
一、前言:
我們在?產環境中,程式代碼、硬體、?絡、協作軟體等任?因素,都會引發意想不到的問題,所以排查產線問題?較困難,所以問題的定位體現了?名?程師的基礎能?,問題的解決則體現了?程師的技能素養,
二、線上常見問題
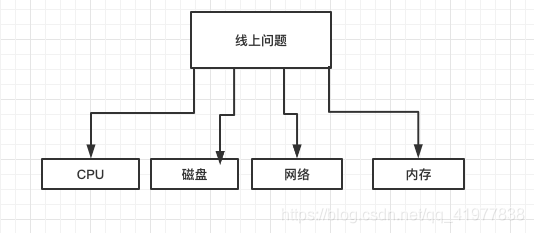
如出現 (CPU占?率過?、磁盤使?率100%、系統可?記憶體低、服務間調?時間過?、多執行緒并發例外、死鎖等)
三、定位問題
方案 :
- 業務?志分析排查
通常情況下,?部分錯誤資訊都會在?志上有所體現
public static void main(String[] args) throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(100000);
System.out.println("開始執行");
for (int i = 0; i < 100000000; i++) {
executorService.execute(() -> {
String payload = IntStream.rangeClosed(1, 1000000)
.mapToObj(__ -> "a") .collect(Collectors.joining("")) + UUID.randomUUID().toString();
System.out.println("等待一小時開始");
try {
TimeUnit.HOURS.sleep(1);
}catch (Exception e){
log.info(payload);
}
});
}
executorService.shutdown();
executorService.awaitTermination(1,TimeUnit.HOURS);
}
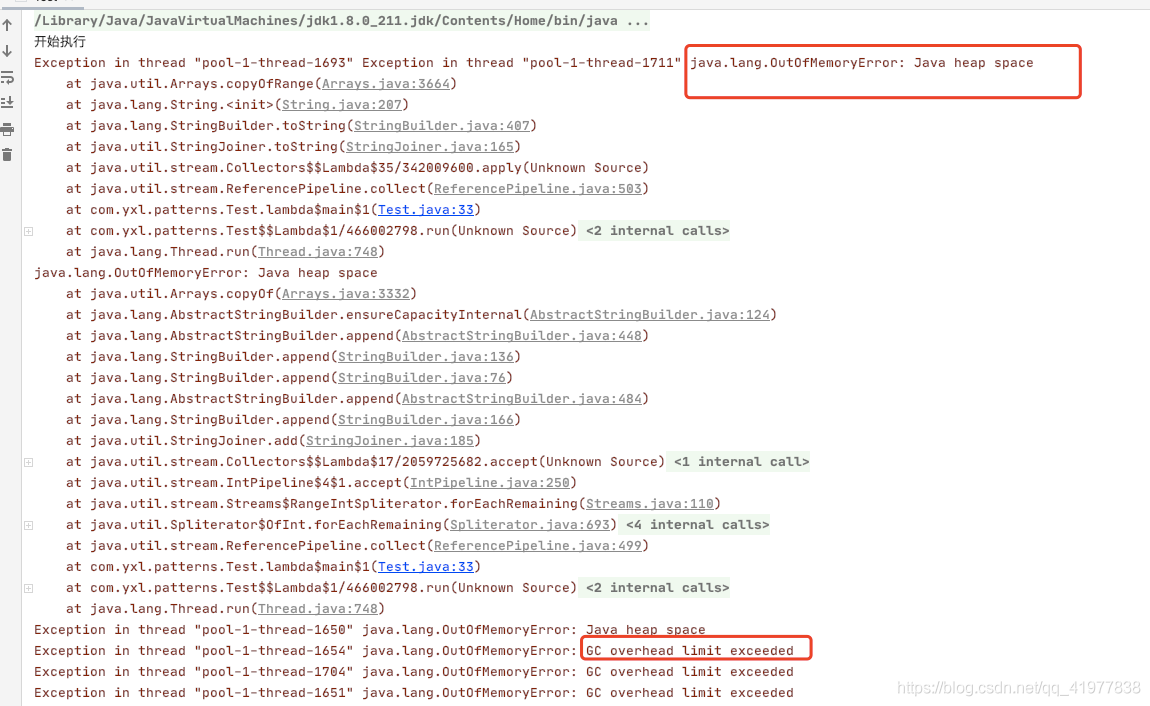
