文章目錄
- 前言
- 一、網路結構
- 二、后處理演算法(漸進式擴展演算法)
- 三、標簽的生成
- 四、損失函式 loss
- 五、OHEM 演算法的思想
- 六、訓練自己的資料集
- 6.1 資料準備
- 6.2 資料增強
- 6.3 pse_general 引數設定
- 6.4 issue
前言
論文: Shape Robust Text Detection with Progressive Scale Expansion Network
代碼: https://github.com/whai362/PSENet
- 自然場景的文本檢測是當前深度學習的重要應用,在之前的文章中已經介紹了基于深度學習的文本檢測模型 CTPN、CRAFT、Seglink、EAST(見文章:『OCR_detection』CTPN、『OCR_detection』CRAFT、『OCR_detection』Seglink、『OCR_detection』EAST),
- 形狀魯棒性文本檢測面臨的挑戰主要有兩個方面:1)現有的基于四邊形邊界盒的文本檢測方法很難找到任意形狀的文本,很難完全封閉在矩形中;2)大多數基于像素的分割檢測器可能不會將彼此非常接近的文本實體分開,為了解決這些問題,我們提出了一種新的漸進尺度擴展網路(PSEnet),它是一種基于分割的檢測器,對每個文本實體都有多個預測,這些預測對應于通過將原始文本實體縮小到不同的尺度而產生的不同的“內核”,因此,最終的檢測可以通過我們的漸進尺度擴展演算法進行,該演算法將最小尺度的核逐步擴展到最大和完全形狀的文本實體,由于這些極小核間存在較大的幾何邊緣,因此我們的方法能夠有效地區分相鄰文本實體,并且對任意形狀具有魯棒性,
一、網路結構
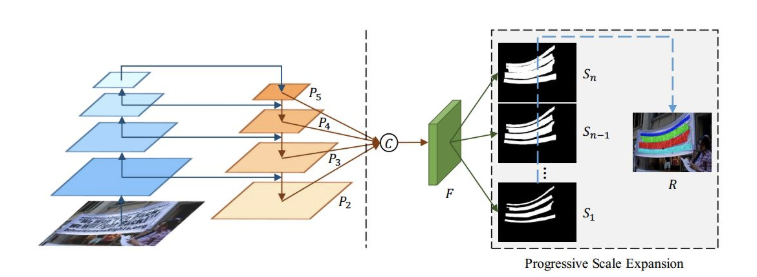
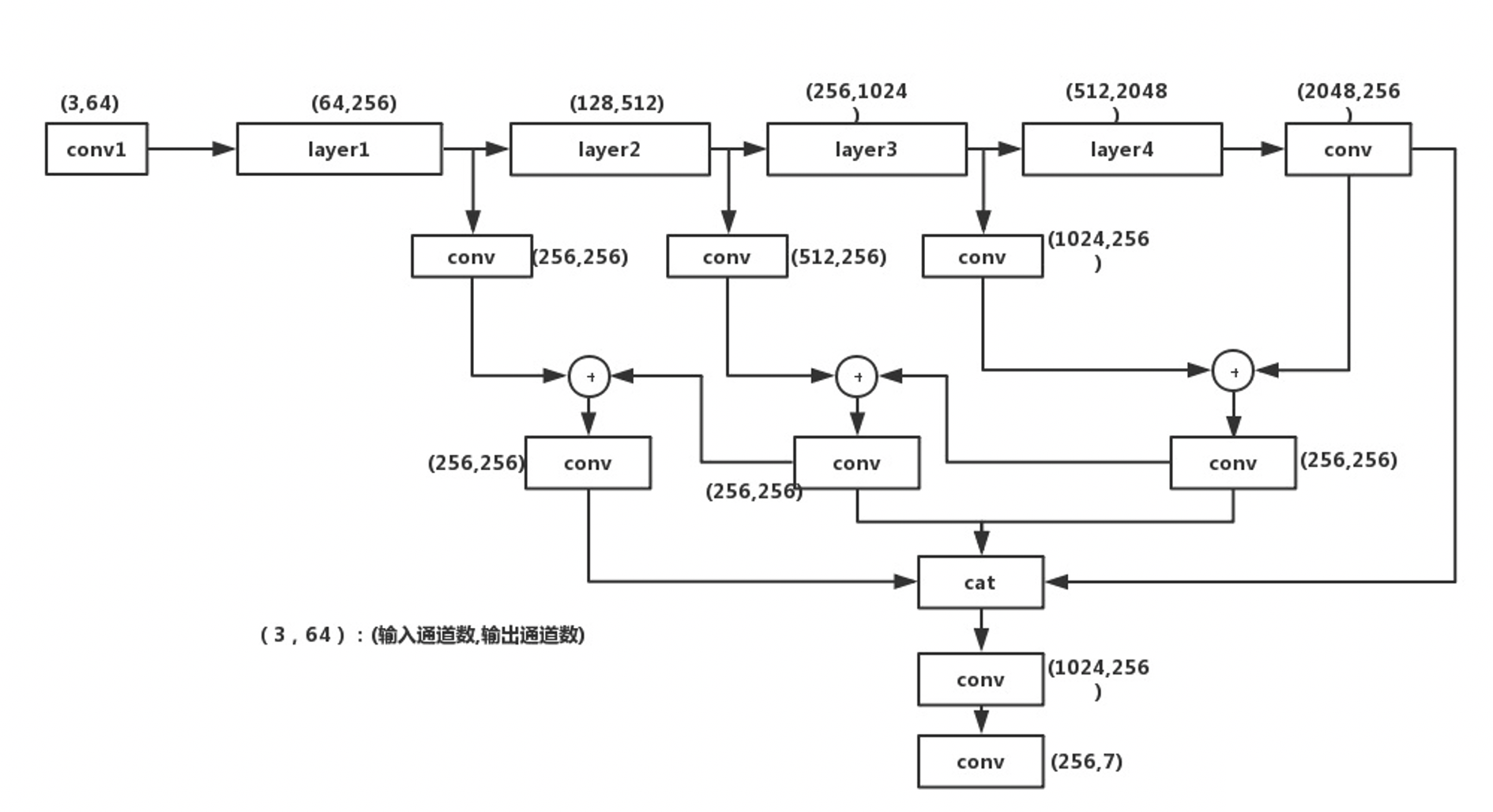
在 ImageNet 資料集上預訓練的 ResNet+FPN 作為特征提取的網路結構,
