備注:
Hive 版本 2.1.1
文章目錄
- 一.Hive ACID and Transactions
- 二.Hive on Tez
- 三. Hive on Spark
- 四.HCatalog
- 參考
這個blog介紹Hive的高級特性
1) Hive ACID and Transactions
2) Hive on Tez
3) Hive on Spark
4) HCatalog
一.Hive ACID and Transactions
Hive 0.14版本開始支持ACID
歷史版本:
- 一次寫入,多次分析查詢的場景(HDFS不可行級別更新)
- 僅支持表或者partition級別的insert overwrite全量重寫
- 不支持行級別的更新或洗掉
ACID 支持: - INSERT INTO … VALUES (…) ,(…) …
- UPDATE … SET xxx=xxx WHERE …
- DELETE FROM … WHERE …
前提條件:
- Hive 0.14版本以上
- 目前僅支持ORC格式
- 表必須分桶且不能sort
- 表必須顯式宣告transactional=true
配置(hive-site.xml):
hive.support.concurrency=true
hive.enforce.bucketing=true
hive.exec.dynamic.partition.mode=nonstrict
hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager
hive.compactor.initiator.on=true
hive.compactor.worker.threads=2
hive 事務表測驗
hive> CREATE TABLE test_transaction(id int, name string) CLUSTERED BY (id) INTO 2 BUCKETS
> STORED AS ORC TBLPROPERTIES ('transactional'='true');
OK
Time taken: 1.661 seconds
hive> INSERT INTO test_transaction VALUES (1, 'John') ,(2,'Lily'),(3, 'Tom');
Query ID = root_20201224175758_cc903192-1091-4893-8f0c-a1448a1c737b
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
20/12/24 17:57:59 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm69
Starting Job = job_1608780340033_0008, Tracking URL = http://hp3:8088/proxy/application_1608780340033_0008/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1608780340033_0008
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 2
2020-12-24 17:58:07,399 Stage-1 map = 0%, reduce = 0%
2020-12-24 17:58:13,627 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.94 sec
