Py之seaborn:資料可視化seaborn庫的柱狀圖、箱線圖(置信區間圖)、散點圖/折線圖、核密度圖/等高線圖、盒形圖/小提琴圖/LV多框圖的簡介、使用方法之最強攻略(建議收藏)
導讀:資料可視化是以客觀資料為主體,從資料角度窺探這個世界;目的是描述真實,洞察未知;從浩如煙海的復雜資料中理出頭緒,化繁為簡,變成看得見的財富,要讓行動的決策人在短時間內看得懂,從而實作更高效的決策,它主要是借助于圖形化手段,清晰有效地傳達與溝通資訊,但是,這并不就意味著資料可視化就一定因為要實作其功能用途而令人感到枯燥乏味,或者是為了看上去絢麗多彩而顯得極端復雜,為了有效地傳達思想概念,美學形式與功能需要齊頭并進,通過直觀地傳達關鍵的方面與特征,從而實作對于相當稀疏而又復雜的資料集的深入洞察,
目錄
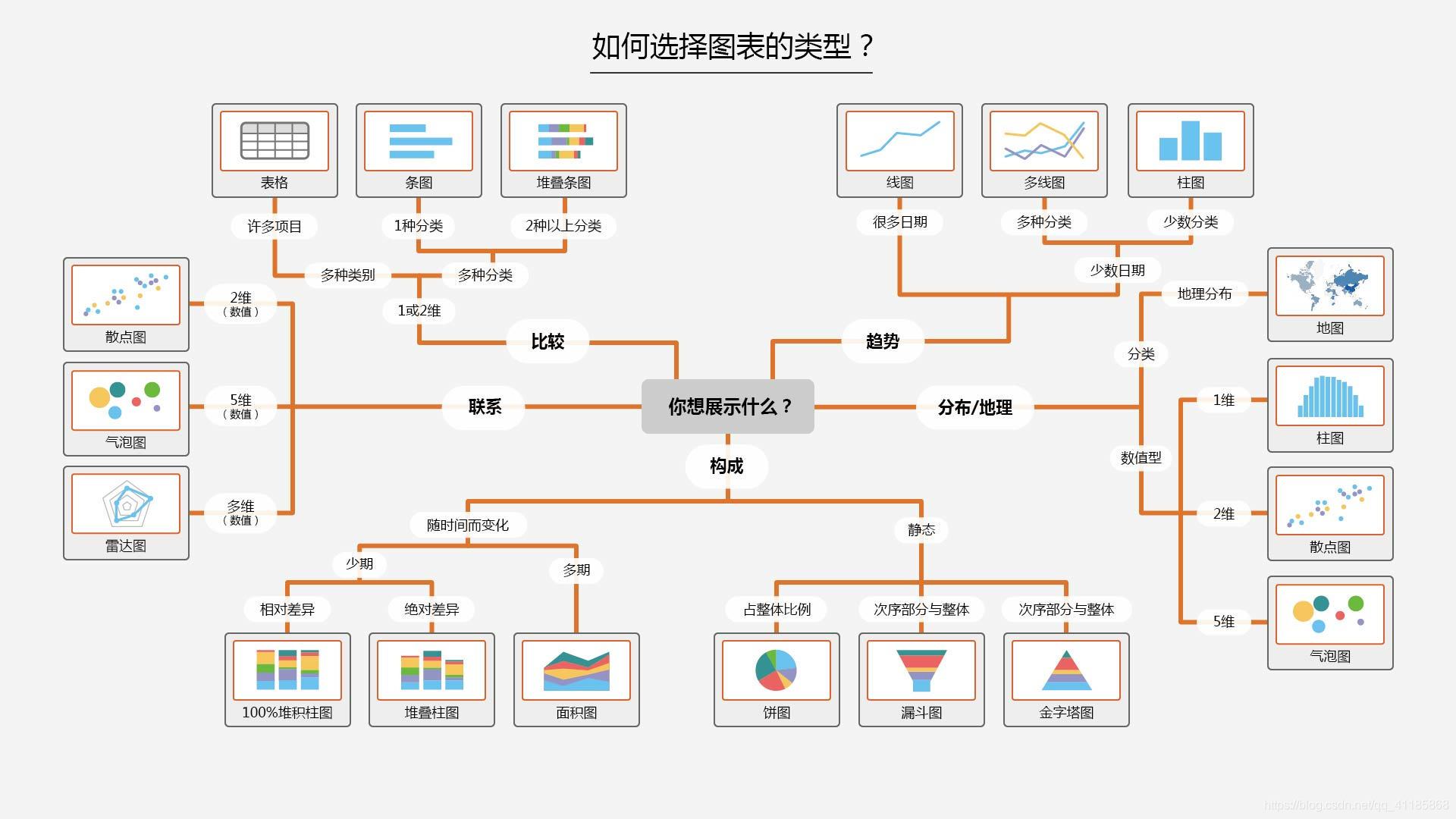
一、如何選擇圖表型別?
二、seaborn庫中單獨繪圖的11種函式講解:資料可視化Seaborn庫的柱狀圖、箱線圖(置信區間圖)、散點圖/折線圖、核密度圖/等高線圖、盒形圖/小提琴圖/LV多框圖的簡介、使用方法之最強攻略(建議收藏)
1、countplot函式:柱狀圖(類別特征計算重復個數)
2、catplot函式:柱狀圖、箱型圖(置信區間)、散點圖、小提琴圖等
(1)、CatPlotByG
(2)、CatPlotByHG
3、barplot函式:條形圖可視化
(1)、BarPlot
(2)、BarPlotByV
(3)、BarPlotBy2V
4、pointplot函式:點估計和置信區間可視化(誤差條)
5、stripplot函式:散點圖可視化
6、relplot函式:散點圖/折線圖可視化
7、regplot函式:散點線性回歸分析圖/置信區間圖可視化
(1)、default
(2)、單獨,用log(x)擬合回歸模型并截斷模型預測
8、kdeplot函式:核密度等高線圖可視化
9、boxplot函式:盒形圖可視化
10、violinplot函式:小提琴圖可視化
11、boxenplot函式:LV多框圖可視化
相關文章
Py之seaborn:seaborn庫的簡介、安裝、使用方法之詳細攻略
一、如何選擇圖表型別?
二、seaborn庫中單獨繪圖的11種函式講解:資料可視化Seaborn庫的柱狀圖、箱線圖(置信區間圖)、散點圖/折線圖、核密度圖/等高線圖、盒形圖/小提琴圖/LV多框圖的簡介、使用方法之最強攻略(建議收藏)
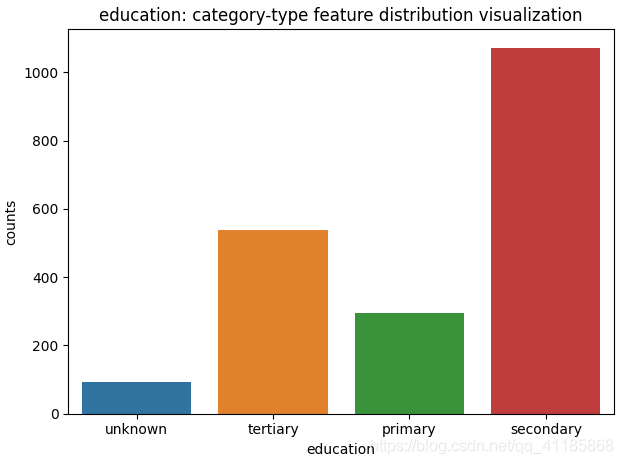
1、countplot函式:柱狀圖(類別特征計算重復個數)
seaborn.countplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, dodge=True, ax=None, **kwargs)官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.countplot.html?highlight=countplot#seaborn.countplot
| Show the counts of observations in each categorical bin using bars. A count plot can be thought of as a histogram across a categorical, instead of quantitative, variable. The basic API and options are identical to those for barplot(), so you can compare counts across nested variables. Input data can be passed in a variety of formats, including: Vectors of data represented as lists, numpy arrays, or pandas Series objects passed directly to the x, y, and/or hue parameters. A “long-form” DataFrame, in which case the x, y, and hue variables will determine how the data are plotted. A “wide-form” DataFrame, such that each numeric column will be plotted. An array or list of vectors. | 使用條形顯示每個分類箱中的觀察值的個數, 計數圖可以看作是一個分類變數的直方圖,而不是定量變數,基本API和選項與barplot()相同,因此可以跨嵌套變數比較計數, 輸入資料可以以多種格式傳遞,包括: 表示為串列、numpy陣列或pandas系列物件的資料向量,直接傳遞給x、y和/或hue引數, 一個“long-form”資料幀,在這種情況下,x, y和hue變數將決定資料如何繪制, 一種“wide-form”資料幀,這樣每個數字列都將被繪制出來, 向量的陣列或串列, |
| In most cases, it is possible to use numpy or Python objects, but pandas objects are preferable because the associated names will be used to annotate the axes. Additionally, you can use Categorical types for the grouping variables to control the order of plot elements.
