年度催淚大劇:2020,我一定會回來的!
年度最佳拒絕白嫖獎:一起學爬蟲(Python) — 19 年輕人,進來學自動化
略顯夸張,略顯,
但是還是希望,也不是希望吧,是卑微地渴望各位姥爺,給個贊吧T-T

論爬某媽媽的另一種方式
- 前言
- 自動化獲取cookies
- 獲取cookies!
- 偷偷地潛入!
- 擴展小知識 - 快速調整字體大小
前言




我被綁架了,竟然三天沒有更新,這個…
對,就理解為我被綁架了吧!
最近不是有那個年度征文嘛,然后我就參加了一下,畢竟……
高情商:你寫的那么好,一下就吸引了一堆小學生來看,一定能獲取評委的認可的!
低情商:就你還參加個xx

所以希望各位能高抬貴手,讓我輸得不要太慘,拜托啦~~

就億次!!!
點這里:2020,我一定會回來的!
那么…點贊的事情,就拜托了,輕一點哦~
自動化獲取cookies
前景回顧:蟬媽媽,嘿嘿
至于為什么要用自動化,這里我們選擇selenium,不過想要實作自動化操作有很多種方法,而且最近不是新出了一個更方便的嘛,我沒記名字,你打我啊,
不過這里我們先用selenium對整體的思路進行一個理解,日后再進行新的方式的傳銷 傳播,
我們上次爬取蟬媽媽的商品資訊的時候,是分了兩大步,
第一步是獲取了登陸后的cookie,
第二步是用帶有登錄后cookie的headers進行一個post請求,然后獲取了那些我們需要的,也可以是不需要的,但是這里假裝我們是需要的,的資料,

那么我們進行模擬登陸的這個操作,就是最難的了吧,相對來說嘛,
如果你要說處理那些資料是更難的操作的話…那就聽你的吧,不過處理資料的方法是可以一直用的嘛,但是不同的網站就有不同的登錄方式,是多變的,所以相對來說還是我說的比較對,你要聽話,

從上一次的結果來看,大致可以推斷出,我們只要獲得登陸后的cookies,就不用進行賬號密碼的輸入了,就是可以直接繞過登錄了,也就避開了驗證碼這一個超級煩人的環節,
那就來讓我們偷偷地潛入…
獲取cookies!
這一呢,我們是用selenium進行一個cookies的獲取,
這里為什么說是cookies,而前面是cookie呢?
因為cookie是有很多的,可以理解為合起來就是一個字典!
cookies里面放的是一條一條的cookie,有的有用,有的只是說明一下ip鴨,時間鴨什么的,是屬于可有可無的,
可以選擇全都放進去,也可以選擇細一點,只放我們需要的!

這里我們先用selenium進行一個模擬的登錄~
# 匯入sleep是為了等待一下,確保網頁可以加載完,避免出現還沒加載出來程式就走完了的情況
from selenium import webdriver
from time import sleep
匯入這些呢,就不多說了,關于等待其實也是有三種等待的,如果想要詳細了解可以到 一起學爬蟲(Python) — 22 自動化詳解 了解一哈~
如果你讓我推薦一個的話,做大專案肯定是要顯式等待,隨便玩玩的話sleep就夠用了,
# 初始化driver物件
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
# 打開指定頁面
driver.get('https://www.chanmama.com/login')
這里有的人可能會先打開https://www.chanmama.com/然后點擊里面的登錄按鈕,其實沒必要哦,直接放登錄界面的url進去就好了,
如果初始化那里錯了,可能就是你的瀏覽器引擎版本不對,或者路徑不對,
# 這里也可以注釋掉,在下面的send_keys里面手動寫上自己的賬號密碼
tmf = input('請輸入你的手機號:')
password = input('請輸入你的密碼:')
# 等待1秒,萬一下面的東西沒加載出來就會報錯了
sleep(1)
# tmf就是手機號的縮寫,不要問我怎么知道的,我剛百度來的!
# 至于xpath里面的東西呢,是我直接復制的,就是那兩個輸入框
tmf_input = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[1]/div[2]/div/div[2]/div[2]/div/form/div[1]/div/div[1]/input')
# 把手機號放到手機號對應的框里
tmf_input.send_keys(tmf)
# psw就是password的縮寫
psw_input = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[1]/div[2]/div/div[2]/div[2]/div/form/div[2]/div/div/input')
psw_input.send_keys(password)
# dl就是登錄嘛,找到登錄按鈕的xpath復制過來
dl = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[1]/div[2]/div/div[2]/div[2]/div/form/div[4]/div/button')
# 點擊~
dl.click()
# 等待了3秒,因為登錄后可能會很慢才加載出來
sleep(3)
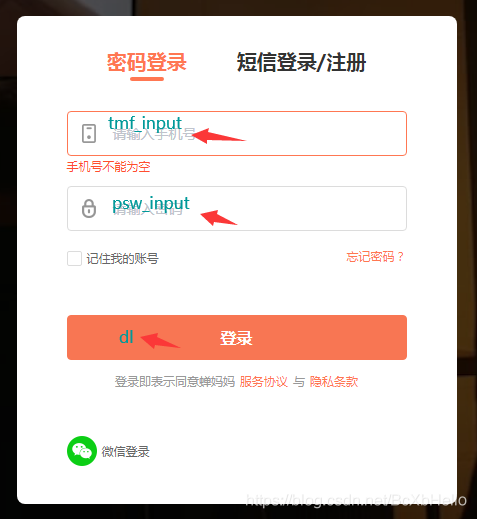
如果大家輸入的賬號密碼是對的,那就順利拿到了登陸后的頁面嘛~
接下來我們就進行cookies的獲取!
當然如果報錯,就試著把等待的時間調得長一點,因為代碼是沒問題的,我是指上面這一部分,
一部分!
一!

