一、寫在前面
周末閑來無事,最近在關心房子的問題,就突發奇想寫個博客,正好把之前學習的知識復習整理一下,也為需要買房的同事提供一點點啟發,整個搞完作業量不小,算是一個小專案,程序有兩大部分,一是宜昌(夷陵區)房源資料獲取,二是對獲取的資料進行分析,發現一些有趣問題與現象,
二、資料獲取
在網上獲取資料首先想到的肯定是寫爬蟲,關于爬蟲目前我只會寫一些簡單的,大神專屬Scrapy框架暫時不會用,但對于常規資料爬取(電影資訊、圖片、評論等)已經夠了,這里需要友情感謝一下鏈家網,對于爬蟲新手簡直不要太友好,不會擔心把人家網站搞崩潰,相當于鏈家在告訴你:“沒事,我網站里的資源你隨便爬,網站崩了算我輸”,爬蟲代碼如下,這里就不多bb了,熟悉的能看懂,不熟悉的童鞋就來看熱鬧吧O(∩_∩)O~
import requests
from lxml import etree
import pandas as pd
import re
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3868.400'
}
class House_price_analyze:
def __init__(self,city_name,district_name,house_num):
self.city_name = city_name
self.district_name = district_name
self.house_num = house_num
self.urls = []
def Page_urls(self):
for i in range(1, int(self.house_num / 30) + 1):
out_url = 'https://'+self.city_name+'.lianjia.com/ershoufang/'+self.district_name+'/pg' + str(i) + '/'
response = requests.get(out_url,headers=headers)
res_xpath = etree.HTML(response.text)
inner_url = res_xpath.xpath("//ul[@class='sellListContent']/li/a/@href")
for item in inner_url:
self.urls.append(item)
def Basic_information(self):
self.Data = []
self.success_count = 0
self.fail_count = 0
for url in self.urls:
response = requests.get(url,headers=headers)
try:
introduce = re.findall(r"<title>(.*?)</title>", response.text)[0]
community_name = re.findall(r'class="info no_resblock_a">(.*?)</a>', response.text)[0]
main_info = re.findall(r'<div class="mainInfo">(.*?)</div>', response.text)[0]
area = re.findall(r'</div><div class="area"><div class="mainInfo">(.*?)</div>', response.text)[0]
sub_info = ''.join(re.findall(r'<div class="subInfo">(.*?)</div>', response.text))
unit_price = re.findall(r'<span class="unitPriceValue">(.*?)<i>', response.text)[0]
total_price = re.findall(r'<span class="total">(.*?)</span>', response.text)[0]
pattern = re.findall(r"resblockPosition:'(.*?)'", response.text)[0]
longitude = pattern.split(',')[0]
latitude = pattern.split(',')[1]
data = {
'introduce':introduce,
'community_name':community_name,
'main_info':main_info,
'area':area,
'sub_info':sub_info,
'unit_price':unit_price,