- 首先,將高層特征和低層特征 融合 后得到 (P2, P3, P4, P5) 四個特征層,其中每個特征層的 channel 數量為 256,
- 之后,將四個特征層 concat 得到 F (將低層次的特征和高層次的分割實體特征進行融合,最后得到與原圖尺寸相同的輸出 F), 其中 F = C(P2,P3,P4,P5) = P2 || Upx2(P3) || Upx4(P4) || Upx8(P5) ,其中的 || 就代表 concat,
x2,x4,x8分別代表 2 倍、4 倍和 8 倍的上采樣,F 的維度大小為 [ B, C, H, W ],其中 C 的大小為確定的 kernel_num, 將 F 送入Conv(3,3)-BN-ReLU層,并將特征層的 channel 數量變為 256,- 最后,將 F 送入多個
Conv(1,1)-Up-Sigmod層來得到 n 個分割結果 S 1 , S 2 , … , S n S_1,S_2,…,S_n S1?,S2?,…,Sn?,其中的 Up 代表上采樣,sigmoid 來預測 n 個 mask
注: S 1 , S 2 , S 3 , ? , S n S_1,S_2,S_3,?,S_n S1?,S2?,S3?,?,Sn? 是影像文字的分割結果,他們的不同點在于他們分割出的文字區域大小不同,例如 S1 給出的是最小的文字區域分割結果, 是預測的圖片中目標文字的核心區域(并不是全部范圍),而 Sn 給出的是最大的文字區域分割結果(理想下就是 GroundTruth)
二、后處理演算法(漸進式擴展演算法)
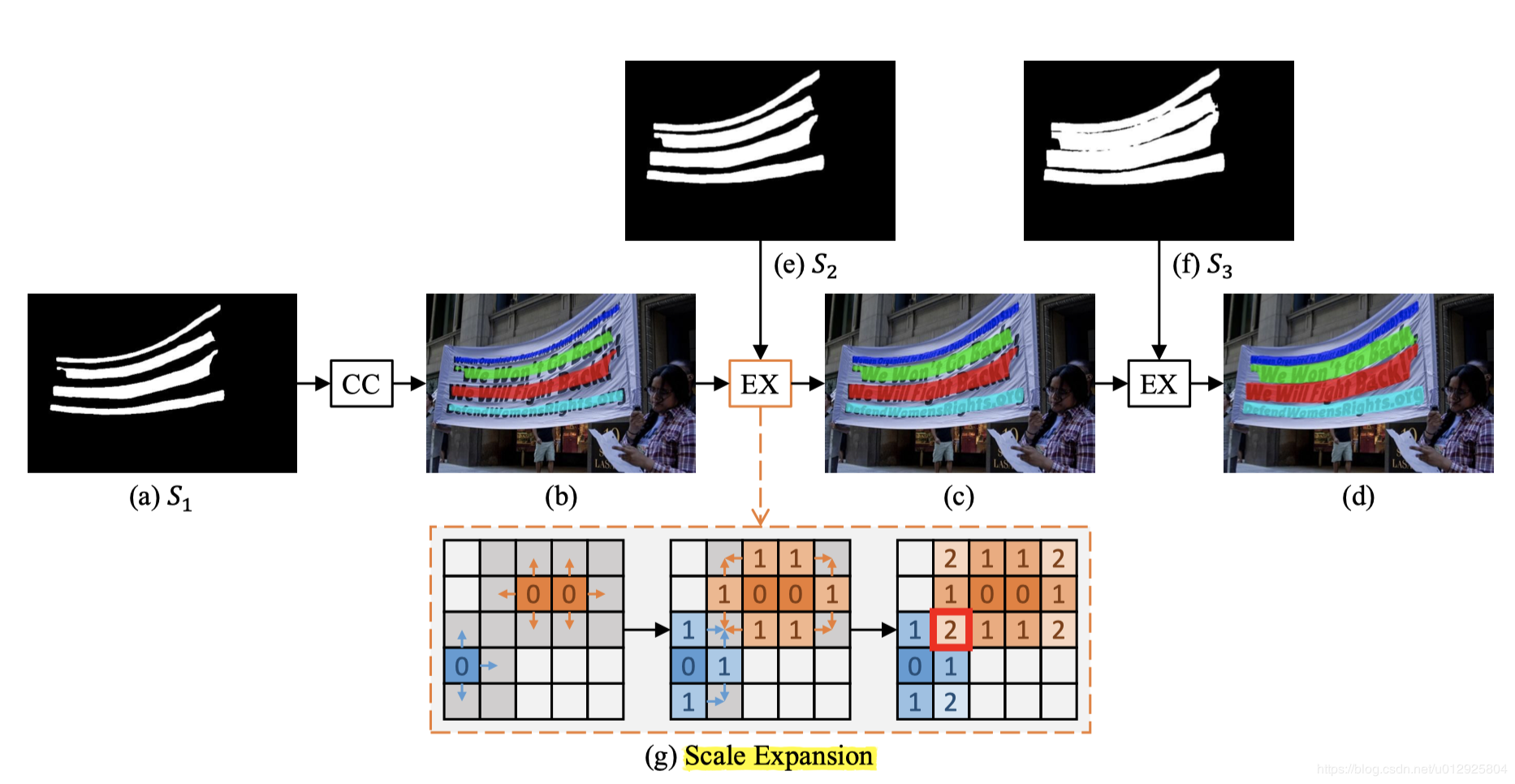
- 實際文章中 n=6,但是為了更方便解釋,這里假設 n=3,即網路最終輸出了 3 張分割結果
- 假設用了 3 個不同尺度的 kernel(如圖a,e,f),其中 S 1 S_1 S1? (上圖a)代表最小 kernel 的分割結果,它內部有四個連通域
