上文我們已經學習到查詢SQL陳述句的執行程序中如何獲取 BoundSql!接下來繼續從查詢SQL陳述句的執行程序中如何創建 StatementHandler!喜歡的朋友們可以來個一鍵三連哦~
目錄
- 查詢SQL陳述句的執行程序
- 2.3 創建 StatementHandler
- 2.4 設定運?時引數到 SQL 中
- 2.5 #{}占位符的決議與引數的設定程序梳理
- 2.6 處理查詢結果
- 1.創建物體類物件
- 2.結果集映射
- 3.關聯查詢與延遲加載
- 4.存盤映射結果
查詢SQL陳述句的執行程序
2.3 創建 StatementHandler
在 MyBatis 的原始碼中,StatementHandler 是一個非常核心介面,之所以說它核心,是因
為從代碼分層的角度來說,StatementHandler 是 MyBatis 原始碼的邊界,再往下層就是 JDBC 層面的介面了,StatementHandler 需要和 JDBC 層面的介面打交道,它要做的事情有很多,在執行 SQL 之前,StatementHandler 需要創建合適的 Statement 物件,然后填充引數值到
Statement 物件中,最后通過 Statement 物件執行 SQL,這還不算完,待 SQL 執行完畢,還要去處理查詢結果等,這些程序看似簡單,但實作起來卻很復雜,好在,這些程序對應的邏輯并不需要我們親自實作,好了,其他的就不多說了,下面我們來看一下 StatementHandler 的繼承體系,
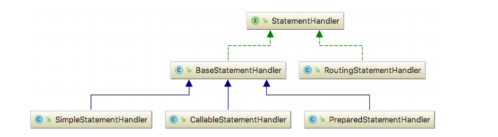
上圖中,最下層的三種 StatementHandler 實作類與三種不同的 Statement 進行互動,這
個不難看出來,但 RoutingStatementHandler 則是一個奇怪的存在,因為 JDBC 中并不存在
RoutingStatement,那它有什么用呢?接下來,我們到代碼中尋找答案,
// -☆- Configuration
public StatementHandler newStatementHandler(Executor executor,
MappedStatement mappedStatement,Object parameterObject,
RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 創建具有路由功能的 StatementHandler
StatementHandler statementHandler = new RoutingStatementHandler(
executor, mappedStatement, parameterObject, rowBounds,
resultHandler, boundSql);
// 應用插件到 StatementHandler 上
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler; }
如上,newStatementHandler 方法在創建 StatementHandler 之后,還會應用插件到
StatementHandler 上,關于 MyBatis 的插件機制,后面獨立成章進行講解,這里就不分析了,下面分析 RoutingStatementHandler 的代碼,
public class RoutingStatementHandler implements StatementHandler {
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms,
Object parameter, RowBounds rowBounds, ResultHandler resultHandler,
BoundSql boundSql) {
// 根據 StatementType 創建不同的 StatementHandler
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms,
parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms,
parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor,
ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("……");
}
}
// 其他方法邏輯均由別的 StatementHandler 代理完成,就不貼代碼了
}
RoutingStatementHandler 的構造方法會根據 MappedStatement 中的 statementType 變數創建不同的 StatementHandler 實作類,默認情況下,statementType 值為 PREPARED,關于StatementHandler 創建的程序就先分析到這,StatementHandler 創建完成了,后續要做到事情是創建 Statement,以及將運行時引數和 Statement 進行系結,
2.4 設定運?時引數到 SQL 中
JDBC 提供了三種 Statement 介面,分別是 Statement 、 PreparedStatement 和
CallableStatement,他們的關系如下:
上面三個介面的層級分明,其中 Statement 介面提供了執行 SQL,獲取執行結果等基本
功能,PreparedStatement 在此基礎上,對 IN 型別的引數提供了支持,使得我們可以使用運
行時引數替換 SQL 中的問號?占位符,而不用手動拼接 SQL,CallableStatement 則是在
PreparedStatement 基礎上,對 OUT 型別的引數提供了支持,該種型別的引數用于保存存盤
程序輸出的結果,本節將分析 PreparedStatement 的創建,以及設定運行時引數到 SQL 中的程序,其他兩種 Statement 的處理程序,大家請自行分析,Statement 的創建入口是在
SimpleExecutor 的 prepareStatement 方法中,下面從這個方法開始進行分析,
// -☆- SimpleExecutor
private Statement prepareStatement(StatementHandler handler, Log
statementLog) throws SQLException {
Statement stmt;
// 獲取資料庫連接
Connection connection = getConnection(statementLog);
// 創建 Statement,
stmt = handler.prepare(connection, transaction.getTimeout());
// 為 Statement 設定 IN 引數
handler.parameterize(stmt);
return stmt; }
上面代碼的邏輯比較簡單,總共包含三個步驟,如下:
- 獲取資料庫連接
- 創建 Statement
- 為 Statement 設定 IN 引數
上面三個步驟看起來并不難實作,實際上如果大家愿意寫的話,也能寫出來,不過
MyBatis 對這三個步驟進行了一些拓展,實作上也相對復雜一些,以獲取資料庫連接為例,
MyBatis 并未沒有在 getConnection 方法中直接呼叫 JDBC DriverManager 的 getConnection 方法獲取獲取連接,而是通過資料源獲取連接,MyBatis 提供了兩種基于 JDBC 介面的資料源,分別為 PooledDataSource 和 UnpooledDataSource,創建或獲取資料庫連接的操作最終是由這兩個資料源執行,本節不會分析以上兩種資料源的原始碼,相關分析會在下一章中展開,
接下來,我將分析 PreparedStatement 的創建,以及 IN 引數設定的程序,按照順序,先
來分析 PreparedStatement 的創建程序,如下:
// -☆- PreparedStatementHandler
public Statement prepare(Connection connection, Integer transactionTimeout)
throws SQLException {
Statement statement = null;
try {
// 創建 Statement
statement = instantiateStatement(connection);
// 設定超時和 FetchSize
setStatementTimeout(statement, transactionTimeout);
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("……");
} }
protected Statement instantiateStatement(Connection connection)
throws SQLException {
String sql = boundSql.getSql();
// 根據條件呼叫不同的 prepareStatement 方法創建 PreparedStatement
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(
sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() != null) {
return connection.prepareStatement(sql,
mappedStatement.getResultSetType().getValue(),
ResultSet.CONCUR_READ_ONLY);
} else {
return connection.prepareStatement(sql);
} }
PreparedStatement 的創建程序沒什么復雜的地方,就不多說了,下面分析運行時引數
是如何被設定到 SQL 中的程序,
// -☆- PreparedStatementHandler
public void parameterize(Statement statement) throws SQLException {
// 通過引數處理器 ParameterHandler 設定運行時引數到 PreparedStatement 中
parameterHandler.setParameters((PreparedStatement) statement);
}
public class DefaultParameterHandler implements ParameterHandler {
private final TypeHandlerRegistry typeHandlerRegistry;
private final MappedStatement mappedStatement;
private final Object parameterObject;
private final BoundSql boundSql;
