排序
- 1.排序的概念
- 2.常見的排序演算法
- 3.常見排序演算法的實作
- 3.1 直接插入排序
- 3.2希爾排序
- 3.3選擇排序
- 3.4堆排序
- 3.5冒泡排序
- 4.快速排序
- 4.1hoare法
- 4.2挖坑法
- 4.3前后指標法
- 4.4快排特性總結
1.排序的概念
排序:所謂排序,就是使一串記錄,按照其中的某個或某些關鍵字的大小,遞增或遞減的排列起來的操作,
穩定性:假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次
序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,則稱這種排
序演算法是穩定的;否則稱為不穩定的,
內部排序:資料元素全部放在記憶體中的排序,
外部排序:資料元素太多不能同時放在記憶體中,根據排序程序的要求不能在內外存之間移動資料的排序,
2.常見的排序演算法
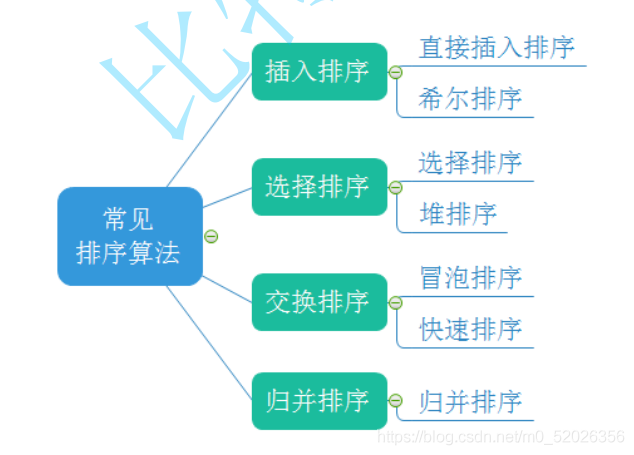
3.常見排序演算法的實作
3.1 直接插入排序
1.演算法思想:直接插入排序是一種簡單的插入排序法,其基本思想是:把待排序的記錄按其關鍵碼值的大小逐個插入到一
個已經排好序的有序序列中,直到所有的記錄插入完為止,得到一個新的有序序列 ,
例如,玩撲克牌進行的排序,
2.當插入第i(i>=1)個元素時,前面的array[0],array[1],…,array[i-1]已經排好序,此時用array[i]的排序碼與
array[i-1],array[i-2],…的排序碼順序進行比較,找到插入位置即將array[i]插入,原來位置上的元素順序后移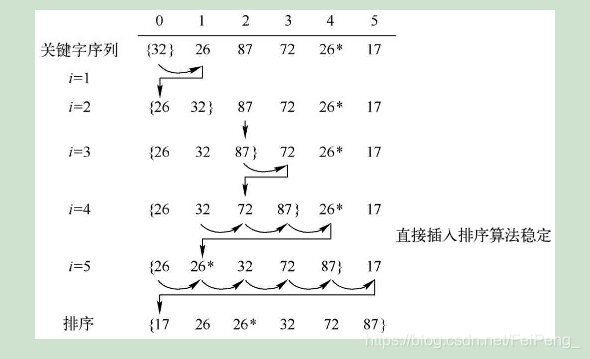
3.代碼實作
void InsertSort(int* a, int n)
{
assert(a);
for (int i = 0; i < n - 1; i++)
{
//單次把end+1的資料插入到區間【0,end】
int end = i;
int temp = a[end + 1];
while (end >= 0)
{
//如果前一個元素比后一位大
if (temp < a[end])
{ //那該元素后移一位
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = temp;
}
}
4.直接插入排序的特性總結:
- 元素集合越接近有序,直接插入排序演算法的時間效率越高
- 時間復雜度:O(N^2)
- 空間復雜度:O(1),它是一種穩定的排序演算法
- 穩定性:穩定
3.2希爾排序
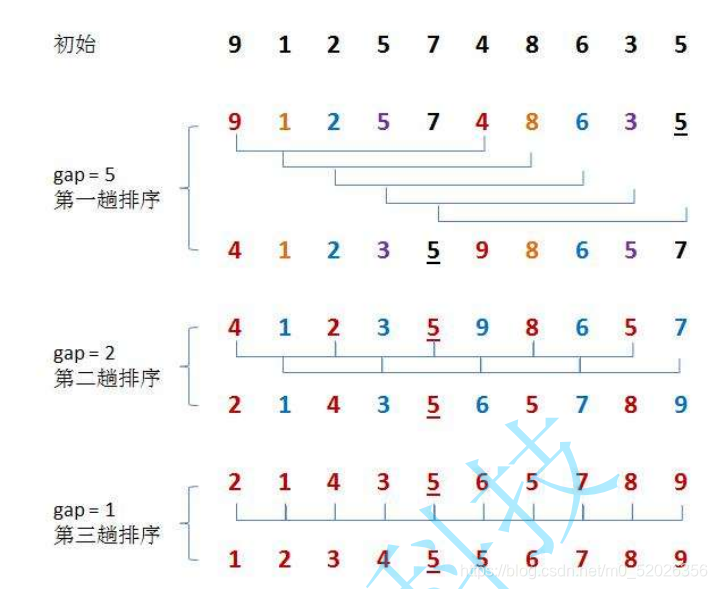
1.演算法思想:希爾排序法又稱縮小增量法,希爾排序法的基本思想是:先選定一個整數,把待排序檔案中所有記錄分成個組,所有距離為的記錄分在同一組內,并對每一組內的記錄進行排序,然后,取,重復上述分組和排序的作業,當到達=1時,所有記錄在統一組內排好序,
2.
