文章目錄
- 引言
- 資料爬取與決議
- 資料爬取
- urllib方法
- requests方法
- 資料決議
- BeaufifulSoup
- xpath
- re正則運算式
- 資料存盤
- 本地excel保存
- sqlite資料庫保存
- 結果展示
- 資料可視化
- Flask
- Echarts
- WordCloud
- 新手問題總結與解決方法
- ip被封
- 查看網頁原始碼和"F12 Elements"后不一致
- 其他問題
引言
在爬蟲學習中,一套完整的專案實戰對于代碼和計算機思維能力有很大的提升,本文基于B站視頻《Python爬蟲基礎5天速成(2021全新合集)Python入門+資料可視化》關于 “豆瓣電影Top250” 專案做出的總結、拓展與分享,
在本文中,只展示資料爬取到資料保存的作業,資料可視化部分只做部分分析和結果展示,具體關于庫的操作我選擇了一些官方檔案做鏈接,知識點比較全面請參考下串列,如果想要專案源代碼,請評論或私信,
- URL處理系統模塊:urllib
- URL處理第三方模塊:requests
- 資料提取bs4模塊:BeautifulSoup
- 資料提取正則運算式模塊:re
- 資料庫保存模塊:sqlite3
- 本地檔案保存模塊:xlwt
資料爬取與決議
資料爬取
資料爬取作業是整個工程的第一步,這一階段所要做的作業是將網頁上帶有我們需要的資訊的網頁原始碼抓取下來,建議在此步驟時,如果資料量不大全部抓取保存到本地;如果資料量很大,則先保存一組到多組資料到本地,在接下的資料決議時通過本地檔案決議,這樣做會避免后面多次訪問網站而被封ip,當然針對被封ip有相應的解決辦法,但是這些內容涉及到網路知識,建議后面再學,
urllib方法
import urllib.request
base_url = "https://movie.douban.com/top250?start="
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36"
}
#構建請求
req = urllib.request.Request(url=base_url,headers=header)
#得到回應
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
with open("top250_first_page.html","w",encoding="utf-8") as f:
f.write(html)
requests方法
import requests
base_url = "https://movie.douban.com/top250?start="
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36"
}
response = requests.get(url=base_url,headers=header)
data = response.content.decode()
with open("top250_first_page.html","w",encoding="utf-8") as f:
f.write(data)
資料決議
資料決議作為第二步是整個工程的核心,這一步直接決定了 我們是否能夠在海量的資料中只得到我們想要的資料,爬蟲中三種重要的資料決議的方法分別是:BeautifulSoup、re正則運算式和xpath,三種方法沒有優劣好壞,按照我前面給出的檔案,自己用好一種即可滿足需求,當然三種方法根據場景使用是最高效的,如果你是大佬的話👍,
我自己常用的是xpath方法,第一,xpath路徑可以直接在網頁上進行復制;第二,可以通過XPath Helper工具進行更好的測驗,我在之前的博客有提到可以點擊查看,下面我用三種不同的方法對保存到本地的一頁上的資料進行了決議,
BeaufifulSoup
from bs4 import BeautifulSoup
import re
#將要決議的網站打開
html = open("top250_first_page.html","rb")
#構建BeautifulSoup物件
soup = BeautifulSoup(html,"html.parser")
#得到每一塊的內容
blocks = soup.select(".grid_view .item")
#構建電影串列
movie_list = []
#電影鏈接和電影圖片鏈接
for index,block in enumerate(blocks):
movie_dict = {}
movie_dict["movie_href"] = block.select("a")[0].get("href") #電影詳情頁鏈接
movie_dict["pic_href"] = block.select("img")[0].get("src") #電影鏈接
title = block.select(".title") #電影名字
if len(title)==2:
movie_dict["c_title"] = block.select(".title")[0].text #電影中文名字
o_title = block.select(".title")[1].text # 電影中文名字
movie_dict["o_title"] = o_title.replace("/","")
else:
movie_dict["c_title"] = block.select(".title")[0].text #電影中文名字
movie_dict["o_title"] = " " #電影外文名字
movie_dict["rate"] = block.select(".star .rating_num")[0].text #電影評分
movie_dict["judge"] = block.select(".star span")[3].text[:-3] #評分人數
bd = block.select(".bd p")[0].text
movie_dict["bd"] = re.sub(" ","",bd)
movie_dict["inq"] = block.select(".quote .inq")[0].text.replace(",","")
movie_list.append(movie_dict)
#列印測驗