'total_price':total_price,
'longitude':longitude,
'latitude':latitude
}
self.success_count += 1
print(data,'第' + str(self.success_count) + '個爬取成功')
self.Data.append(data)
except:
self.fail_count += 1
print('第' + str(self.fail_count) + '個資料產生例外')
pass
house_data = pd.DataFrame(self.Data)
house_data.to_csv(self.city_name + '_' + self.district_name + '_Basic_infomation.csv')
Yichang = House_price_analyze('yichang', 'yilingqu', 1200)
Yichang.Page_urls()
data = Yichang.Basic_information()
print('抓取成功,共成功抓取抓取{}條資訊,失敗{}條'.format(Yichang.success_count,Yichang.fail_count))
這里采集了1200條夷陵區的房源資料,資料內容包括有(房東描述、小區名字、戶型、樓高、建筑結構、是否精裝、面積、總價、均價、地理位置(經緯度)),下圖展示的資料其實不是爬取的原始資料,我在去掉area列尾部的“平米”字符時不小心把sub_info列給刪掉了,不想重新爬(爬一下得半個多小時(┭┮﹏┭┮)),又考慮到對后面資料分析的影響不大,所以就用這個來分析,
二、資料分析
首先用drop_duplicates方法去掉重復44條重復資料,剩下1156條,
1、看一下我們關心的房屋面積、均價、總價資料的整體情況,
import pandas as pd
import seaborn as sns
house_data = pd.read_csv(r'yichang_yilingqu_Basic_infomation.csv')
house_data = house_data.drop_duplicates(subset = 'introduce')
house_data_describe = house_data[['area','unit_price','total_price']]
print(house_data_describe.describe())
運行結果如下:可以發現目前夷陵區房價的均值為每平米6841元,總價均值為87.14萬元,
area unit_price total_price
count 1156.000000 1156.000000 1156.000000
mean 126.142189 6841.746540 87.146946
std 52.835946 1403.095185 49.650589
min 34.000000 3424.000000 16.000000
25% 96.460000 5938.750000 63.000000
50% 122.000000 6792.500000 79.800000
75% 137.025000 7613.250000 95.650000
max 738.680000 16322.000000 665.000000
2、繪制面積與總價的散點圖觀察總體資料,如下圖,我們可以觀察到一些比較特殊(離散)的樣本,比如面積超過了700平米或者總價超過400萬的樣本,看到這些樣本,我不禁納悶,面積超過了700平米的是什么房子?夷陵區還會有房價過400萬的嗎?
sns.scatterplot(x = 'area',y = 'total_price',data = house_data)
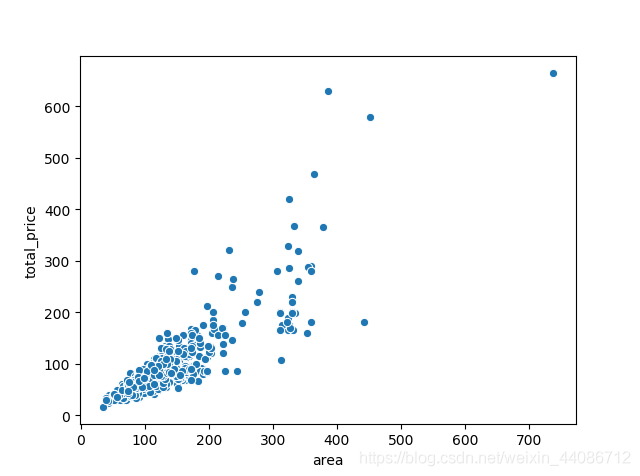
我們把面積大于400平米,房價大于400萬的房子揪出來看看怎么回事,
house_data = house_data[(house_data['area'] > 400) | (house_data['total_price'] > 400)]
print(house_data['introduce'])
運行結果:
266 國賓一號別墅,誠心出售,獨棟獨院_宜昌夷陵區夷陵區國賓一號A區二手房(宜昌鏈家)
320 夷陵萬達旁 稀有獨棟別墅 戶型好 有大花園_宜昌夷陵區夷陵區國賓一號A區二手房(宜昌鏈家)
465 私房整棟出售,一樓門面,二.三.四樓可出租可居住_宜昌夷陵區夷陵區黃金路25號二手房(宜昌鏈家)
600 國賓一號聯排別墅 精裝修業主自住房出租 可看一線湖景_宜昌夷陵區夷陵區國賓一號A區二手房(宜...
