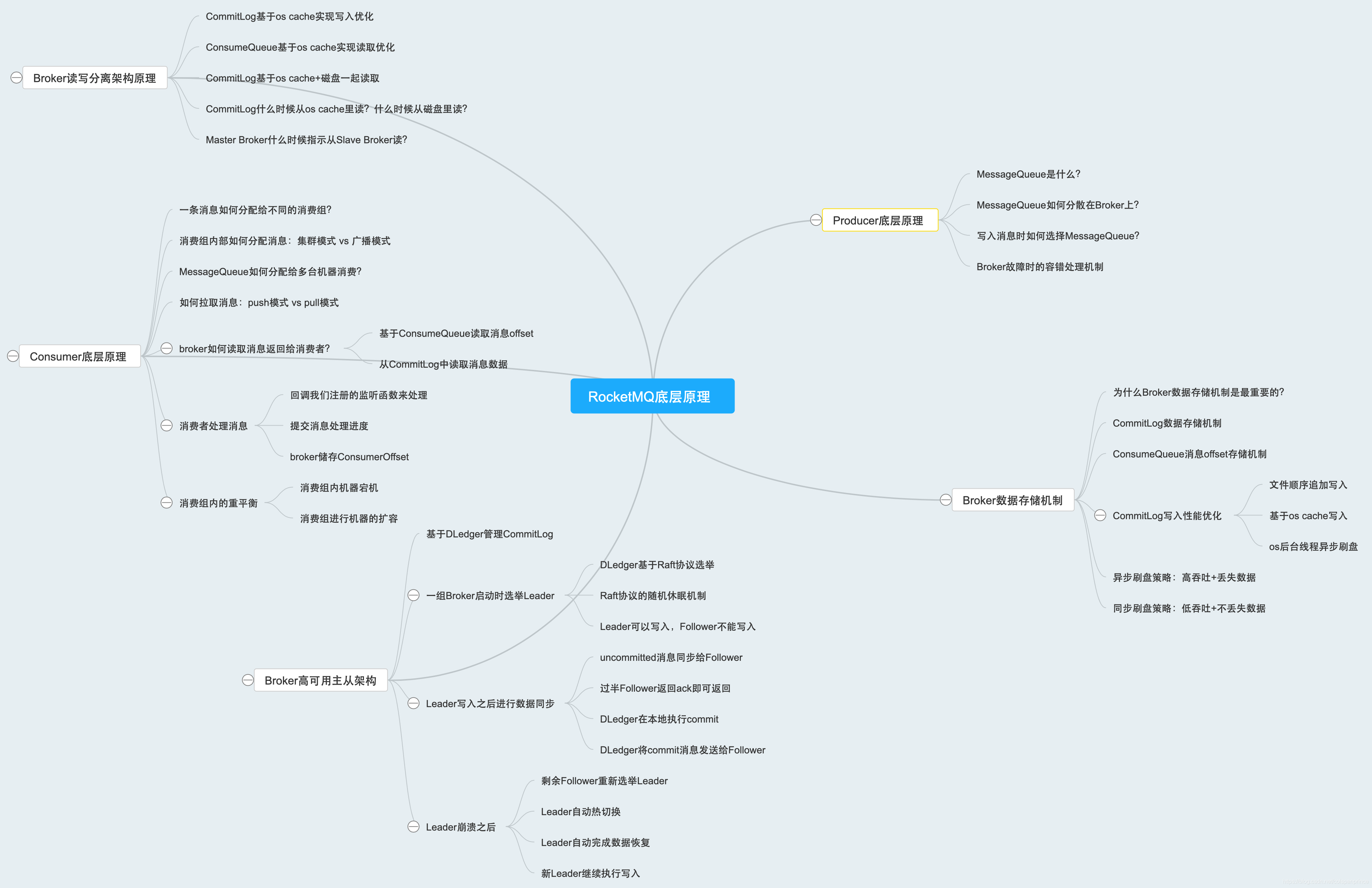
一、第四十九課 生產者是如何發送訊息的
1、Topic、MessageQueue、Broker之間的關系
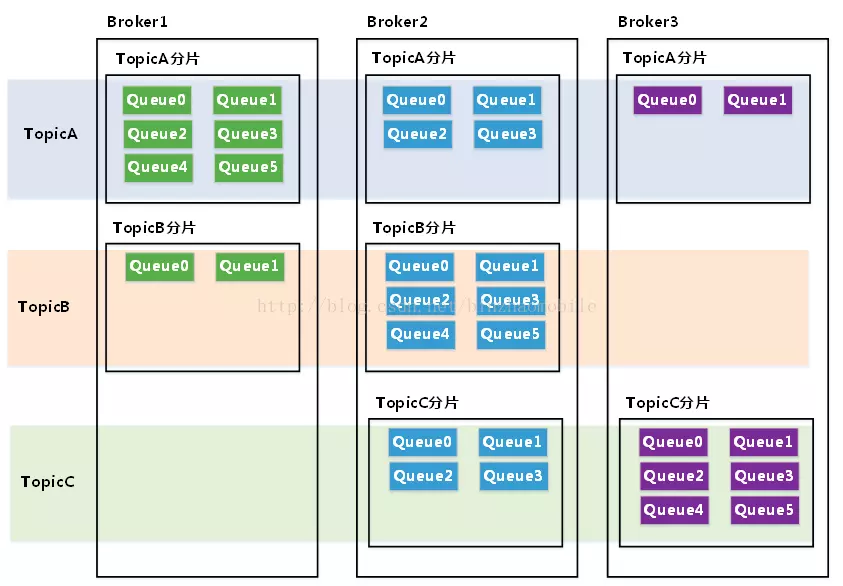
一個Topic可以分布在多個Broker上,所以Topic的資料是分布式存盤在多個Broker機器上的
創建Topic的時候要指定MessageQueue的數量,MessageQueue是非常關鍵的一個資料分片機制,它將Topic的資料拆成了很多個資料分片,然后在每個Broker上存盤了一些MessageQueue,通過這個方法,實作了Topic的分布式存盤
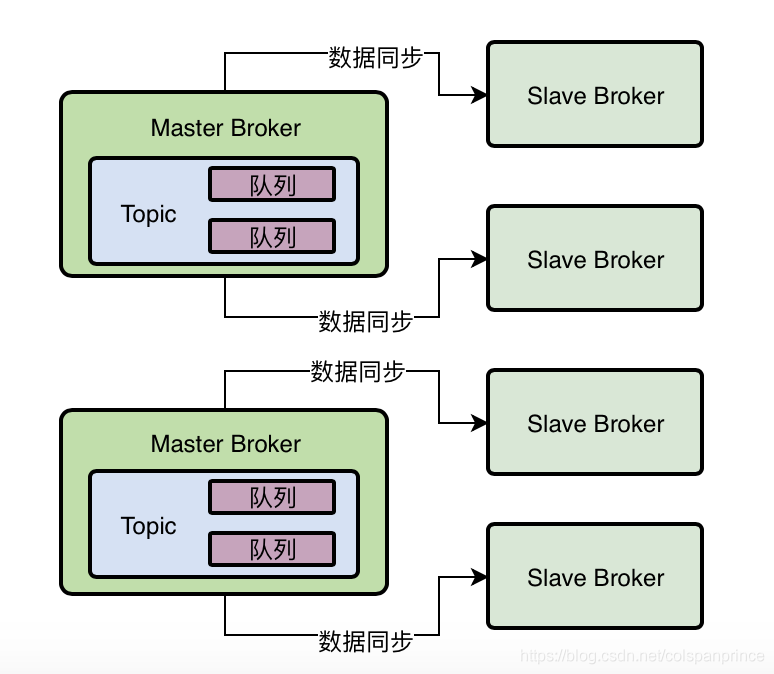
2、生產者寫入
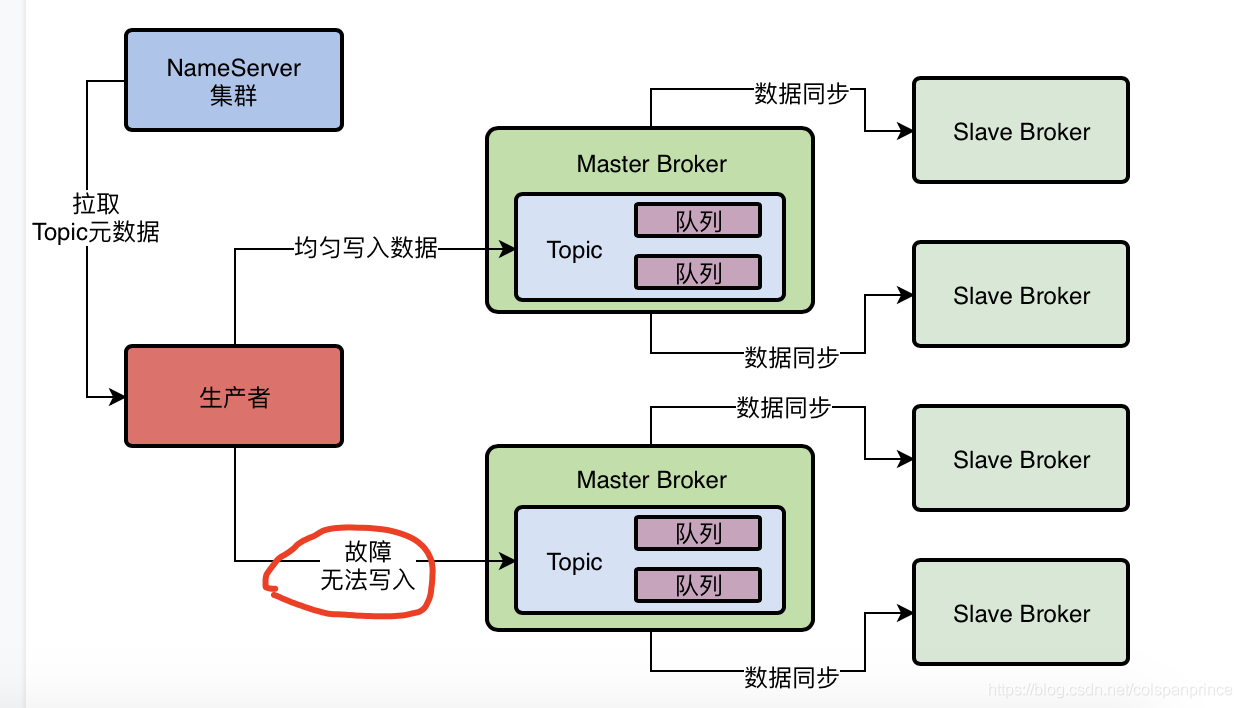
