作者:Redflashing
本文梳理舉例總結深度學習中所遇到的各種卷積,幫助大家更為深刻理解和構建卷積神經網路,
本文將詳細介紹以下卷積概念:
- 2D卷積(2D Convolution)
- 3D卷積(3D Convolution)
- 1 ? 1 1*1 1?1卷積( 1 ? 1 1*1 1?1 Convolution)
- 反卷積(轉置卷積)(Transposed Convolution)
- 擴張卷積(Dilated Convolution / Atrous Convolution)
- 空間可分卷積(Spatially Separable Convolution)
- 深度可分卷積(Depthwise Separable Convolution)
- 平展卷積(Flattened Convolution)
- 分組卷積(Grouped Convolution)
- 混洗分組卷積(Shuffled Grouped Convolution)
- 逐點分組卷積(Pointwise Grouped Convolution)
9. 分組卷積
? 首次在大規模影像資料集(ImageNet)實作了深層卷積神經網路結構,引發深度學習熱潮的AlexNet 論文(https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)在 2012 年引入了分組卷積,實作分組卷積的主要原因是讓網路訓練可在 2 個記憶體有限(每個 GPU 有 1.5 GB 記憶體)的 GPU 上進行,下面的 AlexNet 表明在大多數層中都有兩個分開的卷積路徑,這是在兩個 GPU 上執行模型并行化(當然如果可以使用更多 GPU,還能執行多 GPU 并行化),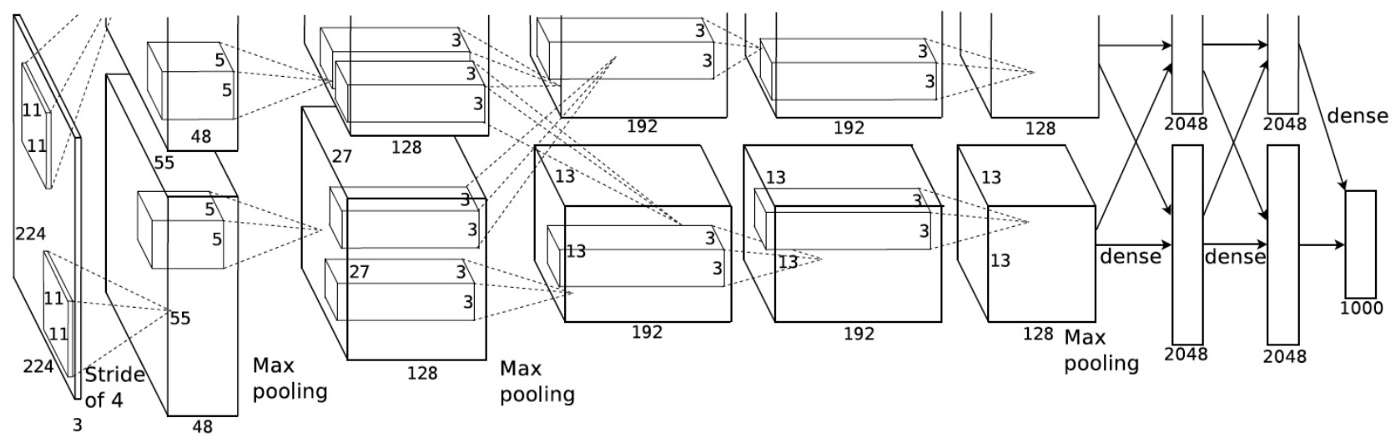
? 這里我們介紹一下分組卷積的作業方式,首先典型的2D卷積步驟如下圖所示,在該例子中通過應用128個大小為
3
?
3
?
3
3*3*3
3?3?3的濾波器將輸入層(
7
?
7
?
3
7*7*3
7?7?3)變換到輸出層(
5
?
5
?
128
5*5*128
5?5?128),推廣而言,即通過
D
o
u
t
D_{out}
Dout?個大小為
h
?
w
?
