文章主要是總結一學期所學,基本
覆寫了所有常見的指令,足夠完成arima模型的資料選擇到模型預測,
時間序列應用廣泛,不能僅僅局限于理論學習,代碼實踐更為重要,
往期文章鏈接:
基于 ARIMA-GARCH 模型人名幣匯率分析與預測[論文完整][2020年]
文章目錄
- 1 安裝包指令
- 2 加載包指令
- 3 help指令的使用
- 4 讀取不同格式資料
- 4.1 讀取csv格式的資料
- 4.2 讀取txt格式的資料
- 4.3 讀取xls和xlsx格式的資料
- 4.4 引數使用
- 5 ts生成時間序列的物件
- 5.1 時間間隔為年的情況
- 5.2 時間間隔為月的情況
- 5.3 時間間隔為日的情況
- 5.4 引數使用
- 6 plot繪制時間序列的折線圖
- 7 平穩性檢驗的三種方式
- 7.1 圖檢法
- 7.2 通過acf自相關系數圖
- 7.3 通過adf函式p值判斷(不需要主觀判斷)
- 8 白噪聲(純隨機)檢驗的方式
- 9 繪制自相關系數圖和偏自相關系數圖
- 10模型選擇及其定階
- 10.1通過acf圖和pacf圖
- 10.2通過auto.arima()自動選擇
- 11AIC,BIC準則判斷模型好壞
- 12 foreca進行模型預測
- 13 差分命令
- 14 差分命令
- 15 完整操作流程圖
- 總結
1 安裝包指令
install.packages("tseries")
install.packages("forecast")
2 加載包指令
說明:載入一個包之后,就可以使用一系列新的函式和資料集了,包中往往提供了演示性的小型資料集和示例代碼,能夠讓我們嘗試這些新功能
library(tseries)
library(forecast)
3 help指令的使用
說明:使用函式help()可以查看其中任意函式或資料集的更多細節
help(package="tseries")
4 讀取不同格式資料
4.1 讀取csv格式的資料
data<-read.csv("路徑",header=F,sep=",")
4.2 讀取txt格式的資料
data<-read.table("路徑",header=F,sep=",")
4.3 讀取xls和xlsx格式的資料
可以統一將資料檔案格式轉成csv進行處理
4.4 引數使用