This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type. | 在大多數情況下,可以使用numpy或Python物件,但pandas物件更合適,因為關聯的名稱將用于注釋坐標軸,此外,您可以為分組變數使用類別型別來控制繪圖元素的順序,
該函式總是將其中一個變數視為類別變數,并在相關軸上的順序位置(0,1,…n)繪制資料,即使資料具有數字或日期型別, |
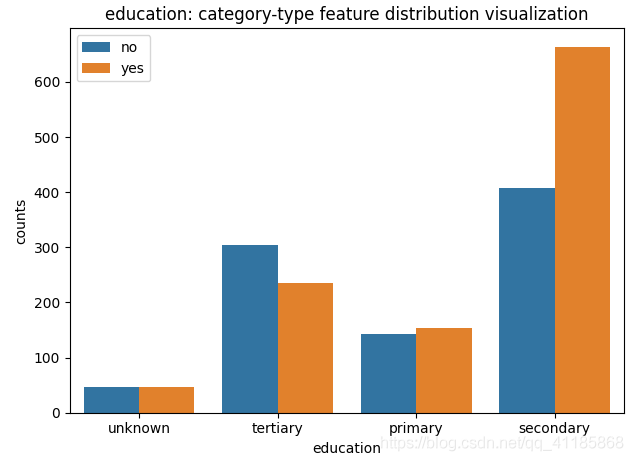
2、catplot函式:柱狀圖、箱型圖(置信區間)、散點圖、小提琴圖等
seaborn.catplot(*, x=None, y=None, hue=None, data=None, row=None, col=None, col_wrap=None, estimator=<function mean at 0x7fecadf1cee0>, ci=95, n_boot=1000, units=None, seed=None, order=None, hue_order=None, row_order=None, col_order=None, kind='strip', height=5, aspect=1, orient=None, color=None, palette=None, legend=True, legend_out=True, sharex=True, sharey=True, margin_titles=False, facet_kws=None, **kwargs)官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.catplot.html?highlight=catplot#seaborn.catplot
| Figure-level interface for drawing categorical plots onto a FacetGrid. This function provides access to several axes-level functions that show the relationship between a numerical and one or more categorical variables using one of several visual representations. The kind parameter selects the underlying axes-level function to use:
Categorical scatterplots: stripplot() (with kind="strip"; the default) swarmplot() (with kind="swarm")
Categorical distribution plots: boxplot() (with kind="box") violinplot() (with kind="violin") boxenplot() (with kind="boxen")
Categorical estimate plots: pointplot() (with kind="point") barplot() (with kind="bar") countplot() (with kind="count") | 用于在FacetGrid上繪制分類圖的圖形級界面, 這個函式提供了對幾個軸級函式的訪問,這些函式使用一種可視表示表示數值和一個或多個分類變數之間的關系,kind引數選擇要使用的axis級函式:
分類散點圖: stripplot() (with kind="strip"; the default) swarmplot() (with kind="swarm"
分類分布繪圖: boxplot() (with kind="box") violinplot() (with kind="violin") boxenplot() (with kind="boxen")
分類預測繪圖: pointplot() (with kind="point") barplot() (with kind="bar") countplot() (with kind="count") |
| Extra keyword arguments are passed to the underlying function, so you should refer to the documentation for each to see kind-specific options.
Note that unlike when using the axes-level functions directly, data must be passed in a long-form DataFrame with variables specified by passing strings to x, y, hue, etc.
As in the case with the underlying plot functions, if variables have a categorical data type, the levels of the categorical variables, and their order will be inferred from the objects. Otherwise you may have to use alter the dataframe sorting or use the function parameters (orient, order, hue_order, etc.) to set up the plot correctly.