通過日志可以發現出錯誤的位置是 第33行,報錯java.lang.OutOfMemoryError 錯誤, 因為我們看下 newFixedThreadPool 方法的原始碼,發現,執行緒池的作業佇列直接 new 了一個 LinkedBlockingQueue,他是一個無界佇列,如果任務較多并且執行較慢但話,佇列可能會快速積壓,撐爆記憶體導致OOM
我們 ?定要在關鍵代碼邏輯位置輸出相關?志,尤其是在代碼發?例外的時候,定要將?志輸出到?件中,只有這樣,才更利于我們的排查,
- APM分析排查
APM,全稱Application Performance Management,應?性能管理,?的是通過各種探針采集資料, 收集關鍵指標,同時搭配資料呈現以實作對應?程式性能管理和故障管理的系統化解決?案,通過分布 式鏈路調?跟蹤系統,通過在系統請求中透傳 trace-id,將所有相關?志進?聚合,然后?志統?采集 和分析后,以圖形化的形式展示給?程師們,?他們在排查問題的時候,可以簡單粗暴且直觀的調度出 問題最根本的原因,
通常在分布式架構中,僅通過分析單個服務的?志資訊是不夠的,此時則需要APM進?全鏈路分析,通過請求鏈路監控,實時的發現鏈路中相關服務的例外情況,
?前市場上使?較多的鏈路跟蹤?具有如下?個:
-
大眾點評 CAT :GitHub - dianping/cat: Central Application Tracking
-
Apache Skywalking:https://skywalking.apache.org/
-
Pinpoint:https://pinpoint.com/product/for-engineers
-
SpringCloud Zipkin:https://docs.spring.io/spring-cloud-sleuth/docs/current-SNAPSHOT/referencre/html/#sending-spans-to-zipkin
- 物理環境排查
CPU分析