路徑(注意反斜杠的方向)
E:/大三上課程/時間序列.csv
E:/大三上課程/時間序列.txt
heaer
這是一個邏輯值,T or F 反映檔案的第一行是否包含變數名
sep
檔案中的欄位分隔符,例如對用制表符分割的檔案使用sep="\t"
5 ts生成時間序列的物件
5.1 時間間隔為年的情況
ts(data$V1,frequency = 1,start=c(1975))
frequent=1表示以年為單位間隔 start說明了資料從1975年開始
5.2 時間間隔為月的情況
ts(data$V1,frequency = 12,start=c(1975,1))
frequent=12表示以月為單位間隔 start說明資料從1975年1月開始

5.3 時間間隔為日的情況
ts(data$V1,frequency = 365,start=c(1975,1,1))
frequent=365表示以日為單位間隔 start說明資料從1975年1月1日開始
5.4 引數使用
data
這個必須是一個矩陣,或者向量,再或者資料框frame
補充 :data$v1 表示資料源的第一排 v2表示第二排 容易遺漏
Frequency
這個是時間觀測頻率數,也就是每個時間單位的資料數目
Start
時間序列開始值(是一個向量),允許第一個個時間單位出現資料缺失
6 plot繪制時間序列的折線圖
plot基本用法
plot(x=x軸資料,y=y軸資料,main="標題",sub="子標題",type="線型",xlab="x軸名稱",ylab="y軸名稱",xlim = c(x軸范圍,x軸范圍),ylim = c(y軸范圍,y軸范圍))
實體演示
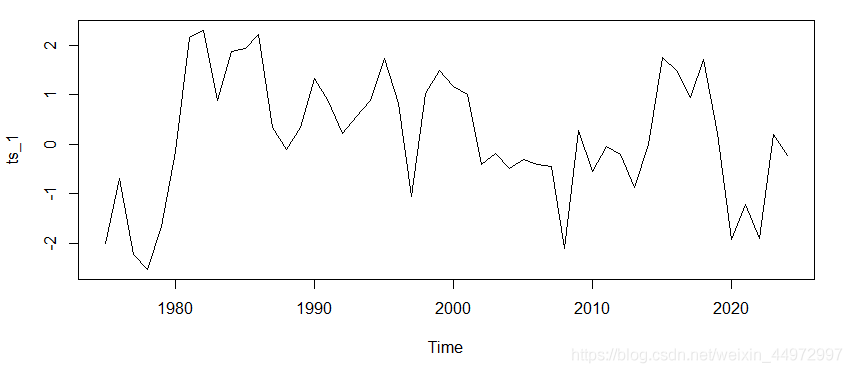
ts_1<-ts(data$V1,frequency = 365,start=c(1975,1,1))
plot(ts_1,main="ceshi",ylab="大小",xlab="時間",ylim=(-3:3))
7 平穩性檢驗的三種方式
7.1 圖檢法
通過plot()繪制時間序列的時序圖,如果序列是平穩的,那么序列應該是圍繞一個均值上下隨機波動,如果序列呈現遞增遞減則不是平穩時間序列,
如下圖時序圖無明顯趨勢,在一個值上下波動,初步判斷為平穩序列,
