一個簡單的字串,為什么 Redis 要設計的如此特別
- 五種基本資料型別之字串物件
- 二進制安全字串
- 什么是二進制安全的字串
- sds 空間分配策略
- 空間預分配
- 惰性空間釋放
- sds 和 C 語言字串區別
- sds 是如何被存盤的
- type 屬性
- encoding 屬性
- embstr 編碼為什么從 39 位修改為 44 位
- embstr 編碼和 raw 編碼的區別
- 總結
本文GitHub已收錄:https://zhouwenxing.github.io/
Redis 中支持的資料型別到 5.0.5 版本,一共有 9 種,分別是:
- 1、Binary-safe strings(二進制安全字串)
- 2、Lists(串列)
- 3、Sets(集合)
- 4、Sorted sets(有序集合)
- 5、Hashes(哈希)
- 6、Bit arrays (or simply bitmaps)(位圖)
- 7、HyperLogLogs
- 8、 geospatial
- 9、Streams
雖然這里列出了 9 種,但是基礎型別就是前面 5 種,后面的 4 種是基于前面 5 種基本型別及特定的演算法來實作的特殊型別,
而在 5 種基礎型別之中,又尤其以字串型別最為常用,且 key 值只能為字串物件,所以要想深入的了解 Redis 的特性,字串物件是首先需要學習的,
五種基本資料型別之字串物件
Redis 當中有五種基礎資料型別,而字串物件又是最重要最常用的一種型別,
二進制安全字串
Redis 是基于 C 語言進行開發的,而 C 語言中的字串是二進制不安全的,所以 Redis 就沒有直接使用 C 語言的字串,而是自己撰寫了一個新的資料結構來表示字串,這種資料結構稱之為:簡單動態字串(Simple dynamic string),簡稱 SDS,
什么是二進制安全的字串
在 C 語言中,字串采用的是一個 char 陣列(柔性陣列)來存盤字串,而且字串必須要以一個空字串 \0 來結尾,而且字串并不記錄長度,所以如果想要獲取一個字串的長度就必須遍歷整個字串,直到遇到第一個 \0 為止(\0 不會計入字串長度),故而獲取字串長度的時間復雜度為 O(n),
正因為 C 語言中是以遇到的第一個空字符 \0 來識別是否到了字串末尾,因此其只能保存文本資料,不能保存圖片,音頻,視頻和壓縮檔案等二進制資料,否則可能出現字串不完整的問題,所以其是二進制不安全的,
Redis 中為了實作二進制安全的字串,對原有 C 語言中的字串實作做了改進,如下所示就是一個舊版本的 sds 字串的結構定義:
struct sdshdr{
int len;//記錄buf陣列已使用的長度,即SDS的長度(不包含末尾的'\0')
int free;//記錄buf陣列中未使用的長度
char buf[];//位元組陣列,用來保存字串
}
經過改進之后,如果想要獲取 sds 的長度不用去遍歷 buf 陣列了,直接讀取 len 屬性就可以得到長度,時間復雜度一下就變成了 O(1),而且因為判斷字串長度不再依賴空字符 \0,所以其能存盤圖片,音頻,視頻和壓縮檔案等二進制資料,不用擔心讀取到的字串不完整,
需要注意的是,sds 依然遵循了 C 語言字串以 \0 結尾的慣例,這么做是為了方便復用 C 語言字串原生的一些API,換言之就是在 C 語言中會以碰到的第一個 \0 字符當做當前字串物件的結尾,所以如果一些二進制資料就會可能出現讀取字串不完整的現象,而 sds 會以長度來判斷是否到字串末尾,
在 Redis 3.2 之后的版本,Redis 對 sds 又做了優化,按照存盤空間的大小拆分成為了 sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,分別用來存盤大小為:32 位元組(2 的 5 次方),256 位元組(2 的 8 次方),64KB(2 的 16 次方),4GB 大小(2 的 32 次方)以及 2 的 64 次方大小的字串(因為目前版本 key 和 value 都限制了最大 512MB,所以 sdshdr64 暫時并未使用到), sdshdr5 只被應用在了 Redis 中的 key 中,value 中不會被使用到,因為sdshdr5和其他型別也不一樣,其并沒有存盤未使用空間,所以其是比較適用于使用大小固定的場景(比如 key 值):
