圖論演算法模板,隨緣不定期更新
- 搜索
- dfs
- bfs
- 并查集(更新于2021/1/8)
- 概念及作用
- 原理及實作
- 完整代碼
- 網路流
- 最大流
- dinic(更新于2021/1/6)
- hlpp(更新于2021/1/6)
- 最小費用最大流(更新于2021/1/6)
- 無源匯有上下界可行流(更新于2021/1/6)
- 有源匯上下界最大流(更新于2021/1/6)
- 最短路徑
- dijkstra(更新于2021/1/6)
- spfa(更新于2021/1/6)
- 最小生成樹
- kruskal(更新于2021/1/6)
- prim(更新于2021/1/6)
- 歐拉通路與歐拉回路
- 判斷存在歐拉回路(更新于2021/1/6)
- 尋找歐拉路徑(更新于2021/1/6)
- prufer編碼
- prufer編碼轉樹(更新于2021/1/6)
- LCA(更新于2021/1/6)
- tarjan求割點(更新于2021/1/6)
用來保存圖論的模板方便備賽,演算法的決議看心情寫
代碼中讀入函式scanf和scanf_s與編譯器有關,沒有太大差別
—Ninght
搜索
dfs
bfs
并查集(更新于2021/1/8)
概念及作用
我對于并查集的理解是她是一種用于處理資料之間關系的資料結構,由一個整型陣列、一個查詢函式和一個合并函式構成,
舉一個最簡單的例子:現在有n名從1到n標號的人,并且我們知道他們之間的一些關系如1與2是朋友關系,2與3是朋友關系,3與4是敵對關系等,我們規定朋友的朋友是朋友,朋友的敵人是敵人切不存在既是朋友又是敵人的情況,那么對于給定的兩個人x,y(小于n),我們要如何根據已知的關系推斷出兩人是朋友還是敵人?
并查集是用于解決類似上述問題的一種資料結構,
原理及實作
并查集的原理可以看成是給離散的n個點建立無向圖來維護給定的關系,這里我們假設n=5并且給出關系(1,2)、(2,3)、(4,5)((x,y)表示x,y為朋友,沒有給出則為敵人關系),
那么我們首先由n=5可以得到五個離散的點
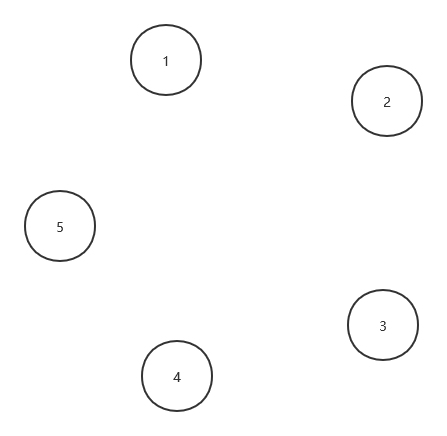 這里我們令關系(x,y)表示連接結點x和y的一條無向邊,那么我們可以得到一個無向圖
這里我們令關系(x,y)表示連接結點x和y的一條無向邊,那么我們可以得到一個無向圖
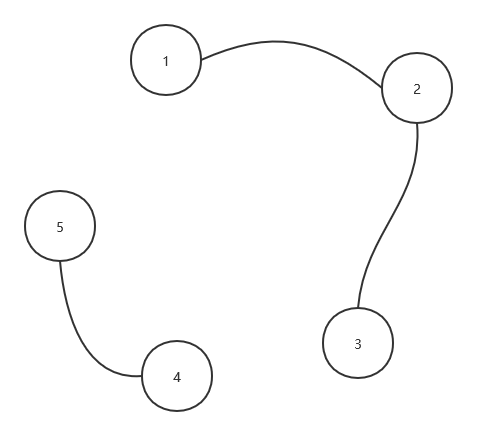 不難看出1、2、3在一個連通分量中,4、5在一個連通分量中,即1,2,3是朋友關系,4,5 是朋友關系,他們(1,2,3和4,5)之間任意兩人為敵對關系,那么如果我們用連通分量中的一個點來表示這個連通分量中所有的點,那么在查找給定兩人x,y的關系時只需判斷兩人是否屬于同一個連通分量即可,
不難看出1、2、3在一個連通分量中,4、5在一個連通分量中,即1,2,3是朋友關系,4,5 是朋友關系,他們(1,2,3和4,5)之間任意兩人為敵對關系,那么如果我們用連通分量中的一個點來表示這個連通分量中所有的點,那么在查找給定兩人x,y的關系時只需判斷兩人是否屬于同一個連通分量即可,
因此這里引入一個整型陣列a[MAX]來記錄每個點所在的連通分量(a[i]=j表示點i所在的連通分量為j即點i和點j在同一個連通分量中,換句話說i和j是朋友關系),顯然,在最開始時所有的點均離散,所以每個點構成了一個連通分量,陣列a要初始化為a[i]=i,
接下來需要根據給出的關系來維護這個陣列a,所以定義函式Hebin(x,y)表示將x與y合并放在同一個連通分量中,那么對于陣列a的操作應為a[x所在的連通分量]=y所在的連通分量(意義為x所在的連通分量與y所在的連通分量是同一個連通分量),
要實作這個操作,我們需要知道x(或y)所在的連通分量是哪一個,這就需要用到陣列a中的值,前面提到,陣列a初始化為a[x]=x,因此我們知道當查詢一個點x在陣列a中對應的值a[x]就是它本身時,點x所在的連通分量就是x,那么若還存在點y、z使得a[y]=x、a[z]=y,我們也可以知道y所在的連通分量是x,z所在的連通分量與y相同也是x,所以查詢點x所在連通分量的函式Chaxun(x)可以通過簡單遞回來實作,
int Chaxun(int x)
{
return (a[x] == x) ? x : a[x] = Chaxun(a[x]);
}
根據Chaxun(x)這個函式我們就可以實作上面的Hebin(x,y)函式(a[x所在的連通分量]=y所在的連通分量)
void Hebin(int x, int y)
{
a[Chaxun(x)] = Chaxun(y);
}
完整代碼
下面的代碼中主函式用于解決洛谷中的模板題P3367
#include <iostream>
#include<cstdio>
using namespace std;
const int maxn = 10002;
int n, m, a[maxn];
int Chaxun(int x)
{
return (a[x] == x) ? x : a[x] = Chaxun(a[x]);
}
void Hebin(int x, int y)
{
a[Chaxun(x)] = Chaxun(y);
}
int main()
{
int i, x, y, z;
scanf("%d%d", &n, &m);
for (i = 1; i <= n; i++)a[i] = i;
for (i = 0; i < m; i++)
{
scanf("%d%d%d", &z, &x, &y);
if (z == 1)Hebin(x, y);
if (z == 2)
{
if (Chaxun(x) == Chaxun(y))printf("Y\n");
else printf("N\n");
}
}
return 0;
}
并查集是一個非常實用而且我很早之前就想整理詳解的資料結構,結果拖了將近一年才寫,原因是匯編語言實在是看不下去了,果然復習的時候除了復習覺得什么事都挺有意思的hhh,現在距離匯編考試還有9個小時,本來以為挺好寫的,結果還是寫了將近兩個小時,組織語言太難了hhh,還是不想復習,回去睡覺了,,,考試加油
—Ninght
網路流
最大流
dinic(更新于2021/1/6)
//輸入頂點數,邊數,源點,匯點及各有向邊的起始點和權值,輸出匯點最大流
#include<algorithm>
#include<cstring>
#include<cstdio>
#include<queue>
#define int long long
using std::queue;
struct node {
int to;//終點