- CPU使?率是衡量系統繁忙程度的重要指標,但是CPU使?率的安全閾值是相對的,取決于你的系統的IO密集型還是計算密集型,?般計算密集型應?CPU使?率偏?load偏低,IO密集型相反,
[root@ ~]# top
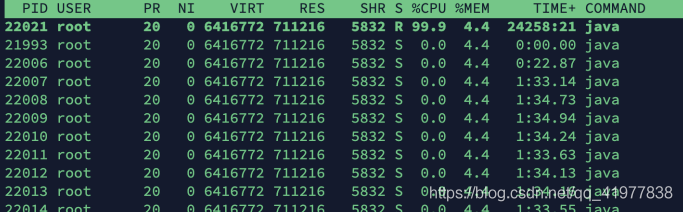
top命令是Linux下常?的 CPU 性能分析?具,能夠實時顯示系統中各個行程的資源占?狀況,常?于服務端性能分析,
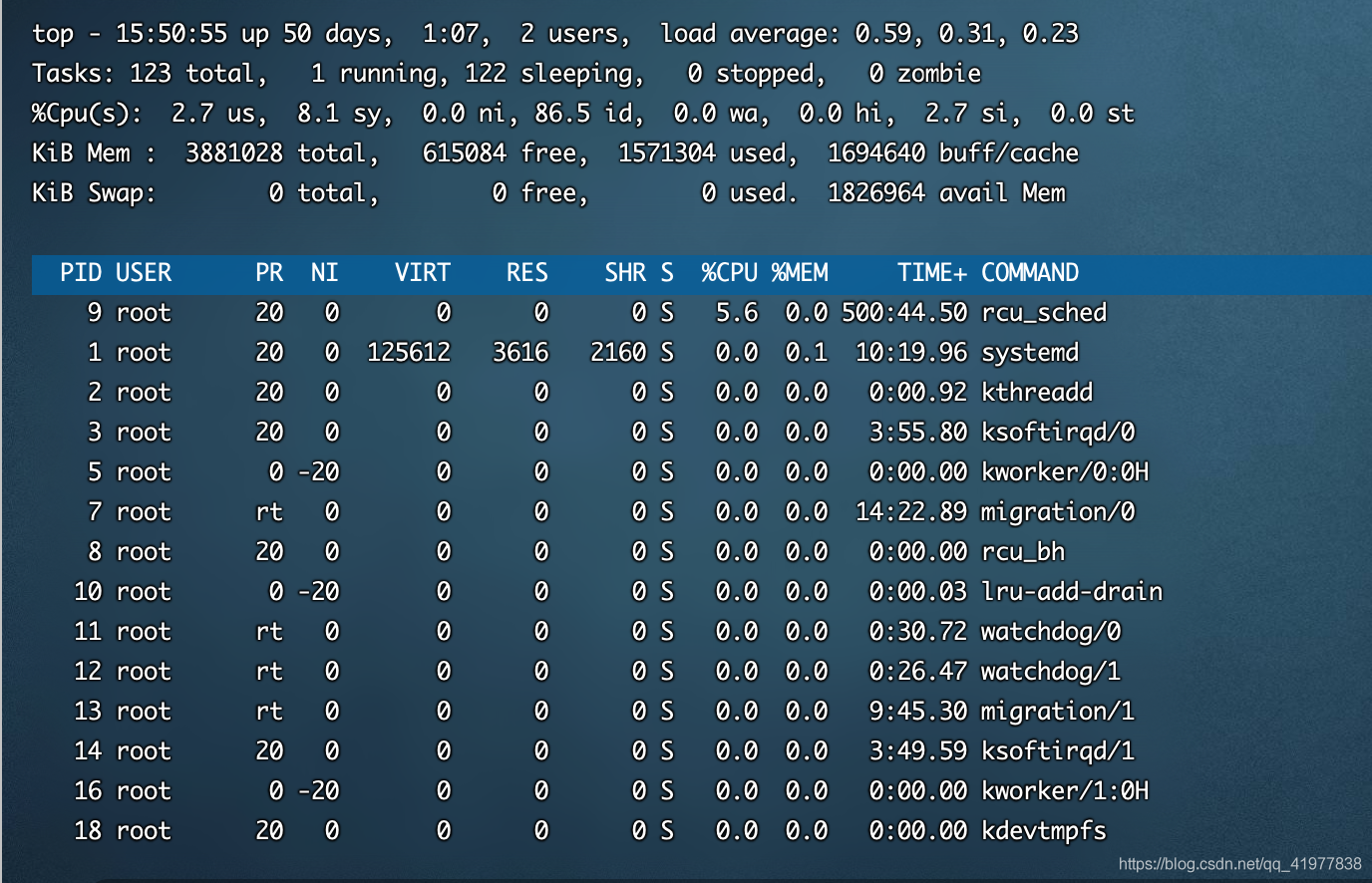
top 命令顯示了各個行程 CPU 使?情況,?般 CPU 使?率從?到低排序展示輸出,其中 LoadAverage 顯示最近1分鐘、5分鐘和15分鐘的系統平均負載,上圖各值為3.4、3.31、3.46,
我們?般會關注 CPU 使?率最?的行程,正常情況下就是我們的應?主行程,第七?以下:各進
程的狀態監控,引數說明:
- PID : 行程id
- USER : 行程所有者的?戶名
- PR : 行程優先級
- NI : nice值,負值表示?優先級,正值表示低優先級
- VIRT : 行程使?的虛擬記憶體總量,單位kb
- SHR : 共享記憶體??
- %CPU : 上次更新到現在的CPU時間占?百分?
- %MEM : 行程使?的物理記憶體百分?
- TIME+ : 行程使?的CPU時間總計,單位1/100秒
- COMMAND : 命令名稱、命令?
記憶體
[root@ ~]# free -h
記憶體是排查線上問題的重要參考依據,free 是顯示的當前記憶體的使?,-h 表示?類可讀性,

引數說明:
- total :記憶體總數
- used:已經使?的記憶體數
- free:空閑的記憶體數
- shared:被共享使?的物理記憶體??
- buffers/buffer:被 buffer 和 cache 使?的物理記憶體??
- available: 還可以被應?程式使?的物理記憶體??
