一、簡介
RocketMQ 是一款開源的分布式訊息系統,基于高可用分布式集群技術,提供低延時的、高可靠的訊息發布與訂閱服務, 最初是由阿里開源的分布式訊息引擎,由于后面維護問題,提交給Apache下的頂級維護專案之一,現在最新版本V4.8.0,如需了解官網地址:https://rocketmq.apache.org
訊息佇列作為高并發系統的核心組件之一,能夠幫助業務系統解構提升開發效率和系統穩定性,主要具有以下優勢:
- 削峰填谷(主要解決瞬時寫壓力大于應用服務能力導致訊息丟失、系統奔潰等問題)
- 系統解耦(解決不同重要程度、不同能力級別系統之間依賴導致一死全死)
- 提升性能(當存在一對多呼叫時,可以發一條訊息給訊息系統,讓訊息系統通知相關系統)
- 蓄流壓測(線上有些鏈路不好壓測,可以通過堆積一定量訊息再放開來壓測)
目前主流的MQ主要是Rocketmq、kafka、Rabbitmq,Rocketmq相比于Rabbitmq、kafka具有主要優勢特性有:
? 1.支持事務型訊息(訊息發送和DB操作保持兩方的最終一致性,rabbitmq和kafka不支持)
? 2.支持結合rocketmq的多個系統之間資料最終一致性(多方事務,二方事務是前提)
? 3.支持18個級別的延遲訊息(rabbitmq和kafka不支持)
? 4.支持指定次數和時間間隔的失敗訊息重發(kafka不支持,rabbitmq需要手動確認)
? 5.支持consumer端tag過濾,減少不必要的網路傳輸(rabbitmq和kafka不支持)
? 6.支持重復消費(rabbitmq不支持,kafka支持)
二、RocketMQ集群部署結構:
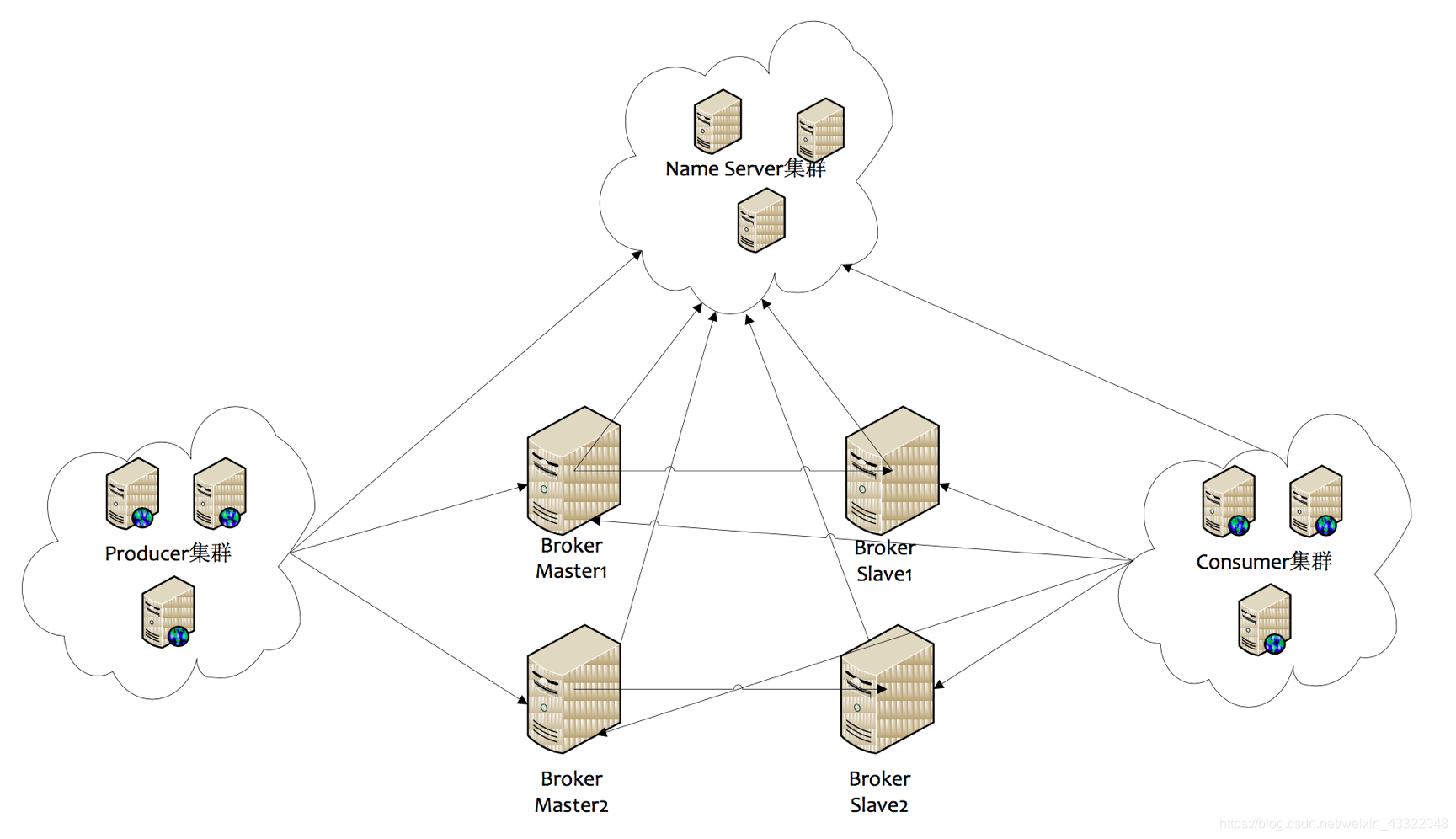
1) Name Server
Name Server是一個幾乎無狀態節點,可集群部署,節點之間無任何資訊同步,
2) Broker
Broker部署相對復雜,Broker分為Master與Slave,一個Master可以對應多個Slave,但是一個Slave只能對應一個Master,Master與Slave的對應關系通過指定相同的Broker Name,不同的Broker Id來定義,BrokerId為0表示Master,非0表示Slave,Master也可以部署多個,
