
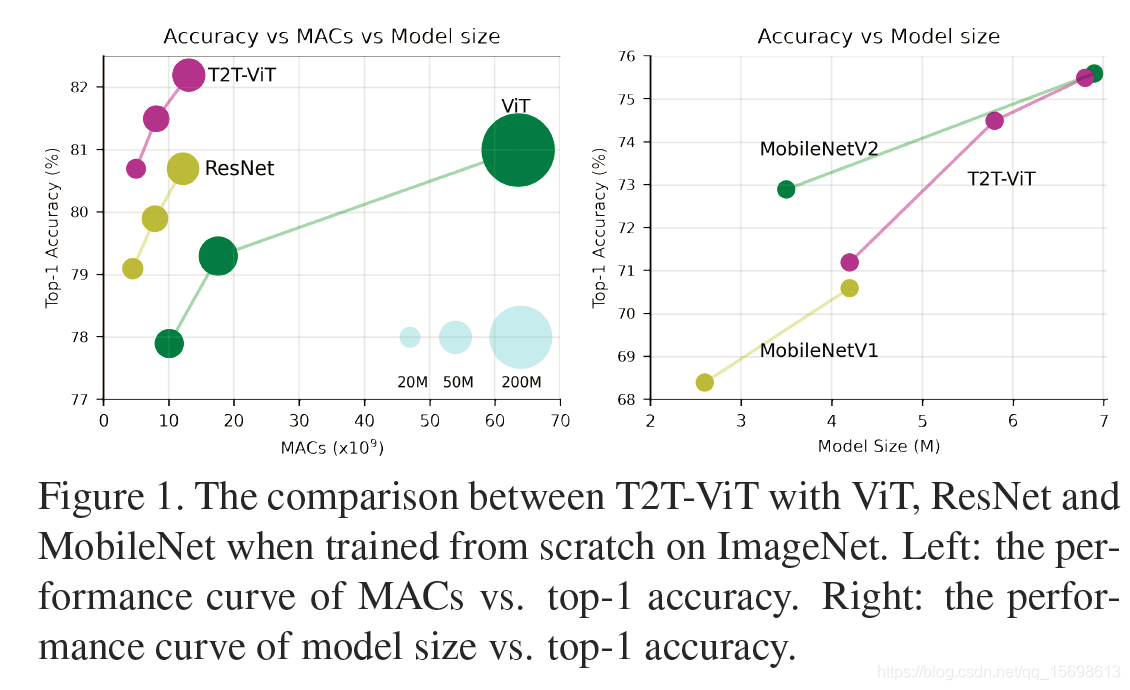
與之前ViT、Detr、Deit等不同之處在于:本文針對ViT的特征多樣性、結構化設計等進行了更深入的思考,提出了一種新穎的Tokens-to-Token機制,用于同時建模影像的區域結構資訊與全域相關性,同時還借鑒了CNN架構設計思想引導ViT的骨干設計,最終,僅僅依賴于ImageNet資料,而無需JFT-300M預訓練,所提方案即可取得全面超越ResNet的性能,且引數量與計算量顯著降低;與此同時,在輕量化方面,所提方法只需簡單減少深度與隱含層維度即可取得優于精心設計的MobileNet系列方案的性能,
分析發現:(1) 輸入影像的簡單token化難以很好的建模近鄰像素間的重要區域結構(比如邊緣、線條等),這就導致了少量樣本時的低效性;(2) 在固定計算負載與有限訓練樣本約束下,ViT中的冗余注意力骨干設計限制了特征的豐富性,
本文的主要貢獻包含以下幾個方面:
-
首次通過精心設計Transformer結構在標準ImageNet資料集上取得了全面超越CNN的性能,而無需在JFT-300M資料進行預訓練;
-