int next;//與該邊同起點的上一條邊的序號
int w;//權值
}qxx[200005];//邊集鏈式前向星
int h[200005];//起點為x的一條邊的序號
int cnt;//計數器
int n, m, st, en;//頂點數,邊數,源點,匯點
int x, y, z;//始點,終點,權值
void add(int x, int y, int z) {
qxx[++cnt] = node{ y,h[x],z };
h[x] = cnt;
}//添加邊(始點,終點,權值)
void ad(int x, int y, int z) {
add(x, y, z);//正向
add(y, x, 0);//反向
}//添加邊
int d[200005];
bool bfs() {
memset(d, 0, sizeof d);
queue<int>q;
while (!q.empty())q.pop();
d[st] = 1;
q.push(st);
while (!q.empty()) {
int x = q.front();
q.pop();
for (int i = h[x]; i; i = qxx[i].next) {
int v = qxx[i].to;
if (!d[v] && qxx[i].w) {
d[v] = d[x] + 1;
q.push(v);
if (v == en)return true;
}
}
}
return false;
}
int dfs(int u, int flow) {
if (u == en)return flow;
int rest = flow;
for (int i = h[u]; i; i = qxx[i].next) {
int v = qxx[i].to;
if (d[v] == d[u] + 1 && qxx[i].w) {
int tmp = dfs(v, std::min(qxx[i].w, rest));
if (!tmp)d[v] = 0;
rest -= tmp;
qxx[i].w -= tmp;
qxx[i ^ 1].w += tmp;
if (!rest)break;
}
}
return flow - rest;
}
int ans, sth;
signed main() {
scanf_s("%lld%lld%lld%lld", &n, &m, &st, &en);
for (int i = 1; i <= m; i++) {
scanf_s("%lld%lld%lld", &x, &y, &z);
ad(x, y, z);
}
while (bfs())while (sth = dfs(st, 1e9))ans += sth;
printf("%lld", ans);
return 0;
}
hlpp(更新于2021/1/6)
#include<cstdio>
#include<cstring>
#include<cmath>
#include<cstdlib>
#include<climits>
#include<ctime>
#include<algorithm>
#include<complex>
#include<iostream>
#include<map>
#include<queue>
#include<vector>
#define ll long long
#define inf 0x3f3f3f3f
#define re register
#define il inline
using namespace std;
struct edge
{
int to, next;
int flow;
}a[2000020];//鏈式前向星
int head[10010];
int gap[10010];//存盤同層結點數
int h[10010];
int e[10010];//e[i]表示第i號節點的超額流
int vis[10010];
int cnt(0);
int n, m, st, ed;//頂點數,邊數,源點,匯點
struct cmp
{
il bool operator ()(int xi, int yi)const
{
return h[xi] < h[yi];
}
};
priority_queue<int, vector<int>, cmp> pq;//以層數為優先級佇列
queue<int> q;
il void addedge(int xi, int yi, int fi)
{
a[cnt].to = yi;
a[cnt].next = head[xi];
a[cnt].flow = fi;
head[xi] = cnt++;
}
il bool bfs()
{
re int i;
memset(h + 1, inf, sizeof(int) * n);//將所有的節點高度均設為inf,表示不在網路內
h[ed] = 0;
q.push(ed);
while (!q.empty())
{
int t = q.front();
q.pop();
for (i = head[t]; i != -1; i = a[i].next)
{
int v = a[i].to;
if (a[i ^ 1].flow && h[v] > h[t] + 1)
{
h[v] = h[t] + 1;//更新節點高度
q.push(v);
}
}
}
return h[st] != inf;
}
il void push(int u)
{
re int i;
for (i = head[u]; i != -1; i = a[i].next)//遍歷當前點的鄰點
{
int v = a[i].to;
if ((a[i].flow) && (h[v] + 1 == h[u]))//將該店的超額流傳入層數小1的鄰點
{
int df = min(e[u], a[i].flow);
a[i].flow -= df;
a[i ^ 1].flow += df;
e[u] -= df;
e[v] += df;
if ((v != st) && (v != ed) && (!vis[v]))
{
pq.push(v);
vis[v] = 1;
}
if (!e[u])break;
}
}
}//只將處源點和匯點以外的點送入佇列
il void relabel(int u)
{
re int i;
h[u] = inf;
for (i = head[u]; i != -1; i = a[i].next)
{
int v = a[i].to;
if ((a[i].flow) && (h[v] + 1 < h[u]))h[u] = h[v] + 1;
}
}