print(movie_list)
xpath
from lxml import etree
import re
#將要決議的網站打開
html = open("top250_first_page.html","rb")
content = html.read().decode("utf-8")
#構建etree物件
data = etree.HTML(content)
#獲取多個電影資訊串列
divs = data.xpath('//div[@class="item"]')
for div in divs:
movie_dict = { }
movie_dict["movie_href"] = div.xpath('div[@class="pic"]/a/@href')
#print(movie_href) #測驗
movie_dict["pic_href"] = div.xpath('div[@class="pic"]//img/@src')
#print(pic_href) #測驗
title = div.xpath('div[@class="info"]//a/span[@class="title"]/text()')
if len(title)==2:
movie_dict["c_title"] = title[0]
o_title = title[1].replace("/","")
movie_dict["o_title"] = "".join(o_title.split())
else:
movie_dict["c_title"] = title[0]
movie_dict["o_title"] = " "
#print(c_title,o_title) #測驗
movie_dict["rate"] = div.xpath('div//div[2]/div/span[2]/text()')
#print(rate) #測驗
judge = div.xpath('div//div[2]/div/span[4]/text()')
movie_dict["judge"] = (str(judge))[2:-5]
#print(judge) #測驗
bd = str(div.xpath('div//div[@class="bd"]/p[1]/text()'))
movie_dict["bd"] = bd.replace(" ","").replace(r"\xa0","").replace(r"\r","").replace(r"\n","")
#print(bd) #測驗
print(movie_dict)
re正則運算式
import re
from bs4 import BeautifulSoup
#影片詳情鏈接規則
findLink = re.compile(r'<a href="(.*?)">') #創建正則運算式物件,表示規則(字串的模式)
#影片圖片規則
findSrclink = re.compile(r'<img.*src="(.*?)"',re.S)
#影片片名規則
findTitle = re.compile(r'<span class="title">(.*)</span>')
#影片的評分規則
