論文筆記《Improving Docker Registry Design based on Production Workload Analysis》
會議:File and Storage Technologies(FAST)
時間:2018-12-15
思維導圖
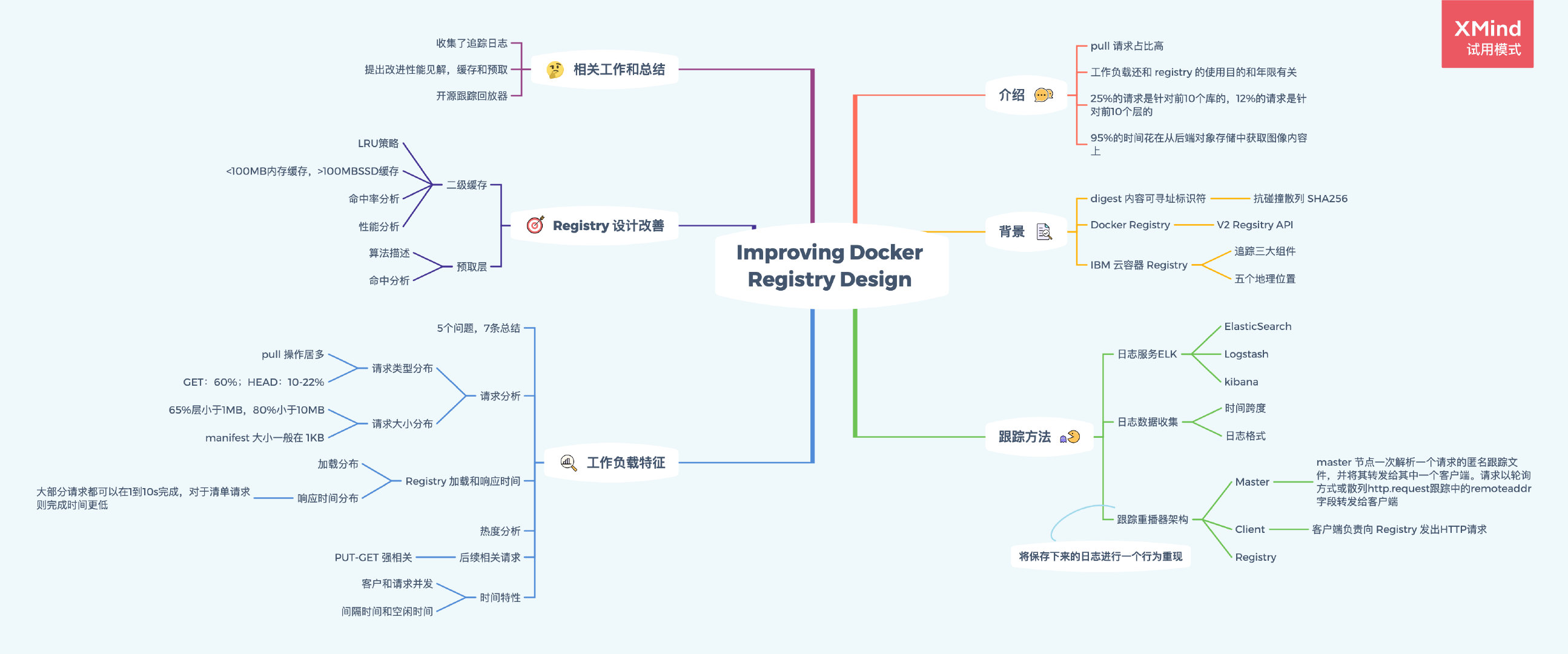
梗概
為了更好地研究 docker 注冊表服務對 docker 的作用,本文基于75天的時間內從五個托管生產級注冊表的IBM資料中心收集的跟蹤資訊,對注冊表作業進行分析,
本文撰寫了一個跟蹤重播器來進行分析,推斷出許多關于容器作業負載的關鍵點,例如請求型別分布,訪問模式和回應時間,基于這些關鍵點,本文得出注冊表的設計優化點,并提高了注冊表的性能,
追蹤器和重播器都是開源的,網址如下:
檔案:https://dssl.cs.vt.edu/drtp/
github:https://github.com/chalianwar/docker-performance
1. 介紹
本文對一個真實的Docker注冊表作業負載進行了大規模和全面的分析,
首先從IBM Cloud container registry service中的五個資料中心收集大跨度的生產級跟蹤,
跟蹤覆寫了注冊中心服務的所有可用區域和許多組件,在75天的時間里,總共有超過3800萬的請求和超過181.3 TB的資料傳輸
通過跟蹤和分析資料,初步發現:
- 與push操作相比,作業負載是高度讀密集型的,包括90- 95%的pull操作
- 不同注冊中心的特征不同,作業負載不僅取決于注冊的目的,還取決于注冊中心服務的年齡;較舊的注冊中心服務在訪問模式和影像流行方面顯示出更可預測的趨勢,
- 觀察到25%的請求是針對前10個庫的,12%的請求是針對前10個層的,此外,注冊中心將95%的時間花在從后端物件存盤中獲取影像內容上,
根據這些發現,提出了幾個容器注冊表服務的設計指示
2. 背景知識
每一層都有一個稱為digest的內容可尋址識別符號,該識別符號通過獲取其資料的抗碰撞散列(默認為SHA256)來唯一地標識一層,這使得Docker能夠有效地檢查兩個層是否相同,并對它們進行重復資料洗掉,以便在不同的影像之間共享,
