目錄
- 概要
- 1、登錄模塊
- 2、生成評論
- 3、主要內容
- 4、源代碼匯總(可直接運行)
建議先看 摘要,了解大體專案內容,配好相應環境, 登錄模塊內容記得改成你自己的賬號和密碼,然后直接看 源代碼匯總,在自己電腦上跑跑,能用就繼續學習本文章內容
概要
功能:
- 對csdn門戶網站進行無限評論和點贊操作
- 該實戰專案使用的是firefox瀏覽器,進行selenium進行自動化操作
- 對selenium使用不熟,可轉至Python Selenium庫的使用
要求:
- 安裝selenium庫,安裝代碼 pip install selenium
- 使用firefox(如果你想用google,相應的驅動自己去裝也行)
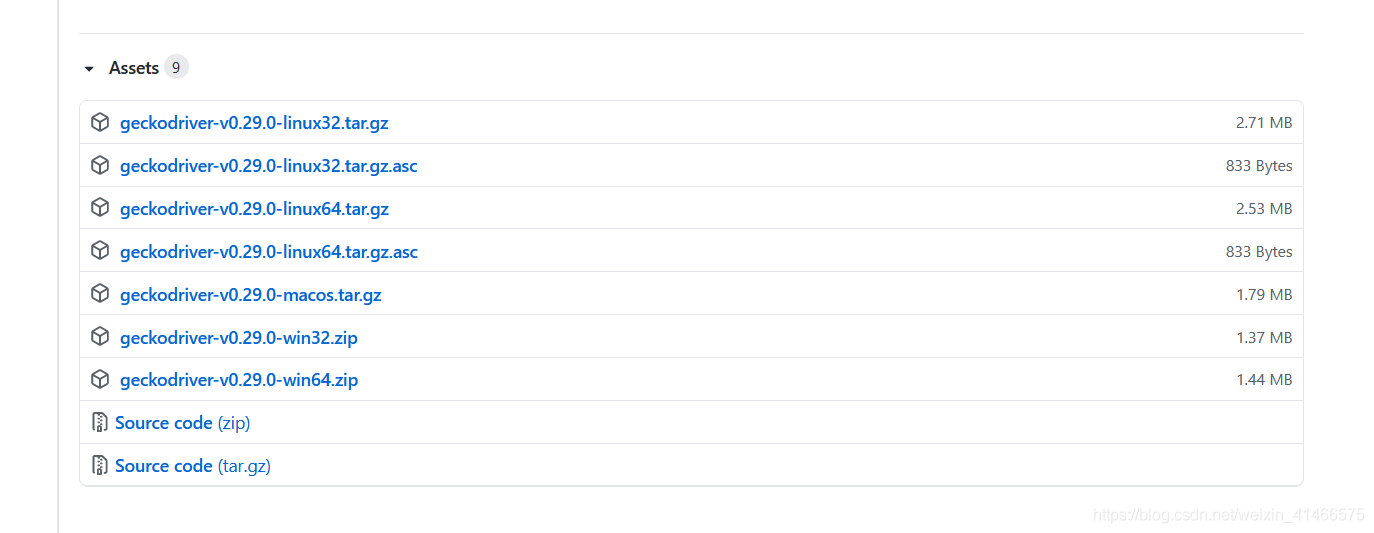
- 下載geckodriver(是Firefox的官方webdriver),如下圖頁面下載
根據不同的系統下載相應的geckodriver
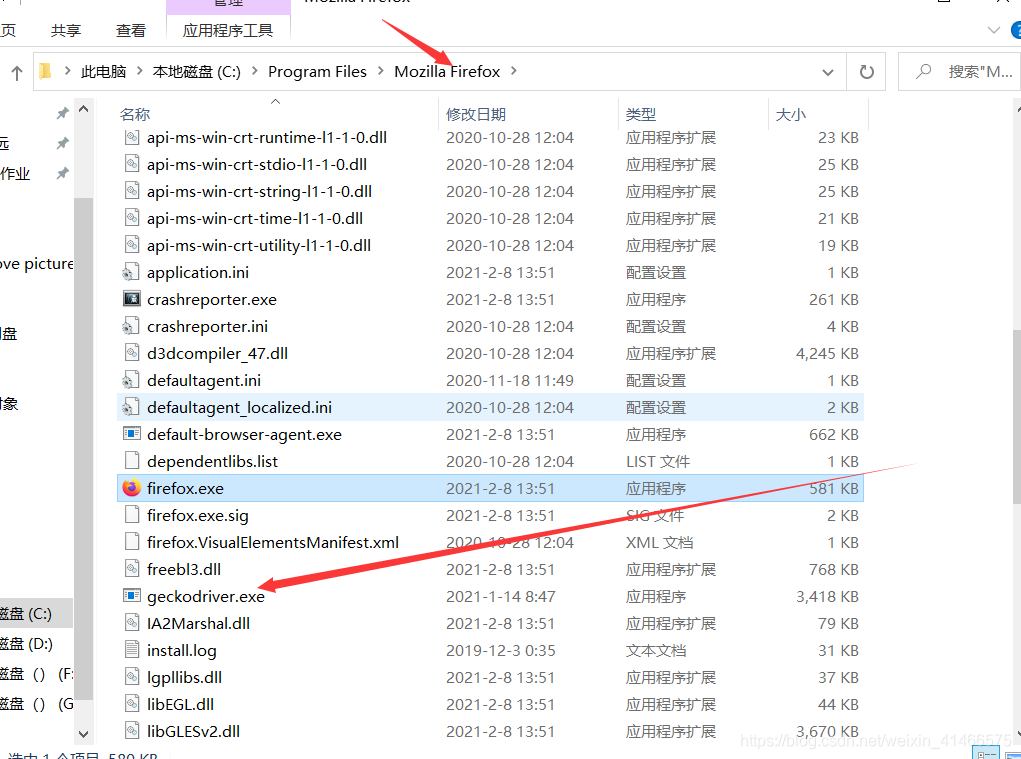
 將geckodriver放在firefox的檔案夾下,如下圖
將geckodriver放在firefox的檔案夾下,如下圖
- 完成以上要求內容,你離成功就剩一半了
專案效果展示:可以看到我的滑鼠可是沒有動的
1、登錄模塊
from selenium import webdriver
import numpy as np
import time
# 1、登錄csdn
# 模擬登錄
def login():
# 以下這個executable_path由自己安裝的geckodriver位置決定
drive = webdriver.Firefox(executable_path='C:\Program Files\Mozilla Firefox\geckodriver.exe')