findGrade = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
#評價人數規則
findJud = re.compile(r'<span>(.*)人評價</span>')
#找到概況
findInq = re.compile(r'<span class="inq">(.*)</span>')
#影片相關內容
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)
#將要決議的網站打開
html = open("top250_first_page.html","rb")
content = html.read().decode("utf-8")
datalist = []
soup = BeautifulSoup(content, "html.parser")
for item in soup.find_all("div",class_ = "item"):
item = str(item)
#print(html) #測驗電影資訊的一小段有沒有內決議拿到
data = [ ]
title = re.findall(findTitle,item)
if(len(title)==2):
Ctitle = title[0]
data.append(Ctitle)
Ftitle = title[1]
Ftitle = title[1].replace("/", "")
Ftitle = "".join(Ftitle.split())
data.append(Ftitle)
else:
Ctitle = title[0]
data.append(Ctitle)
Ftitle = " "
data.append(Ftitle)
link = re.findall(findLink,item)[0]
data.append(link)
srclink = re.findall(findSrclink,item)[0]
data.append(srclink)
grade = re.findall(findGrade,item)
data.append(grade)
judge = re.findall(findJud,item)
data.append(judge)
inq = re.findall(findInq,item)
data.append(inq)
bd = re.findall(findBd,item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?'," ",bd)
bd = re.sub("/"," ",bd)
bd = "".join(bd.split())
data.append(bd)
datalist.append(data)
print(datalist) #測驗所有串列是否被列印
資料存盤
本地excel保存
import xlwt
workbook = xlwt.Workbook(encoding="utf-8", style_compression=0)
worksheet = workbook.add_sheet("豆瓣電影250")