2.1 Docker Registry
本文使用 Docker Registry V2 的 Rest API 做測驗;分別包括 pull 和 push 操作
push與pull的作業順序相反,在本地創建清單之后,守護行程首先將所有層推入注冊表,然后將manifest推入注冊表,
下表為論文中提及的 Docker Registry Rest API
| http方法 | URL | 作用 |
|---|---|---|
| GET | {name}/manifests/{tag} | 獲取影像清單,其中name定義用戶和存盤庫名稱,而tag定義影像標簽, |
| HEAD | {name}/blobs/{digest} | 檢查注冊表中是否有可用的層 |
| GET | {name}/blobs/{digest} | 拉取壓縮的層tar檔案 |
| HEAD | {name}/blobs/{digest} | 檢查一個層是否已經存在于注冊表中 |
| POST | {name}/blobs/uploads/ | 若層不在,使用此URL進行上傳開始操作,其回傳一個URL包含一個唯一的上傳識別符號(uuid),客戶端可以使用它來傳輸實際的層資料, |
| PUT | {name}/blobs/upload/{uuid} | 使用單片上傳整個層資料 |
| PATCH | {name}/blobs/upload/{uuid} | 使用分塊策略上傳層資料,請求在頭部指定一個位元組范圍以及blob的相應部分 |
| PUT | {name}/manifests/{digest} | 上傳完所有layers后,上傳 manifest 檔案資訊 |
Docker 在上傳層資料時可以選擇使用單片或分塊傳輸上傳層,單片傳輸上載在一個PUT請求中裝載一層的全部資料,為了進行分塊傳輸,Docker使用PATCH <name>/blobs/upload /<uuid>請求在頭部指定一個位元組范圍以及blob的相應部分,
2.2 IBM 云容器 Registry
IBM的租戶眾多,并且其V2版本是基于開源 Docker Registry 搭建的,
其包含超過十八個組件,本文中主要追蹤了三個組件,如下圖所示:
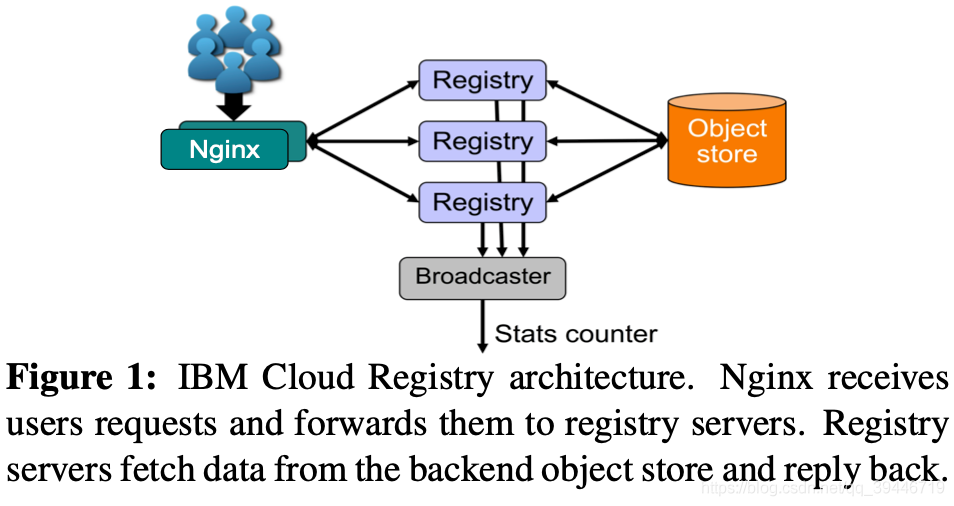
- Nginx:負載均衡器,跟蹤它可以提供回應時間資訊
- Registry:使用OpenStack Swift作為后端物件存盤,跟蹤它可以提供關于請求分布的資訊
- Broadcaster:提供注冊表事件過濾和分發,例如,它會在推送新鏡像時通知其他的漏洞能力顧問組件,跟蹤它可以研究層的大小
盡管Nginx會進行log記錄,但是本文對Registry和Broadcaster也進行了日志收集,
不僅如此,本文還介紹了 IBM 容器倉庫分布于五個地理位置:Dallas (dal), London (lon), Frank- furt (fra), Sydney (syd), 和 Montreal,
每個不同地點的容器倉庫提供不同的功能,如面向客戶的,作為開發和測驗用的,面向內部員工的,等等;并且根據功能的不同,其倉庫規模也不同,不同的容器倉庫其使用年齡也不同
每個可用地區(AZ)都有一個單獨的控制平面和入口路徑,但是后端組件,例如物件存盤,是共享的,這意味著AZ是完全網路隔離的,但是在AZ之間共享映像,
3. 跟蹤方法
本文獲得了 IBM 云倉庫的系統日志服務的訪問權限,除了收集追蹤資訊,本文還開發了追蹤回放器用于評估其他指標
3.1 日志服務
IBM 云容器日志服務是由 ELK 技術堆疊進行管理
- ElasticSearch
- Logstash
- Kibana
每個服務器上的Logstash代理將日志發送到一個集中的日志服務器,在那里它們被索引并添加到ElasticSearch集群中,
每個AZ有自己的ElasticSearch集群,每日日志資料達2TB,這包括系統使用情況、運行狀況資訊、來自不同組件的日志等,收集的資料按時間排序,
3.2 收集資料
通過在ElasticSearch 中對三個組件的日志收集,收集了和鏡像推拉有關的所有請求,從2017-6-20 到 2017-9-2 ,得到了表1 的資料
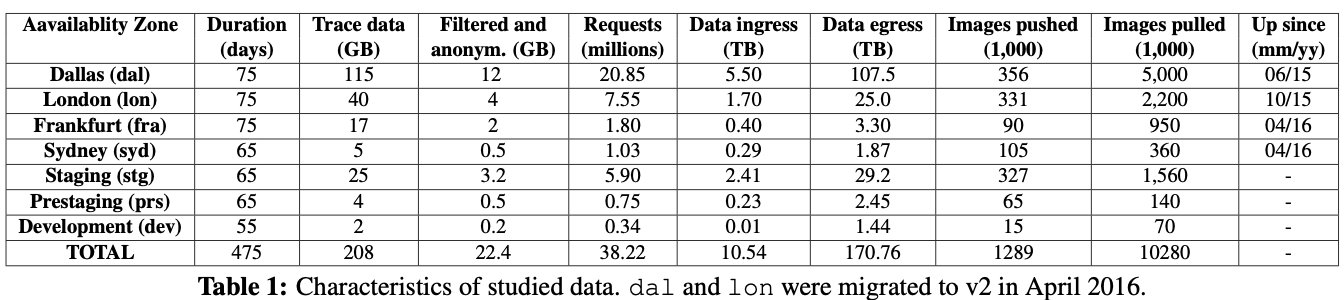
通過移除重復項和過濾資料,剔除掉了22.4G的匿名追蹤資料
下圖就是單次匿名追蹤的記錄格式

3.3 跟蹤重播器
主要介紹了 跟蹤重播器 的架構,用途,行為方式和作用影響