drive.get("https://passport.csdn.net/login?code=public")
drive.maximize_window()
drive.find_element_by_xpath("/html/body/div[2]/div/div/div[1]/div[2]/div[5]/ul/li[2]/a").click()
drive.find_element_by_xpath('//*[@id="all"]').send_keys("你的csdn賬號")
drive.find_element_by_xpath('//*[@id="password-number"]').send_keys("你的csdn密碼")
drive.find_element_by_xpath('/html/body/div[2]/div/div/div[1]/div[2]/div[5]/div/div[6]/div/button').click()
time.sleep(4)
return drive
login()
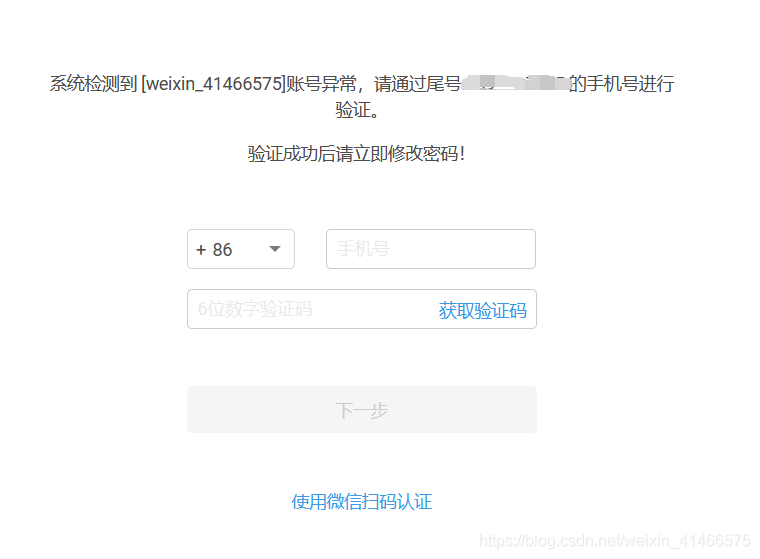
運行結果:可能csdn能檢測到我這是自動化,運行完有如下的一個驗證頁面,不要慌,自己登錄進去即可
 登錄進去就是如下圖,這時候已經獲取的session,之后的代碼如果操作頁面,就是默認以登錄的狀態進行
登錄進去就是如下圖,這時候已經獲取的session,之后的代碼如果操作頁面,就是默認以登錄的狀態進行
2、生成評論
# 2、生成評論
def generate_review():
csdn_review = ['大佬,厲害厲害!!!',"看的出來博主用心了","博客很全面,很仔細,點贊","有所識訓,感謝","內容不錯,三連了",'八千里路的云與月,全部在閱讀中走進了我心靈的深處'
,"文章本天成,妙手偶得之,粹然無疵瑕,豈復須人為?","學習了","哈哈 很棒棒哦","感覺很厲害的亞子","好文章","博主寫的好好,一起加油吖,向Python大佬學習","大佬牛啊,再下佩服",
