本次更新一下SQL執行流程,本篇為上集,喜歡的朋友們可以三連支持一下哦!這才是博主更新的動力~
目錄
- 一、SQL 執??口
- 1.1 為 Mapper 接?創建代理物件
- 1.2 執?代理邏輯
- 1. 創建 MapperMethod 物件
- 2. 執? execute ?法
- 二、 查詢陳述句的執?程序
- 2.1 selectOne ?法分析
- 2.2 獲取 BoundSql
- 1.DynamicContext
- 2. 決議 SQL ?段
一、SQL 執??口
在單獨使用 MyBatis 進行資料庫操作時,我們通常都會先呼叫 SqlSession 介面的
getMapper方法為我們的Mapper介面生成實作類,然后就可以通過Mapper進行資料庫操作,
比如像下面這樣:
ArticleMapper articleMapper = session.getMapper(ArticleMapper.class);
Article article = articleMapper.findOne(1);
如果大家對 MyBatis 較為了解,會知道 SqlSession 是通過 JDK 動態代理的方式為介面
生成代理物件的,在呼叫介面方法時,相關呼叫會被代理邏輯攔截,在代理邏輯中可根據方
法名及方法歸屬介面獲取到當前方法對應的 SQL 以及其他一些資訊,拿到這些資訊即可進
行資料庫操作,
以上是一個簡版的 SQL 執行程序,省略了很多細節,下面我們先按照這個簡版的流程
進行分析,首先來看一下 Mapper 介面的代理物件創建程序,
1.1 為 Mapper 接?創建代理物件
本節,我們從 DefaultSqlSession 的 getMapper 方法開始看起,如下:
// -☆- DefaultSqlSession
public <T> T getMapper(Class<T> type) {
return configuration.<T>getMapper(type, this);
}
// -☆- Configuration
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
return mapperRegistry.getMapper(type, sqlSession);
}
// -☆- MapperRegistry
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
// 從 knownMappers 中獲取與 type 對應的 MapperProxyFactory
final MapperProxyFactory<T> mapperProxyFactory =
(MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("……");
}
try {
// 創建代理物件
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("……");
} }
如上,經過連續的呼叫,Mapper 介面代理物件的創建邏輯初現端倪,如果大家沒分析過
MyBatis組態檔的決議程序,那么可能不知道knownMappers集合中的元素是何時存入的,
這 里簡 單說 明一 下,MyBatis 在決議組態檔的節點的程序中,會呼叫MapperRegistry 的 addMapper 方法將 Class 到 MapperProxyFactory 物件的映射關系存入到knownMappers,具體的代碼就不分析了,大家可以閱讀我之前寫的文章,或者自行分析相關的代碼,
在獲取到 MapperProxyFactory 物件后,即可呼叫工廠方法為 Mapper 介面生成代理物件
了,相關邏輯如下:
// -☆- MapperProxyFactory
public T newInstance(SqlSession sqlSession) {
// 創建 MapperProxy 物件,MapperProxy 實作了 InvocationHandler 介面,
// 代理邏輯封裝在此類中
final MapperProxy<T> mapperProxy =
new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
protected T newInstance(MapperProxy<T> mapperProxy) {
// 通過 JDK 動態代理創建代理物件
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(),
new Class[]{mapperInterface}, mapperProxy);
}
上面的代碼首先創建了一個 MapperProxy 物件,該物件實作了 InvocationHandler 介面,
然后將物件作為引數傳給多載方法,并在多載方法中呼叫 JDK 動態代理介面為 Mapper 生成
代理物件,代理物件已經創建完畢,下面就可以呼叫介面方法進行資料庫操作了,由于介面
方法會被代理邏輯攔截,所以下面我們把目光聚焦在代理邏輯上面,看看代理邏輯會做哪些
事情,
1.2 執?代理邏輯
Mapper 介面方法的代理邏輯首先會對攔截的方法進行一些檢測,以決定是否執行后續
的資料庫操作,對應的代碼如下:
public Object invoke(Object proxy,
Method method, Object[] args) throws Throwable {
try {
// 如果方法是定義在 Object 類中的,則直接呼叫
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
/*
* 下面的代碼最早出現在 mybatis-3.4.2 版本中,用于支持 JDK 1.8 中的
* 新特性 - 默認方法,這段代碼的邏輯就不分析了,有興趣的同學可以
* 去 Github 上看一下相關的相關的討論(issue #709),鏈接如下:
*
* https://github.com/mybatis/mybatis-3/issues/709
*/
} else if (isDefaultMethod(method)) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
// 從快取中獲取 MapperMethod 物件,若快取未命中,則創建 MapperMethod 物件
final MapperMethod mapperMethod = cachedMapperMethod(method);
// 呼叫 execute 方法執行 SQL
return mapperMethod.execute(sqlSession, args);
}
如上,代理邏輯會首先檢測被攔截的方法是不是定義在 Object 中的,比如 equals、
hashCode 方法等,對于這類方法,直接執行即可,除此之外,MyBatis 從 3.4.2 版本開始,
對 JDK1.8 介面的默認方法提供了支持,具體就不分析了,完成相關檢測后,緊接著從快取
中獲取或者創建 MapperMethod 物件,然后通過該物件中的 execute 方法執行 SQL,在分析execute 方法之前,我們先來看一下 MapperMethod 物件的創建程序,MapperMethod 的創建程序看似普通,但卻包含了一些重要的邏輯,所以不能忽視,
1. 創建 MapperMethod 物件
本節來分析一下 MapperMethod 的構造方法,看看它的構造方法中都包含了哪些邏
輯,如下:
public class MapperMethod {
private final SqlCommand command;
private final MethodSignature method;
public MapperMethod(Class<?> mapperInterface,
Method method, Configuration config) {
// 創建 SqlCommand 物件,該物件包含一些和 SQL 相關的資訊
this.command = new SqlCommand(config, mapperInterface, method);
// 創建 MethodSignature 物件,由類名可知,該物件包含了被攔截方法的一些資訊
this.method = new MethodSignature(config, mapperInterface, method);
} }
MapperMethod 構造方法的邏輯很簡單,主要是創建 SqlCommand 和 MethodSignature 對
象,這兩個物件分別記錄了不同的資訊,這些資訊在后續的方法呼叫中都會被用到,下面我
們深入到這兩個類的構造方法中,探索它們的初始化邏輯,
- 創建 SqlCommand 物件
前面說了 SqlCommand 中保存了一些和 SQL 相關的資訊,那具體有哪些資訊呢?答案
在下面的代碼中,
public static class SqlCommand {
private final String name;
private final SqlCommandType type;