磁盤
[root@ ~]# df -h
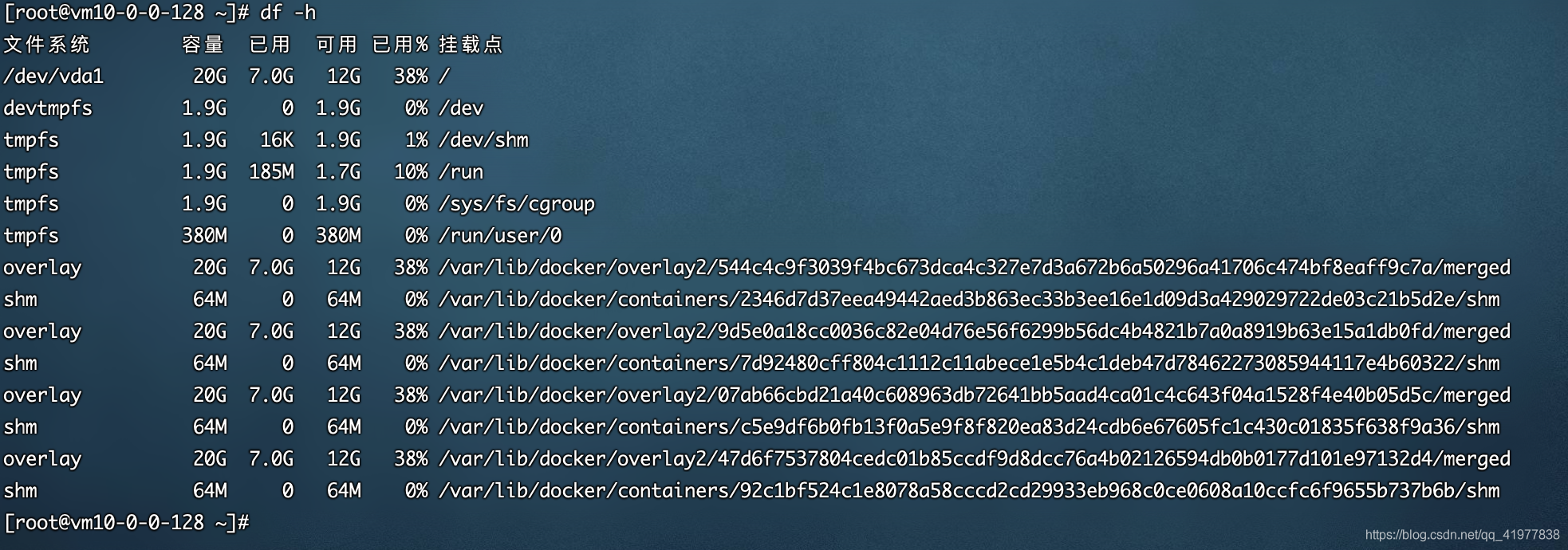
?絡
[root@ ~]# dstat
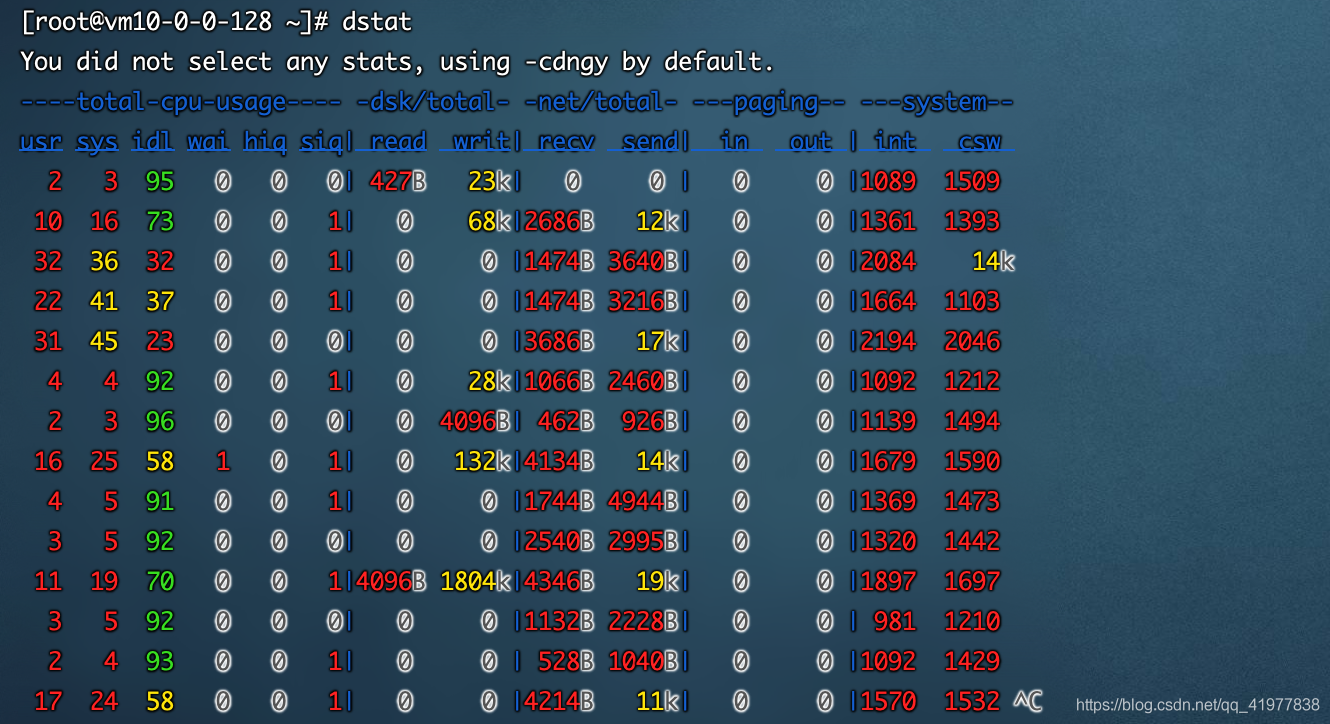
默認情況下,dstat每秒都會重繪資料
三、Arthas診斷命令

Arthas 是Alibaba開源的Java診斷工具,深受開發者喜愛,
- 當你遇到以下類似問題而束手無策時,Arthas可以幫助你解決:
- 這個類從哪個 jar 包加載的?為什么會報各種類相關的 Exception?