private final Configuration configuration;
public void setParameters(PreparedStatement ps) {
// 從 BoundSql 中獲取 ParameterMapping 串列,每個 ParameterMapping
// 與原始 SQL 中的 #{xxx} 占位符一一對應
List<ParameterMapping> parameterMappings =
boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping=parameterMappings.get(i);
// 檢測引數型別,排除掉 mode 為 OUT 型別的 parameterMapping
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
// 獲取屬性名
String propertyName = parameterMapping.getProperty();
// 檢測 BoundSql 的 additionalParameters 是否包含 propertyName
if (boundSql.hasAdditionalParameter(propertyName)) {
value=boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
// 檢測運行時引數是否有相應的型別決議器
} else if (typeHandlerRegistry.hasTypeHandler(
parameterObject.getClass())) {
// 若運行時引數的型別有相應的型別處理器 TypeHandler,則將
// parameterObject 設為當前屬性的值,
value = parameterObject;
} else {
// 為用戶傳入的引數 parameterObject 創建元資訊物件
MetaObject metaObject =
configuration.newMetaObject(parameterObject);
// 從用戶傳入的引數中獲取 propertyName 對應的值
value = metaObject.getValue(propertyName);
}
// ---------------------分割線---------------------
TypeHandler typeHandler =
parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) {
// 此處 jdbcType = JdbcType.OTHER
jdbcType = configuration.getJdbcTypeForNull();
}
try {
// 由型別處理器 typeHandler 向 ParameterHandler 設定引數
typeHandler.setParameter(ps, i + 1, value, jdbcType);
} catch (TypeException e) {
throw new TypeException(...);
} catch (SQLException e) {
throw new TypeException(...);
}
}
}
}
} }
如上代碼,分割線以上的大段代碼用于獲取#{xxx}占位符屬性所對應的運行時引數,分
割線以下的代碼則是獲取#{xxx}占位符屬性對應的 TypeHandler,并在最后通過 TypeHandler將運行時引數值設定到 PreparedStatement 中,
2.5 #{}占位符的決議與引數的設定程序梳理
前面兩節的內容比較多,本節將對前兩節的部分內容進行梳理,以便大家能夠更好理解
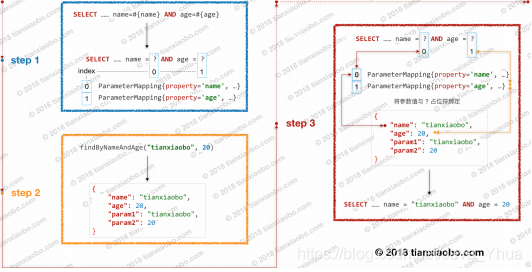
這兩節內容之間的聯系,假設我們有這樣一條 SQL 陳述句:
SELECT * FROM author WHERE name = #{name} AND age = #{age}
這個 SQL 陳述句中包含兩個#{}占位符,在運行時這兩個占位符會被決議成兩個
ParameterMapping 物件,如下:
ParameterMapping{property='name', mode=IN,
javaType=class java.lang.String, jdbcType=null, ...}
和
ParameterMapping{property='age', mode=IN,
javaType=class java.lang.Integer, jdbcType=null, ...}
SELECT * FROM Author WHERE name = ? AND age = ?
這里假設下面這個方法與上面的 SQL 對應:
Author findByNameAndAge(@Param("name")String name, @Param("age")Integer
age)
該方法的引數串列會被 ParamNameResolver 決議成一個 map,如下:
{ 0: "name", 1: "age"
}
假設該方法在運行時有如下的呼叫:
findByNameAndAge("tianxiaobo", 20)
此時,需要再次借助 ParamNameResolver 的力量,這次我們將引數名和運行時的引數
值系結起來,得到如下的映射關系,
{
"name": "tianxiaobo",
"age": 20,
"param1": "tianxiaobo",
"param2": 20
}
下一步,我們要將運行時引數設定到 SQL 中,由于原 SQL 經過決議后,占位符資訊已
經被擦除掉了,我們無法直接將運行時引數 SQL 中,不過好在,這些占位符資訊被記錄在
了 ParameterMapping 中了,MyBatis 會將 ParameterMapping 會按照#{}占位符的決議順序存入到 List 中,這樣我們通過 ParameterMapping 在串列中的位置確定它與 SQL 中的哪一個個?占位符相關聯,同時通過 ParameterMapping 中的 property 欄位,我們可以到“引數名與引數值”映射表中查找具體的引數值,這樣,我們就可以將引數值準確的設定到 SQL 中了,此時SQL 如下:
SELECT * FROM Author WHERE name = "tianxiaobo" AND age = 20
整個流程如下圖所示,
當運行時引數被設定到 SQL 中后,下一步要做的事情是執行 SQL,然后處理 SQL 執行
結果,對于更新操作,資料庫一般回傳一個 int 行數值,表示受影響行數,這個處理起來比
較簡單,但對于查詢操作,回傳的結果型別多變,處理方式也很復雜,接下來,我們就來看
看 MyBatis 是如何處理查詢結果的,
2.6 處理查詢結果
MyBatis 可以將查詢結果,即結果集 ResultSet 自動映射成物體類物件,這樣使用者就無
需再手動操作結果集,并將資料填充到物體類物件中,這可大大降低開發的作業量,提高工
作效率,在 MyBatis 中,結果集的處理作業由結果集處理器 ResultSetHandler 執行,
ResultSetHandler 是一個介面,它只有一個實作類 DefaultResultSetHandler,結果集的處理入口方法是 handleResultSets,下面來看一下該方法的實作,
public List<Object> handleResultSets(Statement stmt) throws SQLException {
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
// 獲取第一個結果集
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
// 處理結果集
handleResultSet(rsw, resultMap, multipleResults, null);
// 獲取下一個結果集
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
// 以下邏輯均與多結果集有關,就不分析了,代碼省略
String[] resultSets = mappedStatement.getResultSets();
if (resultSets != null) {...}
return collapseSingleResultList(multipleResults);
}
private ResultSetWrapper getFirstResultSet(Statement stmt)
throws SQLException {
// 獲取結果集
ResultSet rs = stmt.getResultSet();
while (rs == null) {
/*
* 移動 ResultSet 指標到下一個上,有些資料庫驅動可能需要使用者
* 先呼叫 getMoreResults 方法,然后才能呼叫 getResultSet 方法
* 獲取到第一個 ResultSet
*/
if (stmt.getMoreResults()) {
rs = stmt.getResultSet();
} else {
if (stmt.getUpdateCount() == -1) {
break;
}
}
}
/*
* 這里并不直接回傳 ResultSet,而是將其封裝到 ResultSetWrapper 中,
* ResultSetWrapper 中包含了 ResultSet 一些元資訊,比如列名稱、
* 每列對應的 JdbcType、以及每列對應的 Java 類名(class name,譬如
* java.lang.String)等,
*/
return rs != null ? new ResultSetWrapper(rs, configuration) : null; }
如上,該方法首先從 Statement 中獲取第一個結果集,然后呼叫 handleResultSet 方法對
該結果集進行處理,一般情況下,如果我們不呼叫存盤程序,不會涉及到多結果集的問題,
由于存盤程序并不是很常用,所以關于多結果集的處理邏輯我就不分析了,下面,我們把目
光聚焦在單結果集的處理邏輯上,
private void handleResultSet(ResultSetWrapper rsw, ResultMap resultMap,
List<Object> multipleResults, ResultMapping parentMapping)
throws SQLException {
try {
if (parentMapping != null) {
// 多結果集相關邏輯,不分析了
handleRowValues(rsw, resultMap,
null, RowBounds.DEFAULT, parentMapping);
} else {
/*
* 檢測 resultHandler 是否為空,ResultHandler 是一個介面,使用者可
* 實作該介面,這樣我們可以通過 ResultHandler 自定義接收查詢結果的