This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type. | 額外的關鍵字引數被傳遞給底層函式,因此您應該參考每個函式的檔案來查看特定種類的選項,
請注意,與直接使用ax級函式不同的是,資料必須在一個長格式的資料框架中傳遞,通過向x、y、hue等傳遞字串來指定變數,
與基礎繪圖函式的情況一樣,如果變數具有類別資料型別,則類別變數的級別及其順序將從物件中推斷出來,否則,你可能不得不使用alter the dataframe sorted或使用函式引數(orient, order, hue_order等)來正確設定繪圖,
該函式總是將其中一個變數視為類別變數,并在相關軸上的順序位置(0,1,…n)繪制資料,即使資料具有數字或日期型別, |
(1)、CatPlotByG
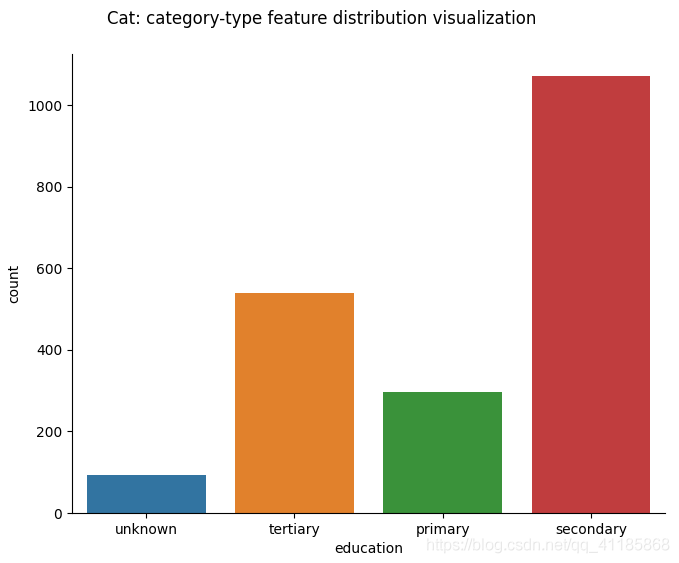
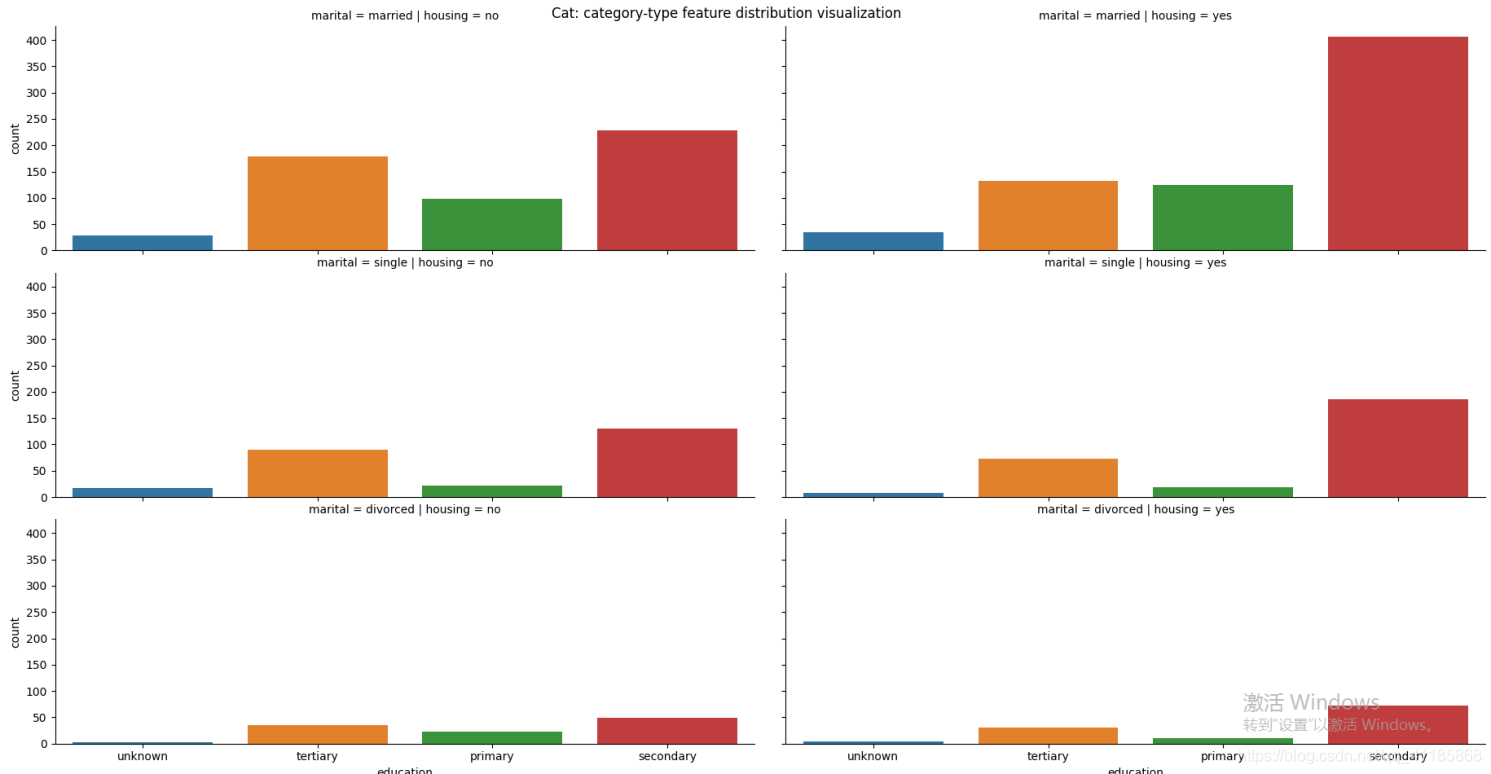
(2)、CatPlotByHG
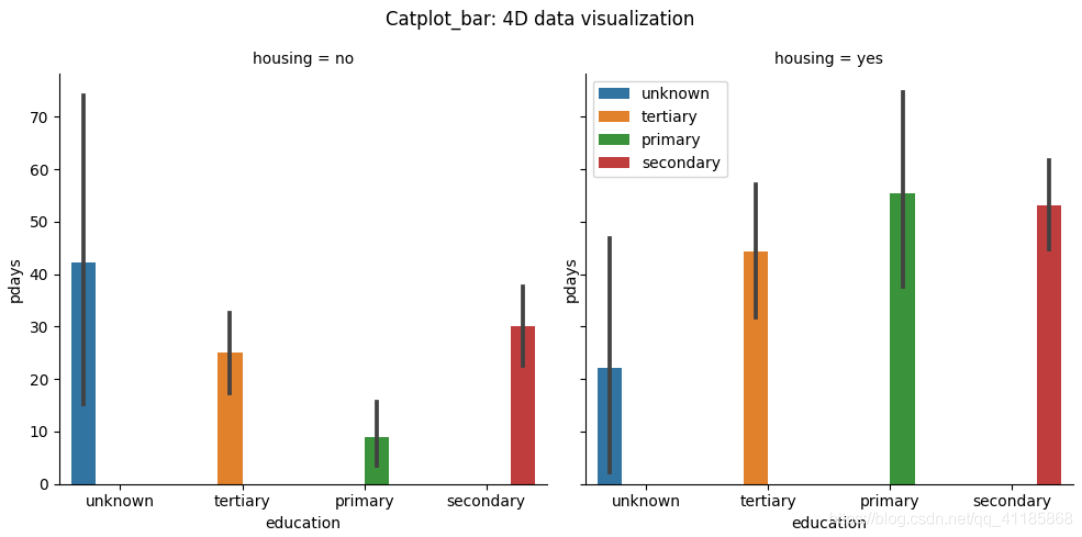
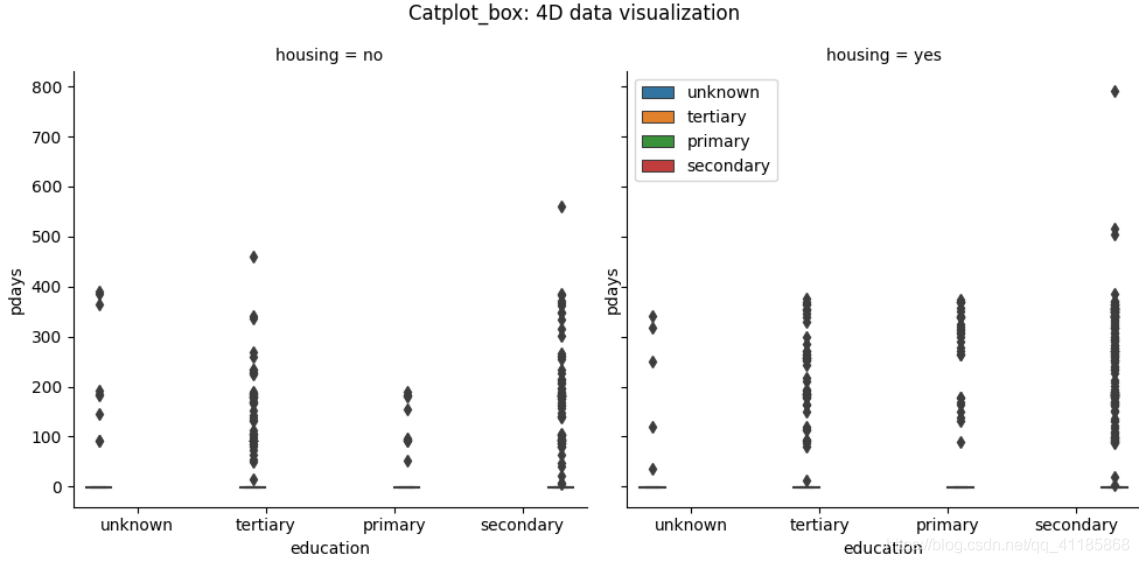
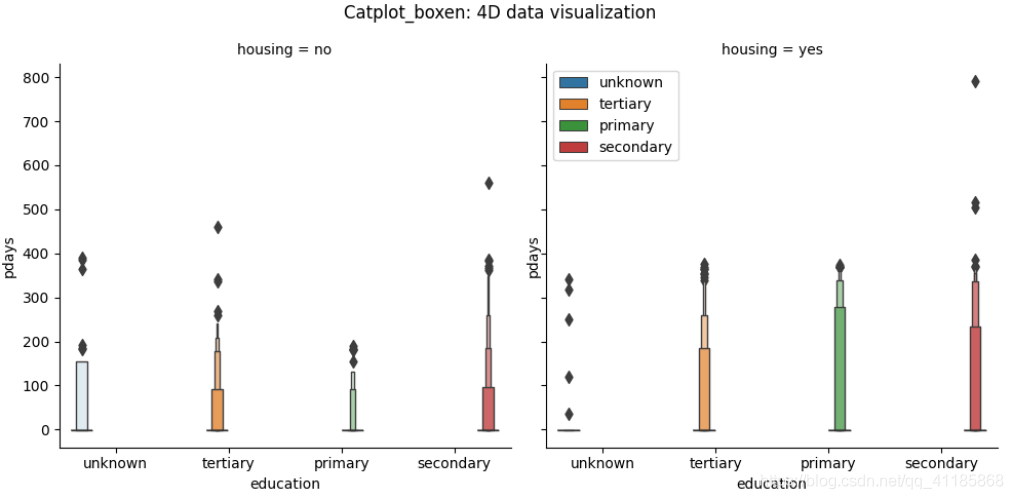
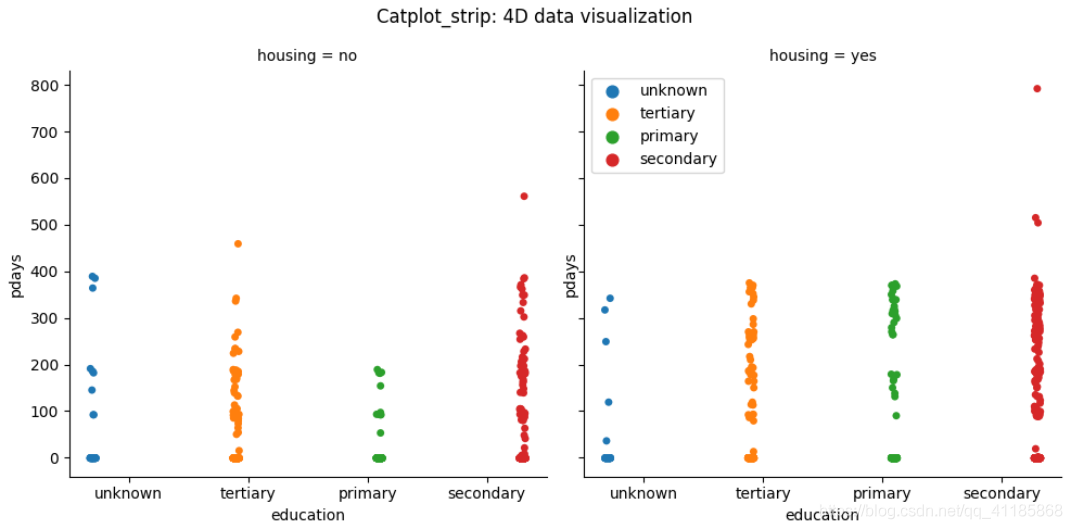
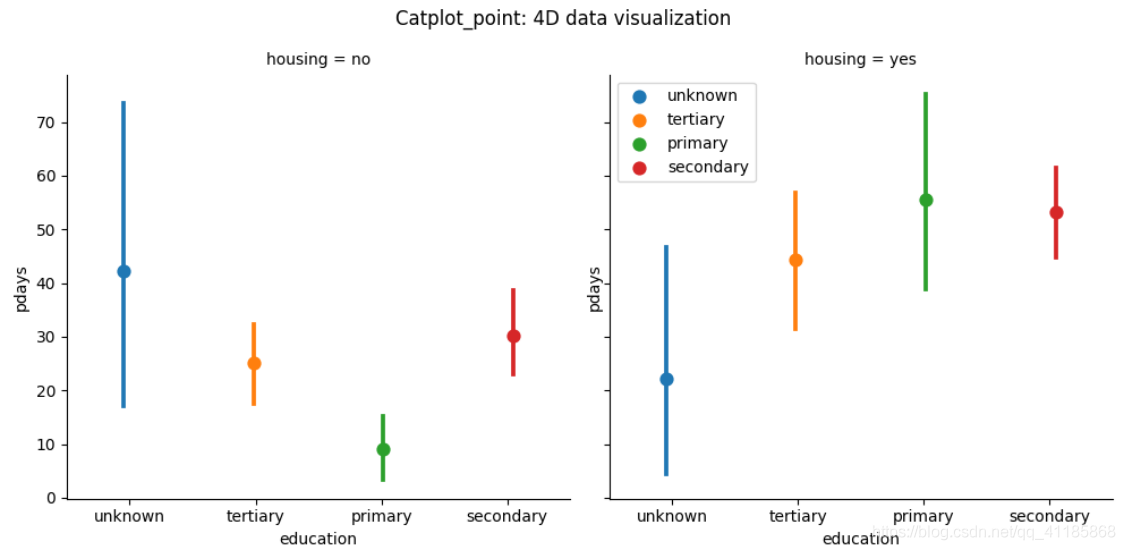
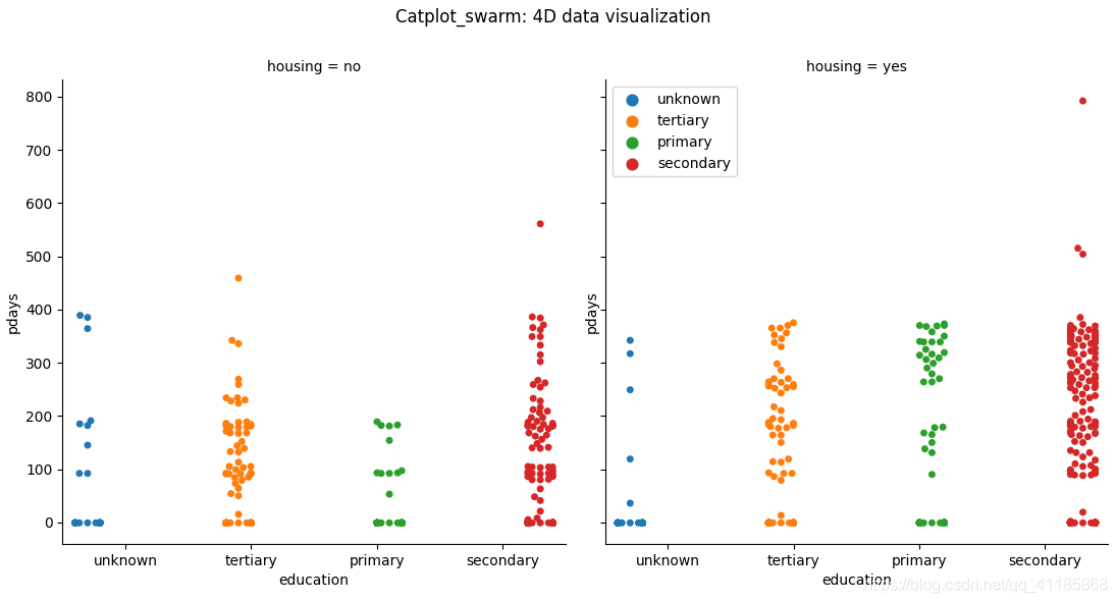
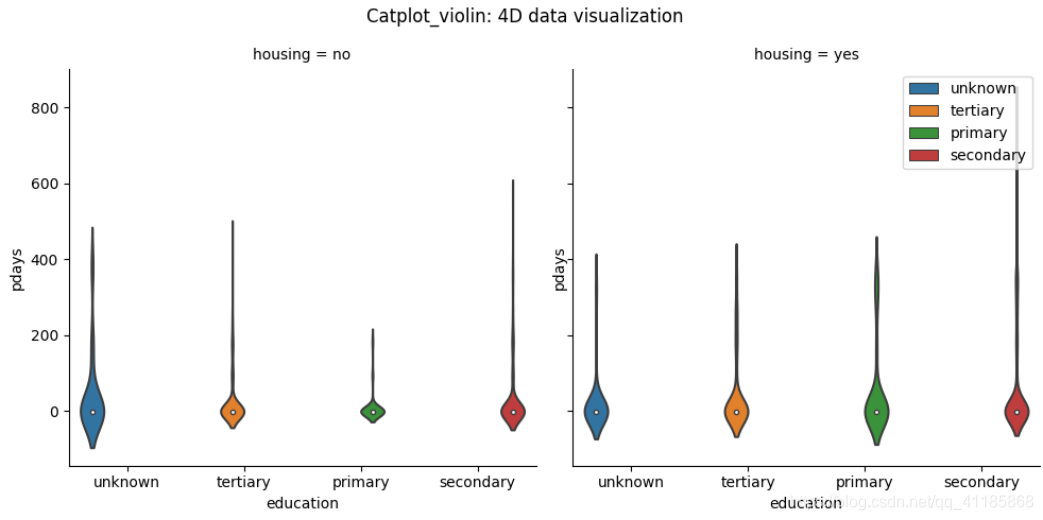
3、barplot函式:條形圖可視化
seaborn.barplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, estimator=<function mean at 0x7fecadf1cee0>, ci=95, n_boot=1000, units=None, seed=None, orient=None, color=None, palette=None, saturation=0.75, errcolor='.26', errwidth=None, capsize=None, dodge=True, ax=None, **kwargs)僅第2變數必須為數值型
條形圖表示數值變數與每個矩形高度的中心趨勢的估計值(默認平均值),并使用誤差條提供關于該估計值附近的不確定性的一些指示,誤差條越長,資料離散程度越大,資料越不穩定,
官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.barplot.html?highlight=barplot#seaborn.barplot
| Show point estimates and confidence intervals as rectangular bars. A bar plot represents an estimate of central tendency for a numeric variable with the height of each rectangle and provides some indication of the uncertainty around that estimate using error bars. Bar plots include 0 in the quantitative axis range, and they are a good choice when 0 is a meaningful value for the quantitative variable, and you want to make comparisons against it. For datasets where 0 is not a meaningful value, a point plot will allow you to focus on differences between levels of one or more categorical variables. It is also important to keep in mind that a bar plot shows only the mean (or other estimator) value, but in many cases it may be more informative to show the distribution of values at each level of the categorical variables. In that case, other approaches such as a box or violin plot may be more appropriate. | 用矩形條顯示點估計和置信區間, 條形圖表示對每個矩形高度的數值變數的集中趨勢的估計,并使用誤差條提供了一些關于估計的不確定性的指示,條形圖在數量軸范圍中包括0,當0是數量變數的一個有意義的值,并希望與之進行比較時,條形圖是一個很好的選擇, 對于0不是一個有意義的值的資料集,點圖將允許你關注一個或多個分類變數的不同級別, 同樣重要的是要記住,條形圖只顯示平均值(或其他估計值),但在許多情況下,顯示分類變數每一級的值分布可能會提供更多資訊,在這種情況下,其他方法,如盒子或小提琴情節可能更合適, |
| Input data can be passed in a variety of formats, including:
In most cases, it is possible to use numpy or Python objects, but pandas objects are preferable because the associated names will be used to annotate the axes. Additionally, you can use Categorical types for the grouping variables to control the order of plot elements. This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type. | 輸入資料可以以多種格式傳遞,包括:
在大多數情況下,可以使用numpy或Python物件,但pandas物件更合適,因為關聯的名稱將用于注釋坐標軸,此外,您可以為分組變數使用類別型別來控制繪圖元素的順序, 該函式總是將其中一個變數視為類別變數,并在相關軸上的順序位置(0,1,…n)繪制資料,即使資料具有numeric 或date 型別, |
(1)、BarPlot
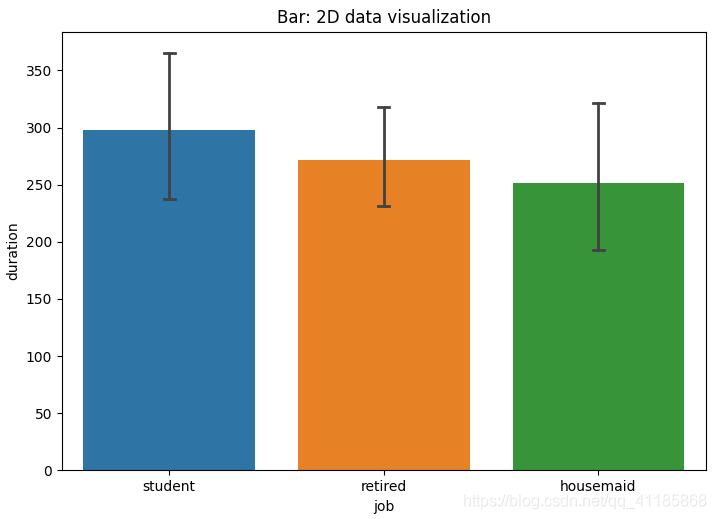
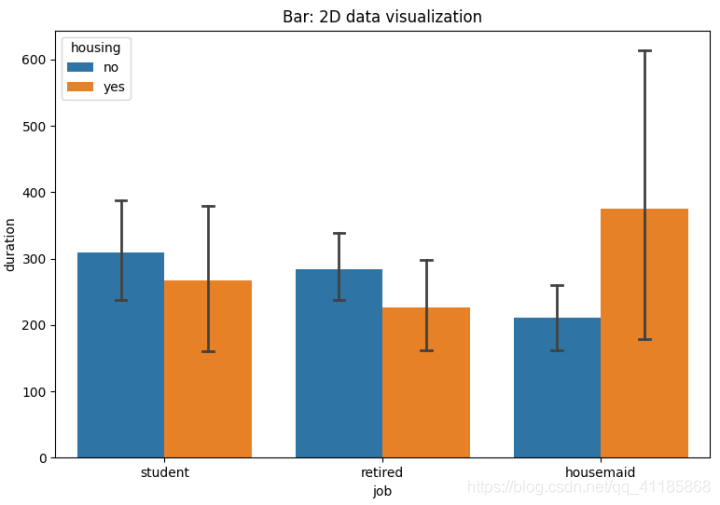
(2)、BarPlotByV
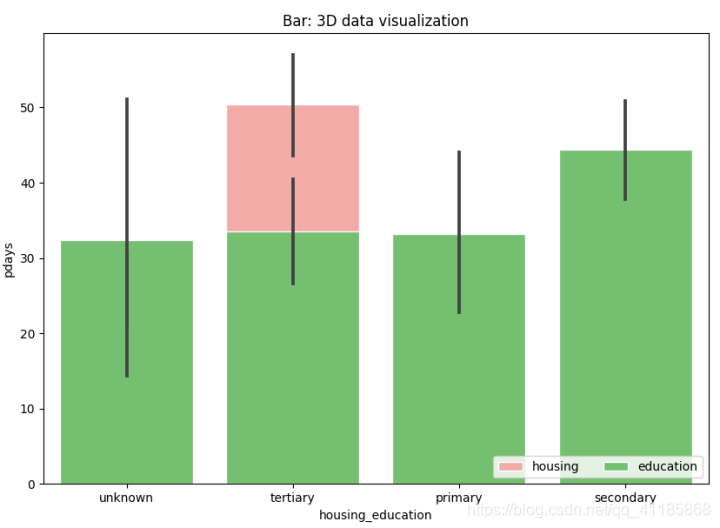
(3)、BarPlotBy2V
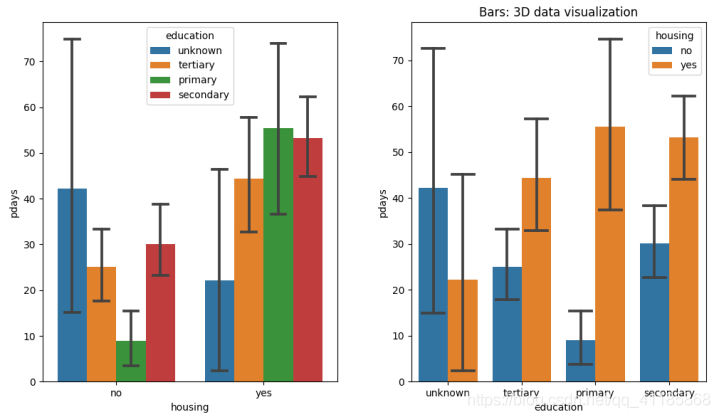
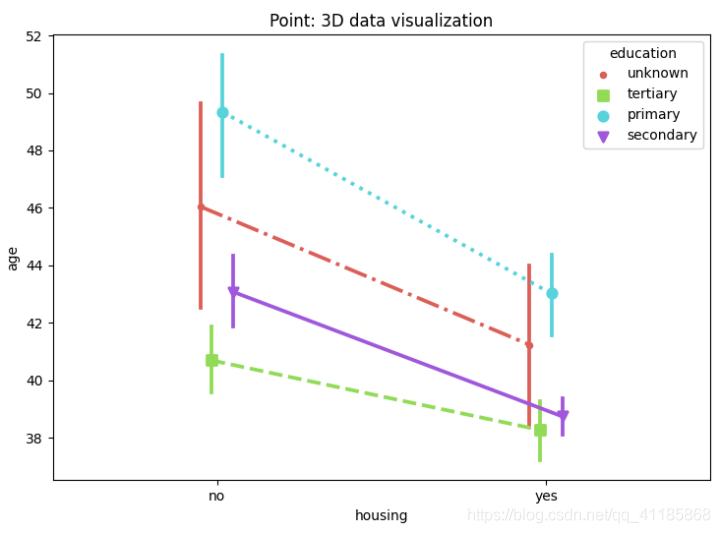
4、pointplot函式:點估計和置信區間可視化(誤差條)
seaborn.pointplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, estimator=<function mean at 0x7fecadf1cee0>, ci=95, n_boot=1000, units=None, seed=None, markers='o', linestyles='-', dodge=False, join=True, scale=1, orient=None, color=None, palette=None, errwidth=None, capsize=None, ax=None, **kwargs)僅第2變數必須為數值型
置信區間估計:圖中的點為該組資料的平均值點,豎線則為誤差條,默認兩個均值點會相連接
官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.pointplot.html?highlight=pointplot#seaborn.pointplot
| Show point estimates and confidence intervals using scatter plot glyphs. A point plot represents an estimate of central tendency for a numeric variable by the position of scatter plot points and provides some indication of the uncertainty around that estimate using error bars. Point plots can be more useful than bar plots for focusing comparisons between different levels of one or more categorical variables. They are particularly adept at showing interactions: how the relationship between levels of one categorical variable changes across levels of a second categorical variable. The lines that join each point from the same hue level allow interactions to be judged by differences in slope, which is easier for the eyes than comparing the heights of several groups of points or bars. It is important to keep in mind that a point plot shows only the mean (or other estimator) value, but in many cases it may be more informative to show the distribution of values at each level of the categorical variables. In that case, other approaches such as a box or violin plot may be more appropriate. | 使用散點圖符號顯示點估計和置信區間, 點圖通過散點的位置表示對數值變數的集中趨勢的估計,并使用誤差條提供一些關于估計的不確定性的指示, 點圖比條形圖更有助于集中比較一個或多個分類變數的不同層次,他們特別擅長展示互動作用:一個分類變數的各個層次之間的關系如何在另一個分類變數的各個層次之間發生變化,連接來自同一色調等級的每個點的線條允許通過斜率的差異來判斷互動作用,這比比較幾組點或條的高度更容易, 重要的是要記住點圖只顯示平均值(或其他估計值),但在許多情況下,顯示分類變數的每一級值的分布可能會提供更多的資訊,在這種情況下,其他方法,如盒子或小提琴情節可能更合適, |