inline int hlpp()
{
re int i;
if (!bfs())return 0;
h[st] = n;
memset(gap, 0, sizeof(int) * (n << 1));
for (i = 1; i <= n; i++)if (h[i] != inf)gap[h[i]]++;
for (i = head[st]; i != -1; i = a[i].next)
{
int v = a[i].to;
if (int f = a[i].flow)
{
a[i].flow -= f; a[i ^ 1].flow += f;
e[st] -= f; e[v] += f;
if (v != st && v != ed && !vis[v])
{
??pq.push(v);
vis[v] = 1;
}
}
}
while (!pq.empty())
{
int t = pq.top(); pq.pop();
vis[t] = 0; push(t);
if (e[t])
{
gap[h[t]]--;
if (!gap[h[t]])
{
for (re int v = 1; v <= n; v++)
{
if (v != st && v != ed && h[v] > h[t] && h[v] < n + 1)
{
h[v] = n + 1;
}
}
}
relabel(t); gap[h[t]]++;
pq.push(t); vis[t] = 1;
}
}
return e[ed];
}
signed main()
{
re int i;
memset(head, -1, sizeof(head));
scanf_s("%d%d%d%d", &n, &m, &st, &ed);
for (i = 1; i <= m; i++)
{
int x, y;
ll f;
scanf_s("%d%d%lld", &x, &y, &f);
addedge(x, y, f);
addedge(y, x, 0);
}
ll maxf = hlpp();
printf("%lld", maxf);
return 0;
}
最小費用最大流(更新于2021/1/6)
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
const int maxn = 100010;
bool vis[maxn];
int n, m, s, t, x, y, z, f, dis[maxn], pre[maxn], last[maxn], flow[maxn], maxflow, mincost;
//dis最小花費;pre每個點的前驅;last每個點的所連的前一條邊;flow源點到此處的流量
struct Edge {
int to, next, flow, dis;//flow流量 dis花費
}edge[maxn];
int head[maxn], num_edge;
queue <int> q;
void add_edge(int from, int to, int flow, int dis)
{
edge[++num_edge].next = head[from];
edge[num_edge].to = to;
edge[num_edge].flow = flow;
edge[num_edge].dis = dis;
head[from] = num_edge;
}
bool spfa(int s, int t)
{
memset(dis, 0x7f, sizeof(dis));
memset(flow, 0x7f, sizeof(flow));
memset(vis, 0, sizeof(vis));
q.push(s); vis[s] = 1; dis[s] = 0; pre[t] = -1;
while (!q.empty())
{
int now = q.front();
q.pop();
vis[now] = 0;
for (int i = head[now]; i != -1; i = edge[i].next)
{
if (edge[i].flow > 0 && dis[edge[i].to] > dis[now] + edge[i].dis)//正邊
{
dis[edge[i].to] = dis[now] + edge[i].dis;
pre[edge[i].to] = now;
last[edge[i].to] = i;
flow[edge[i].to] = min(flow[now], edge[i].flow);//
if (!vis[edge[i].to])
{
vis[edge[i].to] = 1;
q.push(edge[i].to);
}
}
}
}
return pre[t] != -1;
}
void MCMF()
{
while (spfa(s, t))
{
int now = t;
maxflow += flow[t];
mincost += flow[t] * dis[t];
while (now != s)
{//從源點一直回溯到匯點
edge[last[now]].flow -= flow[t];//flow和dis容易搞混
edge[last[now] ^ 1].flow += flow[t];
now = pre[now];
}
}
}
int main()
{
memset(head, -1, sizeof(head)); num_edge = -1;//初始化
scanf("%d%d%d%d", &n, &m, &s, &t);
for (int i = 1; i <= m; i++)
{
scanf("%d%d%d%d", &x, &y, &z, &f);
add_edge(x, y, z, f); add_edge(y, x, 0, -f);
//反邊的流量為0,花費是相反數
}
MCMF();
printf("%d %d", maxflow, mincost);
return 0;
}
無源匯有上下界可行流(更新于2021/1/6)
#include<queue>
#include<cstdio>
#include<cstring>
#include<algorithm>
#define N 100005
#define M 1000005
#define inf 1ll<<31ll-1
using namespace std;
int n, m, s, t, ss, tt, num = 1;
int v[M], w[M], next1[M];
int d[N], f[N], sum[N], first[N];
bool can[N];