7.2 通過acf自相關系數圖
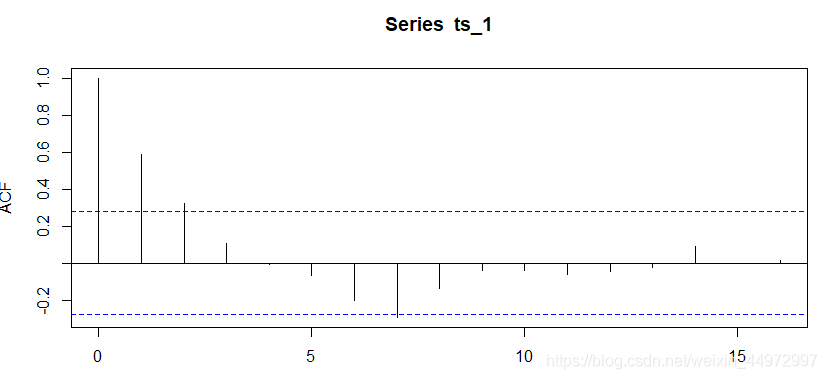
對于平穩時間序列,其自相關圖一般隨著階數的遞增,自相關系數會迅速衰減至0附近,而非平穩時間序列則可能存在先減后增或者周期性波動等變動,如下圖所示,該時間序列隨著階數的遞增迅速衰減至0附近,因此,可以判斷該時間序列不是平穩時間序列,
acf(ts_1)
7.3 通過adf函式p值判斷(不需要主觀判斷)
#使用前要加載包 ts_1是通過ts生成的時間序列(不清楚看前面)
install.packages("tseries")
library(tseries)
adf.test(ts_1)
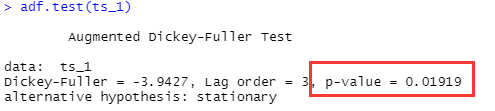
p值為0.02547小于顯著性水平0.05接受備擇假設,為平穩序列,若p值大于0.05則為非平穩性檢驗
8 白噪聲(純隨機)檢驗的方式
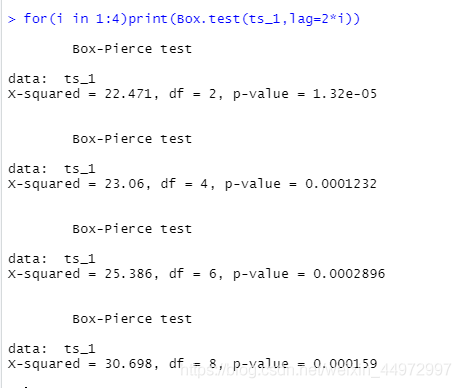
#其中ts_1是通過ts做出的時序序列,for回圈是為了多判斷幾期p值的判斷,
#一般我們判斷前12期的p值,期數越大越不容易小于0.05,
for(i in 1:4)print(Box.test(ts_1,lag=2*i))
當p值都小于0.05,我們接受備擇假設,該序列為非隨機序列,
當p值大于0.05,我們選擇原假設,該序列為 純隨機序列,
例如下,p值都小于0.05判斷為非隨機序列,如果為隨機序列則資料之間無關聯,只能進行差分或者放棄,
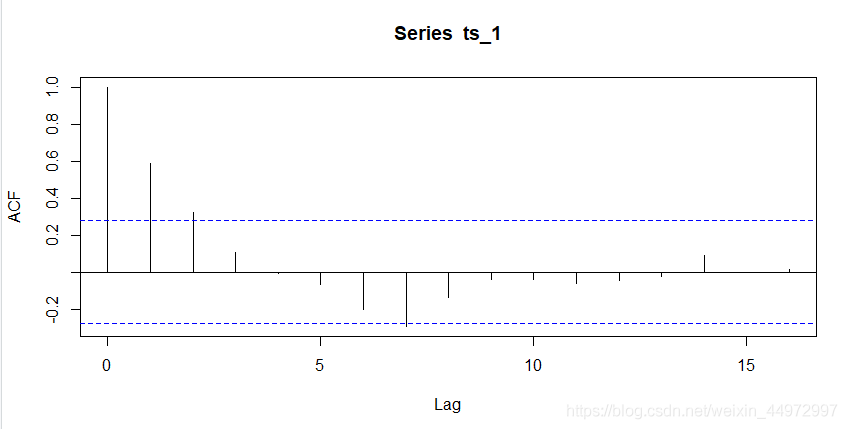
9 繪制自相關系數圖和偏自相關系數圖
自相關系數圖acf
acf(ts_1)
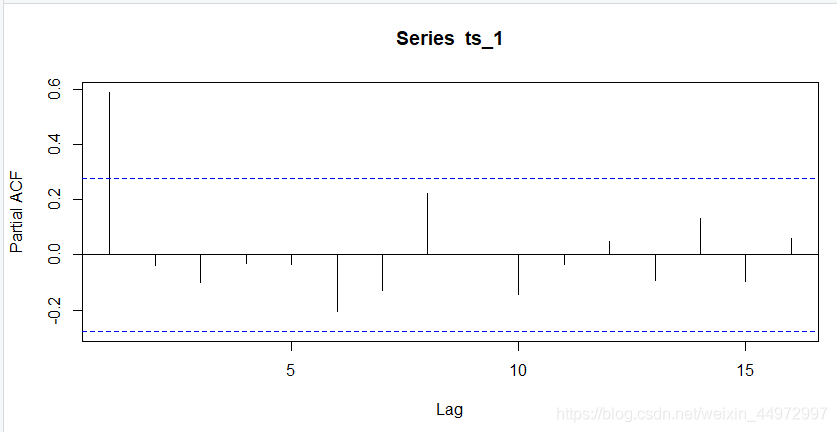
偏自相關系數pacf
pacf(ts_1)
補充
下面指令可以將直接做出時序圖,acf,pacf
tsdisplay(ts_1)
10模型選擇及其定階
10.1通過acf圖和pacf圖
-
若PACF序列滿足在p步截尾,且ACF序列被負指數函式控制收斂到0,則Yn為AR§序列,
-
若ACF序列滿足在q步截尾,且PACF序列被負指數函式控制收斂到0,則Yn為MA(q)序列
, -