public SqlCommand(Configuration configuration,
Class<?> mapperInterface, Method method) {
final String methodName = method.getName();
final Class<?> declaringClass = method.getDeclaringClass();
// 決議 MappedStatement
MappedStatement ms = resolveMappedStatement(
mapperInterface, methodName, declaringClass, configuration);
// 檢測當前方法是否有對應的 MappedStatement
if (ms == null) {
// 檢測當前方法是否有 @Flush 注解
if (method.getAnnotation(Flush.class) != null) {
// 設定 name 和 type 遍歷
name = null;
type = SqlCommandType.FLUSH;
} else {
// 若 ms == null 且方法無 @Flush 注解,此時拋出例外,
// 這個例外比較常見,大家應該眼熟吧
throw new BindingException("……");
}
} else {
// 設定 name 和 type 變數
name = ms.getId();
type = ms.getSqlCommandType();
if (type == SqlCommandType.UNKNOWN) {
throw new BindingException("……");
}
}
} }
SqlCommand 的構造方法主要用于初始化它的兩個成員變數,代碼不是很長,
邏輯也不難理解,就不多說了,繼續往下看,
- 創建 MethodSignature 物件
MethodSignature 即方法簽名,顧名思義,該類保存了一些和目標方法相關的資訊,比如
目標方法的回傳型別,目標方法的引數串列資訊等,下面,我們來分析一下 MethodSignature
的構造方法,
public static class MethodSignature {
private final boolean returnsMany;
private final boolean returnsMap;
private final boolean returnsVoid;
private final boolean returnsCursor;
private final Class<?> returnType;
private final String mapKey;
private final Integer resultHandlerIndex;
private final Integer rowBoundsIndex;
private final ParamNameResolver paramNameResolver;
public MethodSignature(Configuration configuration,
Class<?> mapperInterface, Method method) {
// 通過反射決議方法回傳型別
Type resolvedReturnType = TypeParameterResolver
.resolveReturnType(method, mapperInterface);
if (resolvedReturnType instanceof Class<?>) {
this.returnType = (Class<?>) resolvedReturnType;
} else if (resolvedReturnType instanceof ParameterizedType) {
this.returnType = (Class<?>) (
(ParameterizedType) resolvedReturnType).getRawType();
} else {
this.returnType = method.getReturnType();
}
// 檢測回傳值型別是否是 void、集合或陣列、Cursor、Map 等
this.returnsVoid = void.class.equals(this.returnType);
this.returnsMany = configuration.getObjectFactory()
.isCollection(this.returnType) || this.returnType.isArray();
this.returnsCursor = Cursor.class.equals(this.returnType);
// 決議 @MapKey 注解,獲取注解內容
this.mapKey = getMapKey(method);
this.returnsMap = this.mapKey != null;
// 獲取 RowBounds 引數在引數串列中的位置,如果引數串列中
// 包含多個 RowBounds 引數,此方法會拋出例外
this.rowBoundsIndex = getUniqueParamIndex(method, RowBounds.class);
// 獲取 ResultHandler 引數在引數串列中的位置
this.resultHandlerIndex =
getUniqueParamIndex(method, ResultHandler.class);
// 決議引數串列
this.paramNameResolver =
new ParamNameResolver(configuration, method);
} }
上面的代碼用于檢測目標方法的回傳型別,以及決議目標方法引數串列,其中,檢測返
回型別的目的是為避免查詢方法回傳錯誤的型別,比如我們要求介面方法回傳一個物件,結
果卻回傳了物件集合,這會導致型別轉換錯誤,關于回傳值型別的決議程序先說到這,下面
分析引數串列的決議程序,
public class ParamNameResolver {
private static final String GENERIC_NAME_PREFIX = "param";
private final SortedMap<Integer, String> names;
public ParamNameResolver(Configuration config, Method method) {
// 獲取引數型別串列
final Class<?>[] paramTypes = method.getParameterTypes();
// 獲取引數注解
final Annotation[][] paramAnnotations =
method.getParameterAnnotations();
final SortedMap<Integer, String> map =
new TreeMap<Integer, String>();
int paramCount = paramAnnotations.length;
for (int paramIndex = 0; paramIndex < paramCount; paramIndex++) {
// 檢測當前的引數型別是否為 RowBounds 或 ResultHandler
if (isSpecialParameter(paramTypes[paramIndex])) {
continue;
}
String name = null;
for (Annotation annotation : paramAnnotations[paramIndex]) {
if (annotation instanceof Param) {
hasParamAnnotation = true;
// 獲取 @Param 注解內容
name = ((Param) annotation).value();
break;
}
}
// name 為空,表明未給引數配置 @Param 注解
if (name == null) {
// 檢測是否設定了 useActualParamName 全域配置
if (config.isUseActualParamName()) {
// 通過反射獲取引數名稱,此種方式要求 JDK 版本為 1.8+,
// 且要求編譯時加入 -parameters 引數,否則獲取到的引數名
// 仍然是 arg1, arg2, ..., argN
name = getActualParamName(method, paramIndex);
}
if (name == null) {
/*
* 使用 map.size() 回傳值作為名稱,思考一下為什么不這樣寫:
* name = String.valueOf(paramIndex);
* 因為如果引數串列中包含 RowBounds 或 ResultHandler,這兩個
* 引數會被忽略掉,這樣將導致名稱不連續,
*
* 比如引數串列 (int p1, int p2, RowBounds rb, int p3)
* - 期望得到名稱串列為 ["0", "1", "2"]