* 動作,比如我們可將結果存盤到 List、Map 亦或是 Set,甚至丟棄,
* 這完全取決于大家的實作邏輯,
*/
if (resultHandler == null) {
// 創建默認的結果處理器
DefaultResultHandler defaultResultHandler =
new DefaultResultHandler(objectFactory);
// 處理結果集的行資料
handleRowValues(rsw, resultMap,
defaultResultHandler, rowBounds, null);
multipleResults.add(defaultResultHandler.getResultList());
} else {
// 處理結果集的行資料
handleRowValues(rsw,resultMap,resultHandler,rowBounds,null);
}
}
} finally {
closeResultSet(rsw.getResultSet());
} }
在上面代碼中,出鏡率最高的 handleRowValues 方法,該方法用于處理結果集中的數
據,下面來看一下這個方法的邏輯,
public void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap,
ResultHandler<?> resultHandler,RowBounds rowBounds,
ResultMapping parentMapping) throws SQLException {
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
// 處理嵌套映射,關于嵌套映射本文就不分析了
handleRowValuesForNestedResultMap(rsw,
resultMap, resultHandler, rowBounds, parentMapping);
} else {
// 處理簡單映射
handleRowValuesForSimpleResultMap(rsw,
resultMap, resultHandler, rowBounds, parentMapping);
} }
handleRowValues 方法中針對兩種映射方式進行了處理,一種是嵌套映射,另一種是簡
單映射,本文所說的嵌套查詢是指中嵌套了一個,關于此種映射的
處理方式本節就不進行分析了,下面我將詳細分析簡單映射的處理邏輯,如下:
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw,
ResultMap resultMap, ResultHandler<?> resultHandler,RowBounds rowBounds,
ResultMapping parentMapping) throws SQLException {
DefaultResultContext<Object> resultContext =
new DefaultResultContext<Object>();
// 根據 RowBounds 定位到指定行記錄
skipRows(rsw.getResultSet(), rowBounds);
// 檢測是否還有更多行的資料需要處理
while (shouldProcessMoreRows(resultContext, rowBounds) &&
rsw.getResultSet().next()) {
// 獲取經過鑒別器處理后的 ResultMap
ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(
rsw.getResultSet(), resultMap, null);
// 從 resultSet 中獲取結果
Object rowValue = getRowValue(rsw, discriminatedResultMap);
// 存盤結果
storeObject(resultHandler, resultContext,
rowValue, parentMapping, rsw.getResultSet());
} }
上面方法的邏輯較多,這里簡單總結一下,如下:
- 根據 RowBounds 定位到指定行記錄
- 回圈處理多行資料
- 使用鑒別器處理 ResultMap
- 映射 ResultSet,得到映射結果 rowValue
- 存盤結果
在如上幾個步驟中,鑒別器相關的邏輯就不分析了,不是很常用,第 2 步的檢測邏輯
比較簡單,也忽略了,下面分析第一個步驟對應的代碼邏輯,如下:
private void skipRows(ResultSet rs, RowBounds rowBounds)
throws SQLException {
// 檢測 rs 的型別,不同的型別行資料定位方式是不同的
if (rs.getType() != ResultSet.TYPE_FORWARD_ONLY) {
if (rowBounds.getOffset() != RowBounds.NO_ROW_OFFSET) {
// 直接定位到 rowBounds.getOffset() 位置處
rs.absolute(rowBounds.getOffset());
}
} else {
for (int i = 0; i < rowBounds.getOffset(); i++) {
/*
* 通過多次呼叫 rs.next() 方法實作行資料定位,
* 當 Offset 數值很大時,這種效率很低下
*/
rs.next();
}
} }
MyBatis 默認提供了 RowBounds 用于分頁,從上面的代碼中可以看出,這并非是一個高
效的分頁方式,除了使用 RowBounds,還可以使用一些第三方分頁插件進行分頁,關于第三方的分頁插件,大家請自行查閱資料,這里就不展開說明了,下面分析一下 ResultSet 的映射程序,如下:
private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap)
throws SQLException {
final ResultLoaderMap lazyLoader = new ResultLoaderMap();
// 創建物體類物件,比如 Article 物件
Object rowValue = createResultObject(rsw, resultMap, lazyLoader, null);
if (rowValue != null &&
!hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final MetaObject metaObject = configuration.newMetaObject(rowValue);
boolean foundValues = this.useConstructorMappings;
// 檢測是否應該自動映射結果集
if (shouldApplyAutomaticMappings(resultMap, false)) {
// 進行自動映射
foundValues = applyAutomaticMappings(
rsw, resultMap, metaObject, null) || foundValues;
}
// 根據 <resultMap> 節點中配置的映射關系進行映射
foundValues = applyPropertyMappings(
rsw, resultMap, metaObject, lazyLoader, null) || foundValues;
foundValues = lazyLoader.size() > 0 || foundValues;
rowValue=foundValues || configuration.isReturnInstanceForEmptyRow()
? rowValue : null;
}
return rowValue; }
上面的方法中的重要邏輯已經注釋出來了,這里再簡單總結一下,如下:
- 創建物體類物件
- 檢測結果集是否需要自動映射,若需要則進行自動映射
- 按中配置的映射關系進行映射
這三處代碼的邏輯比較復雜,接下來按順序進行分節說明,首先分析物體類的創建程序,
1.創建物體類物件
在我們的印象里,創建物體類物件是一個很簡單的程序,直接通過 new 關鍵字,或通過
反射即可完成任務,大家可能會想,把這么簡單程序也拿出來說說,怕是有湊字數的嫌疑,
實則不然,MyBatis 的維護者寫了不少邏輯,以保證能成功創建物體類物件,如果實在無法
創建,則拋出例外,下面我們來看一下 MyBatis 創建物體類物件的程序,
// -☆- DefaultResultSetHandler
private Object createResultObject(ResultSetWrapper rsw,
ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix)
throws SQLException {
this.useConstructorMappings = false;
final List<Class<?>> constructorArgTypes = new ArrayList<Class<?>>();
final List<Object> constructorArgs = new ArrayList<Object>();
// 呼叫多載方法創建物體類物件
Object resultObject = createResultObject(rsw,
resultMap, constructorArgTypes, constructorArgs, columnPrefix);
// 檢測物體類是否有相應的型別處理器
if (resultObject != null &&
!hasTypeHandlerForResultObject(rsw, resultMap.getType())) {
final List<ResultMapping> propertyMappings =
resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
// 如果開啟了延遲加載,則為 resultObject 生成代理類
if (propertyMapping.getNestedQueryId() != null &&
propertyMapping.isLazy()) {
// 創建代理類,默認使用 Javassist 框架生成代理類,由于物體類通常
// 不會實作介面,所以不能使用 JDK 動態代理 API 為物體類生成代理,
resultObject = configuration.getProxyFactory()
.createProxy(resultObject, lazyLoader, configuration,
objectFactory,constructorArgTypes, constructorArgs);
break;
}
}
}
this.useConstructorMappings =