跟蹤重播器架構如下圖所示:
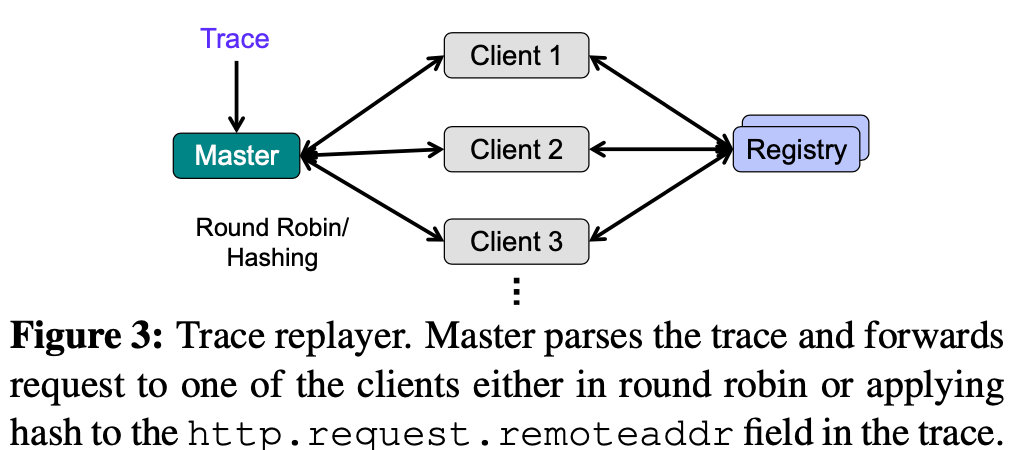
跟蹤重播器作用主要是將收集來的追蹤資訊,通過重播的方式進行再現,各組件的行為如下:
-
Master:master 節點一次決議一個請求的匿名跟蹤檔案,并將其轉發給其中一個客戶端,請求以輪詢方式或散列http.request跟蹤中的remoteaddr欄位轉發給客戶端,
通過使用散列,跟蹤回放器維護請求的位置,以確保與一個鏡像推或拉對應的所有HTTP請求都是由相同的客戶端節點生成的,就像原始注冊中心服務所看到的那樣,
-
Client:客戶端負責向 Registry 發出HTTP請求,
對于所有PUT層請求,客戶端都會生成一個具有相應大小的隨機檔案,并將其傳輸到注冊表, 由于新生成的檔案的內容與在跟蹤中看到的層的內容不同,因此兩者的digest / SHA256將有所不同, 因此,在成功完成請求后,客戶端將以請求延遲以及新生成的檔案的摘要回復主服務器, Master 維護一個跟蹤中的摘要及其對應的新生成的摘要之間的映射, 對于此層將來所有的GET請求,Master 都會發出對新摘要的請求,而不是在原跟蹤中看到的摘要請求, 對于所有GET請求,客戶端僅報告延遲,
跟蹤重播器以兩種模式發出請求:
- 盡可能快
- 保持原樣
跟蹤重播器的主端是多執行緒的,并且在單獨的執行緒中跟蹤每個客戶端的進度, 一旦所有客戶端完成作業,就可以計算總吞吐量和延遲, 每個請求延遲,每個客戶端延遲和吞吐量分別記錄,
跟蹤重播器通過兩種模式可以執行兩種分析
- 大規模注冊表設定的性能分析
- 脫機跟蹤分析:在這種模式下,主服務器不把請求轉發給客戶端,而是把它們交給一個分析插件來處理任何請求的操作,例如,trace播放器可以模擬不同的快取策略,并確定使用不同快取大小的效果,
4. 作業負載特征
本文針對 Registry 優化提出了5個問題:
- 本文的一般作業量是多少?什么是請求型別和大小分布?
- 生產,暫存,預階段和開發部署之間的回應時間是否有所不同?
- Registry 請求是否有空間局限性?
- 后續請求之間存在相關性嗎?可以預測未來的請求嗎?
- 作業負載的時間屬性是什么?是否有突發事件,在時間上有局限性嗎?