2020-12-24 17:58:19,822 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 6.65 sec
2020-12-24 17:58:20,852 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 10.26 sec
MapReduce Total cumulative CPU time: 10 seconds 260 msec
Ended Job = job_1608780340033_0008
Loading data to table test.test_transaction
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 10.26 sec HDFS Read: 12284 HDFS Write: 1438 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 10 seconds 260 msec
OK
Time taken: 24.358 seconds
hive> UPDATE test_transaction SET name='Richard'WHERE id=2;
Query ID = root_20201224175824_91acdbe9-5966-489c-beab-67b374fc6911
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
20/12/24 17:58:25 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm69
Starting Job = job_1608780340033_0009, Tracking URL = http://hp3:8088/proxy/application_1608780340033_0009/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1608780340033_0009
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 2
2020-12-24 17:58:32,217 Stage-1 map = 0%, reduce = 0%
2020-12-24 17:58:39,426 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 7.1 sec
2020-12-24 17:58:45,616 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 11.71 sec
MapReduce Total cumulative CPU time: 11 seconds 710 msec
Ended Job = job_1608780340033_0009
Loading data to table test.test_transaction
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 2 Cumulative CPU: 11.71 sec HDFS Read: 21436 HDFS Write: 770 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 710 msec
OK
Time taken: 23.475 seconds
hive>
> DELETE FROM test_transaction WHERE id=3;
