文章目錄
- 介紹
- 賽事介紹
- 資料分析
- 模型訓練
- 玄學煉丹
介紹
在2020.12-2021.1這段時間和師兄參加了華為云“云上先鋒”·AI主題賽官網(垃圾分類),最后拿到了 第7名(7/1405) 的成績,在最終榜單上分數為96.64.
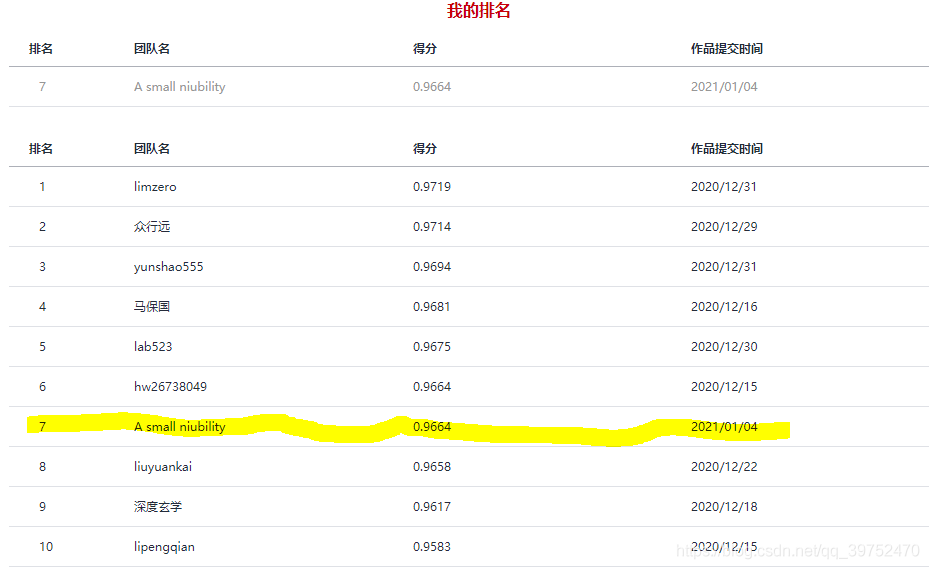
賽事介紹
1.賽題描述
本賽題采用深圳市垃圾分類標準,賽題任務是對垃圾圖片進行分類,即首先識別出垃圾圖片中物品的類別(比如易拉罐、果皮等),然后查詢垃圾分類規則,輸出該垃圾圖片中物品屬于可回收物、廚余垃圾、有害垃圾和其他垃圾中的哪一種,
模型輸出格式示例:
{
" result ": “可回收物/易拉罐”
}
2.資料說明
本次比賽提供的訓練集中包含了43類生活中常見垃圾,參賽者可自行劃分用于模型調優用的驗證集和測驗集,
datasets
|- train_data ( 訓練集目錄,包含垃圾圖片和對應的標簽檔案(.txt))
|- garbage_classify_rule.json (垃圾分類規則字典,key值是id,value是“垃圾種類/具體物品名”,
例如訓練資料標簽檔案img1.txt的內容是“img_1.jpg, 0”,表示img_1.jpg這張圖中的垃圾是“其他垃圾/一次性快餐盒”,)
3.評分標準
如上文模型輸出格式示例中,模型預測的物品類別是“易拉罐”,如果圖片的真實類別是易拉罐,則這張圖片預測正確,否則預測錯誤,評價指標的計算方式是:
識別準確率 = 識別正確的圖片數 / 圖片總數
識別準確率的數值即為最終的模型評分,