* - 實際得到名稱串列為 ["0", "1", "3"]
*/
name = String.valueOf(map.size());
}
}
// 存盤 paramIndex 到 name 的映射
map.put(paramIndex, name);
}
names = Collections.unmodifiableSortedMap(map);
} }
方法引數串列決議完畢后,可得到引數下標與引數名的映射關系,這些映射關系最終存
儲在 ParamNameResolver 的 names 成員變數中,這些映射關系將會在后面的代碼中被用到,大家留意一下,下面寫點代碼測驗一下 ParamNameResolver 的決議邏輯,如下:
public class ParamNameResolverTest {
@Test
public void test() throws NoSuchMethodException,
NoSuchFieldException, IllegalAccessException {
Configuration config = new Configuration();
config.setUseActualParamName(false);
Method method = ArticleMapper.class.getMethod("select",
Integer.class, String.class, RowBounds.class, Article.class);
ParamNameResolver resolver = new ParamNameResolver(config, method);
Field field = resolver.getClass().getDeclaredField("names");
field.setAccessible(true);
// 通過反射獲取 ParamNameResolver 私有成員變數 names
Object names = field.get(resolver);
System.out.println("names: " + names);
}
class ArticleMapper {
public void select(@Param("id") Integer id,
@Param("author") String author, RowBounds rb, Article article) {}
} }
測驗結果如下

引數索引與名稱映射圖如下

到此,關于 MapperMethod 的初始化邏輯就分析完了,繼續往下分析,
2. 執? execute ?法
前面已經分析了 MapperMethod 的初始化程序,現在 MapperMethod 創建好了,那么,
接下來要做的事情是呼叫 MapperMethod 的 execute 方法,執行 SQL,代碼如下:
// -☆- MapperMethod
public Object execute(SqlSession sqlSession, Object[] args) {
Object result;
// 根據 SQL 型別執行相應的資料庫操作
switch (command.getType()) {
case INSERT: {
// 對用戶傳入的引數進行轉換,下同
Object param = method.convertArgsToSqlCommandParam(args);
// 執行插入操作,rowCountResult 方法用于處理回傳值
result = rowCountResult(s
qlSession.insert(command.getName(), param));
break;
}
case UPDATE: {
Object param = method.convertArgsToSqlCommandParam(args);
// 執行更新操作
result = rowCountResult(
sqlSession.update(command.getName(), param));
break;
}
case DELETE: {
Object param = method.convertArgsToSqlCommandParam(args);
// 執行洗掉操作
result = rowCountResult(
sqlSession.delete(command.getName(), param));
break;
}
case SELECT:
// 根據目標方法的回傳型別進行相應的查詢操作
if (method.returnsVoid() && method.hasResultHandler()) {
// 如果方法回傳值為 void,但引數串列中包含 ResultHandler,表明
// 使用者想通過 ResultHandler 的方式獲取查詢結果,而非通過回傳值
// 獲取結果
executeWithResultHandler(sqlSession, args);
result = null;
} else if (method.returnsMany()) {
// 執行查詢操作,并回傳多個結果
result = executeForMany(sqlSession, args);
} else if (method.returnsMap()) {
// 執行查詢操作,并將結果封裝在 Map 中回傳
result = executeForMap(sqlSession, args);
} else if (method.returnsCursor()) {
// 執行查詢操作,并回傳一個 Cursor 物件
result = executeForCursor(sqlSession, args);
} else {
Object param = method.convertArgsToSqlCommandParam(args);
// 執行查詢操作,并回傳一個結果
result = sqlSession.selectOne(command.getName(), param);
}
break;
case FLUSH:
// 執行重繪操作
result = sqlSession.flushStatements();
break;
default:
throw new BindingException("……");
}
// 如果方法的回傳值為基本型別,而回傳值卻為 null,此種情況下應拋出例外
if (result == null && method.getReturnType().isPrimitive()
&& !method.returnsVoid()) {
throw new BindingException("……");
}
return result; }
如上,execute 方法主要由一個 switch 陳述句組成,用于根據 SQL 型別執行相應的資料庫
操作,該方法的邏輯清晰,不需 要太多的分析,不過在上面 代 碼 中convertArgsToSqlCommandParam 方法出現次數比較頻繁,這里分析一下:
// -☆- MapperMethod
public Object convertArgsToSqlCommandParam(Object[] args) {
return paramNameResolver.getNamedParams(args);
}
public Object getNamedParams(Object[] args) {
final int paramCount = names.size();
if (args == null || paramCount == 0) {
return null;
} else if (!hasParamAnnotation && paramCount == 1) {
/*
* 如果方法引數串列無 @Param 注解,且僅有一個非特別引數,則回傳該
* 引數的值,比如如下方法:
* List findList(RowBounds rb, String name)
* names 如下:
* names = {1 : "0"}
* 此種情況下,回傳 args[names.firstKey()],即 args[1] -> name
*/
return args[names.firstKey()];
} else {
final Map<String, Object> param = new ParamMap<Object>();
int i = 0;
for (Map.Entry<Integer, String> entry : names.entrySet()) {
// 添加 <引數名, 引數值> 鍵值對到 param 中
param.put(entry.getValue(), args[entry.getKey()]);
// genericParamName = param + index,比如 param1, param2,... paramN
final String genericParamName =
GENERIC_NAME_PREFIX + String.valueOf(i + 1);
// 檢測 names 中是否包含 genericParamName,什么情況下會包含?
