文章目錄
- 初識ElasticSearch
- 什么是ElasticSearch
- ElasticSearch特點
- ElasticSearch用途
- ElasticSearch底層實作
- ElasticSearch和Solr的區別
- Solr是什么
- 不同場景時兩個的對比
- 總結
- ElasticSearch體系結構
- 倒排索引
- 什么是Term Dictionary
- 什么是Term Index
- 為什么 Elasticsearch/Lucene 檢索可以比 MySQL快
- 什么是ELK
- 安裝ElasticSearch
- 安裝ik分詞器
- 測驗ik分詞器
- IK分詞器的兩種分詞模式
- ik分詞器添加自定義詞庫
- 安裝ElasticSearch-head
- 安裝Kibana
- REST風格說明
- 什么是REST風格
- 基本REST命令說明
- PUT命令
- 創建型別
- 插入資料
- 更新資料
- POST命令
- 更新資料(推薦使用)
- DELETE命令
- GET命令
- 查詢資料(重點)
- 精確查詢
- 查詢字串搜索
- 查詢所有結果
- 條件查詢
- 布爾查詢
- 按排序查詢
- 分頁查詢
- 指定查詢結果的欄位
- 高亮查詢
- 拓展
初識ElasticSearch
什么是ElasticSearch
Elasticsearch 是一個分布式的開源搜索和分析引擎,適用于所有型別的資料,包括文本、數字、地理空間、結構化和非結構化資料,它可以幫助你用前所未有的速度去處理大規模資料,ElasticSearch是一個基于Lucene的搜索服務器,它提供了一個分布式多用戶能力的全文搜索引擎,基于RESTful web介面,Elasticsearch是用Java開發的,并作為Apache許可條款下的開放原始碼發布,是當前流行的企業級搜索引擎,設計用于云計算中,能夠達到實時搜索,穩定,可靠,快速,安裝使用方便,
ElasticSearch特點
- 可以作為一個大型分布式集群(數百臺服務器)技術,處理PB級資料,服務大公司;也可以運行在單機上,服務小公司
- 對用戶而言,是開箱即用的,非常簡單,作為中小型的應用,直接3分鐘部署一下ES
- Elasticsearch作為傳統資料庫的一個補充,比如全文檢索,同義詞處理,相關度排名,復雜資料分析,海量資料的近實時處理
- Elasticsearch不是什么新技術,主要是將全文檢索、資料分析以及分布式技術,合并在了一起,才形成了獨一無二的ES;lucene(全文檢索),商用的資料分析軟體(也是有的),分布式資料庫(mycat)
ElasticSearch用途
Elasticsearch 在速度和可擴展性方面都表現出色,而且還能夠索引多種型別的內容,這意味著其可用于多種用例:
- 應用程式搜索
- 網站搜索
- 企業搜索
- 日志處理和分析
- 基礎設施指標和容器監測
- 應用程式性能監測
- 地理空間資料分析和可視化
- 安全分析
- 業務分析
維基百科使用Elasticsearch提供全文搜索并高亮關鍵字,以及輸入實時搜索(search-asyou-type)和搜索糾錯(did-you-mean)等搜索建議功能,
英國衛報使用Elasticsearch結合用戶日志和社交網路資料提供給他們的編輯以實時的反饋,以便及時了解公眾對新發表的文章的回應,
Github使用Elasticsearch檢索1300億行的代碼,