void add(int x, int y, int f)
{
num++;
next1[num] = first[x];
first[x] = num;
v[num] = y;
w[num] = f;
}
bool bfs(int start, int end)
{
int x, y, i, j;
memset(d, -1, sizeof(d));
memcpy(f, first, sizeof(f));
queue<int>q;
q.push(start);
d[start] = 0;
while (!q.empty())
{
x = q.front();
q.pop();
for (i = first[x]; i; i = next1[i])
{
y = v[i];
if (w[i] && d[y] == -1 && !can[y])
{
d[y] = d[x] + 1;
if (y == end)
return true;
q.push(y);
}
}
}
return false;
}
int dinic(int now, int end, int flow)
{
if (now == end)
return flow;
int x, delta, ans = 0;
for (int& i = f[now]; i; i = next1[i])
{
x = v[i];
if (w[i] && d[x] == d[now] + 1 && !can[x])
{
delta = dinic(x, end, min(flow, w[i]));
w[i] -= delta;
w[i ^ 1] += delta;
flow -= delta;
ans += delta;
if (!flow) break;
}
}
if (flow) d[now] = -1;
return ans;
}
int main()
{
int x, y, i, j, l, r;
int ans = 0, maxflow = 0;
scanf("%d%d%d%d", &n, &m, &s, &t);
ss = 0, tt = n + 1;
for (i = 1; i <= m; ++i)
{
scanf("%d%d%d%d", &x, &y, &l, &r);
sum[x] -= l, sum[y] += l;
add(x, y, r - l), add(y, x, 0);
}
for (i = 1; i <= n; ++i)
{
if (sum[i] > 0) add(ss, i, sum[i]), add(i, ss, 0), ans += sum[i];
if (sum[i] < 0) add(i, tt, -sum[i]), add(tt, i, 0);
}
add(t, s, inf), add(s, t, 0);
while (bfs(ss, tt))
maxflow += dinic(ss, tt, inf);
can[ss] = false;
can[tt] = false;
if (maxflow != ans)
{
printf("please go home to sleep");
return 0;
}
int minflow = 0;
add(t, s, -inf), add(s, t, 0);
while (bfs(t, s))
minflow -= dinic(t, s, inf);
printf("%d", minflow);
return 0;
}
有源匯上下界最大流(更新于2021/1/6)
#include<queue>
#include<cstdio>
#include<cstring>
#include<algorithm>
#define N 100005
#define M 1000005
#define inf 1ll<<31ll-1
using namespace std;
int n, m, s, t, ss, tt, num = 1;
int v[M], w[M], next1[M];
int d[N], f[N], sum[N], first[N];
bool can[N];
void add(int x, int y, int f)
{
num++;
next1[num] = first[x];
first[x] = num;
v[num] = y;
w[num] = f;
}
bool bfs(int start, int end)
{
int x, y, i, j;
memset(d, -1, sizeof(d));
memcpy(f, first, sizeof(f));
queue<int>q;
q.push(start);
d[start] = 0;
while (!q.empty())
{
x = q.front();
q.pop();
for (i = first[x]; i; i = next1[i])
{
y = v[i];
if (w[i] && d[y] == -1 && !can[y])
{
d[y] = d[x] + 1;
if (y == end)
return true;
q.push(y);
}
}
}
return false;
}
int dinic(int now, int end, int flow)
{
if (now == end)
return flow;
int x, delta, ans = 0;
for (int& i = f[now]; i; i = next1[i])
{
x = v[i];
if (w[i] && d[x] == d[now] + 1 && !can[x])
{
delta = dinic(x, end, min(flow, w[i]));
w[i] -= delta;
w[i ^ 1] += delta;
flow -= delta;
ans += delta;
if (!flow) break;
}
}
if (flow) d[now] = -1;
return ans;
}
int main()
{
int x, y, i, j, l, r;
int ans = 0, maxflow = 0;
scanf("%d%d%d%d", &n, &m, &s, &t);
ss = 0, tt = n + 1;
for (i = 1; i <= m; ++i)
{
scanf("%d%d%d%d", &x, &y, &l, &r);
sum[x] -= l, sum[y] += l;
add(x, y, r - l), add(y, x, 0);
}
for (i = 1; i <= n; ++i)
{