// 答案如下:
// 使用者顯式將引數名稱配置為 param1,即 @Param("param1")
if (!names.containsValue(genericParamName)) {
// 添加 <param*, value> 到 param 中
param.put(genericParamName, args[entry.getKey()]);
}i++;
}
return param;
} }
convertArgsToSqlCommandParam 是一個空殼方法,該方法最終呼叫了
ParamNameResolver 的 getNamedParams 方法,getNamedParams 方法的主要邏輯是根據條件回傳不同的結果,該方法的代碼不是很難理解,我也進行了比較詳細的注釋,就不多說了,
分析完 convertArgsToSqlCommandParam 的邏輯,接下來說說 MyBatis 對哪些 SQL 指令提供了支持,如下:
- 查詢陳述句:SELECT
- 更新陳述句:INSERT/UPDATE/DELETE
- 存盤程序:CALL
在上面的串列中,我刻意對 SELECT/INSERT/UPDATE/DELETE 等指令進行了分類,分
類依據指令的功能以及 MyBatis 執行這些指令的程序,這里把 SELECT 稱為查詢陳述句,
INSERT/UPDATE/DELETE 等稱為更新陳述句,下來按照順序對著兩種陳述句執行程序進行分析,
先來分析查詢陳述句的執行程序,
二、 查詢陳述句的執?程序
查詢陳述句對應的方法比較多,有如下幾種:
- executeWithResultHandler
- executeForMany
- executeForMap
- executeForCursor
這些方法在內部呼叫了 SqlSession 中的一些 select方法,比如 selectList、selectMap、
selectCursor 等,這些方法的回傳值型別是不同的,因此對于每種回傳型別,需要有專門的處理方法,以 selectList 方法為例,該方法的回傳值型別為 List,但如果我們的 Mapper 或 Dao的介面方法回傳值型別為陣列,或者 Set,直接將 List 型別的結果回傳給 Mapper/Dao 就不合適了,execute等方法只是對 select等方法做了一層簡單的封裝,因此接下來我們應們應該把目光放在這些 select方法上,
2.1 selectOne ?法分析
本節選擇分析 selectOne 方法,而不是其他的方法,大家或許會覺得奇怪,前面提及了
selectList、selectMap、selectCursor 等方法,這里卻分析一個未提及的方法,這樣做并沒什么
特別之處,主要原因是 selectOne 在內部會呼叫 selectList 方法,這里分析 selectOne 方法是
為了告知大家,selectOne 和 selectList 方法是有聯系的,同時分析 selectOne 方法等同于分析
selectList 方法,如果你不信的話,那我們看原始碼吧,原始碼面前了無秘密,
// -☆- DefaultSqlSession
public <T> T selectOne(String statement, Object parameter) {
// 呼叫 selectList 獲取結果
List<T> list = this.<T>selectList(statement, parameter);
if (list.size() == 1) {
// 回傳結果
return list.get(0);
} else if (list.size() > 1) {
// 如果查詢結果大于 1 則拋出例外,這個例外也是很常見的
throw new TooManyResultsException("……");
} else {
return null;
} }
如上,selectOne 方法在內部呼叫 selectList 了方法,并取 selectList 回傳值的第 1 個元素
作為自己的回傳值,如果 selectList 回傳的串列元素大于 1,則拋出例外,上面代碼比較易懂,就不多說了,下面我們來看看 selectList 方法的實作,
// -☆- DefaultSqlSession
public <E> List<E> selectList(String statement, Object parameter) {
// 呼叫多載方法
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
private final Executor executor;
public <E> List<E> selectList(String statement, Object parameter, RowBounds
rowBounds) {
try {
// 獲取 MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
// 呼叫 Executor 實作類中的 query 方法
return executor.query(ms, wrapCollection(parameter),
rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("……");
} finally {
ErrorContext.instance().reset();
} }
如上,這里要來說說 executor 變數,該變數型別為 Executor,Executor 是一個介面,它
的實作類如下:
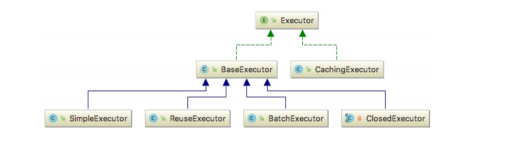
Executor 有這么多的實作類,大家猜一下 executor 變數對應哪個實作類,要弄清楚這個
問題,需要大家到源頭去查證,這里提示一下,大家可以跟蹤一下 DefaultSqlSessionFactory的openSession 方法,很快就能發現 executor 變數創建的蹤跡,限于篇幅原因,本文就不分析 openSession 方法的原始碼了,默認情況下,executor 的型別為 CachingExecutor,該類是一個裝飾器類,用于給目標 Executor 增加二級快取功能,那目標 Executor 是誰呢?默認情況下是 SimpleExecutor,
現在大家搞清楚 executor 變數的身份了,接下來繼續分析 selectOne 方法的呼叫堆疊,先
來看看 CachingExecutor 的 query 方法是怎樣實作的,如下:
// -☆- CachingExecutor
public <E> List<E> query(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 獲取 BoundSql
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 創建 CacheKey
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
// 呼叫多載方法
return query(ms, parameterObject,
rowBounds, resultHandler, key, boundSql);
}
上面的代碼用于獲取 BoundSql 物件,創建 CacheKey 物件,然后再將這兩個物件傳給重
載方法,BoundSql 的獲取程序較為復雜,我將在下一節進行分析,CacheKey 以及接下來即
將出現的一二級快取將會獨立成章分析,上面的方法等代碼和 SimpleExecutor 父類 BaseExecutor 中的實作沒什么區別,有區別的地方在于這個方法所呼叫的多載方法,繼續往下看,
// -☆- CachingExecutor
public <E> List<E> query(MappedStatement ms, Object parameterObject,
RowBounds rowBounds, ResultHandler resultHandler, CacheKey key,
BoundSql boundSql) throws SQLException {
// 從 MappedStatement 中獲取快取
Cache cache = ms.getCache();
// 若映射檔案中未配置快取或參照快取,此時 cache = null
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 若快取未命中,則呼叫被裝飾類的 query 方法
list = delegate.<E>query(ms, parameterObject,
rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
} }