每個Broker與Name Server集群中的所有節點建立長連接,定時(每隔30s)注冊Topic資訊到所有Name Server,Name Server定時(每隔10s)掃描所有存活broker的連接,如果Name Server超過2分鐘沒有收到心跳,則Name Server斷開與Broker的連接,
3) Producer
Producer與Name Server集群中的其中一個節點(隨機選擇)建立長連接,定期從Name Server取Topic路由資訊,并向提供Topic服務的Master建立長連接,且定時向Master發送心跳,Producer完全無狀態,可集群部署,
Producer每隔30s(由ClientConfig的pollNameServerInterval)從Name server獲取所有topic佇列的最新情況,這意味著如果Broker不可用,Producer最多30s能夠感知,在此期間內發往Broker的所有訊息都會失敗,
Producer每隔30s(由ClientConfig中heartbeatBrokerInterval決定)向所有關聯的broker發送心跳,Broker每隔10s中掃描所有存活的連接,如果Broker在2分鐘內沒有收到心跳資料,則關閉與Producer的連接,
4) Consumer
Consumer與Name Server集群中的其中一個節點(隨機選擇)建立長連接,定期從Name Server取Topic路由資訊,并向提供Topic服務的Master、Slave建立長連接,且定時向Master、Slave發送心跳,Consumer既可以從Master訂閱訊息,也可以從Slave訂閱訊息,訂閱規則由Broker配置決定,
Consumer每隔30s從Name server獲取topic的最新佇列情況,這意味著Broker不可用時,Consumer最多最需要30s才能感知,
Consumer每隔30s(由ClientConfig中heartbeatBrokerInterval決定)向所有關聯的broker發送心跳,Broker每隔10s掃描所有存活的連接,若某個連接2分鐘內沒有發送心跳資料,則關閉連接;并向該Consumer Group的所有Consumer發出通知,Group內的Consumer重新分配佇列,然后繼續消費,