| Input data can be passed in a variety of formats, including: Vectors of data represented as lists, numpy arrays, or pandas Series objects passed directly to the x, y, and/or hue parameters. A “long-form” DataFrame, in which case the x, y, and hue variables will determine how the data are plotted. A “wide-form” DataFrame, such that each numeric column will be plotted. An array or list of vectors.
In most cases, it is possible to use numpy or Python objects, but pandas objects are preferable because the associated names will be used to annotate the axes. Additionally, you can use Categorical types for the grouping variables to control the order of plot elements. This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type. | 輸入資料可以以多種格式傳遞,包括: 表示為串列、numpy陣列或pandas系列物件的資料向量,直接傳遞給x、y和/或hue引數,
在大多數情況下,可以使用numpy或Python物件,但pandas物件更合適,因為關聯的名稱將用于注釋坐標軸,此外,您可以為分組變數使用類別型別來控制繪圖元素的順序, 該函式總是將其中一個變數視為類別變數,并在相關軸上的順序位置(0,1,…n)繪制資料,即使資料具有數字或日期型別, |
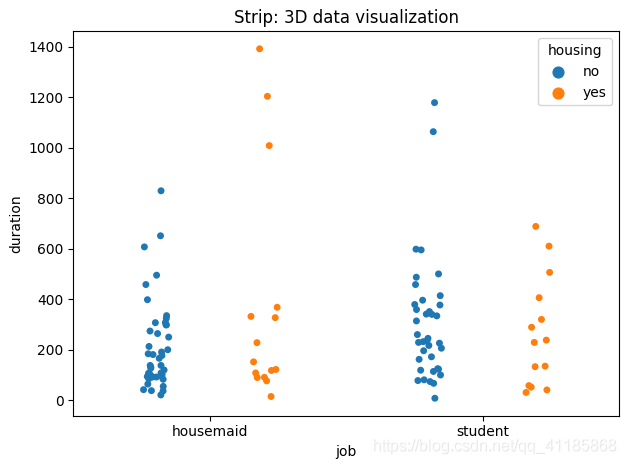
5、stripplot函式:散點圖可視化
seaborn.stripplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, jitter=True, dodge=False, orient=None, color=None, palette=None, size=5, edgecolor='gray', linewidth=0, ax=None, **kwargs)官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.stripplot.html?highlight=stripplot#seaborn.stripplot
| Draw a scatterplot where one variable is categorical. A strip plot can be drawn on its own, but it is also a good complement to a box or violin plot in cases where you want to show all observations along with some representation of the underlying distribution. Input data can be passed in a variety of formats, including: Vectors of data represented as lists, numpy arrays, or pandas Series objects passed directly to the x, y, and/or hue parameters. A “long-form” DataFrame, in which case the x, y, and hue variables will determine how the data are plotted. A “wide-form” DataFrame, such that each numeric column will be plotted. An array or list of vectors. | 繪制一個散點圖,其中一個變數是類別變數, 條形圖可以自己繪制,但在您想要顯示所有觀察結果以及一些潛在分布的表示的情況下,它也是盒形圖或小提琴形圖的一個很好的補充,
輸入資料可以以多種格式傳遞,包括: 表示為串列、numpy陣列或pandas系列物件的資料向量,直接傳遞給x、y和/或hue引數, 一個“長格式”資料幀,在這種情況下,x, y和hue變數將決定資料如何繪制, 一種“寬格式”資料幀,這樣每個數字列都將被繪制出來, 向量的陣列或串列,
|
| In most cases, it is possible to use numpy or Python objects, but pandas objects are preferable because the associated names will be used to annotate the axes. Additionally, you can use Categorical types for the grouping variables to control the order of plot elements.