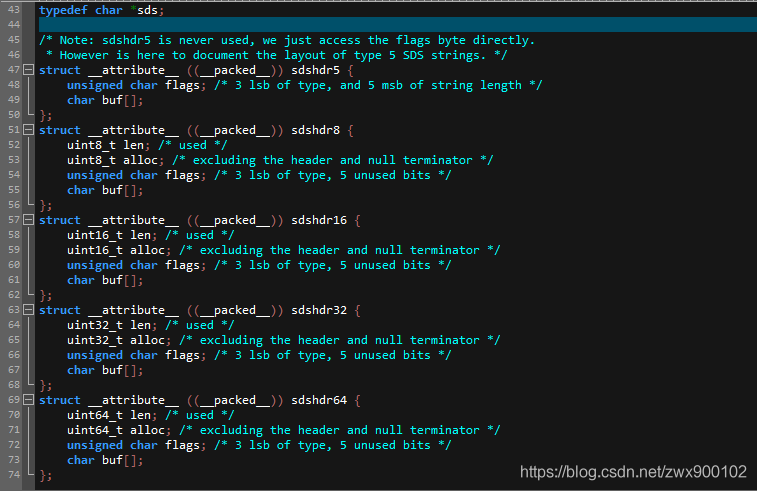
任意選擇其中一種資料型別,其欄位代表含義如下:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; //已使用空間大小
uint8_t alloc; //總共申請的空間大小(包括未使用的)
unsigned char flags; //用來表示當前sds型別是sdshdr8還是sdshdr16等
char buf[]; //真實存盤字串的位元組陣列
};
可以看到相比較于 Redis 3.2 版本之前的 sds 主要是修改了 free 屬性然后新增了一個 flags 標記來區分當前的 sds 型別,
sds 空間分配策略
C 語言中因為字串內部沒有記錄長度,所以如果擴充字串的時候非常容易造成緩沖區溢位(buffer overflow),
請看下面這張圖,假設下面這張圖就是記憶體里面的連續空間,可以很明顯的看到,此時 wolf 和 Redis 兩個字串之間只有三個空位,那么這時候如果我們要將 wolf 字串修改為 lonelyWolf,那么就需要 6 個空間,這時候下面這個空間是放不下的,所以必須要重新申請空間,但是假如說程式員忘了申請空間,或者說申請到的空間依然不夠,那么就會出現后面的 Redis 字串中的 Red 被覆寫了:
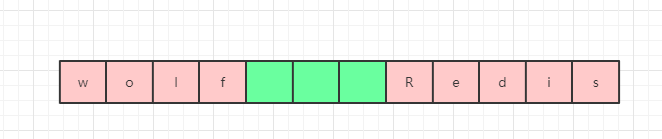
同樣的,假如要縮小字串的長度,那么也需要重新申請釋放記憶體,否則,字串一直占據著未使用的空間,會造成記憶體泄露,
C 語言避免快取區溢位和記憶體泄露完全依賴于人為,很難把控,但是使用 sds 就不會出現這兩個問題,因為當我們操作 sds時,其內部會自動執行空間分配策略,從而避免了上述兩種情況的出現,
空間預分配
空間預分配指的是當我們通過 api 對 sds 進行擴展空間的時候,假如未使用空間不夠用,那么程式不僅會為 sds 分配必須要的空間,還會額外分配未使用空間,未使用空間分配大小主要有兩種情況:
- 1、假如擴大長度之后的
len屬性小于等于1MB(即 1024 * 1024),那么就會同時分配和len屬性一樣大小的未使用空間(此時buf陣列已使用空間 = 未使用空間), - 2、假如擴大長度之后的
len屬性大于1MB,那么就會分配1MB未使用空間大小,
執行空間預分配策略的好處是提前分配了未使用空間備用后,就不需要每次增大字串都需要分配空間,減少了記憶體重分配的次數,
惰性空間釋放
惰性空間釋放指的是當我們需要通過 api 減小 sds 長度的時候,程式并不會立即釋放未使用的空間,而只是更新 free 屬性的值,這樣空間就可以留給下一次使用,而為了防止出現記憶體溢位的情況,sds 單獨提供給了 api 讓我們在有需要的時候去真正的釋放記憶體,
sds 和 C 語言字串區別
下面表格中列舉了 Redis 中的 sds 和 C 語言中實作的字串的區別:
| C 字串 | SDS |
|---|---|
只能保存文本類不含空字串 \0 資料 | 可以保存文本或者二進制資料,允許包含空字串 \0 |
獲取字串長度的復雜度為 O(n) | 獲取字串長度的復雜度為 O(1) |
| 操作字串可能會造成緩沖區溢位 | 不會出現緩沖區溢位情況 |
修改字串長度 N 次,必然需要 N次記憶體重分配 | 修改字串長度 N 次,最多需要 N 次記憶體重分配 |
可以使用 C 字串相關的所有函式 | 可以使用 C 字串相關的部分函式 |
sds 是如何被存盤的