Query ID = root_20201224175855_61fa8aaa-9db7-4f8d-87e9-31a0b4da835b
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
20/12/24 17:58:55 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm69
Starting Job = job_1608780340033_0010, Tracking URL = http://hp3:8088/proxy/application_1608780340033_0010/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1608780340033_0010
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 2
2020-12-24 17:59:01,750 Stage-1 map = 0%, reduce = 0%
2020-12-24 17:59:09,985 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 7.04 sec
2020-12-24 17:59:16,140 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 11.83 sec
MapReduce Total cumulative CPU time: 11 seconds 830 msec
Ended Job = job_1608780340033_0010
Loading data to table test.test_transaction
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 2 Cumulative CPU: 11.83 sec HDFS Read: 21690 HDFS Write: 641 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 830 msec
OK
Time taken: 22.25 seconds
hive>
二.Hive on Tez
Hive 支持多引擎
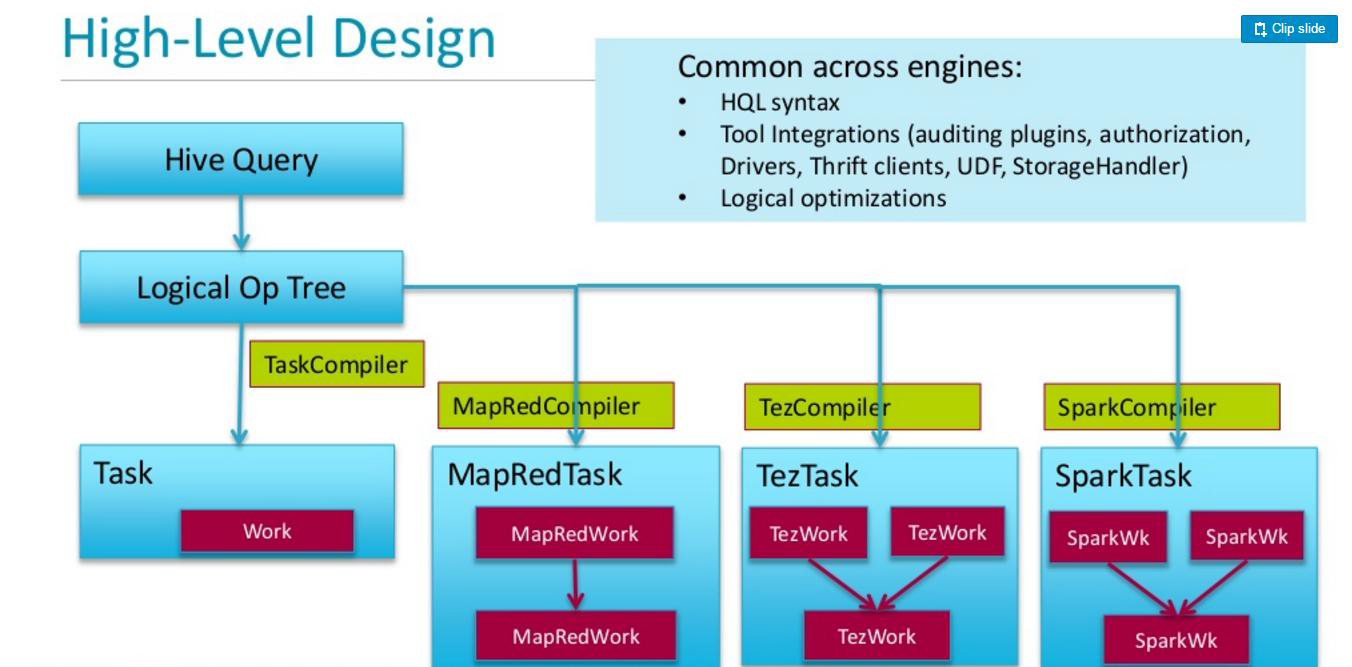
Tez是一種支持DAG作業的開源計算框架,它可以將多個有依賴的作業轉換為一個作業從而大幅提升DAG作業的性能
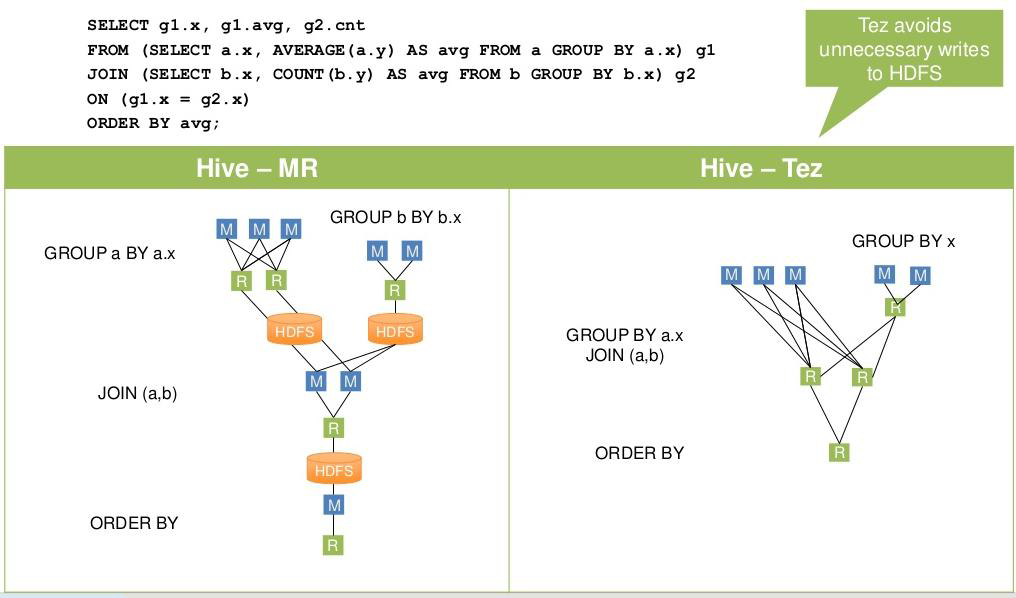
CDH版本不支持 Hive on Tez,此處略過
三. Hive on Spark
Spark發源于美國加州大學伯克利分校AMPLab實驗室,2010年貢獻給Apache
克服了MapReduce在迭代計算和互動式計算方面的不足,引入RDD的資料模型
相對于MapReduce,充分利用記憶體,獲得更高的計算效率
Hive on Spark:
1) 利用Hive的架構不變,引入Spark執行引擎,提供用戶選擇(mr/tez/spark),提升計算效率
2) 官方檔案:https://issues.apache.org/jira/browse/HIVE-7292
MapReduce
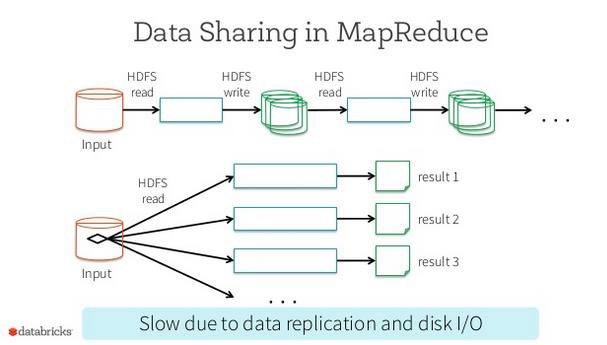
Spark
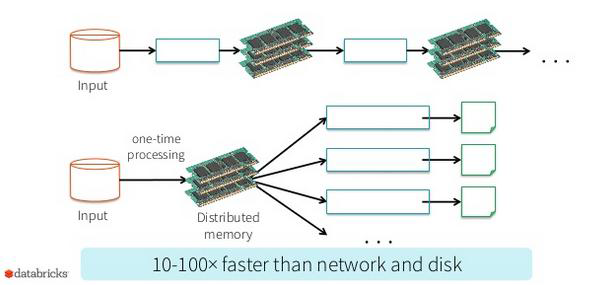
優勢:
- HQL不需要做任何變動,無縫的提供了另一種執行引擎支持
- 有利于與Spark的其他模塊如Mllib/Spark Streaming/GragphX等結合
- 提升了執行效率
如何使用?
