Gauss是基于PostgreSQL基礎之上研發的MPP資料庫,MPP指大規模并行處理架構,在非共享集群中,各獨立節點通過網路進行資料通信協同計算,非共享集群有完全可伸縮性、高可用、高性能等優勢,Gauss采用了Share Nothing架構,即集群各節點相互獨立有獨立記憶體、CPU、磁盤,各節點通過專用網路協議通信,節點下的處理結果將向上層匯總或在節點間流轉,在物理存盤上的水平分割可以大幅提升資料庫的處理能力和容量,主要介紹下相關的調優手段及優化常識,
表結構設計
對于資料量較大的資料結構設計來講,主要從水平拆分和垂直拆分來考慮對資料庫進行拆分來降低表資料量,一般較為常用的為水平拆分,分庫分表磁區為主要的拆分手段,水平拆分的實作是通過物理分割,將同一單元內的資料量降低突破單機資料庫瓶頸極限,
水平分庫: 一般是將資料量到達極限的資料庫中的資料拆分到新建立的其他服務器的新庫中,邏輯上兩個庫的資料為連續,實際存盤分離,
水平分表:一般是將單表資料量極大的大表拆分到多個表中,減少單表的資料量,提升掃描性能,在全表掃描的場景下可以大幅度提高性能,
水平磁區:一般是將表資料進行磁區,相關的資料檔案和索引會存盤在不同磁盤上,磁區一般分為哈希磁區、范圍磁區、串列磁區、數值磁區,常用的一般為范圍磁區和哈希磁區,范圍磁區根據指定欄位將元組分為多個范圍,范圍在不同磁區內沒有重疊,使用where條件對磁區列進行資料篩選時,將會根據條件在指定磁區進行掃描,大大減少了掃描的資料量,哈希磁區根據欄位的散列值將資料均勻地分布在多個磁區中,一般使用范圍磁區較多,將記錄的值按時間范圍或者資料的數值范圍磁區,有選擇性的對欄位較為集中的值進行磁區大大提高查詢效率,
垂直拆分在資料庫優化中比較少,垂直拆分主要是將表資料中的欄位進行拆分,將表欄位較多的大表中不常用資料拆分成多張表,資料查詢通過關聯的方式將資料整合到一起,所以垂直拆分主要是通過業務邏輯將資料拆分,有效減少大表的實際資料,
Gauss的資料處理能力依托于MPP大規模并行處理,也就是分布式集群的計算能力,對于分布式資料庫而言,最為重要的是資料分布、負載均衡,對于資料處理而言需要考慮的就是如何防止資料傾斜導致的單機極限瓶頸,Gauss可以通過節點表來查詢表在每個節點存盤的資料量,來判斷是否存在資料傾斜,我們對于資料傾斜的標準判斷為10%即資料節點最大值-最小值/節點資料平均值 > 10%,判定為表資料傾斜,表資料傾斜會使Gauss需要在節點流轉的處理上花費更長時間,還有可能因為任務并發執行導致的通信阻塞,影響集群的正常運行甚至宕機,Gauss新建表需要選擇表分布方式,hash分布和replication復制兩種,hash分布指定一個或多個欄位按照其散列值將資料均勻分布在多個資料節點,這就要求指定的分布列的值盡可能離散,盡量選擇資料基值較高的列作為分布列,可以保證資料分布較為均勻避免出現嚴重的散列沖突,對于全表掃描、資料關聯等場景會提供較好的節點資料流轉能力,eg:選擇條碼、ID號等唯一識別的資料,或當不具有唯一鍵時選擇多個列作組合分布列進行資料分布,當資料量較小時,沒有必要將資料分布到所有節點,可以選擇建立復制表的方式,復制表指由于節點資料不共享會將表資料在各份節點進行存盤即以空間換時間,集群節點較多且資料較大會造成空間浪費的情況,復制表的好處是當用到復制表時不需要從其他節點獲取對應資料掃描當前節點就可獲取所需資料,減少了資料流動可能造成的阻塞、延遲的情況,
然后就是存盤方式的選擇,列存|行存
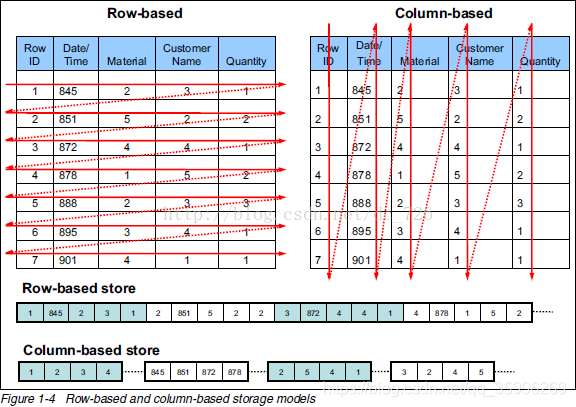
圖片轉載,侵權即刪,
由上圖可看到,行存與列存按照字面意思理解就為按行存盤和按列存盤,按行存盤就是將以行為單位的資料連續存盤,資料讀取時需將所有行資料讀出I/O上會有浪費,按列存盤為將資料列連續存盤,資料讀取時可以按照欄位對需要列進行讀取,不需要讀取多余資料,減少資料塊讀取提高查詢速率,也可以進行資料壓縮節省存盤空間,但當資料需要增刪時,需要較行存更多的I/O,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/259399.html
標籤:其他