接下來就到我們的重頭戲了!
獲取cookies~
不是cookie哦,是cookies!!!
# 這里就獲取了我們的cookies!
c_cookies = driver.get_cookies()
當然想要獲取登錄后的cookies的前提是你登錄成功了哈,也就是頁面確實是加載出來了那種,
列印看一下唄~

看不懂吧,看不懂沒關系,我們把上一次21天的那里的cookie也拿過來:

上一次我們放進去的是這個下面的cookie吧,當時是說的token,
可以發現這個token:

和我們的value:

可以說是非常相似了吧~
那么這個呢,就是當前這個網頁想繞過登錄需要攜帶的cookies!
也許你要問我,那為什么他們不一樣呢???
一樣,就出問題了,
每一次的cookie都是會變得,但是格式,不會變吧,
token呢是這個網頁直接設定的吧,但是這個value是默認的,你從其他網頁獲取的cookies里面也會有這個value,因為這個是瀏覽器自帶格式,并不是說他是value就不是token了,女裝不可以嗎?

偷偷地潛入!
來看一下我們上一次是怎么做的:
# 處理我們的cookies
headers['Authorization'] = res['data']['token']
res是我們請求回來的資料吧,然后我們在headers這個字典里放了一個新的鍵值對,內容就是上面選中的那些東西吧,也就是說我們只需要把這里改一下就ok了!
# 處理我們的cookies
headers['Authorization'] = c_cookies[0]['value']
后面的東西都是一模摸一樣的嘛,只不過獲取cookies的方法變了,但是很明顯,這種selenium輔助我們進行一個模擬登陸的話,肯定會更方便啊,
最后呢,把全部代碼給大家附上!
from selenium import webdriver
from time import sleep
import requests
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
driver.get('https://www.chanmama.com/login')
tmf = input('請輸入你的手機號:')
password = input('請輸入你的密碼:')
sleep(1)
tmf_input = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[1]/div[2]/div/div[2]/div[2]/div/form/div[1]/div/div[1]/input')
tmf_input.send_keys(tmf)
psw_input = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[1]/div[2]/div/div[2]/div[2]/div/form/div[2]/div/div/input')
psw_input.send_keys(password)
dl = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[1]/div[2]/div/div[2]/div[2]/div/form/div[4]/div/button')
dl.click()
sleep(3)
c_cookies = driver.get_cookies()
print(c_cookies)
driver.quit()
headers = {
# 登錄前的cookie
'Cookie': 'Hm_lvt_1f19c27e7e3e3255a5c79248a7f4bdf1=1607054172,1607241195,1607485551,1609118533; Hm_lpvt_1f19c27e7e3e3255a5c79248a7f4bdf1=1609118533; Hm_lvt_ce889f3ae5bf6277ca4cbf05b940acbc=1609118534; Hm_lpvt_ce889f3ae5bf6277ca4cbf05b940acbc=1609118534',
# 證明我們不是通過外部鏈接過來的
'Referer': 'https://www.chanmama.com/login',
# 瀏覽器相關的資訊啦
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
# 處理我們的cookies
headers['Authorization'] = c_cookies[0]['value']
# 搜索界面的url
url = 'https://api-service.chanmama.com/v1/product/search'
# 發起請求時攜帶的引數
data = {
# 要搜索的東西
"keyword": '酒',
"keyword_type": "",
"page": 1,
"price": "",
# 數量
"size": 50,
"filter_coupon": 0,
"is_aweme_goods": 0,
"has_live": 0,
"has_video": 0,
"tb_max_commission_rate": "",
"day_pv_count": "",
"day_order_count": "",
"big_category": "",
"first_category": "",
"second_category": "",
"platform": "",
"sort": "day_order_count",
"order_by": "desc"
}
# 這里為什么用json=而不用data=呢,是json可以幫我們跟網頁說這個資料你需要自己弄成json串
# 使用data傳參的話,是支持嵌套字典的,兩者都可以用,當然這里你也可以選擇手動處理一下data
res = requests.post(url, json=data, headers=headers).json()
for i in res['data']['list']:
# 這里可以用%,也可以用format等等,甚至可以手動拼接,方法很多
print("商品:%s 價格:%s 原價:%s 昨日瀏覽:%s 昨日銷量:%s" % (
i['title'], i['price'], i['market_price'], i['day_pv_count'], i['day_order_count'])
姥爺,如果覺得這一篇對你有一點點幫助的話,務必點個贊吧!!!