set hive.execution.engine=spark; //使用Spark作為執行引擎
Spark Job優化:
spark.master默認提交到YARN
spark.executor.memory
spark.executor.cores
spark.yarn.executor.memoryOverhead
spark.executor.instances
Hive on Spark 運行效率是mr的10倍
-- mr執行
hive>
> select count(*) from ods_fact_sale;
Query ID = root_20201218100909_81d39c2b-0da0-40a1-8988-790040e4e3e1
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1606698967173_0319, Tracking URL = http://hp1:8088/proxy/application_1606698967173_0319/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1606698967173_0319
Hadoop job information for Stage-1: number of mappers: 117; number of reducers: 1
2020-12-18 10:09:18,279 Stage-1 map = 0%, reduce = 0%
2020-12-18 10:09:27,606 Stage-1 map = 2%, reduce = 0%, Cumulative CPU 12.98 sec
2020-12-18 10:09:33,807 Stage-1 map = 3%, reduce = 0%, Cumulative CPU 24.95 sec
2020-12-18 10:09:39,986 Stage-1 map = 5%, reduce = 0%, Cumulative CPU 36.98 sec
2020-12-18 10:09:47,189 Stage-1 map = 7%, reduce = 0%, Cumulative CPU 48.99 sec
2020-12-18 10:09:52,333 Stage-1 map = 8%, reduce = 0%, Cumulative CPU 54.86 sec
2020-12-18 10:09:53,363 Stage-1 map = 9%, reduce = 0%, Cumulative CPU 60.81 sec
2020-12-18 10:09:59,541 Stage-1 map = 10%, reduce = 0%, Cumulative CPU 72.62 sec
2020-12-18 10:10:04,686 Stage-1 map = 11%, reduce = 0%, Cumulative CPU 78.52 sec
2020-12-18 10:10:05,716 Stage-1 map = 12%, reduce = 0%, Cumulative CPU 84.34 sec
2020-12-18 10:10:10,876 Stage-1 map = 13%, reduce = 0%, Cumulative CPU 90.17 sec
2020-12-18 10:10:11,908 Stage-1 map = 14%, reduce = 0%, Cumulative CPU 95.94 sec
2020-12-18 10:10:17,039 Stage-1 map = 15%, reduce = 0%, Cumulative CPU 101.68 sec
2020-12-18 10:10:23,196 Stage-1 map = 16%, reduce = 0%, Cumulative CPU 113.41 sec
2020-12-18 10:10:24,222 Stage-1 map = 17%, reduce = 0%, Cumulative CPU 119.28 sec
2020-12-18 10:10:28,330 Stage-1 map = 18%, reduce = 0%, Cumulative CPU 125.11 sec
2020-12-18 10:10:29,359 Stage-1 map = 19%, reduce = 0%, Cumulative CPU 130.83 sec
2020-12-18 10:10:34,481 Stage-1 map = 20%, reduce = 0%, Cumulative CPU 136.61 sec
2020-12-18 10:10:35,508 Stage-1 map = 21%, reduce = 0%, Cumulative CPU 142.41 sec
2020-12-18 10:10:41,665 Stage-1 map = 22%, reduce = 0%, Cumulative CPU 154.2 sec
2020-12-18 10:10:46,799 Stage-1 map = 23%, reduce = 0%, Cumulative CPU 159.98 sec
2020-12-18 10:10:47,822 Stage-1 map = 24%, reduce = 0%, Cumulative CPU 165.81 sec
2020-12-18 10:10:52,947 Stage-1 map = 25%, reduce = 0%, Cumulative CPU 171.61 sec
2020-12-18 10:10:53,974 Stage-1 map = 26%, reduce = 0%, Cumulative CPU 177.25 sec
2020-12-18 10:11:00,121 Stage-1 map = 27%, reduce = 0%, Cumulative CPU 188.91 sec
2020-12-18 10:11:05,240 Stage-1 map = 28%, reduce = 0%, Cumulative CPU 194.73 sec
2020-12-18 10:11:06,265 Stage-1 map = 29%, reduce = 0%, Cumulative CPU 200.57 sec