if (sum[i] > 0) add(ss, i, sum[i]), add(i, ss, 0), ans += sum[i];
if (sum[i] < 0) add(i, tt, -sum[i]), add(tt, i, 0);
}
add(t, s, inf), add(s, t, 0);
while (bfs(ss, tt))
maxflow += dinic(ss, tt, inf);
can[ss] = false;
can[tt] = false;
if (maxflow != ans)
{
printf("please go home to sleep");
return 0;
}
maxflow = 0;
while (bfs(s, t))
maxflow += dinic(s, t, inf);
printf("%d", maxflow);
return 0;
}
最短路徑
dijkstra(更新于2021/1/6)
#include<cstdio>
#include<iostream>
#include<queue>
#define MAX 200020
#define inf 0x7fffffff
using namespace std;
int n, m,vis[MAX];
long long dis[MAX];
struct edgenode
{
int to;
int next;
int weight;
}edge[MAX];
int cnt, head[MAX];
int u, v, w;
int s;
struct node
{
long long dis;
int pos;
bool operator <(const node& x)const
{
return x.dis < dis;
}
};
std::priority_queue<node> q;//優先佇列
void add_edge(int u, int v, int w);
void dijkstra();
int main()
{
memset(dis, -1, sizeof(dis));
scanf_s("%d%d%d", &n, &m, &s);
for (int i = 1; i <= n; i++)dis[i] = inf;
for (int i = 0; i < m; i++)
{
scanf_s("%d%d%d", &u, &v, &w);
add_edge(u, v, w);
}
dijkstra();
for (int i = 1; i <= n; i++)printf("%lld ", dis[i]);
}
void add_edge(int u, int v, int w)
{
edge[++cnt] = edgenode{ v,head[u],w };
head[u] = cnt;
}
void dijkstra()
{
dis[s] = 0;
q.push(node { 0, s });
while (!q.empty())
{
node tmp = q.top();
q.pop();
int x = tmp.pos, d = tmp.dis;
if (vis[x])
continue;
vis[x] = 1;
for (int i = head[x]; i; i = edge[i].next)
{
int y = edge[i].to;
if (dis[y] > dis[x] + edge[i].weight)
{
dis[y] = dis[x] + edge[i].weight;
if (!vis[y])
{
q.push(node { dis[y], y });
}
}
}
}
}
spfa(更新于2021/1/6)
#include<cstdio>
#include<iostream>
#include<queue>
#define MAX 200010
#define inf 2147483647
using namespace std;
int n, m, s;//點數,邊數,出發點
int vis[MAX];
long long dis[MAX];
int head[MAX], cnt, u, v, w;
struct node
{
int to;
int next;
int weight;
}edge[MAX];
void add_edge(int u, int v, int w);
void spfa();
int main()
{
memset(head, -1, sizeof(head));
scanf_s("%d%d%d", &n, &m, &s);
for (int i = 0; i < m; i++)
{
scanf_s("%d%d%d", &u, &v, &w);
add_edge(u, v, w);
}
spfa();
for (int i = 1; i <= n; i++)
if (i == s)printf("0 ");
else printf("%lld ", dis[i]);
}
void add_edge(int u, int v, int w)
{
edge[++cnt] = node{ v,head[u],w };
head[u] = cnt;
}
void spfa()
{
queue<int> q; //spfa用佇列,這里用了STL的標準佇列
for (int i = 1; i <= n; i++)
{
dis[i] = inf; //帶權圖初始化
vis[i] = 0; //記錄點i是否在佇列中,同dijkstra演算法中的visited陣列
}
q.push(s); dis[s] = 0; vis[s] = 1; //第一個頂點入隊,進行標記
while (!q.empty())
{
int u = q.front(); //取出隊首
q.pop(); vis[u] = 0; //出隊標記
for (int i = head[u]; i!=-1; i = edge[i].next) //鄰接表遍歷7
{
int v = edge[i].to;
if (dis[v] > dis[u] + edge[i].weight) //如果有最短路就更改
{
dis[v] = dis[u] + edge[i].weight;
if (vis[v] == 0) //未入隊則入隊
{
vis[v] = 1; //標記入隊
q.push(v);
}
}
}
}
}
最小生成樹
kruskal(更新于2021/1/6)
#include<stdio.h>
#include<stdlib.h>
#include<iostream>
using namespace std;
#define MAXN 11 //頂點個數的最大值