C={c1,c2,c3,c4},CC 操作得到 S1 中的四個連通域,得圖 b(四個連通區域使用不同顏色標記),- 現在我們已經得到了圖 b 中的四個連通域(小 kernel,不同文本行之間的 margin 很大,很容易區分開),且我們已知 S 2 S_2 S2? 中的 kernel 是比 S 1 S_1 S1? 中的 kernel 大的,也就是可以說 S 2 S_2 S2? 中的 kernel 是包含 S 1 S_1 S1? 中的 kernel 的,現在我們的任務就是將屬于 S 2 S_2 S2? 中的 kernel 的但不屬于 S 1 S_1 S1? 中的 kernel 的像素點(即圖 g 左圖中的灰色的部分,藍色和橘色部分分別表示 S 1 S_1 S1? 中的兩個連通域)進行分配,
- 如圖所示,在灰色區域( S 2 S_2 S2? 的 kernel 范圍)內,將 b 圖所找到的連通域的每個 pixel 以
BFS的方式,逐個向上下左右擴展,即相當于把 S 1 S_1 S1? 中預測的文本行的區域逐漸變寬(或者換種說法:對于 S 2 S_2 S2? 中 kernel 的每個像素點,把它們都分別分配給 S 1 S_1 S1? 中的某個連通域),這里還有一個問題,如圖 g 右圖所示,圖中值為 2 的點為沖突點,例子中的兩個連通域都可能擴展到這個pixel,論文中對這種沖突的解決方法就是“先到先得”原則,這對最后的結果沒什么影響,后面的 S 3 S_3 S3? 同理,最終我們抽取圖 d 中不同顏色標注的連通區域作為最后的文本行檢測結果,- 如何分離靠的很近的文字塊?
直接用語意分割來檢測文字又會遇到新的問題:很難分離靠得很近的文字塊,因為語意分割只關心每個像素的分類問題,所以即使文字塊的一些邊緣像素分類錯誤對 loss 的影響也不大,
解決方案:引入 kernel,文字塊的核心,利用 kernel 可以有效的分離靠的很近的文字塊,- 如何通過 kernel 來構建完整的文字塊?