生產者會從NameServer獲取Topic的路由資料,知道一個Topic有幾個MessageQueue,分別在哪個Broker機器上,現在先假定均勻寫入每個MessageQueue,當一個Master Broker掛了,Slave Broker會切換成Master Broker,在切換的程序中,這個Master Broker就會訪問失敗,所以建議在生產者中設定一個開關:sendLatencyFaultEnable,打開這個開關后,它就有容錯機制,比如某次訪問某個Broker時間超過500ms,那么在接下來的一定時間內,就不會再訪問這個Broker,等這段時間過了,Slave Broker已經切換成Master Broker了,那么又能讓生產者訪問了
二、第五十一課 Broker是如何持久化存盤訊息的
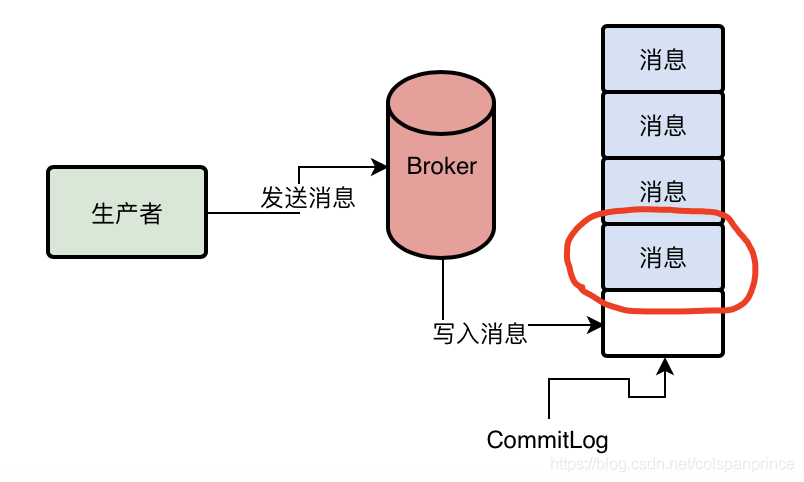
Broker接收到訊息后,順序寫入磁盤上名為CommitLog的日志檔案,這個CommitLog檔案就像LogBack日志檔案一樣,每個檔案最多1G
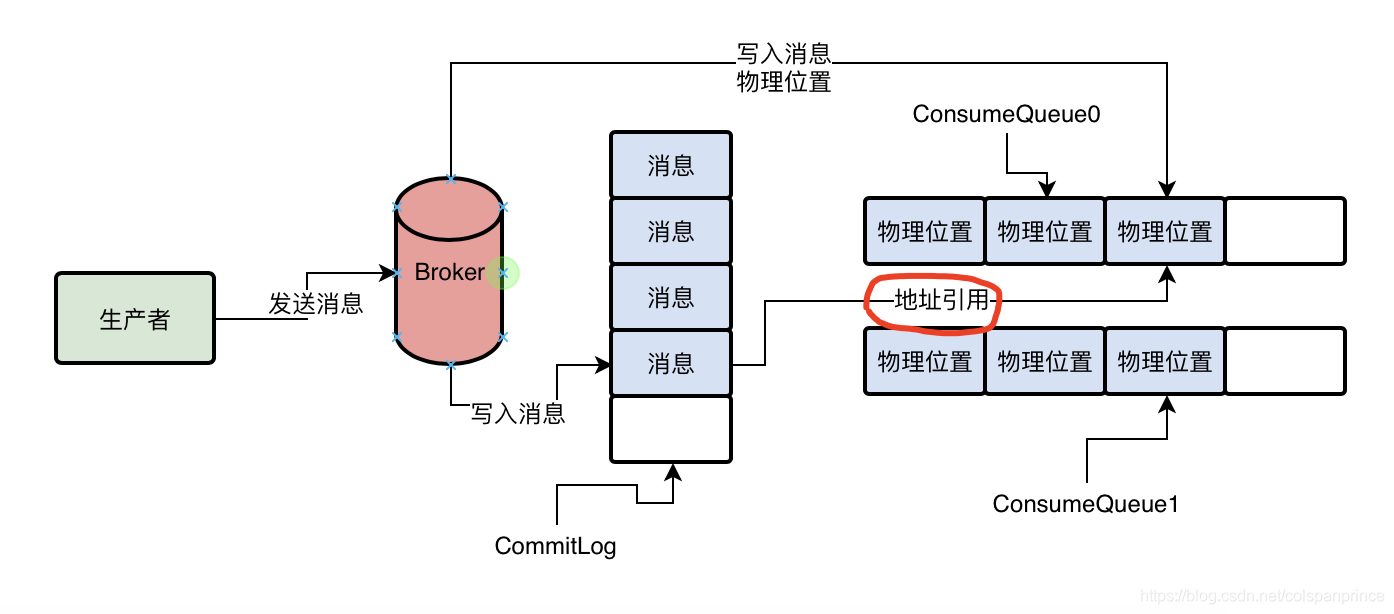
我們之前提過,Topic在這臺Broker機器上會有幾個MessageQueue,而一個MessageQueue,也有很多的ConsumeQueue檔案,存盤目錄是{HOME}/stoe/consumequeue/{topicId}/{queueId}/{fileName}下,這個檔案存盤的是一條資訊對應在CommitLog里的物理地址,即偏移量offset,還包括了訊息長度、tag hashcode,一條資料是20個位元組,每個ConsumeQueue檔案保存30萬條資料,大概是5.72MB