resultObject != null && !constructorArgTypes.isEmpty();
return resultObject; }
創建物體類物件的邏輯被封裝在了 createResultObject 的多載方法中,關于該方法,待
會再分析,創建好物體類對后,還需要對中配置的映射資訊進行檢測,若發現
有關聯查詢,且關聯查詢結果的加載方式為延遲加載,此時需為物體類生成代理類,舉個
例子說明一下,假設有如下兩個物體類:
/** 作者類 */
public class Author {
private Integer id;
private String name;
private Integer age;
private Integer sex; }
/** 文章類 */
public class Article {
private Integer id;
private String title;
// 一對一關系
private Author author;
private String content; }
如上,Article 物件中的資料由一條 SQL 從 article 表中查詢,Article 類有一個 author 字
段,該欄位的資料由另一條 SQL 從 author 表中查出,我們在將 article 表的查詢結果填充到
Article 類物件中時,并不希望 MyBaits 立即執行另一條 SQL 查詢 author 欄位對應的資料,
而是期望在我們呼叫 article.getAuthor()方法時,MyBaits 再執行另一條 SQL 從 author 表中查詢出所需的資料,若如此,我們需要改造 getAuthor 方法,以保證呼叫該方法時可讓 MyBaits執行相關的 SQL,關于延遲加載后面將會進行詳細的分析,這里先說這么多,下面分析createResultObject 多載方法的邏輯,如下:
private Object createResultObject(ResultSetWrapper rsw, ResultMap
resultMap, List<Class<?>> constructorArgTypes, List<Object>
constructorArgs, String columnPrefix) throws SQLException {
final Class<?> resultType = resultMap.getType();
final MetaClass metaType =
MetaClass.forClass(resultType, reflectorFactory);
// 獲取 <constructor> 節點對應的 ResultMapping
final List<ResultMapping> constructorMappings =
resultMap.getConstructorResultMappings();
// 檢測是否有與回傳值型別相對應的 TypeHandler,若有則直接從
// 通過 TypeHandler 從結果集中?取資料,并生成回傳值物件
if (hasTypeHandlerForResultObject(rsw, resultType)) {
// 通過 TypeHandler 獲取?取,并生成回傳值物件
return createPrimitiveResultObject(rsw, resultMap, columnPrefix);
} else if (!constructorMappings.isEmpty()) {
// 通過 <constructor> 節點配置的映射資訊從 ResultSet 中?取資料,
// 然后將這些資料傳給指定構造方法,即可創建物體類物件
return createParameterizedResultObject(rsw, resultType,
constructorMappings, constructorArgTypes,
constructorArgs, columnPrefix);
} else if(resultType.isInterface() || metaType.hasDefaultConstructor()){
// 通過 ObjectFactory 呼叫目標類的默認構造方法創建實體
return objectFactory.create(resultType);
} else if (shouldApplyAutomaticMappings(resultMap, false)) {
// 通過自動映射查找合適的構造方法創建實體
return createByConstructorSignature(rsw, resultType,
constructorArgTypes, constructorArgs, columnPrefix);
}
throw new ExecutorException("……");
}
createResultObject 方法中包含了 4 種創建物體類物件的方式,一般情況下,若無特殊要
求,MyBatis 會通過 ObjectFactory 呼叫默認構造方法創建物體類物件,ObjectFactory 是一個介面,大家可以實作這個介面,以按照自己的邏輯控制物件的創建程序,至此,物體類物件創建好了,接下里要做的事情是將結果集中的資料映射到物體類物件中,
2.結果集映射
在 MyBatis 中,結果集自動映射有三種等級,這三種等級官方檔案上有所說明,這里直
接參考一下,如下:
- NONE - 禁用自動映射,僅設定手動映射屬性
- PARTIAL - 將自動映射結果除了那些有內部定義內嵌結果映射的(joins)
- FULL - 自動映射所有
除了以上三種等級,我們還可以顯示配置節點的 autoMapping 屬性,以啟用
或者禁用指定 ResultMap 的自動映射設定,下面,來看一下自動映射相關的邏輯,
private boolean shouldApplyAutomaticMappings(
ResultMap resultMap, boolean isNested) {
// 檢測 <resultMap> 是否配置了 autoMapping 屬性
if (resultMap.getAutoMapping() != null) {
// 回傳 autoMapping 屬性
return resultMap.getAutoMapping();
} else {
if (isNested) {
// 對于嵌套 resultMap,僅當全域的映射行為為 FULL 時,才進行自動映射
return AutoMappingBehavior.FULL ==
configuration.getAutoMappingBehavior();
} else {
// 對于普通的 resultMap,只要全域的映射行為不為 NONE,即可進行自動映射
return AutoMappingBehavior.NONE !=
configuration.getAutoMappingBehavior();
}
} }
shouldApplyAutomaticMappings 方法用于檢測是否應為當前結果集應用自動映射,檢測
結果取決于節點的 autoMapping 屬性,以及全域自動映射行為,上面代碼的邏輯
不難理解,就不多說了,下面來分析 MyBatis 是如何進行自動映射的,
private boolean applyAutomaticMappings(ResultSetWrapper rsw, ResultMap
resultMap, MetaObject metaObject, String columnPrefix)
throws SQLException {
// 獲取 UnMappedColumnAutoMapping 串列
List<UnMappedColumnAutoMapping> autoMapping = createAutomaticMappings(
rsw, resultMap, metaObject, columnPrefix);
boolean foundValues = false;
if (!autoMapping.isEmpty()) {
for (UnMappedColumnAutoMapping mapping : autoMapping) {
// 通過 TypeHandler 從結果集中獲取指定列的資料
final Object value = mapping.typeHandler
.getResult(rsw.getResultSet(), mapping.column);
if (value != null) {
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() &&
!mapping.primitive)) {
// 通過元資訊物件設定 value 到物體類物件的指定欄位上
metaObject.setValue(mapping.property, value);
}
}
}
return foundValues; }
applyAutomaticMappings 方法的代碼不多,邏輯也不是很復雜,首先是獲取
UnMappedColumnAutoMapping 集合,然后遍歷該集合,并通過 TypeHandler 從結果集中獲取資料,最后再將獲取到的資料設定到物體類物件中,雖然邏輯上看起來沒什么復雜的東西,但如果不清楚 UnMappedColumnAutoMapping 的用途,是無法理解上面代碼的邏輯的,所以這里簡單介紹一下 UnMappedColumnAutoMapping 的用途,UnMappedColumnAutoMapping用于記錄未配置在節點中的映射關系,該類定義在 DefaultResultSetHandler 內部,它的代碼如下:
private static class UnMappedColumnAutoMapping {
private final String column;
private final String property;
private final TypeHandler<?> typeHandler;
private final boolean primitive;
public UnMappedColumnAutoMapping(String column, String property,
TypeHandler<?> typeHandler, boolean primitive) {
this.column = column;
this.property = property;
this.typeHandler = typeHandler;
this.primitive = primitive;
} }
以上就是 UnMappedColumnAutoMapping 類的所有代碼,沒什么邏輯,僅用于記錄映射
關系,下面看一下獲取 UnMappedColumnAutoMapping 集合的程序,
// -☆- DefaultResultSetHandler
private List<UnMappedColumnAutoMapping> createAutomaticMappings(
ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject,
