靈魂三問:
2020年你漲薪了嗎?
2020年你的技術提升了嗎?
對于2020年的自己是否滿意?
“金三銀四”即將到來,作為一年的跳槽季,這是找作業換作業的最佳時機,對于不滿現狀的朋友考慮在這個時間跳槽,但是看看招聘網站,要求玄的要死,面試幾輪之后更是沒有深沒有淺,經過一段時間的接觸之后,內心十分著急,又不知道怎么辦,就是沒有一個具體可執行的計劃,這樣下去導致最壞的結果可能是今年的跳槽可能變成了換坑,跳槽是職業生涯有續線性的增長,無論收入還是title或者平臺,換坑是從這個坑跳到另外一個坑,從而進入一個惡性回圈,給長期職業發展帶來很不利的影響,個人能力的成長長期維持在同一水平線上下浮動,
計劃的意思是了解當下市場招聘環境的變化,并且根據對自己技術勢力的綜合評估對當前的市場行情的預估之后,分析技術差距羅列的一個學習串列,具體細節的實施,學習效果的驗證,要花費多長時間來完成他,每天要投入多少精力學習等等,根據不同的情況來自己把握,
首先給大家分享一份對標騰訊T8(原2.3)職級的技術堆疊,供大家查漏補缺
c/c++ linux服務器開發學習地址:c/c++ linux服務器高級架構師
一、精進基石
1、資料結構與演算法

2、設計模式23種(沒有全部列舉)

3、工程管理

視頻學習地址:設計模式很難嗎?看mark老師如何吊打設計模式
紅黑樹,在Linux內核的那些故事
二、高性能網路設計
1、代碼實作

2、方案分析

視頻學習地址:linux多執行緒之epoll原理剖析與reactor原理及應用
深入理解websocket,為你的專案多條思路
三、基礎組件實作
1、池式結構

2、高性能組件

3、開源組件

視頻學習地址:150行代碼,手把手寫完執行緒池(完整版)
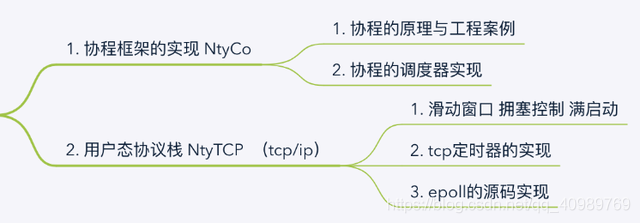
四、協程的原理及實作
五、基礎開源框架
1、skynet