4.1 請求分析
根據拿到的請求日志,將其分為請求型別分布和請求大小分布
請求型別分布
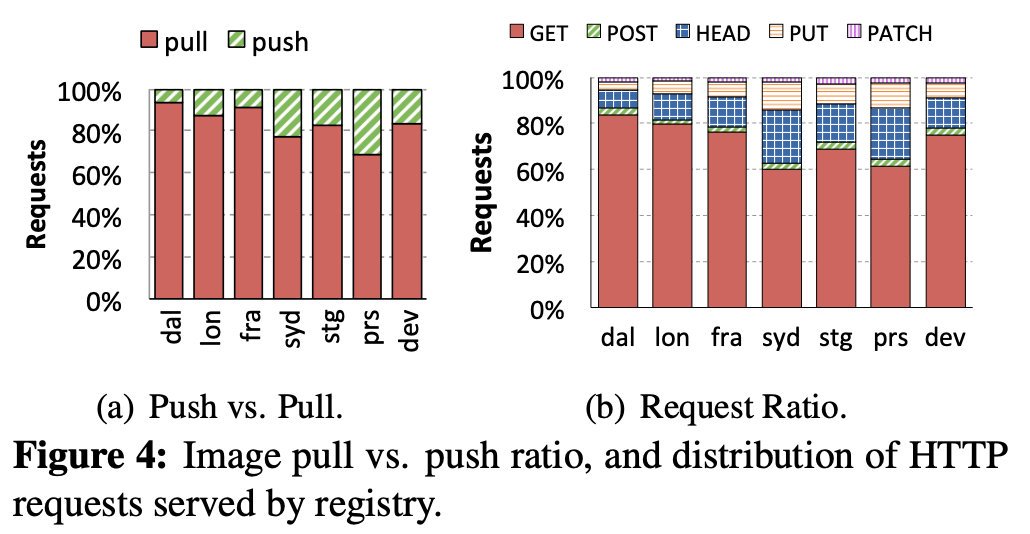
上圖的a顯示了 push 和 pull 在每個 registry 的比例,registry 是讀密集型的
Syd registry 顯示出較低的拉取比例 78%,因為它是一個較新的 registry,因此它比成熟的registry 需要更密集地進行資料填充,
圖b顯示了,所有注冊中心接收60%以上的GET請求和10%-22%的HEAD請求,PUT請求比PATCH請求多了1.9-5.8倍,因為PUT用于上傳清單檔案(除了層之外),而且許多層都足夠小,可以在一個請求中上傳,
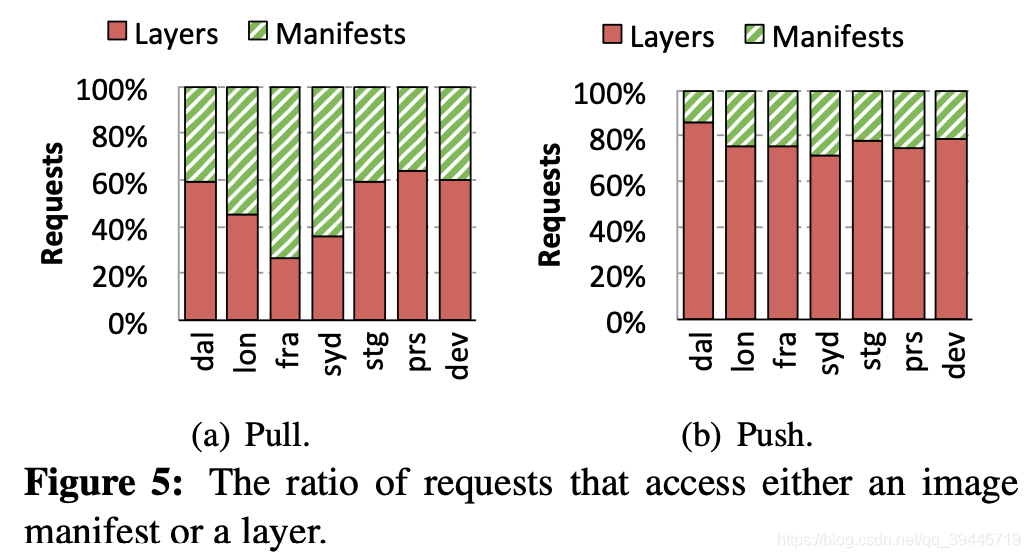
上圖顯示 清單檔案(manifest) 和 層檔案的請求比例,對于 pull 而言,更多的請求是對于層,syd 和 fra registry 的清單請求更多,是因為有很多請求都是拉取過一次再拉取
push 操作里,訪問層比清單比例更大
請求大小分布
圖6顯示的是在 GET 請求中的,清單和層大小的累積分布函式
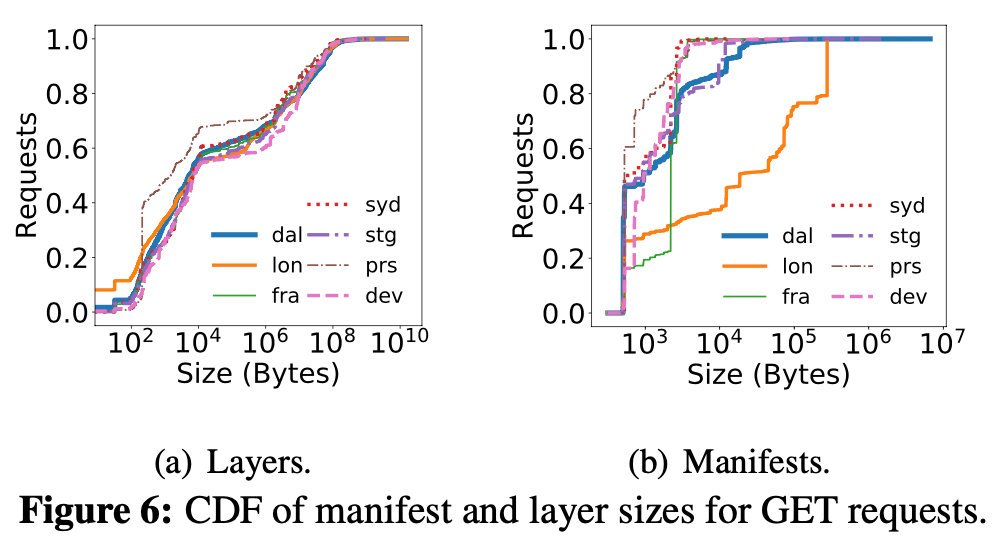
6a可以看到,65%的層小于1MB,80%的小于10MB
6b則顯示了,清單大小一般在1KB左右
對于lon registry 來說,大量的請求都是針對與舊Docker版本兼容的清單,因此增加了它們的大小,
4.2 registry 加載和回應時間
加載分布
通過研究各個 regsitry 的每分鐘被請求數,得到兩個結論
- 首先,開發和預開發注冊中心的利用率很低,
- 其次,注冊表負載隨著年齡的增長而增加,
回應時間分布
對于層請求來說,大部分請求都可以在1到10s完成,對于清單請求則完成時間更低
4.3 熱度分析
本文還對層,清單,庫等熱度進行分析,發現top 1,2 的熱度和命中率很高,之后就呈斷崖式下降