This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type. | 在大多數情況下,可以使用numpy或Python物件,但pandas物件更合適,因為關聯的名稱將用于注釋坐標軸,此外,您可以為分組變數使用類別型別來控制情節元素的順序, 該函式總是將其中一個變數視為類別變數,并在相關軸上的順序位置(0,1,…n)繪制資料,即使資料具有數字或日期型別, |
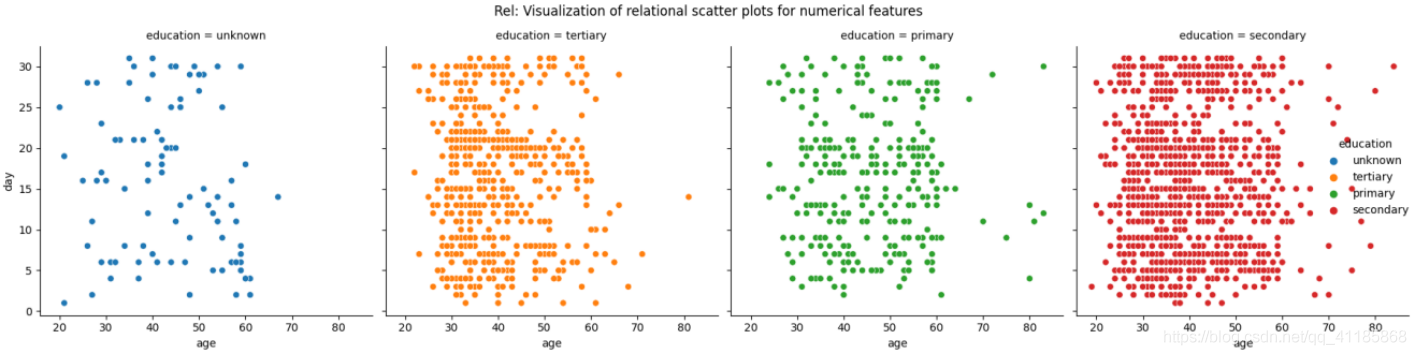
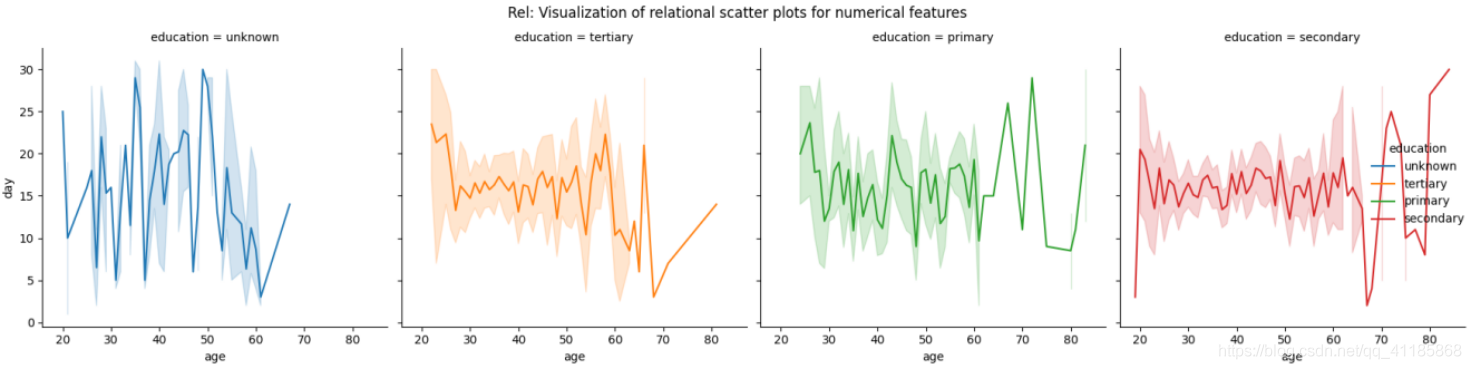
6、relplot函式:散點圖/折線圖可視化
seaborn.relplot(*, x=None, y=None, hue=None, size=None, style=None, data=None, row=None, col=None, col_wrap=None, row_order=None, col_order=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=None, dashes=None, style_order=None, legend='auto', kind='scatter', height=5, aspect=1, facet_kws=None, units=None, **kwargs)官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.relplot.html?highlight=relplot#seaborn.relplot
| Figure-level interface for drawing relational plots onto a FacetGrid. This function provides access to several different axes-level functions that show the relationship between two variables with semantic mappings of subsets. The kind parameter selects the underlying axes-level function to use: scatterplot() (with kind="scatter"; the default) lineplot() (with kind="line") Extra keyword arguments are passed to the underlying function, so you should refer to the documentation for each to see kind-specific options. The relationship between x and y can be shown for different subsets of the data using the hue, size, and style parameters. These parameters control what visual semantics are used to identify the different subsets. It is possible to show up to three dimensions independently by using all three semantic types, but this style of plot can be hard to interpret and is often ineffective. Using redundant semantics (i.e. both hue and style for the same variable) can be helpful for making graphics more accessible. See the tutorial for more information. | 用于在FacetGrid上繪制關系圖的圖形級介面, 這個函式提供了對幾個不同的軸級函式的訪問,這些函式顯示了兩個具有子集語意映射的變數之間的關系,kind引數選擇要使用的axis級函式: scatterplot() (with kind="scatter"; the default) lineplot() (with kind="line") 額外的關鍵字引數被傳遞給底層函式,因此您應該參考每個函式的檔案來查看特定種類的選項, x和y之間的關系可以通過使用hue、size和style引數來顯示資料的不同子集,這些引數控制使用什么視覺語意來標識不同的子集,通過使用這三種語意型別,我們可以獨立呈現出三個維度,但這種繪圖風格很難解釋,而且通常是無效的,使用冗余的語意(例如,相同變數的色調和樣式)有助于讓圖形更容易訪問, 有關更多資訊,請參閱本教程, |
| The default treatment of the hue (and to a lesser extent, size) semantic, if present, depends on whether the variable is inferred to represent “numeric” or “categorical” data. In particular, numeric variables are represented with a sequential colormap by default, and the legend entries show regular “ticks” with values that may or may not exist in the data. This behavior can be controlled through various parameters, as described and illustrated below. After plotting, the FacetGrid with the plot is returned and can be used directly to tweak supporting plot details or add other layers. | 如果存在色相(以及較小程度上的大小)語意的默認處理,則取決于該變數是被推斷為表示“numeric”還是“categorical”資料,具體來說,默認情況下,數值變數用順序的colormap表示,并且圖例條目顯示有規律的“刻度”,刻度的值可能存在于資料中,也可能不存在,這種行為可以通過各種引數來控制,如下面的描述和說明所示, 繪制后,回傳帶有plot的FacetGrid,可以直接用于調整支持的plot細節或添加其他層, |
7、regplot函式:散點線性回歸分析圖/置信區間圖可視化
seaborn.regplot(*, x=None, y=None, data=None, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, seed=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=True, dropna=True, x_jitter=None, y_jitter=None, label=None, color=None, marker='o', scatter_kws=None, line_kws=None, ax=None)官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.regplot.html?highlight=regplot#seaborn.regplot
| Plot data and a linear regression model fit. There are a number of mutually exclusive options for estimating the regression model. See the tutorial for more information. | 圖資料與線性回歸模型擬合, 估計回歸模型有許多互斥的選項,有關更多資訊,請參閱本教程, |
(1)、default
單獨,x_estimator=np.mean, # 如果x為離散資料,顯示其平均值,
(2)、單獨,用log(x)擬合回歸模型并截斷模型預測
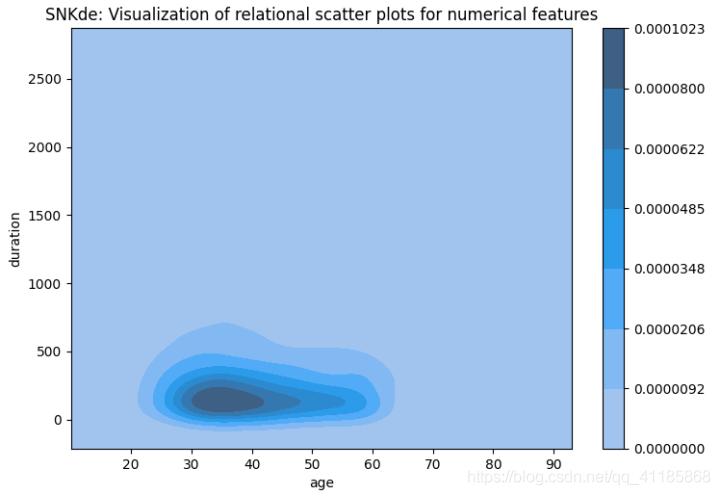
8、kdeplot函式:核密度等高線圖可視化
seaborn.kdeplot(x=None, *, y=None, shade=None, vertical=False, kernel=None, bw=None, gridsize=200, cut=3, clip=None, legend=True, cumulative=False, shade_lowest=None, cbar=False, cbar_ax=None, cbar_kws=None, ax=None, weights=None, hue=None, palette=None, hue_order=None, hue_norm=None, multiple='layer', common_norm=True, common_grid=False, levels=10, thresh=0.05, bw_method='scott', bw_adjust=1, log_scale=None, color=None, fill=None, data=None, data2=None, **kwargs)官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.kdeplot.html?highlight=kdeplot#seaborn.kdeplot
| Plot univariate or bivariate distributions using kernel density estimation. A kernel density estimate (KDE) plot is a method for visualizing the distribution of observations in a dataset, analagous to a histogram. KDE represents the data using a continuous probability density curve in one or more dimensions. The approach is explained further in the user guide. | 使用核密度估計繪制單變數或雙變數分布, 核密度估計(KDE)圖是一種可視化資料集中觀測值分布的方法,類似于直方圖,KDE使用一個或多個維度的連續概率密度曲線表示資料, 該方法在用戶指南中有進一步的解釋, |
9、boxplot函式:盒形圖可視化
seaborn.boxplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, fliersize=5, linewidth=None, whis=1.5, ax=None, **kwargs)官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.boxplot.html?highlight=boxplot#seaborn.boxplot
| Draw a box plot to show distributions with respect to categories. A box plot (or box-and-whisker plot) shows the distribution of quantitative data in a way that facilitates comparisons between variables or across levels of a categorical variable. The box shows the quartiles of the dataset while the whiskers extend to show the rest of the distribution, except for points that are determined to be “outliers” using a method that is a function of the inter-quartile range.