"支持,幫大忙了","好像很膩害的樣子大佬有空帶帶我",'博主寫的非常好,有理論有例子,非常容易看懂,感謝博主!',"學起來,堅持~歡迎回訪一起交流!","看三遍也看不夠的好文,mark~","哈哈",'學到了,收藏一波~歡迎回訪一起交流!',
"看完大佬的文章,我的心情竟是久久不能平靜,正如老子所云:大音希聲,大象無形,我現在終于明白我缺乏的是什么了,","牛蛙牛蛙,以后跟著大佬學習","收藏了,趁著春節好好學習",'總結的太棒了,這是一位寶藏博主啊,mark一波,小弟期待您的關注哦,',
"風雨過后天空幾度平靜的蒼白,你走后我的心幾分速bai跳的空白","欲寄彩箋兼尺素,山長水闊知何處,——晏殊《鵲踏枝》","紅豆生南國,春來發幾枝,",'人生苦短,我用python',"沒有字母的日子,如同一堆溫暖的木頭,被人們記住,是一種大腦的煙霧,","行到水窮處 坐看云起時",
"三十功名塵與土,八千里路云和月",'所愛隔山海 山海不可平',"代碼之路任重道遠,愿跟博主努力習之,","愛了愛了","覽君荊山作,江鮑堪動色","快進我的收藏夾吃灰吧","七月的風,八月的云,"]
# print (len(csdn_review))
random = np.random.randint(len(csdn_review))
return csdn_review[random]
def scroll2Bottom(drive,times=3):
js = "var q=document.documentElement.scrollTop=20000"
for i in range(times):
drive.execute_script(js)
time.sleep(1)
- 這一部分很簡單就是兩個函式
- 一個是隨機生成各種評論
- 另一個是模擬三次滾動潭訓到最底部的操作,這個操作有點費解?