3.代碼實作
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{ //以gap分組直到gap為1
gap = gap / 3;
for (int i = 0; i < n - gap; i++)
{ //單趟比較
int end = i;
int temp = a[end + gap];
while (end >= 0)
{
if (temp < a[end])
{
a[end + gap] = a[end];
end = end - gap;
}
else
{
break;
}
}
a[end + gap] = temp;
}
}
}
4.希爾排序的特性總結:
- 希爾排序是對直接插入排序的優化,
- 當gap > 1時都是預排序,目的是讓陣列更接近于有序,當gap == 1時,陣列已經接近有序的了,這樣就會很快,這樣整體而言,可以達到優化的效果,我們實作后可以進行性能測驗的對比,
- 希爾排序的時間復雜度不好計算,需要進行推導,推匯出來平均時間復雜度: O(N1.3—N2)
- 穩定性:不穩定
3.3選擇排序
1.基本思想:每一次從待排序的資料元素中選出最小(或最大)的一個元素,存放在序列的起始位置,直到全部待排序的資料元素排完 ,
2. 直接選擇排序:在元素集合array[i]–array[n-1]中選擇關鍵碼最大(小)的資料元素若它不是這組元素中的最后一個(第一個)元素,則將它與這組元素中的最后一個(第一個)元素交換在剩余的array[i]–array[n-2](array[i+1]–array[n-1])集合中,重復上述步驟,直到集合剩余1個元素
3.代碼實作:
選擇排序一:
void SelectSort(int* a, int n)
{
int k;
for (int i = 0; i <= n - 2; i++)
{
k = i;
for (int j = i+1; j < n ; j++)
{
if (a[j] < a[k])
{
k = j;
}
}
if (k != i)
{
int temp = a[i];
a[i] = a[k];
a[k] = temp;
}
}
}
選擇排序二:
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int maxi, mini;
maxi = mini = begin;
for (int i = begin + 1; i <= end; i++)
{
if (a[i]>a[maxi])
{
maxi = i;
}
if (a[i] < a[mini])
{
mini = i;
}
}
//swap兩數交換函式
swap(&a[begin], &a[mini]);
if (begin == maxi)
{
maxi = mini;