col = ["中文名", "外文名", "電影鏈接", "圖片鏈接", "評分", "評價人數", "概評", "概述"]
for i in range(0, 8):
worksheet.write(0, i, col[i])
for i in range(len(datalist)):
for j in range(0, 8):
worksheet.write(i + 1, j, datalist[i][j])
workbook.save("豆瓣top250_firstPage.xls")
sqlite資料庫保存
import sqlite3
def init_db(dbpath):
sql = '''
create table movie250
(
id integer primary key autoincrement,
info_link text,
pic_link text,
cname varchar,
ename varchar,
score numeric ,
rated numeric ,
instroduction text,
info text
)
''' # 創建資料表
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
def saveData2DB(datalist, dbpath):
#init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
if index == 4 or index == 5 or index==6:
#data[index] = '"' + data[index] + '"'
data[index] = str(data[index])
sql = '''
insert into movie250 (
info_link,pic_link,cname,ename,score,rated,instroduction,info)
values(%s)''' % ",".join(data)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
saveData2DB(datalist,"movie.db")
結果展示
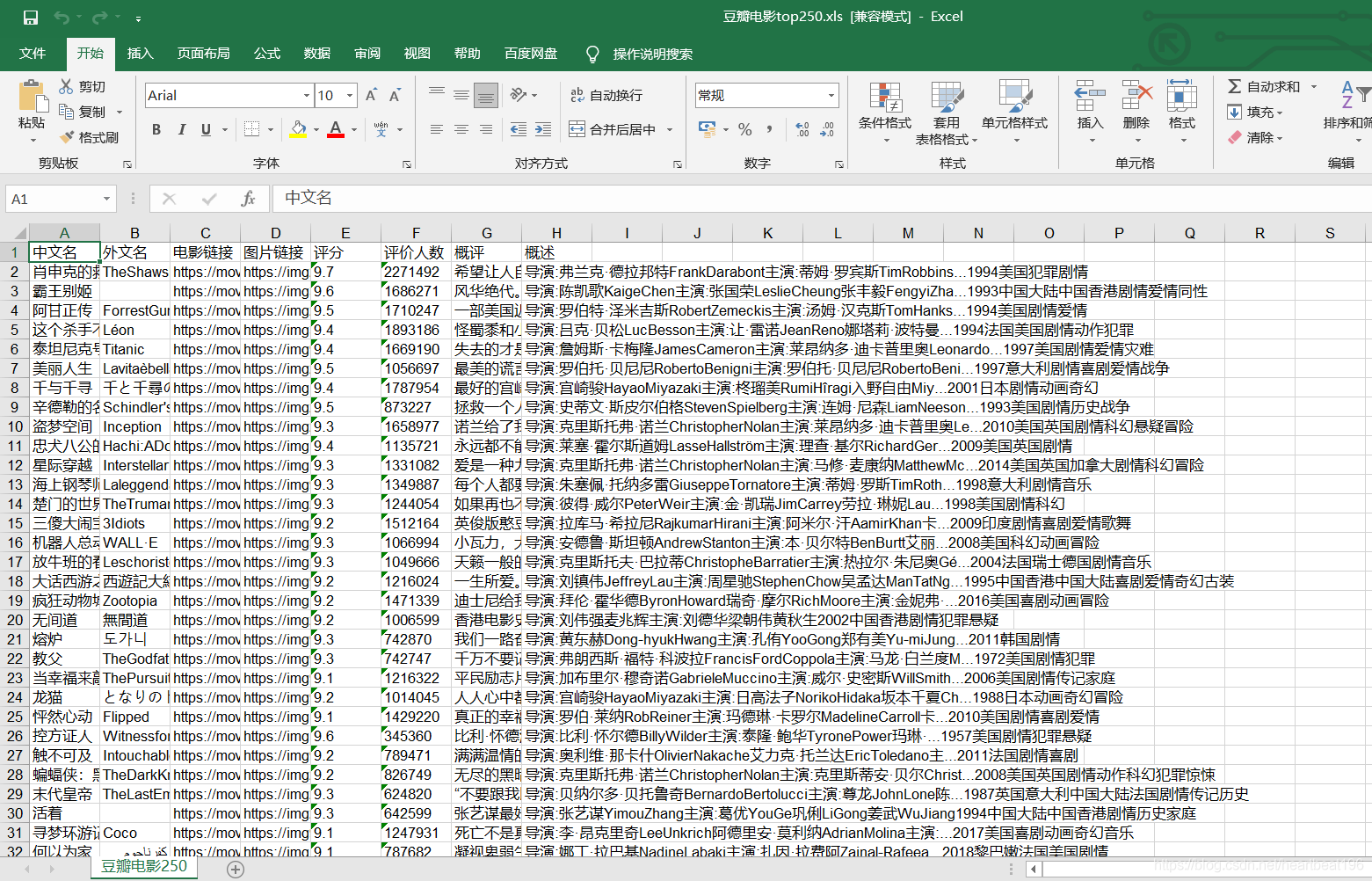
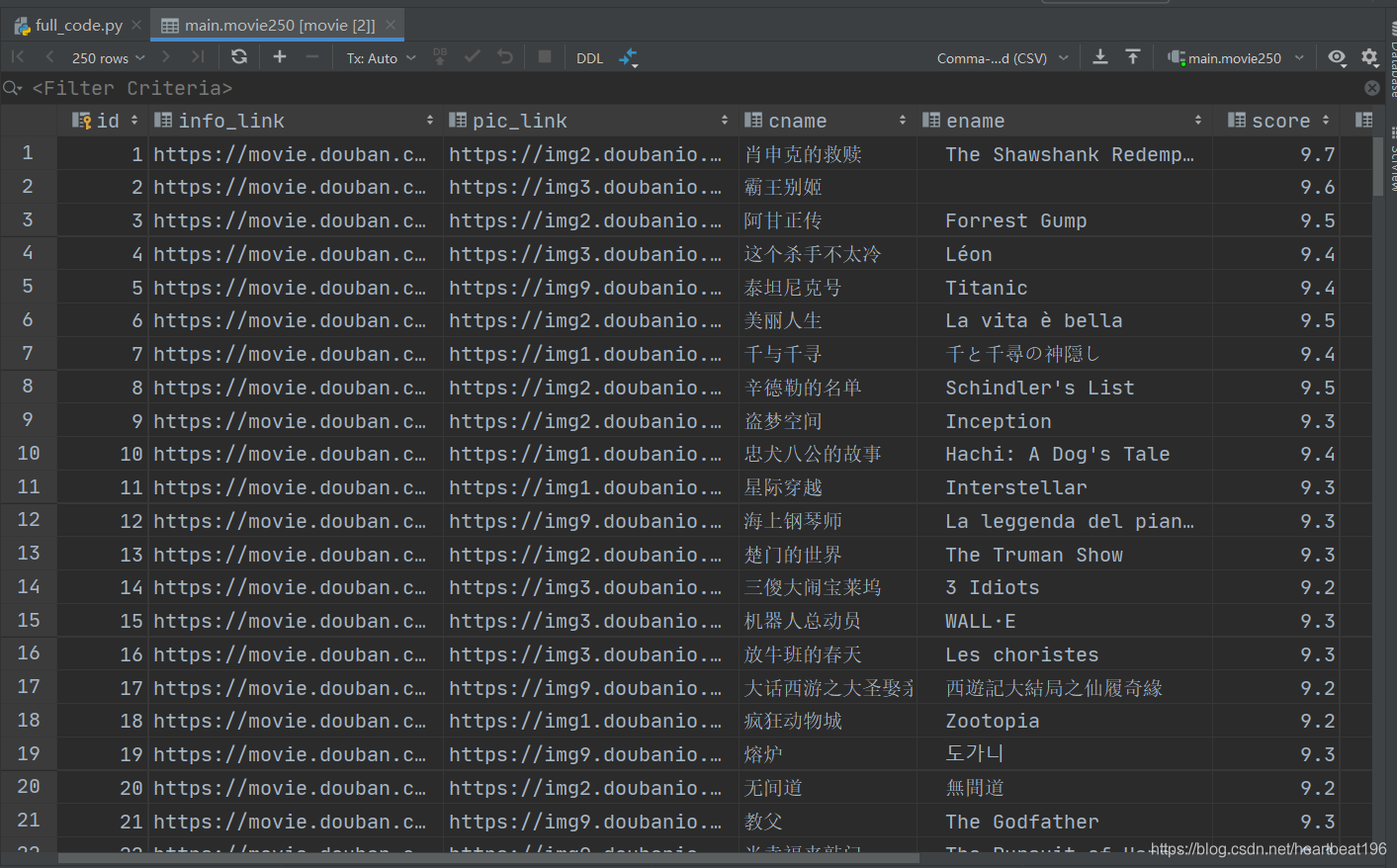
資料可視化
Flask
Flask 是一個微型的 Python 開發的 Web 框架,基于Werkzeug WSGI工具箱和Jinja2 模板引擎, Flask使用BSD授權, Flask也被稱為“microframework”,因為它使用簡單的核心,用extension增加其他功能,Flask沒有默認使用的資料庫、表單驗證工具,
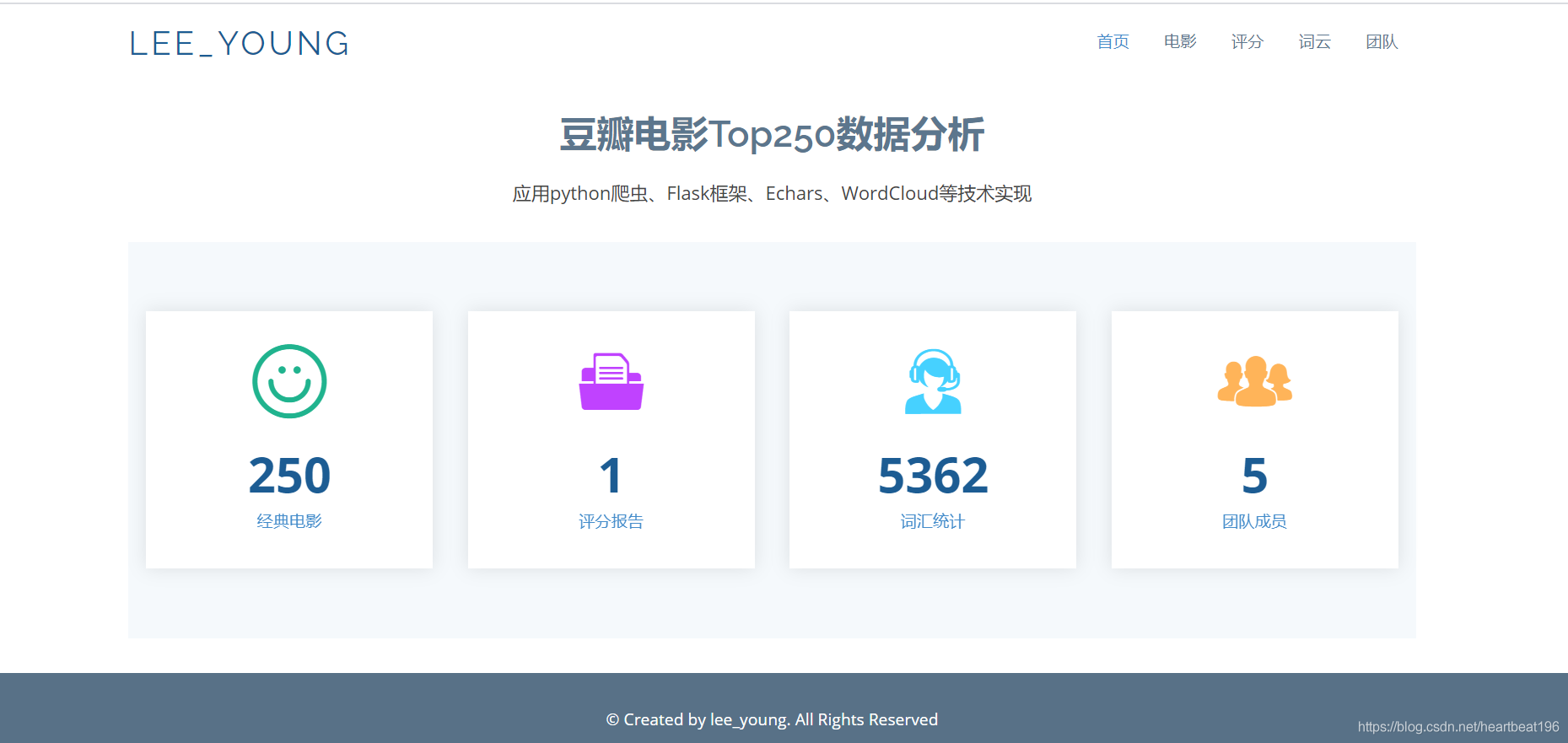
簡單來說在此專案中,Flask框架給我們提供了一個本地網頁平臺展示資料,我們根據不同的路由地址進行到不同的頁面訪問,如下圖是首界面,通過不同的鏈接地址可以實作頁面跳轉,當然只是本地!