// 呼叫被裝飾類的 query 方法
return delegate.<E>query(
ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
以上代碼涉及到了二級快取,若二級快取為空,或未命中,則呼叫被裝飾類的 query 方
法,下面來看一下 BaseExecutor 的中簽名相同的 query 方法是如何實作的,
// -☆- BaseExecutor
public <E> List<E> query(MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler, CacheKey key,
BoundSql boundSql) throws SQLException {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 從一級快取中獲取快取項
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 存盤程序相關處理邏輯,本文不分析存盤程序,故該方法不分析了
handleLocallyCachedOutputParameters(ms,key,parameter,boundSql);
} else {
// 一級快取未命中,則從資料庫中查詢
list = queryFromDatabase(ms, parameter,
rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--; }
if (queryStack == 0) {
// 從一級快取中延遲加載嵌套查詢結果
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear();
if (configuration.getLocalCacheScope()==LocalCacheScope.STATEMENT) {
clearLocalCache();
}
}
return list; }
上面的方法主要用于從一級快取中查找查詢結果,若快取未命中,再向資料庫進行查詢,
在上面的代碼中,出現了一個新的類 DeferredLoad,這個類用于延遲加載,該類的實作并不
復雜,但是具體用途讓我有點疑惑,這個我目前也未完全搞清楚,就不分析了,接下來,我
們來看一下 queryFromDatabase 方法的實作,
// -☆- BaseExecutor
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler, CacheKey key,
BoundSql boundSql) throws SQLException {
List<E> list;
// 向快取中存盤一個占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// 呼叫 doQuery 進行查詢
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 移除占位符
localCache.removeObject(key);
}
// 快取查詢結果
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list; }
上面的代碼仍然不是 selectOne 方法呼叫堆疊的終點,拋開快取操作,queryFromDatabase
最侄訓會呼叫 doQuery 進行查詢,所以下面我們繼續進行跟蹤,
// -☆- SimpleExecutor
public <E> List<E> doQuery(MappedStatement ms, Object parameter,
RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
// 創建 StatementHandler
StatementHandler handler = configuration.newStatementHandler(
wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 創建 Statement
stmt = prepareStatement(handler, ms.getStatementLog());
// 執行查詢操作
return handler.<E>query(stmt, resultHandler);
} finally {
// 關閉 Statement
closeStatement(stmt);
} }
doQuery 方法中仍然有不少的邏輯,完全看不到即將要到達終點的趨勢,不過這離終點
又近了一步,接下來,我們先跳過 StatementHandler 和 Statement 創建程序,這兩個物件的創建程序會在后面進行說明,這里,我們以 PreparedStatementHandler 為例,看看它的 query 方法是怎樣實作的,如下:
// -☆- PreparedStatementHandler
public <E> List<E> query(Statement statement, ResultHandler resultHandler)
throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
// 執行 SQL
ps.execute();
// 處理執行結果
return resultSetHandler.<E>handleResultSets(ps);
}
到這里似乎看到了希望,整個呼叫程序總算要結束了,不過先別高興的太早,SQL 執行
結果的處理程序也很復雜,稍后將會專門拿出一節內容進行分析,
以上就是 selectOne 方法的執行程序,盡管我已經簡化了代碼分析,但是整個程序看起來還是很復雜的,查詢程序涉及到了很多方法呼叫,不把這些呼叫方法搞清楚,很難對
MyBatis 的查詢程序有深入的理解,所以在接下來的章節中,我將會對一些重要的呼叫進行
分析,如果大家不滿足于泛泛而談,那么接下來咱們一起進行更深入的探索吧,
2.2 獲取 BoundSql
在執行 SQL 之前,需要將 SQL 陳述句完整的決議出來,我們都知道 SQL 是配置在映射文
件中的,但由于映射檔案中的 SQL 可能會包含占位符#{},以及動態 SQL 標簽,比如、
等,因此,我們并不能直接使用映射檔案中配置的 SQL,MyBatis 會將映射檔案中
的 SQL 決議成一組 SQL 片段,如果某個片段中也包含動態 SQL 相關的標簽,那么,MyBatis會對該片段再次進行分片,最終,一個 SQL 配置將會被決議成一個 SQL 片段樹,形如下面的圖片:
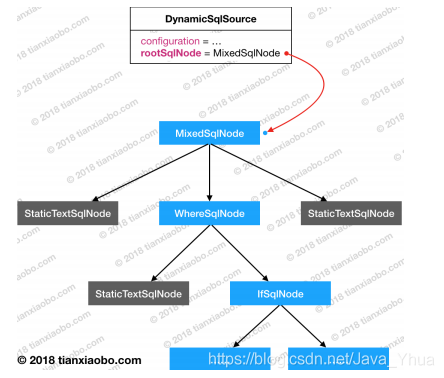
我們需要對片段樹進行決議,以便從每個片段物件中獲取相應的內容,然后將這些內容
組合起來即可得到一個完成的 SQL 陳述句,這個完整的 SQL 以及其他的一些資訊最侄訓存盤
在 BoundSql 物件中,下面我們來看一下 BoundSql 類的成員變數資訊,如下:
private final String sql;
private final List<ParameterMapping> parameterMappings;
private final Object parameterObject;
private final Map<String, Object> additionalParameters;
private final MetaObject metaParameters;
下面用一個表格列舉各個成員變數的含義
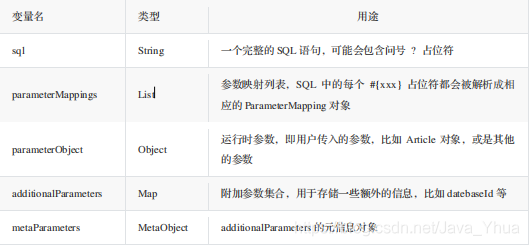
以上對 BoundSql 的成員變數做了簡要的說明,部分引數的用途大家現在可能不是很明
白,不過不用著急,這些變數在接下來的原始碼分析程序中會陸續的出現,到時候對著原始碼多
思考,或是寫點測驗代碼除錯一下,即可弄懂,
好了,現在準備作業已經做好,接下來,開始分析 BoundSql 的構建程序,我們原始碼之
旅的第一站是 MappedStatement 的 getBoundSql 方法,代碼如下:
// -☆- MappedStatement
public BoundSql getBoundSql(Object parameterObject) {
// 呼叫 sqlSource 的 getBoundSql 獲取 BoundSql
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
List<ParameterMapping> parameterMappings =
boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.isEmpty()) {