若ACF序列和PACF序列滿足皆不截尾,但都被負指數函式控制收斂到0,則Yn為ARMA序列,
當我們選擇好模型可以通過如下指令進行構建模型
#其中p表示AR的階數 d表示差分的次數 q表示MA的階數
all<-arima(ts_1,order=c(p,d,q))
all
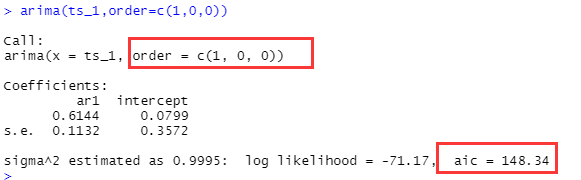
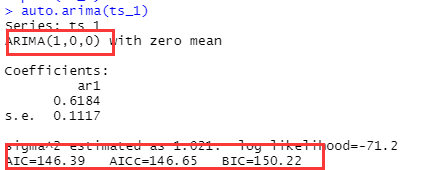
10.2通過auto.arima()自動選擇
# 無特殊要求使用默認引數即可
auto.arima(ts_1)
如下函式為我們選擇的是AR(1) ,aic aicc bic都是用來判斷模型的好壞的準則,后面具體說明,
11AIC,BIC準則判斷模型好壞
AIC
AIC = -2In(L) + 2k
其中L指對應的最大似然函式,k指對應的模型的變數的個數,
BIC
BIC = -2In(L) + In(n)*k
n指對應的資料數量,L和k同上所述,kln(n)懲罰項在維數過大且訓練樣本資料相對較少的情況下,可以有效避免出現維度災難現象,
AIC,BIC越小越好
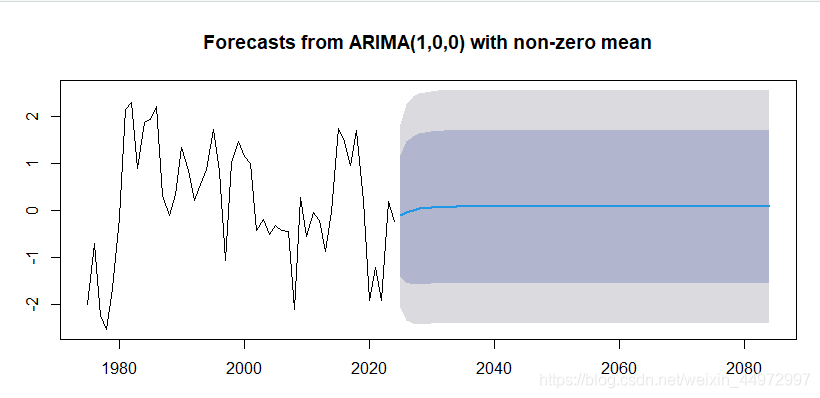
12 foreca進行模型預測
# all表示模型 all<-arima(ts_1,order=c(1,0,0))
# 60表示預測接下來的60個值
library(forecast)
plot(forecast(all,60))#繪制圖形
forecast(all,60) #顯示所有預測值
13 差分命令
#s1 表示差分后新的序列
#data$v1表示資料源的第一列,也就是要進行操作的資料
#1表示差分一次
s1<-diff(data$v1,1)
14 差分命令
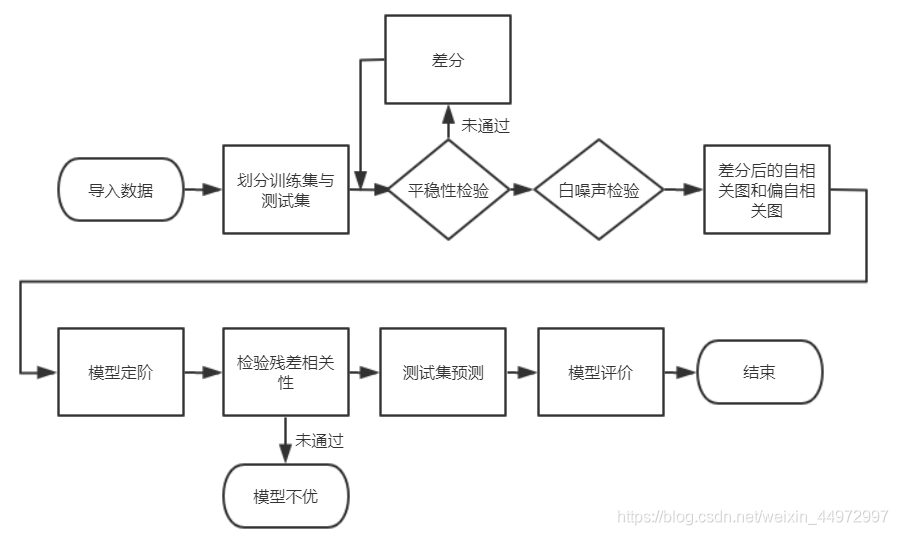
15 完整操作流程圖
總結
最后希望給文章
點個贊,整理不易!!!
最后希望給文章點個贊,整理不易!!!
最后希望給文章點個贊,整理不易!!!
如果有錯誤可以評論私信,
如有需要完整論文及代碼資料便于參考學習可評論、私信,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/259521.html
標籤:其他