當Consumer得到master宕機通知后,轉向slave消費,slave不能保證master的訊息100%都同步過來了,因此會有少量的訊息丟失,但是一旦master恢復,未同步過去的訊息會被最終消費掉,
消費者對列是消費者連接之后(或者之前有連接過)才創建的,我們將原生的消費者標識由 {IP}@{消費者group}擴展為 {IP}@{消費者group}{topic}{tag},(例如xxx.xxx.xxx.xxx@mqtest_producer-group_2m2sTest_tag-zyk),任何一個元素不同,都認為是不同的消費端,每個消費端會擁有一份自己消費對列(默認是broker對列數量*broker數量),新掛載的消費者對列中擁有commitlog中的所有資料,
三、RocketMQ如何支持分布式事務:
應用場景:
A(存在DB操作)、B(存在DB操作)兩方需要保證分布式事務一致性,通過引入中間層MQ,A和MQ保持事務一致性(例外情況下通過MQ反查A介面實作check),B和MQ保證事務一致(通過重試),從而達到最終事務一致性,
原理:大事務 = 小事務 + 異步
MQ與DB一致性原理(雙方事務):
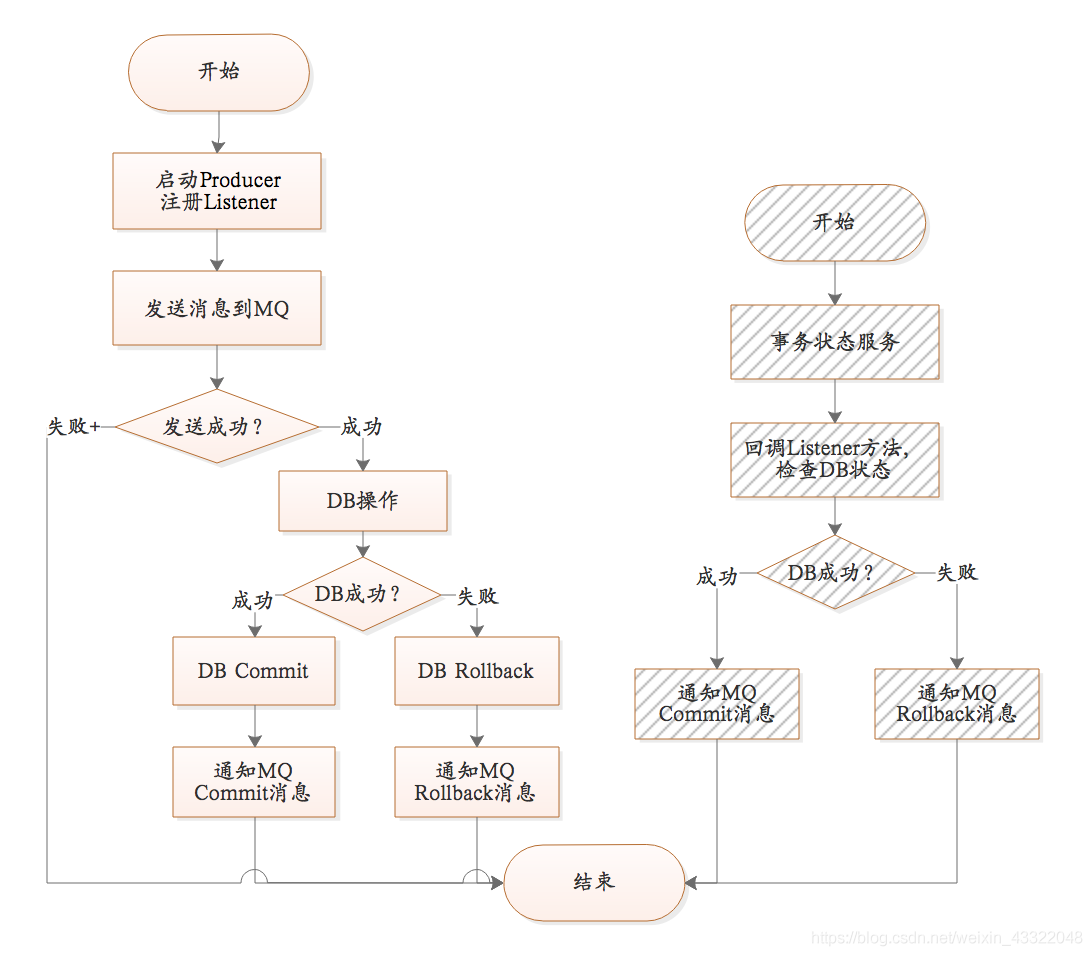
上圖是RocketMQ提供的保證MQ訊息、DB事務一致性的方案,
MQ訊息、DB操作一致性方案:
-
發送訊息到MQ服務器,此時訊息狀態為SEND_OK,此訊息為consumer不可見,
-
執行DB操作;DB執行成功Commit DB操作,DB執行失敗Rollback DB操作,
-
如果DB執行成功,回復MQ服務器,將狀態為COMMIT_MESSAGE;如果DB執行失敗,回復MQ服務器,將狀態改為ROLLBACK_MESSAGE,注意此程序有可能失敗,
-
MQ內部提供一個名為“事務狀態服務”的服務,此服務會檢查事務訊息的狀態,如果發現訊息未COMMIT,則通過Producer啟動時注冊的TransactionCheckListener來回呼業務系統,業務系統在checkLocalTransactionState方法中檢查DB事務狀態,如果成功,則回復COMMIT_MESSAGE,否則回復ROLLBACK_MESSAGE,