#define MAXM 20 //邊的個數的最大值
struct edge //邊
{
int u, v, w;
}edges[MAXM]; //邊的陣列
int parent[MAXN]; //parent[i]為頂點i所在集合對應的樹中的根結點
int n, m; //頂點個數、邊的個數
int i, j; //回圈變數
void UFset() //初始化
{
for (i = 1; i <= n; i++) parent[i] = -1;
}
int Find(int x) //查找并回傳結點x所屬集合的根結點
{
int s; //查找位置
for (s = x; parent[s] >= 0; s = parent[s]);
while (s != x) //優化方案——壓縮路徑,使后續的查找操作加速
{
int tmp = parent[x];
parent[x] = s;
x = tmp;
}
return s;
}
//運用并查集,將兩個不同集合的元素進行合并,使兩個集合中任意兩個元素都連通
void Union(int R1, int R2)
{
int r1 = Find(R1), r2 = Find(R2); //r1和r2分別為R1和R2的根結點
int tmp = parent[r1] + parent[r2]; //兩個集合結點數之和(負數)
//如果R2所在樹結點個數 > R1所在樹結點個數(注意parent[r1]是負數)
if (parent[r1] > parent[r2])
{
parent[r1] = r2;
parent[r2] = tmp;
}
else
{
parent[r2] = r1;
parent[r1] = tmp;
}
}
int cmp(const void* a, const void* b) //實作從小到大的比較函式
{
edge aa = *(const edge*)a, bb = *(const edge*)b;
return aa.w - bb.w;
}
void Kruskal()
{
int sumweight = 0; //生成樹的權值
int num = 0; //已選用的邊的數目
UFset(); //初始化parent陣列
for (i = 0; i < m; i++)
{
if (Find(edges[i].u) != Find(edges[i].v))
{
printf("%d %d %d\n", edges[i].u, edges[i].v, edges[i].w);
sumweight += edges[i].w; num++;
Union(edges[i].u, edges[i].v);
}
if (num >= n - 1) break;
}
printf("The weight of MST is : %d\n", sumweight);
}
void main()
{
scanf("%d%d", &n, &m); //讀入頂點個數和邊數
for (int i = 0; i < m; i++)
scanf("%d%d%d", &edges[i].u, &edges[i].v, &edges[i].w); //讀入邊的起點和終點
printf("The edges chosen are :\n");
qsort(edges, m, sizeof(edges[0]), cmp); //對邊按權值從小到大排序
Kruskal();
}
prim(更新于2021/1/6)
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<algorithm>
using namespace std;
#define INF 0x3f3f3f3f
#define MAXN 110
int map[MAXN][MAXN], lowcost[MAXN];
bool visit[MAXN];
int nodenum, sum;
void prim()
{
int temp, k;
sum = 0;
memset(visit, false, sizeof(visit)); //初始化visit
visit[1] = true;
for (int i = 1; i <= nodenum; ++i) //初始化lowcost[i]
lowcost[i] = map[1][i];
for (int i = 1; i <= nodenum; ++i)//找生成樹集合點集相連最小權值的邊
{
temp = INF;
for (int j = 1; j <= nodenum; ++j)
if (!visit[j] && temp > lowcost[j])
temp = lowcost[k = j];
if (temp == INF) break;
visit[k] = true; //加入最小生成樹集合
sum += temp;//記錄權值之和
for (int j = 1; j <= nodenum; ++j) //更新lowcost陣列
if (!visit[j] && lowcost[j] > map[k][j])
lowcost[j] = map[k][j];
}
}
int main()
{
int a, b, cost, edgenum;
while (scanf("%d", &nodenum) && nodenum)//結點數
{
memset(map, INF, sizeof(map));
edgenum = nodenum * (nodenum - 1) / 2;
for (int i = 1; i <= edgenum; ++i) //輸入邊的資訊
{
scanf("%d%d%d", &a, &b, &cost);
if (cost < map[a][b])
map[a][b] = map[b][a] = cost;
}
prim();
printf("%d\n", sum); //最小生成樹權值之和
}
return 0;
}
歐拉通路與歐拉回路
判斷存在歐拉回路(更新于2021/1/6)
#include <stdio.h>
int arr[1000];
int father[1000];
int rand_deep[1000];
int findSet(int x) {
int px = x, i;
while (px != father[px])
px = father[px];
//路徑壓縮,加快查找速度
while (x != px) {
i = father[x];
father[x] = px;
x = i;
}
return px;
}