4.提交說明
參賽者需使用華為云一站式AI開發平臺ModelArts來開發模型,將模型部署為在線服務或批量服務驗證其正確性,確認模型無誤后在ModelArts平臺上將開發好的模型提交判分,最后在競賽平臺上提交作品、查看成績,
模型規范
1、所提交的模型必須滿足賽題說明中的模型輸出格式
2、評分系統使用ModelArts批量服務加載選手提交的模型,對比賽評分專用的測驗集圖片(此部分圖片不公開)進行批量預測,后臺會根據預測結果自動計算識別準確率
3、不允許使用“測驗時增強”策略和“模型融合”策略(如投票、stacking和blending)來提升模型的效果,只能使用端到端預測的單模型,每個賽事階段結束后,都會要求入圍選手提交代碼和模型,由賽事組進行人工審核模型是否符合要求
4、ModelArts模型管理中的模型創建后,不會自動更新,如果您有了更好的模型需要提交,要重新匯入模型,然后再重新發布模型、提交作品
5、排名靠前選手所提交的模型,會被擇優發布到ModelArts AI市場
這個ModelArts系統挺一言難盡的,評判時間會很慢,一個多小時出結果,有時候還會評分失敗,,
資料分析
這次也是屬于影像分類的一種,但是官方要求不能使用多模型融合和TTA,只能看單模型的泛化能力,所以要在單模型上挖掘出最大潛能,影像訓練集總共包含43類,2.1W張,這個比賽在2019年已經有過類似的了,當時是40類,為了增強泛化,我們把上一屆比賽某獲獎方案中自行添加的4K資料也加了進來,后續結果證明,因為這個附加資料已經經過篩選,加入后會帶來0.2左右的提升,
下面是做一個資料可視化分析:
類別說明:
{
“0”: “其他垃圾/一次性快餐盒”,
“1”: “其他垃圾/污損塑料”,
“2”: “其他垃圾/煙蒂”,
“3”: “其他垃圾/牙簽”,
“4”: “其他垃圾/破碎花盆及碟碗”,
“5”: “其他垃圾/竹筷”,
“6”: “廚余垃圾/剩飯剩菜”,
“7”: “廚余垃圾/大骨頭”,
“8”: “廚余垃圾/水果果皮”,
“9”: “廚余垃圾/水果果肉”,
“10”: “廚余垃圾/茶葉渣”,
“11”: “廚余垃圾/菜葉菜根”,
“12”: “廚余垃圾/蛋殼”,
“13”: “廚余垃圾/魚骨”,
“14”: “可回收物/充電寶”,
“15”: “可回收物/包”,
“16”: “可回收物/化妝品瓶”,
“17”: “可回收物/塑料玩具”,
“18”: “可回收物/塑料碗盆”,
“19”: “可回收物/塑料衣架”,
“20”: “可回收物/快遞紙袋”,
“21”: “可回收物/插頭電線”,
“22”: “可回收物/舊衣服”,
“23”: “可回收物/易拉罐”,
“24”: “可回收物/枕頭”,
“25”: “可回收物/毛絨玩具”,
“26”: “可回收物/洗發水瓶”,
“27”: “可回收物/玻璃杯”,
“28”: “可回收物/皮鞋”,
“29”: “可回收物/砧板”,
“30”: “可回收物/紙板箱”,
“31”: “可回收物/調料瓶”,
“32”: “可回收物/酒瓶”,
“33”: “可回收物/金屬食品罐”,
“34”: “可回收物/鍋”,
“35”: “可回收物/食用油桶”,
“36”: “可回收物/飲料瓶”,
“37”: “有害垃圾/干電池”,
