深度詳解Linux內核網路結構及分布
linux內核,行程調度器的實作,完全公平調度器 CFS
1、調度型別和時機
調度觸發有兩種型別,行程主動觸發的主動調度和被動調度,被動調度又叫搶占式調度,
主動調度:行程主動觸發以下情況,然后陷入內核態,最終呼叫schedule函式,進行調度,
1、當行程發生需要等待IO的系統呼叫,如read、write,
2、行程主動呼叫sleep時,
3、行程等待占用信用量或mutex時,注意spin鎖不會觸發調度,可能在空轉,
被動調度:當發生以下情況時會發生被動調度:
1、tick_clock,cpu的時鐘中斷,一般是10ms一次,也有1ms一次的,取決于cpu的主頻,此時會通過cfs檢查行程佇列,如果當前占用cpu的行程的vruntime不是最小時,且超過sched_min_granularity_ns(詳細可見前文調度演算法),發生“被動調度”,此處有引號,原由下面說,
2、fork出新行程時,此時會通過cfs演算法檢查進度佇列,如果當前占用cpu的行程的vruntime不是最小時且超過sched_min_granularity_ns,發生“被動調度”,此處有引號,原由下面說,
為什么上面“被動調度”加引號了?因為被動調度不是立即進行的,上面兩種情況僅僅是確認需要調度后給行程的打上標志_TIF_NEED_RESCHED,然后會在以下時機會檢查_TIF_NEED_RESCHED標志,如果標志存在再呼叫schedule函式:
1、中斷結束回傳用戶態或內核態之前,
2、開啟內核搶占開關后,kernal2.5 引入內核搶占,即在內核態也允許搶占,但不是內核態運行全周期都允許去搶占,所以thread_info.preempt_count用于標志當前是否可以進行內核搶占,當使用preempt_enable()開關打開時,會檢查_TIF_NEED_RESCHED,進行調度,
從上可以總結下:
1、所有調度的發生都是出于內核態,中斷也是出于內核態,不會有調度出現在用戶態,
2、所有調度的都在schedule函式中發生,
Linux、C/C++技術交流群:【960994558】整理了一些個人覺得比較好的學習書籍技術教學視頻資料共享在里面(包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒體,CDN,P2P,K8S,Docker,TCP/IP,協程,DPDK等等.),有需要的可以自行添加哦!~
2、調度代碼邏輯
代碼呼叫層次簡單提一下,方便需要擼原始碼的同學理理思路,
schedule -> __schedule -> pick_next_task -> fail_sched_class.pick_next_task_fair
-> update_curr, pick_next_entity, context_switch
schedule:通過preempt_disable()首先關閉內核搶占,然后呼叫__schedule,
__schedule:smp_processor_id()獲取當前運行的cpu id,rq = cpu_rq(cpu_id),獲取當前cpu的調度佇列rq
pick_next_task:遍歷所有調度的sched_class,并呼叫sched_class.pick_next_task方法,實時行程的sched_class在鏈表前段,會被優先遍歷并且呼叫,以保證實時行程優先被調度,同時本函式進行優化,如果rq -> nr_running == rq -> cfs.h_nr_running,表示佇列中的行程數 == cfs調度器中的行程數,即所有行程都是普通行程,則直接使用cfs調度器, ps:pick_next_task會完成行程調度,被調度出的行程會在此處暫時結束,當從pick_next_task回傳的時候已經是下一次再將該行程調入cpu之后才執行,這塊會在context_switch中詳細講,
pick_next_task_fair:如果是公平調度器,則呼叫fail_sched_class.pick_next_task_fair,其包含update_curr, pick_next_entity, context_switch三個函式,
update_curr:更新當前行程的vruntime,然后更新紅黑樹和cfs_rq -> min_vruntime以及left_most,
pick_next_entity:選擇紅黑樹的left_most,比較和當前行程和left_most是否是同一行程,如果不是則進行context_switch,
3、context switch(背景關系切換)
這是行程調度最難的部分,因為涉及硬體,linux也會支持不同的硬體體系,不過搞懂了背景關系切換,對于硬體和linux會有更深入的了解,
介紹背景關系切換前,需要介紹下相關的資料結構:內核堆疊、thread_struct、tss,
1、內核堆疊:行程進入內核態后使用內核堆疊,和用戶堆疊完全隔離,task_struct -> stack指向該行程的內核堆疊,大小一般為8k,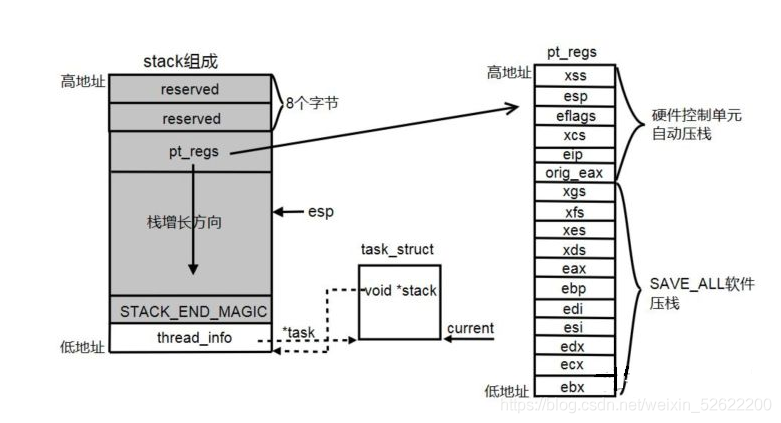
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
