文章目錄
- 一、Pandas 概述
- 二、Series 物件
- 三、DataFrame 物件
- 四、匯入外部資料
- 1. 匯入 .xls 或 .xlsx 檔案
- 2. 匯入 .csv 檔案
- 3. 匯入 .txt 文本檔案
- 4. 匯入 HTML 網頁
- 五、資料抽取
- 六、資料的增加、修改和洗掉
- 1. 增加資料
- 2. 修改資料
- 3. 洗掉資料
- 七、資料清洗
- 1. 查看與處理缺失值
- 2. 重復值處理
- 3. 例外值的檢測與處理
- 八、索引值的設定
- 1. 索引的作用
- 2. 重新設定索引
- 九、資料排序與排名
- 1. 資料排序
- 2. 資料排名
一、Pandas 概述
1. 概述
Pandas 是資料分析的三大劍客之一,是 Python 的核心資料分析庫,它提供了快速、靈活、明確的資料結構,能夠簡單、直觀、快速地處理各種型別的資料,具體介紹如下:Pandas 能夠處理以下型別的資料:
- 與 SQL 或 Excel 表類似的資料,
- 有序和無序 (非固定頻率) 的時間序列資料,
- 帶行列標簽的矩陣資料,
- 任意其他形式的觀測、統計資料集,
Pandas 提供的兩個主要資料結構 Series(一維陣列結構) 與 DataFrame(二維陣列結構),可以處理金融、統計、社會科學、工程等領域里的大多數典型案例,并且 Pandas 是基于 NumPy 開發的,它可以與其他第三方科學計算庫完美集成,Pandas 的功能很多,它的優勢如下:
- 處理浮點與非浮點資料里的缺失資料,表示為NaN,
- 大小可變,例如插入或洗掉 DataFrame 等多維物件的列,
- 自動、顯式資料對齊,顯式地將物件與一組標簽對齊,也可以忽略標簽,在 Series、DataFrame 計算時自動與資料對齊,
- 強大、靈活的分組統計(groupby) 功能,即資料聚合、資料轉換,
- 可以把 Python 和 NumPy 資料結構里不規則、不同索引的資料輕松地轉換為 DataFrame 物件,
- 智能標簽,對大型資料集進行切片、花式索引、子集分解等操作,
- 直觀地合并 (merge)、連接(join) 資料集,
- 靈活地重塑 (reshape)、透視 (pivot) 資料集,
- 成熟的匯入匯出工具,匯入文本檔案(CSV 等支持分隔符的檔案)、Excel 檔案、資料庫等來源的資料;匯出 Excel 檔案、文本檔案等,利用超快的 HDF5 格式保存或加載資料,
- 時間序列:支持日期范圍生成、頻率轉換、移動視窗統計、移動視窗線性回歸、日期位移等時間序列功能,
綜上所述,Pandas 是處理資料時最理想的工具,
2. 安裝 Pandas
需要注意的是,Pandas 有一些依賴庫,當通過 Pandas 讀取 Excel 檔案時,如果只安裝 Pandas 模塊,就會報錯,安裝命令如下:
pip install xlrd
pip install xlwt
pip install Pandas
讀者如果要提高下載速度,可以自己添加國內的鏡像源,
二、Series 物件
Series 是 Python 的 Pandas 庫中的一種資料結構,它類似一維陣列,由一組資料以及這組資料相關的標簽 (即索引) 組成,或者僅有一組資料而沒有索引也可以創建一個簡單的 Series 物件,Series 可以存盤整數、浮點數、字串、Python 物件等多種型別的資料,
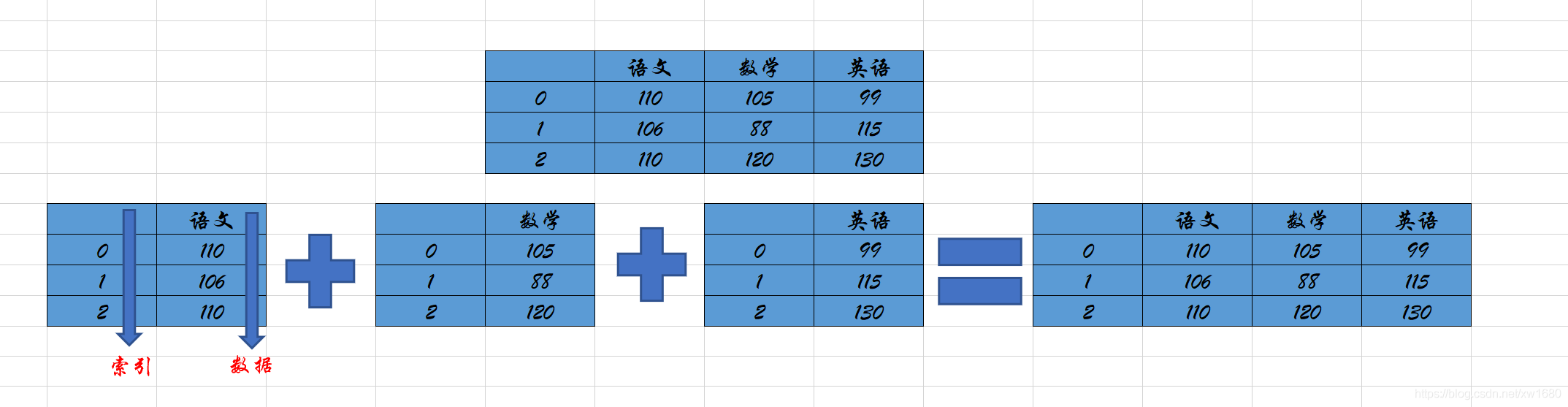
例如,在下圖成績中包含了 Series 物件和 DataFrame 物件,其中語文、數學和英語每一列都是一個 Series 物件,而語文、數學和英語三列組成了一個 DataFrame 物件,
1. 創建一個 Series 物件
創建 Series 物件時,主要使用 Pandas 的 Series 方法,語法如下:
s=pd.Series(data,index=index)
引數說明:
- data:表示資料,支持 Python 字典、多維陣列、標量值 (即只有大小、沒有方向的量,也就是說,只是一個數值,如 s=pd.Series(5)),
- index:表示行標簽(索引),
- 回傳值:Series 物件,
說明:當 data 引數是多維陣列時,index 長度必須與 data 長度一致,如果沒有指定 index 引數,將自動創建數值型索引(從0~data的資料長度減1),
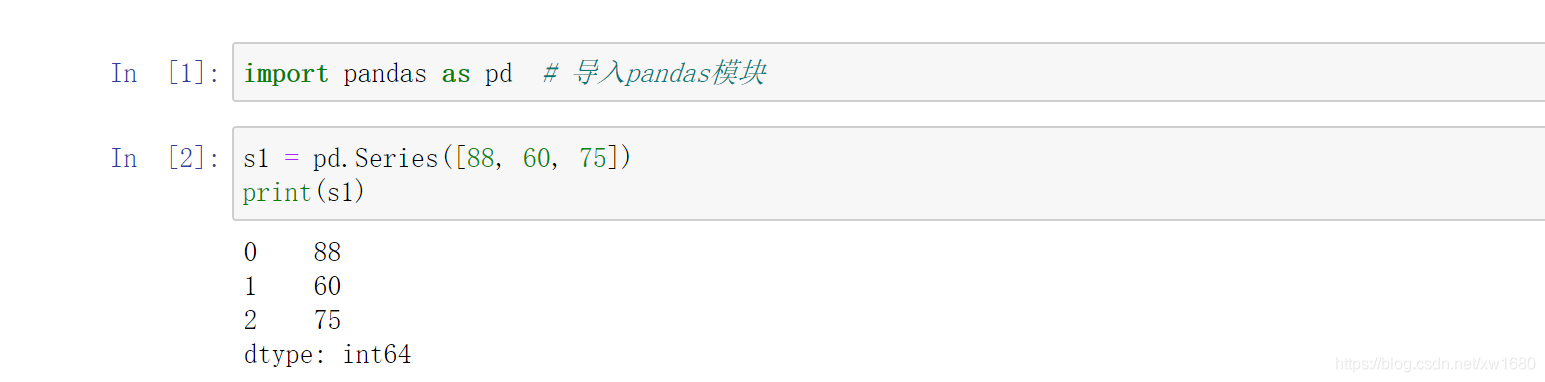
2. 創建一個 Series 物件,為成績表添加一列物理成績,程式代碼如下:
3. 手動設定索引
下面手動設定索引,將上面添加的物理成績的索引設定為1、2、3,也可以是向同學、劉同學、趙同學,程式代碼如下:
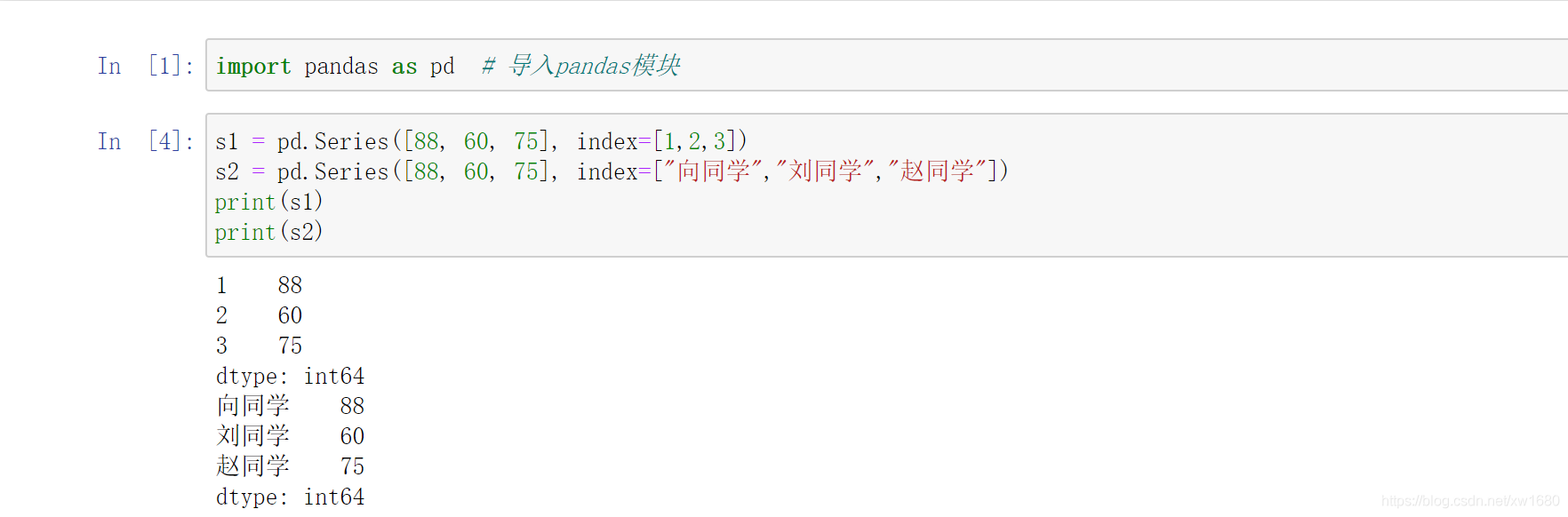
上述結果中輸出的 dtype,是 DataFrame 資料的資料型別,int 為整型,后面的數字表示位數,
4. Series 的索引
位置索引是從 0 開始,[0] 是 Series 的第一個數;[1] 是 Series 的第二個數,依次類推,獲取第一個學生的物理成績,程式代碼如下:
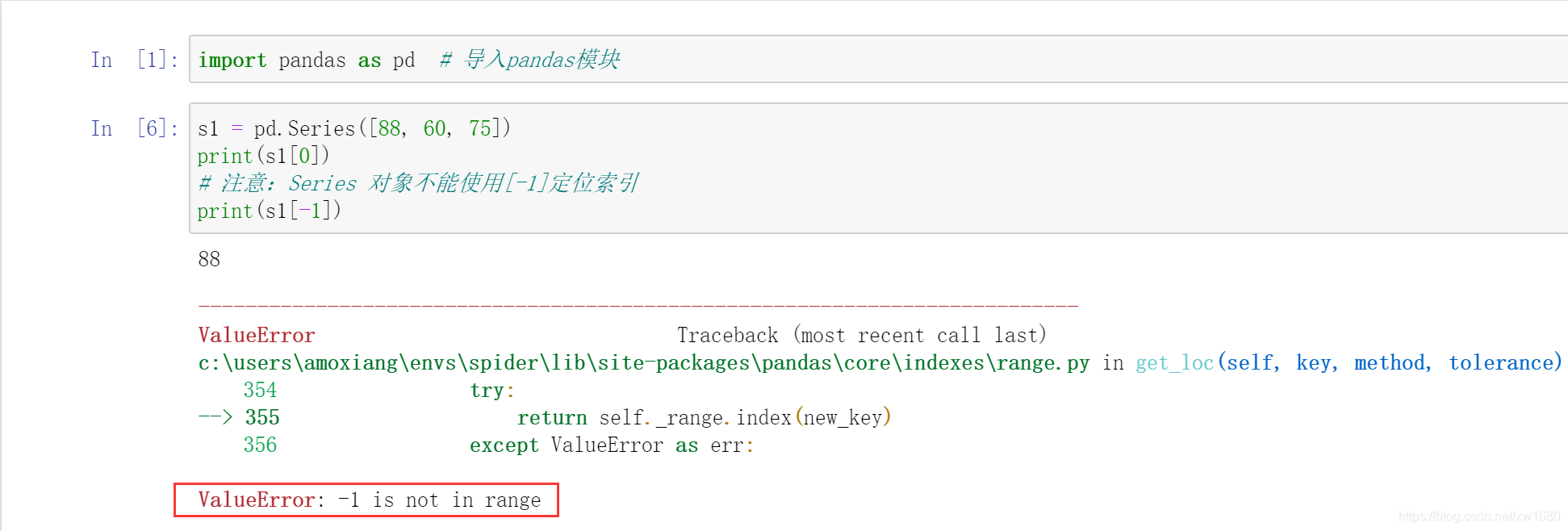
Series 標簽索引與位置索引方法類似,用 [] 表示,里面是索引名稱,注意 index 的資料型別是字串,如果需要獲取多個標簽索引值,則用 [[]] 表示(相當于在 [] 中包含一個串列),通過標簽索引 向同學 和 劉同學 獲取物理成績,程式代碼如下:
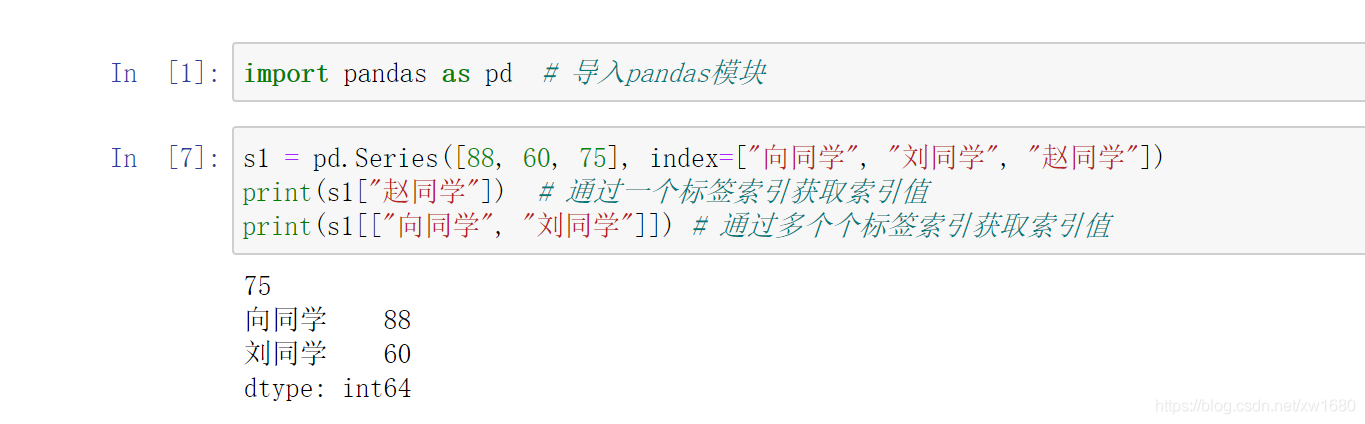
5. Series 的切片索引
用標簽索引做切片,可以包頭包尾(即包含了索引開始位置的資料,也包含了索引結束位置的資料),通過標簽切片索引 向同學 趙同學 獲取資料,程式代碼如下:

用位置索引做切片,和 list 串列的用法一樣,可以包頭不包尾(即包含了索引開始位置的資料,但不包含索引結束位置的資料),通過位置切片 1-4 獲取資料,程式代碼如下:
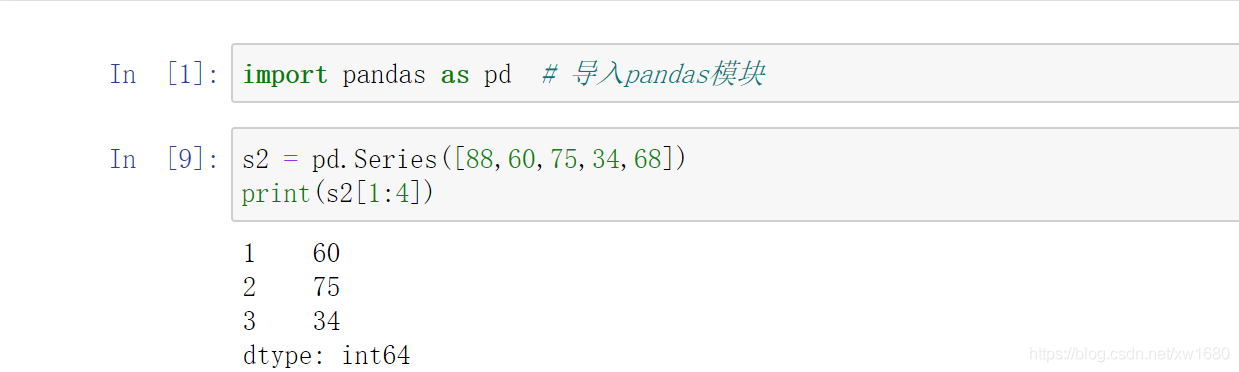
6. 獲取 Series 的索引和值