void unionSet(int x, int y) {
x = findSet(x);
y = findSet(y);
if (rand_deep[x] > rand_deep[y])
father[y] = x;
else {
father[x] = y;
if (rand_deep[x] == rand_deep[y])rand_deep[y]++;
}
}
//并查集
int main() {
int N, M;
while (scanf("%d", &N) != EOF && N) {
scanf("%d", &M);
int i;
int flag = 1;
for (i = 1; i <= N; i++) {
father[i] = i;
rand_deep[i] = 0;
arr[i] = 0;
}
for (i = 0; i < M; i++) {
int x, y;
scanf("%d %d", &x, &y);
arr[x] ++;
arr[y] ++;
unionSet(x, y);
}
int father;
for (i = 1; i <= N; i++) {
if (i == 1)
father = findSet(1);
else {
if (father != findSet(i)) {
flag = 0;
break;
}
}
if (arr[i] == 0 || arr[i] % 2 != 0) {
flag = 0;
break;
}
}
//判斷是否在同一連通分量中
printf("%d\n", flag);
}
return 0;
}
尋找歐拉路徑(更新于2021/1/6)
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string.h>
#include<algorithm>
#include<vector>
using namespace std;
const int N = 1005;
int n, m, flag, top, sum, du[N], ans[5005], map[N][N];
void dfs(int x)
{
ans[++top] = x;
for (int i = 1; i <= n; i++)
{
if (map[x][i] >= 1)
{
map[x][i]--;
map[i][x]--;
dfs(i);
break;
}
}
}
void fleury(int x)
{
top = 1;
ans[top] = x;
while (top > 0)
{
int k = 0;
for (int i = 1; i <= n; i++)//判斷是否可擴展
{
if (map[ans[top]][i] >= 1)//若存在一條從ans[top]出發的邊 那么就是可擴展
{
k = 1; break;
}
}
if (k == 0)//該點x沒有其他的邊可以先走了(即不可擴展), 那么就輸出它
{
printf("%d ", ans[top]);
top--;
}
else if (k == 1)//如可擴展, 則dfs可擴展的哪條路線
{
top--;//這需要注意
dfs(ans[top + 1]);
}
}
}
int main()
{
while (scanf("%d%d", &n, &m) != EOF)
{
memset(du, 0, sizeof(du));
memset(map, 0, sizeof(map));
for (int i = 1; i <= m; i++)
{
int x, y;
scanf("%d%d", &x, &y);
map[x][y]++; //記錄邊, 因為是無向圖所以加兩條邊, 兩個點之間可能有多條邊
map[y][x]++;
du[x]++;
du[y]++;
}
flag = 1; // flag標記開始點, 如果所有點度數全為偶數那就從1開始搜
sum = 0;
for (int i = 1; i <= n; i++)
{
if (du[i] % 2 == 1)
{
sum++;
flag = i;// 若有奇數邊, 從奇數邊開始搜
}
}
if (sum == 0 || sum == 2)//度數均為偶數或僅有兩個奇度定點則開始演算法
fleury(flag);
}
return 0;
}
prufer編碼
prufer編碼轉樹(更新于2021/1/6)
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<queue>
using namespace std;
#define MAX 20//頂點數最大值
typedef struct arc
{
int u;
int v;
}arcnode;
queue<int> q1;
int flag[MAX];
int n, m, edgenum;
int min();
int main()
{
arcnode edge[MAX * (MAX - 1) / 2];//邊集
scanf_s("%d", &n);//頂點數
for (int i = 0; i < n - 2; i++)
{
scanf_s("%d", &m);
q1.push(m);
flag[m]++;
}
q1.push(n);
flag[n]++;
while(!q1.empty())
{
int u = min();
flag[u]++;
int v = q1.front();
q1.pop();
flag[v]--;
edge[edgenum].u = u;
edge[edgenum].v = v;
edgenum++;
}
for (int i = 0; i < edgenum; i++)
{
printf("(%d,%d)\n", edge[i].u, edge[i].v);
}
return 0;
}
int min()//求不在佇列內的點編號最小值
{
for (int i = 1; i <= n; i++)
{
if (flag[i] == 0)return i;
}
}
LCA(更新于2021/1/6)
#include<cstdio>
#include<iostream>
#define MAX 600000
using namespace std;
int n, m, s;//樹節點個數,詢問個數,根節點序號
int x, y;//查詢點序號
int father[MAX][20], log_2[MAX], depth[MAX],lca[MAX];//father[i][j]表示節點i的第2^j級祖先
struct node
{
int to;
int next;
}edge[2*MAX];