ElasticSearch底層實作
ElasticSearch是基于對 Lucene 進行封裝,將搜索引擎的操作封裝成了RESTful API,通過http請求就可以呼叫,目的是為了隱藏Lucene的復雜性,從而讓全文搜索變得簡單,
ElasticSearch和Solr的區別
Solr是什么
Solr 是Apache下的一個頂級開源專案,采用Java開發,它是基于Lucene的全文搜索服務器,Solr提供了比Lucene更為豐富的查詢語言,同時實作了可配置、可擴展,并對索引、搜索性能進行了優化,
Solr可以獨立運行,運行在Jetty、Tomcat等這些Servlet容器中,Solr 索引的實作方法很簡單,用 POST 方法向 Solr 服務器發送一個描述 Field 及其內容的 XML 檔案,Solr根據xml檔案添加、洗掉、更新索引 ,Solr 搜索只需要發送 HTTP GET 請求,然后對 Solr 回傳Xml、json等格式的查詢結果進行決議,組織頁面布局,Solr不提供構建UI的功能,Solr提供了一個管理界面,通過管理界面可以查詢Solr的配置和運行情況,
Solr是基于lucene開發企業級搜索服務器,實際上就是封裝了lucene,
Solr是一個獨立的企業級搜索應用服務器,它對外提供類似于Web-service的API介面,用戶可以通過http請求,向搜索引擎服務器提交一定格式的檔案,生成索引;也可以通過提出查找請求,并得到回傳結果,
不同場景時兩個的對比
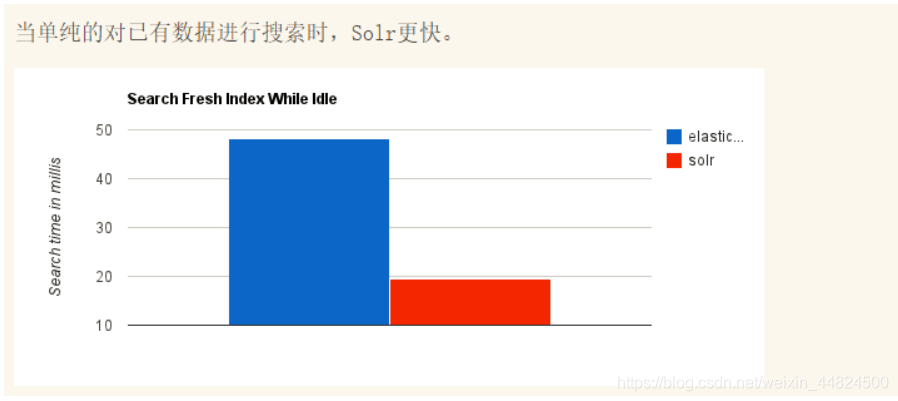
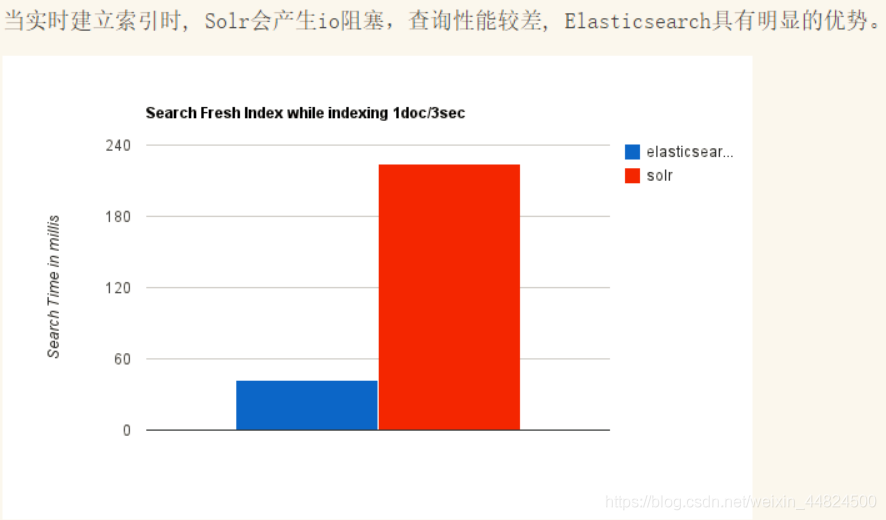
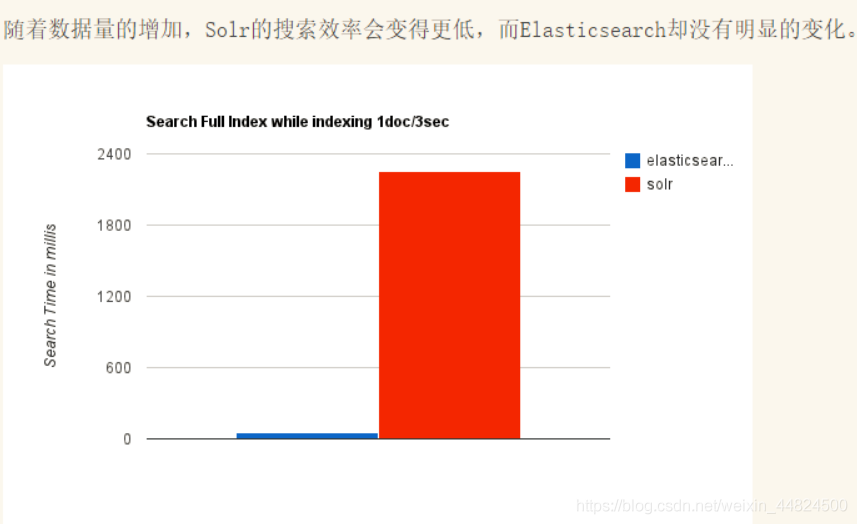
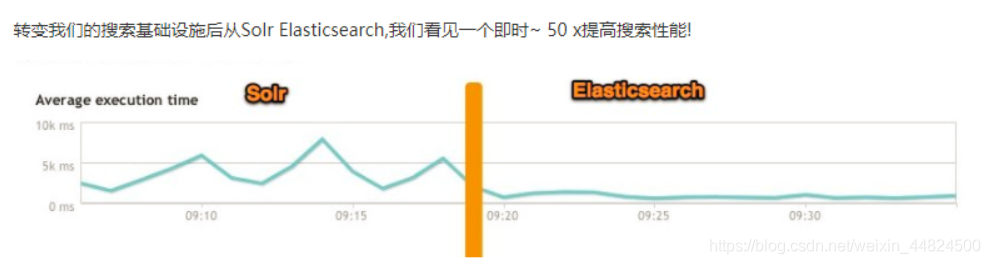
總結
(1)es基本是開箱即用,非常簡單,Solr安裝略微復雜一點,
(2)Solr 利用 Zookeeper 進行分布式管理,而 Elasticsearch 自身帶有分布式協調管理功能,
(3)Solr 支持更多格式的資料,比如JSON、XML、CSV,而 Elasticsearch 僅支持json檔案格式,
(4)Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高級功能多有第三方插件提供,例如圖形化界面需要kibana支撐
(5)Solr 查詢快,但更新索引時慢(即插入洗掉慢),用于電商等查詢多的應用;ES建立索引快(即查詢慢),即實時性查詢快,用于FaceBook、百度等搜索,Solr 是傳統搜索應用的有力解決方案,但 Elasticsearch 更適用于新興的實時搜索應用,
(6)Solr比較成熟,有一個更大,更成熟的用戶、開發和貢獻者社區,而 Elasticsearch相對開發維護者較少,更新太快,學習使用成本較高,
ElasticSearch體系結構
初學者建議將 ElasticSearch當為一個資料庫進行學習,
下圖是Elasticsearch與關系型資料庫邏輯結構概念的對比:
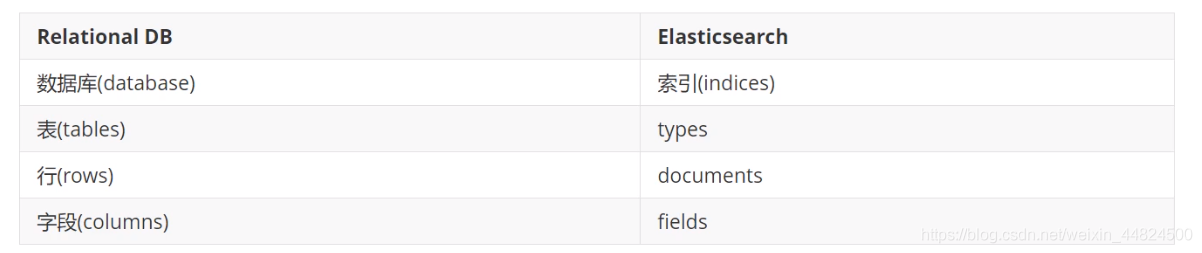
倒排索引
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引,通俗地來講,正向索引是通過key找value,反向索引則是通過value找key,