獲取 Series 的索引和值主要使用 Series 物件的 index 方法和 values 方法,使用 Series 的 index 方法和 values 方法獲取物理成績的索引和值,程式代碼如下:

三、DataFrame 物件
DataFrame 是 Pandas 庫中的一種資料結構,它是由多種型別的列組成的二維表資料結構,類似于 Excel、SQL 或 Series 物件構成的字典,DataFrame 是最常用的 Pandas 物件,它與 Series 物件一樣支持多種型別的資料,
1. 圖解 DataFrame 物件
DataFrame 是一個二維表資料結構,即由行列資料組成的表格,DataFrame 既有行索引也有列索引,它可以看作是由 Series 物件組成的字典,不過這些 Series 物件共用一個索引,如下圖所示,

處理 DataFrame 表格資料時,用 index 表示行或用 columns 表示列更直觀,而且用這種方式迭代 DataFrame 物件的列,代碼更易讀懂,
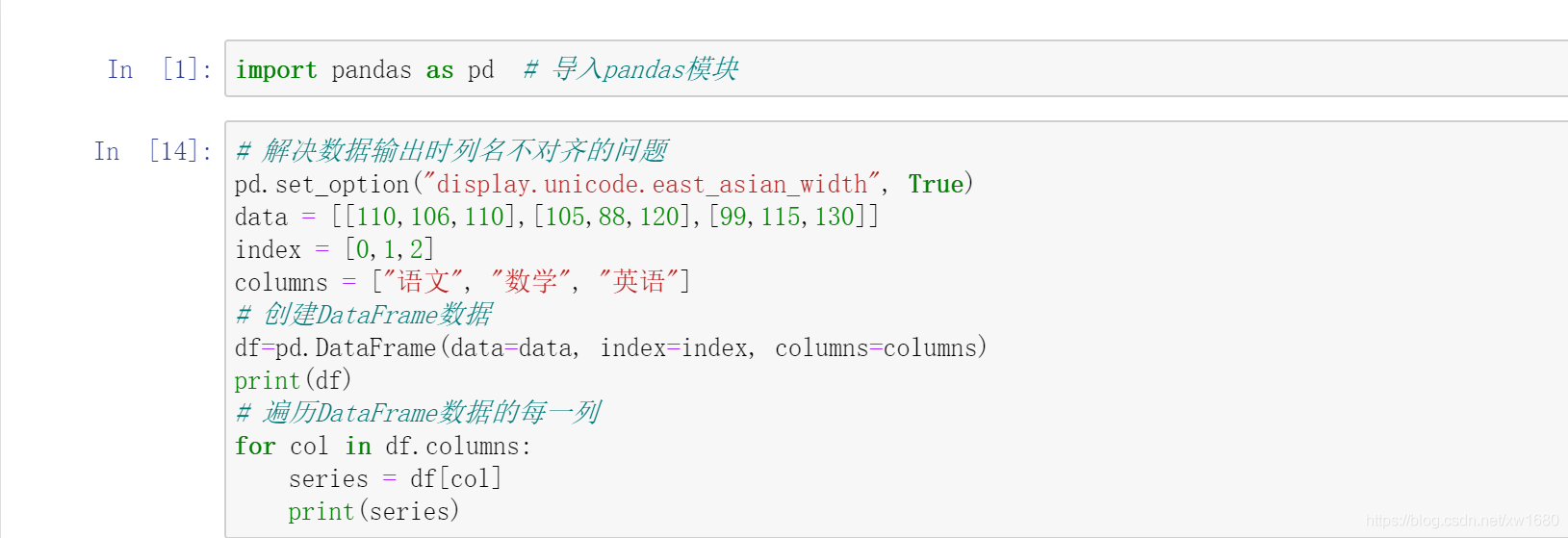
2. 創建一個 DataFrame 物件
創建 DataFrame 主要使用 Pandas 模塊的 DataFrame 方法,語法如下:
pandas.DataFrame(data, index, columns, dtype, copy)
引數說明:
- data:表示資料,可以是 ndarray 陣列、series 物件、串列、字典等,
- index:表示行標簽(索引),
- columns:列標簽(索引),
- dtype:每一列資料的資料型別,其與 Python 資料型別有所不同,如 object 資料型別對應的是 Python 的字符型,如下表所示,是 Pandas 資料型別與 Python 資料型別的對應,
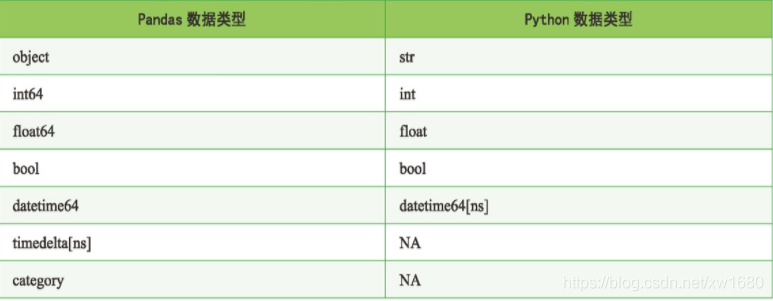
- copy:用于復制資料,
- 回傳值:DataFrame,
下面通過兩種方法來創建 DataFrame 物件,即二維陣列和字典,通過二維陣列創建成績表,包括語文、數學和英語,程式代碼如下:
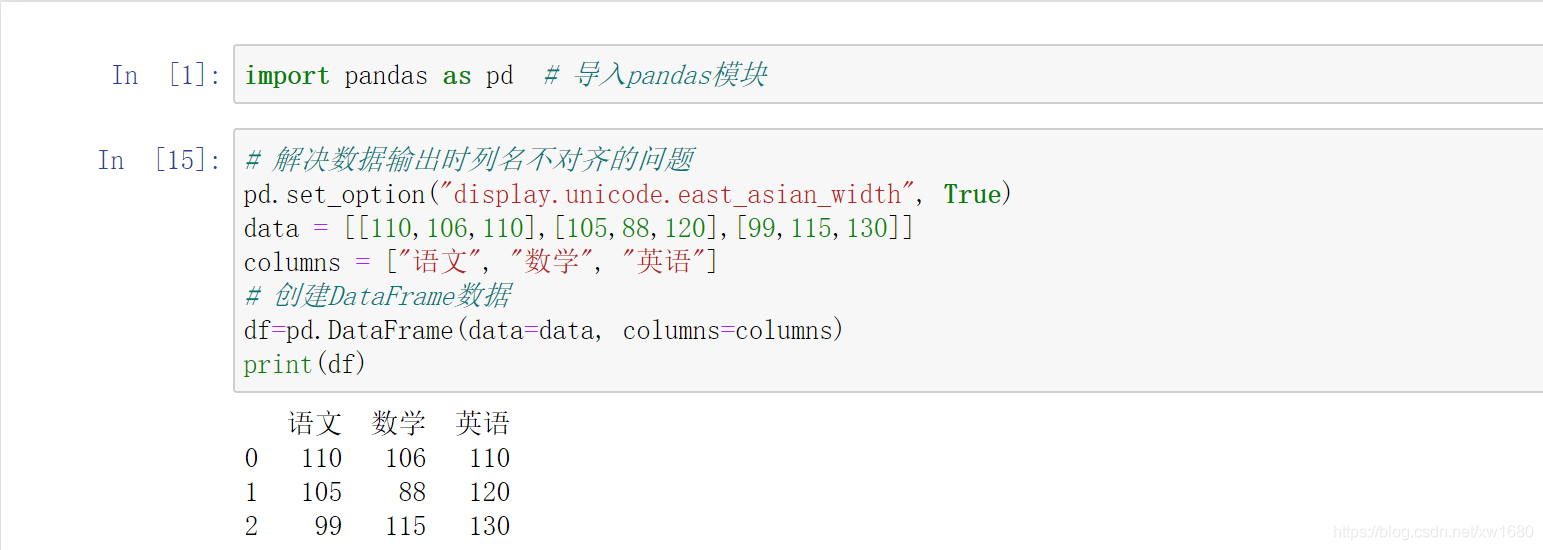
通過字典創建 DataFrame,需要注意:字典中的 value 值只能是一維陣列或單個的簡單資料型別,如果是陣列,則要求所有的陣列長度一致;如果是單個資料,則每行都需要添加相同資料,通過字典創建成績表,包括語文、數學、英語和班級,程式代碼如下:
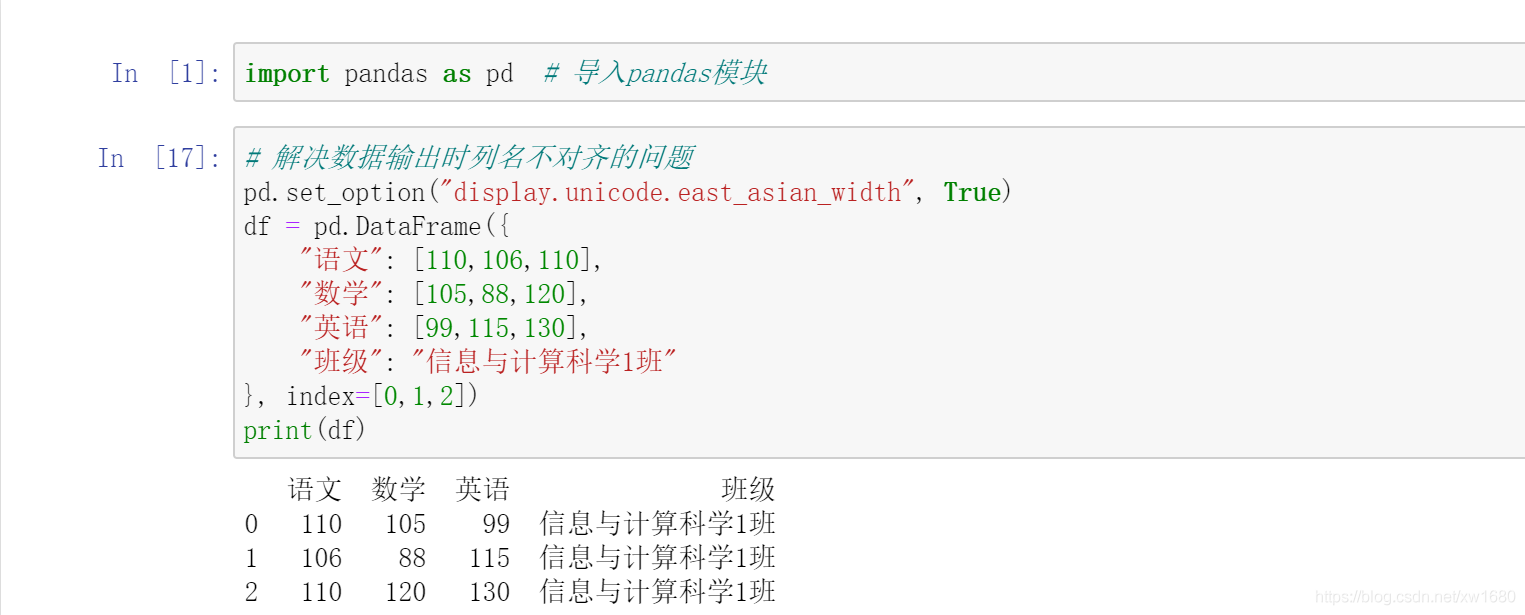
在上述代碼中,班級的 value 值是單個資料,所以每一行都添加了相同的資料 資訊與計算科學1班,
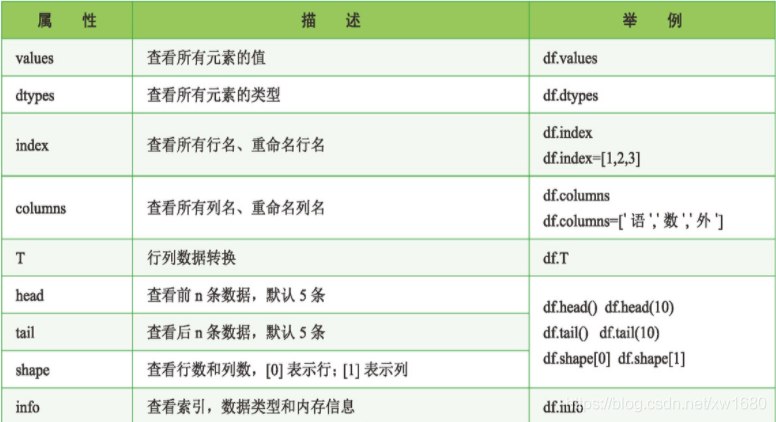
3. DataFrame 的重要屬性和函式
DataFrame 是 Pandas 中一個重要的物件,它的屬性和函式有很多,下面先簡單了解一下 DataFrame 物件的幾個重要屬性和函式,重要屬性及描述如下表所示:
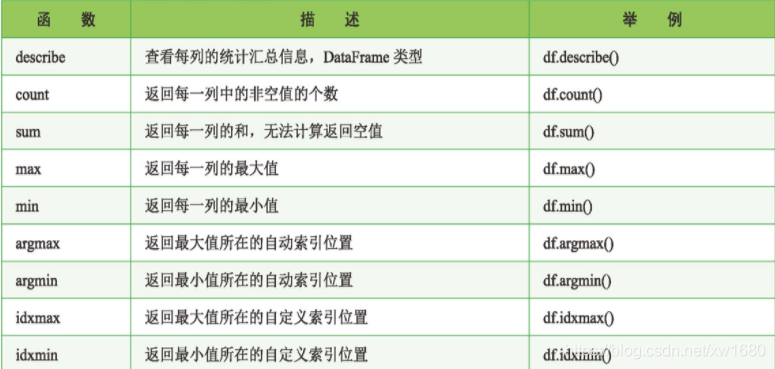
重要函式及描述如下表所示:
四、匯入外部資料
1. 匯入 .xls 或 .xlsx 檔案
匯入 .xls 或 .xlsx 檔案主要使用 Pandas 的 read_excel 方法,語法如下:
def read_excel(
io, sheet_name=0, header=0, names=None,
index_col=None, usecols=None, squeeze=False, dtype=None,
engine=None, converters=None, true_values=None, false_values=None,
skiprows=None, nrows=None, na_values=None, keep_default_na=True,
na_filter=True, verbose=False, parse_dates=False, date_parser=None,
thousands=None, comment=None, skipfooter=0, convert_float=True,
mangle_dupe_cols=True,
):
常用引數說明:
- io:字串,xls或 xlsx 檔案路徑或類檔案物件,
- sheet_name:None、字串、整數、字串串列或整數串列,默認值為 0,字串用于作業表名稱;整數為索引,表示作業表位置,字串串列或整數串列用于請求多個作業表,為 None 時則獲取所有的作業表,引數值如下表所示,

- header:指定作為列名的行,默認值為 0,即取第一行的值為列名,資料為除列名以外的資料;若資料不包含列名,則設定為 header=None,
- names:默認值為None,要使用的列名串列,
- index_col:指定列為索引列,默認值為 None,索引 0 是 DataFrame 物件的行標簽,
- usecols:int、list 或字串,默認值為 None,
- 如果為 None,則決議所有列,
- 如果為 int,則決議最后一列,
- 如果為 list 串列,則決議列號和串列的列,
- 如果為字串,則表示以逗號分隔的 Excel 列字母和列范圍串列(例如,A : E 或 A, C, E : F),范圍包括雙方,
- squeeze:布林值,默認值為 False,如果決議的資料只包含一列,則回傳一個 Series,
- dtype:列的資料型別名稱或字典,默認值為 None,例如, 為 { ‘a’ : np.float64,‘b’ : np.int32},
- skiprows:省略指定行數的資料,從第一行開始,
- skipfooter:省略指定行數的資料,從尾部數的行開始,
1. 常規匯入
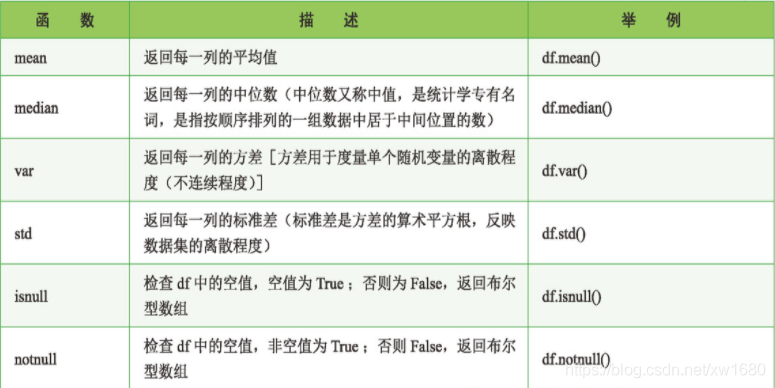
匯入 1 月.xlsx 的 Excel 檔案,程式代碼如下:
匯入外部資料,必然要涉及路徑問題,下面來復習一下相對路徑和絕對路徑的知識,相對路徑 就是以當前檔案為基準,從而一級級目錄指向被參考的資源檔案,以下是常用的表示當前目錄和當前目錄的父級目錄的識別符號,
