Python爬蟲學習( 一 )
Web大致有三層
- 客戶端:訪問遠程網站;
- 服務端:為網站和Web API 提供資料;
- Web API 和服務:用另一種不同于可視化網頁的方式來交換資料,
互聯網最底層的網路傳輸使用的是:傳輸控制協議 / 因特網協議,更常用的叫法是TCP/IP,
TCP/IP
? 因特網是基于規則的,這些規則定義了如何創建連接、交換資料、中止連接、處理超時等,這些規則被稱為協議,
? 它們被分布在不同的層中,分層的目的是兼容多種實作方法,你可以在某一層中做任何想做的事情,只要遵循上一個層和下一層的約定,
? 最底層處理的是電信號,其余層都是基于下面的層構建而成,在大約中間的的位置是 IP( 因特網協議 )層,這層規定了網路位置和地址的映射方法以及資料包的傳輸方式,
爬蟲基礎:
URI 和 URL
? URI指的是統一資源識別符號,URL是統一資源定位符,
? 我們可以用 URL/URI 來唯一指定某個網站的訪問方式,例如:https://www.baidu.com:443,這其中包括了訪問協議https、訪問路徑…,通過這樣的一個鏈接,我們可以從互聯網上找到這個資源,這個就URL/URI,
? URL是URI的子集,也就是說每個URL都是URI,但不是每個URI都是URL,URI還包括一個子類叫做URN,叫做統一資源名稱,URN只命名資源而不指定如何定位資源,例如urn:0451450523指定了一本書的ISBN( 國際標準書號 ),可以唯一標識這本書,但是沒有指定到哪里定位這本書,這就是URN,
HTTP和HTTPS
? URL的開頭會有http或https,這就是訪問資源需要的協議型別,有時候,我們還會看到ftp、sftp、smb開頭的URL,它們都是協議型別,在爬蟲中,我們抓取的網頁通常就是http或https協議的,
? HTTP的中文名叫超文本傳輸協議,HTTP協議是用于從網路傳輸超文本資料到本地瀏覽器的傳送協議,它能保證高效而準確地傳送超文本檔案,
? HTTPS是以安全為目標的HTTP通道,簡單講是HTTP的安全版,即HTTP下加入SSL層,簡稱為HTTPS,
? HTTPS的安全基礎是SSL,因此通過它傳輸的內容都是經過SSL加密的,它的主要作用可以分為兩種:
- 建立一個資訊安全通道來保證資料傳輸的安全,
- 確認網站的真實性,凡是使用了HTTPS的網站,都可以通過點擊瀏覽器地址欄的鎖頭標志,來查看網站認證之后的真實資訊,也可以通過CA機構頒發的安全簽章來查詢,
