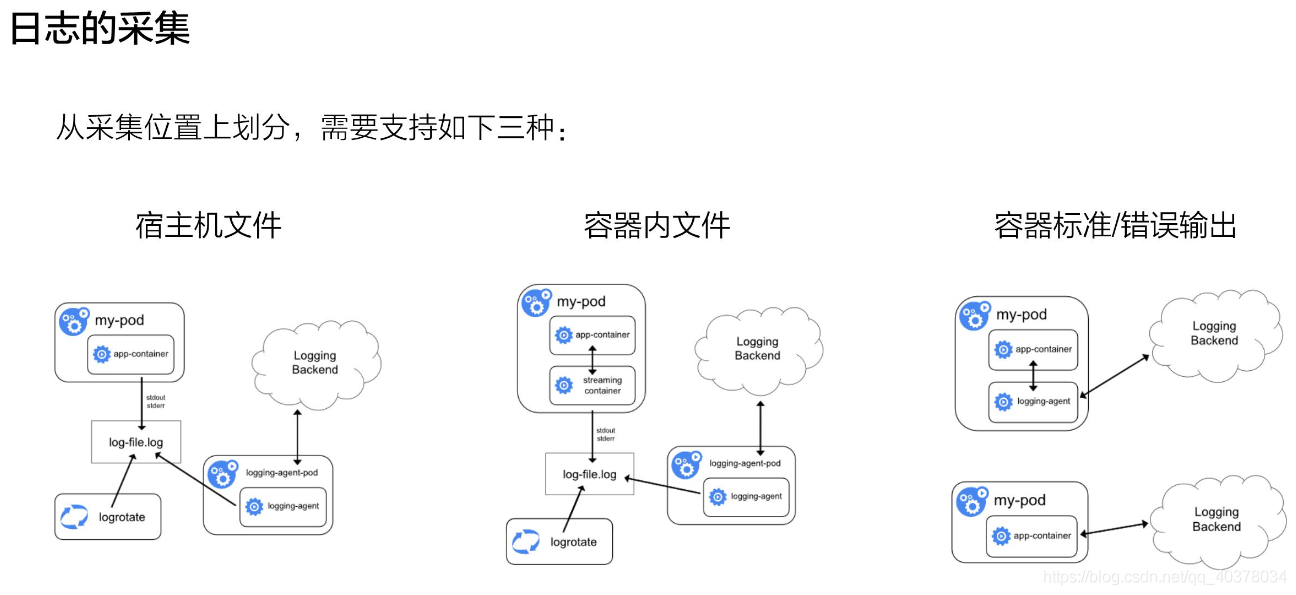
日志采集從采集位置是哪個劃分,需要支持如下三種:
-
首先是宿主機檔案,這種場景比較常見的是說我的這個容器里面,通過類似像volume,把日志檔案寫到了宿主機之上,通過宿主機的日志輪轉的策略進行日志的輪轉,然后再通過我的宿主機上的這個agent進行采集
-
第二種是容器內有日志檔案,那這種常見方式怎么處理呢,比較常見的一個方式是說我通過一個Sidecar的streaming的container,轉寫到stdout,通過stdout寫到相應的log-file,然后再通過本地的一個日志輪轉,然后以及外部的一個agent采集
-
第三種我們直接寫到stdout,這種比較常見的一個策略,第一種就是直接我拿這個agent去采集到遠端,第二種我直接通過類似像一些sls的標準API采集到遠端
課程地址:https://edu.aliyun.com/roadmap/cloudnative?spm=5176.11399608.aliyun-edu-index-014.4.dc2c4679O3eIId#suit
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/244257.html
標籤:其他
上一篇:電商秒殺設計解決方案