../:表示當前檔案所在目錄的上一級目錄,./:表示當前檔案所在的目錄 (可以省略),/:表示當前檔案的根目錄 (域名映射或硬碟目錄),
如果使用系統默認檔案路徑 \,那么在 Python 中則需要在路徑最前面加一個 r,以避免路徑里面的 \ 被轉義,絕對路徑是檔案真正存在的路徑,是指從硬碟的根目錄(盤符) 開始,從而一級級目錄指向檔案,
2. 匯入指定的 Sheet 頁
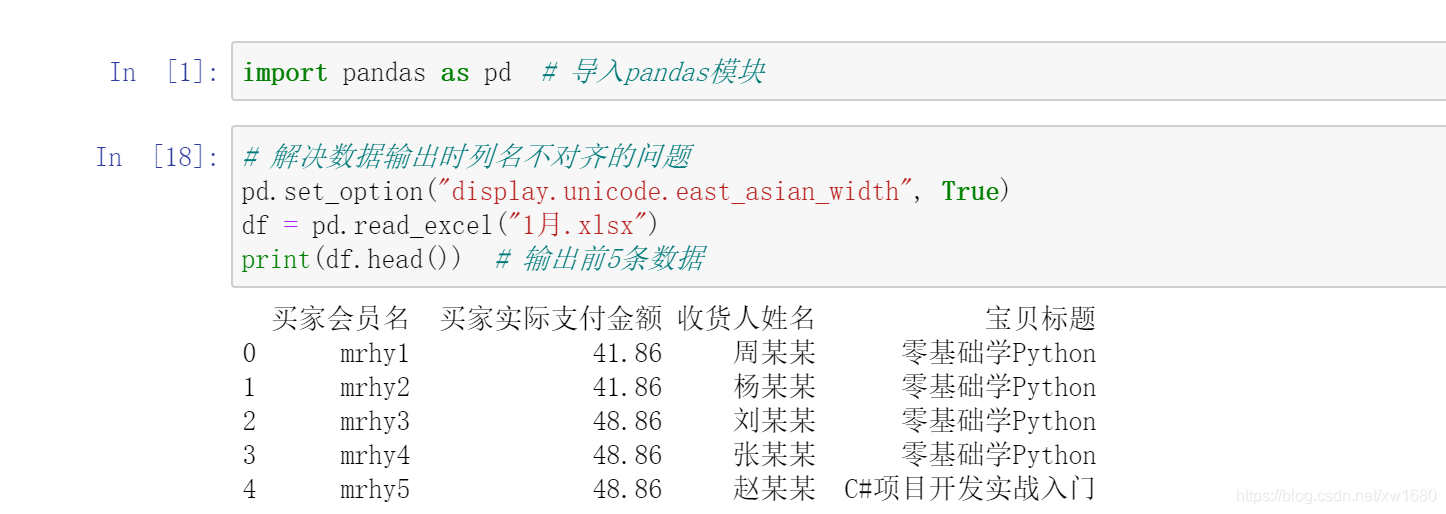
一個 Excel 檔案中包含多家店鋪的銷售資料,匯入其中一家店鋪,如 (莫寒) 的銷售資料,程式代碼如下:
除了指定 Sheet 頁的名字,還可以指定 Sheet 頁的順序,從 0 開始,例如,sheet_name=0 表示匯入第一個 Sheet 頁的資料,sheet_name=1 表示匯入第二個 Sheet 頁的資料,以此類推,如果不指定 sheet_name引數,則默認匯入第一個 Sheet 頁的資料,
3. 通過行列索引匯入指定行列資料
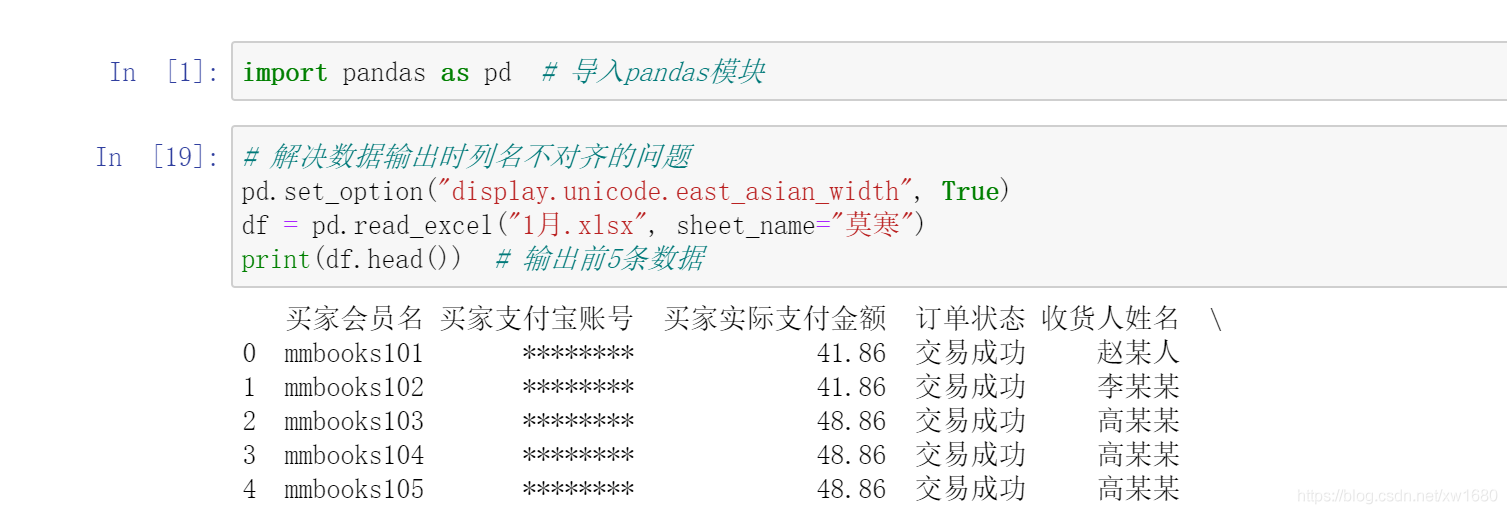
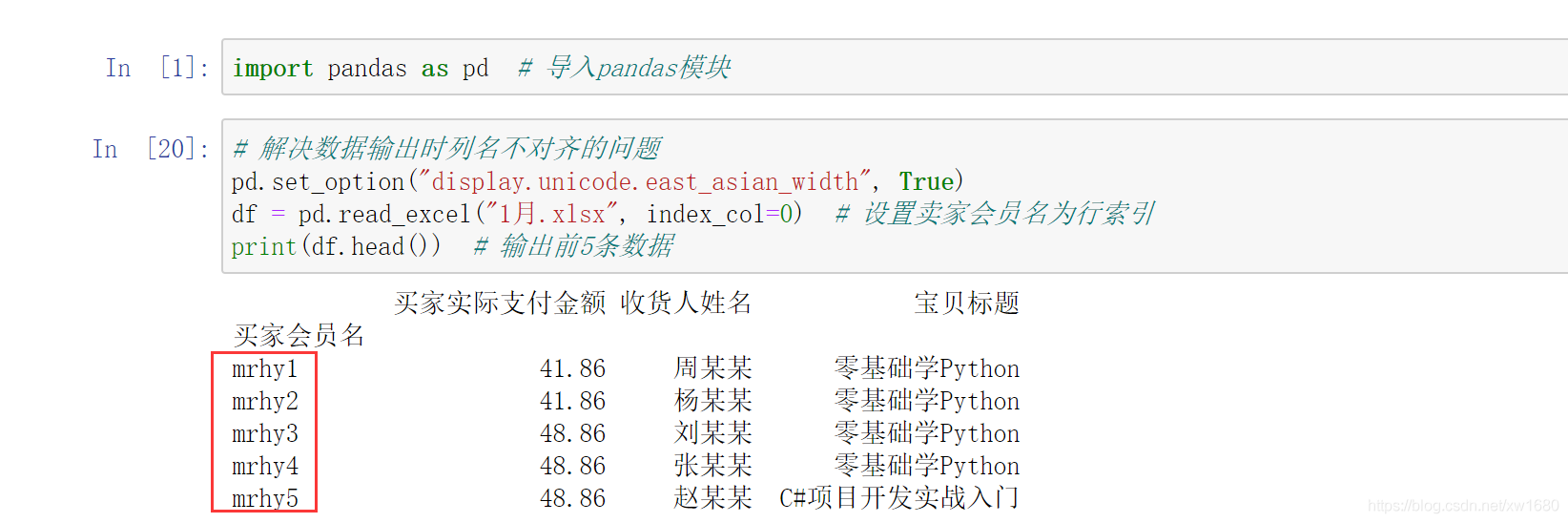
DataFrame 是二維資料結構,因此它既有行索引又有列索引,當匯入 Excel 資料時,行索引會自動生成,如 0、1、2,而列索引則默認將第 0 行作為列索引(如 A,B,…,J),如果通過指定行索引匯入 Excel 資料,則需要設定 index_col 引數,下面將 買家會員名 作為行索引(位于第 0 列),匯入 Excel 資料,程式代碼如下:
如果通過指定列索引匯入 Excel 資料,則需要設定 header 引數,程式代碼如下:
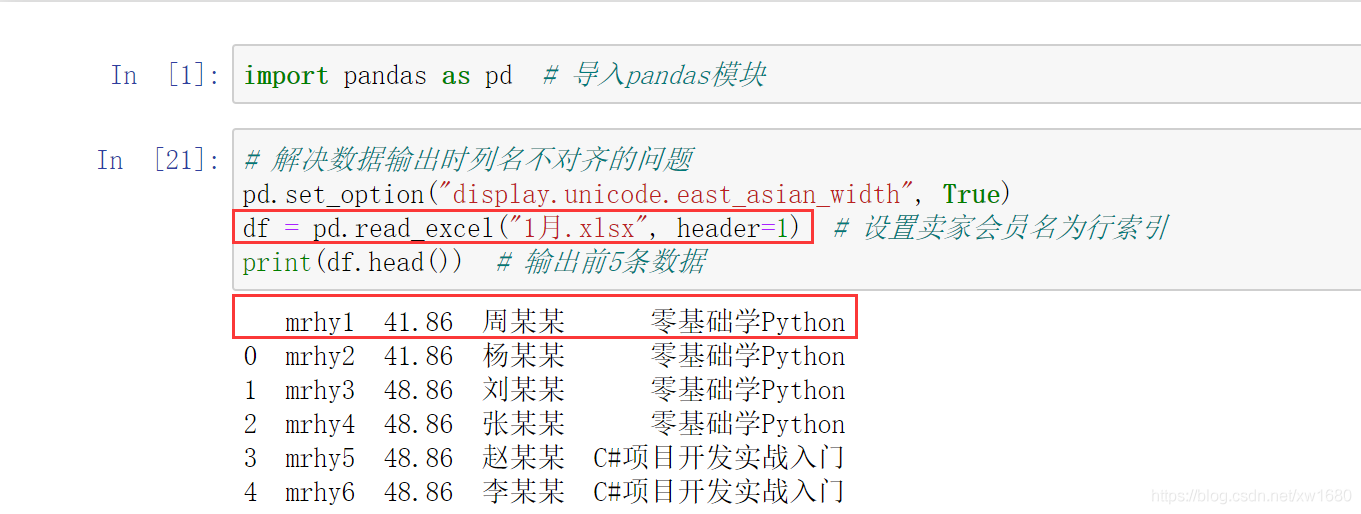
如果將數字作為列索引,可以設定 header 引數為 None,程式代碼如下:
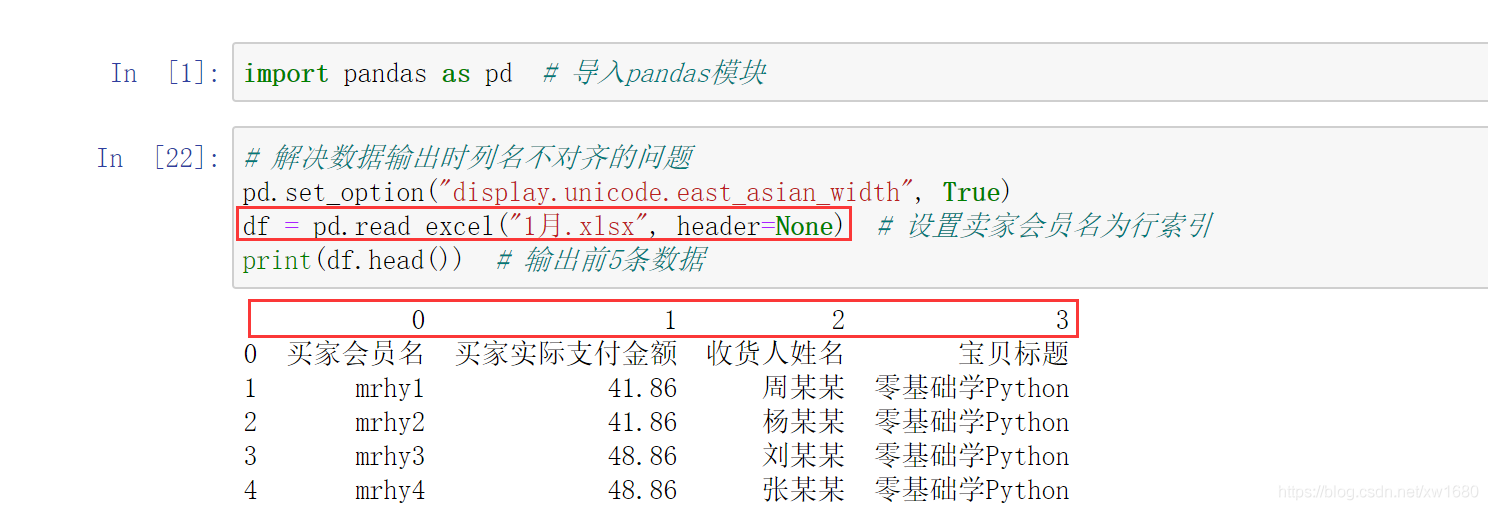
指定索引的目的是因為通過索引可以快速地檢查資料,例如根據 df[0],就可以快速檢索到 買家會員名 這一列資料,
4. 匯入指定列資料
一個 Excel 表中往往包含多列,如果只需要其中的幾列,可以通過 usecols 引數指定需要的列,從 0 開始(表示第 1 列,依次類推),下面匯入第一列資料(索引為 0),程式代碼如下:
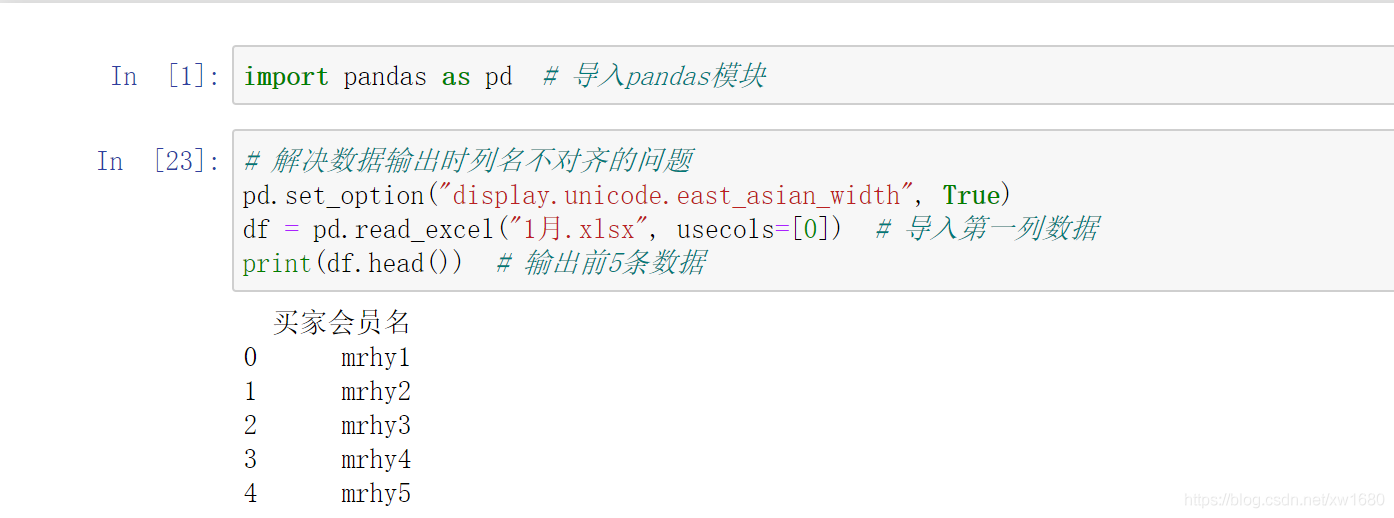
如果是匯入多列,則可以在串列中指定多個值,例如,匯入第一列和第四列,關鍵代碼如下:
df = pd.read_excel("1月.xlsx", usecols=[0,3])
也可以指定列名稱,關鍵代碼如下:
df = pd.read_excel("1月.xlsx", usecols=["買家會員名", "寶貝標題"])
2. 匯入 .csv 檔案
介紹匯入 .csv 檔案前,需要先了解 csv 檔案 (.csv 檔案格式),csv 檔案中的每行代表電子表格中的一行,并用逗號分隔該行中的單元格,
例如,電子表格檔案 book.xlsx,如下圖所示,
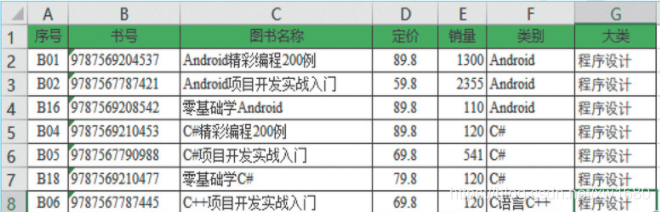
而在一個 CSV 檔案中,它是下面的樣子,如下圖所示:
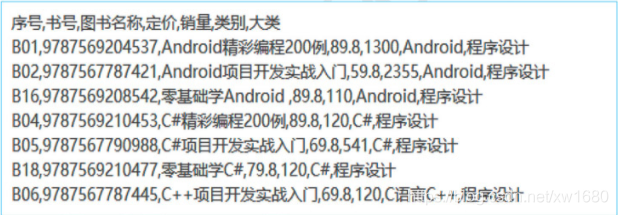
csv 檔案可以使用記事本打開,可以使用 Excel 另存為 .csv 檔案格式,或者在文本編輯器中輸入文本,保存為 .csv 檔案格式,csv 檔案是比較簡單的檔案格式,缺少 Excel 電子表格的許多功能,例如:
- 值沒有型別,所有資料都是字串,
- 沒有字體大小和顏色的設定,
- 沒有多個作業表,
- 不能指定單元格的寬度和高度,
- 不能合并單元格,
- 不能嵌入影像或圖表,
csv 檔案被應用程式廣泛支持的原因,也正因為它的簡單,它可以在文本編輯器中查看(包括 IDLE 的檔案編輯器),是表示電子表格資料的直接方式,匯入 .csv 檔案時主要使用 Pandas 的 read_csv() 方法,語法如下:
pandas.read_csv(引數省略....) 具體的引數可以點原始碼進去查看
常用引數說明:
- filepath_or_buffer:字串,檔案路徑,也可以是 URL 鏈接,
- sep、 delimiter:字串,分隔符,
- header:指定作為列名的行,默認值為0,即取第一行的值為列名,資料為除列名以外的資料;若資料不包含列名,則設定 header=None,
- names:默認值為 None, 要使用的列名串列,
- index_col:指定列為索引列,默認值為 None, 索引 0 是 DataFrame 物件的行標簽,
- usecols:int、 list 或字串,默認值為 None,
- 如果為 None,則決議所有列,
- 如果為 int,則決議最后一列,
- 如果為 list 串列,則決議列號、串列的列,.
- 如果為字串,則表示以逗號分隔的 Excel 列字母和列范圍串列(例如,A : E 或 A, C, E : F"),范圍包括雙方,
- dtype:列的資料型別名稱或字典,默認值為 None,例如,{‘a’: np.float64, ‘b’: np.int32},
- parse_ dates:布爾型別值、int 型別值的串列、串列或字典,默認值為 False,可以通過 parse_ dates 引數直接將某列轉換成 datetime64 的日期型別,例如,df1=pd.read_csv(‘1 月.csv’, parse_dates=[‘訂單付款時間"D’]),
- parse_dates為 True 時,嘗試決議索引,
- parse_dates 為 int 型別值組成的串列時,如[1,2,3],則決議 1、2、3 列的值作為獨立的日期列,
- parse_date 為串列組成的串列,如[[1,3]],則將 1、3 列合并,作為一個日期列使用,
- parse_date 為字典時,如{‘總計’: [1,3]}, 則將 1、3 列合并,合并后的列名為總計,
- encoding:字串,默認值為 None,檔案的編碼格式,
- 回傳值:回傳一個 DataFrame 物件,
1. 匯入.csv 檔案