963 長江市場繁華地段,獨棟別墅.大花園大露臺_宜昌夷陵區夷陵區瑪歌莊園二手房(宜昌鏈家)
1199 昌耀電力別墅區三層別墅 全新毛坯可以幾代同堂_宜昌夷陵區夷陵區昌耀沁園二手房(宜昌鏈家)
從結果可以看到基本上都是別墅,所以房價高在情理之中,但其中有一個(465號)是整棟樓一起出售,還真是活久見,果然貧窮限制了我的想象,
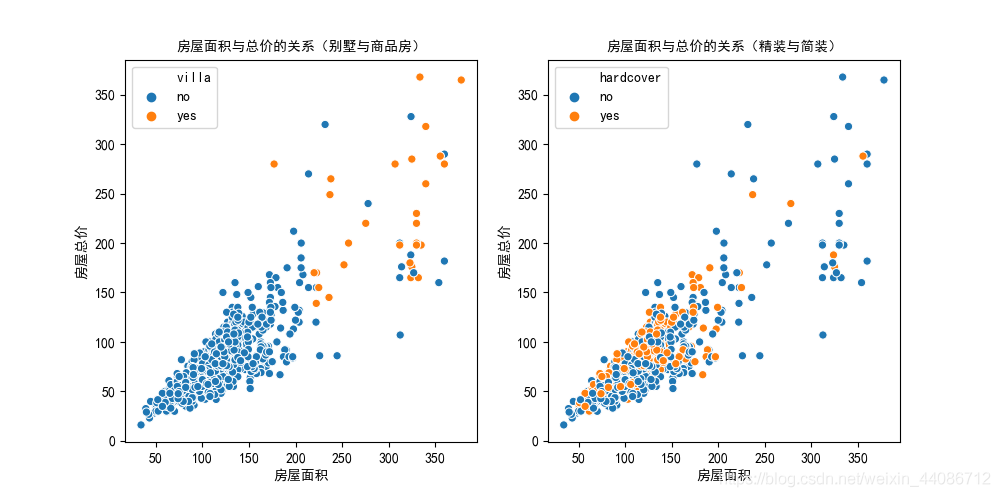
3、看到這里,也許有的小伙伴會比較好奇別墅、精裝房的面積與價格會如何分布?下面用圖直觀展示給大家(這里我去除了一些離散的樣本,這樣更直觀),
f, [ax1,ax2] = plt.subplots(1,2,figsize=(10,5))
sns.set_style({'font.sans-serif':['simhei','Arial']})
sns.scatterplot(x = 'area',y = 'total_price',hue = 'villa',data = house_data,ax = ax1)
ax1.set_title('房屋面積與總價的關系(別墅與商品房)',fontsize = 10)
ax1.set_xlabel('房屋面積')
ax1.set_ylabel('房屋總價')
sns.scatterplot(x = 'area',y = 'total_price',hue = 'hardcover',data = house_data,ax = ax2)
ax2.set_title('房屋面積與總價的關系(精裝與簡裝)',fontsize = 10)
ax2.set_xlabel('房屋面積')
ax2.set_ylabel('房屋總價')
運行結果:可以發現別墅(villa)是真的貴,最便宜的也得150萬,絕大多數都是200w+,接下來看精裝房(hardcover)的樣本:在面積相同的情況下,精裝房的整體總價在非精裝房之上,這點可以很直觀地發現,也很好理解,人家裝修也得花錢對不對,裝修不花錢,那建筑工人吃飯總得花錢吧 (`?ω?′)
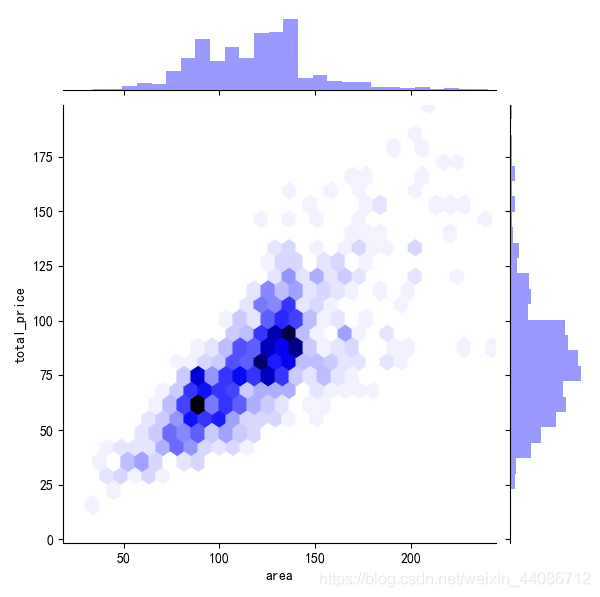
4、使用熱力圖來看看夷陵區房子的總體面積與售價情況,
g = sns.jointplot(x=house_data['area'], y=house_data['total_price'], kind="hex", color="b")
g.add_legend()