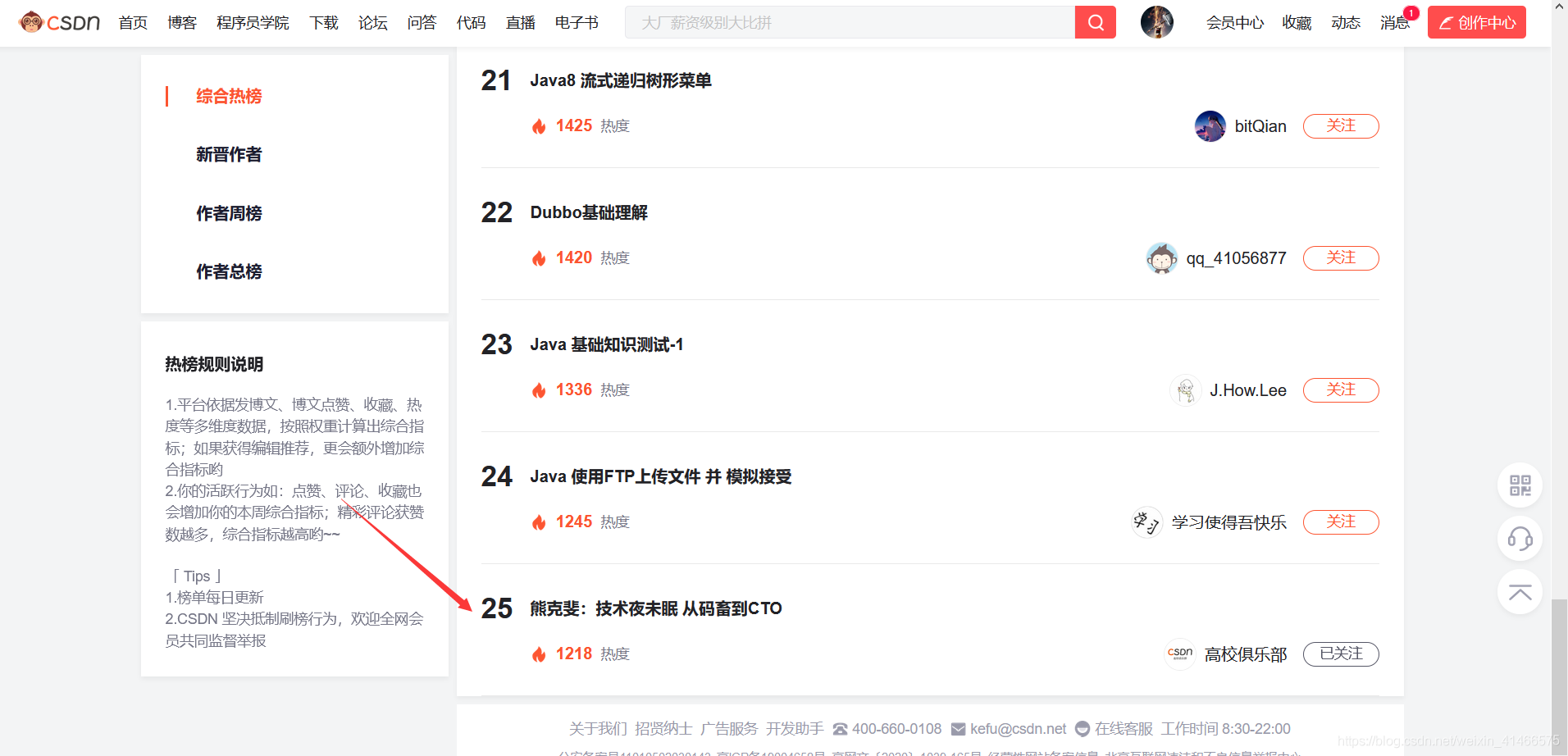
- 不要慌,點進去看這個頁面,這個頁面劃到底部只有25篇文章(如下圖),我要將所有文章都顯示出來只能先模擬三次滾動潭訓到最底部,不信你可以試試嘍
3、主要內容
這一步就是我們模擬評論的核心代碼嘍,這部分比較多,我講一下我的思路,
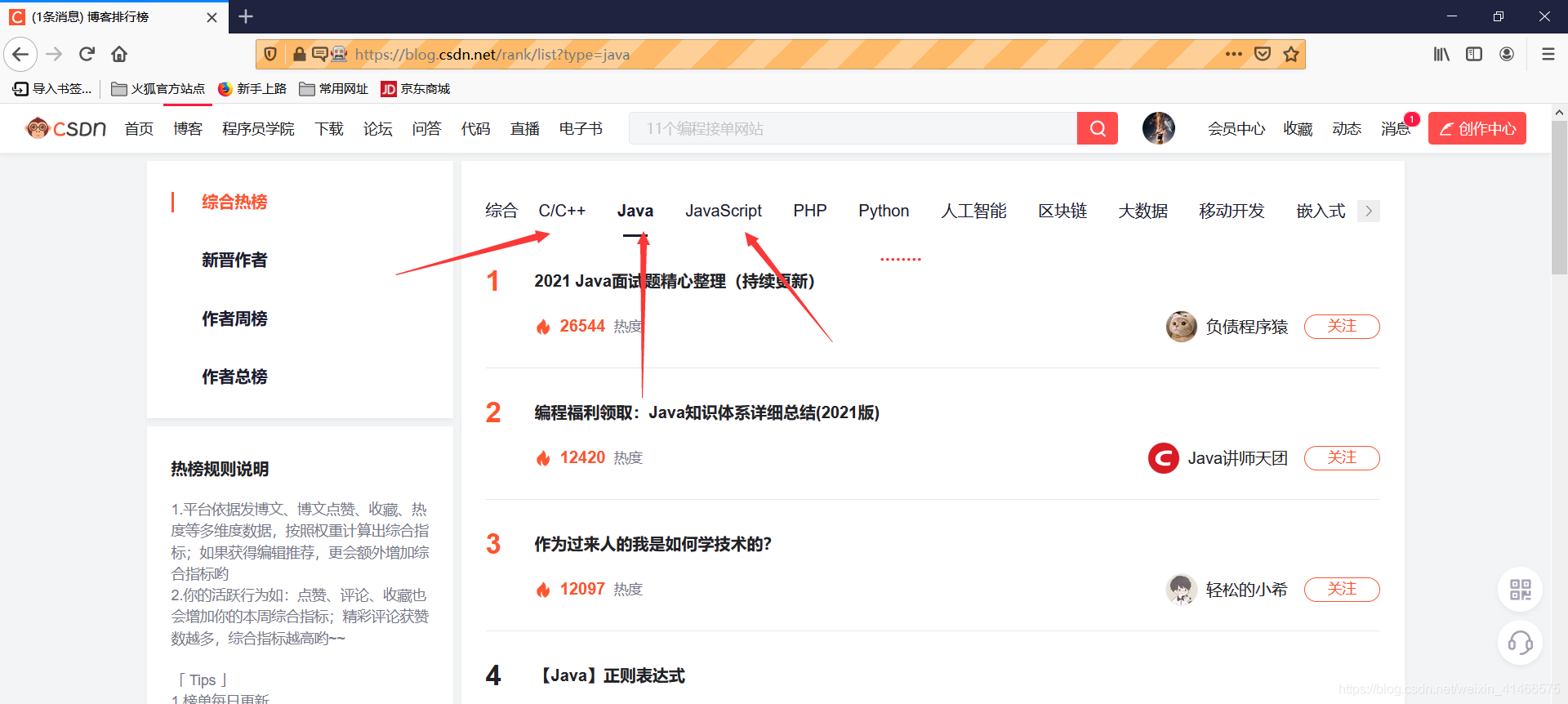
- 先維護一個url_lists,就是如下圖的url鏈接(C++,java,etc…)
- 對每一個鏈接內的所有文章回圈
- 對每個文章內部進行評論以及關注操作
- 大概內容就是如此,細節可以自己去揪,你可以先運行一遍代碼,看下能否成功,這能給你提供一個正反饋
def category_handle(url,sleep_time):
article_times = 0
drive.get(url)
scroll2Bottom(drive,5)
# 定位一組元素,使用elements即可進行定位
all_articles = drive.find_elements_by_xpath('/html/body/div[2]/div/div/div/div/div/div/div/div[2]/div[1]/div/div[2]/div')
for article in all_articles:
article_times = article_times + 1
a = article.find_element_by_tag_name("a")
href = a.get_attribute('href')
js='window.open("'+href+'");'
drive.execute_script(js)
# 將句柄轉換為新的頁面
current_window = drive.current_window_handle
allHandles = drive.window_handles
for handle in allHandles:
if handle != drive.current_window_handle:
drive.switch_to_window(handle)
break;
# 進行評論點贊,二連
try:
time.sleep(2)
# 1、評論
toolbox = drive.find_element_by_class_name("toolbox-list")
toolbox.find_element_by_xpath("li[2]/a").click()