int cnt, u, v, head[MAX];
void add_edge(int u, int v);
void dfs(int present_node, int father_node);
int LCA(int x, int y);//求點x和y的最近公共祖先
int main()
{
memset(head, -1, sizeof(head));
scanf_s("%d%d%d", &n, &m, &s);//樹節點個數,詢問個數,根節點序號
for (int i = 0; i < n - 1; i++)
{
scanf_s("%d%d", &u, &v);
add_edge(u, v); add_edge(v, u);
}
for (int i = 1; i <= n; ++i) //預先算出log_2(i)+1的值
log_2[i] = log_2[i - 1] + (1 << log_2[i - 1] == i);
dfs(s, 0);
for (int i = 0; i < m; i++)
{
scanf_s("%d%d", &x, &y);
lca[i] = LCA(x, y);
}
for (int i = 0; i < m;i++)printf("%d\n", LCA(x, y));
return 0;
}
void add_edge(int u, int v)
{
edge[++cnt] = node{ v,head[u] };
head[u] = cnt;
}
void dfs(int present_node, int father_node)
{
father[present_node][0] = father_node;
depth[present_node] = depth[father_node] + 1;
for (int i = 1; i <= log_2[depth[present_node]]; i++)
{
father[present_node][i] = father[father[present_node][i - 1]][i - 1];
}//當前節點的2^i祖先等于當前節點的2^(i-1)級祖先的2^(i-1)級祖先即2^i=2^(i+1)+2^(i+1)
for (int i = head[present_node]; i; i = edge[i].next)
{
if (edge[i].to != father_node)
dfs(edge[i].to, present_node);
}
}
int LCA(int x, int y)
{
if (depth[x] < depth[y])
swap(x, y);//不妨x的深度大于y的深度
while (depth[x] > depth[y])
x = father[x][log_2[depth[x] - depth[y]] - 1];//將x跳到與y同深度
if (x == y)return x;
for (int k = log_2[depth[x]] - 1; k >= 0; --k) //不斷向上跳
{
if (father[x][k] != father[y][k]) //因為我們要跳到它們LCA的下面一層,所以它們肯定不相等,如果不相等就跳過去,
x = father[x][k], y = father[y][k];
}
return father[x][0]; //回傳父節點
}
tarjan求割點(更新于2021/1/6)
#include<bits/stdc++.h>
#include<cstdio>
#include<iostream>
#include<algorithm>
#define MAX 20100
using namespace std;
int n, m, index1, cutnum;
int LOW[MAX], cut_vex[MAX], DFN[MAX];
struct node
{
int to;
int next;
}edge[MAX * 10];
int u, v;
int head[MAX], cnt;
void add_edge(int u, int v);
void tarjan(int u, int fa);
int main()
{
memset(DFN, 0, sizeof(DFN));
memset(head, -1, sizeof(head));
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i++)
{
scanf("%d%d", &u, &v);
add_edge(u, v);
add_edge(v, u);
}
for (int i = 1; i <= n; i++)
{
if (DFN[i] == 0)
tarjan(i, i);
}
for (int i = 1; i <= n; i++)
{
if (cut_vex[i])
cutnum++;
}
printf("%d\n", cutnum);
for (int i = 1; i <= n; i++)
{
if (cut_vex[i])
printf("%d ", i);
}
}
void add_edge(int u, int v)
{
edge[++cnt].to = v;
edge[cnt].next = head[u];
head[u] = cnt;
}
void tarjan(int u, int fa)//當前節點及其父節點
{
index1++;
DFN[u] = index1;
LOW[u] = index1;//index記錄遍歷的點的個數,當前節點的DFN和LOW均為查詢順序
int child = 0;
for (int i = head[u]; i != -1; i = edge[i].next)//遍歷當前節點的所有子節點
{
int nx = edge[i].to;
if (!DFN[nx])//若該子節點未訪問則求出其所在連通分量
{
tarjan(nx, fa);
LOW[u] = min(LOW[u], LOW[nx]);//更新當前節點的最近根節點
if (LOW[nx] >= DFN[u] && u != fa)//
cut_vex[u] = 1;
if (u == fa)
child++;
}
LOW[u] = min(LOW[u], DFN[nx]);
}
if (child >= 2 && u == fa)
cut_vex[u] = 1;
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/246069.html
標籤:其他