運行結果:可以發現夷陵區房子面積有兩個集中的區間,分別是85到95,125到135,房價多集中在75w~100w之間,
5、采用分類資料來觀察樣本分布,主要回答了“夷陵區各種戶型的占比情況如何?”以及“哪些小區房源比較充足?”兩個問題,
f, [ax1,ax2] = plt.subplots(1,2,figsize=(30,5))
sns.set_style({'font.sans-serif':['simhei','Arial']})
df_house_count_1 = house_data.groupby('main_info')['total_price'].count().sort_values(ascending=False).to_frame().reset_index()
df_house_count_2 = house_data.groupby('community_name')['total_price'].count().sort_values(ascending=False).to_frame().reset_index()
sns.barplot(x='main_info',y='total_price',data = df_house_count_1[df_house_count_2['total_price'] > 30],ax = ax1)
ax1.set_title('各戶型在售數量',fontsize = 10)
ax1.set_xlabel('戶型')
ax1.set_ylabel('數量(個)')
sns.barplot(x='community_name',y='total_price',data = df_house_count_2[df_house_count_2['total_price'] > 30],ax = ax2)
ax2.set_title('各小區在售數量',fontsize = 10)
ax2.set_xlabel('小區')
ax2.set_ylabel('數量(個)')
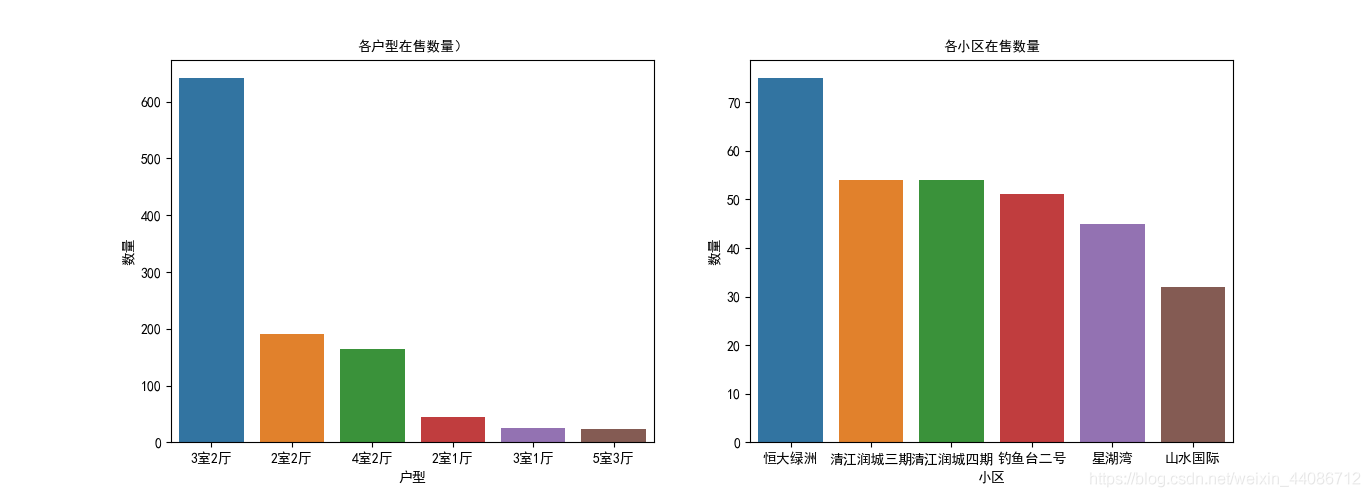
運行結果如下:可以發現有超過600套的戶型是3室2廳,整體占比超過了在售數量的50%,在各小區房源數量上看,恒大綠洲的房源最充足,有70多套,其他幾個主要小區(清江潤城、釣魚臺等)在售都在50套左右,數量尚可,
6、我們知道,市場價格與房源數量肯定是存在關系的,那么問題就來了:到底哪些小區的房價最高呢?