D
i
n
h*w*D_{in}
h?w?Din?的濾波器將輸入層(
H
i
n
?
W
i
n
?
D
i
n
H_{in}*W_{in}*D_{in}
Hin??Win??Din?)變換到輸出層(
H
o
u
t
?
W
o
u
t
?
D
o
u
t
H_{out}*W_{out}*D_{out}
Hout??Wout??Dout?),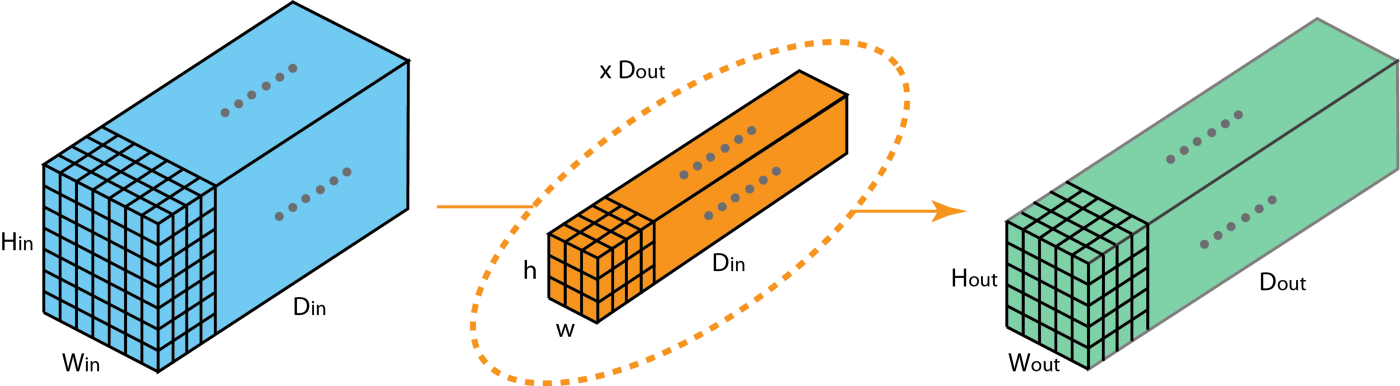
? 而在分組卷積中,濾波器被分成不同的組,每個組負責具有一定深度的2D卷積,下圖展示了具有兩個濾波器分組的分組卷積,在每個濾波器組中,每個濾波器只有原2D卷積的一半數目,它們的深度是
D
i
n
2
\frac{D_{in}}{2}
2Din??個濾波器,第一個濾波器分組(紅色)與輸入層的前一半(按深度分半,即
[
:
,
:
,
0
:
D
o
u
t
2
]
[:,:,0:\frac{D_{out}}{2}]
[:,:,0:2Dout??])進行卷積操作,因此,每個濾波器分組都會創建
D
o
u
t
2
\frac{D_{out}}{2}
2Dout??個通道,整體而言,兩個分組會創建
2
?