說明:
上面以DB為例,其實此處可以是任何業務或者資料源,
以上SEND_OK、COMMIT_MESSAGE、ROLLBACK_MESSAGE均是client jar提供的狀態,在MQ服務器內部是一個數字,
TransactionCheckListener 是在訊息的commit或者rollback訊息丟失的情況下才會回呼(上圖中灰色部分),這種訊息丟失只存在于斷網或者rocketmq集群掛了的情況下,當rocketmq集群掛了,如果采用異步刷盤,存在1s內資料丟失風險,異步刷盤場景下保障事務沒有意義,所以如果要核心業務用Rocketmq解決分布式事務問題,建議選擇同步刷盤模式,
四、RocketMQ如何保證消費順序:
Produce在發送訊息的時候,把訊息發到同一個佇列(Queue)中,消費者注冊訊息監聽器為MessageListenerOrderly,這樣就可以保證消費端只有一個執行緒去消費訊息,
注意:把訊息發到同一個佇列(queue),不是同一個topic,默認情況下一個topic包括4個queue
拓展:可以通過實作發送訊息的對列選擇器方法,實作部分順序訊息,
舉例:比如一個資料庫通過MQ來同步,只需要保證每個表的資料是同步的就可以,決議binlog,將表名作為對列選擇器的引數,這樣就可以保證每個表的資料到同一個對列里面,從而保證表資料的順序消費
總結: Producer端保證發送訊息有序,且發送到同一個佇列; Consumer端保證消費同一個佇列有且只有一個執行緒消費,
五、RocketMQ如何保證訊息不丟失:
分別從Producer發送機制、Broker的持久化機制,以及消費者的offSet機制來最大程度保證訊息不易丟失,
- Producer的視角來看:如果訊息未能正確的存盤在MQ中,或者消費者未能正確的消費到這條訊息,都是訊息丟失,
- Broker的視角來看:如果訊息已經存在Broker里面了,如何保證不會丟失呢(宕機、磁盤崩潰)
- Comsumer的視角來看:如果訊息已經完成持久化了,但是Comsumer取了,但是未消費成功且沒有反饋,就是訊息丟失
Producer分析:如何確保訊息正確的發送到了Broker?