那么寫入CommitLog的速度就直接影響了MQ的性能,所以MQ是基于OS系統的PageCache和順序寫兩個機制,來提升寫入性能的
順序寫就是上面提到的,在CommitLog的尾部追加資料,而PageCache,是在資料寫入CommitLog時,不是直接寫入底層的物理磁盤檔案的,而是先寫入OS的pageCache記憶體快取中,然后后續由OS的后臺執行緒自己找一個時間,異步將OS的pageCache快取中的資料重繪到磁盤檔案中
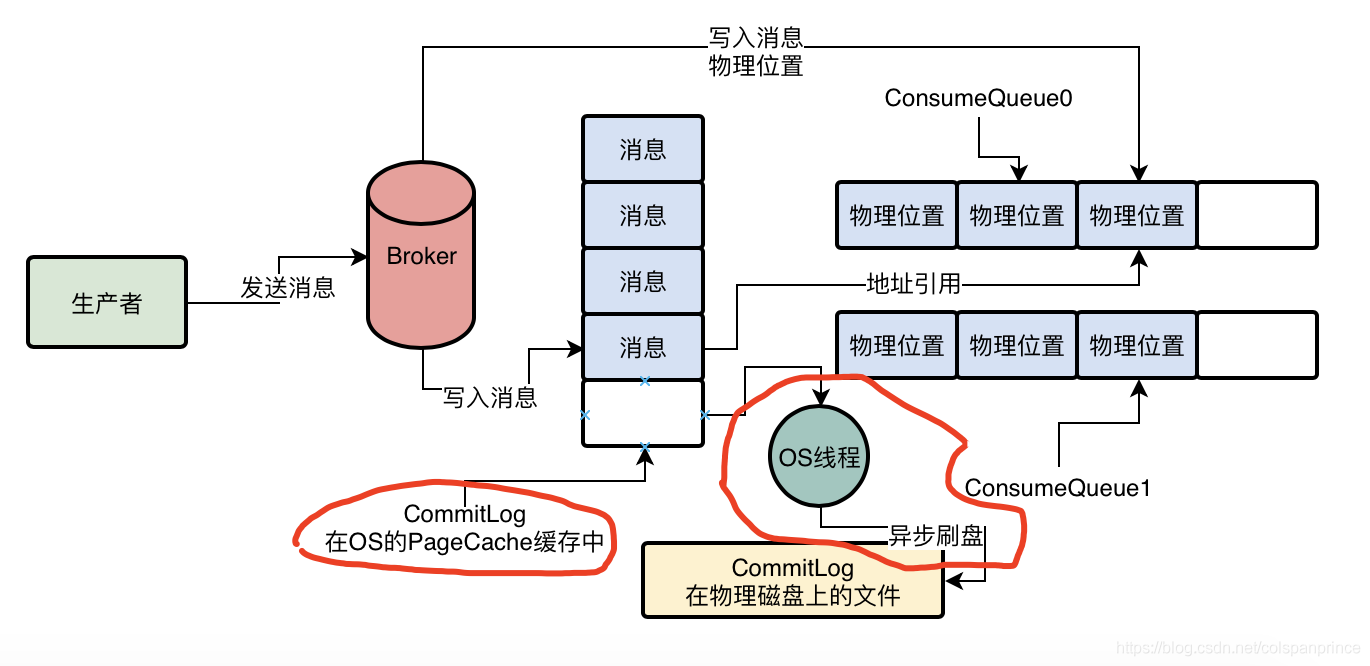
使用PageCache被稱作異步刷盤,因為資料寫入PageCache就被視作寫入成功,當Broker宕機時,這些資料就會消失,因此異步刷盤適合高吞吐量的環境,但存在資料丟失風險,另一種模式被稱作同步刷盤,broker必須把訊息寫入硬碟內,才視作寫入成功