整個內核堆疊用union表示,thread_info和stack共用一段存盤空間,thread_info占用低地址,在pt_regs和STACK_END_MAGIC之間,就是內核代碼的運行堆疊,當內核堆疊增長超過STACK_END_MAGIC就會報內核堆疊溢位,
thread_info:存盤內核態運行的一些資訊,如指向task_struct的task指標,使得陷入內核態之后仍然能夠找到當前行程的task_struct,還包括是否允許內核中斷的preemt_count開關等等,
struct thread_info {
unsigned long flags; /* low level flags */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
int preempt_count; /* 0 => preemptable, <0 => bug */
int cpu; /* cpu */
};
pt_regs:存盤用戶態的硬體背景關系(ps:用戶態),用戶態 -> 內核態后,由于使用的堆疊、記憶體地址空間、代碼段等都不同,所以用戶態的eip、esp、ebp等需要保存現場,內核態 -> 用戶態時再將堆疊中的資訊恢復到硬體,由于行程調度一定會在內核態的schedule函式,用戶態的所有硬體資訊都保存在pt_regs中了,SAVE_ALL指令就是將用戶態的cpu暫存器值保存如內核堆疊,RESTORE_ALL就是將pt_regs中的值恢復到暫存器中,這兩個指令在介紹中斷的時候還會提到,
TSS(task state segment):這是intel為上層做行程切換提供的硬體支持,還有一個TR(task register)暫存器專門指向這個記憶體區域,當TR指標值變更時,intel會將當前所有暫存器值存放到當前行程的tss中,然后再講切換行程的目標tss值加載后暫存器中,其結構如下: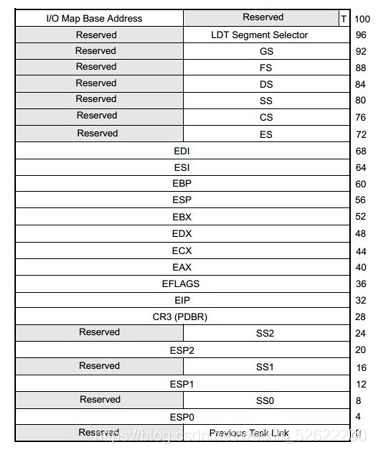
這里很多人都會有疑問,不是有內核堆疊的pt_regs存盤硬體背景關系了嗎,為什么還要有tss?前文說過,行程切換都是在內核態,而pt_regs是保存的用戶態的硬體背景關系,tss用于保存內核態的硬體背景關系,
但是linux并沒有買賬使用tss,因為linux實作行程切換時并不需要所有暫存器都切換一次,如果使用tr去切換tss就必須切換全部暫存器,性能開銷會很高,這也是intel設計的敗筆,沒有把這個功能做的更加的開放導致linux沒有用,linux使用的是軟切換,主要使用thread_struct,tss僅使用esp0這個值,用于行程在用戶態 -> 內核態時,硬體會自動將該值填充到esp暫存器,在初始化時僅為每1個cpu僅系結一個tss,然后tr指標一直指向這個tss,永不切換,
4、thread_struct:一個和硬體體系強相關的結構體,用來存盤內核態切換時的硬體背景關系,
struct thread_struct {
unsigned long rsp0;
unsigned long rsp;
unsigned long userrsp; /* Copy from PDA */
unsigned long fs;
unsigned long gs;
unsigned short es, ds, fsindex, gsindex;
/* Hardware debugging registers */
....
/* fault info */
unsigned long cr2, trap_no, error_code;
/* floating point info */
union i387_union i387 __attribute__((aligned(16)));
/* IO permissions. the bitmap could be moved into the GDT, that would make
switch faster for a limited number of ioperm using tasks. -AK */
int ioperm;
unsigned long *io_bitmap_ptr;
unsigned io_bitmap_max;
/* cached TLS descriptors. */
u64 tls_array[GDT_ENTRY_TLS_ENTRIES];
} __attribute__((aligned(16)));
5、行程切換邏輯主要分為兩部分:1)switch__mm_irqs_off:切換行程記憶體地址空間,對于每個行程都有一個行程記憶體地址空間,是一個以行程隔離的虛擬記憶體地址空間,所以此處也需要切換,包括頁表等,后面后詳細講到,2)switch_to:切換暫存器和堆疊,
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
struct mm_struct *mm, *oldmm;
......
mm = next->mm;
oldmm = prev->active_mm;
......
switch_mm_irqs_off(oldmm, mm, next);
......