- 默認情況下,可以通過同步的方式阻塞式的發送,check SendStatus,狀態是OK,表示訊息一定成功的投遞到了Broker,狀態超時或者失敗,則會觸發默認的2次重試,此方法的發送結果,可能Broker存盤成功了,也可能沒成功
- 采取事務訊息的投遞方式,并不能保證訊息100%投遞成功到了Broker,但是如果訊息發送Ack失敗的話,此訊息會存盤在CommitLog當中,但是對ComsumerQueue是不可見的,可以在日志中查看到這條例外的訊息,嚴格意義上來講,也并沒有完全丟失
- RocketMQ支持 日志的索引,如果一條訊息發送之后超時,也可以通過查詢日志的API,來check是否在Broker存盤成功
Broker分析:如果確保接收到的訊息不會丟失?
- 訊息支持持久化到Commitlog里面,即使宕機后重啟,未消費的訊息也是可以加載出來的
- Broker自身支持同步刷盤、異步刷盤的策略,可以保證接收到的訊息一定存盤在本地的記憶體中
- Broker集群支持 1主N從的策略,支持同步復制和異步復制的方式,同步復制可以保證即使Master 磁盤崩潰,訊息仍然不會丟失
Comsumer分析:如何確保拉取到的訊息被成功消費?
- 消費者可以根據自身的策略批量Pull訊息
- Comsumer自身維護一個持久化的offset(對應MessageQueue里面的min offset),標記已經成功消費或者已經成功發回到broker的訊息下標
- 如果Comsumer消費失敗,那么它會把這個訊息發回給Broker,發回成功后,再更新自己的offset
- 如果Comsumer消費失敗,發回給broker時,broker掛掉了,那么Comsumer會定時重試這個操作
- 如果Comsumer和broker一起掛了,訊息也不會丟失,因為Comsumer里面的offset是定時持久化的,重啟之后,繼續拉取offset之前的訊息到本地
六、RabbitMQ如何保證消費順序:
Producer在發送訊息時將多個消費者消費的佇列,拆分為多個佇列,也就是一個消費者對應一個佇列,避免了多個消費者消費同一個佇列,造成消費順序錯亂,但這樣就會損耗資源,無非就多了很多佇列,
Comsumer在消費訊息時,要保證一個佇列且一個執行緒去消費,
七、RabbitMQ如何保證訊息不丟失:
1、訊息持久化 2、ACK確認機制 3、設定集群鏡像模式 4、訊息補償機制
第一種(訊息持久化):
RabbitMQ 的訊息默認存放在記憶體上面,如果不特別宣告設定,訊息不會持久化保存到硬碟上面的,如果節點重啟或者意外crash掉,訊息就會丟失,
所以就要對訊息進行持久化處理,如何持久化,下面具體說明下:
要想做到訊息持久化,必須滿足以下三個條件,缺一不可:
1)Exchange 設定持久化
2)Queue 設定持久化
3)Message持久化發送:發送訊息設定發送模式deliveryMode=2,代表持久化訊息
第二種(ACK確認機制):
多個消費者同時收取訊息,比如訊息接收到一半的時候,一個消費者死掉了(邏輯復雜時間太長,超時了或者消費被停機或者網路斷開鏈接),如何保證訊息不丟?