String columnPrefix) throws SQLException {
final String mapKey = resultMap.getId() + ":" + columnPrefix;
// 從快取中獲取 UnMappedColumnAutoMapping 串列
List<UnMappedColumnAutoMapping> autoMapping =
autoMappingsCache.get(mapKey);
// 快取未命中
if (autoMapping == null) {
autoMapping = new ArrayList<UnMappedColumnAutoMapping>();
// 從 ResultSetWrapper 中獲取未配置在 <resultMap> 中的列名
final List<String> unmappedColumnNames =
rsw.getUnmappedColumnNames(resultMap, columnPrefix);
for (String columnName : unmappedColumnNames) {
String propertyName = columnName;
if (columnPrefix != null && !columnPrefix.isEmpty()) {
if (columnName.toUpperCase(Locale.ENGLISH) .startsWith(columnPrefix)) {
// 獲取不包含列名前綴的屬性名
propertyName =
columnName.substring(columnPrefix.length());
} else {
continue;
}
}
// 將下劃線形式的列名轉成駝峰式,比如 AUTHOR_NAME -> authorName
final String property = metaObject.findProperty(
propertyName, configuration.isMapUnderscoreToCamelCase());
if (property != null && metaObject.hasSetter(property)) {
// 檢測當前屬性是否存在于 resultMap 中
if (resultMap.getMappedProperties().contains(property)) {
continue;
}
// 獲取屬性對于的型別
final Class<?> propertyType =
metaObject.getSetterType(property);
if (typeHandlerRegistry.hasTypeHandler(
propertyType, rsw.getJdbcType(columnName))) {
// 獲取型別處理器
final TypeHandler<?> typeHandler =
rsw.getTypeHandler(propertyType, columnName);
// 封裝上面獲取到的資訊到 UnMappedColumnAutoMapping 物件中
autoMapping.add(new UnMappedColumnAutoMapping(
columnName, property, typeHandler,
propertyType.isPrimitive()));
} else {
configuration.getAutoMappingUnknownColumnBehavior()
.doAction(mappedStatement,
columnName, property, propertyType);
}
} else {
// 若 property 為空,或物體類中無 property 屬性,此時無法完成
// 列名與物體類屬性建立映射關系,針對這種情況,有三種處理方式,
// 1. 什么都不做
// 2. 僅列印日志
// 3. 拋出例外
// 默認情況下,是什么都不做
configuration.getAutoMappingUnknownColumnBehavior()
.doAction(mappedStatement, columnName,
(property != null) ? property : propertyName, null);
}
}
// 寫入快取
autoMappingsCache.put(mapKey, autoMapping);
}
return autoMapping; }
上面的代碼有點多,不過不用太擔心,耐心看一下,還是可以看懂的,下面總結一下這
個方法的邏輯,
- 從 ResultSetWrapper 中獲取未配置在中的列名
- 遍歷上一步獲取到的列名串列
- 若列名包含列名前綴,則移除列名前綴,得到屬性名
- 將下劃線形式的列名轉成駝峰式
- 獲取屬性型別
- 獲取型別處理器
- 創建 UnMappedColumnAutoMapping 實體
以上步驟中,除了第一步,其他都是常規操作,無需過多說明,下面來分析第一個步
驟的邏輯,如下:
// -☆- ResultSetWrapper
public List<String> getUnmappedColumnNames(ResultMap resultMap,
String columnPrefix) throws SQLException {
List<String> unMappedColumnNames = unMappedColumnNamesMap.get(
getMapKey(resultMap, columnPrefix));
if (unMappedColumnNames == null) {
// 加載已映射與未映射列名
loadMappedAndUnmappedColumnNames(resultMap, columnPrefix);
// 獲取未映射列名
unMappedColumnNames = unMappedColumnNamesMap.get(
getMapKey(resultMap, columnPrefix));
}
return unMappedColumnNames; }
private void loadMappedAndUnmappedColumnNames(ResultMap resultMap,
String columnPrefix) throws SQLException {
List<String> mappedColumnNames = new ArrayList<String>();
List<String> unmappedColumnNames = new ArrayList<String>();
final String upperColumnPrefix = columnPrefix == null ?
null : columnPrefix.toUpperCase(Locale.ENGLISH);
// 為 <resultMap> 中的列名拼接前綴
final Set<String> mappedColumns = prependPrefixes(
resultMap.getMappedColumns(), upperColumnPrefix);
// 遍歷 columnNames,columnNames 是 ResultSetWrapper 的成員變數,
// 保存了當前結果集中的所有列名
for (String columnName : columnNames) {
final String upperColumnName =
columnName.toUpperCase(Locale.ENGLISH);
// 檢測已映射列名集合中是否包含當前列名
if (mappedColumns.contains(upperColumnName)) {
mappedColumnNames.add(upperColumnName);
} else {
// 將列名存入 unmappedColumnNames 中
unmappedColumnNames.add(columnName);
}
}
// 快取列名集合
mappedColumnNamesMap.put(
getMapKey(resultMap, columnPrefix), mappedColumnNames);
unMappedColumnNamesMap.put(
getMapKey(resultMap, columnPrefix), unmappedColumnNames);
}
如上,已映射列名與未映射列名的分揀邏輯并不復雜,這里簡述一下相關邏輯,首先是
從當前資料集中獲取列名集合,然后獲取中配置的列名集合,之后遍歷資料集中
的列名集合,并判斷列名是否被配置在了節點中,若配置了,則表明該列名已有
映射關系,此時該列名存入 mappedColumnNames 中,若未配置,則表明列名未與物體類的某個欄位形成映射關系,此時該列名存入 unmappedColumnNames 中,這樣,列名的分揀作業就完成了,分揀程序示意圖如下:
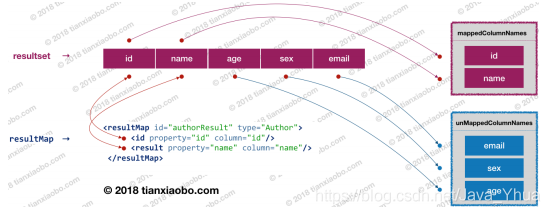
如上圖所示,物體類 Author 的 id 和 name 欄位與列名 id 和 name 被配置在了<resultMap>
中,它們之間形成了映射關系,列名 age、sex 和 email 未配置在<resultMap>中,因此未與Author 中的欄位形成映射,所以他們最終都被放入了 unMappedColumnNames 集合中,弄懂了未映射列名獲取的程序,自動映射的代碼邏輯就不難懂了,好了,關于自動映射的分析就先到這,接下來分析一下 MyBatis 是如何將結果集中的資料填充到已映射的物體類欄位中的,
// -☆- DefaultResultSetHandler
private boolean applyPropertyMappings(ResultSetWrapper rsw, ResultMap
resultMap, MetaObject metaObject,ResultLoaderMap lazyLoader, String
columnPrefix) throws SQLException {
// 獲取已映射的列名
final List<String> mappedColumnNames =
rsw.getMappedColumnNames(resultMap, columnPrefix);
boolean foundValues = false;
// 獲取 ResultMapping
final List<ResultMapping> propertyMappings =
resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
// 拼接列名前綴,得到完整列名
String column = prependPrefix(
propertyMapping.getColumn(), columnPrefix);
if (propertyMapping.getNestedResultMapId() != null) {
column = null;
}
/*