D
o
u
t
2
=
D
o
u
t
2*\frac{D_{out}}{2}=D_{out}
2?2Dout??=Dout?個通道,然后我們將這些通道堆疊在一起得到有
D
o
u
t
D_{out}
Dout?個通道的輸出層,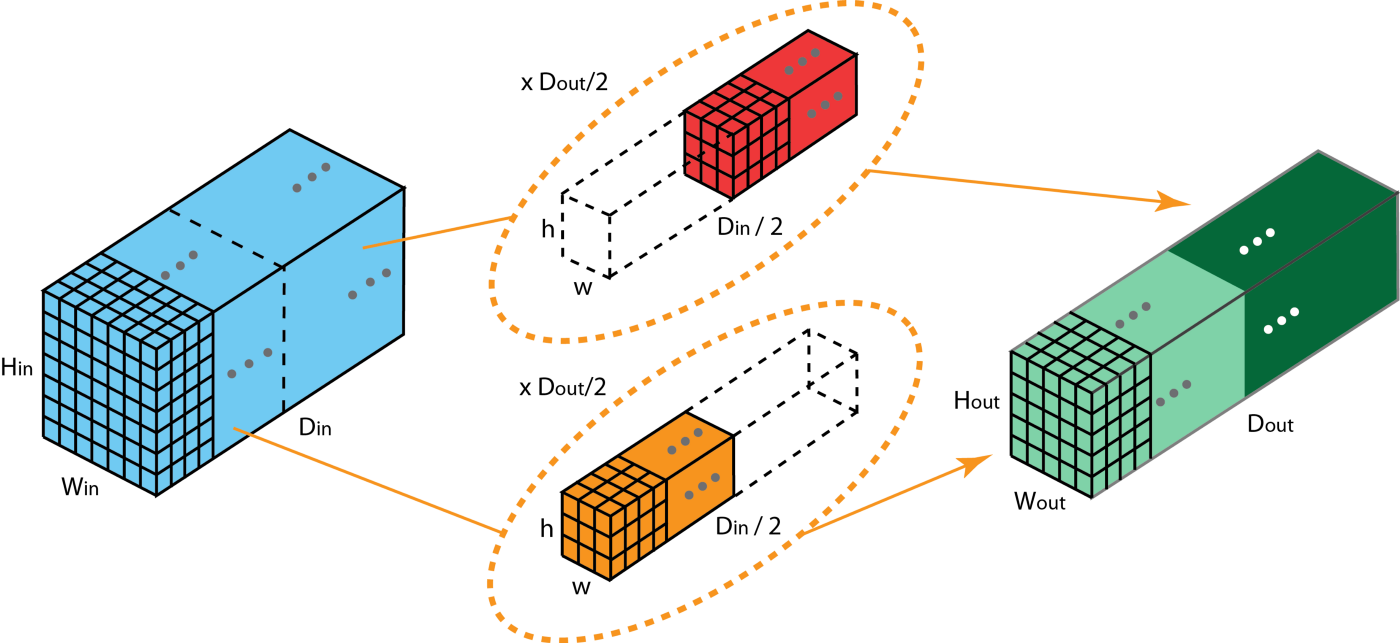
9.1. 分組卷積與深度可分卷積比較
? 從上面的例子已經可以發現分組卷積和深度可分卷積之間的聯系和差異,如果濾波器組的數量和輸入層通道數相同,則每個濾波器的深度都為1,這與深度可分卷積相同,另一方面,每個濾波器組都包含 D o u t D i n \frac{D_{out}}{D_{in}} Din?Dout??個濾波器,整體而言,輸出層的深度為 D o u t D_{out} Dout?,這不同于深度可分卷積的情況–深度卷積的第一個步驟并不會改變層的深度,深度可分卷積的深度通過 1 ? 1 1*1 1?1卷積進行深度的擴展,
9.2. 分組卷積的優點
-
高效訓練
? 由于卷積可分為多個路徑,因此每個路徑可以由不同的GPU進行處理,此程序允許以并行的方式對多個GPU進行模型訓練,這種基于多GPU的模型并行化允許網路在每個步驟處理更多影像,一般認為模型并行化比資料并行化效果更好,后者將資料集分成多個批次(Batch),然后分開訓練每一批次,但是當批次大小過小時,本質上執行的是隨機梯度下降,而非批梯度下降,這會造成收斂速度緩慢切收斂結果更差,
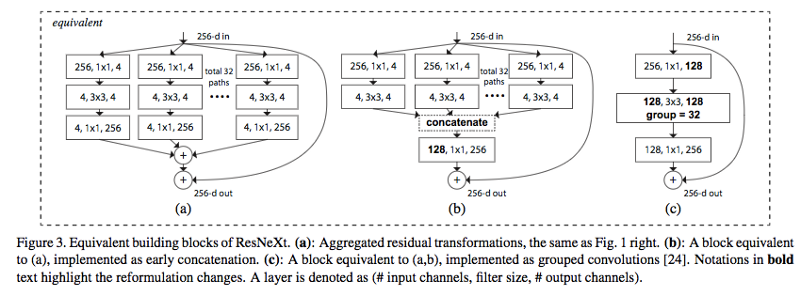
? 在訓練非常深的神經網路時,分組卷積會非常重要,正如下圖ResNeXt中那樣,圖片來自論文(https://arxiv.org/abs/1611.05431)
-
高效模型
? 即模型引數隨著濾波器組的數量的增加而減少,在前面的示例中,濾波器在標準2D卷積中引數量為: h ? w ? D i n ? D o u t h*w*D_{in}*D_{out} h?w?Din??Dout?,而具有2個濾波器組的分組卷積的引數量為: ( h ? w ? D i n 2 ? D o u t 2 ) ? 2 (h*w*\frac{D_{in}}{2}*\frac{D_{out}}{2})*2 (h?w?2Din???2Dout??)?2,引數量減少了一半,
-
模型性能更優
? 這有一點讓人驚訝,分組卷積在某些情況下能提供比標準2D卷積更好的模型,這在文章(https://blog.yani.io/filter-group-tutorial/)有很好地解釋,這里僅做簡要的分析,