drive.find_element_by_xpath('//*[@id="comment_content"]').send_keys(generate_review())
time.sleep(2)
# 1.1、點擊確認評論
# 使用如下定位,否則很容易出問題,具有區域特殊性
rightBox = drive.find_element_by_xpath('//*[@id="rightBox"]')
rightBox.find_element_by_tag_name("input").click()
# 2、點贊
time.sleep(3)
drive.find_element_by_xpath('//*[@id="is-like-span"]').click()
print ("自動化第"+str(article_times)+"個頁面,該頁面成功了")
except:
# print (drive.title)
print ("自動化第"+str(article_times)+"個頁面,該頁面失敗了")
finally:
time.sleep(sleep_time)
drive.close()
drive.switch_to_window(current_window)
articles = article_times
url_lists = ["https://blog.csdn.net/rank/list?type=c%2Fc%2B%2B","https://blog.csdn.net/rank/list?type=java","https://blog.csdn.net/rank/list?type=javascript","https://blog.csdn.net/rank/list?type=php","https://blog.csdn.net/rank/list?type=python","https://blog.csdn.net/rank/list?type=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD","https://blog.csdn.net/rank/list?type=%E5%8C%BA%E5%9D%97%E9%93%BE","https://blog.csdn.net/rank/list?type=%E5%A4%A7%E6%95%B0%E6%8D%AE","https://blog.csdn.net/rank/list?type=%E7