- 我改的代碼為什么沒有執行到?難道是我沒 commit?分支搞錯了?
- 遇到問題無法在線上 debug,難道只能通過加日志再重新發布嗎?
- 線上遇到某個用戶的資料處理有問題,但線上同樣無法 debug,線下無法重現!
- 是否有一個全域視角來查看系統的運行狀況?
- 有什么辦法可以監控到JVM的實時運行狀態?
- 怎么快速定位應用的熱點,生成火焰圖?
官方檔案 :https://arthas.aliyun.com/doc/
安裝
[root ~]# mkdir arthas
[root ~]# cd arthas/
[root ~]# wget https://maven.aliyun.com/repository/public/com/taobao/arthas/arthas-packaging/3.1.4/arthas-packaging-3.1.4-bin.zip
[root ~]# rm -rf /home/admin/.arthas/lib/*
[root ~]# cd arthas
[root ~]# ./install-local.sh
[root ~]# java -jar arthas-boot.jar
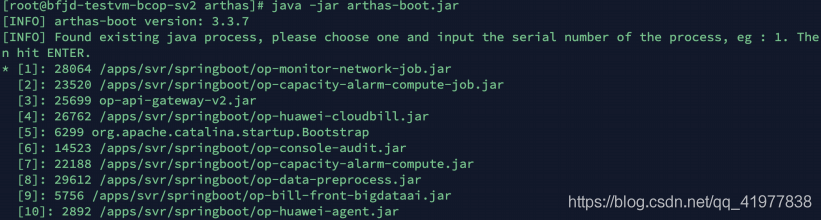
arthas 會列出已存在的Java行程,并提醒輸?序號,鍵?回?,進?arthas 診斷界?,
arthas常?命令介紹
- jvm 查看當前 JVM 的資訊
- thread 查看當前 JVM 的執行緒堆疊資訊,-b選項可以?鍵檢測死鎖
- trace ?法內部調?路徑,并輸出?法路徑上的每個節點上耗時,服務間調?時間過?時使?
- stack 輸出當前?法被調?的調?路徑
- Jad 反編譯指定已加載類的原始碼,反編譯便于理解業務
- logger 查看和修改logger,可以動態更新?志級別,
四、JVM問題定位命令
在 JDK 安裝?錄的 bin ?錄下默認提供了很多有價值的命令??具,每個??具體積基本都?較?,因
為這些?具只是 jdk\lib\tools.jar 的簡單封裝,
其中,定位排查問題時最為常?命令包括:jps(行程)、jmap(記憶體)、jstack(執行緒)、jinfo(參
數)等,
- jps:查詢當前機器所有Java行程資訊
- jmap:輸出某個 Java 行程記憶體情況
- jstack:列印某個 Java 執行緒的執行緒堆疊資訊
- jinfo:?于查看 jvm
1. jps
jps ?于輸出當前?戶啟動的所有行程 ID,當線上發現故障或者問題時,利? jps 快速定位對應的 Java
行程 ID,
[root ~]# jps -m
引數解釋:
- m:輸出傳? main ?法的引數
- l:輸出完全的包名,應?主類名,jar的完全路徑名

當然,我們也可以使? Linux 提供的查詢行程狀態命令也能快速獲取 Tomcat 服務的行程 id,?如:
[root ~]# ps -ef|grep tomcat
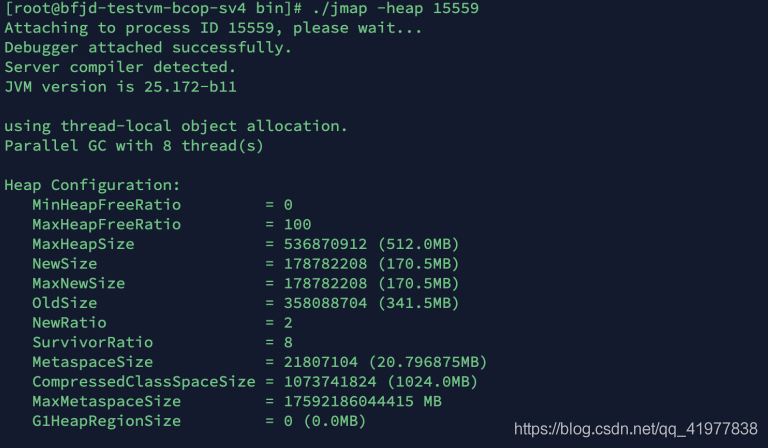