Input data can be passed in a variety of formats, including: Vectors of data represented as lists, numpy arrays, or pandas Series objects passed directly to the x, y, and/or hue parameters. A “long-form” DataFrame, in which case the x, y, and hue variables will determine how the data are plotted. A “wide-form” DataFrame, such that each numeric column will be plotted. An array or list of vectors. | 畫一個盒形圖來顯示與類別特征有關的分布, 盒形圖(或盒須圖)顯示了定量資料的分布,以促進變數之間的比較或分類變數的層次,盒形圖顯示資料集的四分位數,而須擴展顯示分布的其余部分,除了使用四分位數間范圍函式的方法確定為“例外值”的點,
輸入資料可以以多種格式傳遞,包括: 表示為串列、numpy陣列或pandas系列物件的資料向量,直接傳遞給x、y和/或hue引數, 一個“長格式”資料幀,在這種情況下,x, y和hue變數將決定資料如何繪制, 一種“寬格式”資料幀,這樣每個數字列都將被繪制出來, 向量的陣列或串列, |
| In most cases, it is possible to use numpy or Python objects, but pandas objects are preferable because the associated names will be used to annotate the axes. Additionally, you can use Categorical types for the grouping variables to control the order of plot elements. This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type. | 在大多數情況下,可以使用numpy或Python物件,但pandas物件更合適,因為關聯的名稱將用于注釋坐標軸,此外,您可以為分組變數使用類別型別來控制繪圖元素的順序, 該函式總是將其中一個變數視為類別變數,并在相關軸上的順序位置(0,1,…n)繪制資料,即使資料具有數字或日期型別, |
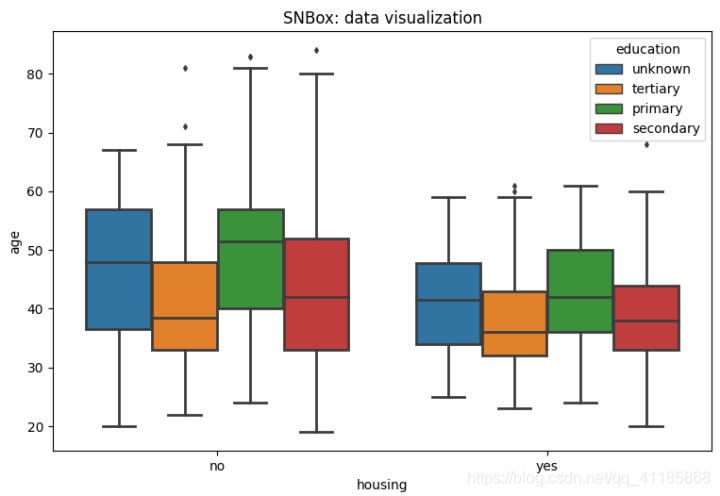
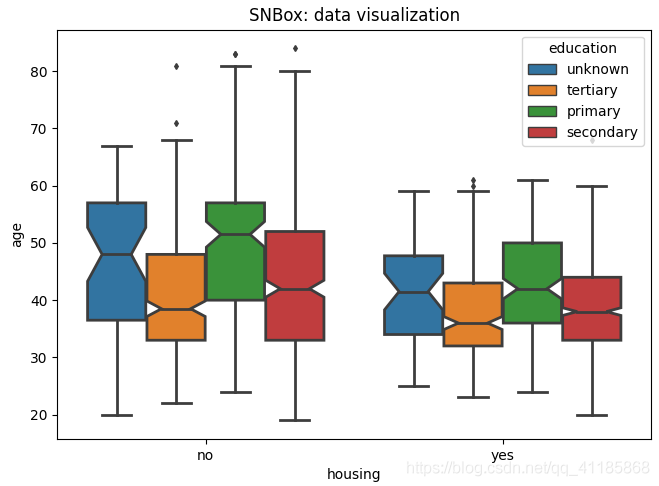
10、violinplot函式:小提琴圖可視化
seaborn.violinplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, bw='scott', cut=2, scale='area', scale_hue=True, gridsize=100, width=0.8, inner='box', split=False, dodge=True, orient=None, linewidth=None, color=None, palette=None, saturation=0.75, ax=None, **kwargs)官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.violinplot.html?highlight=violinplot#seaborn.violinplot
| Draw a combination of boxplot and kernel density estimate. A violin plot plays a similar role as a box and whisker plot. It shows the distribution of quantitative data across several levels of one (or more) categorical variables such that those distributions can be compared. Unlike a box plot, in which all of the plot components correspond to actual datapoints, the violin plot features a kernel density estimation of the underlying distribution. This can be an effective and attractive way to show multiple distributions of data at once, but keep in mind that the estimation procedure is influenced by the sample size, and violins for relatively small samples might look misleadingly smooth. Input data can be passed in a variety of formats, including: Vectors of data represented as lists, numpy arrays, or pandas Series objects passed directly to the x, y, and/or hue parameters. A “long-form” DataFrame, in which case the x, y, and hue variables will determine how the data are plotted. A “wide-form” DataFrame, such that each numeric column will be plotted. An array or list of vectors. | 繪制箱線圖和核密度估計的組合, 小提琴圖的作用類似于盒子和胡須圖,它顯示了定量資料在一個(或多個)分類變數的幾個層次上的分布,這樣就可以比較這些分布,盒形圖的所有圖組件都對應于實際的資料點,與盒形圖不同,小提琴形圖的特點是對底層分布的核密度估計, 這是一種有效且有吸引力的同時顯示多個資料分布的方法,但請記住,估計程序受到樣本大小的影響,相對較小的樣本可能看起來平滑得令人誤解,
輸入資料可以以多種格式傳遞,包括: 表示為串列、numpy陣列或pandas系列物件的資料向量,直接傳遞給x、y和/或hue引數, 一個“長格式”資料幀,在這種情況下,x, y和hue變數將決定資料如何繪制, 一種“寬格式”資料幀,這樣每個數字列都將被繪制出來, 向量的陣列或串列, |