2、zeromq

3、dpdk

視頻學習地址:為什么dpdk越來越受歡迎,看完以后,讓人醍醐灌頂
聊聊linux服務器端高級架構—云風的skynet
六、中間件開發
1、mysql

2、redis

3、nginx

4、mongodb

5、dfs

視頻學習地址:16萬行Nginx原始碼,就該這么讀
七、linux內核
1、行程管理

2、記憶體管理

3、檔案系統

4、設備驅動

視頻學習地址:5個方面分析linux內核架構,讓你對內核不再陌生
linux內核,行程調度器的實作,完全公平調度器 CFS
八、性能分析

九、分布式框架

視頻學習地址:去中心化,p2p,網路穿透一起搞定
其次,跳槽找作業肯定是需要面試的,在這總結一些面試題供大家參考(因為是C/C++的,而鵝廠是cpp的主戰場,所以總結的是鵝廠的一些面試題)
【文章福利】小編還總結了很多其它一線互聯網大廠的面試題,有需要的朋友可以加群812855908領取
C/C++
const
多型
什么類不能被繼承(這個題目非常經典,我當時答出了private但是他說不好,我就沒想到final我以為那個是java的)
網路
網路的位元組序
網路知識 tcp三次握手 各種細節 timewait狀態
tcp 與 udp 區別 概念 適用范圍
TCP四次揮手講一下程序,最后一次ack如果客戶端沒收到怎么辦,為什么揮手不能只有三次,為什么time_wait,
對于socket編程,accept方法是干什么的,在三次握手中屬于第幾次,可以猜一下,為什么這么覺得,
tcp怎么保證有序傳輸的,講下tcp的快速重傳和擁塞機制,知不知道time_wait狀態,這個狀態出現在什么地方,有什么用?
知道udp是不可靠的傳輸,如果你來設計一個基于udp差不多可靠的演算法,怎么設計?
http與https有啥區別?說下https解決了什么問題,怎么解決的?說下https的握手程序,
tcp 粘包半包問題怎么處理?
keepalive 是什么東東?如何使用?
列舉你所知道的tcp選項,并說明其作用,
socket什么情況下可讀?
nginx的epoll模型的介紹以及io多路復用模型
SYN Flood攻擊
流量控制,擁塞控制
TCP和UDP區別,TCP如何保證可靠性,對方是否存活(心跳檢測)
tcpdump抓包,如何分析資料包
tcp如何設定超時時間
基于socket網路編程和tcp/ip協議堆疊,講講從客戶端send()開始,到服務端recv()結束的程序,越細越好
http報文格式
http1.1與http1.0區別,http2.0特性
http3了解嗎
http1.1長連接時,發送一個請求阻塞了,回傳什么狀態碼?
udp呼叫connect有什么作用?
作業系統
行程和執行緒-分別的概念 區別 適用范圍 它們分別的通訊方式 不同通訊方式的區別優缺點
僵尸行程
死鎖是怎么產生的
CPU的執行方式
代碼中遇到行程阻塞,行程僵死,記憶體泄漏等情況怎么排查,
有沒有了解過協程?說下協程和執行緒的區別?
堆是執行緒共有還是私有,堆是行程共有還是私有,堆疊呢
了解過協程嗎(我:攜程???不了解嗚嗚嗚)
共享記憶體的使用實作原理(必考必問,然后共享記憶體段被映射進行程空間之后,存在于行程空間的什么位置?共享記憶體段最大限制是多少?)
c++行程記憶體空間分布(注意各部分的記憶體地址誰高誰低,注意堆疊從高道低分配,堆從低到高分配)
ELF是什么?其大小與程式中全域變數的是否初始化有什么關系(注意.bss段)
使用過哪些行程間通訊機制,并詳細說明(重點)
多執行緒和多行程的區別(重點 面試官最最關心的一個問題,必須從cpu調度,背景關系切換,資料共享,多核cup利用率,資源占用,等等各方面回答,然后有一個問題必須會被問到:哪些東西是一個執行緒私有的?答案中必須包含暫存器,否則悲催)
信號:列出常見的信號,信號怎么處理?
i++是否原子操作?并解釋為什么???????
說出你所知道的各類linux系統的各類同步機制(重點),什么是死鎖?如何避免死鎖(每個技術面試官必問)
列舉說明linux系統的各類異步機制
exit() _exit()的區別?
如何實作守護行程?
linux的記憶體管理機制是什么?
linux的任務調度機制是什么?
標準庫函式和系統呼叫的區別?
補充一個坑爹坑爹坑爹坑爹的問題:系統如何將一個信號通知到行程?(這一題哥沒有答出來)
Linux系統
linux的各種命令 給你場景讓你解決
Linux了解么,查看行程狀態ps,查看cpu狀態 top,查看占用埠的行程號netstat grep
Linux的cpu 100怎么排查,top jstack,日志,gui工具
Linux作業系統了解么
怎么查看CPU負載,怎么查看一個客戶下有多少行程
Linux內核是怎么實作定時器的
gdb怎么查看某個執行緒
core dump有沒有遇到過,gdb怎么除錯
linux如何設定core檔案生成