這個使用就要使用Message acknowledgment 機制,就是消費端消費完成要通知服務端,服務端才把訊息從記憶體洗掉,
這樣就解決了,及時一個消費者出了問題,沒有同步訊息給服務端,還有其他的消費端去消費,保證了訊息不丟的case,
第三種(設定集群鏡像模式):
我先來介紹下RabbitMQ三種部署模式:
1)單節點模式:最簡單的情況,非集群模式,節點掛了,訊息就不能用了,業務可能癱瘓,只能等待,
2)普通模式:默認的集群模式,某個節點掛了,該節點上的訊息不能用,有影響的業務癱瘓,只能等待節點恢復重啟可用(必須持久化訊息情況下),
3)鏡像模式:把需要的佇列做成鏡像佇列,存在于多個節點,屬于RabbitMQ的HA方案
為什么設定鏡像模式集群,因為佇列的內容僅僅存在某一個節點上面,不會存在所有節點上面,所有節點僅僅存放訊息結構和元資料,下面自己畫了一張圖介紹普通集群丟失訊息情況:
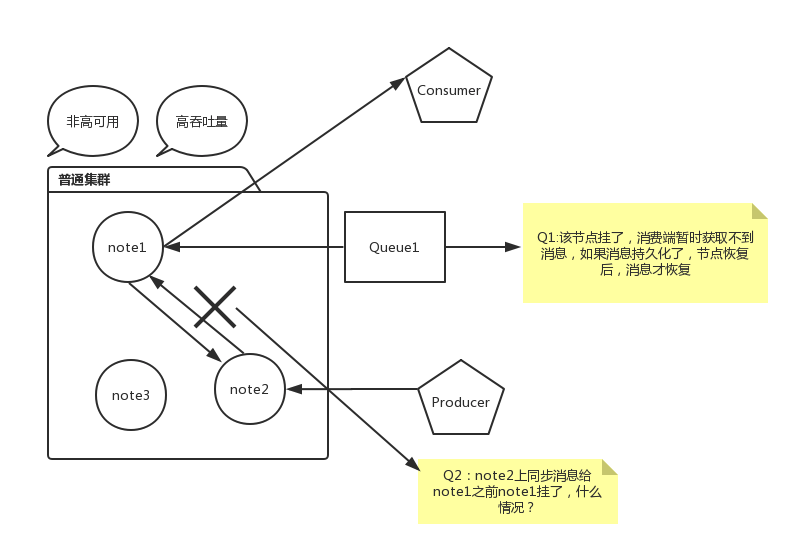
如果想解決上面途中問題,保證訊息不丟失,需要采用HA 鏡像模式佇列,
1)同步至所有的
2)同步最多N個機器
3)只同步至符合指定名稱的nodes
命令處理HA策略模版:rabbitmqctl set_policy [-p Vhost] Name Pattern Definition [Priority]
1)為每個以“rock.wechat”開頭的佇列設定所有節點的鏡像,并且設定為自動同步模式
rabbitmqctl set_policy ha-all “^rock.wechat” ‘{“ha-mode”:“all”,“ha-sync-mode”:“automatic”}’
rabbitmqctl set_policy -p rock ha-all “^rock.wechat” ‘{“ha-mode”:“all”,“ha-sync-mode”:“automatic”}’
2)為每個以“rock.wechat.”開頭的佇列設定兩個節點的鏡像,并且設定為自動同步模式
rabbitmqctl set_policy -p rock ha-exacly “^rock.wechat”
‘{“ha-mode”:“exactly”,“ha-params”:2,“ha-sync-mode”:“automatic”}’
3)為每個以“node.”開頭的佇列分配指定的節點做鏡像
rabbitmqctl set_policy ha-nodes “^nodes.”
‘{“ha-mode”:“nodes”,“ha-params”:[“rabbit@nodeA”, “rabbit@nodeB”]}’
但是:HA 鏡像佇列有一個很大的缺點就是: 系統的吞吐量會有所下降,
第四種(訊息補償機制):
為什么還要訊息補償機制呢?難道訊息還會丟失,沒錯,系統是在一個復雜的環境,不要想的太簡單了,雖然以上的三種方案,基本可以保證訊息的高可用不丟失的問題,
但是作為有追求的程式員來講,要絕對保證我的系統的穩定性,有一種危機意識,
比如:持久化的訊息,保存到硬碟程序中,當前佇列節點掛了,存盤節點硬碟又壞了,訊息丟了,怎么辦?