kernel 只是文字塊的核心,并不是完整的文字塊,不能作為最終的檢測效果,
方法: 基于 廣度優先搜索 的 漸近擴展演算法 來構建完整的文字塊
核心思想: 從每個 kernel 出發,利用廣度優先搜索來不斷地合并周圍的像素,使得 kernel 不斷地擴展,最后得到完整的文字塊
基于 廣度優先搜索(BFS) 由三個步驟組成:
step 1: 從具有最小尺度的核 S1 開始(在此步驟中可以區分實體,不同實體有不同的連通域);
step 2: 通過逐步在較大的核中加入更多的像素來擴展它們的區域;
step 3: 完成直到發現最大的核,
三、標簽的生成
- 首先從網路結構中可以看出,需要生成不同尺度的 kernel,這是需要有標簽的影像來進行訓練的,因為網路輸出有 n 個分割結果,所以對于一張輸入圖片來說 groundtruth 也要有 n 個,這里 groundtruth 就是簡單的將標定的文本框進行不同尺度的縮小
- 為了生成訓練時不同尺寸 kernels 所對應的 groundtruths,作者采用
Vatti clipping algorithm將原始多邊形 P n P_n Pn? 縮放 d i d_i di? 個像素從而得到 P i P_i Pi?,其中每個縮放的 P i P_i Pi? 都是使用 0/1 的二進制 mask 來表示分割后的標簽的,- 需要縮小的像素通過右邊式子得到: d i = A r e a ( P n ) × ( 1 ? r i 2 ) P e r i m e t e r ( P n ) d_{i} = \frac{Area(P_{n})\times(1-r_{i}^{2})}{Perimeter(P_{n})} di?=Perimeter(Pn?)Area(Pn?)×(1?ri2?)?, 其中 r i = 1 ? ( 1 ? m ) ( n ? i ) n ? 1 r_{i} = 1 - \frac{(1-m)(n-i)}{n-1} ri?=1?n?1(1?m)(n?i)?