linux如何設定開機自啟動
linux用過哪些命令、工具
用過哪些工具檢測程式性能,如何定位性能瓶頸的地方
netstat tcpdump ipcs ipcrm (如果這四個命令沒聽說過或者不能熟練使用,基本上可以回家,通過的概率較小 _ ,這四個命令的熟練掌握程度基本上能體現面試者實際開發和除錯程式的經驗)
cpu 記憶體 硬碟 等等與系統性能除錯相關的命令必須熟練掌握,設定修改權限 tcp網路狀態查看 各行程狀態 抓包相關等相關命令 必須熟練掌握
awk sed需掌握
gdb除錯相關的經驗,會被問到
MongoDB
關于大資料存盤的(mongodb hadoop)各種原理 mongodb又問的深入很多
Redis
Redis記憶體資料庫的記憶體指的是共享記憶體么
Redis的持久化方式
Redis和MySQL有什么區別,用于什么場景,
redis有沒有用過,常用的資料結構以及在業務中使用的場景,redis的hash怎么實作的
問了下快取更新的模式,以及會出現的問題和應對思路?
redis的sentinel上投票選舉的問題 raft演算法
redis單執行緒結構有什么優勢?有什么問題? 主要優勢單執行緒,避免執行緒切換產生靜態消耗,缺點是容易阻塞,雖然redis使用io復用epoll和輸入緩沖區把命令按照佇列先進先出輸入等等
你覺得針對redis這些缺點那些命令在redis上不可使用? 比如keys、hgetall等等這些命令 建議用scan等等 這方面闡述
你覺得為什么專案中沒有用mysql而用了es,redis在這里到底起到了什么作用?因為架構上這里理解不清楚,最后回答自己都覺得有漏洞了
你覺得redis什么算有用? 有用? 是說存進去了還是說命中快取?最后把快取命中率是什么說了一遍
你們這邊redis集群是怎么樣子的
平常redis用的多的資料結構是什么,跳表實作,怎么維護索引,當時我說是一個簡單的二分,手寫二分演算法,并且時間復雜度是怎么計算出來的 (2的k次方等于n k等于logn)
MySQL
你們后端用什么資料庫做持久化的?有沒有用到分庫分表,怎么做的?
索引的常見實作方式有哪些,有哪些區別?MySQL的存盤引擎有哪些,有哪些區別?InnoDB使用的是什么方式實作索引,怎么實作的?說下聚簇索引和非聚簇索引的區別?
mysql查詢優化
MySQL的索引,B+樹性質,
B+樹和B樹,聯合索引等原理
mysql的悲觀鎖和樂觀鎖區別和應用,ABA問題的解決
專案性能瓶頸在哪,資料庫表怎么設計
假設專案的性能瓶頸出現在寫資料庫上,應該怎么解決峰值時寫速度慢的問題
假設資料庫需要保存一年的資料,每天一百萬條資料,一張表最多存一千萬條資料,應該怎么設計表
資料庫自增索引,100臺服務器,每臺服務器有若干個用戶,用戶有id,同時會有新用戶加入,實作id自增,統計用戶個數?不能重復,好像是這樣的,
mysql,會考sql語言,服務器資料庫大規模資料怎么設計,db各種性能指標
演算法
堆疊
有序陣列排序,二分,復雜度
常見排序演算法,說下快排程序,時間復雜度
有N個節點的滿二叉樹的高度,1+logN
如何實作關鍵字輸入提示,使用字典樹,復雜度多少,有沒有其他方案,答哈希,如果是中文呢,分詞后建立字典樹?
hashmap的實作講一下吧,講的很詳細了,講一下紅黑樹的結構,查詢性能等,
快排的時間復雜度,冒泡時間復雜度,快排是否穩定,快排的程序
100w個數,怎么找到前1000個最大的,堆排序,怎么構造,怎么調整,時間復雜度,
一個矩陣,從左上角到右下角,每個位置有一個權值,可以上下左右走,到達右下角的路徑權值最小怎么走,
四輛小車,每輛車加滿油可以走一公里,問怎么能讓一輛小車走最遠,說了好幾種方案,面試官引導我優化了一下,但是還是不滿意,最后他說跳過,
MySQL的索引,B+樹性質,
十億和數找到前100個最大的,堆排序,怎么實作,怎么調整,
布隆過濾器
hash表解決沖突的方法
跳表插入洗掉程序
讓你實作一個哈希表,怎么做(當時按照Redis中哈希表的實作原理回答)
設計模式
對于單例模式,有什么使用場景了,講了全域id生成器,他問我分布式id生成器怎么實作,說了zk,問我zk了解原理不,講了zab,然后就沒問啦,
除了單例模式,知道配接器模式怎么實作么,有什么用
分布式架構
CAP BASE理論
看你專案里面用了etcd,講解下etcd干什么用的,怎么保證高可用和一致性?
既然你提到了raft演算法,講下raft演算法的基本流程?raft演算法里面如果出現腦裂怎么處理?有沒有了解過paxos和zookeeper的zab演算法,他們之前有啥區別?
rpc有沒有了解
最后再送你一句來自丘吉爾的名言:
“成功不是最終的,失敗也不是致命的,開始的勇氣才是最重要的!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/256840.html
標籤:其他