df = house_data[house_data['total_price'] > 80][['unit_price','community_name','total_price']]
df_1 = df.groupby(df['community_name'])['total_price'].mean().sort_values(ascending = False)[3:10]
df_1.plot(kind = 'bar')
plt.title('總價最高小區')
plt.ylabel('均價(萬)')
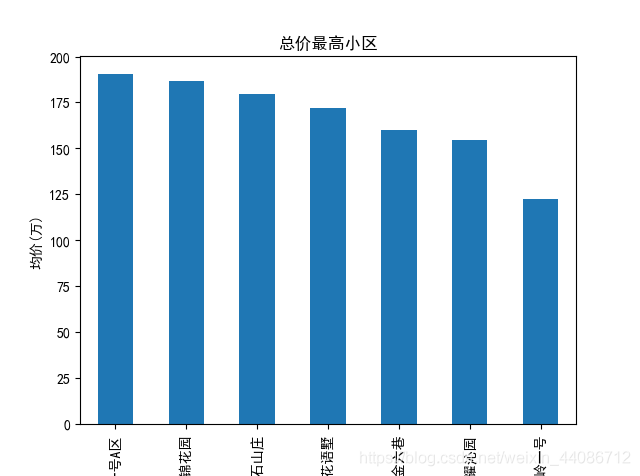
運行結果:(這里我未考慮一些房源較少的小區(比如在售數量 < 5 ),因其定價主觀偏差較大,價格不具有代表性)可以看出,小區均價最高前四是國賓一號、湖蕉訓園、無石山莊、花語墅,在下面的百度地圖中我們可以看到,貌似這些住宅區都在湖岸、江岸邊,加上別墅加持,房價想跌也跌不下來,大家看看就好╮(╯﹏╰)╭,
8、用百度地圖展示夷陵區房價區域分布熱力圖,這部分比較復雜,當然最后的展示效果會很好,
首先要將資料中的經緯度和總價資訊調出來,并修改成json格式才可以在百度地圖API中呼叫,
import pandas as pd
file = open('經緯度總價.json','w')
data = pd.read_csv("yichang_yilingqu_Basic_infomation.csv")