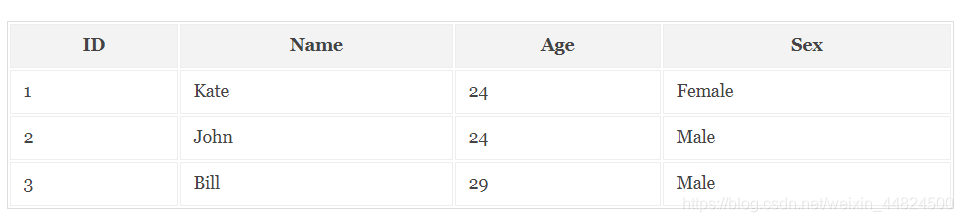
正向索引:
MYSQL資料庫所用的索引就是正向索引,適合根據檔案中的ID來查詢對應的內容,但是在查詢一個keyword在哪些檔案里包含的時候需對所有的檔案進行掃描以確保沒有遺漏,這樣就使得檢索時間大大延長,檢索效率低下,
正向索引構建的結果如下圖:
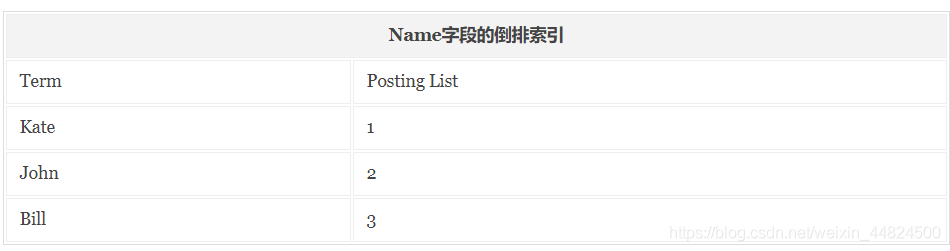
倒排索引:
與正序索引相反,在搜索引擎中每個檔案都對應一個檔案ID,檔案內容被表示為一系列關鍵詞的集合,記錄每個關鍵字在檔案中出現的頻率和出現的位置,
按照上面的檔案內容構建的倒排索引結果會如下圖:
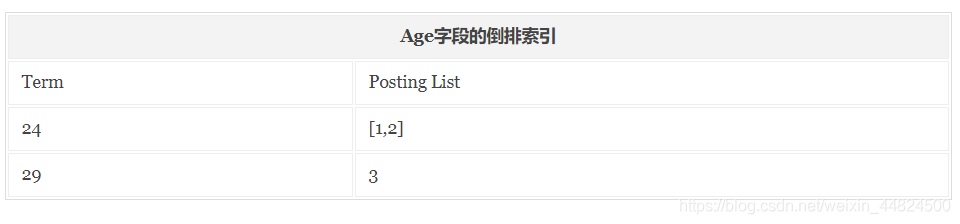

如果我們要通過倒排索引查找‘Male’這個關鍵詞在哪些檔案中出現過,首先我們通過倒排索引可以查詢到該關鍵詞出現的檔案位置是在2和3中;然后再通過正排索引查詢到檔案2和3的內容并回傳結果,
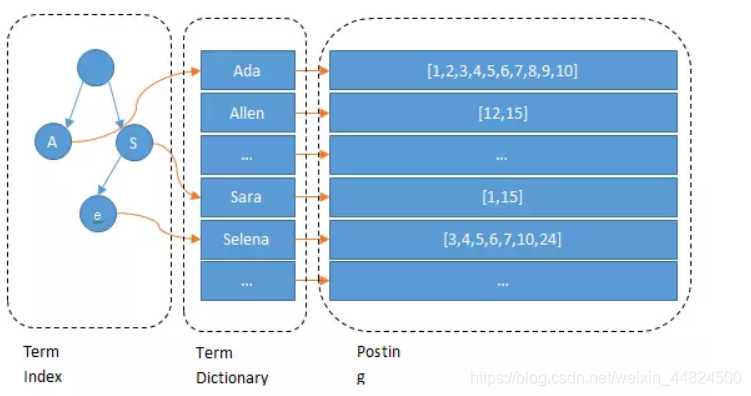
什么是Term Dictionary
Elasticsearch為了能快速找到某個Term,將所有的Term排個序,二分法查找Term,這就是Term Dictionary,
什么是Term Index
如果Term太多,Term Dictionary也會很大,全部放在記憶體不現實,只能部分存盤到磁盤上,這是又出現了新的問題,磁盤尋道次數太多也會嚴重影響查找效率,為了減少磁盤尋道次數來提高查詢性能,于是有了Term Index,就像字典里的索引頁一樣,A開頭的有哪些Term,分別在哪頁,可以理解Term Index是一顆樹:
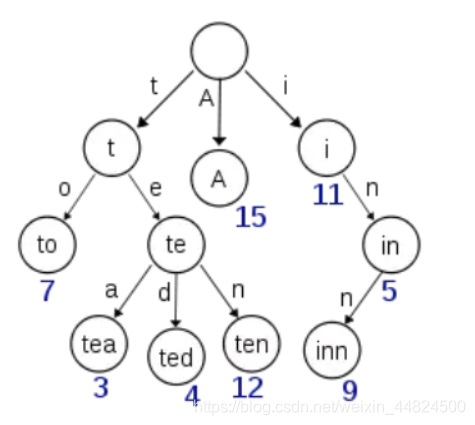
Term Index不需要存下所有的Term,而僅僅是它們的一些前綴與Term Dictionary的Block之間的映射關系,再結合相關的壓縮技術,可以使Term Index快取到記憶體中,從Term Index查到對應的Term Dictionary的Block位置之后,再去磁盤上找Term,大大減少了磁盤隨機讀的次數,
為什么 Elasticsearch/Lucene 檢索可以比 MySQL快
MySQL 只有 Term Dictionary 這一層,是以 B+Tree 排序的方式存盤在磁盤上的,檢索一個 Term 需要若干次的 Random Access 的磁盤操作,
Lucene 在 Term Dictionary 的基礎上添加了 Term Index 來加速檢索,Term Index 以樹的形式快取在記憶體中,從 Term Index 查到對應的 Term Dictionary 的 Block 位置之后,再去磁盤上找 Term,大大減少了磁盤的 Random Access 次數,
值得一提的兩點是:
Term Index 在記憶體中是以 FST(finite state transducers)的形式保存的,其特點是非常節省記憶體,
Term Dictionary 在磁盤上是以分 Block 的方式保存的,一個 Block 內部利用公共前綴壓縮,比如都是 Ab 開頭的單詞就可以把 Ab 省去,這樣 Term Dictionary 可以比 B-Tree 更節約磁盤空間,