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
在switch_to中直接呼叫匯編__switch_to_asm,進入__switch_to_asm前,eax存盤prev task(當前行程,即將被換出)的task_struct指標,edx存盤next task(即將被換入的行程)的task_struct指標,
/*
* %eax: prev task
* %edx: next task
*/
ENTRY(__switch_to_asm)
/*
* Save callee-saved registers
* This must match the order in struct inactive_task_frame
*/
pushl %ebp
pushl %ebx
pushl %edi
pushl %esi
pushfl
/* switch stack */
movl %esp, TASK_threadsp(%eax)
movl TASK_threadsp(%edx), %esp
....
/* restore callee-saved registers */
popfl
popl %esi
popl %edi
popl %ebx
popl %ebp
jmp __switch_to
END(__switch_to_asm)
1)將prev task的ebp、ebx、edi、esi、eflags暫存器值壓入prev task的內核堆疊,
2)TASK_threadsp是從task_struct -> thread_struct -> sp獲取esp指標,在switch stack階段,首先保存prev task內核堆疊的esp指標到thread_struct -> sp,然后將next的thread_struct -> sp恢復到esp暫存器,此后所有的操作都在next task的內核堆疊上運行,
只要完成了esp暫存器的切換,基本就完成了行程的切換最核心的一步,因為通過esp找到next task的內核堆疊,然后就能在內核堆疊中找到其他暫存器的值(步驟1壓入的暫存器值)和通過thread_info找到task_struct.thread_struct,
3)將next task的eflags、esi、edi、ebx、ebp pop到對應的寄存,和步驟1push的順序正好相反,
__switch_to:
struct task_struct * __switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread;
struct thread_struct *next = &next_p->thread;
......
int cpu = smp_processor_id();
struct tss_struct *tss = &per_cpu(cpu_tss, cpu);
......
load_TLS(next, cpu);
......
this_cpu_write(current_task, next_p);
/* Reload esp0 and ss1. This changes current_thread_info(). */
load_sp0(tss, next);
......
return prev_p;
}
1)load_TLS:加載next task的TLS(行程區域變數)到CPU的GDT(全域描述符表,global descriptor table)的TLS中,關于GDT和TLS后面中斷的時候會著重講這兩個結構,
2)load_sp0:將next task的esp0加載到tss中,esp和esp0的區別是前者是用戶態堆疊的esp,后者是內核堆疊的esp,當從用戶態進入內核態(ring0優先級)時,硬體會自動將esp = tss - > esp0,切換esp后,再進行彈堆疊等操作回復其他的暫存器,如switch宏后半部分一樣,
記憶體虛擬空間、暫存器、內核堆疊都恢復了,還有一個重要的EIP(指令指標暫存器)還沒有恢復,但linux的做法是不恢復EIP暫存器,
1)當prev -> next內核堆疊完成切換后(假設prev是A行程,next是B行程),EIP仍然指向switch_to函式,因為A行程是在執行到switch_to的時候結束的,此時對于行程B,因為上次被換出的時候一定是在內核態且也是執行到switch_to函式,所以即使不切換EIP,EIP的指向也是正確的,對于next task就應該指向switch_to函式,只是內核堆疊變化了,執行內核代碼段的背景關系變化了,而且內核態的代碼段是唯一的,各行程公用,
2)此時next_task的switch_to函式繼續執行直到完成,然后內核堆疊進行彈堆疊操作,彈出switch_to的堆疊幀,同時彈出上一堆疊幀的EIP指標的值到EIP暫存器,恢復next_task的運行,如下,在進行函式呼叫時,需要壓入堆疊幀,壓入堆疊幀前需要先push EIP,當彈出堆疊幀的時候恢復到EIP,比如A行程中是a -> b -> c -> switch_to,此時彈出switch_to的堆疊幀后,會把c的EIP恢復到eip暫存器,恢復c函式的運行,
switch_to(prev, next, last):還有一個關鍵點,switch_to為什么是三個引數?而且被強制編譯為暫存器傳遞引數,對于一次行程切換,A -> B,prev = A,next = B,但當再次切換回A時,就不一定是B了,可能是C,但是在再次切換回A時,A的內核堆疊prev = A,next = B,就會丟失A的前序行程 C,而context_switch中最后一個函式finish_task_switch(prev)此時要求傳入的prev = C,以執行一些鎖的釋放和硬體體系的一些回呼,
此時就增加了一個last引數,是一個輸出引數,
1)A -> B的時候,switch_to(A, B, A),此時prev = last,
2)當C -> A的時候,switch_to(C, A, C),此時eax = C,當已經切換到A時,會將eax的值賦值給A內核堆疊中的last變數,此時prev變數的值也會變為C,這樣保證A的前序行程C不丟失,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/254783.html
標籤:其他
下一篇:STM32F103輸入捕獲實驗