// 創建新的 BoundSql,這里的 parameterMap 是 ParameterMap 型別,
// 由<ParameterMap> 節點進行配置,該節點已經廢棄,不推薦使用,
// 默認情況下,parameterMap.getParameterMappings() 回傳空集合
boundSql = new BoundSql(configuration, boundSql.getSql(),
parameterMap.getParameterMappings(), parameterObject);
}
// 省略不重要的邏輯
return boundSql; }
如上,MappedStatement 的 getBoundSql 在內部呼叫了 SqlSource 實作類的 getBoundSql
方法,處理此處的呼叫,余下的邏輯都不是重要邏輯,就不啰嗦了,接下來,我們把目光轉
移到 SqlSource 實作類的 getBoundSql 方法上,SqlSource 是一個介面,它有如下幾個實作類:
- DynamicSqlSource
- RawSqlSource
- StaticSqlSource
- ProviderSqlSource
- VelocitySqlSource
在如上幾個實作類中,我們應該選擇分析哪個實作類的邏輯呢?首先我們把最后兩個排
除掉,不常用,剩下的三個實作類中,僅前兩個實作類會在映射檔案決議的程序中被使用,
當 SQL 配置中包含${}(不是#{})占位符,或者包含、等標簽時,會被認為是
動態 SQL,此時使用 DynamicSqlSource 存盤 SQL 片段,否則,使用 RawSqlSource 存盤 SQL配置資訊,相比之下 DynamicSqlSource 存盤的 SQL 片段型別較多,決議起來也更為復雜一些,因此下面我將分析 DynamicSqlSource 的 getBoundSql 方法,弄懂這個,RawSqlSource 也不在話下,
// -☆- DynamicSqlSource
public BoundSql getBoundSql(Object parameterObject) {
// 創建 DynamicContext
DynamicContext context =
new DynamicContext(configuration, parameterObject);
// 決議 SQL 片段,并將決議結果存盤到 DynamicContext 中
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ?
Object.class : parameterObject.getClass();
// 構建 StaticSqlSource,在此程序中將 sql 陳述句中的占位符 #{} 替換為問號 ?,
// 并為每個占位符構建相應的 ParameterMapping
SqlSource sqlSource = sqlSourceParser.parse(
context.getSql(), parameterType, context.getBindings());
// 呼叫 StaticSqlSource 的 getBoundSql 獲取 BoundSql
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
// 將 DynamicContext 的 ContextMap 中的內容拷貝到 BoundSql 中
for(Map.Entry<String, Object> entry : context.getBindings().entrySet()){
boundSql.setAdditionalParameter(entry.getKey(), entry.getValue());
}
return boundSql; }
如上,DynamicSqlSource 的 getBoundSql 方法的代碼看起來不多,但是邏輯卻并不簡單,
該方法由數個步驟組成,這里總結一下:
- 創建 DynamicContext
- 決議 SQL 片段,并將決議結果存盤到 DynamicContext 中
- 決議 SQL 陳述句,并構建 StaticSqlSource
- 呼叫 StaticSqlSource 的 getBoundSql 獲取 BoundSql
- 將 DynamicContext 的 ContextMap 中的內容拷貝到 BoundSql 中
如上 5 個步驟中,第 5 步為常規操作,就不多說了,其他步驟將會在接下來章節中一一
進行分析,按照順序,我們先來分析 DynamicContext 的實作,
1.DynamicContext
DynamicContext 是 SQL 陳述句構建的背景關系,每個 SQL 片段決議完成后,都會將決議結
果存入 DynamicContext 中,待所有的 SQL 片段決議完畢后,一條完整的 SQL 陳述句就會出現在 DynamicContext 物件中,下面我們來看一下 DynamicContext 類的定義,
public class DynamicContext {
public static final String PARAMETER_OBJECT_KEY = "_parameter";
public static final String DATABASE_ID_KEY = "_databaseId";
private final ContextMap bindings;
private final StringBuilder sqlBuilder = new StringBuilder();
public DynamicContext(
Configuration configuration, Object parameterObject) {
// 創建 ContextMap
if (parameterObject != null && !(parameterObject instanceof Map)) {
MetaObject metaObject =
configuration.newMetaObject(parameterObject);
bindings = new ContextMap(metaObject);
} else {
bindings = new ContextMap(null);
}
// 存放運行時引數 parameterObject 以及 databaseId
bindings.put(PARAMETER_OBJECT_KEY, parameterObject);
bindings.put(DATABASE_ID_KEY, configuration.getDatabaseId());
} }
上面只貼了 DynamicContext 類的部分代碼,其中 sqlBuilder 變數用于存放 SQL 片段的
決議結果,bindings 則用于存盤一些額外的資訊,比如運行時引數和 databaseId 等,bindings型別為 ContextMap,ContextMap 定義在 DynamicContext 中,是一個靜態內部類,該類繼承自 HashMap,并覆寫了 get 方法,它的代碼如下:
static class ContextMap extends HashMap<String, Object> {
private MetaObject parameterMetaObject;
public ContextMap(MetaObject parameterMetaObject) {
this.parameterMetaObject = parameterMetaObject;
}
@Override
public Object get(Object key) {
String strKey = (String) key;
// 檢查是否包含 strKey,若包含則直接回傳
if (super.containsKey(strKey)) {
return super.get(strKey);
}
if (parameterMetaObject != null) {
// 從運行時引數中查找結果
return parameterMetaObject.getValue(strKey);
}
return null;
} }
DynamicContext 對外提供了兩個介面,用于操作 sqlBuilder,分別如下:
public void appendSql(String sql) {
sqlBuilder.append(sql);
sqlBuilder.append(" ");
}
public String getSql() {
return sqlBuilder.toString().trim();
}
以上就是對 DynamicContext 的簡單介紹,DynamicContext 的原始碼不難理解,這里就不