}
swap(&a[end], &a[maxi]);
begin++;
end--;
}
}
4.直接選擇排序的特性總結:
- 直接選擇排序思考非常好理解,但是效率不是很好,實際中很少使用
- 時間復雜度:O(N^2)
- 空間復雜度:O(1)
- 穩定性:不穩定
3.4堆排序
1.演算法思想:堆排序(Heapsort)是指利用堆積樹(堆)這種資料結構所設計的一種排序演算法,它是選擇排序的一種,它是通過堆來進行選擇資料,需要注意的是排升序要建大堆,排降序建小堆,
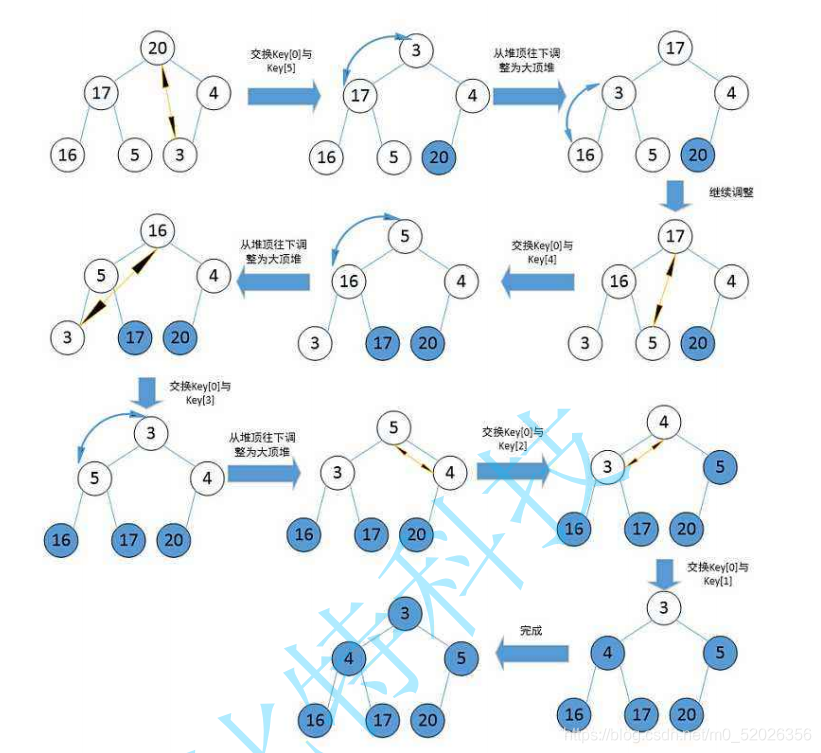
2.代碼實作:
//建堆
void AdjustDwon(int* a, int n, int root)
{
int parent = root;
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n&&a[child + 1] > a[child])
{
child++;
}
if (a[child] > a[parent])
{
swap(&a[child],&a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
//堆排序
void HeapSort(int* a, int n)
{
for (int i = (n - 2) / 2; i >= 0; i--)
{
AdjustDwon(a, n, i);
}
int end = n - 1;
while (end > 0)
{
swap(&a[0], &a[end]);
AdjustDwon(a, end, 0);
end--;
}
}
3.堆排序的特性總結:
- 堆排序使用堆來選數,效率就高了很多,
- 時間復雜度:O(N*logN)
- 空間復雜度:O(1)
- 穩定性:不穩定
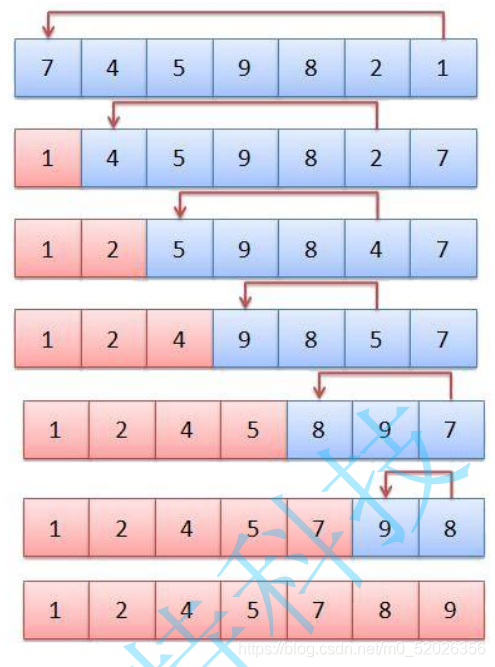
3.5冒泡排序
1.冒泡排序法原理圖
2.代碼實作:
void BubbleSort(int* a, int n)
{
int i, j;
for (i = 0; i < n; i++)
{
for (j = i + 1; j < n; j++)
{
if (a[i]>a[j])
{
swap(&a[i], &a[j]);
}
}
}
}
3.冒泡排序的特性:
- 冒泡排序是一種非常容易理解的排序
- 時間復雜度:O(N^2)
- 空間復雜度:O(1)
- 穩定性:穩定
4.快速排序
快速排序是Hoare于1962年提出的一種二叉樹結構的交換排序方法,其基本思想為:任取待排序元素序列中
的某元素作為基準值,按照該排序碼將待排序集合分割成兩子序列,左子序列中所有元素均小于基準值,右