啟發就是,過小的快取不足以有效地快取資料,例如,根據這些結果,我們估計資料集大小的2%的快取大小可以提供40%或更高的命中率,快取對于提高容器注冊中心的性能非常有效,
4.4 請求相關
本文還研究對某個清單的GET請求是否總是會導致相應層的后續GET請求,
本文將一次請求會話的時間閾值定義為1分鐘,然后計算一個會話中跟隨GET manifest請求的所有GET層請求,
在大多數情況下,GET manifest請求之后沒有任何后續請求,原因是,每當客戶端已經獲取一個鏡像,然后提取一個鏡像,只有清單檔案被請求檢查鏡像中是否有任何更改,這表明GET清單和層請求之間沒有很強的相關性,
總的來說,分析表明,如果考慮前面的PUT請求,那么GET清單請求和后續層請求之間存在很強的相關性,
4.5 時間特性
客戶和請求并發性
間隔時間和空閑時間
間隔時間定義為兩個后續請求之間的時間
空閑時間是指沒有活動請求的時間,
分析表明雖然一些可用磁區有大量的空閑期,但它們的持續時間很短,因此很難用傳統的資源供應方法來利用它們
4.6 分析總結*
經過大量的資料和多維度的分析,總結出了7條結論
-
GET請求在所有注冊表中占主導地位,超過一半的請求是針對層的,這為有效的層快取和注冊表預取提供了機會,
-
65%的層小于1mb, 80%的層小于10mb,這使得各個層都適合快取,
-
registry 負載受 registry 預期用例和注冊表年齡的影響,
與長期運行的生產系統相比,年輕的非生產注冊中心的負載更低,
在為AZ提供資源以節省成本和更有效地使用現有資源時,應該考慮到這一點,
-
回應時間與注冊表負載相關,因此也取決于注冊表的使用年限(較年輕的注冊表的負載較少)和用例,
-
對層、清單、庫和用戶的 registry 訪問是嚴重傾斜的,有非常少的熱門的鏡像會被頻繁訪問,但熱度會迅速下降,因此,快取技術是可行的,但應該謹慎選擇快取大小,
-