“38”: “有害垃圾/軟膏”,
“39”: “有害垃圾/過期藥物”,
“40”: “可回收物/毛巾”,
“41”: “可回收物/飲料盒”,
“42”: “可回收物/紙袋”
}
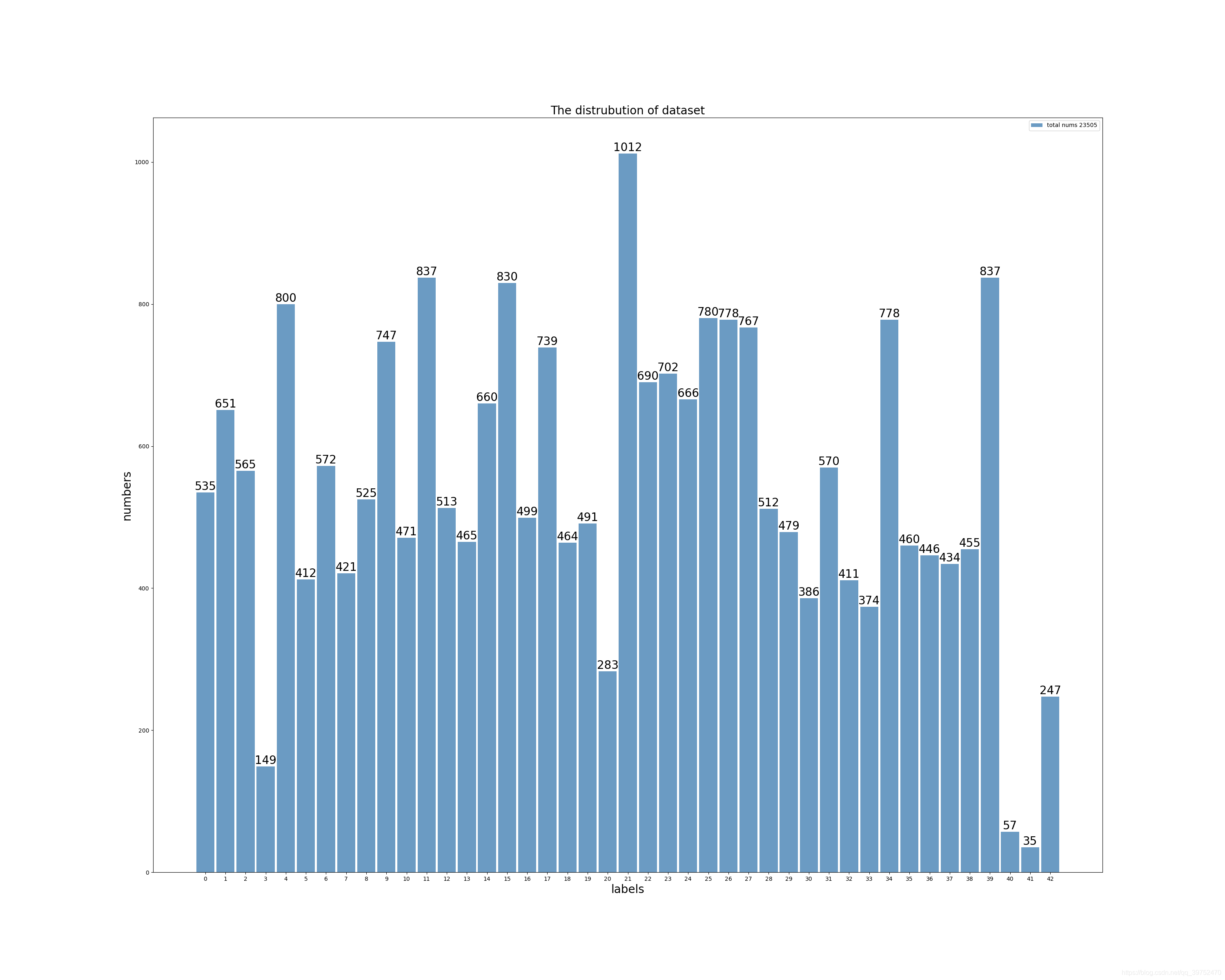
上圖可以看到類別還是不太平衡的,后續結果表明,雖然類似于3,20,40,41,42的資料較少,但在這些類別上的正確率還不錯,沒有表現出很惡劣的情況,我們在訓練時把資料劃分為9-1格式,90%train,10%val,最后也嘗試過全部資料進行訓練,但是結果一直不太好,還沒能超越9-1劃分最高分,
做資料增強的時候,發現很多垃圾圖片都是對稱的,還有輕微的旋轉角度,所以也沒有加入過多的資料增強,


最終選擇的訓練資料增強操作如下:
self.transforms = T.Compose([
T.Resize((int(input_size / 0.934), int(input_size / 0.934))),
T.RandomCrop((input_size,input_size)),
T.RandomRotation(10),
T.RandomHorizontalFlip(),
T.ToTensor(),
normalize
])
驗證和測驗都是只加入了中心裁剪:
self.transforms = T.Compose([
T.Resize((int(input_size / 0.934), int(input_size / 0.934))),
T.CenterCrop((input_size,input_size)),