Echarts
Echarts是一個純基于js的圖表庫,可以流暢的運行在 PC 和移動設備上,在本專案中可以將資料進行統計分類從而用不同的展示方法進行展現,在Echarts中可以支持的圖表型別有很多,同時其有一個很好的點在于它能滿足我們實時修改查看,最終形成自己想要的圖,便將js代碼復制粘貼到我們所需要的網頁代碼的地方,
由于在頁面內有動態顯示,所以不在進行展示,
WordCloud
詞云展示方法是近些年來較為常用的資料可視化方法,其主要是通過分詞技術將一篇文章或者一段話分成若干單詞,然后統計這些詞出現的頻率,我們根據自定義化設定畫布和這些詞出現的顏色大小等等來得到某個詞云,詞云中重要的是畫布的配置、自己所要定義的形式是什么樣子,其他更多的是某些固定的方法,下圖為我通過爬取毛不易的歌詞內容獲得毛不易的歌詞詞云圖,如果需要此專案原始碼或者方法請私信,

新手問題總結與解決方法
ip被封
ip被封可能是新手在爬蟲學習階段遇到的最大的問題,首先如果是初學想要盡快實作一些成果時,建議在合理范圍內減少爬取次數,如果我們能獲得網頁內容了首先將其存到本地檔案夾下進行后續的測驗和決議,俗話說:上有政策下有對策,面對ip被封:基礎階段我們可以添加請求頭,盡可能的進行偽裝像一個瀏覽器在訪問;再進一步我們可以自己構建代理ip函式,仿照原始碼添加免費ip,構建handler處理器使用opener方法也可以;如果有能力的話,可以學習代理ip池的方法來解決該問題,
當然,爬蟲我們是要在合法范圍內進行抓取,如果某些資料是機密或者不能訪問的,我們還一直訪問可能就很快有自己的小手鐲子了🔓,我們只爬取我們可以訪問到的,爬蟲只是提高效率,不是翻過禁墻,
查看網頁原始碼和"F12 Elements"后不一致
該問題可以總結為用一般方法有些需要的元素抓取不到,在本次專案中我們爬取的頁面是靜態網頁所以可以直接抓取,但是對于動態網頁就會無能為力,
查看網頁原始碼:最原始的代碼,指的是服務器直接發送到瀏覽器的代碼,
F12檢查元素:js渲染后的代碼,而確實的部分就是js所渲染的,
如果我們想要抓取這部分代碼可以采取以下兩種方法:
- 在頁面上進行抓包,獲取表單的元素和js鏈接提交請求
- 通過selenium技術,模擬用戶打開網頁,進行自動化的抓取,
其他問題
以上兩個問題是我在這個專案中所遇到的,當然在面對更復雜的爬蟲作業時,會有更加繁瑣的問題出現,還有一些其他問題,我將其總結為基礎知識問題,在很多初學的時候,我們獲得的資料往往以不同的格式進行存盤,但是某些方法只能針對某些固定資料格式,這些需要我們提起注意;還有就是我們不可避免的馬虎問題,關鍵詞拼寫錯誤,變數書寫錯誤等等,這些最好的解決辦法就是孰能生巧,
最后就是建議大家在完成一個專案時選擇分塊按照不同的模塊去練習測驗,最終完成專案,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/259511.html
標籤:其他