總結: 一個Broker上可以有多個Topic,但都存盤在統一的CommitLog中,一個Topic分布在多個Broker上,一個Topic分片內有多個MessageQueue,一個MessageQueue對應多個ConsumeQueue檔案
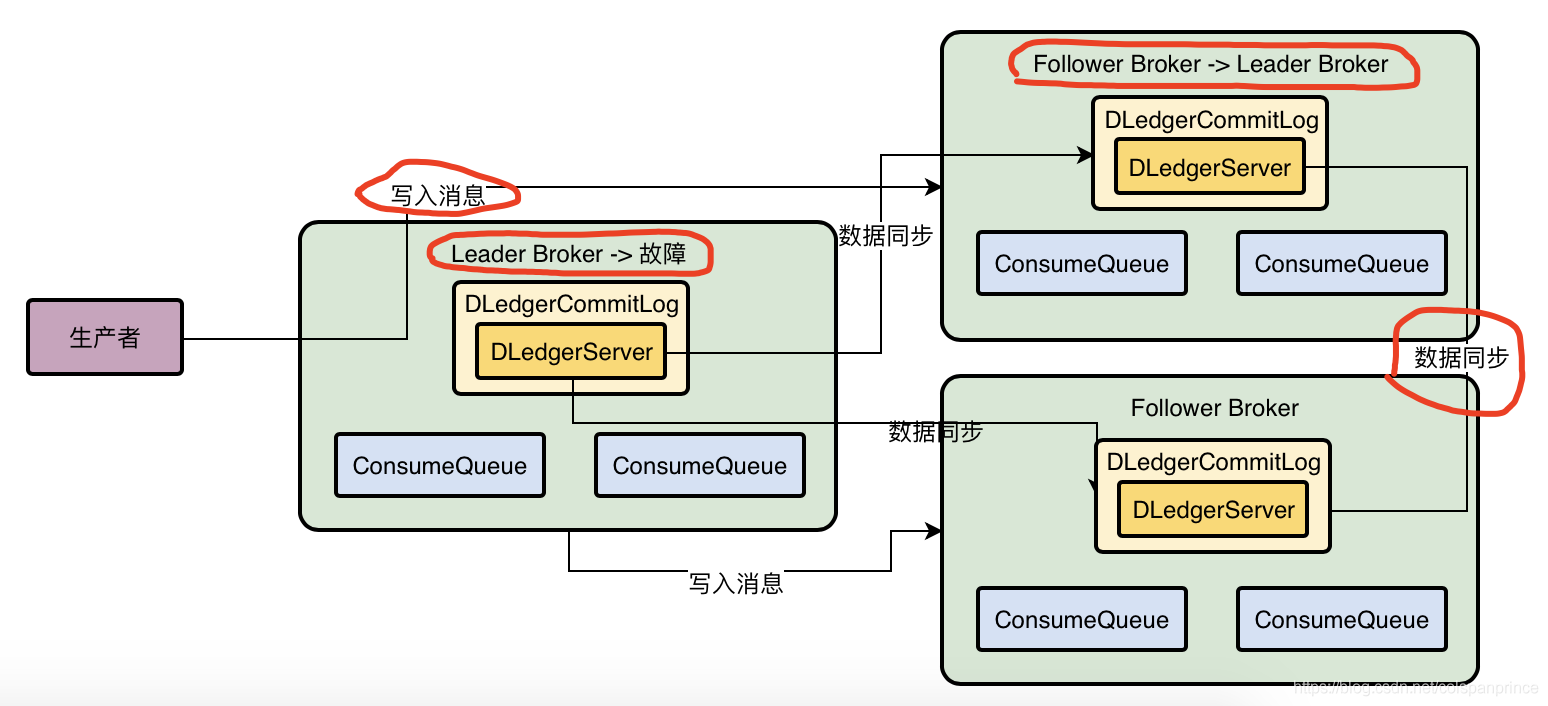
三、第五十三課 基于DLedger技術的Broker主從同步原理到底是什么
在使用DLedger前,RocketMQ的主從Broker模式,如果主Broker掛了,那么只能通過手動方式來進行重啟或切換,而引入DLedger就是為了實作自動切換,DLedger是基于Raft協議的,使用DLedger CommitLog替代了原來的CommitLog
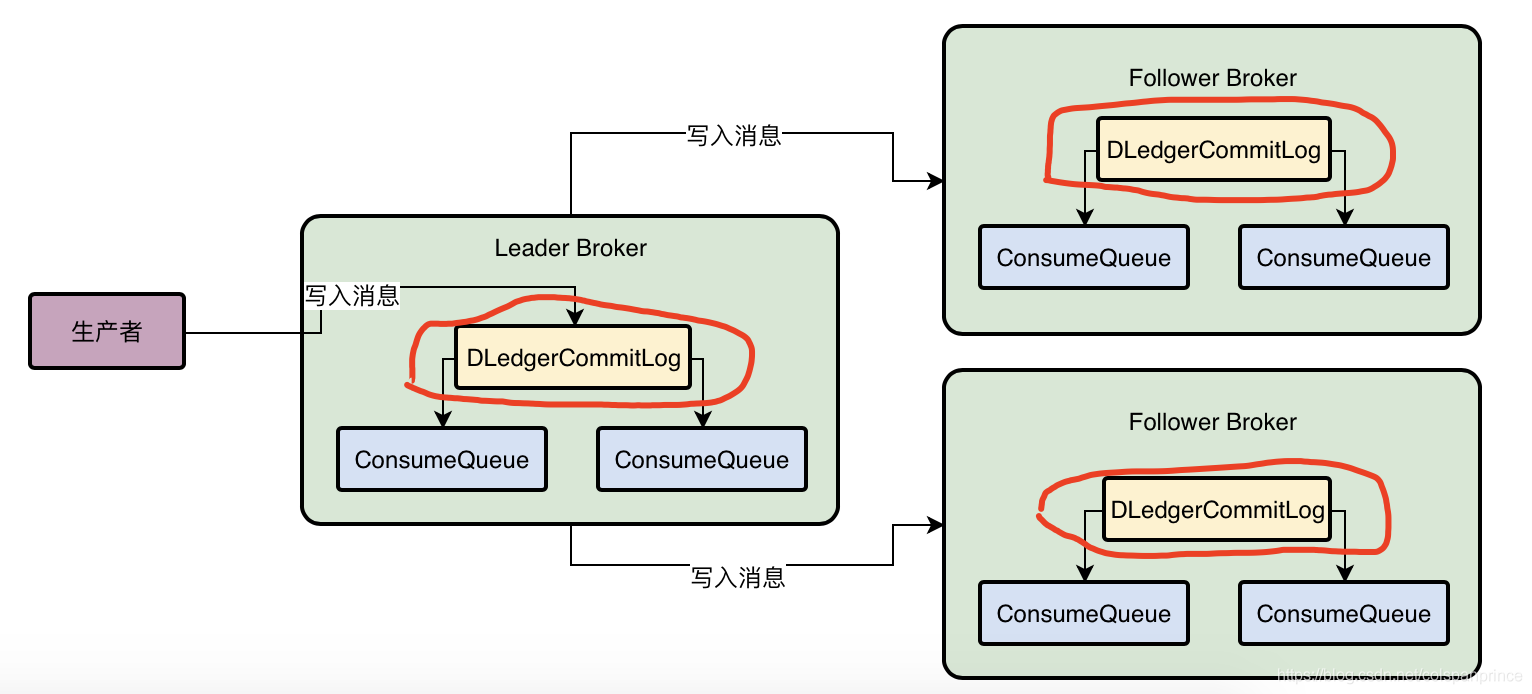
Raft協議的多副本同步機制