2. jmap
jmap(Java Memory Map)可以輸出所有記憶體中物件的?具,甚?可以將 VM 中的 heap,以?進制輸
出成?本,使??式如下: jmap -heap:
[root ~]# jmap -heap pid #輸出當前行程JVM堆記憶體新?代、?年代、持久代、GC演算法等信
注意:pid 通過jps命令得知
3. jstack
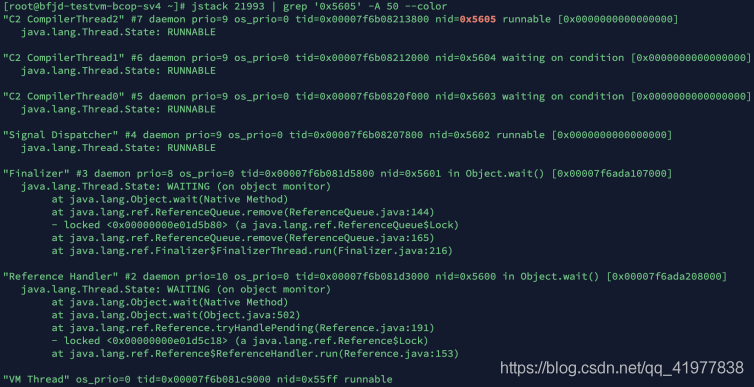
jstack?于列印某個 Java 執行緒的執行緒堆疊資訊
舉個栗?,某 Java 行程 CPU 占?率?,我們想要定位到其中 CPU 占?率最?的執行緒,如何定位?
3.1 利? top 命令可以查出占 CPU 最?的執行緒 pid
[root ~]# top -Hp pid
3.2 占?率最?的執行緒 ID 為 22021,將其轉換為16進制形式(因為 java native 執行緒以16進制形式輸
出)
[root ~]# printf '%x\n' 22021
3.3 利? jstack 列印出 Java 執行緒調?堆疊資訊
[root ~]# jstack 21993 | grep '0x5605' -A 50 --color
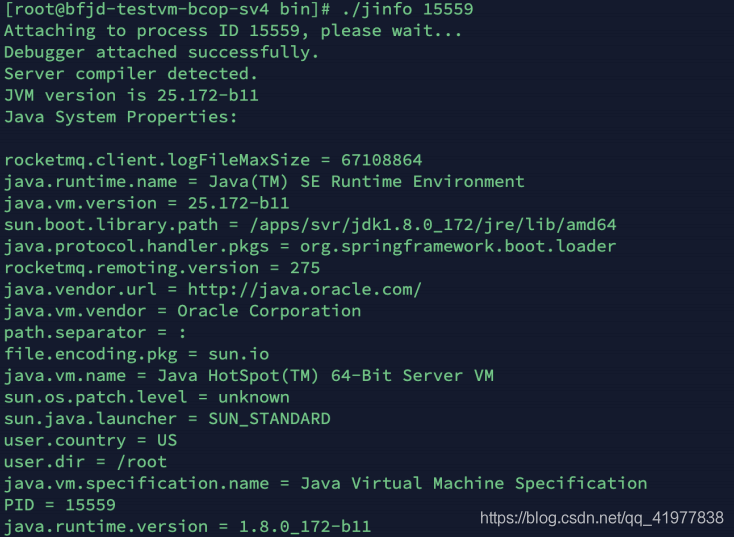
4. jinfo
jinfo可以?來查看正在運?的 java 應?程式的擴展引數,包括Java System屬性和JVM命令?引數;也
可以動態的修改正在運?的 JVM ?些引數,
[root ~]# jinfo pid
5. jstat
jstat命令可以查看堆記憶體各部分的使?量,以及加載類的數量,
[root ~]# jstat -gc pid

五、GC分析
- Gc日志分析
Java 虛擬機GC?志是?于定位問題重要的?志資訊,頻繁的GC將導致應?吞吐量下降、回應時間增
加,甚?導致服務不可?,
JVM的GC日志的主要引數包括如下幾個:
- -XX:+PrintGC 輸出GC日志
- -XX:+PrintGCDetails 輸出GC的詳細日志
- -XX:+PrintGCTimeStamps 輸出GC的時間戳(以基準時間的形式)
- -XX:+PrintGCDateStamps 輸出GC的時間戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
- -XX:+PrintHeapAtGC 在進行GC的前后列印出堆的資訊
- -Xloggc:…/logs/gc.log 日志檔案的輸出路徑
IDEA 配置
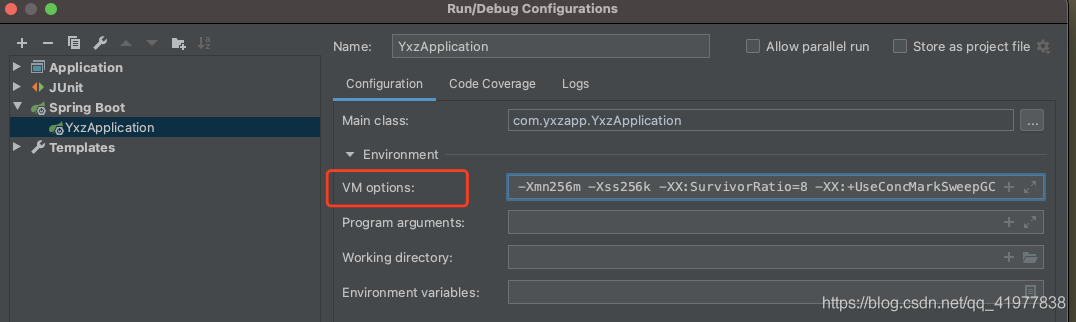
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/apps/logs/gc/gc.log -
XX:+UseConcMarkSweepGC
我們可以在 Java 應?的啟動引數中增加-XX:+PrintGCDetails 可以輸出 GC 的詳細?志,例外還可以增