%A7%BB%E5%8A%A8%E5%BC%80%E5%8F%91","https://blog.csdn.net/rank/list?type=%E5%B5%8C%E5%85%A5%E5%BC%8F","https://blog.csdn.net/rank/list?type=%E5%BC%80%E5%8F%91%E5%B7%A5%E5%85%B7","https://blog.csdn.net/rank/list?type=%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%B8%8E%E7%AE%97%E6%B3%95","https://blog.csdn.net/rank/list?type=%E6%B5%8B%E8%AF%95","https://blog.csdn.net/rank/list?type=%E6%B8%B8%E6%88%8F","https://blog.csdn.net/rank/list?type=%E7%BD%91%E7%BB%9C","https://blog.csdn.net/rank/list?type=%E8%BF%90%E7%BB%B4"]
articles = 0
# 設定每評論一次的睡眠時間,防止檢測到機操,這里設定為了10秒
sleep_time = 10
# 設定從第幾個url鏈接開始自動化
start_url_num = 6
time_start=time.time()
for i in range(start_url_num,len(url_lists)):
cur_review_success_times = 0
cur_like_success_times = 0
articles = 0
print ("第"+str(i)+"個鏈接進行selenium :"+url_lists[i])
category_handle(url_lists[i],sleep_time)
print ("訪問共"+str(articles)+"條")
time_end=time.time()
print('all time cost',(time_end-time_start)/60,'min')
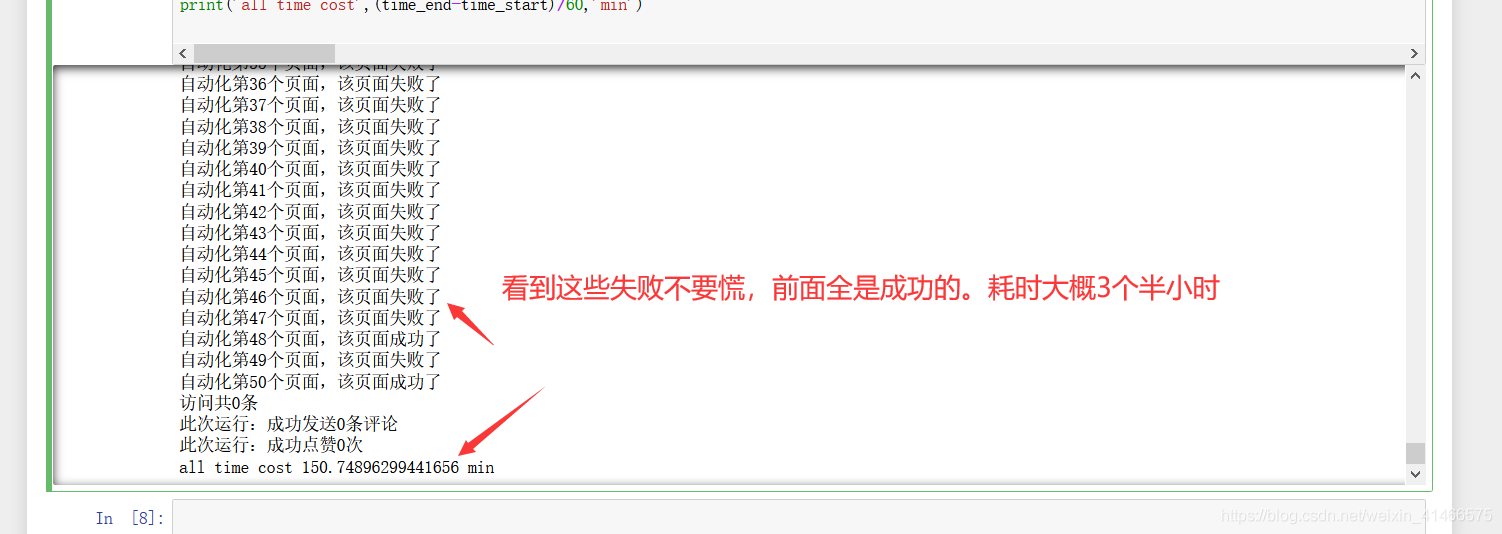
運行結果:
- 運行了大概3小時,進行了有上千次評論和點贊了,
- 效果就是文章最前面的那個gif動圖
- 文本結果如下圖
- 如下圖,才跑了幾十分鐘就有這么多訊息了,哈哈哈哈哈!