| In most cases, it is possible to use numpy or Python objects, but pandas objects are preferable because the associated names will be used to annotate the axes. Additionally, you can use Categorical types for the grouping variables to control the order of plot elements. This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type. | 在大多數情況下,可以使用numpy或Python物件,但pandas物件更合適,因為關聯的名稱將用于注釋坐標軸,此外,您可以為分組變數使用類別型別來控制情節元素的順序, 該函式總是將其中一個變數視為類別變數,并在相關軸上的順序位置(0,1,…n)繪制資料,即使資料具有數字或日期型別, |
split=True, # 設定是否拆分小提琴圖,前提條件是第三特征為二類別屬性,嘗試測驗
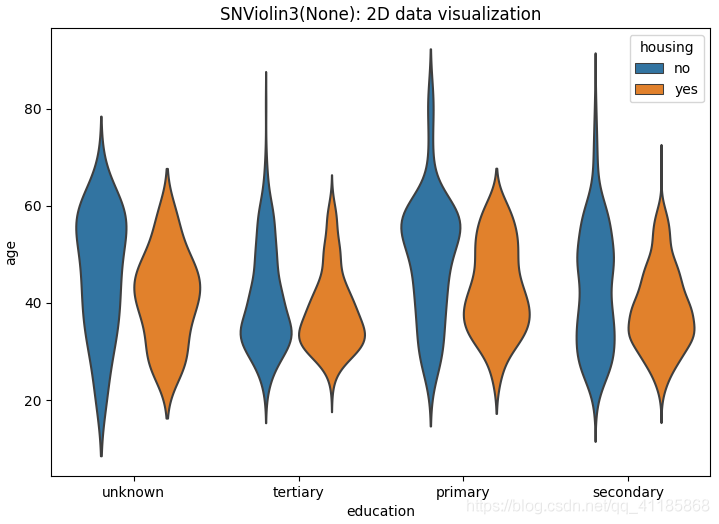
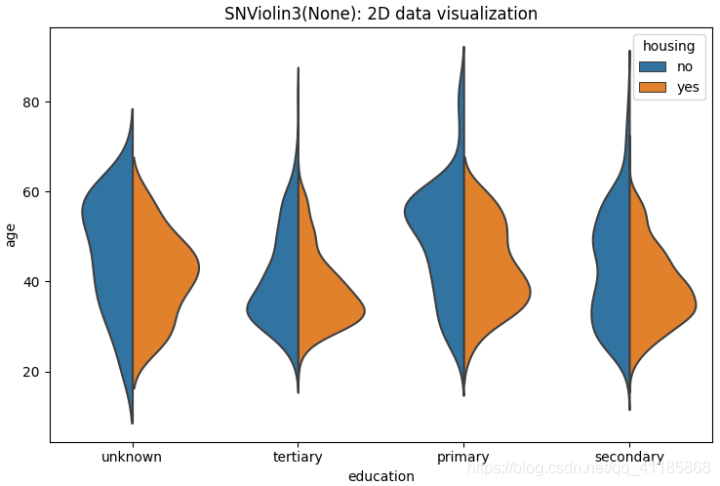
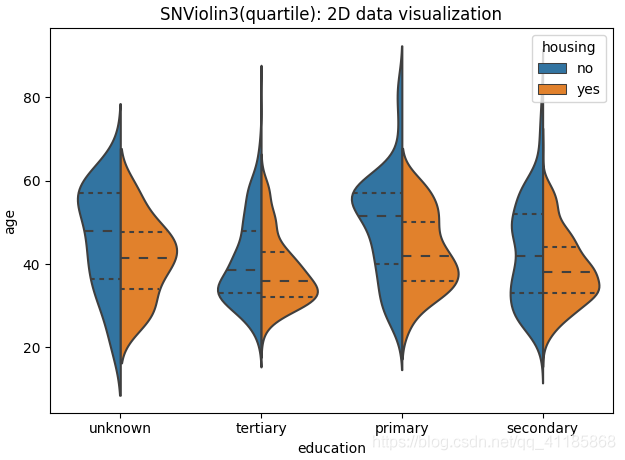
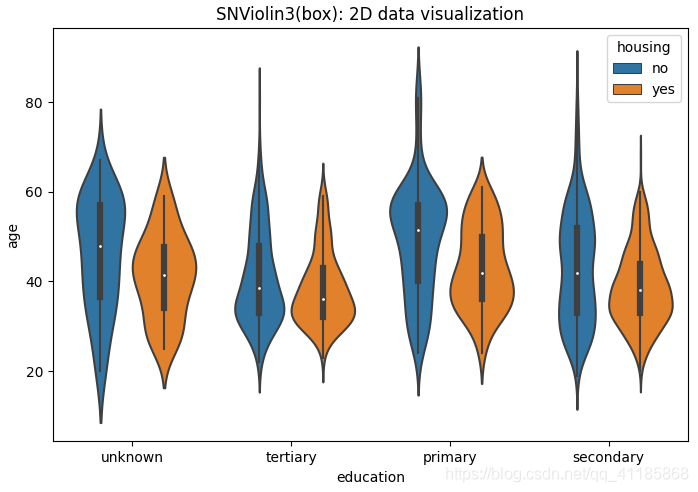
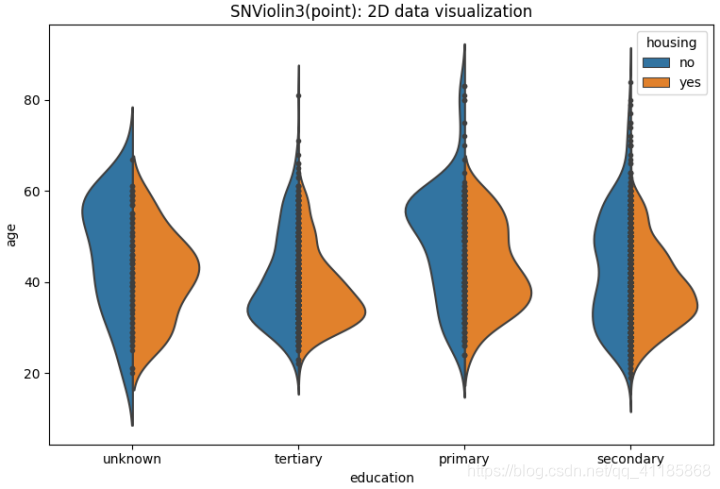
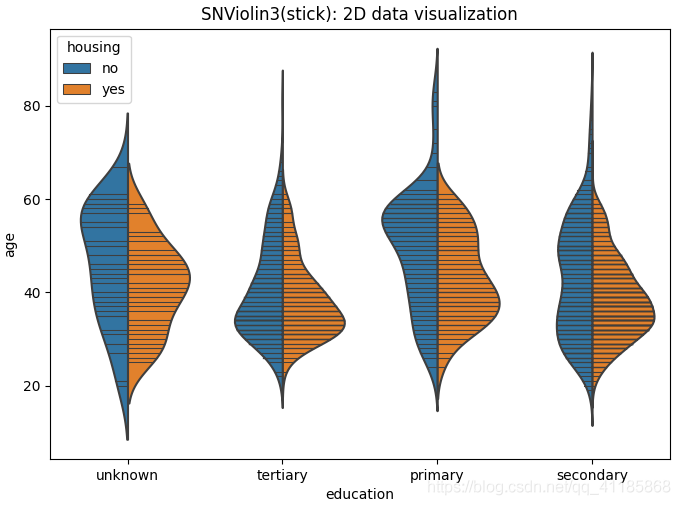
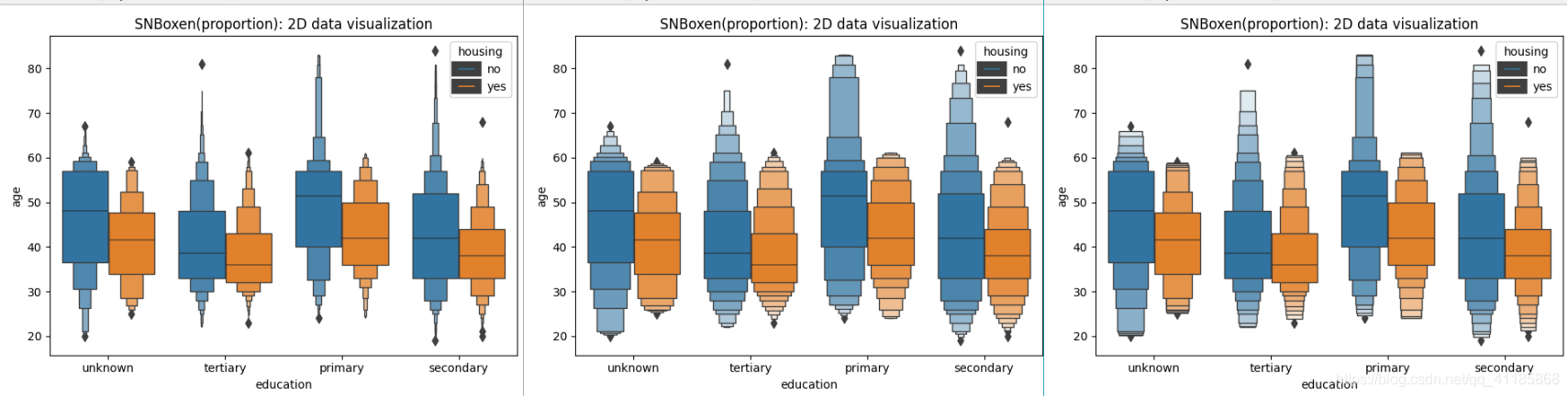
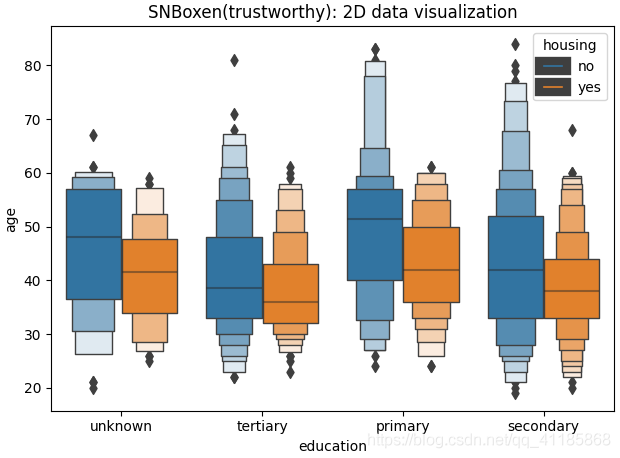
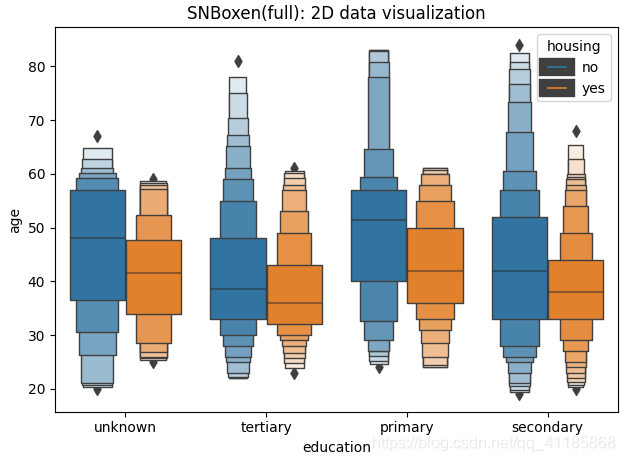
11、boxenplot函式:LV多框圖可視化
seaborn.boxenplot(*, x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, width=0.8, dodge=True, k_depth='tukey', linewidth=None, scale='exponential', outlier_prop=0.007, trust_alpha=0.05, showfliers=True, ax=None, **kwargs)官方檔案解釋:http://seaborn.pydata.org/generated/seaborn.boxenplot.html?highlight=boxenplot#seaborn.boxenplot
| Draw an enhanced box plot for larger datasets. This style of plot was originally named a “letter value” plot because it shows a large number of quantiles that are defined as “letter values”. It is similar to a box plot in plotting a nonparametric representation of a distribution in which all features correspond to actual observations. By plotting more quantiles, it provides more information about the shape of the distribution, particularly in the tails. For a more extensive explanation, you can read the paper that introduced the plot: https://vita.had.co.nz/papers/letter-value-plot.html
Input data can be passed in a variety of formats, including: Vectors of data represented as lists, numpy arrays, or pandas Series objects passed directly to the x, y, and/or hue parameters. A “long-form” DataFrame, in which case the x, y, and hue variables will determine how the data are plotted. A “wide-form” DataFrame, such that each numeric column will be plotted. An array or list of vectors. | 為更大的資料集繪制增強的箱線圖, 這種樣式的圖最初被稱為“字母值”圖,因為它顯示了大量定義為“字母值”的分位數,它類似于用非引數表示一個分布的箱線圖,其中所有的特征都對應于實際的觀察結果,通過繪制更多的分位數,它提供了更多關于分布形狀的資訊,特別是在尾部,要想獲得更廣泛的解釋,你可以閱讀介紹情節的文章: https://vita.had.co.nz/papers/letter-value-plot.html
輸入資料可以以多種格式傳遞,包括: 表示為串列、numpy陣列或pandas系列物件的資料向量,直接傳遞給x、y和/或hue引數, 一個“長格式”資料幀,在這種情況下,x, y和hue變數將決定資料如何繪制, 一種“寬格式”資料幀,這樣每個數字列都將被繪制出來, 向量的陣列或串列, |
| In most cases, it is possible to use numpy or Python objects, but pandas objects are preferable because the associated names will be used to annotate the axes. Additionally, you can use Categorical types for the grouping variables to control the order of plot elements. This function always treats one of the variables as categorical and draws data at ordinal positions (0, 1, … n) on the relevant axis, even when the data has a numeric or date type. | 在大多數情況下,可以使用numpy或Python物件,但pandas物件更合適,因為關聯的名稱將用于注釋坐標軸,此外,您可以為分組變數使用類別型別來控制情節元素的順序, 該函式總是將其中一個變數視為類別變數,并在相關軸上的順序位置(0,1,…n)繪制資料,即使資料具有數字或日期型別, |

 CSDN認證博客專家
華為杯研電賽一等
華為研數模一等獎
國內外AI競十
CSDN認證博客專家
華為杯研電賽一等
華為研數模一等獎
國內外AI競十
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/254785.html
標籤:其他
上一篇:STM32F103輸入捕獲實驗