子序列中所有元素均大于基準值,然后最左右子序列重復該程序,直到所有元素都排列在相應位置上為止,
將區間按斬訓準值劃分為左右兩半部分的常見方式有:
- hoare版本
- 挖坑法
- 前后指標版本
- 對于快速排序的優化:三數取中選key
int GetMidIndex(int* a, int begin, int end)
{
int mid = (begin + end) / 2;
if (a[begin] < a[mid])
{
if (a[mid] < a[end])
return mid;
else if (a[begin]>a[end])
return begin;
else
return end;
}
else //a[begin] > a[mid]
{
if (a[mid] > a[end])
return mid;
else if (a[begin] < a[end])
return begin;
else
return end;
}
}
4.1hoare法
1.演算法思想:
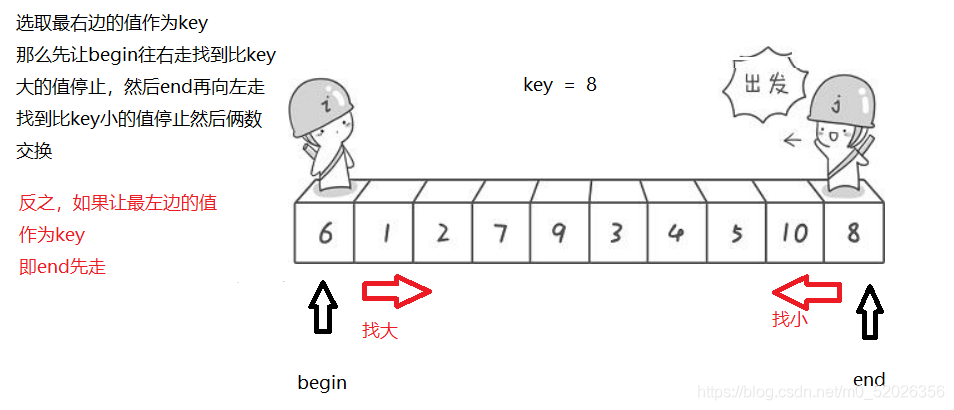
2.代碼:
//前后指標法
int QuickSort1(int* a, int begin, int end)
{
int midIndex = GetMidIndex(a, begin, end);
swap(&a[midIndex], &a[end]);
int keyindex = end;
while (begin < end)
{
// begin找大
while (begin < end && a[begin] <= a[keyindex])
{
++begin;
}
// end找小
while (begin < end && a[end] >= a[keyindex])
{
--end;
}
swap(&a[begin], &a[end]);
}
swap(&a[begin], &a[keyindex]);
return begin;
}
//快速排序遞回
void quicksort(int* a, int left, int right)
{
assert(a);
if (left >= right)
return;
int div = QuickSort1(a, left, right);
quicksort(a, left, div - 1);
quicksort(a, div+1, right);
}
4.2挖坑法
1.演算法思想:
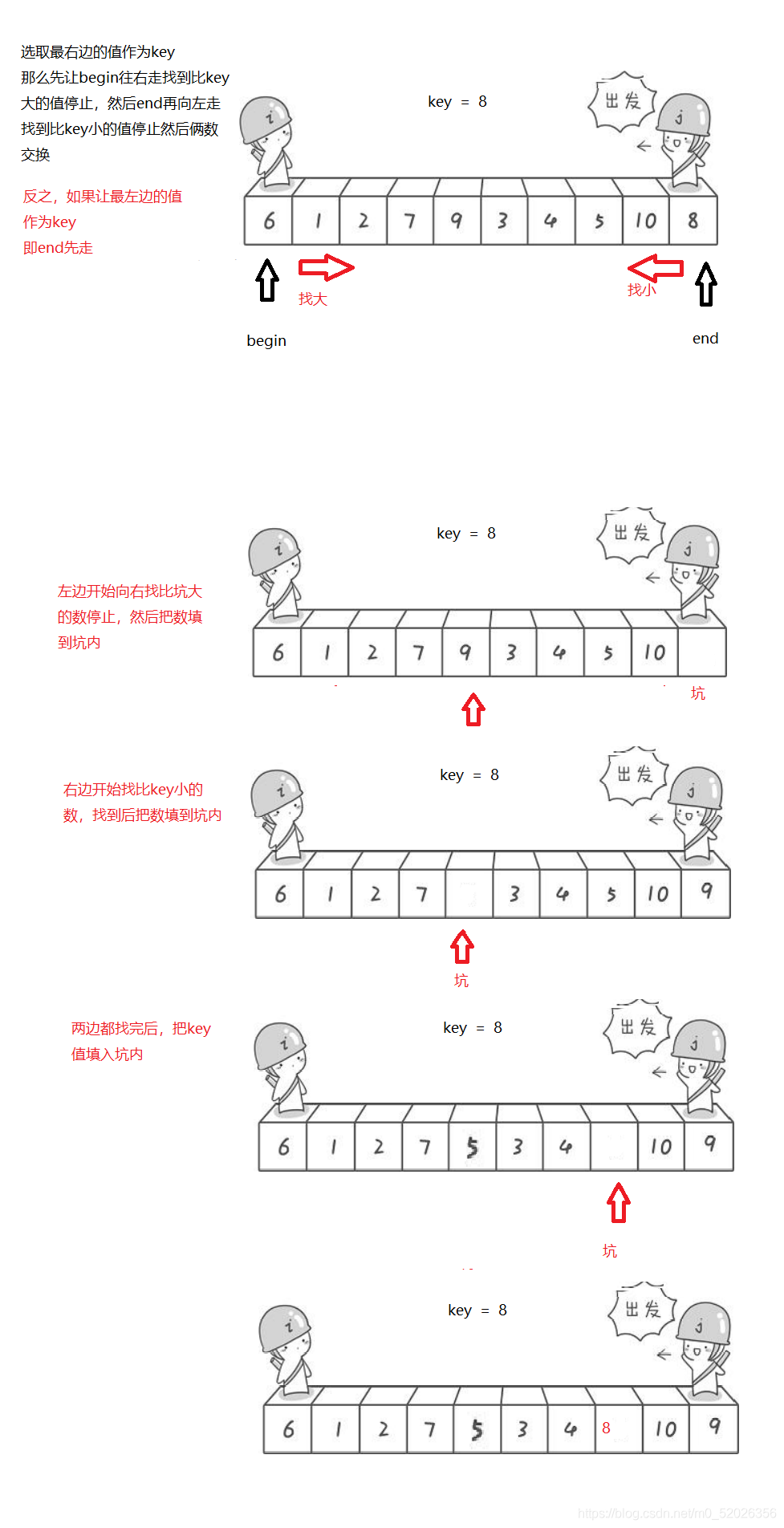
2.代碼實作:
//挖坑
int QuickSort2(int* a, int begin, int end)
{
int midIndex = GetMidIndex(a, begin, end);