4、源代碼匯總(可直接運行)
from selenium import webdriver
import numpy as np
import time
# 1、登錄csdn
# 模擬登錄
def login():
# 以下這個executable_path由自己安裝的geckodriver位置決定
drive = webdriver.Firefox(executable_path='C:\Program Files\Mozilla Firefox\geckodriver.exe')
drive.get("https://passport.csdn.net/login?code=public")
drive.maximize_window()
drive.find_element_by_xpath("/html/body/div[2]/div/div/div[1]/div[2]/div[5]/ul/li[2]/a").click()
# 注意這里當然要你的賬號和密碼
# 要不然怎么可能可以直接跑
drive.find_element_by_xpath('//*[@id="all"]').send_keys("你的csdn賬號")
drive.find_element_by_xpath('//*[@id="password-number"]').send_keys("你的csdn密碼")
drive.find_element_by_xpath('/html/body/div[2]/div/div/div[1]/div[2]/div[5]/div/div[6]/div/button').click()
time.sleep(4)
return drive
drive = login()
# 2、生成評論
def generate_review():
csdn_review = ['大佬,厲害厲害!!!',"看的出來博主用心了","博客很全面,很仔細,點贊","有所識訓,感謝","內容不錯,三連了",'八千里路的云與月,全部在閱讀中走進了我心靈的深處'
,"文章本天成,妙手偶得之,粹然無疵瑕,豈復須人為?","學習了","哈哈 很棒棒哦","感覺很厲害的亞子","好文章","博主寫的好好,一起加油吖,向Python大佬學習","大佬牛啊,再下佩服",
"支持,幫大忙了","好像很膩害的樣子大佬有空帶帶我",'博主寫的非常好,有理論有例子,非常容易看懂,感謝博主!',"學起來,堅持~歡迎回訪一起交流!","看三遍也看不夠的好文,mark~","哈哈",'學到了,收藏一波~歡迎回訪一起交流!',
"看完大佬的文章,我的心情竟是久久不能平靜,正如老子所云:大音希聲,大象無形,我現在終于明白我缺乏的是什么了,","牛蛙牛蛙,以后跟著大佬學習","收藏了,趁著春節好好學習",'總結的太棒了,這是一位寶藏博主啊,mark一波,小弟期待您的關注哦,',
"風雨過后天空幾度平靜的蒼白,你走后我的心幾分速bai跳的空白","欲寄彩箋兼尺素,山長水闊知何處,——晏殊《鵲踏枝》","紅豆生南國,春來發幾枝,",'人生苦短,我用python',"沒有字母的日子,如同一堆溫暖的木頭,被人們記住,是一種大腦的煙霧,","行到水窮處 坐看云起時",
"三十功名塵與土,八千里路云和月",'所愛隔山海 山海不可平',"代碼之路任重道遠,愿跟博主努力習之,","愛了愛了","覽君荊山作,江鮑堪動色","快進我的收藏夾吃灰吧","七月的風,八月的云,"]
# print (len(csdn_review))
random = np.random.randint(len(csdn_review))
return csdn_review[random]
def scroll2Bottom(drive,times=3):
js = "var q=document.documentElement.scrollTop=20000"
for i in range(times):
drive.execute_script(js)
time.sleep(1)
# 3、主要內容
def category_handle(url,sleep_time):
article_times = 0
drive.get(url)
scroll2Bottom(drive,5)
# 定位一組元素,使用elements即可進行定位
all_articles = drive.find_elements_by_xpath('/html/body/div[2]/div/div/div/div/div/div/div/div[2]/div[1]/div/div[2]/div')
for article in all_articles:
article_times = article_times + 1
a = article.find_element_by_tag_name("a")
href = a.get_attribute('href')
js='window.open("'+href+'");'
drive.execute_script(js)
# 將句柄轉換為新的頁面
current_window = drive.current_window_handle
allHandles = drive.window_handles
for handle in allHandles:
if handle != drive.current_window_handle:
drive.switch_to_window(handle)
break;
# 進行評論點贊,二連
try:
time.sleep(2)
# 1、評論
toolbox = drive.find_element_by_class_name("toolbox-list")
toolbox.find_element_by_xpath("li[2]/a").click()
drive.find_element_by_xpath('//*[@id="comment_content"]').send_keys(generate_review())
time.sleep(2)
# 1.1、點擊確認評論
# 使用如下定位,否則很容易出問題,具有區域特殊性
rightBox = drive.find_element_by_xpath('//*[@id="rightBox"]')
rightBox.find_element_by_tag_name("input").click()
# 2、點贊
time.sleep(3)
drive.find_element_by_xpath('//*[@id="is-like-span"]').click()
print ("自動化第"+str(article_times)+"個頁面,該頁面成功了")
except:
# print (drive.title)
print ("自動化第"+str(article_times)+"個頁面,該頁面失敗了")
finally:
time.sleep(sleep_time)
drive.close()
drive.switch_to_window(current_window)
articles = article_times
url_lists = ["https://blog.csdn.net/rank/list?type=c%2Fc%2B%2B","https://blog.csdn.net/rank/list?type=java","https://blog.csdn.net/rank/list?type=javascript","https://blog.csdn.net/rank/list?type=php","https://blog.csdn.net/rank/list?type=python","https://blog.csdn.net/rank/list?type=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD","https://blog.csdn.net/rank/list?type=%E5%8C%BA%E5%9D%97%E9%93%BE","https://blog.csdn.net/rank/list?type=%E5%A4%A7%E6%95%B0%E6%8D%AE","https://blog.csdn.net/rank/list?type=%E7%A7%BB%E5%8A%A8%E5%BC%80%E5%8F%91","https://blog.csdn.net/rank/list?type=%E5%B5%8C%E5%85%A5%E5%BC%8F","https://blog.csdn.net/rank/list?type=%E5%BC%80%E5%8F%91%E5%B7%A5%E5%85%B7","https://blog.csdn.net/rank/list?type=%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%B8%8E%E7%AE%97%E6%B3%95","https://blog.csdn.net/rank/list?type=%E6%B5%8B%E8%AF%95","https://blog.csdn.net/rank/list?type=%E6%B8%B8%E6%88%8F","https://blog.csdn.net/rank/list?type=%E7%BD%91%E7%BB%9C","https://blog.csdn.net/rank/list?type=%E8%BF%90%E7%BB%B4"]
articles = 0
# 設定每評論一次的睡眠時間,防止檢測到機操,這里設定為了10秒
sleep_time = 10
# 設定從第幾個url鏈接開始自動化
start_url_num = 1
time_start=time.time()
for i in range(start_url_num,len(url_lists)):
cur_review_success_times = 0
cur_like_success_times = 0
articles = 0
print ("第"+str(i)+"個鏈接進行selenium :"+url_lists[i])
category_handle(url_lists[i],sleep_time)
print ("訪問共"+str(articles)+"條")
time_end=time.time()
print('all time cost',(time_end-time_start)/60,'min')
函式內部做了例外處理,兼容性應該很強,直接跑代碼試試,有疑問歡迎評論區下留言,盡量及時回復,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/258475.html
標籤:其他