多說了,繼續往下分析,
2. 決議 SQL ?段
對于一個包含了${}占位符,或<if>、<where>等標簽的 SQL,在決議的程序中,會被分解
成多個片段,每個片段都有對應的型別,每種型別的片段都有不同的決議邏輯,在原始碼中,
片段這個概念等價于 sql 節點,即 SqlNode,SqlNode 是一個介面,它有眾多的實作類,其繼
承體系如下:
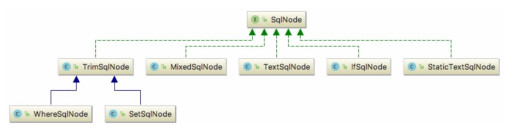
上圖只畫出了部分的實作類,還有一小部分沒畫出來,不過這并不影響接下來的分析,
在眾多實作類中,StaticTextSqlNode 用于存盤靜態文本,TextSqlNode 用于存盤帶有${}占位符的文本,IfSqlNode 則用于存盤節點的內容,MixedSqlNode 內部維護了一個 SqlNode
集合,用于存盤各種各樣的 SqlNode,接下來,我將會對 MixedSqlNode、StaticTextSqlNode、TextSqlNode、IfSqlNode、WhereSqlNode 以及 TrimSqlNode 等進行分析,其他的實作類請大家自行分析,
public class MixedSqlNode implements SqlNode {
private final List<SqlNode> contents;
public MixedSqlNode(List<SqlNode> contents) {
this.contents = contents;
}
@Override
public boolean apply(DynamicContext context) {
// 遍歷 SqlNode 集合
for (SqlNode sqlNode : contents) {
// 呼叫 salNode 物件本身的 apply 方法決議 sql
sqlNode.apply(context);
}
return true;
} }
MixedSqlNode 可以看做是 SqlNode 實作類物件的容器,凡是實作了 SqlNode 介面的類
都可以存盤到 MixedSqlNode 中,包括它自己,MixedSqlNode 決議方法 apply 邏輯比較簡單,即遍歷 SqlNode 集合,并呼叫其他 SalNode 實作類物件的 apply 方法決議 sql,那下面我們來看看其他 SalNode 實作類的 apply 方法是怎樣實作的,
public class StaticTextSqlNode implements SqlNode {
private final String text;
public StaticTextSqlNode(String text) {
this.text = text;
}
@Override
public boolean apply(DynamicContext context) {
context.appendSql(text);
return true;
} }
StaticTextSqlNode 用于存盤靜態文本,所以它不需要什么決議邏輯,直接將其存盤的
SQL 片段添加到 DynamicContext 中即可,StaticTextSqlNode 的實作比較簡單,看起來很輕
松,下面分析一下 TextSqlNode,
public class TextSqlNode implements SqlNode {
private final String text;
private final Pattern injectionFilter;
@Override
public boolean apply(DynamicContext context) {
// 創建 ${} 占位符決議器
GenericTokenParser parser = createParser(
new BindingTokenParser(context, injectionFilter));
// 決議 ${} 占位符,并將決議結果添加到 DynamicContext 中
context.appendSql(parser.parse(text));
return true;
}
private GenericTokenParser createParser(TokenHandler handler) {
// 創建占位符決議器,GenericTokenParser 是一個通用決議器,
// 并非只能決議 ${} 占位符
return new GenericTokenParser("${", "}", handler);
}
private static class BindingTokenParser implements TokenHandler {
private DynamicContext context;
private Pattern injectionFilter;
public BindingTokenParser(
DynamicContext context, Pattern injectionFilter) {
this.context = context;
this.injectionFilter = injectionFilter;
}
@Override
public String handleToken(String content) {
Object parameter = context.getBindings().get("_parameter");
if (parameter == null) {
context.getBindings().put("value", null);
}else if(SimpleTypeRegistry.isSimpleType(parameter.getClass())){
context.getBindings().put("value", parameter);
}
// 通過 ONGL 從用戶傳入的引數中獲取結果
Object value = OgnlCache
.getValue(content, context.getBindings());
String srtValue = (value == null ? "" : String.valueOf(value));
// 通過正則運算式檢測 srtValue 有效性
checkInjection(srtValue);
return srtValue;
}
} }
如上,GenericTokenParser 是一個通用的標記決議器,用于決議形如KaTeX parse error: Expected 'EOF', got '#' at position 7: {xxx},#?{xxx}等標 記 ,Gene…{xxx}標記,舉個例子說明一下吧,如下,我們有這樣一個 SQL 陳述句,用于從 article 表中查詢某個作者所寫的文章,如下:
SELECT * FROM article WHERE author = '${author}'
假設我們我們傳入的 author 值為 tianxiaobo,那么該 SQL 最侄訓被決議成如下的結果:
SELECT * FROM article WHERE author = 'tianxiaobo'
一般情況下,使用${author}接受引數都沒什么問題,但是怕就怕在有人不懷好意,構建
了一些惡意的引數,當用這些惡意的引數替換${author}時就會出現災難性問題——SQL 注
入,比如我們構建這樣一個引數 author=tianxiaobo’;DELETE FROM article;#,然后我們把這個引數傳給 TextSqlNode 進行決議,得到的結果如下
SELECT * FROM article WHERE author = 'tianxiaobo'; DELETE FROM article;#'
看到沒,由于傳入的引數沒有經過轉義,最終導致了一條 SQL 被惡意引數拼接成了兩
條 SQL,更要命的是,第二天 SQL 會把 article 表的資料清空,這個后果就很嚴重了(從刪
庫到跑路),這就是為什么我們不應該在 SQL 陳述句中是用${}占位符,風險太大,
分析完 TextSqlNode 的邏輯,接下來,分析 IfSqlNode 的實作,
public class IfSqlNode implements SqlNode {
private final ExpressionEvaluator evaluator;
private final String test;
private final SqlNode contents;
public IfSqlNode(SqlNode contents, String test) {
this.test = test;
this.contents = contents;
this.evaluator = new ExpressionEvaluator();
}
@Override