簡單來說,資料同步會分為uncommitted階段和committed階段,首先Leader Broker上的DLedger收到一條資料后,會標記為uncommitted狀態,然后它會通過自己的DLedgerServer組件把這個uncommitted資料發送給Follower Broker的DLedgerServer,接著Follower Broker的DLedgerServer收到uncommitted訊息之后,必須回傳一個ack給Leader Broker的DLedgerServer,然后如果Leader Broker收到超過半數的的Follower Broker回傳ack后,就將訊息標記為committed狀態,然后Leader Broker就把committed訊息也發給Follower Broker的DLedgerServer,讓它們也把訊息標記為committed狀態
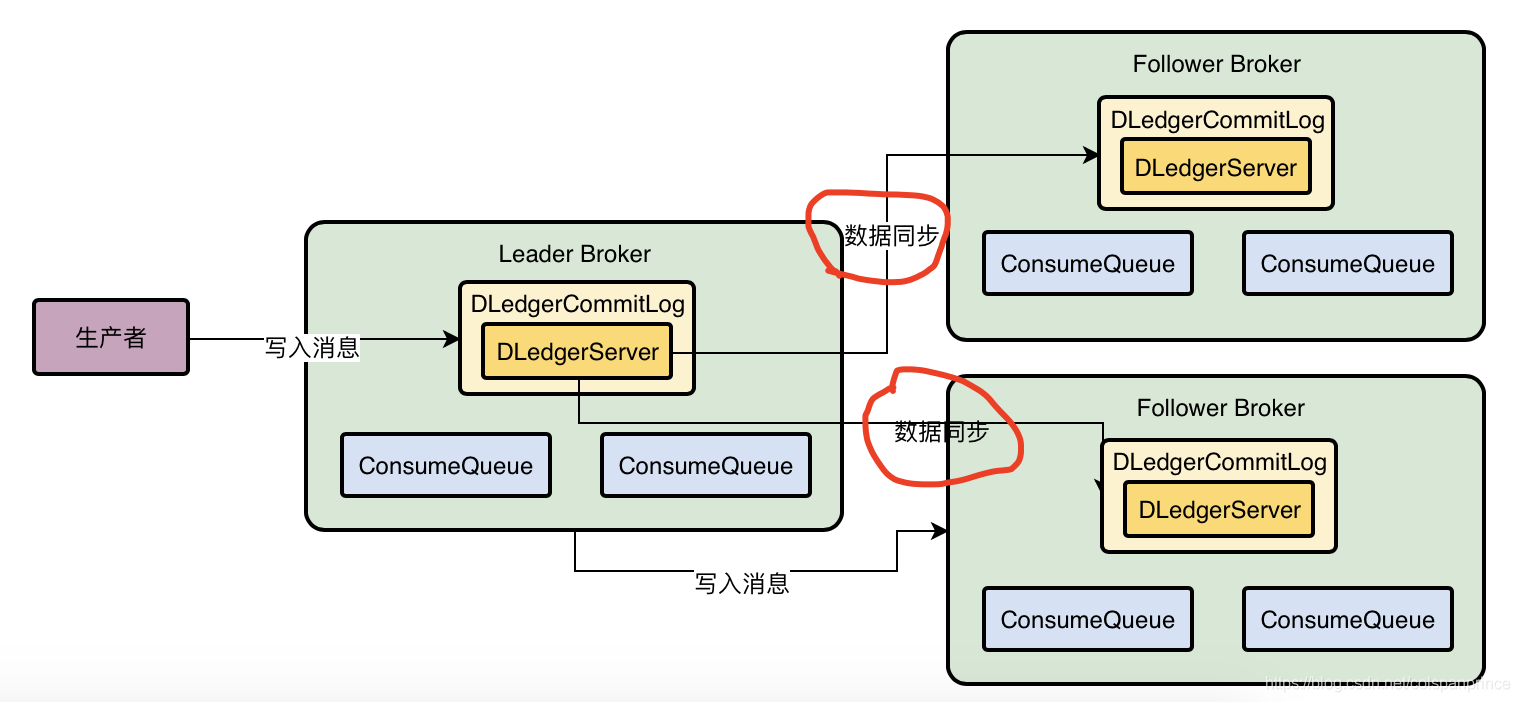
如果Leader Broker掛了,剩下的兩個Follower Broker就會重新選舉出新的Leader Broker,并且會對沒有完成的資料同步進行一些恢復性操作,保證資料不丟失
四、第五十五課 消費者是如何獲取訊息處理以及進行ACK的
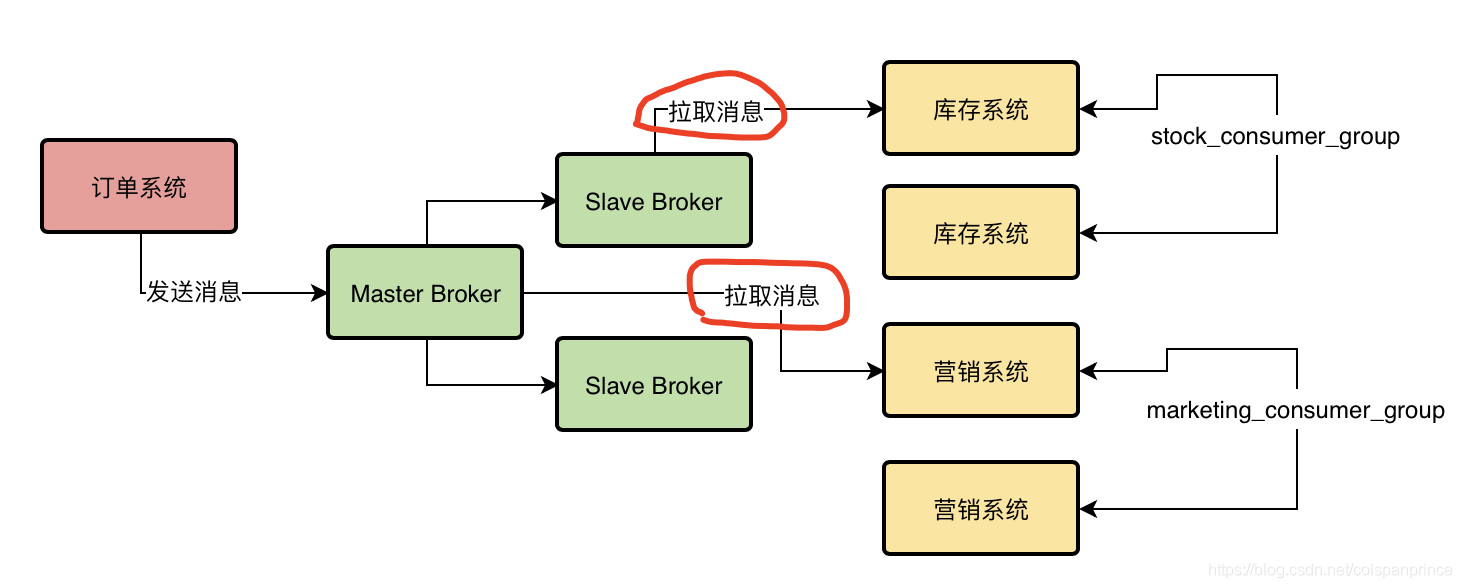
1、消費者組
給一組消費者起一個名字,它們會消費同一個Topic中的內容,
生產者生產一條訊息后,一個消費者組的多臺機器都能消費到這條訊息嗎?在集群模式下,不能,只有其中一臺能消費到,在廣播模式下,都可以消費到,但廣播模式基本不使用,
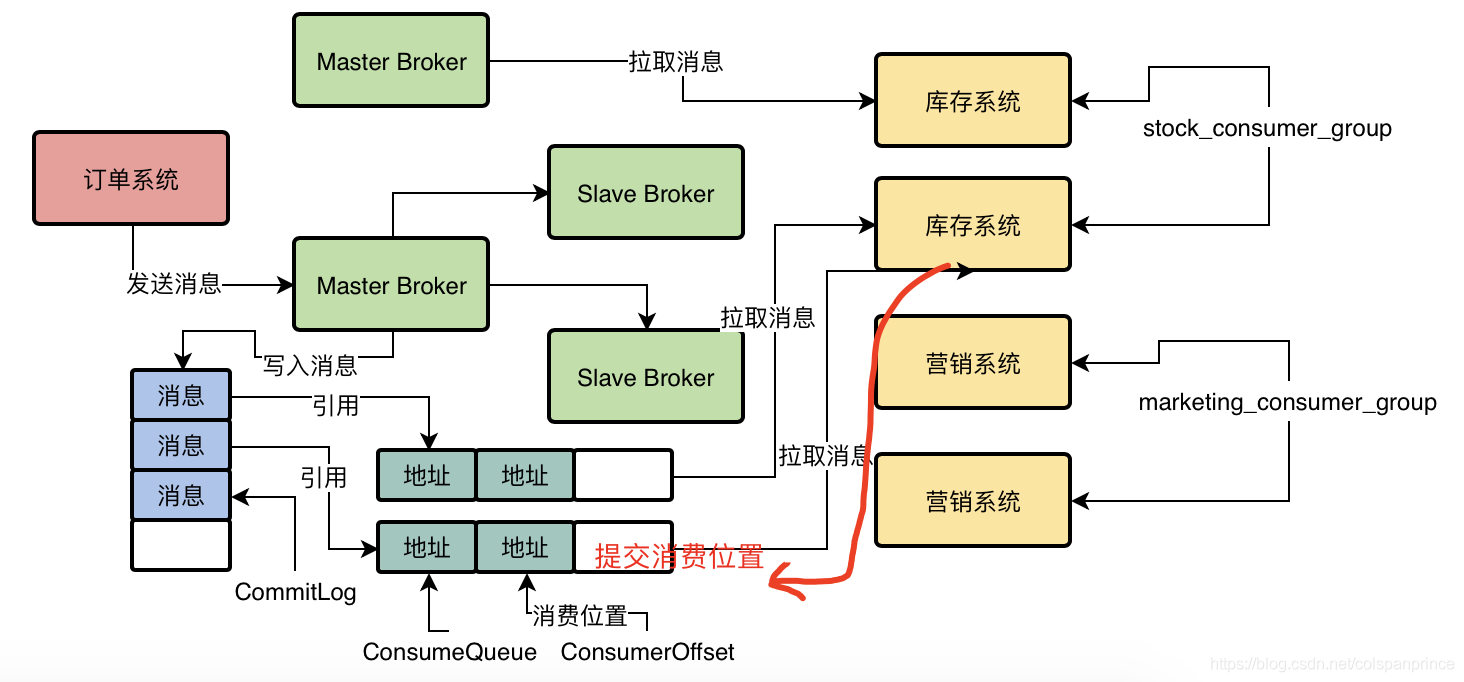