? 原因主要和稀疏濾波器(稀疏矩陣)有關,下圖是相鄰層濾波器的相關性,為稀疏關系,圖為在 CIFAR10 上訓練的一個 Network-in-Network 模型中相鄰層的過濾器的相關性矩陣,高度相關的過濾器對更明亮,而相關性更低的過濾器則更暗,圖片來自:https://blog.yani.io/filter-group-tutorial

但當我們用分組卷積后,神奇的事情發生了

? 上圖是當用 1、2、4、8、16 個過濾器分組訓練模型時,相鄰層的濾波器之間的相關性,那篇文章提出了一個可能的解釋:濾波器分組的效果是在通道維度上學習塊對角結構的稀疏性……在網路中,具有高相關性的過濾器是使用過濾器分組以一種更為結構化的方式學習到,從效果上看,不必學習的過濾器關系就不再引數化,這樣顯著地減少網路中的引數數量能使其不容易過擬合,因此,一種類似正則化的效果讓優化器可以學習得到更準確更高效的深度網路,

? 上圖是AlexNet中Conv1濾波器分解:正如作者指出的那樣,過濾器分組似憾訓將學習到的過濾器結構性地組織成兩個不同的分組,圖片來自 AlexNet 論文(https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf),
? 此外,每個濾波器分組都會學習資料的一個獨特表征,正如 AlexNet 的作者指出的那樣,濾波器分組似憾訓將學習到的過濾器結構性地組織成兩個不同的分組——黑白過濾器和彩色過濾器,
9.3. 混洗分組卷積(Shuffled Grouped Convolution)
? 混洗分組卷積由曠視(Face++)團隊在ShuffleNet(https://arxiv.org/abs/1707.01083)首次提出,ShuffleNet是一種計算效率非常高的卷積結構,專門為計算能力非常有限的移動設備(10-150MFLOP)而設計,
? 混洗分組卷積背后的思想與分組卷積背后的理念(用于 MobileNet和ResNeXt示例)和深度可分卷積(在Xception 中使用),總體而言,隨機分組卷積涉及分組卷積和通道混洗,
? 在有關分組卷積的部分中,我們知道濾波器被分成不同的組,每個組負責具有一定深度的傳統 2D 卷積,總的計算量顯著減少,對于下圖中的示例,我們有 3 個濾波器組,第一個濾波器組與輸入層中的紅色部分進行卷積操作,同樣,第二個和第三個濾波器組與輸入中的綠色和藍色部分進行卷積操作,每個濾波器組中的卷積核深度僅占輸入層中總通道計數的
1
3
\frac{1}{3}
31?,在此示例中,在第一個分組卷積 GConv1 之后,輸入圖層映射再通過中間層(下文針對該部分進行講解),然后,通過第二個分組卷積 GConv2 映射到輸出圖層,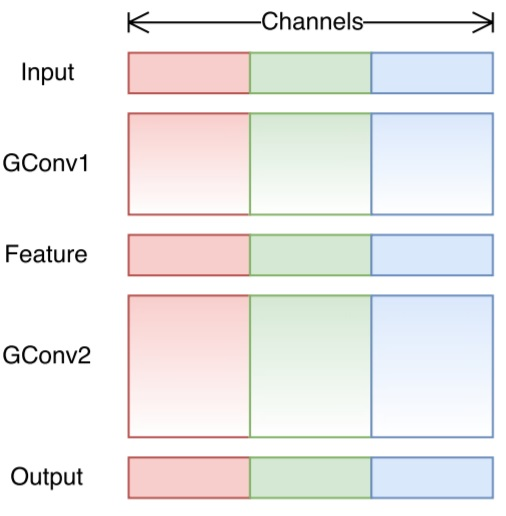