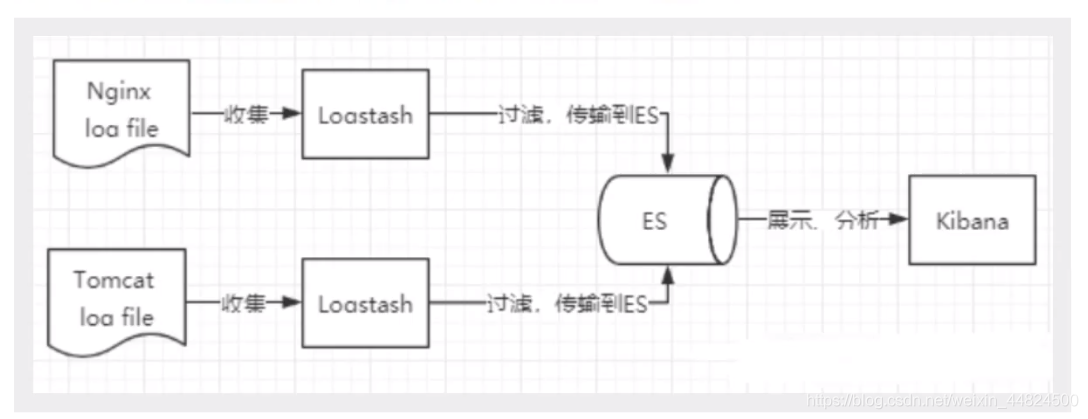
什么是ELK
ELK 是elastic公司提供的一套完整的日志收集以及展示的解決方案,分別表示:ElasticSearch , Logstash, Kibana,
ElasticSearch是個開源分布式搜索引擎,提供搜集、分析、存盤資料三大功能,它的特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格介面,多資料源,自動搜索負載等,
Logstash 主要是用來日志的搜集、分析、過濾日志的工具,支持大量的資料獲取方式,一般作業方式為c/s架構,client端安裝在需要收集日志的主機上,server端負責將收到的各節點日志進行過濾、修改等操作在一并發往elasticsearch上去,
Kibana 也是一個開源和免費的工具,Kibana可以為 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以幫助匯總、分析和搜索重要資料日志,
安裝ElasticSearch
由于官網下載較慢,下方鏈接為華為云的鏡像,
ElasticSearch:
https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
選好自己的版本,下載壓縮包,
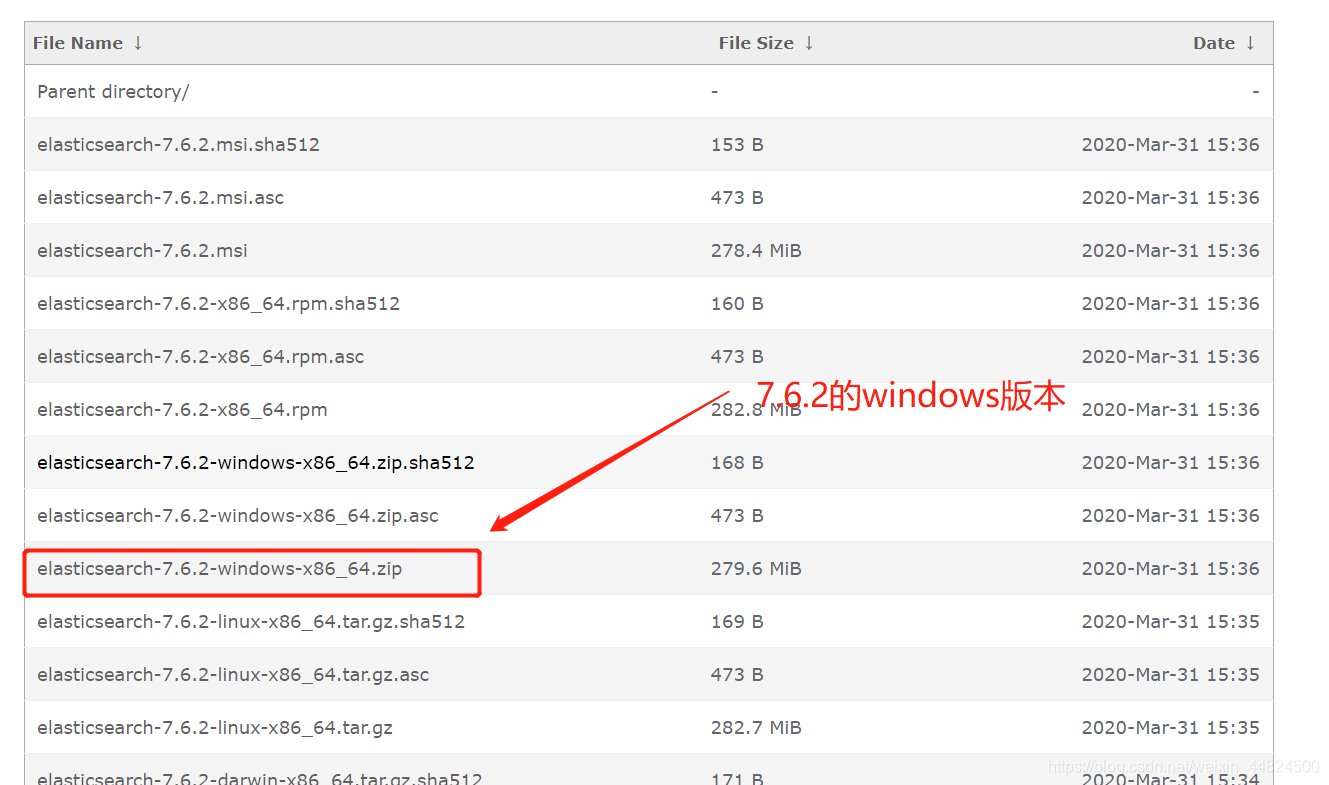
我選擇的是7.6.2的Windows版本,需要清晰知道自己下載的版本,后面下載kibana等都必須版本一致,
下載完成后解壓,
重點關注一下config檔案夾中的 jvm.options
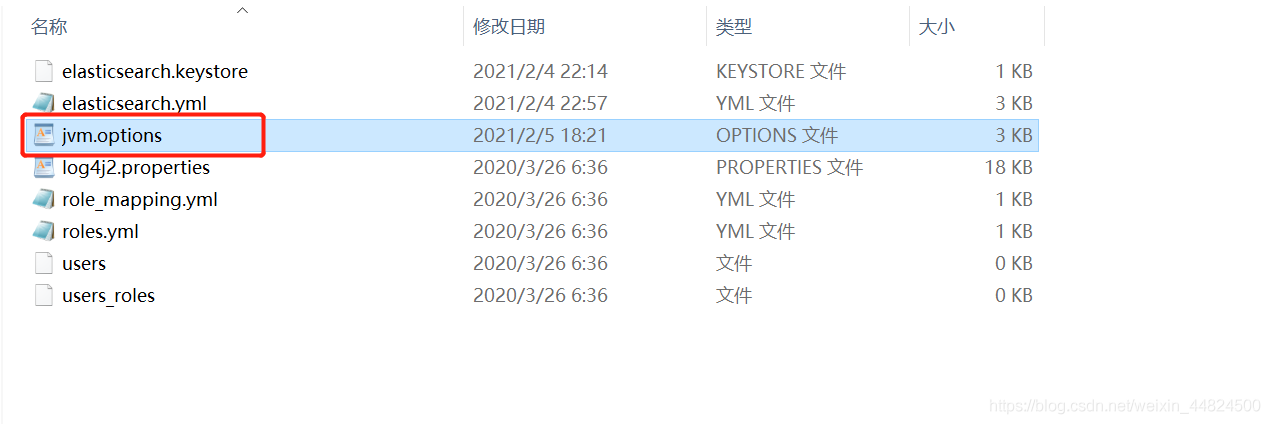
很多同學一啟動馬上閃退,就是因為這里的記憶體設定過大,按照自己電腦配置進行設定,1g閃退就設定512M,以此類推,

接著我們打開bin目錄中的elasticsearch.bat

出現下面圖片,在瀏覽器輸入紅框地址,
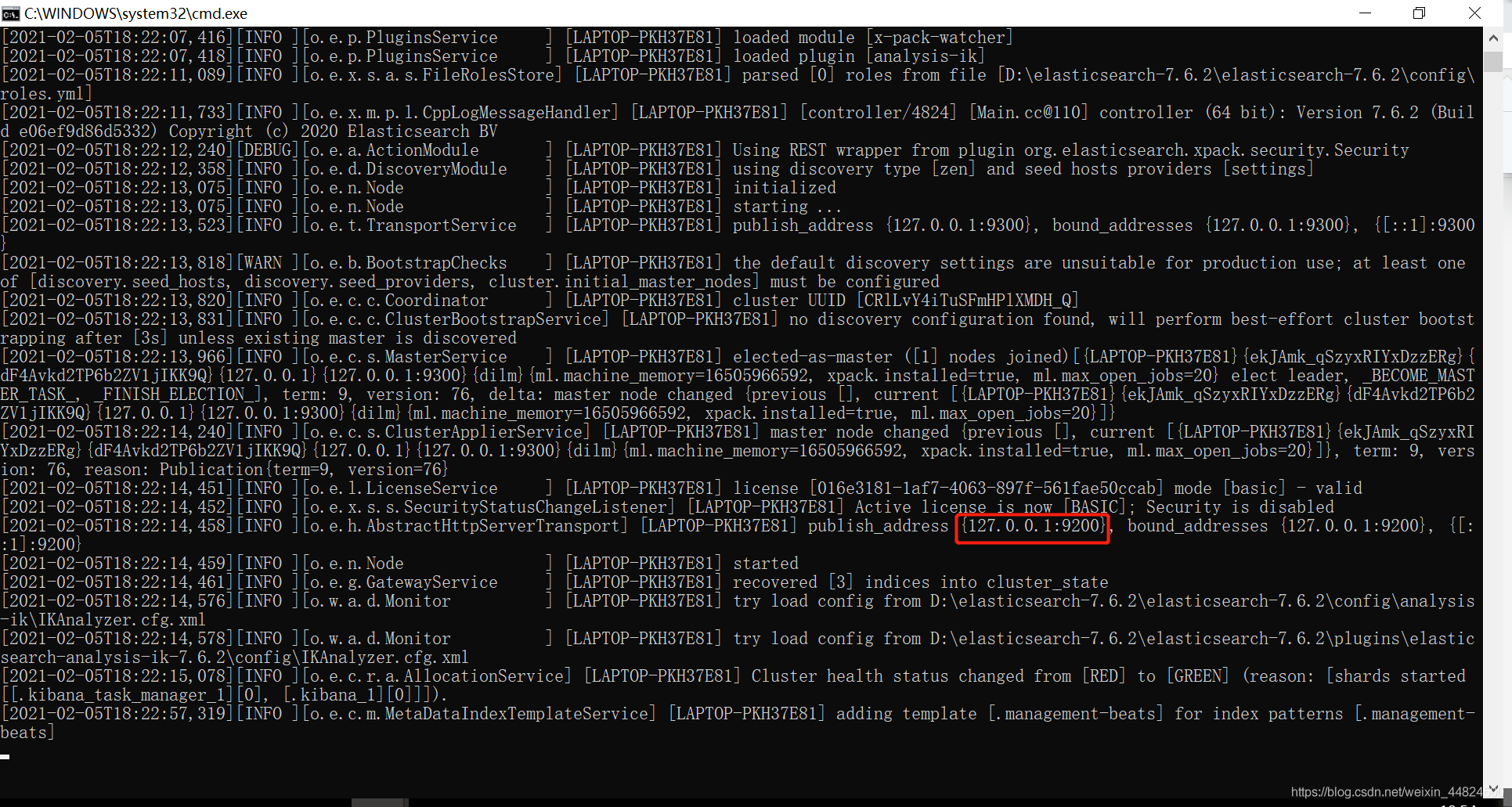
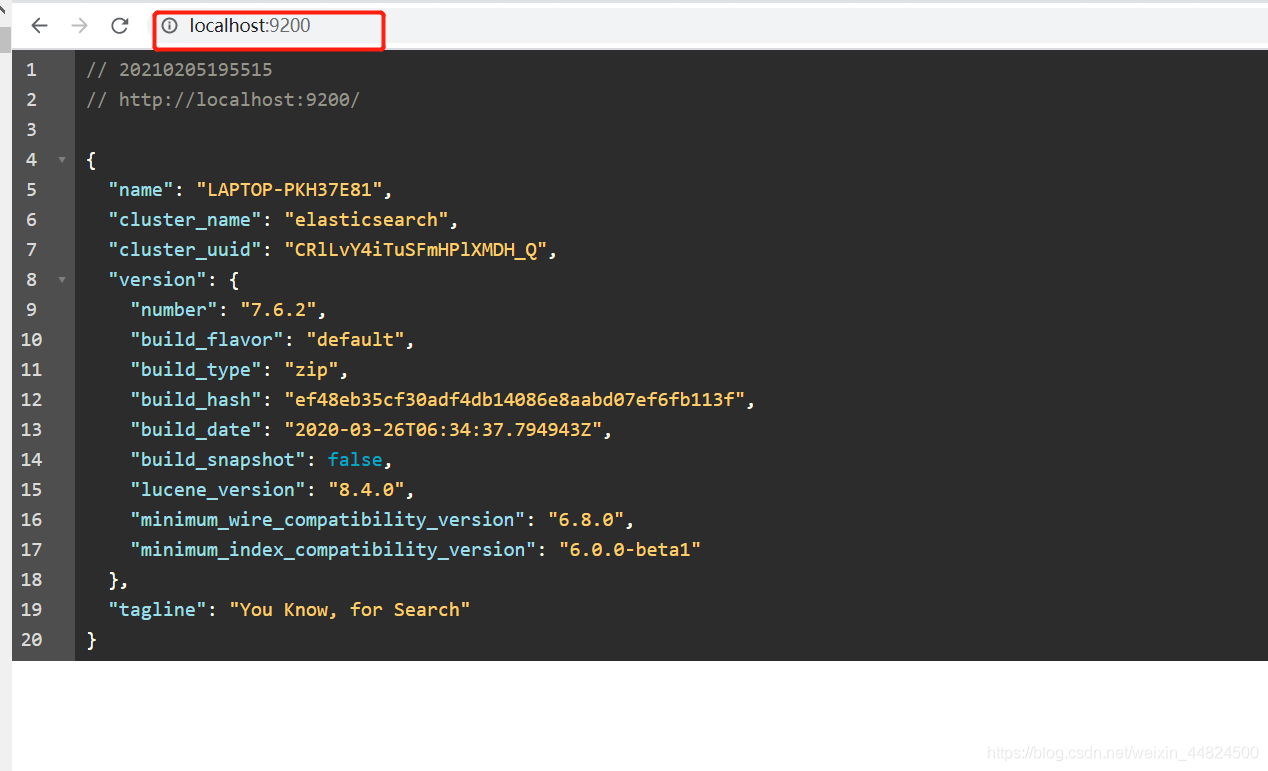
出現下方 json格式則安裝成功
安裝ik分詞器
打開下方網址,找到和自己elasticsearch一樣版本的下載,
https://github.com/medcl/elasticsearch-analysis-ik/releases
下載完成后,將其解壓到elasticsearch檔案夾中的plugins,由于ik分詞器是elasticsearch的一個插件,elasticsearch的插件都是放在plugins中的,
重啟elasticsearch,觀察其啟動界面的命令列是否出現下圖
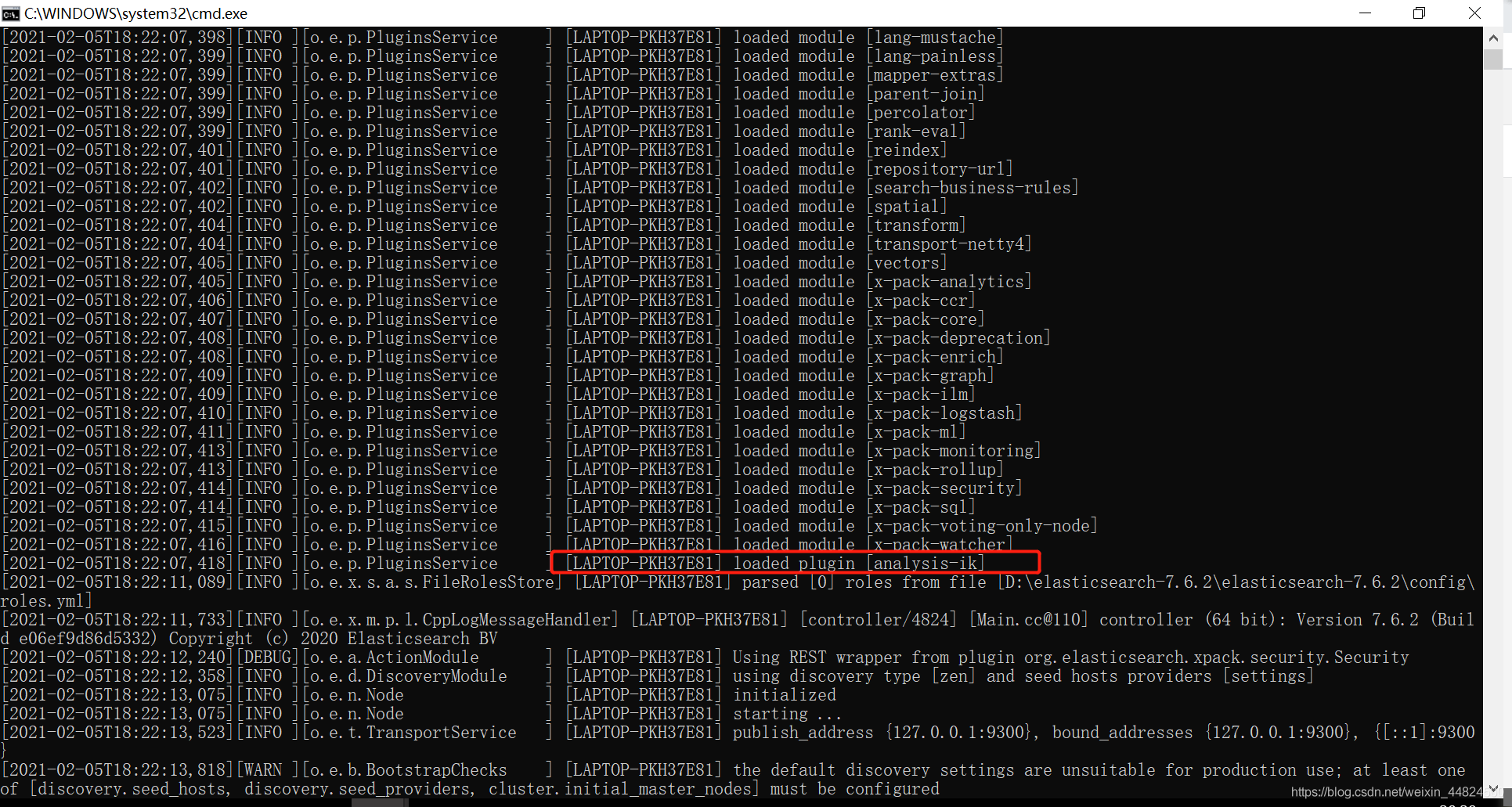
出現了即安裝ik插件成功,
測驗ik分詞器
安裝成功后我們打開Kibana可以嘗試一下ik分詞器如何使用,
IK分詞器的兩種分詞模式
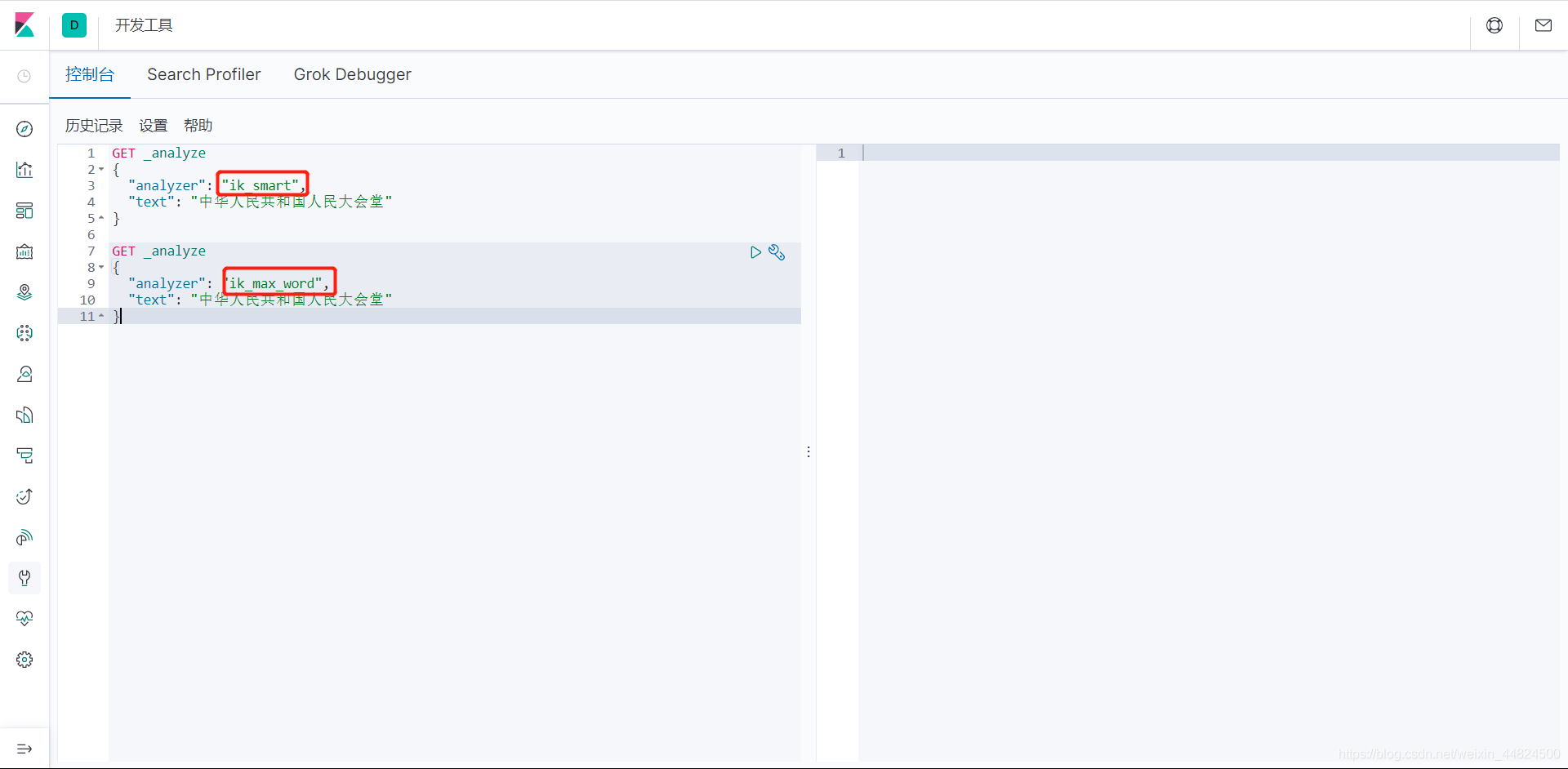
IK分詞器有兩種分詞模式:ik_max_word和ik_smart模式,
-
ik_max_word
會將文本做最細粒度的拆分,比如會將“中華人民共和國人民大會堂”拆分為“中華人民共和國、中華人民、中華、華人、人民共和國、人民、共和國、大會堂、大會、會堂等詞語, -