HTTP請求程序
? 我們在瀏覽器中輸入一個URL,回車之后便會在瀏覽器中觀察到頁面內容,實際上,這個程序是瀏覽器向網站所在的服務器發送了一個請求,網站服務器接受到這個請求后進行處理和決議,然后回傳對應的回應,接著傳回給瀏覽器,回應里包含了頁面的源代碼等內容,瀏覽器再對其進行決議,便將網頁呈現了出來,
? 客戶端>>>服務器,服務器>>>客戶端
? 此處客戶端代表我們自己的PC( 個人計算機 )或者手機瀏覽器,服務器即要訪問的網站所在的服務器,
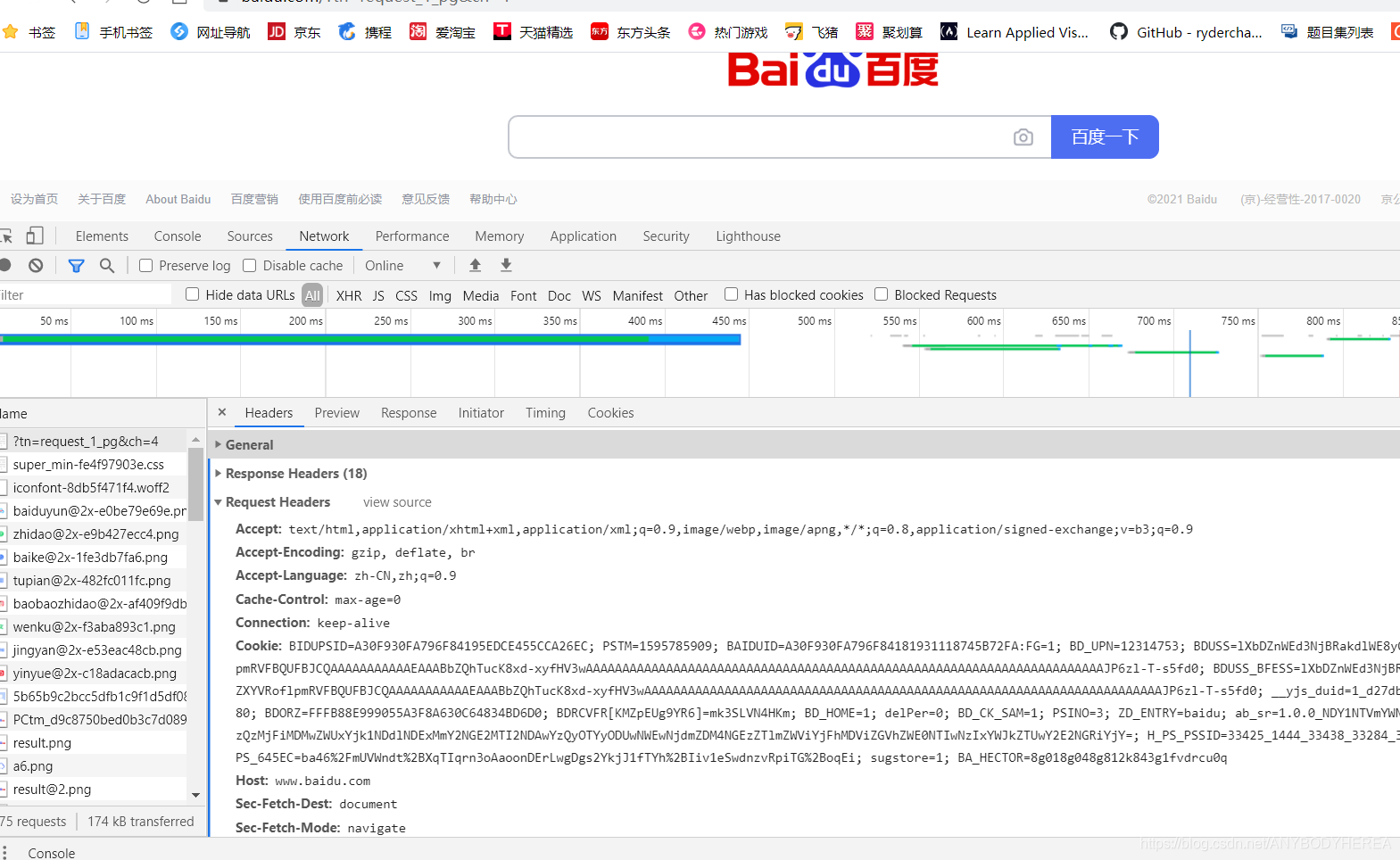
點開可以看到,存在Response Headers 和 Request Headers,這分別代表回應頭和請求頭,請求頭里帶有許多請求資訊,例如瀏覽器表示、Cookies、Host等資訊,這是請求的一部分,服務器會根據請求頭內的資訊判斷請求是否合法,進而做出對應的回應,Response Headers就是回應的一部分,例如其中包含了服務器的型別、檔案型別、日期等資訊,瀏覽器接受到回應后,會決議回應內容,進而呈現網頁內容,
請求
? 請求,由客戶端向服務端發出,可以分為4部分內容:
? 請求方法( Request Method )、請求的網址( Request URL )、請求頭( Request Headers )、請求體( Request Body )
? 1、請求方法
? 常見的請求方法有兩種:GET 和 POST
? 在瀏覽器中直接輸入URL并回車,這便發起了一個GET請求,請求的引數會直接包含到URL里,
? 例如,在百度中搜索Python,這就是一個GET請求,鏈接為https://www.baidu.com/s?wd=Python,其中URL中包含了請求的引數資訊,這里引數wd表示要搜尋的關鍵字,

? POST請求大多在表單提交時發起,比如,對于一個登錄表單,輸入用戶名和密碼后,點擊"登錄"按鈕,這通常會發起一個POST請求,其資料通常以表單的形式傳輸,而不會體現在URL中,
? GET和POST請求方法有如下區別:
-
GET請求中的引數包含在URL里面,資料可以在URL中看到,而POST請求的URL不會包含這些資料,資料都是通過表單的形式傳輸,會包含在請求體中;
-
GET請求提交的資料最多只有1024位元組,而POST方式沒有限制;