2020-12-18 10:11:11,391 Stage-1 map = 31%, reduce = 0%, Cumulative CPU 212.26 sec
2020-12-18 10:11:16,511 Stage-1 map = 32%, reduce = 0%, Cumulative CPU 218.19 sec
2020-12-18 10:11:22,652 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 229.83 sec
2020-12-18 10:11:23,676 Stage-1 map = 34%, reduce = 0%, Cumulative CPU 235.64 sec
2020-12-18 10:11:28,795 Stage-1 map = 35%, reduce = 0%, Cumulative CPU 241.55 sec
2020-12-18 10:11:29,819 Stage-1 map = 36%, reduce = 0%, Cumulative CPU 247.31 sec
2020-12-18 10:11:34,933 Stage-1 map = 37%, reduce = 0%, Cumulative CPU 253.12 sec
2020-12-18 10:11:36,979 Stage-1 map = 38%, reduce = 0%, Cumulative CPU 258.87 sec
2020-12-18 10:11:43,128 Stage-1 map = 39%, reduce = 0%, Cumulative CPU 270.73 sec
2020-12-18 10:11:47,224 Stage-1 map = 40%, reduce = 0%, Cumulative CPU 276.6 sec
2020-12-18 10:11:50,294 Stage-1 map = 41%, reduce = 0%, Cumulative CPU 282.38 sec
2020-12-18 10:11:54,390 Stage-1 map = 42%, reduce = 0%, Cumulative CPU 288.34 sec
2020-12-18 10:11:56,437 Stage-1 map = 43%, reduce = 0%, Cumulative CPU 294.18 sec
2020-12-18 10:12:00,533 Stage-1 map = 44%, reduce = 0%, Cumulative CPU 300.09 sec
2020-12-18 10:12:05,655 Stage-1 map = 45%, reduce = 0%, Cumulative CPU 311.75 sec
2020-12-18 10:12:07,703 Stage-1 map = 46%, reduce = 0%, Cumulative CPU 317.38 sec
2020-12-18 10:12:11,806 Stage-1 map = 47%, reduce = 0%, Cumulative CPU 323.19 sec
2020-12-18 10:12:13,854 Stage-1 map = 48%, reduce = 0%, Cumulative CPU 328.94 sec
2020-12-18 10:12:17,946 Stage-1 map = 49%, reduce = 0%, Cumulative CPU 334.82 sec
2020-12-18 10:12:19,994 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 340.55 sec
2020-12-18 10:12:26,146 Stage-1 map = 51%, reduce = 0%, Cumulative CPU 351.6 sec
2020-12-18 10:12:29,221 Stage-1 map = 52%, reduce = 0%, Cumulative CPU 357.31 sec
2020-12-18 10:12:33,314 Stage-1 map = 53%, reduce = 0%, Cumulative CPU 363.32 sec
2020-12-18 10:12:35,363 Stage-1 map = 54%, reduce = 0%, Cumulative CPU 369.29 sec
2020-12-18 10:12:39,454 Stage-1 map = 55%, reduce = 0%, Cumulative CPU 375.2 sec
2020-12-18 10:12:41,494 Stage-1 map = 56%, reduce = 0%, Cumulative CPU 381.08 sec
2020-12-18 10:12:47,644 Stage-1 map = 57%, reduce = 0%, Cumulative CPU 392.97 sec
2020-12-18 10:12:50,711 Stage-1 map = 58%, reduce = 0%, Cumulative CPU 398.84 sec
2020-12-18 10:12:53,784 Stage-1 map = 59%, reduce = 0%, Cumulative CPU 404.66 sec
2020-12-18 10:12:56,848 Stage-1 map = 60%, reduce = 0%, Cumulative CPU 410.55 sec
2020-12-18 10:12:58,898 Stage-1 map = 61%, reduce = 0%, Cumulative CPU 416.3 sec
2020-12-18 10:13:02,994 Stage-1 map = 62%, reduce = 0%, Cumulative CPU 422.16 sec
2020-12-18 10:13:09,141 Stage-1 map = 63%, reduce = 0%, Cumulative CPU 434.12 sec
2020-12-18 10:13:11,194 Stage-1 map = 64%, reduce = 0%, Cumulative CPU 440.01 sec