T.ToTensor(),
normalize
])
這里的 input_size / 0.934 是針對 tf_efficientnet_b5_ns 模型456輸入的cropt_pct,對應普通的224輸入就是 input_size/0.875 ,
模型訓練
1.網路選擇
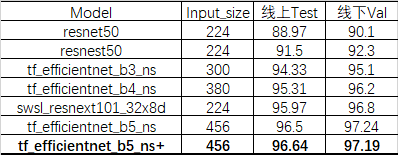
最開始用resnet50跑了一個baseline,提交后再換不同模型,這些操作都比較無腦,就是加大解析度大模型了,因為之前ACCV細粒度分類比賽第2名使用了efficientnet的ns模型,這次延續了上次的做法,改為timm庫中的tf_efficientnet_bx_ns 系列,這個在imagent上的Top1準確率表現很不錯
2.訓練程序
我們在單卡2080TI上訓練,優化器選擇了SGD,初始 lr=0.001,使用ReduceLROnPlateau進行衰減,這里是對val_loss進行判斷,如果2個epoch都沒有減少,則學習率衰減0.1倍,因為val_acc震蕩太多在20epoch左右,使用val_loss會更好一點,
optimizer = optim.SGD((model.parameters()), lr=0.001, momentum=0.9, weight_decay=0.0004)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=2, verbose=False)