一般來說,登錄時,需要提交用戶名和密碼,其中包含了敏感資訊,使用GET方式請求的話,密碼就會暴露在URL里面,造成密碼泄露,所以這里最好以POST方式發送,上傳檔案時,由于檔案內容比較大,也會選用POST方式,

? 2、請求的網址
? 請求的網址,即統一資源定位符URL,它可以唯一確定我們想請求的資源,
? 3、請求頭
? 請求頭,用來說明服務器使用的附加資訊,比較重要的資訊有Cookie、Referer、User-Agent等,

-
Cookie:也常用復數形式Cookies,這是網站為了辨別用戶進行會話跟蹤而儲存在用戶本地的資料,它的主要功能是維持當前訪問會話,例如,我們輸入用戶名和密碼成功登錄某個網站后,服務器會用會話保存登錄狀態資訊,后面我們每次重繪或請求該站點的其他頁面時,會發現都是登錄狀態,這就是Cookies的功勞,Cookies里有資訊標識了我們所對應的服務器的會話,每次瀏覽器在請求該站點的頁面時,都會在請求頭中加上Cookies并將其發送給服務器,服務器通過Cookies識別出是我們自己,并且查出當前狀態是登錄狀態,所以回傳結果就是登錄之后才能看到的網頁內容,
-
Referer:此內容用來表示這個請求是從哪個頁面發過來的,服務器可以拿到這一資訊并做相應的處理,如做來源統計、防盜鏈處理等,
-
User-Agent:簡稱UA,它是一個特殊的字串頭,可以使服務器識別客戶使用的作業系統及版本、瀏覽器及版本等資訊,在做爬蟲時加上此資訊,可以偽裝為瀏覽器;如果不加,很可能會被識別出為爬蟲,
因此,請求頭使請求的重要組成部分,在寫爬蟲時,大部分情況下都需要設定請求頭,
? 4、請求體
? 登錄之前,我們填寫了用戶名和密碼資訊,提交時這些內容就會以表單資料的形式交給服務器,此時注意例子Request Headers 中指定Content-Type 為 application/x-www-form-urlencoded,只有Content-Type設定為application/x-www-form-urlencoded,才會以表單資料的形式提交,

? 在爬蟲中,如果要構造POST請求,需要使用正確的Content-Type,并了解各種請求庫的各個引數設定時使用的使哪種Content-Type,不然可能會導致POST提交后無法正常回應,
回應
? 回應,由服務端回傳給客戶端,可以分為三部分:
? 回應狀態碼( Response Status Code )、回應頭( Response Headers )和回應體( Response Body )
? 1、回應狀態碼表示服務器的回應狀態,如 200 代表服務器正常回應,404 代表頁面未找到,500 代表服務器內部發生錯誤,在爬蟲中,我們可以根據狀態碼來判斷服務器回應狀態,如狀態碼為200,則證明成功回傳資料,再進行進一步處理, 否則直接忽略,

? 2、回應頭
? 回應頭包含了服務器對請求的應答資訊,如Content-Type、Server、Set-Cookie等,
- Date:標識回應產生的時間;
- Last-Modified:指定資源的最后修改時間;
- Content-Encoding:指定回應內容的編碼
- Server:包含服務器的資訊,比如名稱、版本號等;
- Content-Type:檔案型別,指定回傳的資料型別是什么,如text/html代表回傳HTML檔案;
- Set-Cookie:設定Cookies,回應頭中的Set-Cookie告訴瀏覽器需要將此內容放在Cookies中,下次請求攜帶Cookies請求,
- Expires:指定回應的過期時間,可以使代理服務器或瀏覽器將加載的內容更新到快取中,如果再次訪問時,就可以直接從快取中加載,降低服務器負載,縮短加載時間,
? 3、回應體
? 最重要的當屬回應體的內容了,回應的正文資料都在回應體中,比如請求網頁時,它的回應體就是網頁的HTML代碼;請求一張圖片時,它的回應體就是圖片的二進制資料,我們做爬蟲請求網頁后,要決議的內容就是回應體,
? 在做爬蟲時,我們主要通過回應體得到網頁的源代碼、JSON資料等,然后從中做回應內容的提取,
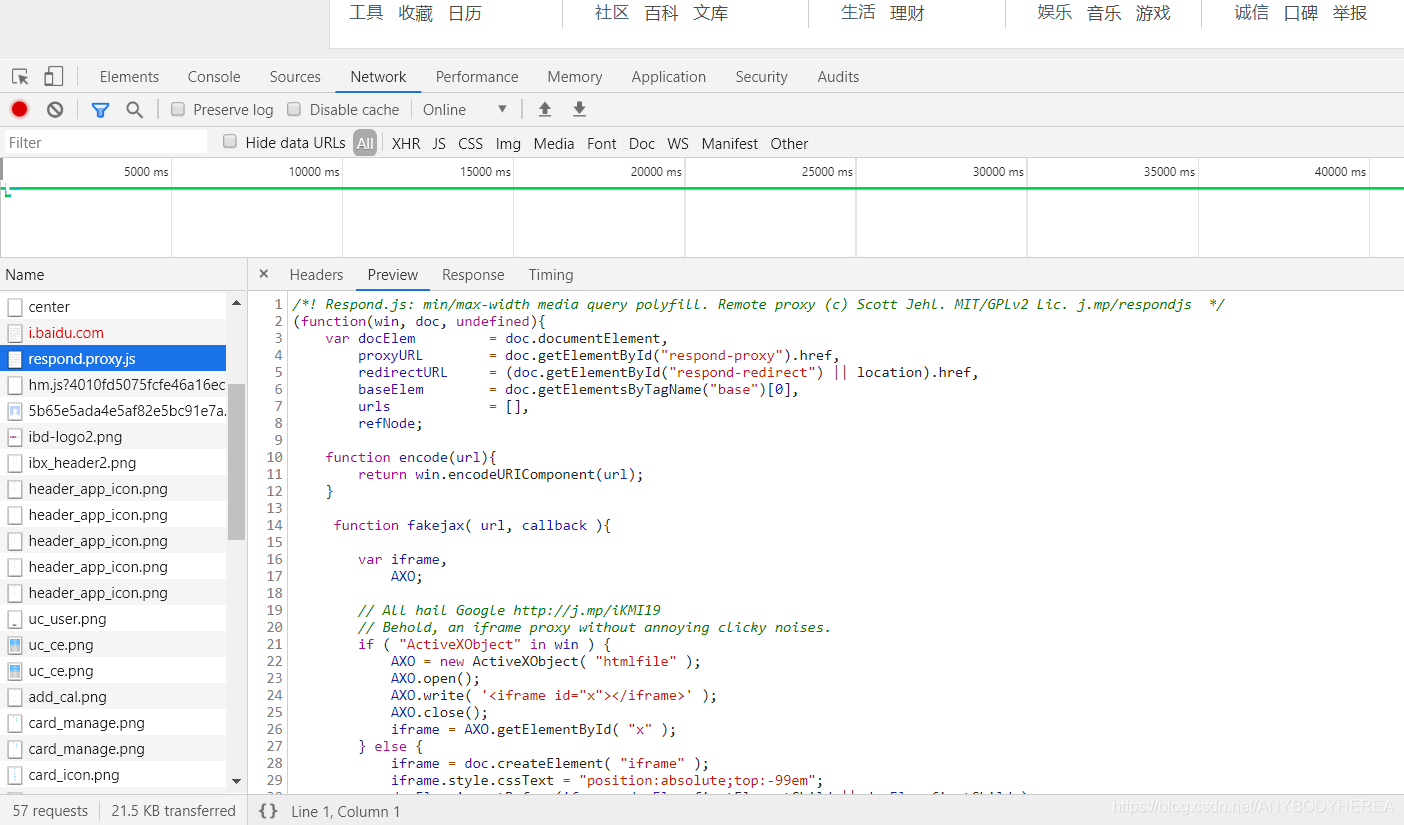
在瀏覽器開發者工具中點擊 Preview,就可以看到網頁的源代碼,也就是回應體的內容,它是決議的內容,
提示:
內容大多來自崔慶才《Python3——網路爬蟲開發實戰》
網址:https://www.ituring.com.cn/book/tupubarticle/29396
如有侵權,請聯系本人洗掉,謝謝,
本人只是某大學學生,發布該篇博客作為該書的學習筆記,和大家一起分享學習和交流,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/246205.html
標籤:其他