* 下面的 if 分支由三個或條件組合而成,三個條件的含義如下:
* 條件一:檢測 column 是否為 {prop1=col1, prop2=col2} 形式,該
* 種形式的 column 一般用于關聯查詢
* 條件二:檢測當前列名是否被包含在已映射的列名集合中,
* 若包含則可進行資料集映射操作
* 條件三:多結果集相關,暫不分析
*/
if (propertyMapping.isCompositeResult()
|| (column != null && mappedColumnNames.contains(
column.toUpperCase(Locale.ENGLISH)))
|| propertyMapping.getResultSet() != null) {
// 從結果集中獲取指定列的資料
Object value = getPropertyMappingValue(rsw.getResultSet(),
metaObject, propertyMapping, lazyLoader, columnPrefix);
final String property = propertyMapping.getProperty();
if (property == null) {
continue;
// 若獲取到的值為 DEFERED,則延遲加載該值
} else if (value == DEFERED) {
foundValues = true;
continue;
}
if (value != null) {
foundValues = true;
}
if (value != null || (configuration.isCallSettersOnNulls() &&
!metaObject.getSetterType(property).isPrimitive())) {
// 將獲取到的值設定到物體類物件中
metaObject.setValue(property, value);
}
}
}
return foundValues; }
private Object getPropertyMappingValue(ResultSet rs, MetaObject
metaResultObject, ResultMapping propertyMapping, ResultLoaderMap
lazyLoader, String columnPrefix) throws SQLException {
if (propertyMapping.getNestedQueryId() != null) {
// 獲取關聯查詢結果,下一節分析
return getNestedQueryMappingValue(rs, metaResultObject,
propertyMapping, lazyLoader, columnPrefix);
} else if (propertyMapping.getResultSet() != null) {
addPendingChildRelation(rs, metaResultObject, propertyMapping);
return DEFERED;
} else {
final TypeHandler<?> typeHandler = propertyMapping.getTypeHandler();
// 拼接前綴
final String column = prependPrefix(propertyMapping.getColumn(),
columnPrefix);
// 從 ResultSet 中獲取指定列的值
return typeHandler.getResult(rs, column);
} }
applyPropertyMappings 方法首先從 ResultSetWrapper 中獲取已映射列名集合
mappedColumnNames, 從 ResultMap 獲取映射物件 ResultMapping 集合,然后遍歷
ResultMapping 集合,在此程序中呼叫 getPropertyMappingValue 獲取指定指定列的資料,最后將獲取到的資料設定到物體類物件中,到此,基本的結果集映射程序就分析完了,
3.關聯查詢與延遲加載
我們在學習 MyBatis 框架時,會經常碰到一對一,一對多的使用場景,對于這樣的場景,
通常我們可以用一條 SQL 進行多表查詢完成任務,當然我們也可以使用關聯查詢,將一條
SQL 拆成兩條去完成查詢任務,MyBatis 提供了兩個標簽用于支持一對一和一對多的使用場
景,分別是和,下面我來演示一下如何使用完成一對一的關聯查詢,先來看看物體類的定義:
/** 作者類 */
public class Author {
private Integer id;
private String name;
private Integer age;
private Integer sex;
private String email;
// 省略 getter/setter
}
/** 文章類 */
public class Article {
private Integer id;
private String title;
// 一對一關系
private Author author;
private String content;
private Date createTime;
// 省略 getter/setter
}
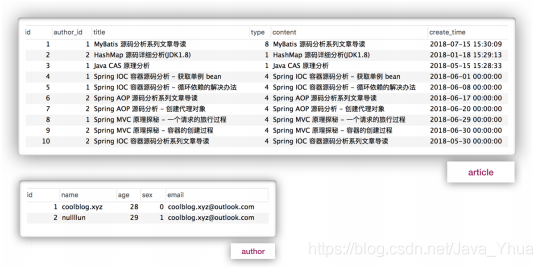
相關表記錄如下
接下來看一下 Mapper 介面與映射檔案的定義,
public interface ArticleDao {
Article findOne(@Param("id") int id);
Author findAuthor(@Param("id") int authorId);
}
<mapper namespace="xyz.coolblog.chapter4.dao.ArticleDao">
<resultMap id="articleResult" type="Article">
<result property="createTime" column="create_time"/>
<association property="author" column="author_id"
javaType="Author" select="findAuthor"/>
</resultMap>
<select id="findOne" resultMap="articleResult">
SELECT
id, author_id, title, content, create_time
FROM
article
WHERE
id = #{id}
</select>
<select id="findAuthor" resultType="Author">
SELECT
id, name, age, sex, email
FROM
author
WHERE
id = #{id}
</select>
</mapper>
好了,必要在的準備作業做完了,下面可以寫測驗代碼了,如下:
public class OneToOneTest {
private SqlSessionFactory sqlSessionFactory;
@Before
public void prepare() throws IOException {
String resource = "chapter4/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new
SqlSessionFactoryBuilder().build(inputStream);
inputStream.close();
}
@Test
public void testOne2One() {
SqlSession session = sqlSessionFactory.openSession();
try {
ArticleDao articleDao = session.getMapper(ArticleDao.class);
Article article = articleDao.findOne(1);
Author author = article.getAuthor();
article.setAuthor(null);
System.out.println("\narticles info:");
System.out.println(article);
System.out.println("\nauthor info:");
System.out.println(author);
} finally {
session.close();
}
} }
測驗結果如下:
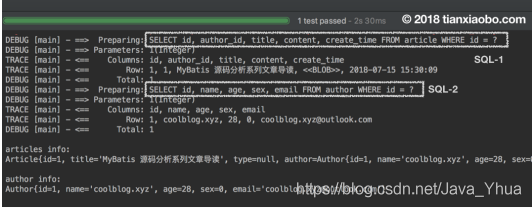
如上,從上面的輸出結果中可以看出,我們在呼叫 ArticleDao 的 findOne 方法時,MyBatis
執行了兩條 SQL,完成了一對一的查詢需求,理解了上面的例子后,下面就可以深入到原始碼
中,看看 MyBatis 是如何實作關聯查詢的,接下里從 getNestedQueryMappingValue 方法開始分析,如下:
private Object getNestedQueryMappingValue(ResultSet rs,
MetaObject metaResultObject, ResultMapping propertyMapping,
ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
// 獲取關聯查詢 id,id = 命名空間 + <association> 的 select 屬性值
final String nestedQueryId = propertyMapping.getNestedQueryId();
final String property = propertyMapping.getProperty();
// 根據 nestedQueryId 獲取 MappedStatement
final MappedStatement nestedQuery =
configuration.getMappedStatement(nestedQueryId);
final Class<?> nestedQueryParameterType =
nestedQuery.getParameterMap().getType();
/*
* 生成關聯查詢陳述句引數物件,引數型別可能是一些包裝類,Map 或是自定義的物體類,
* 具體型別取決于配置資訊,以上面的例子為基礎,下面分析不同配置對
* 引數型別的影響:
* 1. <association column="author_id">
* column 屬性值僅包含列資訊,引數型別為 author_id 列對應的型別,
* 這里為 Integer
* 2. <association column="{id=author_id, name=title}">
* column 屬性值包含了屬性名與列名的復合資訊,MyBatis 會根據列名從
* ResultSet 中獲取列資料,并將列資料設定到物體類物件的指定屬性中,比如:
* Author{id=1, name="MyBatis 原始碼分析系列文章導讀", age=null, …}
* 或是以鍵值對 <屬性, 列資料> 的形式,將兩者存入 Map 中,比如:
* {"id": 1, "name": "MyBatis 原始碼分析系列文章導讀"}
*
* 至于引數型別到底為物體類還是 Map,取決于關聯查詢陳述句的配置資訊,比如:
* <select id="findAuthor"> -> 引數型別為 Map
* <select id="findAuthor" parameterType="Author">
* -> 引數型別為物體類
*/
final Object nestedQueryParameterObject=prepareParameterForNestedQuery(
rs, propertyMapping, nestedQueryParameterType, columnPrefix);
Object value = null;
if (nestedQueryParameterObject != null) {
// 獲取 BoundSql
final BoundSql nestedBoundSql =
nestedQuery.getBoundSql(nestedQueryParameterObject);
final CacheKey key = executor.createCacheKey(nestedQuery,
nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql);
final Class<?> targetType = propertyMapping.getJavaType();
// 檢查一級快取是否保存了關聯查詢結果
if (executor.isCached(nestedQuery, key)) {
// 從一級快取中獲取關聯查詢的結果,并通過 metaResultObject
// 將結果設定到相應的物體類物件中
executor.deferLoad(nestedQuery,
metaResultObject, property, key, targetType);
value = DEFERED;
} else {
// 創建結果加載器
final ResultLoader resultLoader = new ResultLoader(
configuration, executor, nestedQuery,
nestedQueryParameterObject, targetType, key, nestedBoundSql);
// 檢測當前屬性是否需要延遲加載
if (propertyMapping.isLazy()) {
// 添加延遲加載相關的物件到 loaderMap 集合中
lazyLoader.addLoader(
property, metaResultObject, resultLoader);
value = DEFERED;
} else {
// 直接執行關聯查詢
value = resultLoader.loadResult();
}
}
}
return value; }
上面對關聯查詢進行了比較多的注釋,導致該方法看起來有點復雜,當然,真實的邏輯
確實有點復雜,因為它還呼叫了其他的很多方法,下面先來總結一下該方法的邏輯:
- 根據 nestedQueryId 獲取 MappedStatement
- 生成引數物件
- 獲取 BoundSql
- 檢測一級快取中是否有關聯查詢的結果,若有,則將結果設定到物體類物件中
- 若一級快取未命中,則創建結果加載器 ResultLoader
- 檢測當前屬性是否需要進行延遲加載,若需要,則添加延遲加載相關的物件到
loaderMap 集合中 - 如不需要延遲加載,則直接通過結果加載器加載結果
如上,getNestedQueryMappingValue 方法中邏輯多是都是和延遲加載有關,除了延遲加
載,以上流程中針對一級快取的檢查是十分有必要的,若快取命中,可直接取用結果,無需
再在執行關聯查詢 SQL,若快取未命中,接下來就要按部就班執行延遲加載相關邏輯,接下
來,分析一下 MyBatis 延遲加載是如何實作的,首先我們來看一下添加延遲加載相關物件到
loaderMap 集合中的邏輯,如下:
// -☆- ResultLoaderMap
public void addLoader(String property, MetaObject metaResultObject,
ResultLoader resultLoader) {
// 將屬性名轉為大寫
String upperFirst = getUppercaseFirstProperty(property);
if (!upperFirst.equalsIgnoreCase(property) &&
loaderMap.containsKey(upperFirst)) {
throw new ExecutorException("……");
}
// 創建 LoadPair,并將 <大寫屬性名,LoadPair 物件> 鍵值對添加到 loaderMap 中
loaderMap.put(upperFirst,
new LoadPair(property, metaResultObject, resultLoader));
}
addLoader 方法的引數最終都傳給了 LoadPair,該類的 load 方法會在內部呼叫
ResultLoader 的 loadResult 方法進行關聯查詢,并通過 metaResultObject 將查詢結果設定到實
體類物件中,那 LoadPair 的 load 方法由誰呼叫呢?答案是物體類的代理物件,下面我們修改一下上面示例中的部分代碼,演示一下延遲加載,首先,我們需要在 MyBatis 組態檔的
<settings>節點中加入或覆寫如下配置:
<!-- 開啟延遲加載 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 關倍訓極的加載策略 -->
<setting name="aggressiveLazyLoading" value="false"/>
<!-- 延遲加載的觸發方法 -->
<setting name="lazyLoadTriggerMethods" value="equals,hashCode"/>
上面三個配置 MyBatis 官方檔案中有較為詳細的介紹,大家可以參考官方檔案,這里就
不詳細介紹了,下面修改一下測驗類的代碼:
public class OneToOneTest {
private SqlSessionFactory sqlSessionFactory;
@Before
public void prepare() throws IOException {...}
@Test
public void testOne2One2() {
SqlSession session = sqlSessionFactory.openSession();
try {
ArticleDao articleDao = session.getMapper(ArticleDao.class);
Article article = articleDao.findOne(1);
System.out.println("\narticles info:");
System.out.println(article);
System.out.println("\n 延遲加載 author 欄位:");
// 通過 getter 方法觸發延遲加載
Author author = article.getAuthor();
System.out.println("\narticles info:");
System.out.println(article);
System.out.println("\nauthor info:");
System.out.println(author);
} finally {
session.close();
}
} }
測驗結果如下:
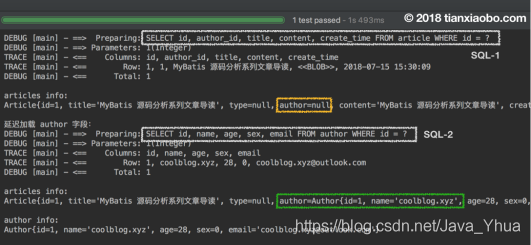
從上面結果中可以看出,我們在未呼叫 getAuthor 方法時,Article 物件中的 author 欄位
為 null,呼叫該方法后,再次輸出 Article 物件,發現其 author 欄位有值了,表明 author 欄位的延遲加載邏輯被觸發了,既然呼叫 getAuthor 可以觸發延遲加載,那么該方法一定被做過手腳了,不然該方法應該回傳 null 才是,實際情況確實如此,MyBatis 會為需要延遲加載的類生成代理類,代理邏輯會攔截物體類的方法呼叫,默認情況下,MyBatis 會使用 Javassist為物體類生成代理,代理邏輯封裝在 JavassistProxyFactory 類中,下面一起看一下,
// -☆- JavassistProxyFactory
public Object invoke(Object enhanced, Method method, Method methodProxy,
Object[] args) throws Throwable {
final String methodName = method.getName();
try {
synchronized (lazyLoader) {
if (WRITE_REPLACE_METHOD.equals(methodName)) {
// 針對 writeReplace 方法的處理邏輯,與延遲加載無關,不分析了
} else {
if (lazyLoader.size() > 0 &&
!FINALIZE_METHOD.equals(methodName)) {
// 如果 aggressive 為 true,或觸發方法(比如 equals,
// hashCode 等)被呼叫,則加載所有的所有延遲加載的資料
if (aggressive ||
lazyLoadTriggerMethods.contains(methodName)) {
lazyLoader.loadAll();
} else if (PropertyNamer.isSetter(methodName)) {
final String property =
PropertyNamer.methodToProperty(methodName);
// 如果使用者顯示呼叫了 setter 方法,則將相應的
// 延遲加載類從 loaderMap 中移除
lazyLoader.remove(property);
// 檢測使用者是否呼叫 getter 方法
} else if (PropertyNamer.isGetter(methodName)) {
final String property =
PropertyNamer.methodToProperty(methodName);
// 檢測該屬性是否有相應的 LoadPair 物件
if (lazyLoader.hasLoader(property)) {
// 執行延遲加載邏輯
lazyLoader.load(property);
}
}
}
}
