能用的東西為什么要改?因為改了之后效果更好,開發者換用其他工具或語言來編程也是這個道理,因為換了之后作業效率更高,如果不肯改變現有的習慣,那么就體會不到新技術的好處,但如果這種新的技術與你熟悉的技術看上去很像,那么改起來就特別困難,例如C#語言就與C++或Java語言相似,由于它們都用一對花括號來表示代碼塊,因此,開發者即便切換到了C#語言,也總是會把使用那兩門語言時所養成的習慣直接帶過來,這樣做其實并不能發揮出C#的優勢,這門語言的首個商用版本發布于2001年,經過這些年的演變,當前這一版C#語言與C++或Java之間的差別已經遠遠大于那個年代,如果你是從其他語言轉入C#的,那么需要學習C#語言自己的編程習慣,使得這門語言能夠促進你的作業,而不是阻礙你的作業,本章會提醒大家把那些與C#編程風格不符的做法改掉,并培養正確的編程習慣,
第1條:優先使用隱式型別的區域變數
隱式型別的區域變數是為了支持匿名型別機制而加入C#語言的,之所以要添加這種機制,還有一個原因在于:某些查詢操作所獲得的結果是IQueryable,而其他一些則回傳IEnumerable,如果硬要把前者當成后者來對待,那就無法使用由IQueryProvider所提供的很多增強功能了(參見第42條),用var來宣告變數而不指明其型別,可以令開發者把注意力更多地集中在名稱上面,從而更好地了解其含義,例如,jobsQueuedByRegion這個變數名本身就已經把該變數的用途說清楚了,即便將它的型別Dictionary>寫出來,也不會給人提供多少幫助,
對于很多區域變數,筆者都喜歡用var來宣告,因為這可以令人把注意力放在最為重要的部分,也就是變數的語意上面,而不用分心去考慮其型別,如果代碼使用了不合適的型別,那么編譯器會提醒你,而不用你提前去操心,變數的型別安全與開發者有沒有把變數的型別寫出來并不是同一回事,在很多場合,即便你費心去區分IQueryable與IEnumerable之間的差別,開發者也無法由此獲得有用的資訊,如果你非要把型別明確地告訴編譯器,那么有時可能會改變代碼的執行方式(參見第42條),在很多情況下,完全可以使用var來宣告隱式型別的區域變數,因為編譯器會自動選擇合適的型別,但是不能濫用這種方式,因為那樣會令代碼難于閱讀,甚至可能產生微妙的型別轉換bug,
區域變數的型別推斷機制并不影響C#的靜態型別檢查,這是為什么呢?首先必須了解區域變數的型別推斷不等于動態型別檢查,用var來宣告的變數不是動態變數,它的型別會根據賦值符號右側那個值的型別來確定,var的意義在于,你不用把變數的型別告訴編譯器,編譯器會替你判斷,
筆者現在從代碼是否易讀的角度講解隱式型別的區域變數所帶來的好處和問題,其實在很多情況下,區域變數的型別完全可以從初始化陳述句中看出來:

懂C#的開發者只要看到這條陳述句,立刻就能明白foo變數是什么型別,此外,如果用工廠方法的回傳值來初始化某個變數,那么其型別通常也是顯而易見的:
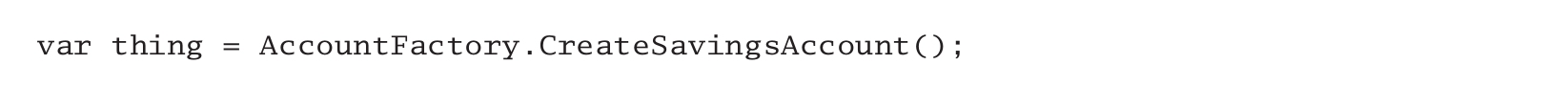
某些方法的名稱沒有清晰地指出回傳值的型別,例如
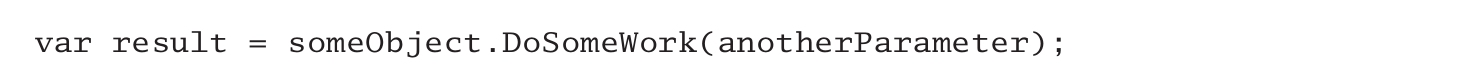
這個例子當然是筆者刻意構造的,大家在撰寫代碼的時候應該把方法的名字起好,使得呼叫方可以據此推斷出回傳值的型別,對于剛才那個例子來說,其實只需要修改變數的名稱,就能令代碼變得清晰:

盡管方法名本身沒有指出回傳值的型別,但是像這樣修改之后,很多開發者就可以通過變數的名稱推斷出該變數的型別應該是Product,
HighestSellingProduct變數的真實型別當然要由DoSomeWork方法的簽名來決定,因此,它的型別可能并不是Product本身,而是繼承自Product的類,或是Product所實作的介面,總之,編譯器會根據DoSomeWork方法的簽名來認定HighestSellingProduct變數的型別,無論它在運行期的實際型別是不是Product,只要沒有明確執行型別轉換操作,那么一律以編譯器判斷的型別為準,
用var來宣告變數可能會令閱讀代碼的人感到困惑,比方說,如果像剛才那樣用方法的回傳值來給這樣的變數做初始化,那么就會造成此類問題,查看代碼的人會按照自己的理解來認定這個變數的型別,而他所認定的型別可能恰好與變數在運行期的真實型別相符,但是編譯器卻不會像人那樣去考慮該物件在運行期的型別,而是會根據宣告判定其在編譯期的型別,如果宣告變數的時候直接指出它的型別,那么編譯器與其他開發者就都會看到這個型別,并且會以該型別為準,反之,若用var來宣告,則編譯器會自行推斷其型別,而其他開發者卻看不到編譯器所推斷出的型別,因此,他們所認定的型別可能與編譯器推斷出的型別不符,這會令代碼在維護程序中遭到錯誤地修改,并產生一些本來可以避免的bug,
如果隱式型別的區域變數的型別是C#內置的數值型別,那么還會產生另外一些問題,因為在使用這樣的數值時,可能會觸發各種形式的轉換,有些轉換是寬化轉換(widening conversion),這種轉換肯定是安全的,例如從float到double就是如此,但還有一些轉換是窄化轉換(narrowing conversion),這種轉換會令精確度下降,例如從long到int的轉換就會產生這個問題,如果明確地寫出數值變數所應具備的型別,那么就可以更好地加以控制,而且編譯器也會把有可能因轉換而丟失精度的地方給你指出來,
現在看這段代碼:

請問total的值是多少?這個問題取決于GetMagicNumber方法的回傳值是什么型別,下面這5種輸出結果分別對應5個GetMagicNumber版本,每個版本的回傳值型別都不一樣:

total變數在這5種情況下會表現出5種不同的型別,這是因為該變數的型別由變數f來確定,而變數f的型別又是編譯器根據GetMagicNumber()的回傳值型別推斷出來的,計算total值的時候,會用到一些常數,由于這些常數是以字面量的形式寫出的,因此,編譯器會將其轉換成和f一致的型別,并按照那種型別的規則加以計算,于是,不同的型別就會產生不同的結果,
這并不是C#編譯器的缺陷,因為它只是按照代碼的含義照常完成了任務而已,由于代碼采用了隱式型別的區域變數,因此編譯器會自己來設定變數的型別,也就是根據賦值符號右側的那一部分做出最佳的選擇,用隱式型別的區域變數來表示數值的時候要多加小心,因為可能會發生很多隱式轉換,這不僅容易令閱讀代碼的人產生誤解,而且其中某些轉換還會令精確度下降,
這個問題當然也不是由var所引發的,而是因為閱讀代碼的人不清楚GetMagic-Number()的回傳值究竟是什么型別,也不知道運行程序中會發生哪些默認的數值轉換,把變數f的宣告陳述句拿掉之后,問題依然存在:

就算明確指出total變數的型別,也無法消除疑惑:

total的型別雖然是double,但如果GetMagicNumber()回傳的是整數值,那么程式就會按照整數運算的規則來計算100*GetMagicNumber()/6的值,而無法把小數部分也保存到total中,
代碼之所以令人誤解,是因為開發者看不到GetMagicNumber()的實際回傳型別,也無法輕易觀察出計算程序中所發生的數值轉換,
如果把GetMagicNumber()的回傳值保存在型別明確的變數中,那么這段代碼就會好讀一點,因為編譯器會把開發者所犯的錯誤指出來,當GetMagicNumber()的回傳值型別可以隱式地轉換為變數f所具備的型別時,編譯器不會報錯,例如當方法回傳的是int且變數f的型別是decimal時,就會發生這樣的轉換,反之,若不能執行隱式轉換,則會出現編譯錯誤,這會令開發者明白自己原來理解得不對,現在必須修改代碼,這樣的寫法使得開發者能夠仔細審視代碼,從而看出正確的轉換方式,
剛才那個例子說明區域變數的型別推斷機制可能會給開發者維護代碼造成困難,與不使用型別推斷的情況相比,編譯器在這種情況下的運作方式其實并沒有多少變化,它還是會執行自己應該完成的型別檢查,只是開發者不太容易看出相關的規則與數值轉換行為,在這些場合中,區域變數的型別推斷機制起到了阻礙作用,使得開發者難以判斷相關的型別,
但是在另外一些場合里面,編譯器所選取的型別可能比開發者手工指定的型別更為合適,下面這段簡單的代碼會把客戶姓名從資料庫里面拿出來,然后尋找以字串start開頭的那些名字,并把查詢結果保存到變數q2中:

這段代碼有嚴重的性能問題,第一行查詢陳述句會把每一個人的姓名都從資料庫里取出來,由于它要查詢資料庫,因此,其回傳值實際上是IQueryable型別,但是開發者卻把保存該回傳值的變數q宣告成了IEnumerable型別,由于IQueryable繼承自IEnumerable,因此編譯器并不會報錯,但是這樣做將導致后續的代碼無法使用由IQueryable所提供的某些特性,接下來的那行查詢陳述句,就受到了這樣的影響,它本來可以使用Queryable.Where去查詢,但是卻用了Enumerable.Where,如果開發者不把變數q的型別明確指定為IEnumerable,那么編譯器就可以將其設為更加合適的IQueryable型別了,假如IQueryable不能隱式地轉換成IEnumerable,那么剛才那種寫法會令編譯器報錯,但實際上是可以完成隱式轉換的,因此編譯器不會報錯,這使得開發者容易忽視由此引發的性能問題,
第二條查詢陳述句呼叫的并不是Queryable.Where,而是Enumerable.Where,這對程式性能有很大影響,第42潭訓講到,IQueryable能夠把與資料查詢有關的多個運算式樹組合成一項操作,以便一次執行完畢,而且通常是在存放資料的遠程服務器上面執行的,剛才那段代碼的第二條查詢陳述句相當于SQL查詢中的where子句,由于執行這部分查詢時所針對的資料源是IEnumerable型別,因此,程式只會把第一條查詢陳述句所涉及的那部分操作放在遠程電腦上面執行,接下來,必須先把從資料庫中獲取到的客戶姓名全都拿到本地,然后才能執行第二條查詢陳述句(相當于SQL查詢中的where子句),以便從中搜索指定的字串,并回傳與之相符的結果,
下面這種寫法比剛才那種寫法要好:

這次的變數q是IQueryable型別,該型別是編譯器根據第一條查詢陳述句的回傳型別推斷出來的,C#系統會把接下來那條用于表示Where子句的查詢陳述句與第一條查詢陳述句相結合,從而創建一棵更為完備的運算式樹,只有呼叫方真正去列舉查詢結果里面的內容時,這棵樹所表示的查詢操作才會得到執行,由于過濾查詢結果所用的那條運算式已經傳給了資料源,因此,查到的結果中只會包含與過濾標準相符的聯系人姓名,這可以降低網路流量,并提高查詢效率,這段范例代碼是筆者特意構造出來的,現實作業中如果遇到此類需求,直接把兩條陳述句合起來寫成一條就行了,不過這個例子所演示的情況卻是真實的,因為作業中經常遇到需要連續撰寫多條查詢陳述句的地方,
這段代碼與剛才那段代碼相比,最大的區別就在于變數q的型別不再由開發者明確指定,而是改由編譯器來推斷,這使得其型別從原來的IEnumerable變成了現在的IQueryable,由于擴展方法是靜態方法而不是虛方法,因此,編譯器會根據物件在編譯期的型別選出最為匹配的呼叫方式,而不會按照其在運行期的型別去處理,也就是說,此處不會發生后期系結,即便運行期的那種型別里面確實有實體成員與這次呼叫相匹配,編譯器也看不到它們,因而不會將其納入候選范圍,
一定要注意:由于擴展方法可以看到其引數的運行期型別,因此,它能夠根據該型別創建另一套實作方式,比方說,Enumerable.Reverse()方法如果發現它的引數實作了IList或ICollection介面,那就會改用另一種方式執行,以求提升效率(關于這一點,請參見本章稍后的第3條),
寫程式的時候,如果發現編譯器自動選擇的型別有可能令人誤解代碼的含義,使其無法立刻看出這個區域變數的準確型別,那么就應該把型別明確指出來,而不要采用var來宣告,反之,如果讀代碼的人根據代碼本身的語意所推測出的型別與編譯器自動選擇的型別相符,那就可以用var來宣告,比方說,在剛才那個例子里面,變數q用來表示一系列聯系人的姓名,看到這條初始化陳述句的人肯定會把q的型別理解成字串,而實際上,編譯器所判定的型別也正是字串,像這樣通過查詢運算式來初始化的變數,其型別通常是較為明確的,因此,不妨用var來宣告,反之,若是初始化變數所用的那條運算式無法清晰地傳達出適當的語意,從而令閱讀代碼的人容易誤解其型別,那么就不應該用var來宣告該變數了,而是應該明確指出其型別,
總之,除非開發者必須看到變數的宣告型別之后才能正確理解代碼的含義,否則,就可以考慮用var來宣告區域變數(此處所說的開發者也包括你自己在內,因為你將來也有可能要查看早前寫過的代碼),注意,筆者在標題里面用的詞是優先,而非總是,這意味著不能盲目地使用var來宣告一切區域變數,例如對int、float、double等數值型的變數,就應該明確指出其型別,而對其他變數則不妨使用var來宣告,有的時候,即便你多敲幾下鍵盤,把變數的型別打上去,也未必能確保型別安全,或是保證代碼變得更容易讀懂,如果你選用了不合適的型別,那么程式的效率就有可能會下降,這樣做的效果還不如讓編譯器自動去選擇,
更多C語言相關VIP專享文章免費閱讀、近千本電子書免費閱讀、N次資源下載、千門課程免費學習等特權,
↑↑ 開通CSDN會員免費享有 ↑↑
戳我,立即開通>> 立享7項VIP專項特權!

戳我,立即開通>>
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/253524.html
標籤:其他
上一篇:位元組+谷歌超全Kotlin學習王炸筆記!Kotlin入門到精通+高級Kotlin強化實戰(附Demo)
下一篇:各地留守過年最全福利盤點