損失函式開始選擇 CrossEntropyLoss ,后面改為LabelSmoothingLoss,smoothing=0.1,會漲點0.25.
后面改為b6/b7系列發現效果會變差,b5是最優的選擇,也試了swsl_resnext101系列,發現效果不怎么好,但是可能也是我們煉丹不夠好,
在訓練 tf_efficientnet_b5_ns 時,使用了混合精度Apex訓練,batchsize=12,20-40個epoch之間出最好結果,
from timm.models import create_model
model = create_model(
'tf_efficientnet_b5_ns',
pretrained=True,
num_classes=43,
drop_rate=0.1,
drop_connect_rate=None, # DEPRECATED, use drop_path
drop_path_rate=None,
drop_block_rate=None,
global_pool=None,
bn_tf=False,
bn_momentum=None,
bn_eps=None,
checkpoint_path=None)
我們發現加大模型,加大解析度最多在b5上達到了96.5的結果,后面試了很多方法也沒有提升:
(1)全部資料訓練后,沒啥提升;
(2)還使用了破壞-重建學習DCL網路,沒提升;
(3)NIPS2020湯凱華新提出的De-confound TDE(訓練時需要De-confound Training,說人話就是classifier需要使用multi-head normalized classifier),沒啥提升;
(4)也試了隨機SWA方法,波動大,效果也不行;
(5)試了超引數搜索,設定初始學習率和drop_rate兩個引數,發現還是lr=0.001,drop_rate=0.1效果最好;
(6)分層學習率,特征提取部分學習率0.001,全連接層為0.01,效果也一般,
玄學煉丹
比賽結束前一天,試了最后一個trick,在96.5最好結果的預訓練模型上訓練全部資料,凍結特征提取層,僅跑全連接層,提交了第3個epoch的結果,因為它看著val_loss最低,val_acc還可以,然后結果出來96.64,煉丹大法最后一天終于有了可見的效果,
從第8到了第7,之前開始做的時候一路順風一直到第4(96.5),然后就是溫水煮青蛙,再上不去了,慢慢掉下來,最后又掙扎了一下,

最后是我們最好模型的val結果混淆矩陣分析:
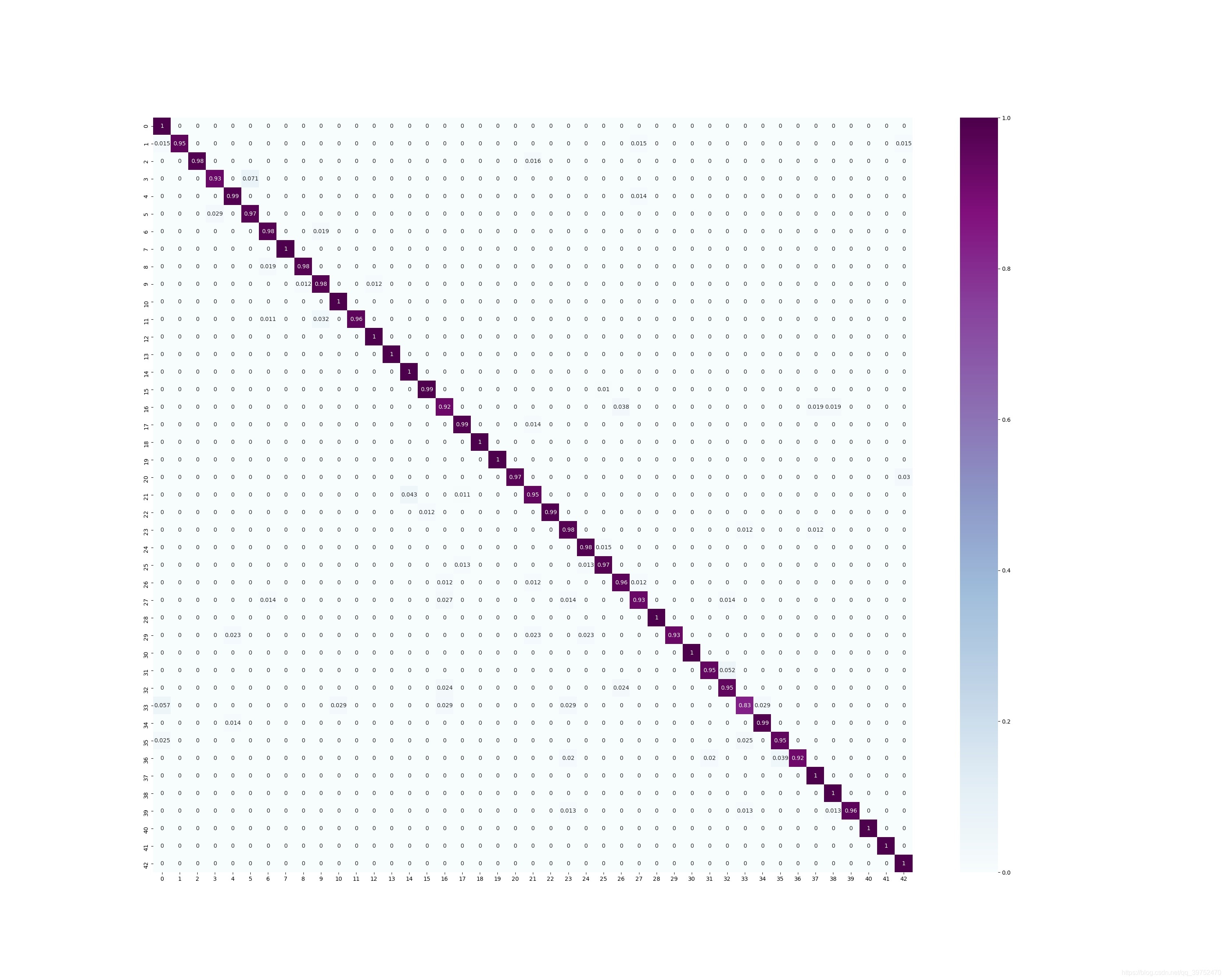 這個中間數字是對應類別的分類正確概率,
這個中間數字是對應類別的分類正確概率,
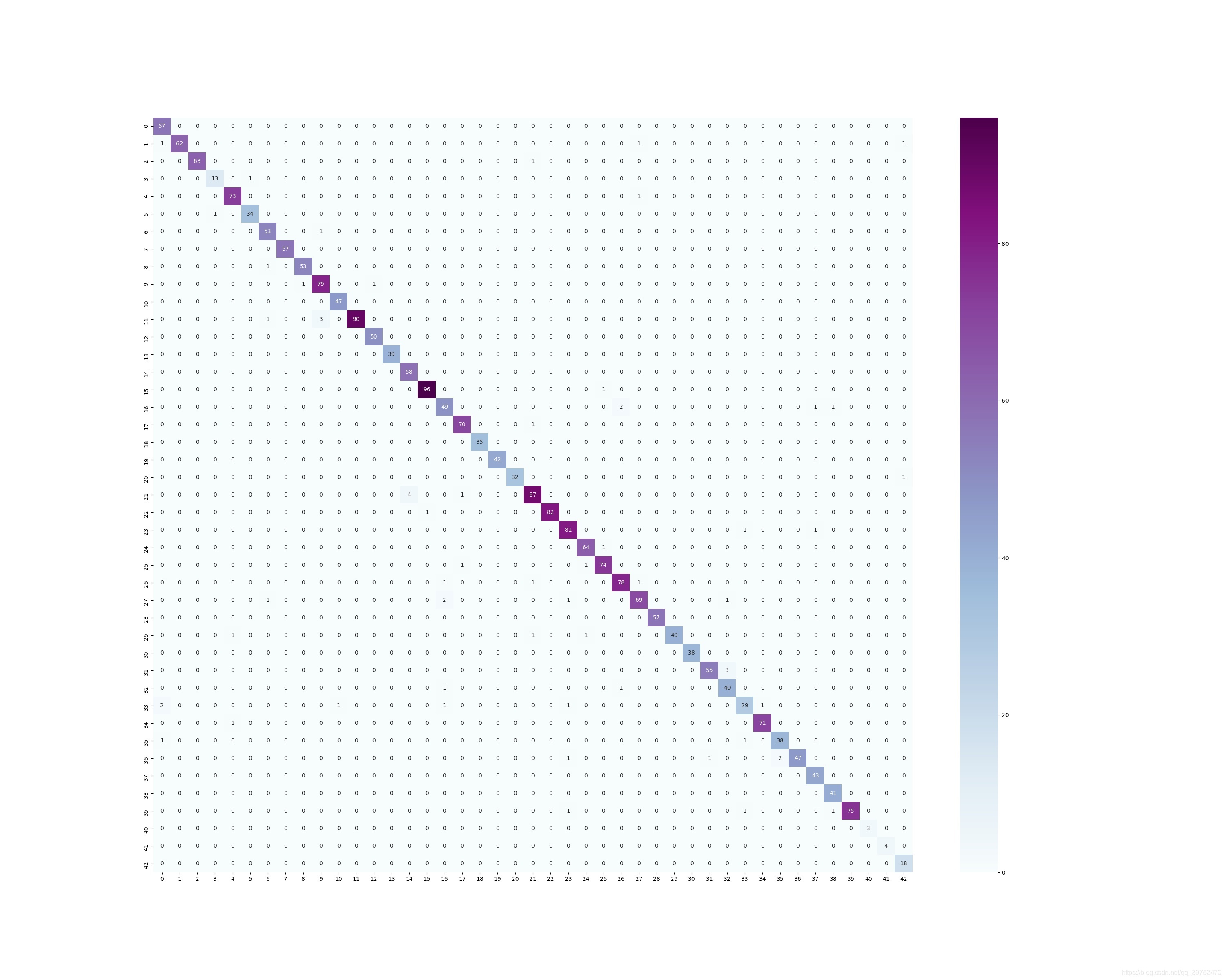 上面是對應類別的分類正確數量,
上面是對應類別的分類正確數量,
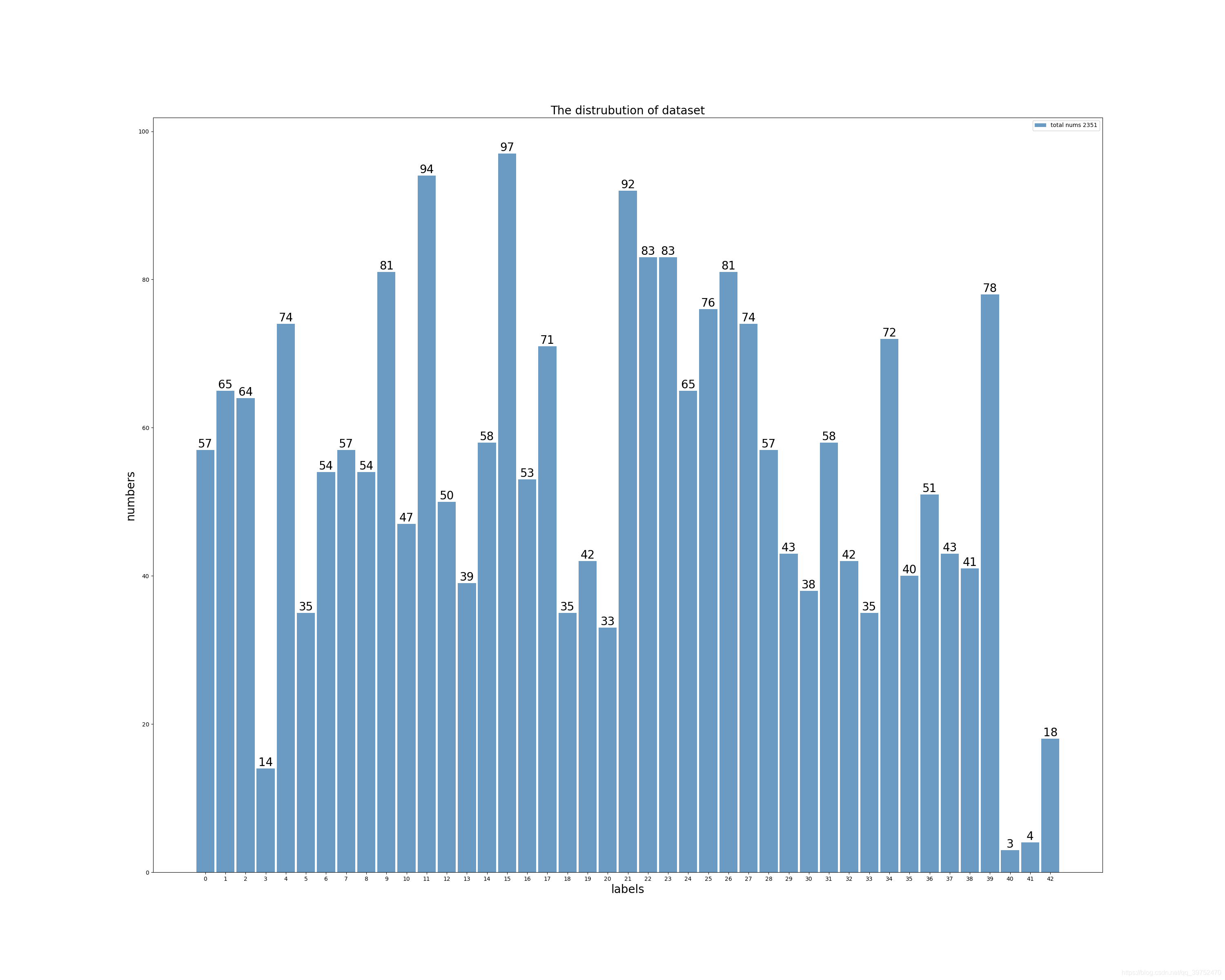 上面是val資料的類別分布,
上面是val資料的類別分布,
具體代碼見github:
完整code
期待更多大佬方案,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/245247.html
標籤:其他