df = data.copy()
columns = ['total_price','longitude','latitude']
df = pd.DataFrame(df,columns=columns)
for i in df.values:
total_price = i[0]
lng = i[1]#獲取經度
lat = i[2]#獲取緯度
str_temp = '{"lat":' + str(lat) + ',"lng":' + str(lng) +',"total_price":'+str(total_price) +'},'
file.write(str_temp)
file.close()
轉換完成后可以在當前檔案夾看見名為“經緯度總價.json”的檔案,接下來就開始呼叫百度地圖API,首先你需要去百度地圖官網注冊一個密匙,這樣才能有呼叫入口,注冊完成后,打開這里,復制原始碼編輯器中的所有內容,將密匙修改為自己注冊的,在var points中將自己json中的所有資料傳進去,后續還可以修改一些引數,使熱力圖更美觀,這里就不想贅述了,如果有小伙伴不清楚,麻煩點個贊,然后私聊我吧,O(∩_∩)O~
(1)填入密匙
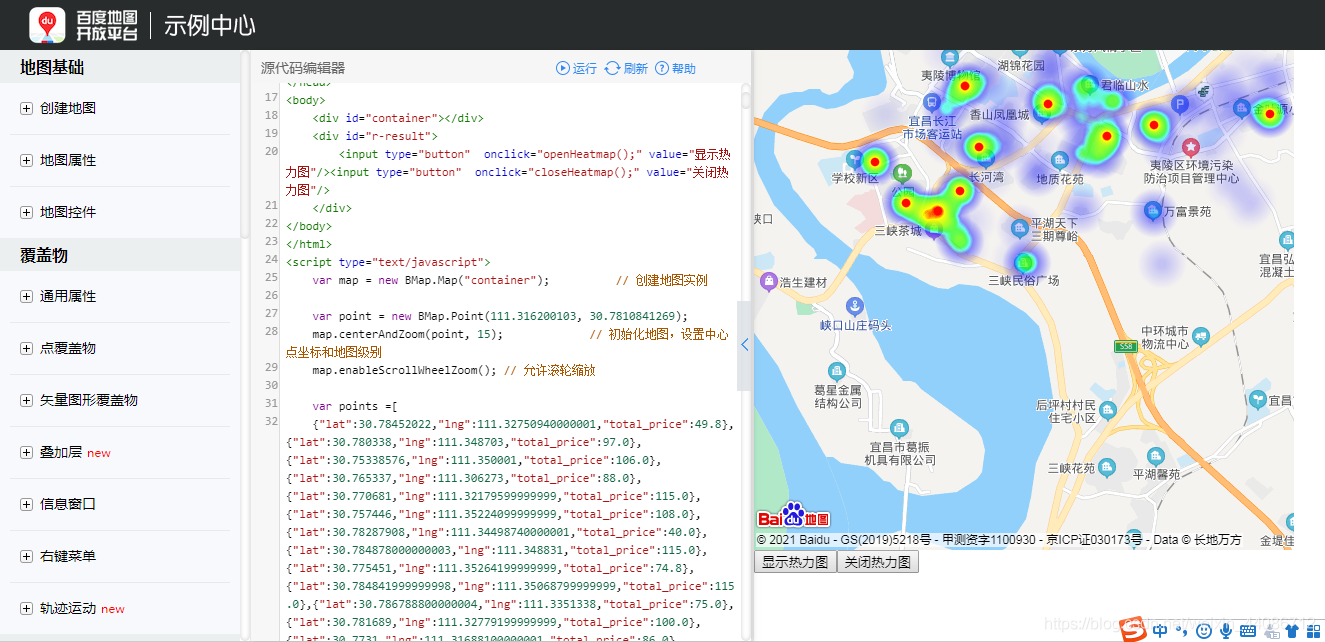
(2)填入坐標及價格資料
(3)修改引數
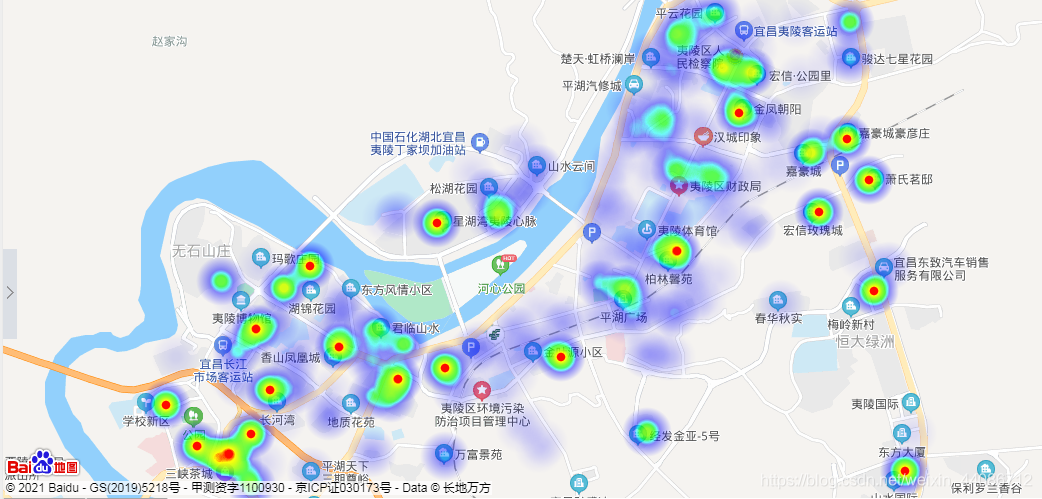