ik_smart
會做最粗粒度的拆分,比如會將“中華人民共和國人民大會堂”拆分為中華人民共和國、人民大會堂,
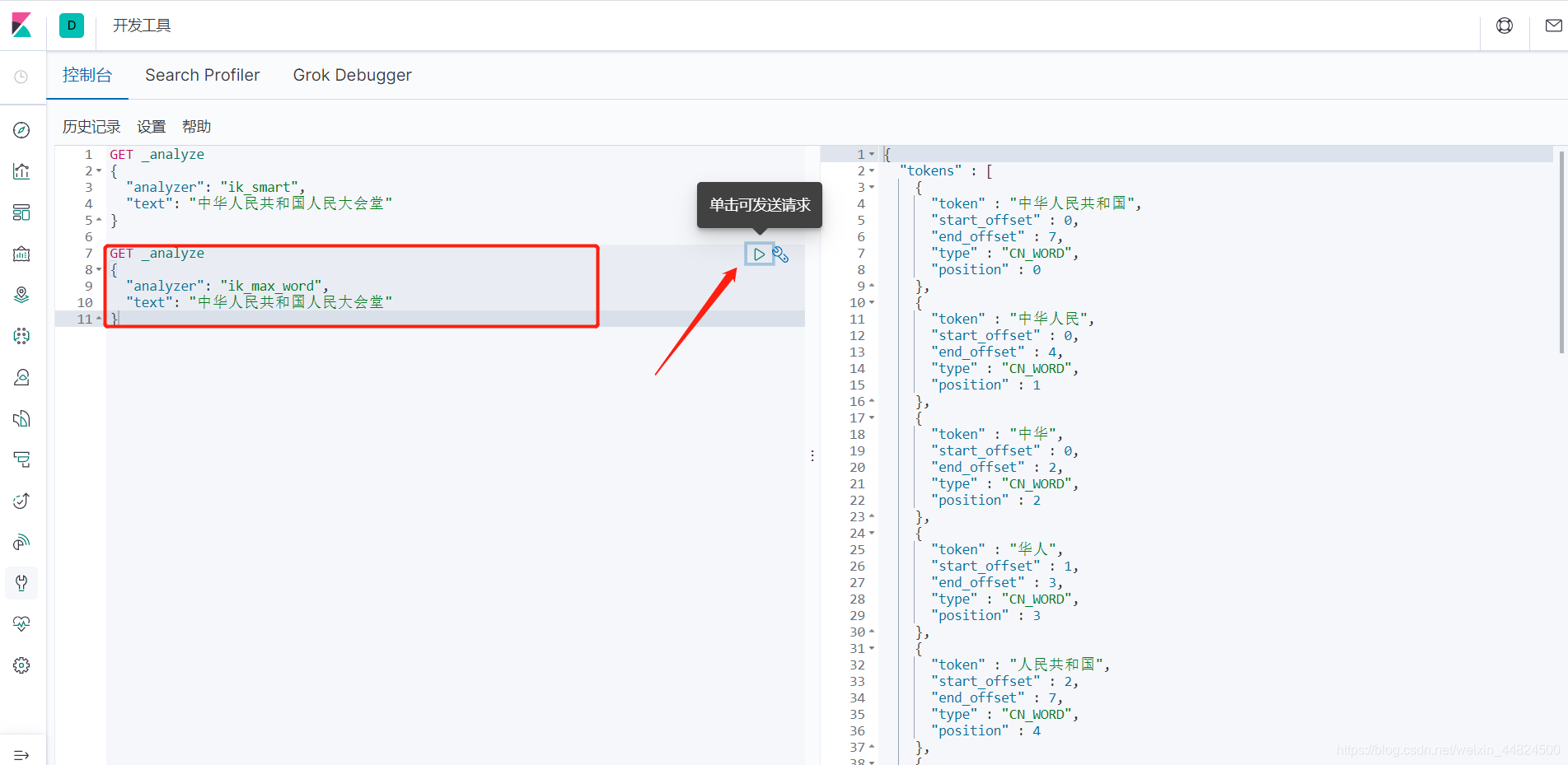
點擊小三角形對該陰影區域的json的text進行分詞
ik_smart
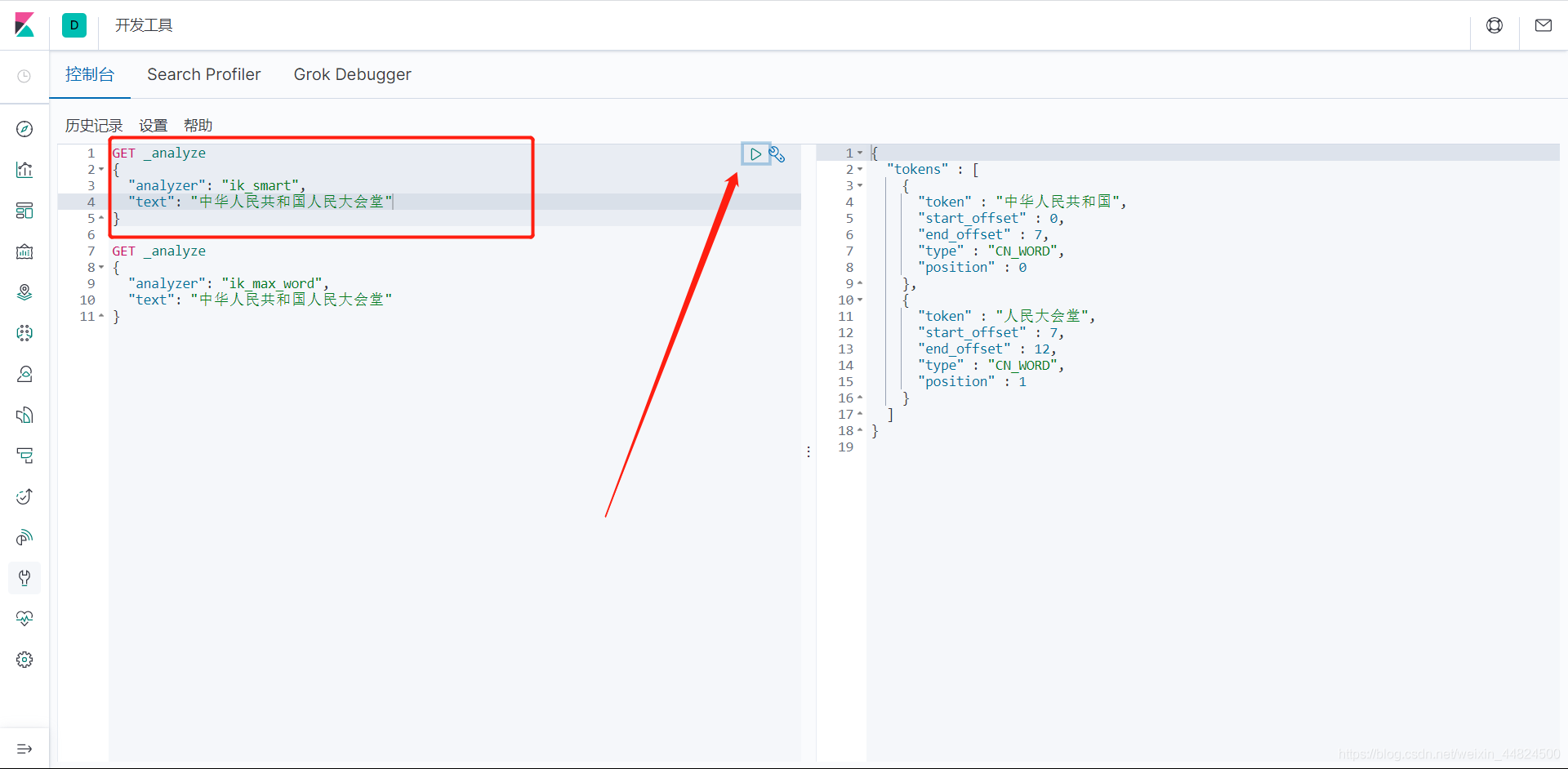
ik_max_word
{
"tokens" : [
{
"token" : "中華人民共和國",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中華人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中華",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "華人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和國",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和國",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "國人",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 8
},
{
"token" : "人民大會堂",
"start_offset" : 7,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 9
},
{
"token" : "人民大會",
"start_offset" : 7,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 10
},
{
"token" : "人民",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 11
},
{
"token" : "大會堂",
"start_offset" : 9,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 12
},
{
"token" : "大會",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 13
},
{
"token" : "會堂",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 14
}
]
}
ik分詞器添加自定義詞庫
當有一些自造詞需要ik分詞器進行分詞時,可以打開在ik分詞器的解壓檔案夾中的config
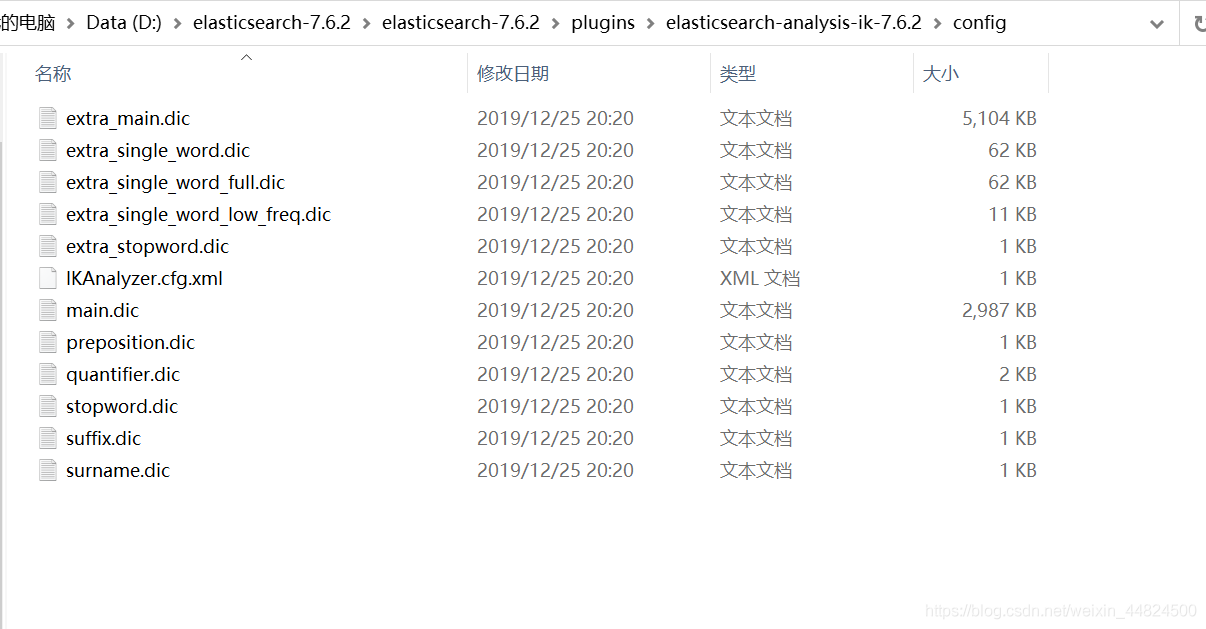
新建一個檔案將自造詞放進去即可,記得要把檔案后綴改為dic,編碼為UTF-8

保存后,打開IKAnalyzer.cfg.xml
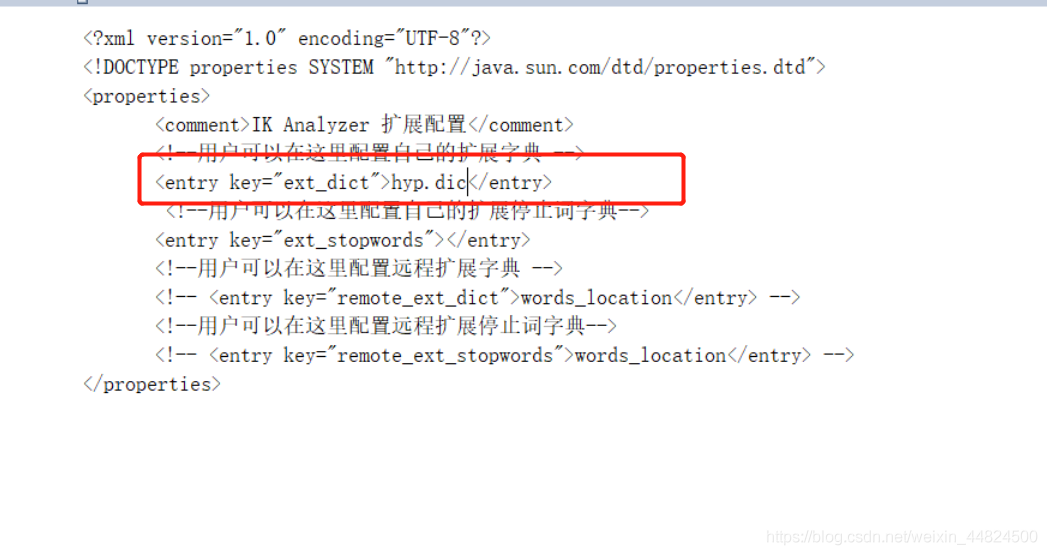
將自己詞典的檔案名填寫進去,保存,添加成功,重啟es,
安裝ElasticSearch-head
elasticsearch-head將是一款專門針對于elasticsearch的客戶端工具,包括資料可視化,增刪改查工具,es陳述句的可視化等等,