}
// 呼叫被代理類的方法
return methodProxy.invoke(enhanced, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
} }
如上,代理方法首先會檢查 aggressive 是否為 true ,如果不滿足,再去檢查
lazyLoadTriggerMethods 是否包含當前方法名,這里兩個條件只要一個為 true,當前物體類
中所有需要延遲加載,aggressive 和 lazyLoadTriggerMethods 兩個變數的值取決于下面的配置,
<setting name="aggressiveLazyLoading" value="false"/>
<setting name="lazyLoadTriggerMethods" value="equals,hashCode"/>
回到上面的代碼中,如果執行執行緒未進入第一個條件分支,那么緊接著,代理邏輯會檢
查使用者是不是呼叫了物體類的 setter 方法,如果呼叫了,就將該屬性對應的 LoadPair 從
loaderMap 中移除,為什么要這么做呢?答案是:使用者既然手動呼叫 setter 方法,說明使用者想自定義某個屬性的值,此時,延遲加載邏輯不應該再修改該屬性的值,所以這里從
loaderMap 中移除屬性對于的 LoadPair,最后如果使用者呼叫的是某個屬性的 getter 方法,
且該屬性配置了延遲加載,此時延遲加載邏輯就會被觸發,那接下來,我們來看看延遲加載
邏輯是怎樣實作的的,
// -☆- ResultLoaderMap
public boolean load(String property) throws SQLException {
// 從 loaderMap 中移除 property 所對應的 LoadPair
LoadPair pair = loaderMap.remove(property.toUpperCase(Locale.ENGLISH));
if (pair != null) {
// 加載結果
pair.load();
return true;
}
return false; }
// -☆- LoadPair
public void load() throws SQLException {
if (this.metaResultObject == null) {
throw new IllegalArgumentException("metaResultObject is null");
}
if (this.resultLoader == null) {
throw new IllegalArgumentException("resultLoader is null");
}
// 呼叫多載方法
this.load(null);
}
public void load(final Object userObject) throws SQLException {
// 若 metaResultObject 和 resultLoader 為 null,則創建相關物件,
// 在當前呼叫情況下,兩者均不為 null,條件不成立,篇幅原因,下面代碼不分析了
if (this.metaResultObject == null || this.resultLoader == null) {...}
// 執行緒安全檢測
if (this.serializationCheck == null) {
final ResultLoader old = this.resultLoader;
// 重新創建新的 ResultLoader 和 ClosedExecutor,
// ClosedExecutor 是非執行緒安全的
this.resultLoader = new ResultLoader(old.configuration,
new ClosedExecutor(), old.mappedStatement, old.parameterObject,
old.targetType, old.cacheKey, old.boundSql);
}
// 呼叫 ResultLoader 的 loadResult 方法加載結果,
// 并通過 metaResultObject 設定結果到物體類物件中
this.metaResultObject.setValue(property,this.resultLoader.loadResult());
}
上面的代碼比較多,但是沒什么特別的邏輯,我們重點關注最后一行有效代碼就行了,
下面看一下 ResultLoader 的 loadResult 方法邏輯是怎樣的,
public Object loadResult() throws SQLException {
// 執行關聯查詢
List<Object> list = selectList();
// 抽取結果
resultObject = resultExtractor.extractObjectFromList(list, targetType);
return resultObject; }
private <E> List<E> selectList() throws SQLException {
Executor localExecutor = executor;
if (Thread.currentThread().getId() != this.creatorThreadId ||
localExecutor.isClosed()) {
localExecutor = newExecutor();
}
try {
// 通過 Executor 就行查詢,這個之前已經分析過了
return localExecutor.<E>query(mappedStatement, parameterObject,
RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER, cacheKey,boundSql);
} finally {
if (localExecutor != executor) {
localExecutor.close(false);
}
} }
如上,我們在 ResultLoader 中終于看到了執行關聯查詢的代碼,即 selectList 方法中的
邏輯,該方法在內部通過 Executor 進行查詢,至于查詢結果的抽取程序,并不是本節所關心
的點,因此大家自行分析吧,到此,關于關聯查詢與延遲加載就分析完了,
4.存盤映射結果
存盤映射結果是“查詢結果”處理流程中的最后一環,實際上也是查詢陳述句執行程序的最
后一環,本節內容分析完,整個查詢程序就分析完了,那接下來讓我們帶著喜悅的心情來分
析映射結果存盤邏輯,
private void storeObject(ResultHandler<?> resultHandler,
DefaultResultContext<Object> resultContext,Object rowValue, ResultMapping
parentMapping, ResultSet rs) throws SQLException {
if (parentMapping != null) {
// 多結果集相關,不分析了
linkToParents(rs, parentMapping, rowValue);
} else {
// 存盤結果
callResultHandler(resultHandler, resultContext, rowValue);
} }
private void callResultHandler(ResultHandler<?> resultHandler,
DefaultResultContext<Object> resultContext, Object rowValue) {
// 設定結果到 resultContext 中
resultContext.nextResultObject(rowValue);
// 從 resultContext 獲取結果,并存盤到 resultHandler 中
((ResultHandler<Object>) resultHandler).handleResult(resultContext);
}
上面方法顯示將 rowValue 設定到 ResultContext 中,然后再將 ResultContext 物件作為參
數傳給 ResultHandler 的 handleResult 方法,下面我們分別看一下 ResultContext 和
ResultHandler 的實作類,如下:
public class DefaultResultContext<T> implements ResultContext<T> {
private T resultObject;
private int resultCount;
/** 狀態欄位 */
private boolean stopped;
// 省略部分代碼
@Override
public boolean isStopped() {
return stopped;
}
public void nextResultObject(T resultObject) {
resultCount++;
this.resultObject = resultObject;
}
@Override
public void stop() {
this.stopped = true;
} }
DefaultResultContext 中包含了一個狀態欄位,表明結果背景關系的狀態,在處理多行資料
時,MyBatis 會檢查該欄位的值,已決定是否需要進行后續的處理,該類的邏輯比較簡單,
不多說了,下面再來看一下 DefaultResultHandler 的原始碼,
public class DefaultResultHandler implements ResultHandler<Object> {
private final List<Object> list;
public DefaultResultHandler() {
list = new ArrayList<Object>();
}
@Override
public void handleResult(ResultContext<? extends Object> context) {
// 添加結果到 list 中
list.add(context.getResultObject());
}
public List<Object> getResultList() {
return list;
} }
如上,DefaultResultHandler 默認使用 List 存盤結果,除此之外,如果 Mapper(或 Dao)
介面方法回傳值為 Map 型別,此時則需要另一種 ResultHandler 實作類處理結果,即
DefaultMapResultHandler,關于 DefaultMapResultHandler 的原始碼大家自行分析吧啊,本節就不展開了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/247686.html
標籤:其他
上一篇:p1593 因子和
下一篇:陣列實作的單鏈表