? 分組卷積在計算上是有效的,但問題是,每個濾波器組只處理從輸入層中的固定部分傳遞的資訊,對于上圖中的示例,第一個濾波器組(紅色)僅處理從輸入通道前 1/3 傳遞的資訊,藍色濾波器組(藍色)僅處理從輸入通道的最后 1/3 傳遞的資訊,因此,每個濾波器組都僅限于學習一些特定功能,這一特性阻止通道組之間的資訊流,并在訓練期間削弱了模型表現力,為了克服此問題,ShuffleNet 中引入了通道混洗(Channel Shuffle), 用來進行不同分組的特征之間的資訊流動, 以提高性能.,
? 通道混洗操作(Channel Shuffle Operation)的想法是,我們希望混合來自不同篩選器組的資訊,在下圖中,我們使用 3 個濾波器組應用第一個分組卷積 GConv1 后獲取特征,在將結果輸入到第二個分組卷積之前,我們首先將每個組中的通道劃分為多個子組,我們混洗了這些子組,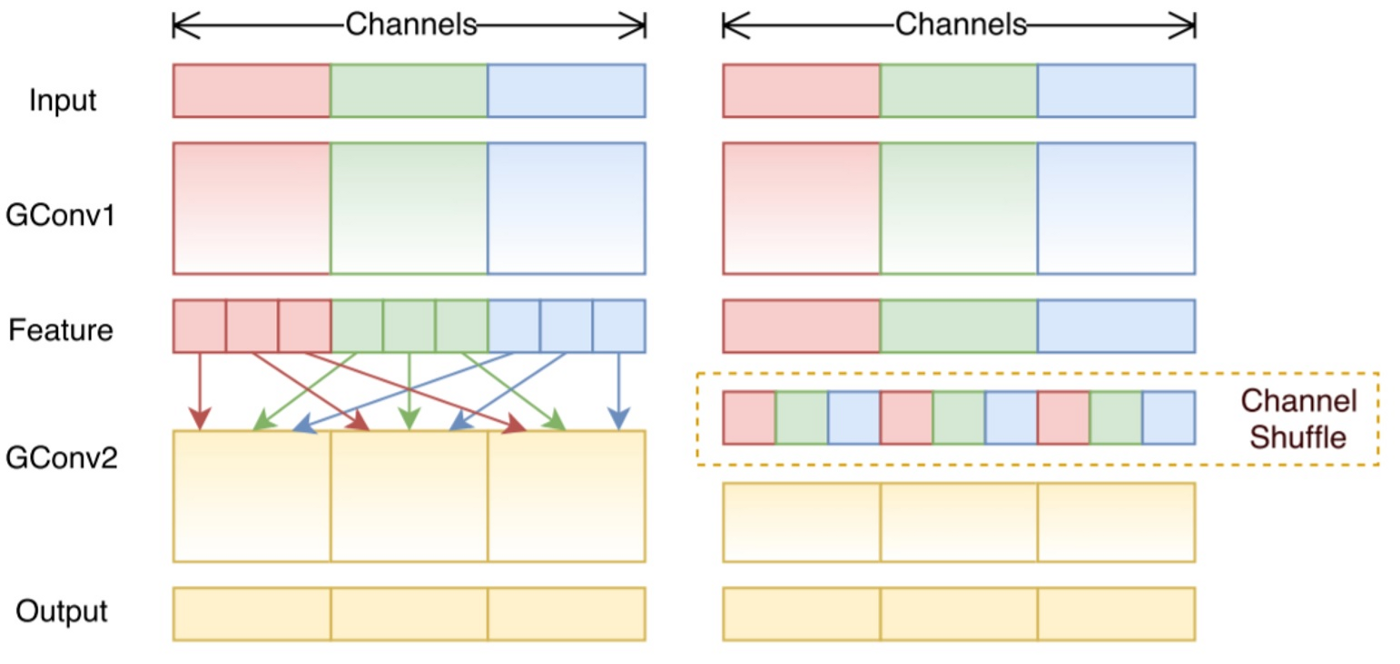
? 在進行這樣的洗牌之后,我們繼續一樣執行第二組卷積 GConv2,但現在,由于經過混洗后資訊已經混合,因此,通過允許通道之間的資訊交換,增強了模型的表現力,
9.4. 逐點分組卷積(Pointwise Grouped Convolution)
? ShuffleNet 也引入了組點分組卷積.通常對于分組卷積(如 MobileNet或 ResNeXt,組操作在 3 ? 3 3*3 3?3空間卷積上執行,但在 1 ? 1 1*1 1?1卷積上不執行,
? ShuffleNet論文認為, 1 ? 1 1*1 1?1卷積在計算上也是昂貴的,并建議在 1 ? 1 1*1 1?1卷積上也應用分組卷積,顧名思義,逐點分組卷積執行 1 ? 1 1*1 1?1卷積的組操作,該操作與分組卷積相同,只有一個修改在 1 ? 1 1*1 1?1篩選器上執行,而不是 n ? n n*n n?n濾波器 ( n > 1 n>1 n>1),
? 在ShuffleNet的論文中,作者利用了三種型別的卷積:(1) 混洗分組卷積;(2) 逐點分組卷積;和 (3) 深度可分卷積,這種架構設計在保持精度的同時顯著降低了計算成本,例如,ShuffleNet 和 AlexNet 的分類錯誤在實際移動設備上是可比的,但是,計算成本已大幅降低,從 AlexNet 中的 720 MFLOP 減少到 ShuffleNet 中的 40~140 MFLOP,由于計算成本相對較低,模型性能好,ShuffleNet在移動設備卷積神經網領域越來越受歡迎,