匯入 .csv 檔案,程式代碼如下:
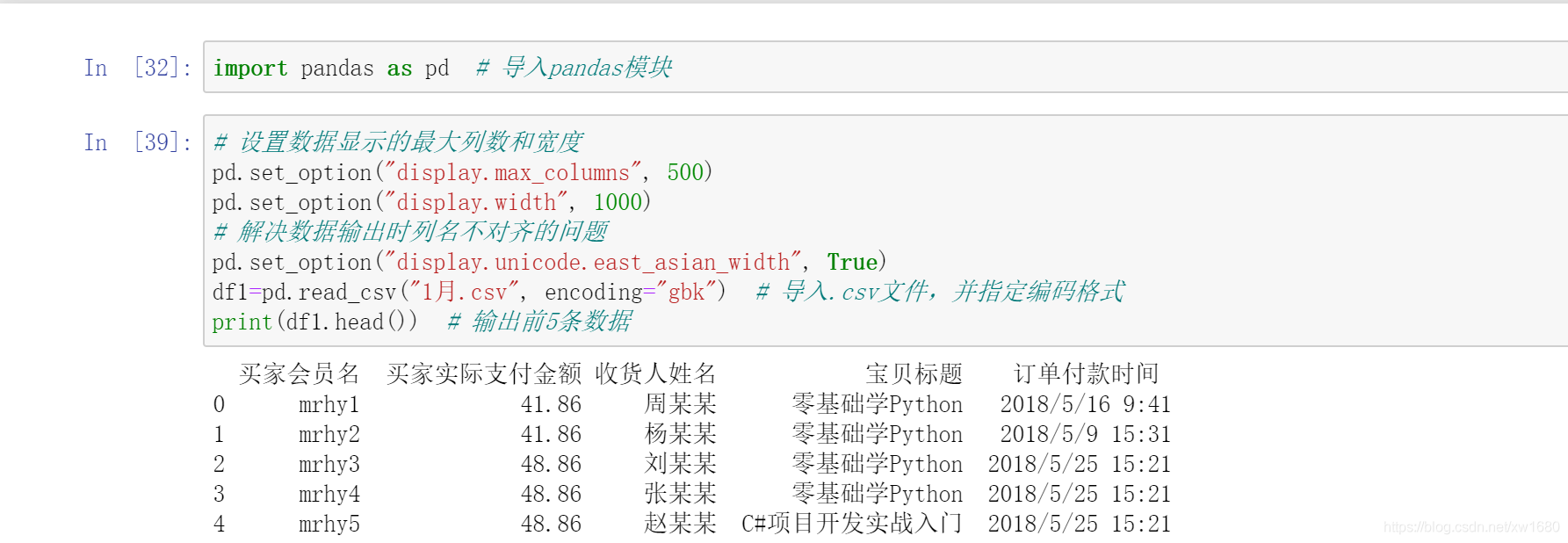
注意:上述代碼中指定了編碼格式,即 encoding=‘gbk’,Python 常用的編碼格式是 UTF-8 和 GBK 格式,默認編碼格式為 UTF-8,匯入 .csv 檔案時,需要通過 encoding 引數指定編碼格式,當我們將 Excel 檔案另存為.csv 檔案時,默認編碼格式為 GBK,此時撰寫代碼匯入 .csv 檔案時,就需要設定編碼格式為 GBK,與原檔案的編碼格式保持一致,否則會提示錯誤,
3. 匯入 .txt 文本檔案
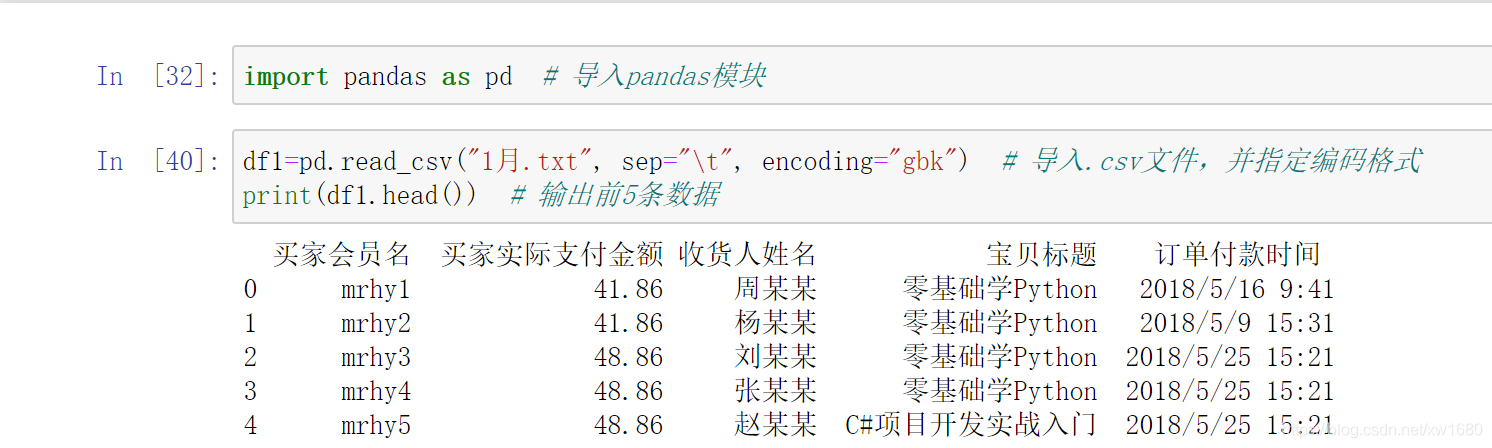
匯入 .txt 檔案同樣使用 Pandas 模塊的 read_csv() 方法,不同的是需要指定 sep 引數(如制表符 \t),read_ csv() 方法讀取 .txt 檔案后將回傳一個 DataFrame 物件,像表格一樣的二維資料結構,如圖所示,
下面使用 read_csv() 方法匯入 1月的 .txt 檔案,關鍵代碼如下:
4. 匯入 HTML 網頁
匯入 HTML 網頁資料主要使用 Pandas 的 read_html() 方法,該方法用于匯入帶有 table 標簽的網頁表格資料,常用引數說明如下:
- io:字串,檔案路徑,也可以是 URL 鏈接,網址不接受 https, 可以嘗試去掉 https 中的 s 后爬取,
- match:正則運算式,回傳與正則運算式匹配的表格,
- flavor:決議器默認為 lxml,
- header:指定列標題所在的行,串列 list 為多重索引
- index_col:指定行標題對應的列,串列 list 為多重索引,
- encoding:字串,默認為 None,檔案的編碼格式,
- 回傳值:回傳一個 DataFrame 物件,
使用 read_html() 方法前,首先要確定網頁表格是否為 table 標簽,例如,NBA球員薪資網頁,右鍵單擊該網頁中的表格,在彈出的選單中選擇檢查元素,查看代碼中是否含有表格標簽 <table>...</table> 的字樣,如下圖所示,確定后才可以使用 read_html() 方法,
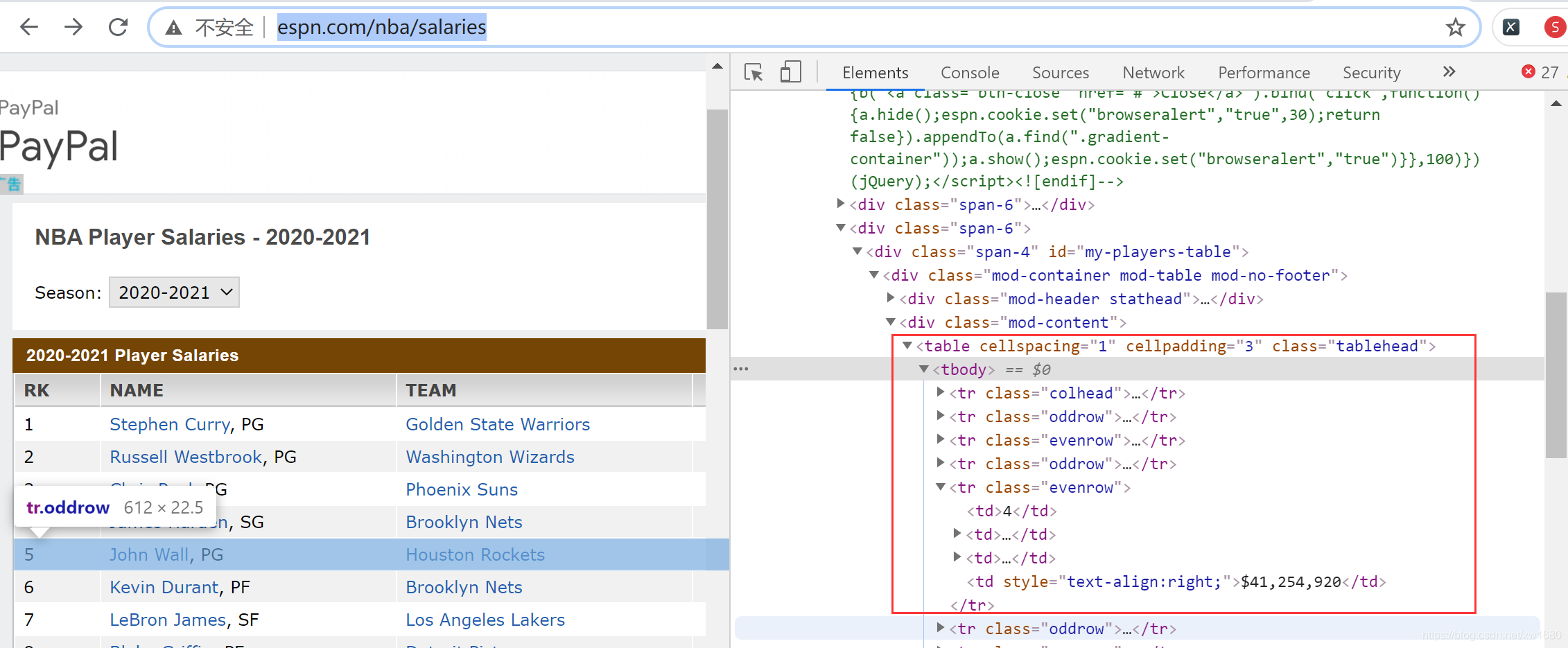
下面使用 read_html() 方法匯入 NBA 球員的薪資資料,程式代碼如下:
五、資料抽取
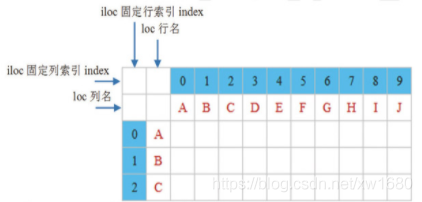
在資料分析程序中,并不是所有的資料都是我們想要的,此時可以抽取部分資料,主要使用 DataFrame 物件中的 loc 屬性和 iloc 屬性,如下圖所示,
DataFrame 物件中的 loc 屬性和 iloc 屬性都可以抽取資料,區別如下:
- loc 屬性:以列名 (columns) 和行名 (index) 作為引數,當只有一個引數時,默認是行名,即抽取整行資料,包括所有列,如 df.loc[‘A’]
- iloc 屬性:以行和列位置索引(即0,1,2, …作為引數,0 表示第一行;1 表示第二行,以此類推,當只有一個引數時,默認是行索引,即抽取整行資料,包括所有列,如抽取第一行資料,df.iloc[0],
1. 抽取一行資料
抽取 1 行名為 明日 的考試成績資料(包括所有列),程式代碼如下:
2. 抽取多行資料
抽取任意多行資料,通過 loc 屬性和 iloc 屬性指定行名和行索引即可實作抽取任意多行資料,抽取行名為明日和高袁圓(即 第 1 行和第 3 行資料) 的考試成績資料,關鍵代碼如下:
print(df.loc[["明日", "高袁圓"]])
print(df.iloc[[0,2]])
抽取連續任意多行資料,在 loc 屬性和 iloc 屬性中合理使用冒號 : ,即可抽取連續任意多行資料,實作抽取連續幾個學生的考試成績,關鍵代碼如下:
print(df.loc["明日":"二月二"]) # 明日到二月二
print(df.loc[:"七月流火":]) # 第1行到七月流火
print(df.iloc[0:4]) # 第1行到第4行
print(df.iloc[1::]) # 第2行到最后一行
3. 抽取指定列資料
想要抽取指定列資料,可以直接使用列名,也可以使用 loc 屬性和 iloc 屬性,抽取列名為語文和數學的考試成績資料,程式代碼如下:
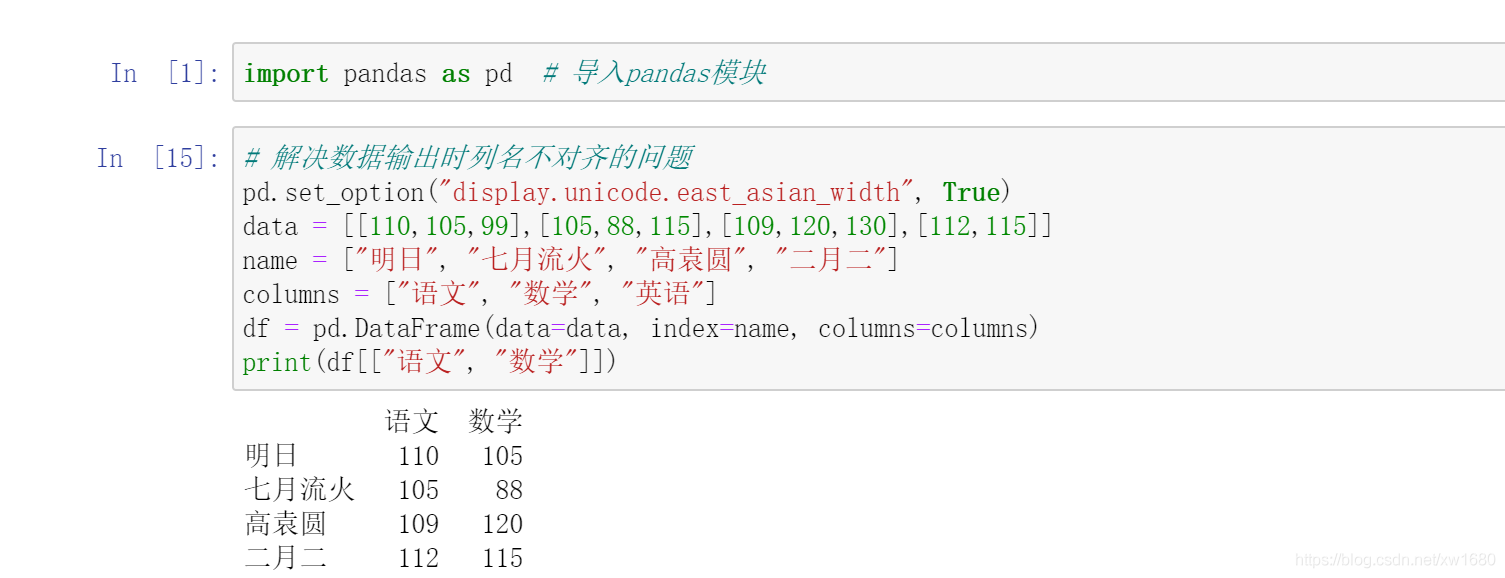
前面介紹 loc 屬性和 iloc 屬性都包含了兩個引數,第一個引數代表行;第二個引數代表列,那么這里在抽取指定列資料時,行引數不能省略,下面使用 loc 屬性和 iloc 屬性抽取指定列資料,關鍵代碼如下:
print(df.loc[:,["語文","數學"]]) # 抽取語文和數學
print(df.iloc[:,[0,1]]) # 抽取第1列和第2列
print(df.loc[:,"語文":]) # 抽取從"語文"開始到最后一列
print(df.iloc[:,:2]) # 連續抽取從第1列開始到第3列,但不包括第3列
4. 抽取指定行列資料
抽取指定行列資料主要使用 loc 屬性和 iloc 屬性,這兩個方法中的兩個引數都指定后,就可以實作指定行列資料的抽取,使用 loc 屬性和 iloc 屬性抽取指定學科和指定學生的考試成績,程式代碼如下:
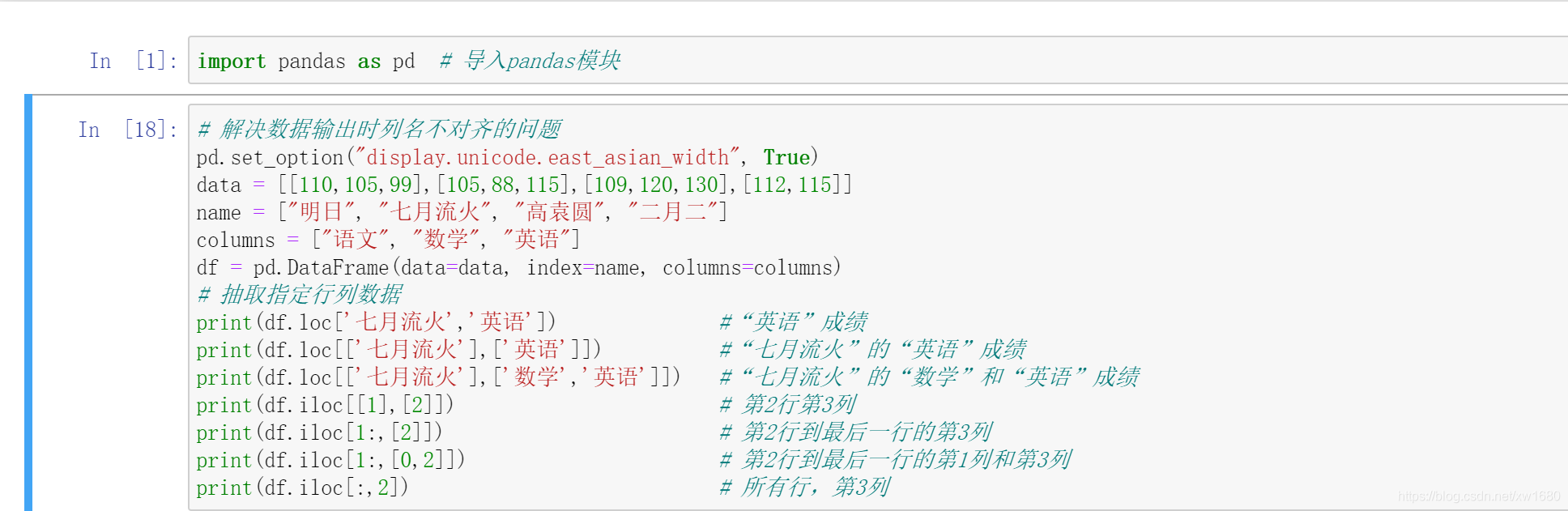
在上述代碼執行后的結果中,第一個輸出結果是一個數字,不是陣列,這是由于 df.loc[‘七月流火’,‘英語’] 陳述句中沒有使用方括號 [],導致輸出的資料不是 DataFrame 物件,
5. 按指定條件抽取資料
使用 DataFrame 物件實作資料查詢有以下 3 種方式:
(1) 取其中的一個元素,如 .iat[x,x],
(2) 基于位置的查詢,如 .iloc[]、iloc[2,1],
(3) 基于行列名稱的查詢,如 .loc[x],
抽取語文成績大于 105 分,數學成績大于 88 分的資料,程式代碼如下:
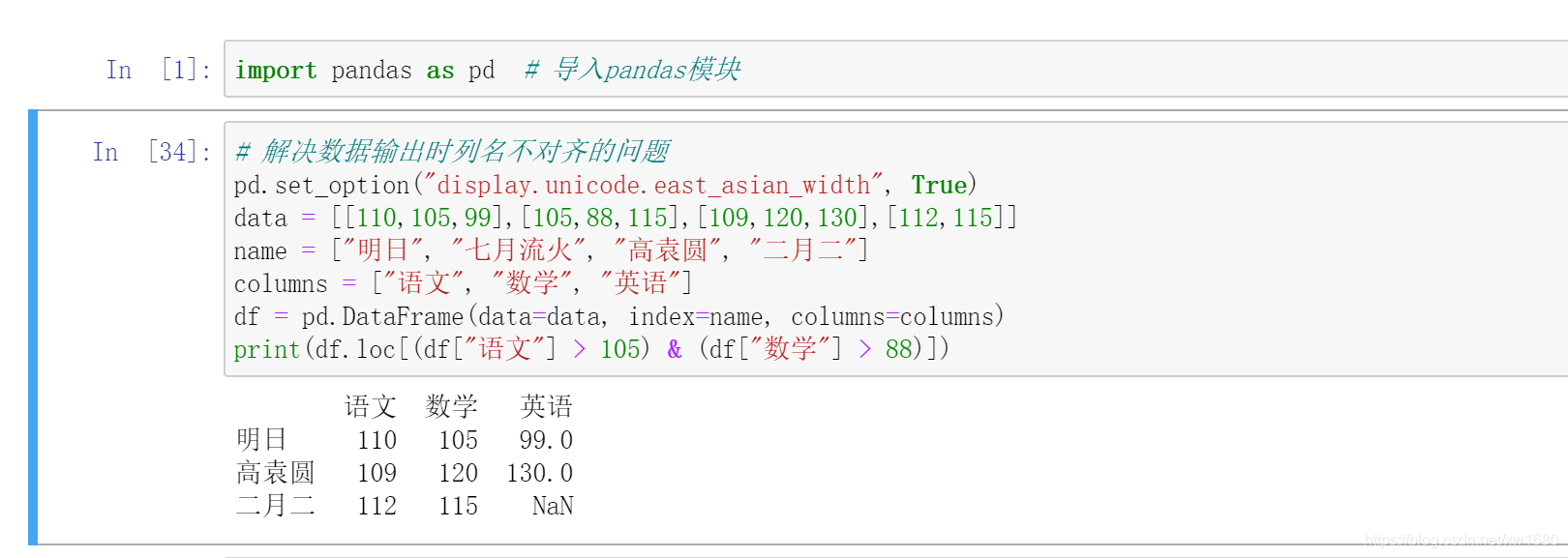
六、資料的增加、修改和洗掉
本節主要介紹如何操縱 DataFrame 物件中的各種資料,例如,資料的增加、修改和洗掉等,