下載地址:
https://github.com/mobz/elasticsearch-head
和elasticsearch安裝一樣,將解壓包解壓,進入elasticsearch-head的檔案夾
進入解壓路徑的命令列
執行 npm install
執行 npm run start
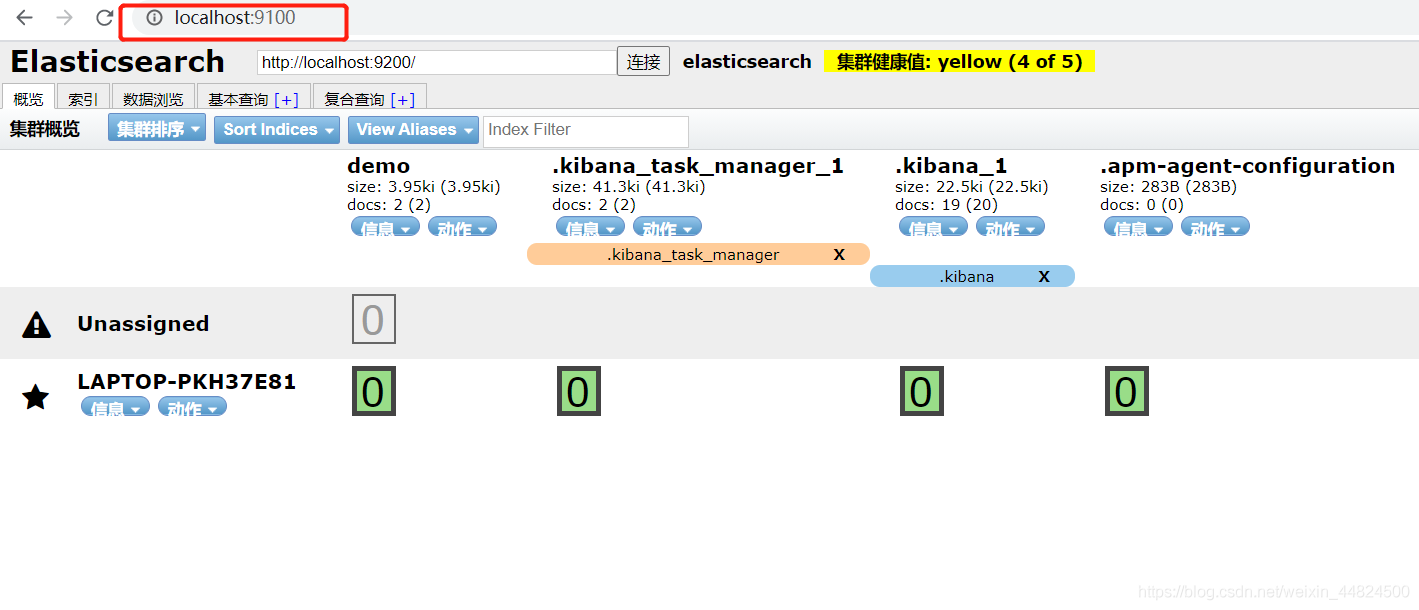
在瀏覽器訪問http://localhost:9100,可看到如下界面,表示啟動成功:
安裝Kibana
依舊是華為云的鏡像
Kibana
https://mirrors.huaweicloud.com/kibana/?C=N&O=D
選擇和你的ElasticSearch一樣的版本下載,和es一樣解壓即可用,
由于Kibana默認是英文,我們需要進入config檔案夾中的kibana.yml
在末尾加入i18n.locale: "zh-CN",更改保存,讓國際化變成中文,
接著進入bin目錄打開kibana.bat,出現下方界面,
在瀏覽器打開http://localhost:5601,進入下方頁面即安裝成功,

REST風格說明
什么是REST風格
REST是一種軟體架構風格,或者說是一種規范,其強調HTTP應當以資源為中心,并且規范了URI的風格;規范了HTTP請求動作(GET/PUT/POST/DELETE/HEAD/OPTIONS)的使用,具有對應的語意,
基本REST命令說明
PUT命令
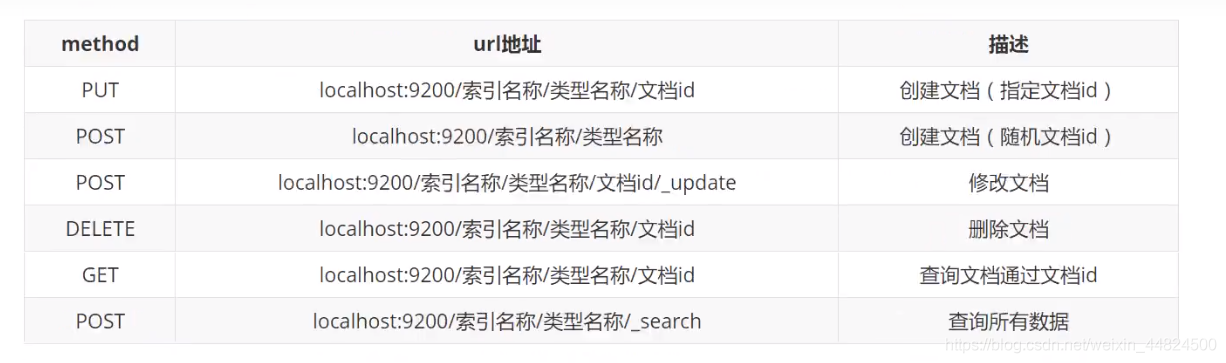
創建一個demo索引的 type型別下保存1號資料為 “name”: “小黃”, “age”:21
PUT demo/type/1
{
"name": "小黃",
"age":21
}
創建成功
對照著和關系型資料庫的聯系理解
創建型別
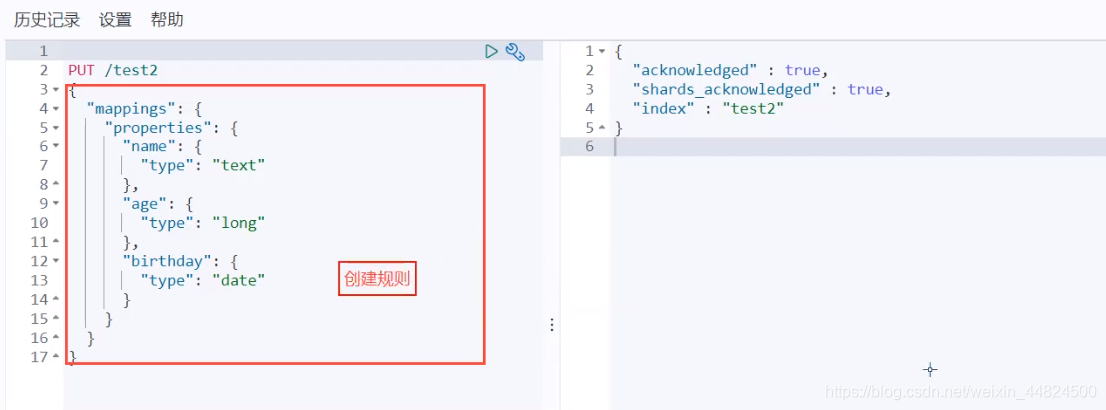
不填寫時,默認為_.doc型別,在未來8.多的版本具體型別可能會被拋棄,
指定某個欄位使用指定型別,常見型別有下圖:

我們在下方創建了一個test2的索引里面的欄位和對應的型別
插入資料
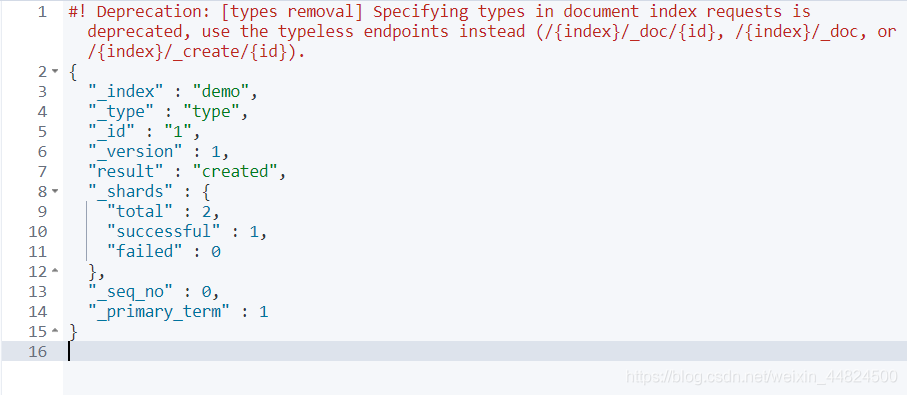
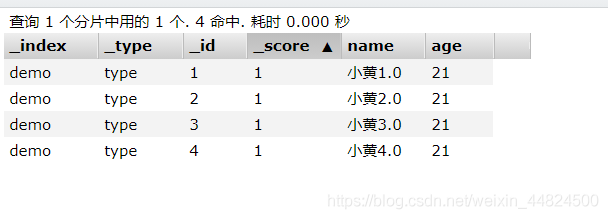
這里在demo索引下的插入了4個記錄
PUT demo/type/1
{
"name": "小黃1.0",
"age":21
}
PUT demo/type/2
{
"name": "小黃2.0",
"age":21
}
PUT demo/type/3
{
"name": "小黃3.0",
"age":21
}
PUT demo/type/4
{
"name": "小黃4.0",
"age":21
}
更新資料
假設我需要更新name為小黃2.0,直接在對應的欄位更改成對應資料即可,需要將不修改欄位的資料也寫上去,否則將會被空白覆寫,
PUT demo/type/1 # 更新id為1的資料
{
"name": "小黃2.0",
"age":21 #即使21不用修改還是需要寫
}
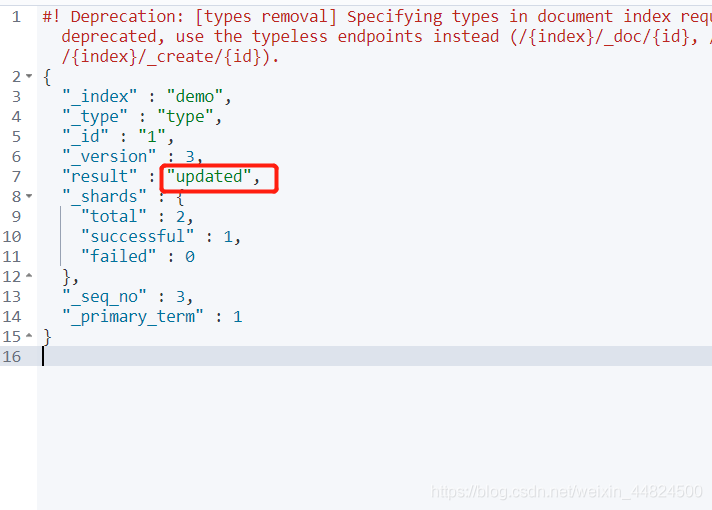
修改后 _version增加
POST命令
POST可以不帶ID發送,ES會自動生成一個ID,如果再次請求也會再次新增一個ID