swap(&a[midIndex], &a[end]);
int key = a[end];
while (begin < end)
{
while (begin < end&&a[begin] <= key)
{
begin++;
}
a[end] = a[begin];
while (begin < end&& a[end] >= key)
{
end--;
}
a[begin] = a[end];
}
a[begin] = key;
return begin;
}
//遞回排序
void quicksort(int* a, int left, int right)
{
assert(a);
if (left >= right)
return;
int div = QuickSort2(a, left, right);
quicksort(a, left, div - 1);
quicksort(a, div+1, right);
}
4.3前后指標法
1.演算法思想:
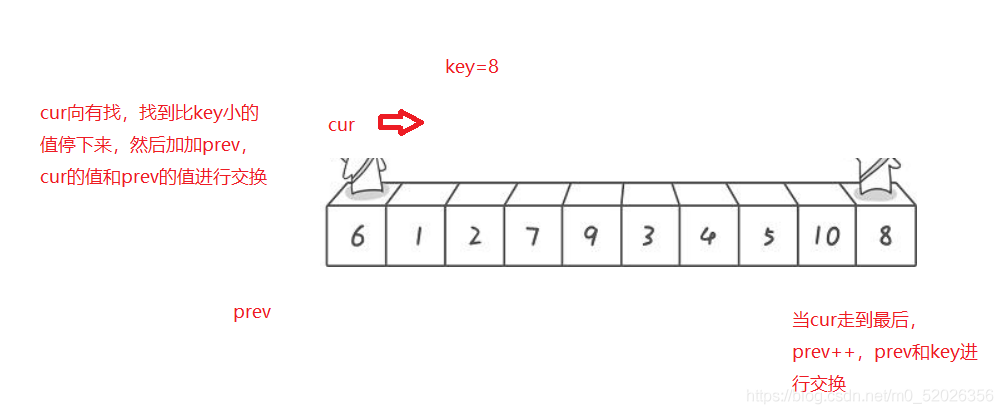
2.代碼實作:
//前后指標法
int QuickSort3(int* a, int begin, int end)
{
int midIndex = GetMidIndex(a, begin, end);
swap(&a[midIndex], &a[end]);
int keyindex = end;
int prev = begin - 1;
int cur = begin;
while (cur < end)
{
if (a[cur] < a[keyindex] && ++prev != cur)
swap(&a[prev], &a[cur]);
cur++;
}
swap(&a[++prev], &a[keyindex]);
return prev;
}
//遞回
void quicksort(int* a, int left, int right)
{
assert(a);
if (left >= right)
return;
int div = QuickSort3(a, left, right);
quicksort(a, left, div - 1);
quicksort(a, div+1, right);
}
4.4快排特性總結
快速排序的特性總結:
- 快速排序整體的綜合性能和使用場景都是比較好的,所以才敢叫快速排序
- 時間復雜度:O(N*logN)
- 空間復雜度:O(logN)
- 穩定性:不穩定
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/254777.html
標籤:其他
上一篇:面試阿里被質問:ConcurrentHashMap執行緒安全嗎
下一篇:VRRP(虛擬路由冗余協議)