public boolean apply(DynamicContext context) {
// 通過 ONGL 評估 test 運算式的結果
if (evaluator.evaluateBoolean(test, context.getBindings())) {
// 若 test 運算式中的條件成立,則呼叫其他節點的 apply 方法進行決議
contents.apply(context);
return true;
}
return false;
} }
IfSqlNode 對應的是<iftest=‘xxx’>節點,節點是日常開發中使用頻次比較高的一個節
點,它的具體用法我想大家都很熟悉了,這里就不多啰嗦,IfSqlNode 的 apply 方法邏輯并不復雜,首先是通過 ONGL 檢測 test 運算式是否為 true,如果為 true,則呼叫其他節點的 apply方法繼續進行決議,需要注意的是節點中也可嵌套其他的動態節點,并非只有純文本,
因此 contents 變數遍歷指向的是 MixedSqlNode,而非 StaticTextSqlNode,
關于 IfSqlNode 就說到這,接下來分析 WhereSqlNode 的實作,
public class WhereSqlNode extends TrimSqlNode {
/** 前綴串列 */
private static List<String> prefixList = Arrays.asList(
"AND ", "OR ", "AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t");
public WhereSqlNode(Configuration configuration, SqlNode contents) {
// 呼叫父類的構造方法
super(configuration, contents, "WHERE", prefixList, null, null);
} }
在 MyBatis 中,WhereSqlNode 和 SetSqlNode 都是基于 TrimSqlNode 實作的,所以上面
的代碼看起來很簡單,WhereSqlNode 對應于節點,關于該節點的用法以及它的應用
場景,大家請自行查閱資料,我在分析原始碼的程序中,默認大家已經知道了該節點的用途和
應用場景,
接下來,我們把目光聚焦在 TrimSqlNode 的實作上,
public class TrimSqlNode implements SqlNode {
private final SqlNode contents;
private final String prefix;
private final String suffix;
private final List<String> prefixesToOverride;
private final List<String> suffixesToOverride;
private final Configuration configuration;
@Override
public boolean apply(DynamicContext context) {
// 創建具有過濾功能的 DynamicContext
FilteredDynamicContext filteredDynamicContext =
new FilteredDynamicContext(context);
// 決議節點內容
boolean result = contents.apply(filteredDynamicContext);
// 過濾掉前綴和后綴
filteredDynamicContext.applyAll();
return result;
} }
如上,apply 方法首選呼叫了其他 SqlNode 的 apply 方法決議節點內容,這步操作完成
后,FilteredDynamicContext 中會得到一條 SQL 片段字串,接下里需要做的事情是過濾字
符串前綴后和后綴,并添加相應的前綴和后綴,這個事情由 FilteredDynamicContext 負責,
FilteredDynamicContext 是 TrimSqlNode 的私有內部類,我們去看一下它的代碼,
private class FilteredDynamicContext extends DynamicContext {
private DynamicContext delegate;
/** 構造方法會將下面兩個布林值置為 false */
private boolean prefixApplied;
private boolean suffixApplied;
private StringBuilder sqlBuffer;
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
String trimmedUppercaseSql =
sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
// 參考前綴和后綴,也就是對 sql 進行過濾操作,移除掉前綴或后綴
applyPrefix(sqlBuffer, trimmedUppercaseSql);
applySuffix(sqlBuffer, trimmedUppercaseSql);
}
// 將當前物件的 sqlBuffer 內容添加到代理類中
delegate.appendSql(sqlBuffer.toString());
}
private void applyPrefix(StringBuilder sql, String trimmedUppercaseSql){
if (!prefixApplied) {
// 設定 prefixApplied 為 true,以下邏輯僅會被執行一次
prefixApplied = true;
if (prefixesToOverride != null) {
for (String toRemove : prefixesToOverride) {
// 檢測當前 sql 字串是否包含前綴,比如 'AND ', 'AND\t'等
if (trimmedUppercaseSql.startsWith(toRemove)) {
// 移除前綴
sql.delete(0, toRemove.trim().length());
break;
}
}
}
// 插入前綴,比如 WHERE
if (prefix != null) {
sql.insert(0, " ");
sql.insert(0, prefix);
}
}
}
// 該方法邏輯與 applyPrefix 大同小異,大家自行分析
private void applySuffix(
StringBuilder sql, String trimmedUppercaseSql){
} }
在上面的代碼中,我們重點關注 applyAll 和 applyPrefix 方法,其他的方法大家自行分
析,applyAll 方法的邏輯比較簡單,首先從 sqlBuffer 中獲取 SQL 字串,然后呼叫 applyPrefix和 applySuffix 進行過濾操作,最后將過濾后的 SQL 字串添加到被裝飾的類中,applyPrefix方法會首先檢測 SQL 字串是不是以"AND",“OR”,或"AND\n","OR\n"等前綴開頭,若是則將前綴從 sqlBuffer 中移除,然后將前綴插入到 sqlBuffer 的首部,整個邏輯就結束了,下面寫點代碼簡單驗證一下,如下:
public class SqlNodeTest {
@Test
public void testWhereSqlNode() throws IOException {
String sqlFragment = "AND id = #{id}";
MixedSqlNode msn = new MixedSqlNode(
Arrays.asList(new StaticTextSqlNode(sqlFragment)));
WhereSqlNode wsn = new WhereSqlNode(new Configuration(), msn);
DynamicContext dc = new DynamicContext(
new Configuration(), new ParamMap<>());
wsn.apply(dc);
System.out.println("決議前:" + sqlFragment);
System.out.println("決議后:" + dc.getSql());
} }
測驗結果如下

今天就先更到這,后續會繼續更新!三連支持一下吧!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/246888.html
標籤:其他