POST demo/type
{
"name": "小黃",
"age":21
}
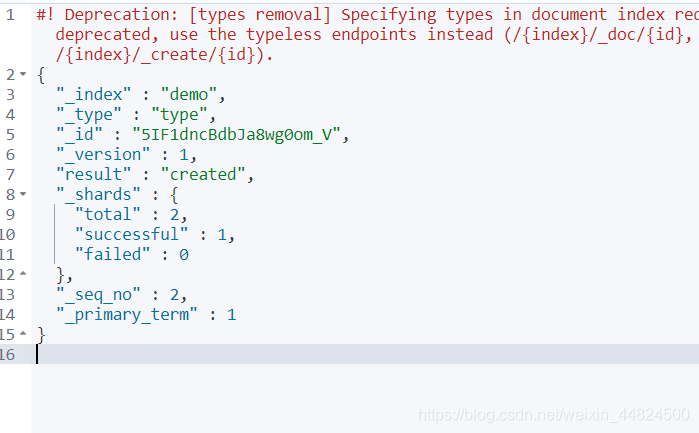
可以看到自動生成一個ID為 5IF1dncBdbJa8wg0om_V
更新資料(推薦使用)
POST一樣可以更新資料,只需要在最后加上需要修改的ID號和/_update,加上 “doc”:{}包圍需要修改的資料欄位即可,不需要將不修改的資料寫上去,
POST demo/type/1/_update
{
"doc":{
"name": "小黃3.0"
}
}

DELETE命令
DELETE demo #洗掉demo索引
DELETE demo/type/1 #洗掉demo索引下的1號檔案
根據請求判斷洗掉索引還是檔案記錄
GET命令
查詢資料(重點)
GET demo #獲取索引資訊

GET demo/type/1 #獲取demo索引的 type型別下保存1號資料
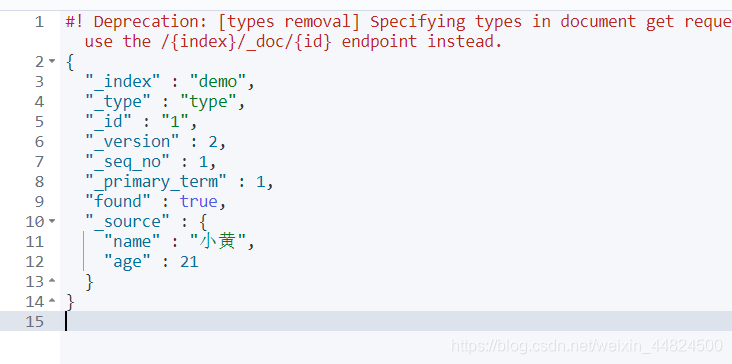
_index:表示在哪個索引下
_type:型別
_id:添加時的id
_version:版本號
_seq_no:并發控制欄位,序列號,每次更新+1 (樂觀鎖操作使用)
_primary_term:分片,作用同上,重啟會變化
_source:真正的內容
精確查詢
term查詢是直接通過倒排索引指定的詞條進行精確查找的
GET demo/type/_search
{
"query": {
"term": {
"age": "21"
}
}
}
而match會使用分詞器決議(先分析檔案,在通過分析的檔案進行查詢)
keyword型別資料不能被分詞器決議
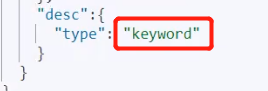
而其他型別可以被分詞器決議
查詢字串搜索
將具有"黃"的資料全部搜索出來
GET demo/type/_search?q=name:黃
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 0.10536051,
"hits" : [
{
"_index" : "demo",
"_type" : "type",
"_id" : "1",
"_score" : 0.10536051,
"_source" : {
"name" : "小黃1.0",
"age" : 21
}
},
{
"_index" : "demo",
"_type" : "type",
"_id" : "2",
"_score" : 0.10536051,
"_source" : {
"name" : "小黃2.0",
"age" : 21
}
},
{
"_index" : "demo",
"_type" : "type",
"_id" : "3",
"_score" : 0.10536051,
"_source" : {
"name" : "小黃3.0",
"age" : 21
}
},
{
"_index" : "demo",
"_type" : "type",
"_id" : "4",
"_score" : 0.10536051,
"_source" : {
"name" : "小黃4.0",
"age" : 21
}
}
]
}
}
hits:顯示索引和檔案資訊,查詢總結果數,權重, 具體檔案,資料中的東西都可以遍歷出來