擴展小知識 - 快速調整字體大小
不少小可愛應該會遇到敲代碼的時候字體大小不合適的問題,但是又不能通過快捷鍵很快速地進行調整,怎么感覺這個口吻是老營銷號了…

咳咳,這里小澤就教大家一個可以一勞永逸的方法!
首先呢,找到我們File里的Settings:
點進去,進入到我們的Keymap里面:
在圖中畫框框的那個框框里呢,進行一個搜索:
先搜Increase Font Size:
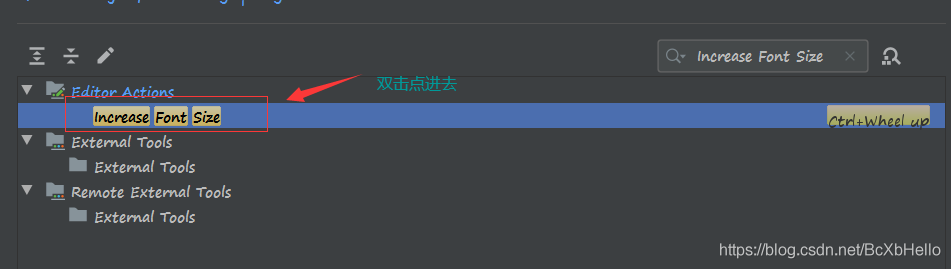
Increase Font Size翻譯過來就是放大字體嘛,然后雙擊點開之后會有這樣的界面:
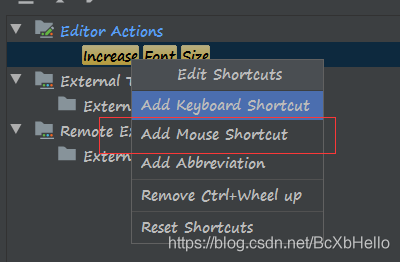
這里我們選擇第二個,Mouse Shortcut,通過滑鼠來進行字體的放大!
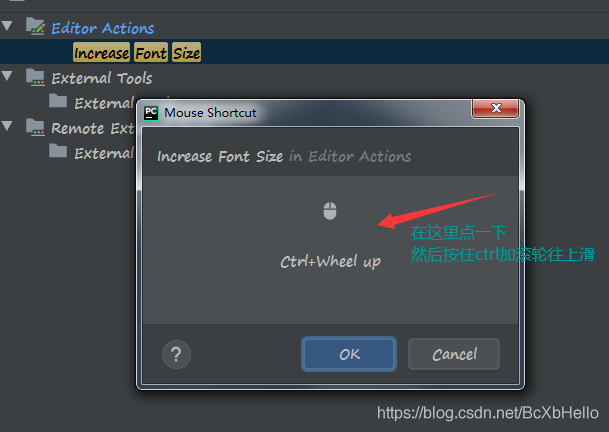
直到里面出現這種Ctrl + Wheel up這種提示,就可以點OK啦~
同樣的操作,我們再搜索一下Decrease Font Size(縮小字體):
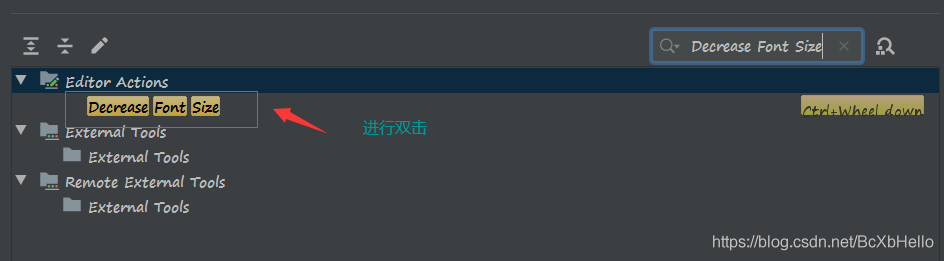
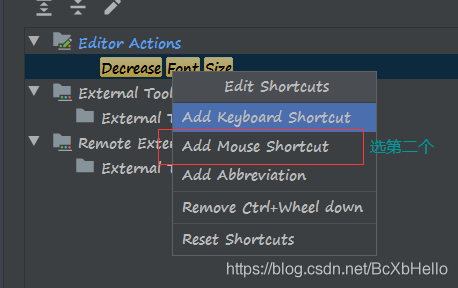
然后…
然后就跟上面那個一樣了好吧,只不過是換成了ctrl + 滾輪往下滑,
這些操作都做完之后呢,小可愛就可以隨便打開一個專案試一試按住ctrl+滾輪亂滑,是不是超級爽!
如果覺得對你有幫助的話…

當然,你也可以 選擇點一個免費的贊嘛~

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/244713.html
標籤:其他
上一篇:c++入門:分享一些實用的函式
下一篇:(三 Ribbon 什么是負載均衡?spring cloud如何實作負載均衡)手摸手帶你一起搭建 Spring cloud 微服務 理論+實踐+決議