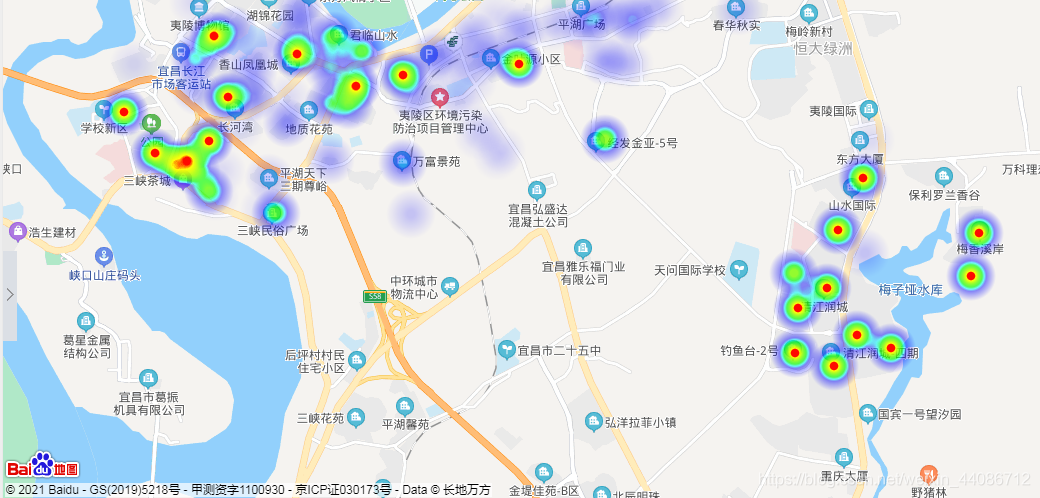
運行結果:顏色越深房價越高,但是這其中我不知道會不會產生多個樣本重疊加在同一地方造成資料變深的問題,例如:假如釣魚臺一號小區房子的均價是6500,因為這里樣本較多,本來房價不是很高,但疊加在一起會不會意外使其顏色變深?搞不懂,暫時先這樣,如果有知道的歡迎指正!
從圖中可以看到,夷陵區的房子大量集中在黃柏河附近,因為這里是老城區,但同時也可以看到發展大道上的房子不少,房價也不低,可能這里也是夷陵區未來的發展的重點吧,當然,這也是我從房價方面妄加猜測的,
三、結語
我的天終終終于寫完了!其實這里面的許多內容以前自己零散得摸索過,只是現在用總結的方式碼出來了,其實碼的程序中非常畝訓,一些看起來很容易的操作就是不容易實作,例如怎么都搞不懂Dataframe的groupby函式,又只能面向百度編程,自己摸著石頭過河,碼起來實屬不易,但再回頭看看這些圖,頓時覺得碼代碼是一個既枯燥又有趣的程序,當然,這個程序中也在不斷學習成長,寫完之后對爬蟲、Dataframe操作、seaborn繪圖熟悉多了,也算是不小的識訓了,之后的學習計劃多研究一下資料結構與演算法,希望能早一天學習到寫博客、分享經驗的程度,任何幸福都來自平凡的努力與堅持,大家加油~!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/252710.html
標籤:其他
上一篇:使用寶塔分分鐘部署前端專案