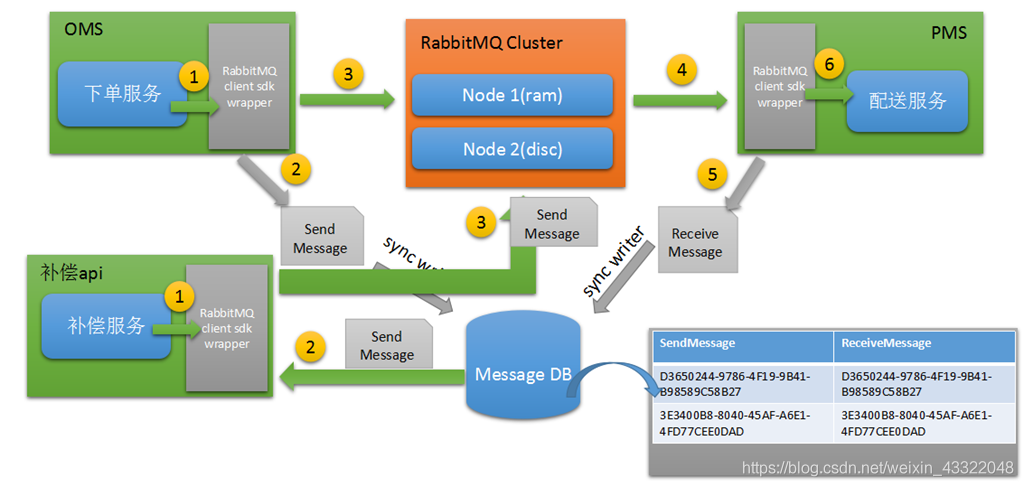
產線網路環境太復雜,所以不知數太多,訊息補償機制需要建立在訊息要寫入DB日志,發送日志,接受日志,兩者的狀態必須記錄,
然后根據DB日志記錄check 訊息發送消費是否成功,不成功,進行訊息補償措施,重新發送訊息處理,
八、RocketMQ與RabbitMQ之間的區別:
RabbitMQ 2007年發布,是一個在AMQP(高級訊息佇列協議)基礎上完成的,可復用的企業訊息系統,是當前最主流的訊息中間件之一,
RabbitMQ優點:
由于erlang語言的特性,mq 性能較好,高并發;
吞吐量到萬級,MQ功能比較完備 ;
健壯、穩定、易用、跨平臺、支持多種語言、檔案齊全;
開源提供的管理界面非常棒,用起來很好用;
社區活躍度高,
RabbitMQ缺點:
erlang開發,很難去看懂原始碼,基本職能依賴于開源社區的快速維護和修復bug,不利于做二次開發和維護,
RabbitMQ確實吞吐量會低一些,這是因為他做的實作機制比較重,
需要學習比較復雜的介面和協議,學習和維護成本較高,
RocketMQ
RocketMQ出自 阿里公司的開源產品,用 Java 語言實作,在設計時參考了 Kafka,并做出了自己的一些改進,
RocketMQ在阿里集團被廣泛應用在訂單,交易,充值,流計算,訊息推送,日志流式處理,binglog分發等場景,
RocketMQ優點:
單機吞吐量:十萬級
可用性:非常高,分布式架構
訊息可靠性:經過引數優化配置,訊息可以做到0丟失
功能支持:MQ功能較為完善,還是分布式的,擴展性好
支持10億級別的訊息堆積,不會因為堆積導致性能下降
原始碼是java,我們可以自己閱讀原始碼,定制自己公司的MQ,可以掌控
RocketMQ缺點:
支持的客戶端語言不多,目前是java及c++,其中c++不成熟;
社區活躍度一般;
沒有在 mq 核心中去實作JMS等介面,有些系統要遷移需要修改大量代碼 ,
九、訊息佇列選擇建議:
RocketMQ
天生為金融互聯網領域而生,對于可靠性要求很高的場景,尤其是電商里面的訂單扣款,以及業務削峰,在大量交易涌入時,后端可能無法及時處理的情況,
RoketMQ在穩定性上可能更值得信賴,這些業務場景在阿里雙11已經經歷了多次考驗,如果你的業務有上述并發場景,建議可以選擇RocketMQ,
RabbitMQ
RabbitMQ :結合erlang語言本身的并發優勢,性能較好,社區活躍度也比較高,但是不利于做二次開發和維護,不過,RabbitMQ的社區十分活躍,可以解決開發程序中遇到的bug,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/259445.html
標籤:其他
上一篇:Java面經-Dubbo