加其他的輔助引數,如 -Xloggc 制定 GC ?志?件地址,如果你的應?還沒有開啟該引數,下次重啟時請
加?該引數,
以后列印出來的日志為:
0.756: [Full GC (System) 0.756: [CMS: 0K->1696K(204800K), 0.0347096 secs] 11488K->1696K(252608K),
[CMS Perm : 10328K->10320K(131072K)], 0.0347949 secs] [Times: user=0.06 sys=0.00, real=0.05 secs]
分析:
5.617(時間戳): [GC(Young GC) 5.617(時間戳): [ParNew(使用ParNew作為年輕代的垃圾回收期):
43296K(年輕代垃圾回收前的大小)->7006K(年輕代垃圾回收以后的大小)(47808K)(年輕代的總大小), 0.0136826 secs(回收時間)]
- CMS GC ?志分析
Concurrent Mark Sweep(CMS)是?年代垃圾收集器,從名字(Mark Sweep)可以看出,CMS 收集
器就是“標記-清除”演算法實作的,分為六個步驟:
- 初始標記(STW initial mark)
- 并發標記(Concurrent marking)
- 并發預清理(Concurrent precleaning)
- 重新標記(STW remark)
- 并發清理(Concurrent sweeping)
- 并發重置(Concurrent reset)
其中初始標記(STW initial mark) 和 重新標記(STW remark)需要“Stop the World”,
老年代的GC日志(CMS)
//第一階段 初始標記,CMS的第一個STW階段,這個階段會所有的GC Roots進行標記,
2020-10-20T17:04:45.424+0800: 10.756: [GC (CMS Initial Mark) [1 CMS-initial-mark: 68287K(68288K)] 69551K(99008K), 0.0019516 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
決議:CMS Initial Mark 說明該階段為初始標記階段,68287K(68288K)當前老年代空間的用量和總量,69551K(99008K)當前堆空間的用量和總量,0.0019516 secs初始化標記所耗費的時間,
?
?
//第二階段并發標記
2020-10-20T17:04:45.426+0800: 10.758: [CMS-concurrent-mark-start]
2020-10-20T17:04:45.519+0800: 10.850: [CMS-concurrent-mark: 0.092/0.092 secs] [Times: user=0.56 sys=0.01, real=0.09 secs]
決議:CMS-concurrent-mark: 0.092/0.092 secs] 并發標記所所耗費的時間
?