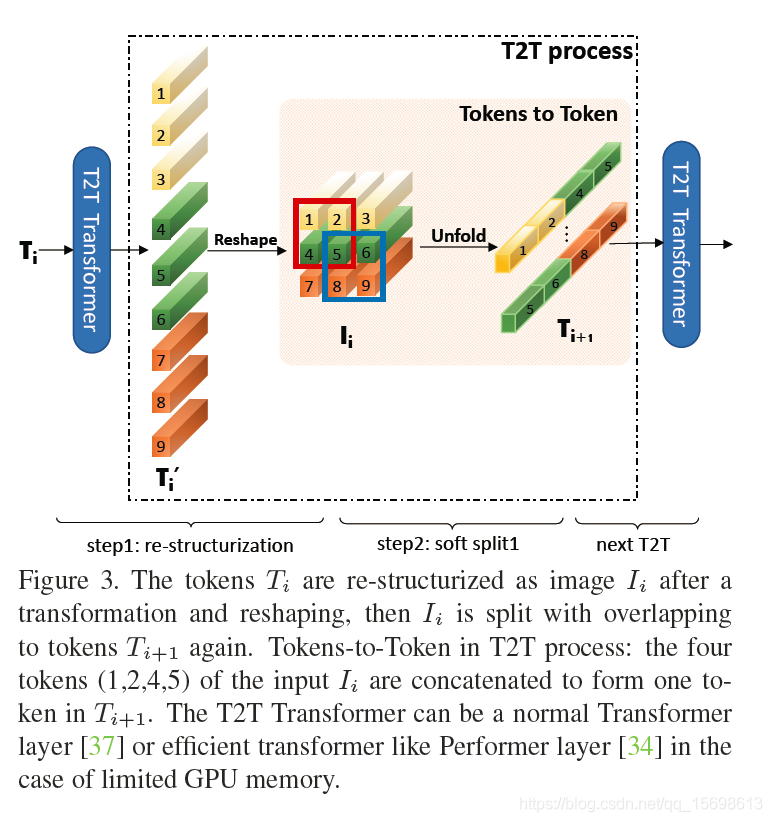
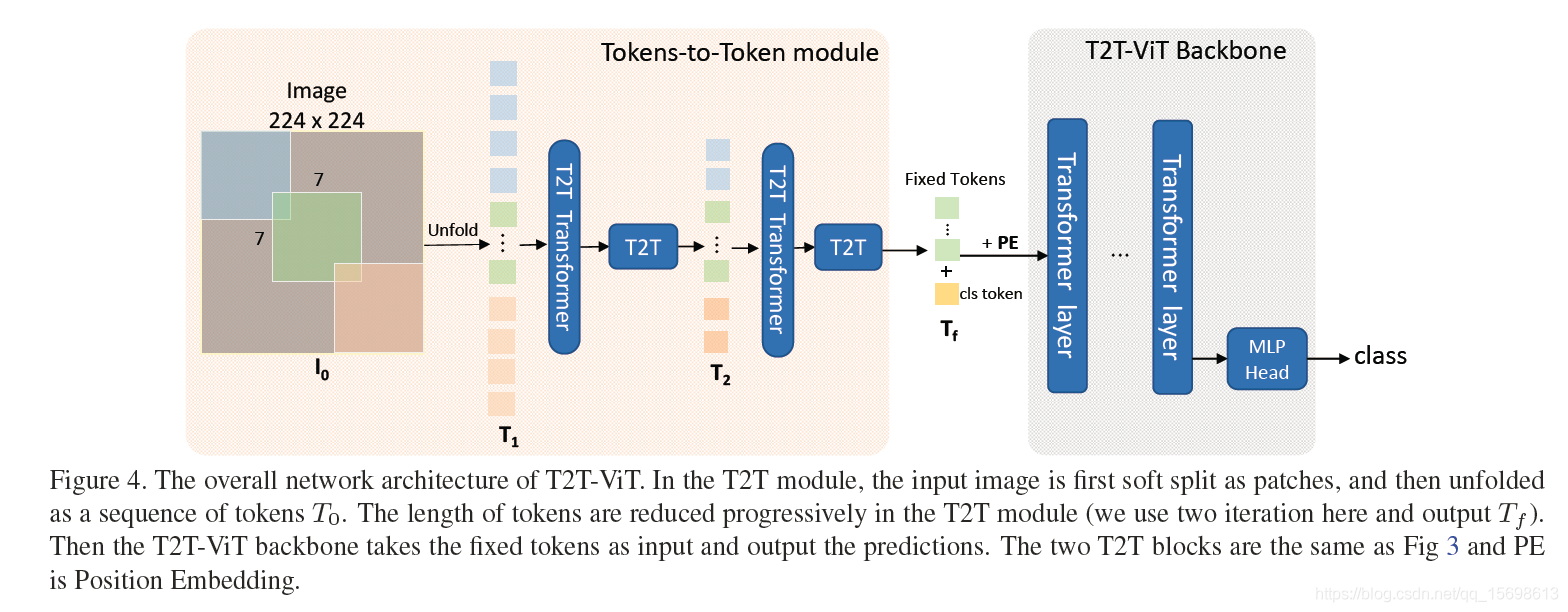
提出一種新穎的漸進式Token化機制用于ViT,并證實了其優越性,所提T2T模塊可以更好的協助每個token建模區域重要結構資訊;
-
CNN的架構設計思想有助于ViT的骨干結構設計并提升其特征豐富性、減少資訊冗余,通過實驗發現:
deep-narrow結構設計非常適合于ViT,

人工智能博士
 CSDN認證博客專家
985AI博士
AI專家
博客專家
CSDN認證博客專家
985AI博士
AI專家
博客專家
CSDN認證博客專家
985AI博士
AI專家
博客專家
王博Kings,985AI博士在讀,CSDN博客專家,華為云專家,是《機器學習手推筆記》、《深度學習手推筆記》等作者,我的微信:Kingsplusa,歡迎交流學習;在人工智能、計算機視覺、無人駕駛等具有豐富的經驗,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/254914.html
標籤:其他
上一篇:云計算學習路線