PUT請求與后續的GET清單和GET層請求之間有很強的相關性,注冊中心可以利用這個模式將層從后端物件存盤區預取到快取中,這大大減少了客戶端的拉取延遲,對于流行鏡像和非流行鏡像都存在這種相關性,
-
盡管周末的請求率下降幅度很小,但我們沒有發現可用于改善資源配置的明顯重復峰值,
5. Registry 設計改善*
通過上述的分析,對 registry 進行兩點改善
- 對熱度層使用一個多層快取
- 一個新推送層的跟蹤器,它支持從后端物件存盤中預取最新的層,
5.1 實作
對于快取和預取,我們實作了兩個單獨的模塊,為了實作記憶體層快取,我們修改了注冊表的Swift存盤驅動程式(修改/添加了大約200 LoC),修改后的驅動程式將小的層存盤在記憶體中,對大的層使用Swift,
5.2 性能分析
本文在一樣的配置環境下比較了四種不同的后端
- 直接用OpenStack Swift
- 快取小于1mb的層,其余層用Swift存盤(記憶體+ Swift)
- 本地檔案系統與SSD(本地FS)
- 重定向,即注冊表通過Swift中的層鏈接進行回復,然后客戶端直接從Swift中獲取層,
結果如下圖所示:
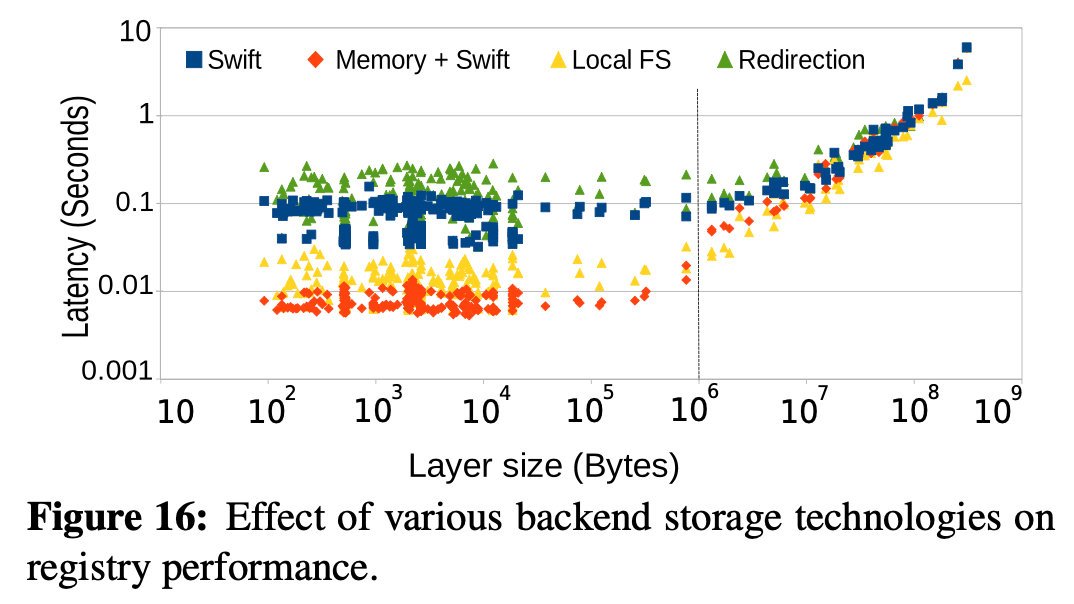
結果突出了注冊表的快速后端存盤系統的優勢,并展示了快取可以顯著提高注冊表性能的機會,
5.3 二級快取**
本文觀察到,一小部分的層太大了,不能證明使用記憶體來快取它們是合理的,
因此,設計了一個由主存(用于較小的層)和ssd(用于較大的層)組成的兩級快取,
命中率分析
快取策略:使用 LRU 快取策略,淘汰時,從記憶體快取中逐出的任何物件在完全逐出之前都會首先進入SSD快取,將小于100 MB的層存盤在記憶體級快取中,而較大的層存盤在SSD級快取中,
為每個AZ選擇資料輸入的2%、4%、6%、8%和10%的快取大小
對于SSD級快取大小,我們選擇記憶體快取大小為10×、15×和20×
下圖為命中率分析圖
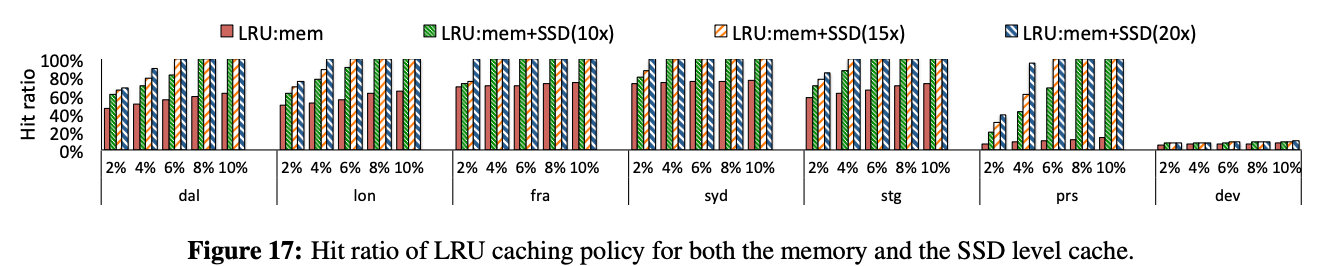