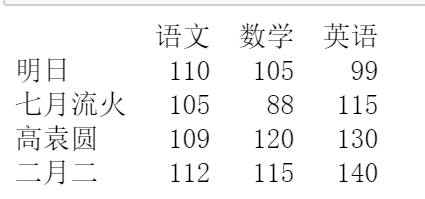
1. 增加資料
在 DataFrame 物件中增加資料主要包括列資料和行資料的增加,首先看下原始資料,如下圖所示,
1. 按列增加資料
按列增加資料,可以通過以下 3 種方式實作:
(1) 直接為 DataFrame 物件賦值,
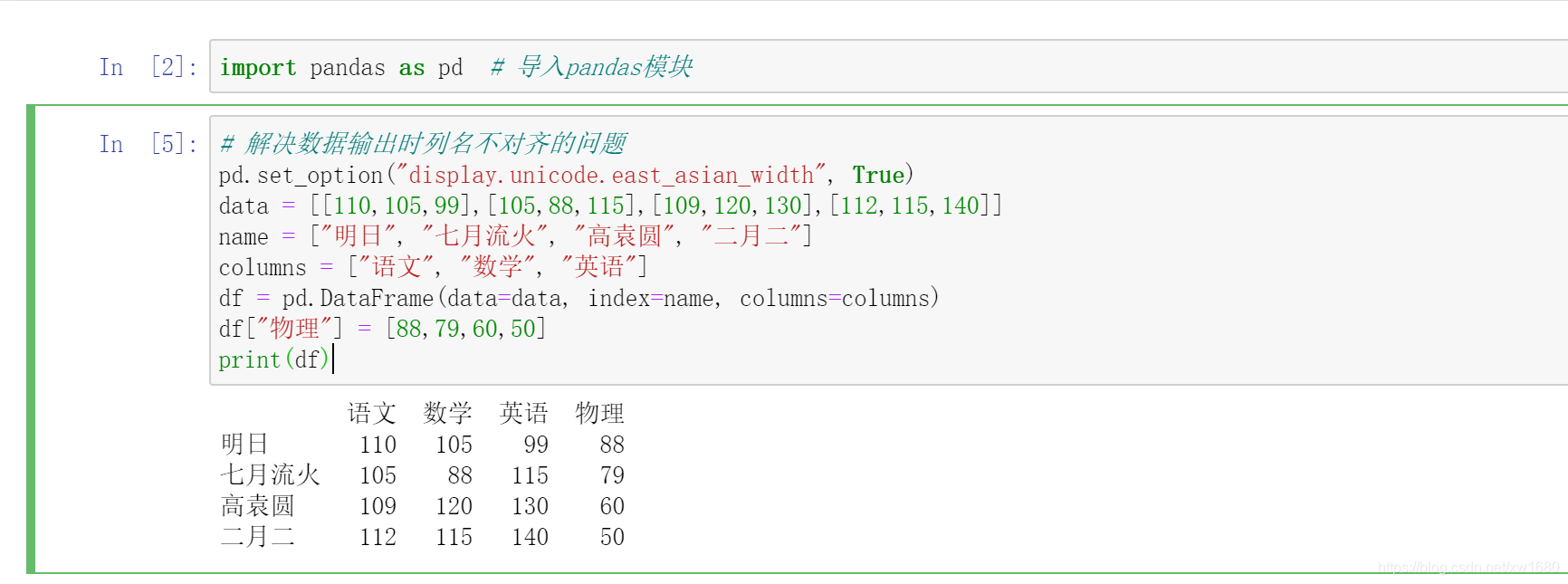
(2) 使用 loc 屬性在 DataFrame 物件的最后增加一列,
使用 loc 屬性在 DataFrame 物件的最后增加一列,例如,增加物理一列,關鍵代碼如下:
df.loc[:, "物理"] = [88,79,60,50]
在 DataFrame 物件的最后增加一列物理,其值為等號的右邊資料,
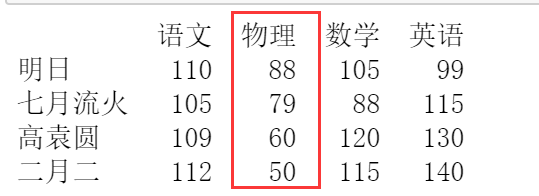
(3) 在指定位置插入一列,
在指定位置插入一列,主要使用 insert() 方法,例如,在第一列的后面插入物理,其值為 wl 的數值,關鍵代碼如下:
wl = [88,79,60,50]
df.insert(1,"物理",wl)
2. 按行增加資料
按行增加資料,可以通過以下兩種方式實作:
(1) 增加一行資料,增加一行資料主要使用 loc 屬性實作,在成績表中增加一行資料,即錢多多同學的成績,關鍵代碼如下:
df.loc["錢多多"] = [100,120,99]
(2) 增加多行資料,增加多行資料主要使用字典并結合 append 方法實作,在原有資料中增加錢多多,童年,無名,同學的考試成績,關鍵代碼如下:
df_insert = pd.DataFrame({"語文":[100,123,138],"數學":[99,142,60],"英語":[98,139,99]}
,index = ["錢多多","童年","無名"])
df1 = df.append(df_insert)
print(df1)
2. 修改資料
修改資料包括行列標題和資料的修改,首先看下原始資料,如圖所示:
1. 修改列標題
修改列標題主要使用 DataFrame 物件中的 columns 屬性,直接賦值即可,將數學修改為數學(上),關鍵代碼如下:
df.columns = ["語文", "數學(上)", "英語"]
print(df)
下面再介紹一種方法,使用 DataFrame 物件中的 rename 方法修改標題,將語文修改為語文上、數學修改為數學上、英語修改為英語上,關鍵代碼如下:
df.rename(columns={"語文":"語文(上)", "數學":"數學(上)", "英語":"英語(上)"},inplace=True)
在上述代碼中,引數 inplace 為 True,表示直接修改 df;否則不修改 df,只回傳修改后的資料,
2. 修改行標題
修改行標題主要使用 DataFrame 物件中的 index 屬性,直接賦值即可,將行標題統一修改為數字編號,關鍵代碼如下:
df.index=list("1234")
使用 DataFrame 物件中的 rename 方法也可以修改行標題,例如,將行標題統一修改為數字編號,關鍵代碼如下:
df.rename({"明日":1,"七月流火":2,"高袁圓":3,"二月二":4},axis=0,inplace=True)
3. 修改資料
修改資料主要使用 DataFrame 物件中的 loc 屬性和 iloc 屬性,
(1) 修改整行資料,例如,修改明日同學的各科成績,關鍵代碼如下:
df.loc["明日"] = [120,115,109]
如果各科成績均加 10 分,可以直接在原有值加 10,關鍵代碼如下:
df.loc["明日"] = df.loc["明日"] + 10
(2) 修改整列資料,例如,修改所有同學的語文成績,關鍵代碼如下:
df.loc[:,"語文"]=[115,108,112,118]
(3) 修改某一處資料,例如,修改明日同學的語文成績,關鍵代碼如下:
df.loc["明日", "語文"] = 115
(4) 使用 iloc 屬性修改資料,通過 iloc 屬性指定行列位置實作修改資料,關鍵代碼如下:
df.iloc[0,0]=115 # 修改某一處資料
df.iloc[:,0]=[115,108,112,118] # 修改整列資料
df.iloc[0,:]=[120,115,109] # 修改整行資料
3. 洗掉資料
洗掉資料主要使用 DataFrame 物件中的 drop() 方法,語法如下:
def drop(self, labels=None, axis=0, index=None,
columns=None, level=None, inplace=False, errors="raise",)
引數說明:
- labels:表示行標簽或列標簽,
- axis:axis = 0,表示按行洗掉;axis = 1,表示按列洗掉,默認值為 0,
- index:洗掉行,默認值為 None,
- columns:洗掉列,默認值為 None,
- level:針對有兩級索引的資料,level = 0,表示按第 1 級索引洗掉整行;level = 1,表示按第 2 級索引洗掉整行,默認值為 None,
- inplace:可選引數,對原陣列作出修改并回傳一個新陣列,默認值為 False,如果值為 True,那么原陣列直接就將被替換,
- errors:引數值為 ignore 或 raise,默認值為 raise,如果值為 ignore(忽略),則取消錯誤,
1. 洗掉行列資料
洗掉指定的學生成績資料,關鍵代碼如下:
df.drop(["數學"],axis=1,inplace=True) # 洗掉某列
df.drop(columns="數學",inplace=True) # 洗掉columns為數學的列
df.drop(labels="數學",axis=1,inplace=True) # 洗掉列標簽為數學的列
df.drop(["明日", "二月二"],inplace=True) # 洗掉某一行
df.drop(index="明日",inplace=True) # 洗掉index為明日的行
df.drop(labels="明日",axis=0,inplace=True) # 洗掉行標簽為明日的行