在 Redis 中所有的資料型別都是將對應的資料結構再進行了再一次包裝,創建了一個字典物件來存盤的,sds也不例外,每次創建一個 key-value 鍵值對,Redis 都會創建兩個物件,一個是鍵物件,一個是值物件,而且需要注意的是在 Redis 中,值物件并不是直接存盤,而是被包裝成 redisObject 物件,并同時將鍵物件和值物件通過 dictEntry 物件進行封裝,如下就是一個 dictEntry 物件:
typedef struct dictEntry {
void *key;//指向key,即sds
union {
void *val;//指向value
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;//指向下一個key-value鍵值對(哈希值相同的鍵值對會形成一個鏈表,從而解決哈希沖突問題)
} dictEntry;
redisObject 物件的定義為:
typedef struct redisObject {
unsigned type:4;//物件型別(4位=0.5位元組)
unsigned encoding:4;//編碼(4位=0.5位元組)
unsigned lru:LRU_BITS;//記錄物件最后一次被應用程式訪問的時間(24位=3位元組)
int refcount;//參考計數,等于0時表示可以被垃圾回收(32位=4位元組)
void *ptr;//指向底層實際的資料存盤結構,如:sds等(8位元組)
} robj;
當我們在 Redis 客戶端中執行命令 set name lonely_wolf ,就會得到下圖所示的一個結構(省略了部分屬性):
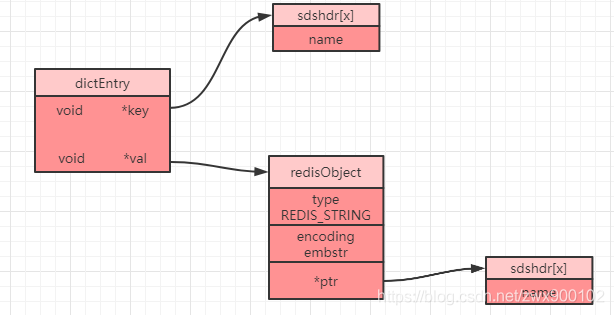
看到這個圖想必大家會有疑問,這里面的 type 和 encoding 到底是什么呢?其實這兩個屬性非常關鍵,Redis 就是通過這兩個屬性來識別當前的 value 到除錯于哪一種基本資料型別,以及當前資料型別的底層采用了何種資料結構進行存盤,
type 屬性
type 屬性表示物件型別,其對應了 Redis 當中的 5 種基本資料型別:
| 型別屬性 | 描述 | type命令回傳值 |
|---|---|---|
| REDIS_STRING | 字串物件 | string |
| REDIS_LIST | 串列物件 | list |
| REDIS_HASH | 哈希物件 | hash |
| REDIS_SET | 集合物件 | set |
| REDIS_ZSET | 有序集合物件 | zset |
可以看到,這就是對應了我們 5 種常用的基本資料型別,
encoding 屬性
Redis 當中每種資料型別都是經過特別設計的,相信大家看完這個系列也會體會到 Redis 設計的精妙之處,字串在我們眼里是非常簡單的一種資料結構了,但是 Redis 卻把它優化到了極致,為了節省空間,其通過編碼的方式定義了三種不同的存盤方式:
| 編碼屬性 | 描述 | object encoding命令回傳值 |
|---|---|---|
| OBJ_ENCODING_INT | 使用整數的字串物件 | int |
| OBJ_ENCODING_EMBSTR | 使用 embstr 編碼實作的字串物件 | embstr |
| OBJ_ENCODING_RAW | 使用 raw 編碼實作的字串物件 | raw |
int編碼
當我們用字串物件存盤的是整型,且能用8個位元組的long型別進行表示(即2的63次方減1),則Redis會選擇使用int編碼來存盤,此時redisObject物件中的ptr指標直接替換為long型別,我們想想8個位元組如果用字串來存盤只能存8位,也就是千萬級別的數字,遠遠達不到2的63次方減1這個級別,所以如果都是數字,用long型別會更節省空間,embstr編碼
當字串物件中存盤的是字串,且長度小于44(Redis 3.2版本之前是39)時,Redis會選擇使用embstr編碼來存盤,raw編碼
當字串物件中存盤的是字串,且長度大于44時,Redis會選擇使用raw編碼來存盤,
講了半天理論,接下來讓我們一起來驗證下這些結論,依次輸入 set name lonely_wolf,type name,object encoding name 命令:

可以發現當前的資料型別就是 string,普通字串因為長度小于 44,所以采用的是 embstr 編碼,
再依次輸入:set num 1111111111,set address aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa(長度 44),set address aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa(長度 45),分別查看型別和編碼:
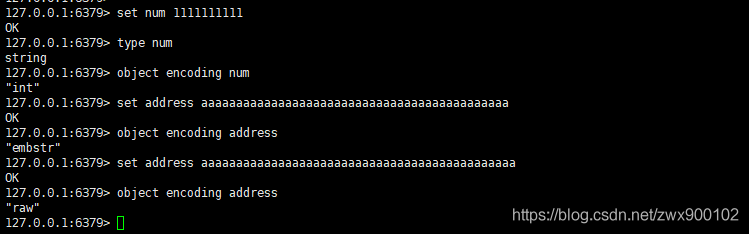
可以發現,當輸入純數字的時候,采用的是 int 編碼,而字串小于等于 44 則為 embstr,大于 44 則為 raw 編碼,
字串物件中除了上面提到的純整數和字串,還可以存盤浮點型型別,所以字串物件可以存盤以下三種型別:
- 字串
- 整數
- 浮點數
而當我們的 value 為整數時,還可以使用原子自增命令來實作 value 的自增,這個命令在實際開發程序中非常實用,
incr:自增1,incrby:自增指定數值,

不過這兩個命令只能用在 value 為整數的場景,當 value 不是整數時則會報錯,
embstr 編碼為什么從 39 位修改為 44 位
embstr 編碼中,redisObject 和 sds 是連續的一塊記憶體空間,這塊記憶體空間 Redis 限制為了 64 個位元組,而redisObject 固定占了16位元組(上面定義中有標注),Redis 3.2 版本之前的 sds 占了 8 個位元組,再加上字串末尾 \0 占用了 1 個位元組,所以:64-16-8-1=39 位元組,
Redis 3.2 版本之后 sds 做了優化,對于 embstr 編碼會采用 sdshdr8 來存盤,而 sdshdr8 占用的空間只有 24 位:3 位元組(len+alloc+flag)+ \0 字符(1位元組),所以最后就剩下了:64-16-3-1=44 位元組,
embstr 編碼和 raw 編碼的區別
embstr 編碼是一種優化的存盤方式,其在申請空間的時候因為 redisObject 和 sds 兩個物件是一個連續空間,所以只需要申請 1 次空間(同樣的,釋放記憶體也只需要 1 次),而 raw 編碼因為 redisObject 和 sds 兩個物件的空間是不連續的,所以使用的時候需要申請 2 次空間(同樣的,釋放記憶體也需要 2 次),但是使用 embstr 編碼時,假如需要修改字串,那么因為 redisObject 和 sds 是在一起的,所以兩個物件都需要重新申請空間,為了避免這種情況發生,embstr 編碼的字串是只讀的,不允許修改,
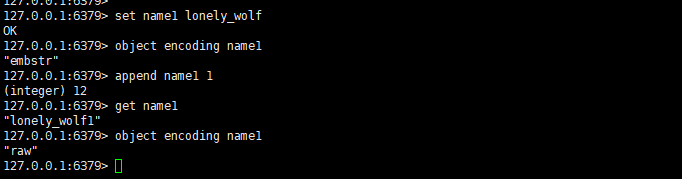
上圖中的示例我們看到,對一個 embstr 編碼的字串物件進行 append 操作時,長度還沒有達到 45,但是編碼已經被修改為 raw 了,這就是因為 embstr 編碼是只讀的,如果需要對其修改,Redis 內部會將其修改為 raw 編碼之后再操作,同樣的,如果是操作 int 編碼的字串之后,導致 long 型別無法存盤時(int 型別不再是整數或者長度超過 2 的 63 次方減 1 時),也會將 int 編碼修改為 raw 編碼,
PS:需要注意的是,編碼一旦升級(int–>embstr–>raw),即使后期再把字串修改為符合原編碼能存盤的格式時,編碼也不會回退,
總結
本文主要講述了 Redis 當中最常用的字符創物件,通過二進制安全字串的特別逐步分析了 sds 的底層存盤即編碼格式,并分別介紹了每種編碼格式的區別,最后通過示例來演示了編碼的轉換程序,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/247693.html
標籤:其他
上一篇:學習分享:POI-TL 匯出Word復雜表格合并分享
下一篇:HTML5知識點總結(三)