快取對于大部分registry 還是有效的,但是 prs 和 dev 這兩個跟蹤表示注冊表開發團隊的測驗互動,因此在這種情況下,我們看不到使用快取的任何好處,
5.4 預取層**
預取演算法如下圖所示:

演算法描述:
L M t h r e s h LM_{thresh} LMthresh?:PUT層和隨后的GET清單請求之間持續時間的閾值
M L t h r e s h ML_{thresh} MLthresh?:保持預取層的持續時間閾值
上述兩個閾值是配置的
if r=PUT layer then:當接收到PUT時,存盤庫和請求中指定的層將被添加到一個包含請求到達時間和客戶端地址的查找表中,
else if r=GET manifest then:當在某個閾值
L
M
t
h
r
e
s
h
LM_{thresh}
LMthresh?內從客戶端接收到GET清單請求時,主機檢查查找表是否包含請求中指定的存盤庫,如果是命中,并且客戶端的地址不在表中,那么客戶端的地址就添加到表中,并且從后端物件存盤中預取層,
命中分析
下圖為預取技術的命中分析,單條bar 表示 ML 值,而一組條則為 LM 值

提高 M L t h r e s h ML_{thresh} MLthresh?可以顯著提高命中率,但提高 LM 命中率只有略微提高
6. 相關作業
Docker 容器
Docker 倉庫
作業負載分析
快取和預取
7. 總結
本文在75天的時間跨度內跟蹤了在5個不同地理位置的 registry,總共3800萬個請求,最終拿到了181.3 TB的跟蹤日志
本文提供了改進Docker注冊表性能和使用的見解,提出了有效的快取和預取策略,利用特定于注冊表的作業負載特征來顯著提高性能,
最后,開源了跟蹤器,并提供了一個跟蹤回放器,它可以作為容器注冊和基于容器的虛擬化的新研究和研究的堅實基礎,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/247638.html
標籤:其他
上一篇:Redis-String(字串)