參考資料
-
A Comprehensive Introduction to Different Types of Convolutions in Deep Learning | by Kunlun Bai | Towards Data Science
-
Convolutional neural network - Wikipedia
-
Convolution - Wikipedia
-
一文讀懂卷積神經網路中的1x1卷積核 - 知乎 (zhihu.com)
-
[1312.4400] Network In Network (arxiv.org)
-
Inception網路模型 - 啊順 - 博客園 (cnblogs.com)
-
ResNet決議_lanran2的博客-CSDN博客
-
一文帶你了解深度學習中的各種卷積(上) | 機器之心 (jiqizhixin.com)
-
Intuitively Understanding Convolutions for Deep Learning | by Irhum Shafkat | Towards Data Science
-
An Introduction to different Types of Convolutions in Deep Learning
-
Review: DilatedNet — Dilated Convolution (Semantic Segmentation)
-
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
-
Separable convolutions “A Basic Introduction to Separable Convolutions
-
Inception network “A Simple Guide to the Versions of the Inception Network”
-
A Tutorial on Filter Groups (Grouped Convolution)
-
Convolution arithmetic animation
-
Up-sampling with Transposed Convolution
-
Intuitively Understanding Convolutions for Deep Learning
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/252110.html
標籤:其他
下一篇:淺談用戶中心-資料庫設計