2. 洗掉特定條件的行
洗掉滿足特定條件的行,首先找到滿足該條件的行索引,然后再使用 drop() 方法將其洗掉,洗掉數學中包含分數 88 的行語文小于分數 110 的行,關鍵代碼如下:
df.drop(index=df[df["數學"].isin([88])].index[0], inplace=True) # 洗掉數學包含分數88的行
df.drop(index=df[df["語文"]<110].index[0],inplace=True) # 洗掉語文小于分數110的行
七、資料清洗
1. 查看與處理缺失值
缺失值指的是由于某種原因導致資料為空,這種情況一般有四種處理方式:一是不處理;二是洗掉;三是填充或替換;四是插值 (以均值、中位數、眾數等填補),
1. 查看缺失值
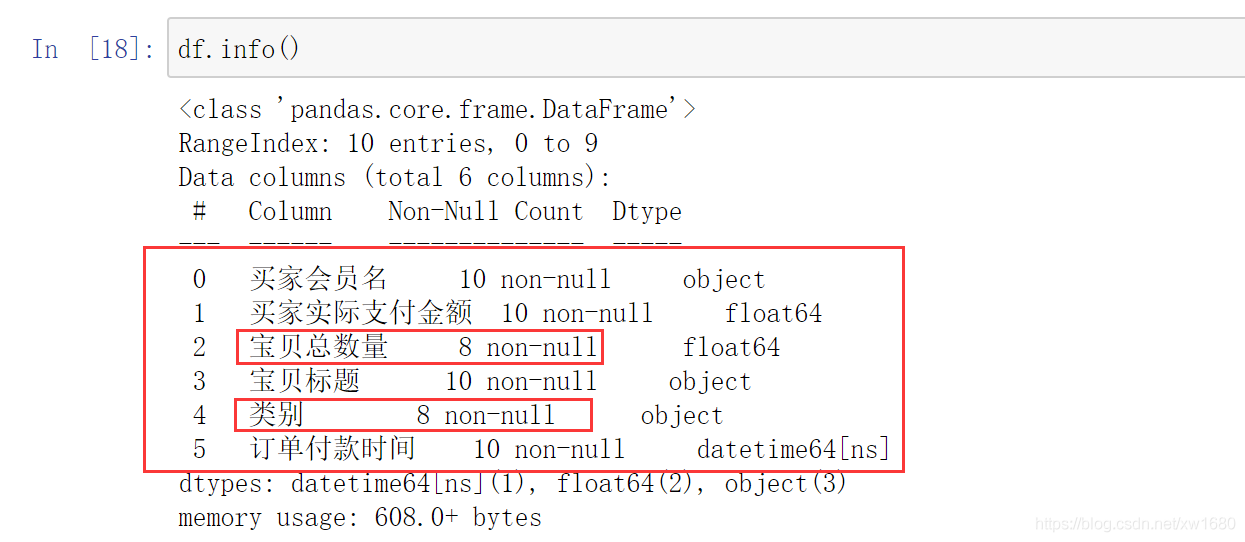
首先需要找到缺失值,主要使用 DataFrame 物件中的 info 方法,以淘寶銷售資料為例,首先輸出資料,然后使用 info 方法查看資料,程式代碼如下:
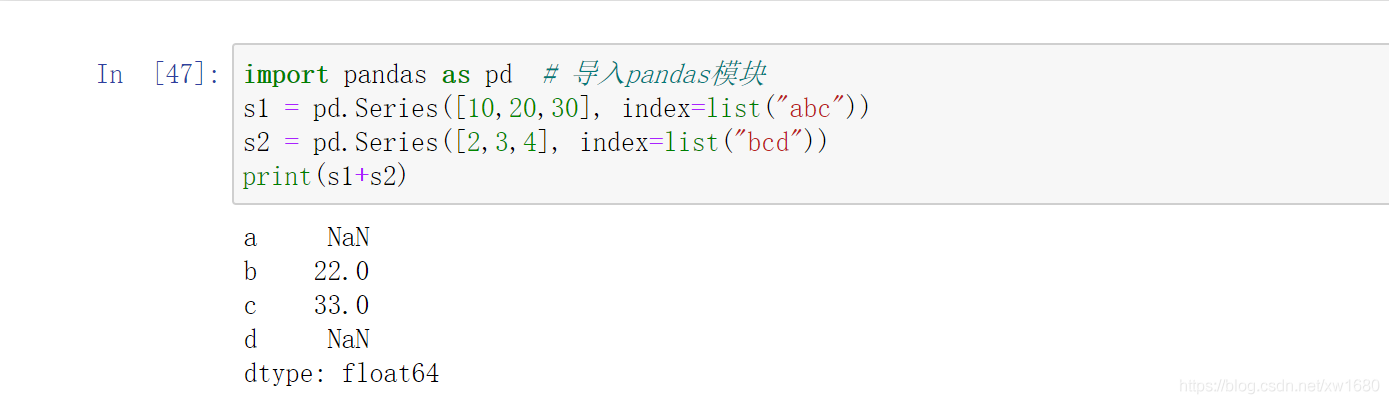
import pandas as pd # 匯入pandas模塊
df = pd.read_excel("TB2018.xls")
print(df)
print(df.info())
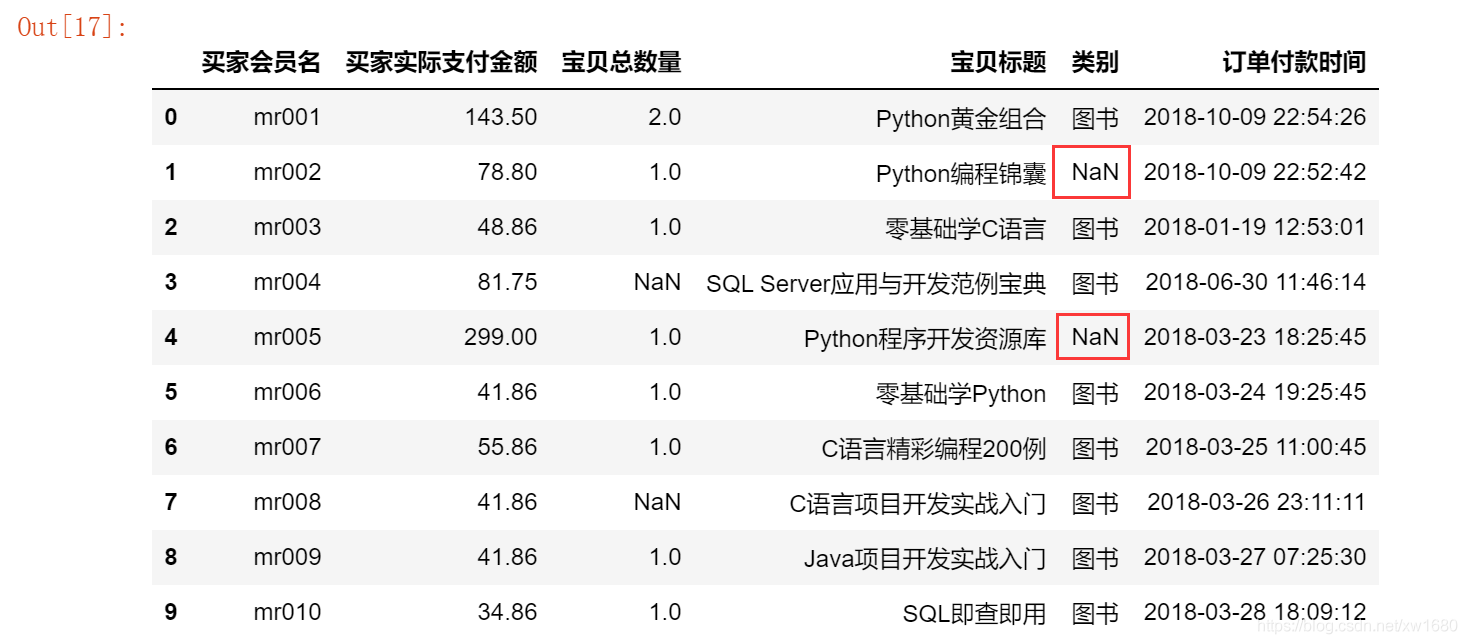
在 Python 中,缺失值一般以 NaN 表示,如上圖所示,通過 info() 方法可以看到買家會員名、買家實際支付金額、寶貝標題和訂單付款時間的非空數量是 10,而寶貝總數量和類別的非空數量是 8,則說明這兩項存在空值,
現在判斷資料是否存在缺失值,還可以使用 isnull() 方法和 notnull() 方法,關鍵代碼如下:
print(df.isnull())
print(df.notnull())
輸出結果如下圖所示:
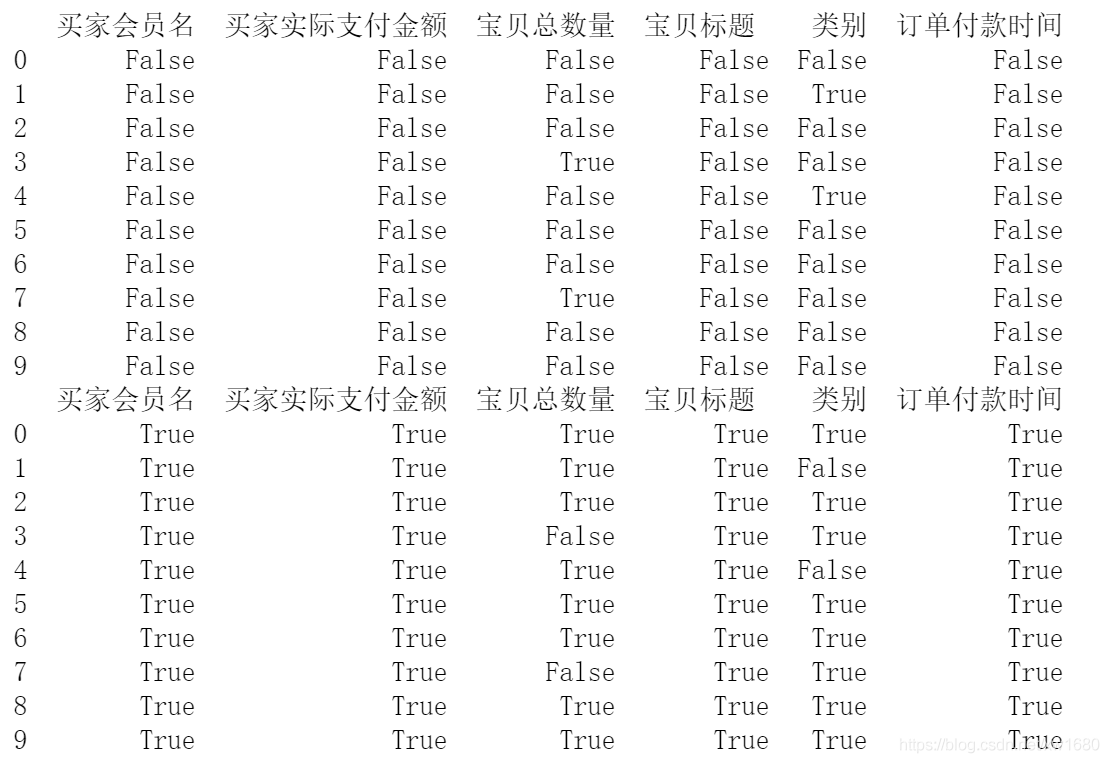
使用 isnull() 方法,缺失值回傳 True;非缺失值回傳 False;而 notnull() 方法與 isnull() 方法正好相反,即缺失值回傳 False;非缺失值回傳 True,如果使用 df[df.isnull()=False] 陳述句,則會將所有不是缺失值的資料找出來,但是只針對 Series 物件,
2. 缺失值洗掉處理
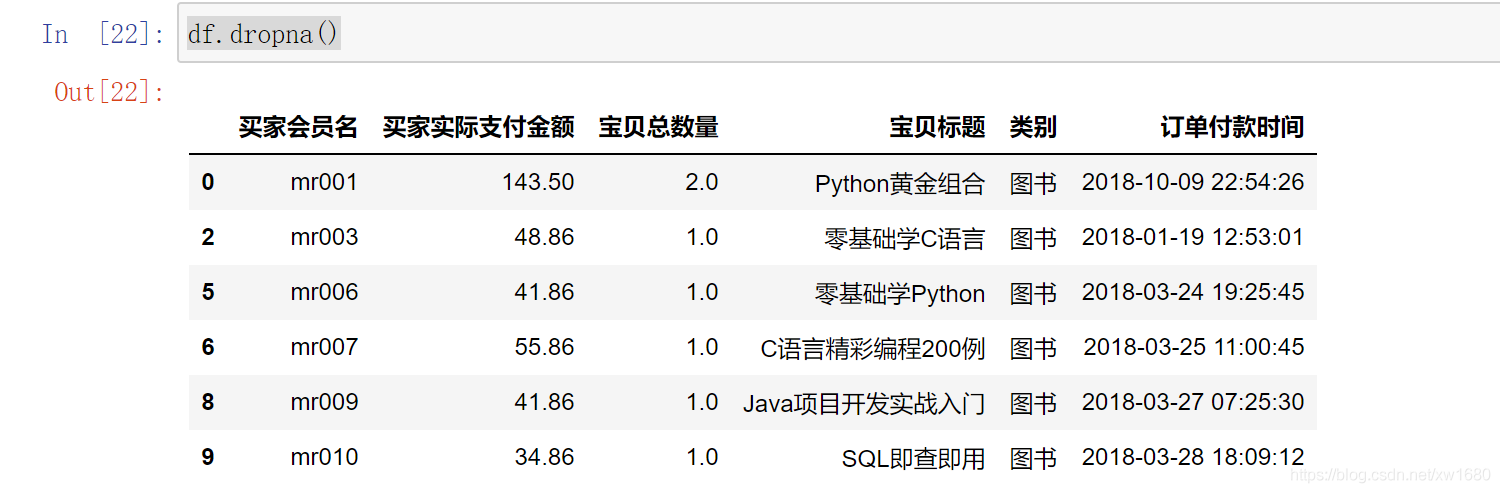
通過前面的判斷得知了資料缺失情況,下面將缺失值洗掉,主要使用 dropna() 方法,該方法用于洗掉含有缺失值的行,關鍵代碼如下:
df.dropna()
輸出結果如圖所示:
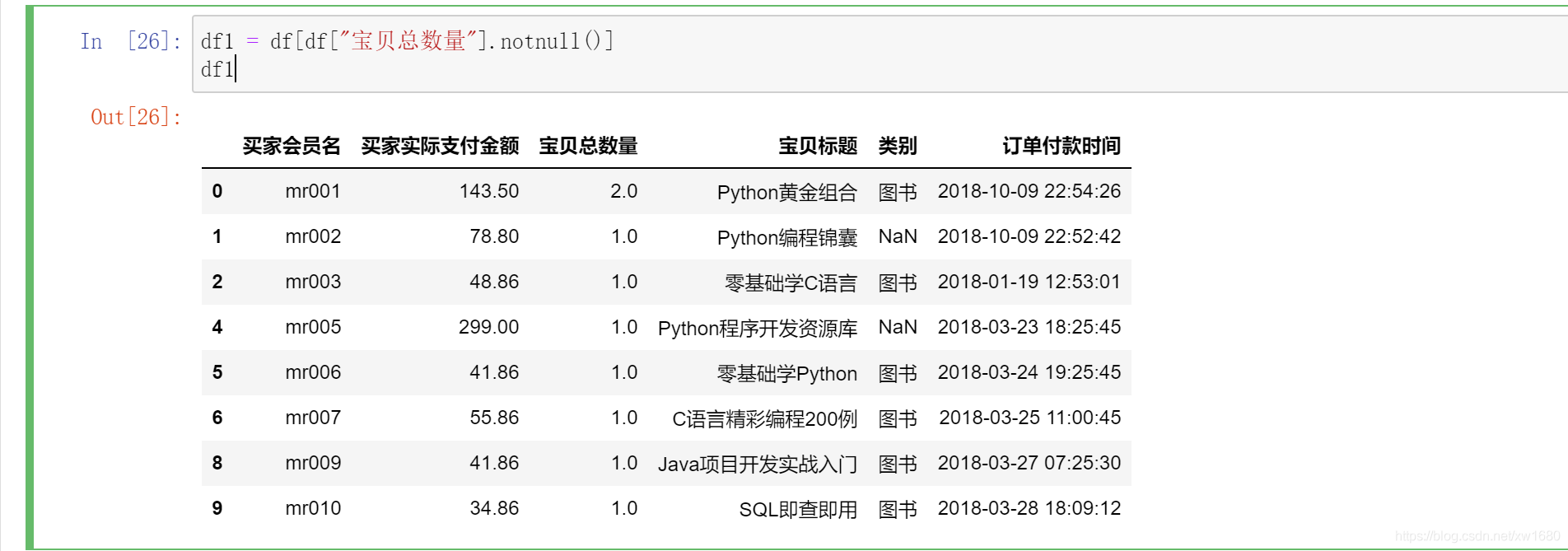
有些時候,資料可能存在整行為空的情況,此時可以在 dropna() 方法中指定引數 how=“all”,洗掉所有空行,從運行結果得知:dropna() 方法將所有包含缺失值的資料全部洗掉了,那么,此時如果認為有些資料雖然存在缺失值,但是不影響資料分析,那么可以使用以下方法進行處理,例如,在上述資料中只保留寶貝總數量中不存在缺失值的資料,而類別是否缺失無所謂,則可以使用 notnull() 方法判斷,關鍵代碼如下:
3. 缺失值填充處理
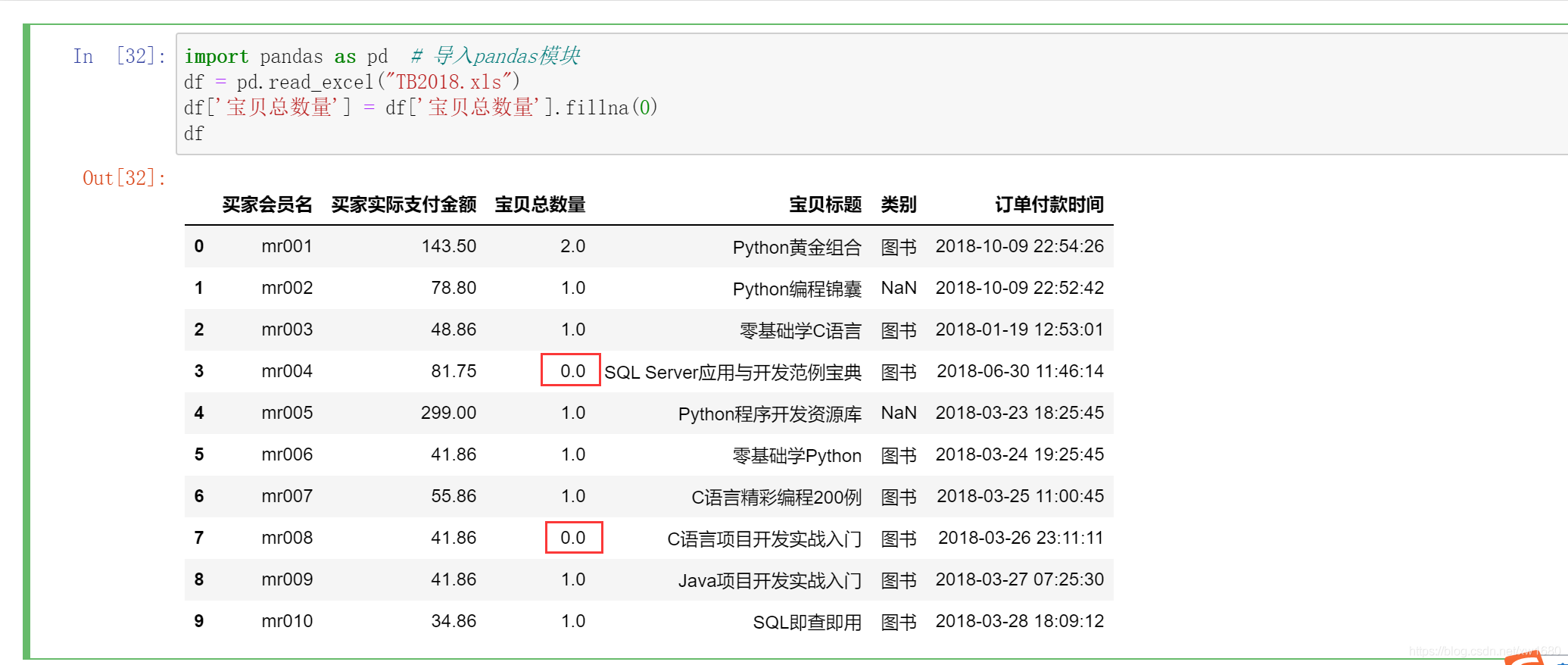
對于缺失資料,如果比例高于 30%,則可以選擇放棄這個指標,進行洗掉處理;低于 30% 時,盡量不要洗掉,而是選擇將這部分資料填充,一般以 0、均值、眾數(大多數) 填充,DataFrame 物件中的 fillna 函式可以實作填充缺失資料,pad/ffill() 函式表示用前一個非缺失值去填充該缺失值;backfill/bfill() 函式表示用下一個非缺失值填充該缺失值;None 用于指定一個值去替換缺失值,
對于用于計算的數值型資料,如果為空,可以選擇用 0 填充,例如,將寶貝總數量為空的資料填充為 0,代碼如下:
2. 重復值處理
對于資料中存在的重復資料,包括重復的行或者某幾行中某幾列的值重復,一般做洗掉處理,主要使用 DataFrame 物件中的 drop_duplicates() 方法,
下面以 2月.xlsx 的淘寶銷售資料為例,對其中的重復資料進行處理,
-
判斷每一行資料是否重復(完全相同)
df.duplicated() -
去除重復的全部資料
df.drop_duplicates() -
去除指定列的重復資料
df.drop_duplicates(["買家會員名"]) -
保留重復行中的最后一行
df.drop_duplicates(["買家會員名"], keep="last")以上代碼中引數 keep 的值有三個,當 keep=“first” 表示保留第一次出現的重復行時,是默認值;當 keep 為另外兩個取值 last 和 False 時,分別表示保留最后一次出現的重復行和去除所有的重復行,
-
直接洗掉,保留一個副本
df.drop_duplicates(["買家會員名","買家支付寶賬號"], inplace=False)inplace=True 表示直接在原來的 DataFrame 物件上洗掉重復項,而默認值 False 表示洗掉重復項后再生成一個副本,
3. 例外值的檢測與處理
首先了解一下什么是例外值,在資料分析中,例外值是指超出或低于正常范圍的值,如年齡大于 200、身高大于 3 米、寶貝總數量為負數等類似資料,那么這些資料如何檢測呢?主要有以下幾種方法:
- 根據給定的資料范圍進行判斷,不在范圍內的資料視為例外值,
- 均方差,在統計學中,如果一個資料分布近似正態分布(資料分布的一種形式,呈鐘型,兩頭低,中間高,左右對稱,因其曲線呈鐘形),那么大約 68% 的資料值都會在均值的一個標準差范圍內,大約 95% 的資料值會在兩個標準差范圍內,大約 99.7% 的資料值會在三個標準差范圍內,
- 箱形圖,箱形圖是顯示一組資料分散情況資料的統計圖,它可以將資料通過四分位數的形式進行圖形化描述,箱形圖通過上限和下限作為資料分布的邊界,任何高于上限或低于下限的資料都可以認為是例外值,如圖所示,
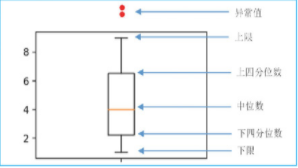