Note:
- r i r_{i} ri? 表示縮小的比例
- m: 最小的縮放比例,是一個超引數,取值范圍為(0,1],本文取得是 m=0.5
- n: 最終輸出多少個尺度的分割結果,即 kernel 的數量
四、損失函式 loss
- 損失由完整的 mask 的 loss 加上腐蝕后的 mask 的 loss,其中兩項是加權相加:
L = λ L c + ( 1 ? λ ) L s L = \lambda L_{c} + (1-\lambda)L_{s} L=λLc?+(1?λ)Ls?
其中, L c L_{c} Lc? 表示沒有進行縮放時候的損失函式,即相對于原始大小的groundtruth的損失函式, L s L_{s} Ls? 表示的是相對于縮放后的框的損失函式,- 由于正常狀態下非文本區域遠大于文本區域,所以使用二分類的交叉熵損失會使得結果更加偏向于非文本區域,故 PSE 模型使用的是
dice cofficient:
D ( S i , G i ) = 2 × ∑ x , y ( S i , x , y × G i , x , y ) ∑ x , y S i , x , y 2 + ∑ x , y G i , x , y 2 D(S_i, G_{i})=\frac{2\times\sum_{x, y}(S_{i, x, y}\times G_{i, x, y})}{\sum_{x, y}S_{i, x, y}^{2} + \sum_{x, y}G_{i, x, y}^{2}} D(Si?,Gi?)=∑x,y?Si,x,y2?+∑x,y?Gi,x,y2?2×∑x,y?(Si,x,y?×Gi,x,y?)?
Note:
- S x , y S_{x, y} Sx,y? 為預測實體中像素點 (x, y) 的值,
- G x , y G_{x, y} Gx,y? 為 label 中像素點 (x, y) 的值,
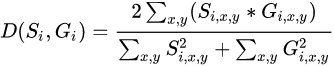
五、OHEM 演算法的思想
在線難例挖掘(online hard example mining),根據輸入樣本的損失進行篩選,篩選出難例,表示對分類和檢測影響較大的樣本,然后將篩選得到的這些樣本應用在隨機梯度下降中訓練,具體到該模型中,選取所有正樣本(主要是正樣本本來就偏少,所以就全取)以及困難樣本,過濾掉 easy 的負樣本,被選中的像素點取值為 1,未選中的取值為 0 ,
六、訓練自己的資料集
6.1 資料準備
step 1: 資料獲取:手動標注,獲得 8 個點坐標(或者矩形框,獲得 4 個坐標),得到 xml 檔案;[ PSE也可以檢測多邊框圖,即點坐標可以不止 8 個 ]
step 2: xml 檔案轉換成 txt 檔案,只包含 8 個坐標資訊,以,分割;(xml2txt.py)
step 3: draw_small_box:畫出 16px 的小框;驗證小框是否正確 (draw_small_box.py) [ PSE 不需要此步驟,需要的話也僅僅是為了驗證框的標注正確性 ]
6.2 資料增強
1. img_transform.py
2. data_aug.py
6.3 pse_general 引數設定
- –arch: resnet50
- –batchsize: 8
- –lr: 0.001
- –imgsize: 640
- –n_epoch: 50
- –resume: 中間訓練結束,繼續訓練的起始位
- –pretrain: 加載預訓練模型,僅相當于匯入初始權重
- –schedule: [ 10, 25, 40 ] 學習率衰減位置
Note: 訓練速度太慢,可以調整學習率改變的位置
輸入影像維度為:[ B, 3, H, W ] 經過特征融合,上采樣程序 得到 feature map : [ B, C, H, W ],其中 C 的大小為確定的 kernel_num,設定為7,
對于一個文本實體,有幾個對應的內核,每個內核與原始的整個文本實體共享相似的形狀,并且它們都位于相同的中心點但在比例上不同,
6.4 issue
-
當 long_size 設定到 2240+ 時速度慢,但是設定小一點的時候出現檢測框往上飄的情況?
-
當出現 ImportError: libopencv_dnn.so.3.4: cannot open shared object file: No such file or directory 的錯誤時,將 opencv-3.4.6 復制過來,然后執行
export LD_LIBRARY_PATH=/mnt/libo/opencv-3.4.6/build/lib/:$LD_LIBRAR
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/252173.html
標籤:其他
上一篇:有序資料程式設計
下一篇:淺談漢諾塔