_score:表示權重,越高表示該資料和搜索欄位越匹配,由于我上面的資料格式一樣,都只具有一個"黃"所以權重一樣,都是0.10536051,
查詢所有結果
GET demo/type/_search
{
"query":{"match_all":{}}
}
條件查詢
GET demo/type/_search
{
"query":{
"match":{
"name":"黃"
}
}
}
布爾查詢
使用 "bool":{} 宣告使用布爾查詢
must等同于MySQL中的 and
GET demo/type/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "huang"
}
},
{
"match": {
"age": 21
}
}
]
}
}
}
should等同于MySQL中的 or
filter條件過濾查詢,過濾條件的范圍用range表示gt表示大于、lt表示小于、gte表示大于等于、lte表示小于等于)
GET demo/type/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "黃"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lt": 27
}
}
}
}
}
}
按排序查詢
GET demo/type/_search
{
"query":{
"match":{
"name":"黃"
}
},
"sort":[
{
"age":"desc" #降序
}
]
}
分頁查詢
GET demo/type/_search
{
"query":{"match_all":{}},
"from":0,
"size":2 #從零開始查詢所有記錄,每頁只顯示2條記錄
}
指定查詢結果的欄位
GET demo/type/_search
{
"query":{"match_all":{}},
"_source":["name","age"]
}
高亮查詢
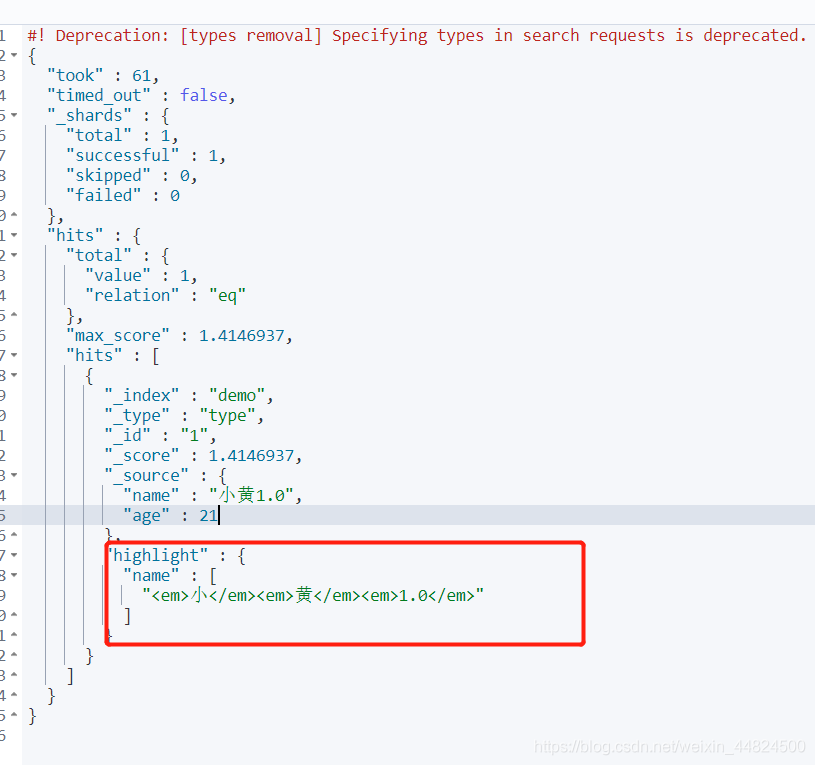
搜索出name為小黃1.0的資料,并將其name欄位高亮顯示
GET demo/type/_search
{
"query":{
"match_phrase":{
"name":"小黃1.0"
}
} ,
"highlight":{
"fields":{
"name":{}
}
}
}
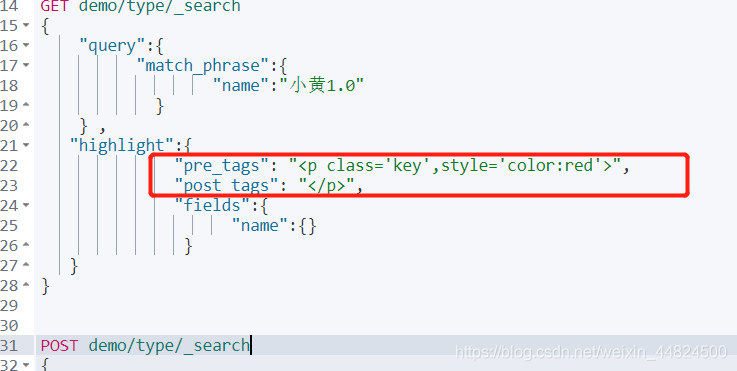
自定義搜索高亮欄位格式前后綴

拓展
GET _cat/nodes #查看所有節點

GET _cat/health #查看es健康狀況

GET _cat/master #查看主節點

GET _cat/indices #查看所有索引 == MySQL中的show databases

參考:
https://www.bilibili.com/video/BV17a4y1x7zq
http://www.mybatis.cn/archives/1112.html
https://www.jianshu.com/p/c96576fcbcd9
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/257429.html
標籤:其他
上一篇:Soul網關(十九)總結02