了解例外值的檢測后,接下來介紹如何處理例外值,主要包括以下幾種處理方式:
- 最常用的方式是洗掉,
- 將例外值當缺失值處理,以某個值填充,
- 將例外值當特殊情況進行分析,研究例外值出現的原因,
八、索引值的設定
索引能夠快速查詢資料,本節主要介紹索引的作用以及應用,
1. 索引的作用
索引的作用相當于圖書的目錄,可以根據目錄中的頁碼快速找到所需的內容,Pandas 索引的作用如下:
- 更方便地查詢資料,
- 使用索引可以提升查詢性能,
- 如果索引是唯一的,Pandas 會使用哈希表優化,查找資料的時間復雜度為O(1),
- 如果索引不是唯一的,但是有序,Pandas 會使用二分查找演算法,查找資料的時間復雜度為O(logN),
- 如果索引是完全隨機的,那么每次查詢都要掃描資料表,查找資料的時間復雜度為O(N),
- 利用索引實作自動的資料對齊功能,如圖所示,
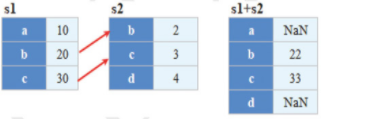
實作上述效果,程式代碼如下:
- 強大的資料結構
- 基于分類數的索引,提升性能,
- 多維索引,用于 group by 多維聚合結果等,
- 時間型別索引,強大的日期和時間的方法支持,
2. 重新設定索引
Pandas 有一個很重要的方法是 reindex,它的作用是創建一個適應新索引的新物件,常用引數說明:
- labels:標簽,可以是陣列,默認值為 None,
- index:行索引,默認值為 None,
- columns:列索引,默認值為 None,
- axis:軸,0 表示行;1 表示列,默認值為 None,
- method:默認值為 None,重新設定索引時,選擇插值(用來填充缺失資料) 方法,其值可以是 None、bfill/backfill(向后填充)、ffill/pad(向前填充)等,
- fill_value:缺失值要填充的資料,如缺失值不用 NaN 填充,用 0 填充,則設定
fill_value=0即可,
1. 對 Series 物件重新設定索引
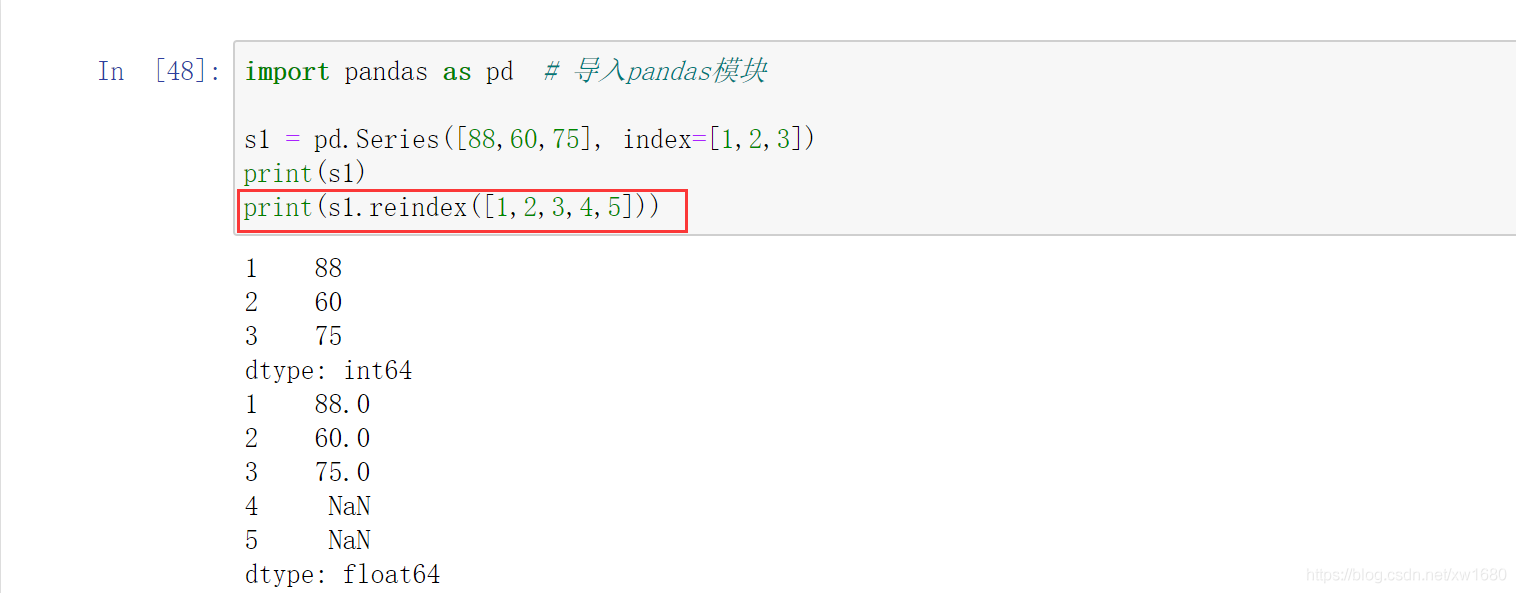
從運行結果得知:reindex() 方法根據新索引進行了重新排序,并且對缺失值自動填充 NaN,如果不想用 NaN 填充,可以為 fill_value 引數指定值,例如 0,關鍵代碼如下:
print(s1.reindex([1,2,3,4,5], fill_value=0))
而對于有一定順序的資料,則可能需要插值來填充缺失的資料,這時可以使用 method 引數,實作向前填充(和前面資料一樣)、向后填充(和后面資料一樣),關鍵代碼如下:
print(s1.reindex([1,2,3,4,5], method="ffill")) # 向前填充
print(s1.reindex([1,2,3,4,5], method="bfill")) # 向后填充
2. 對 DataFrame 物件重新設定索引
對于 DataFrame 物件,reindex() 方法用于修改行索引和列索引,通過二維陣列創建成績表,程式代碼如下:
import pandas as pd # 匯入pandas模塊
# 解決資料輸出時列名不對齊的問題
pd.set_option("display.unicode.east_asian_width", True)
data = [[110,105,99],[105,88,115],[109,120,130]]
index = ["amo001", "amo003", "amo005"]
columns = ["語文", "數學", "英語"]
df = pd.DataFrame(data=data, index=index, columns=columns)
print(df)
通過 reindex 方法重新設定行索引,關鍵代碼如下:
print(df.reindex(["amo001","amo002","amo003","amo004","amo005"]))
通過 reindex 方法重新設定列索引,關鍵代碼如下:
print(df.reindex(columns=["語文","物理","數學","英語"]))
通過 reindex 方法重新設定行索引和列索引,關鍵代碼如下:
print(df.reindex(index=["amo001", "amo002", "amo003", "amo004", "amo005"],columns=["語文","物理","數學","英語"]))
3. 設定某列為索引
設定某列為行索引主要使用 set_index 方法,首先,匯入 1月.xlsx 的 Excel 檔案,程式代碼如下:
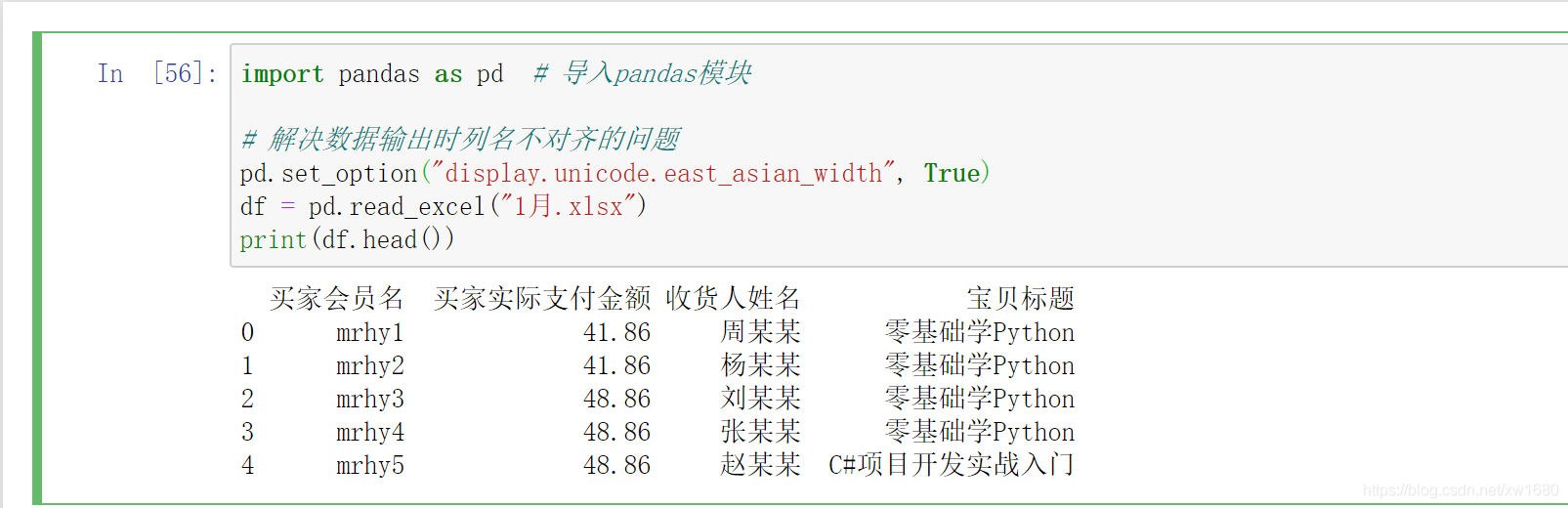
此時默認行索引為 0、1、2、3、4,下面將買家會員名作為行索引,代碼如下:
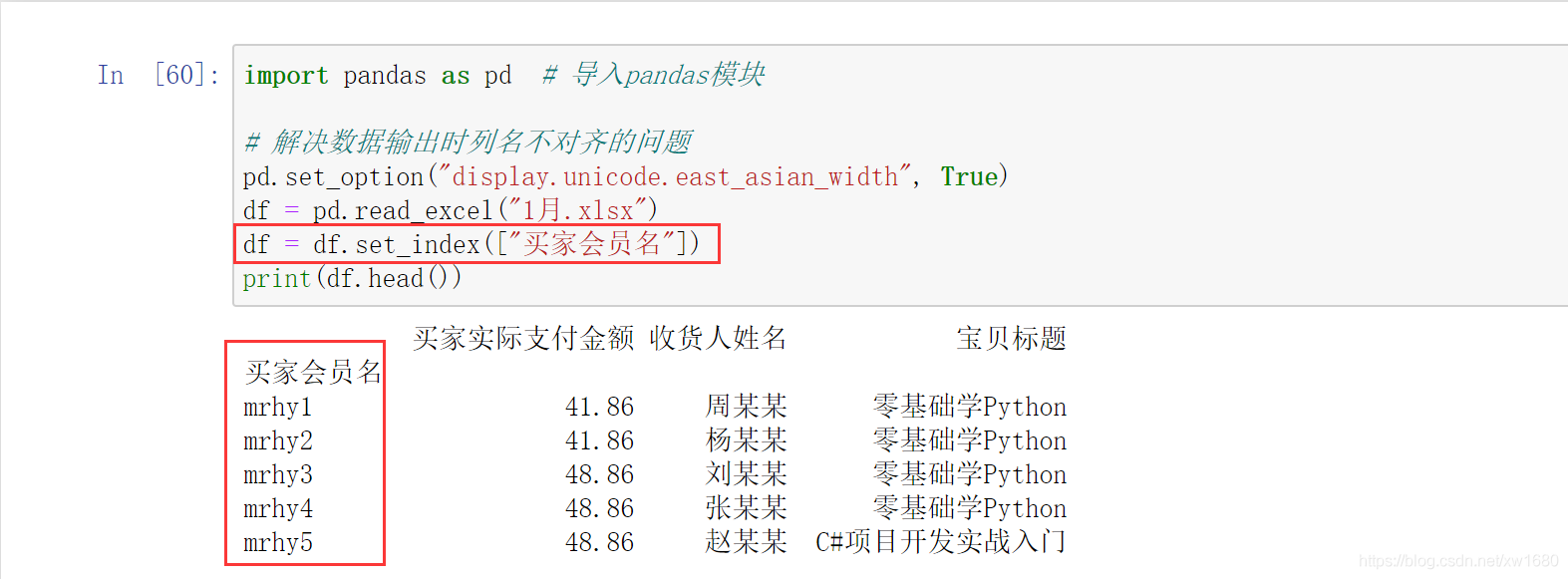
如果在 set_index 方法中傳入引數 drop=True,則會洗掉買家會員名;如果傳入 drop=False,則會保留買家會員名,默認為 False,
4. 資料清洗后重新設定連續的行索引
當我們對 DataFrame 物件進行資料清洗之后,例如,去掉含 NaN 的行之后,發現行索引沒有變化,如果要重新設定索引則可以使用 reset_index 方法,在洗掉缺失資料后重新設定索引,關鍵代碼如下:
df.dropna().reset_index(drop=True)
另外,對于分組統計后的資料,有時也需要重新設定連續的行索引,方法同上,
九、資料排序與排名
1. 資料排序
DataFrame 資料排序時主要使用 sort_values() 方法,該方法類似于 SQL 中的 order by 方法,sort_values() 方法可以根據指定行/列進行排序,引數說明:
- by:要排序的名稱串列,
- axis:軸,0 表示行;1 表示列,默認按行排序,
- ascending:升序或降序排序,布林值,指定多個排序可以使用布林值串列,默認值為 True,升序,如果要降序排列,改為 False 即可,
- inplace:布林值,默認值為 False,如果值為 True,則就地排序,