?
//第三階段 并發預清理階段,并發執行的階段,在本階段,會查找前一階段執行程序中,從新生代晉升或新分配或被更新的物件,通過并發地重新掃描這些物件,預清理階段可以減少重新標記階段的作業量,
2020-10-20T17:04:45.519+0800: 10.850: [CMS-concurrent-preclean-start]
2020-10-20T17:04:45.598+0800: 10.930: [CMS-concu決議rrent-preclean: 0.080/0.080 secs] [Times: user=0.46 sys=0.00, real=0.08 secs]
決議: [CMS-concurrent-preclean: 0.080/0.080 secs] 預清階段所使用功能的時間,
?
?
//第四階段 并發可中止的預清理階段,這個階段作業和上一個階段差不多,增加這一階段是為了讓我們可以控制這個階段的結束時機,比如掃描多長時間(默認5秒)或者Eden區使用占比達到期望比例(默認50%)就結束本階段,
2020-10-20T17:04:45.599+0800: 10.930: [CMS-concurrent-abortable-preclean-start]
2020-10-20T17:04:45.599+0800: 10.930: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
?
?
//第五階段 重新標記階段,需要STW,從GC Root開始重新掃描整堆,標記存活的物件,需要注意的是,雖然CMS只回收老年代的垃圾物件,但是這個階段依然需要掃描新生代,因為很多GC Root都在新生代,
2020-10-20T17:04:45.608+0800: 10.939: [GC (CMS Final Remark) [YG occupancy: 25310 K (30720 K)]2020-10-20T17:04:45.608+0800: 10.939: [Rescan (parallel) , 0.0117481 secs]2020-10-20T17:04:45.620+0800: 10.951: [weak refs processing, 0.0000354 secs]2020-10-20T17:04:45.620+0800: 10.951: [class unloading, 0.0268352 secs]2020-10-20T17:04:45.647+0800: 10.978: [scrub symbol table, 0.0053781 secs]2020-10-20T17:04:45.652+0800: 10.983: [scrub string table, 0.0006005 secs][1 CMS-remark: 68287K(68288K)] 93598K(99008K), 0.0447563 secs] [Times: user=0.18 sys=0.00, real=0.04 secs]
決議:
[YG occupancy: 25310 K (30720 K)] =》 新生代空間占用大小,新生代總大小,
[Rescan (parallel) , 0.0117481 secs] =》 暫停用戶執行緒的情況下完成對所有存活物件的標記,此階段所花費的時間,
[weak refs processing, 0.0000354 secs] =》第一步 標記處理弱參考;
[class unloading, 0.0033120 secs] =》 第二步,標記那些已卸載未使用的類;
[scrub symbol table, 0.0053781 secs][scrub string table, 0.0004780 secs =》 最后標記未被參考的常量池物件,
[1 CMS-remark: 68287K(68288K)] 93598K(99008K), 0.0447563 secs] =》 重新標記完成后 老年代使用量與總量,堆空間使用量與總量,
[Times: user=0.18 sys=0.00, real=0.04 secs] =》 各個維度的時間消耗,
?
?
//第六階段 并發清理階段, 對前面標記的所有可回收物件進行回收
2020-10-20T17:04:45.653+0800: 10.984: [CMS-concurrent-sweep-start]
2020-10-20T17:04:45.689+0800: 11.020: [CMS-concurrent-sweep: 0.036/0.036 secs] [Times: user=0.20 sys=0.01, real=0.04 secs]
2020-10-20T17:04:45.689+0800: 11.020: [CMS-concurrent-reset-start]
2020-10-20T17:04:45.689+0800: 11.021: [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
決議:
[CMS-concurrent-sweep: 0.036/0.036 secs] 開并發清理所耗費的時間,
[CMS-concurrent-reset: 0.000/0.000 secs] 重置資料和結構資訊,
例外情況有:
伴隨 prommotion failed,然后 Full GC:
[prommotion failed:存活區記憶體不?,物件進??年代,?此時?年代也仍然沒有記憶體容納物件,將
導致?次Full GC]
伴隨 concurrent mode failed,然后 Full GC:
[concurrent mode failed:CMS回收速度慢,CMS完成前,?年代已被占滿,將導致?次Full GC]
頻繁 CMS GC: [記憶體吃緊,?年代?時間處于較滿的狀態]
個人博客地址:http://blog.yanxiaolong.cn/
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/257425.html
標籤:其他