2020-12-18 10:13:15,299 Stage-1 map = 65%, reduce = 0%, Cumulative CPU 445.82 sec
2020-12-18 10:13:17,351 Stage-1 map = 66%, reduce = 0%, Cumulative CPU 451.66 sec
2020-12-18 10:13:21,451 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 457.44 sec
2020-12-18 10:13:23,504 Stage-1 map = 68%, reduce = 0%, Cumulative CPU 463.24 sec
2020-12-18 10:13:29,652 Stage-1 map = 69%, reduce = 0%, Cumulative CPU 474.77 sec
2020-12-18 10:13:33,752 Stage-1 map = 70%, reduce = 0%, Cumulative CPU 480.62 sec
2020-12-18 10:13:34,775 Stage-1 map = 71%, reduce = 0%, Cumulative CPU 486.3 sec
2020-12-18 10:13:39,912 Stage-1 map = 72%, reduce = 0%, Cumulative CPU 492.12 sec
2020-12-18 10:13:41,966 Stage-1 map = 73%, reduce = 0%, Cumulative CPU 498.08 sec
2020-12-18 10:13:45,043 Stage-1 map = 74%, reduce = 0%, Cumulative CPU 503.87 sec
2020-12-18 10:13:51,204 Stage-1 map = 75%, reduce = 0%, Cumulative CPU 515.12 sec
2020-12-18 10:13:54,282 Stage-1 map = 76%, reduce = 0%, Cumulative CPU 520.94 sec
2020-12-18 10:13:57,358 Stage-1 map = 77%, reduce = 0%, Cumulative CPU 526.82 sec
2020-12-18 10:14:00,430 Stage-1 map = 78%, reduce = 0%, Cumulative CPU 532.64 sec
2020-12-18 10:14:03,509 Stage-1 map = 79%, reduce = 0%, Cumulative CPU 538.41 sec
2020-12-18 10:14:09,659 Stage-1 map = 80%, reduce = 0%, Cumulative CPU 549.96 sec
2020-12-18 10:14:12,735 Stage-1 map = 81%, reduce = 0%, Cumulative CPU 555.69 sec
2020-12-18 10:14:15,817 Stage-1 map = 82%, reduce = 0%, Cumulative CPU 561.59 sec
2020-12-18 10:14:20,942 Stage-1 map = 83%, reduce = 0%, Cumulative CPU 567.48 sec
2020-12-18 10:14:27,127 Stage-1 map = 84%, reduce = 28%, Cumulative CPU 573.97 sec
2020-12-18 10:14:33,274 Stage-1 map = 85%, reduce = 28%, Cumulative CPU 579.95 sec
2020-12-18 10:14:45,558 Stage-1 map = 86%, reduce = 28%, Cumulative CPU 591.63 sec
2020-12-18 10:14:50,679 Stage-1 map = 86%, reduce = 29%, Cumulative CPU 591.72 sec
2020-12-18 10:14:51,704 Stage-1 map = 87%, reduce = 29%, Cumulative CPU 597.42 sec
2020-12-18 10:14:57,850 Stage-1 map = 88%, reduce = 29%, Cumulative CPU 603.15 sec
2020-12-18 10:15:04,001 Stage-1 map = 89%, reduce = 29%, Cumulative CPU 609.1 sec
2020-12-18 10:15:09,118 Stage-1 map = 90%, reduce = 30%, Cumulative CPU 614.94 sec
2020-12-18 10:15:15,266 Stage-1 map = 91%, reduce = 30%, Cumulative CPU 620.71 sec
2020-12-18 10:15:27,555 Stage-1 map = 92%, reduce = 30%, Cumulative CPU 632.32 sec
2020-12-18 10:15:33,697 Stage-1 map = 93%, reduce = 31%, Cumulative CPU 638.27 sec
2020-12-18 10:15:40,849 Stage-1 map = 94%, reduce = 31%, Cumulative CPU 644.15 sec
2020-12-18 10:15:46,996 Stage-1 map = 95%, reduce = 31%, Cumulative CPU 650.08 sec
2020-12-18 10:15:51,090 Stage-1 map = 95%, reduce = 32%, Cumulative CPU 650.12 sec
2020-12-18 10:15:52,109 Stage-1 map = 96%, reduce = 32%, Cumulative CPU 655.98 sec