- kind:指定排序演算法,值為 quicksort(快速排序)、mergesort(混合排序) 或 heapsort(堆排),默認值為 quicksort,
- na_position:空值(NaN)的位置,值為 first 空值在資料開頭,值為 last 空值在資料最后,默認值為 last,
- ignore_index:布林值,是否忽略索引,值為 True 標記索引(從 0 開始按順序的整數值),值為 False 則忽略索引,
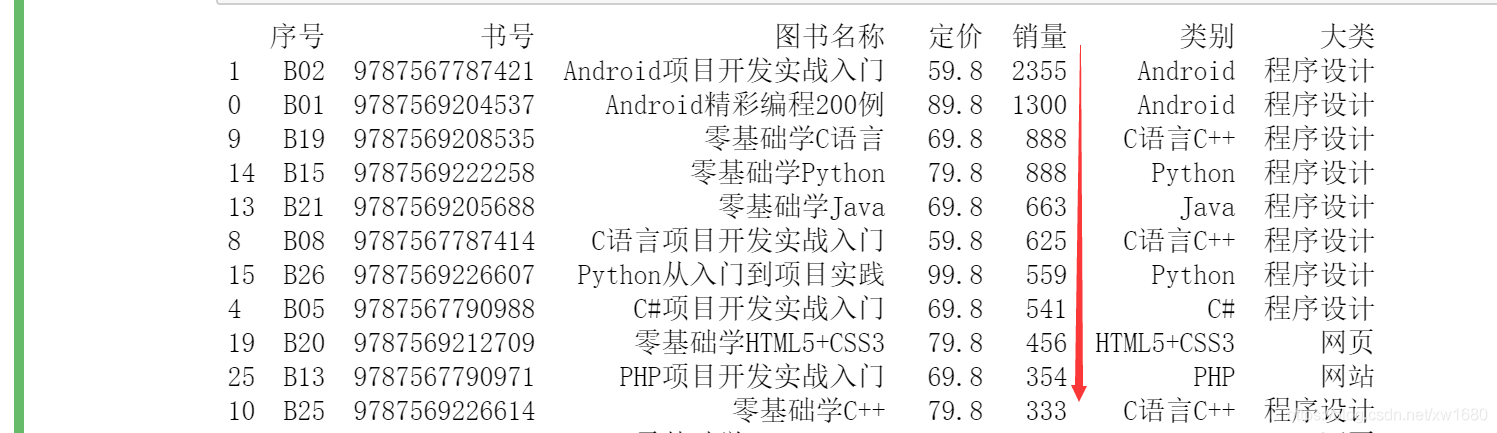
1. 按銷量進行降序排列,示例代碼如下:
import pandas as pd # 匯入pandas模塊
excelFile = "mrbook.xlsx"
df = pd.DataFrame(pd.read_excel(excelFile))
# 設定資料顯示的列數和寬度
pd.set_option("display.max_columns", 500)
pd.set_option("display.width", 1000)
# 解決資料輸出時列名不對齊的問題
pd.set_option("display.unicode.ambiguous_as_wide", True)
pd.set_option("display.unicode.east_asian_width", True)
# 按銷量列降序排列
df = df.sort_values(by="銷量", ascending=False)
print(df)
如下圖所示:
2. 按照圖書名稱和銷量降序排序
按照圖書名稱和銷量進行降序排序,首先按圖書名稱降序排序,然后再按銷量降序排序,關鍵代碼如下:
df = df.sort_values(by=["圖書名稱", "銷量"], ascending=False)
3. 對分組統計資料進行排序
df1 = df.groupby(["類別"])["銷量"].sum().reset_index()
df2 = df1.sort_values(by="銷量", ascending=False)
4. 按行資料進行排序
dfrow.sort_values(by=0,ascending=True,axis=1)
按行排序的資料型別要一致,否則會出現錯誤提示,
2. 資料排名
排名是根據 Series 或 DataFrame 物件的某幾列的值進行排名,主要使用 rank 方法,引數說明:
- axis:軸,0 表示行;1 表示列,默認按行排序,
- method:表示在具有相同值的情況下所使用的排序方法,設定值如下:
- average:默認值,平均排名,
- min:最小值排名,
- max:最大值排名,
- first:按值在原始資料中的出現的順序分配排名,
- dense:密集排名,類似最小值排名,但是排名每次只增加 1,即排名相同的資料只占一個名次,
- numeric_only:對于 DataFrame 物件,如果設定值為 True,則只對數字列進行排序,
- na_option:空值的排序方式,設定值如下:
- keep:保留,將空值等級賦值給 NaN 值,
- top:如果按升序排序,則將最小排名賦值給 NaN 值,
- bottom:如果按升序排序,則將最大排名賦值給 NaN 值,
- ascending:升序或降序排序,布林值,指定多個排序可以使用布林值串列,默認值為 True,
- pct:布林值,是否以百分比形式回傳排名,默認值為 False,
1. 對產品銷量按順序進行排名
import pandas as pd # 匯入pandas模塊
excelFile = "mrbook.xlsx"
df = pd.DataFrame(pd.read_excel(excelFile))
# 設定資料顯示的列數和寬度
pd.set_option("display.max_columns", 500)
pd.set_option("display.width", 1000)
# 解決資料輸出時列名不對齊的問題
pd.set_option("display.unicode.ambiguous_as_wide", True)
pd.set_option("display.unicode.east_asian_width", True)
# 按銷量列降序排序
df = df.sort_values(by="銷量", ascending=False)
# 順序排名
df["順序排名"] = df["銷量"].rank(method="first", ascending=False)
print(df[["圖書名稱","銷量", "順序排名"]])
2. 對產品銷量進行平均排名
現在對銷量相同的產品,按照順序排名的平均值進行平均排名,關鍵代碼如下:
df["平均排名"] = df["銷量"].rank(ascending=False)
3. 最小值排名
銷量相同的,按順序排名并取最小值作為排名,關鍵代碼如下:
df["銷量"].rank(method="min", ascending=False)
4. 最大值排名
銷量相同的,按順序排名并取最大值作為排名,關鍵代碼如下:
df["銷量"].rank(method="max", ascending=False)
本篇博文介紹了 Pandas 資料處理的基本知識,從最初的資料來源開始 (創建 DataFrame 資料或匯入外部資料) 到資料抽取、資料的增、刪、改操作、資料清洗、索引到資料排序,包括常用的資料處理操作基本都涉及到了,筆者希望通過本篇博文的學習能夠幫助讀者獨立完成一些簡單的資料處理作業,
感謝您閱讀本篇博文,希望本文能成為您編程路上的領航者,祝您閱讀愉快!

好書不厭讀百回,熟讀課思子自知,而我想要成為全場最靚的仔,就必須堅持通過學習來獲取更多知識,用知識改變命運,用博客見證成長,用行動證明我在努力,
如果我的博客對你有幫助、如果你喜歡我的博客內容,請點贊、評論、收藏一鍵三連哦!聽說點贊的人運氣不會太差,每一天都會元氣滿滿呦!如果實在要白嫖的話,那祝你開心每一天,歡迎常來我博客看看,
?編碼不易,大家的支持就是我堅持下去的動力,點贊后不要忘了關注我哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/256845.html
標籤:其他