2020-12-18 10:15:58,259 Stage-1 map = 97%, reduce = 32%, Cumulative CPU 661.66 sec
2020-12-18 10:16:10,547 Stage-1 map = 98%, reduce = 32%, Cumulative CPU 673.09 sec
2020-12-18 10:16:15,660 Stage-1 map = 98%, reduce = 33%, Cumulative CPU 673.15 sec
2020-12-18 10:16:16,685 Stage-1 map = 99%, reduce = 33%, Cumulative CPU 678.98 sec
2020-12-18 10:16:22,828 Stage-1 map = 100%, reduce = 33%, Cumulative CPU 684.83 sec
2020-12-18 10:16:23,855 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 686.77 sec
MapReduce Total cumulative CPU time: 11 minutes 26 seconds 770 msec
Ended Job = job_1606698967173_0319
MapReduce Jobs Launched:
Stage-Stage-1: Map: 117 Reduce: 1 Cumulative CPU: 686.77 sec HDFS Read: 31436878698 HDFS Write: 109 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 11 minutes 26 seconds 770 msec
OK
767830000
Time taken: 435.425 seconds, Fetched: 1 row(s)
hive> exit;
-- 調整執行引擎為 spark執行
hive> select count(*) from ods_fact_sale;
Query ID = root_20201218102616_475f2d81-1430-4ad4-83c9-8f447a66476a
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Running with YARN Application = application_1606698967173_0320
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/yarn application -kill application_1606698967173_0320
Hive on Spark Session Web UI URL: http://hp3:39738
Query Hive on Spark job[0] stages: [0, 1]
Spark job[0] status = RUNNING
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-0 ........ 0 FINISHED 117 117 0 0 0
Stage-1 ........ 0 FINISHED 1 1 0 0 0
--------------------------------------------------------------------------------------
STAGES: 02/02 [==========================>>] 100% ELAPSED TIME: 50.34 s
--------------------------------------------------------------------------------------
Spark job[0] finished successfully in 50.34 second(s)
Spark Job[0] Metrics: TaskDurationTime: 306308, ExecutorCpuTime: 239414, JvmGCTime: 5046, BytesRead / RecordsRead: 31436886423 / 767830000, BytesReadEC: 0, ShuffleTotalBytesRead / ShuffleRecordsRead: 6669 / 117, ShuffleBytesWritten / ShuffleRecordsWritten: 6669 / 117
OK
767830000
Time taken: 68.884 seconds, Fetched: 1 row(s)
hive>
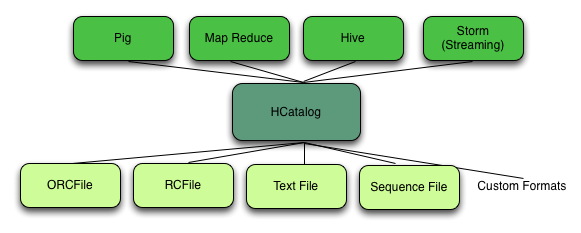
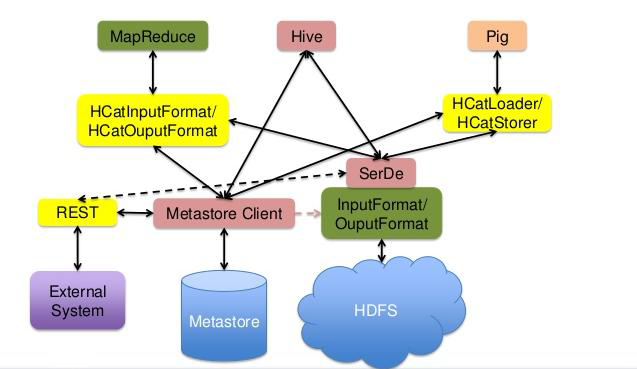
四.HCatalog
HCatalog是Hadoop的元資料和資料表的管理系統,它基于Hive中的元資料層,通過類似SQL的語言展現Hadoop資料的關聯關系,
HCatalog允許用戶通過Hive,Pig,MapReduce共享資料和元資料,在用戶撰寫應用程式時,無需關心資料怎么存盤,在哪里存盤,避免用戶因schema和存盤格式的改變而受到影響,
通過HCatalog,用戶能夠通過工具訪問Hadoop上的Hive metastore,它為MapReduce和Pig提供了連接器,用戶可以使用工具對Hive的關聯列格式的資料進行讀寫,
HCatalog架構圖:
參考
1.https://cwiki.apache.org/confluence/display/Hive/Hive+on+Spark%3A+Getting+Started (hive on spark)
2.https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/admin_hive_configure.html#xd_583c10bfdbd326ba-590cb1d1-149e9ca9886–7b23 (Cloudera 上調整執行引擎為spark)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/250659.html
標籤:其他
上一篇:大資料計算系統學習筆記