如下圖所示,庫存系統和營銷系統就是2個消費者組,它們訂閱了同一個Topic,所以都可以獲取到這個Topic生產的消費資訊,但各自系統中只有一個機器可以獲取到這條資訊,
2、MessageQueue與消費者的關系
大致理解為,讓一個Topic內的多個MesageQueue均勻分攤給消費者組內的多個機器去消費,基本原則是一個MessageQueue只能有一個消費者機器消費,但一個消費者機器可以消費多個MesageQueue
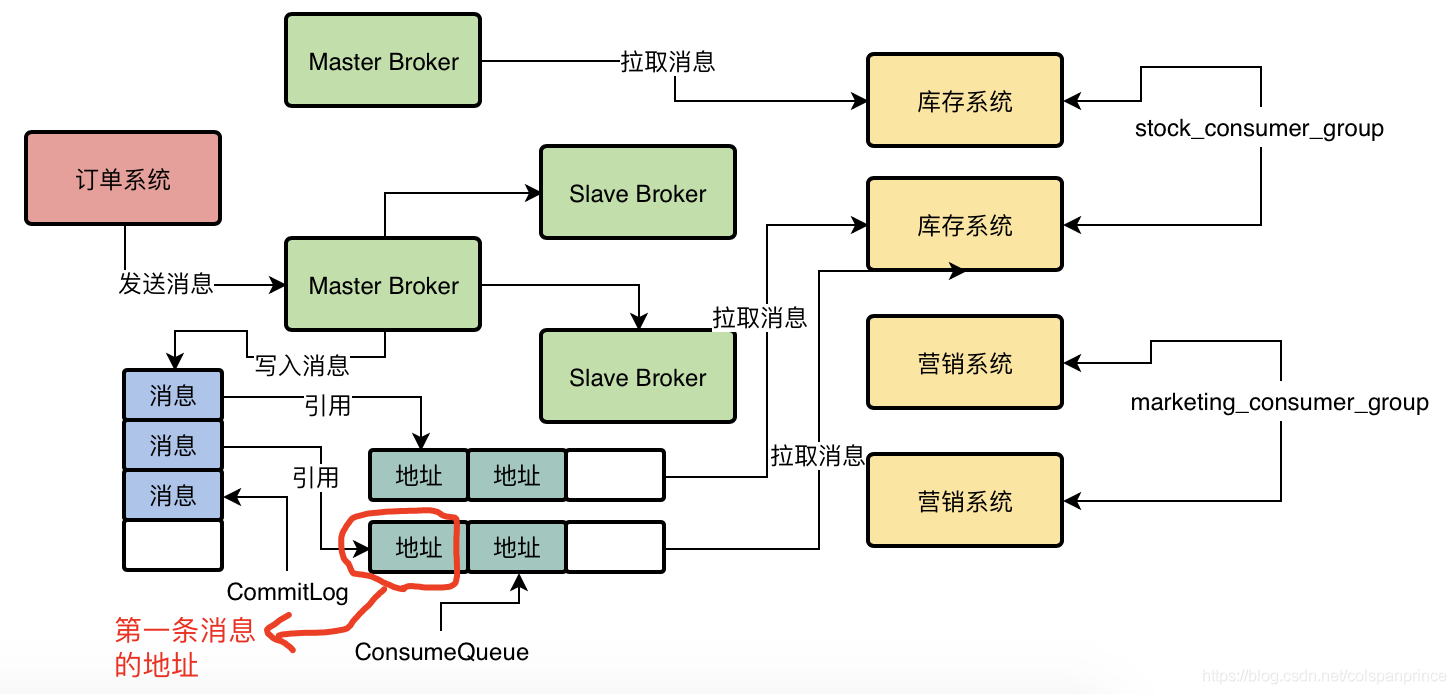
3、Broker是如何將訊息讀取出來給消費者的
假設一臺消費者機器要拉去MessageQueue0的訊息,并且之前從沒拉過,那就從第一條開始拉,于是,Broker找到MessageQueue0對應的ConsumeQueue0,找到第一條訊息的offset,去CommitLog中讀取出來這條資料
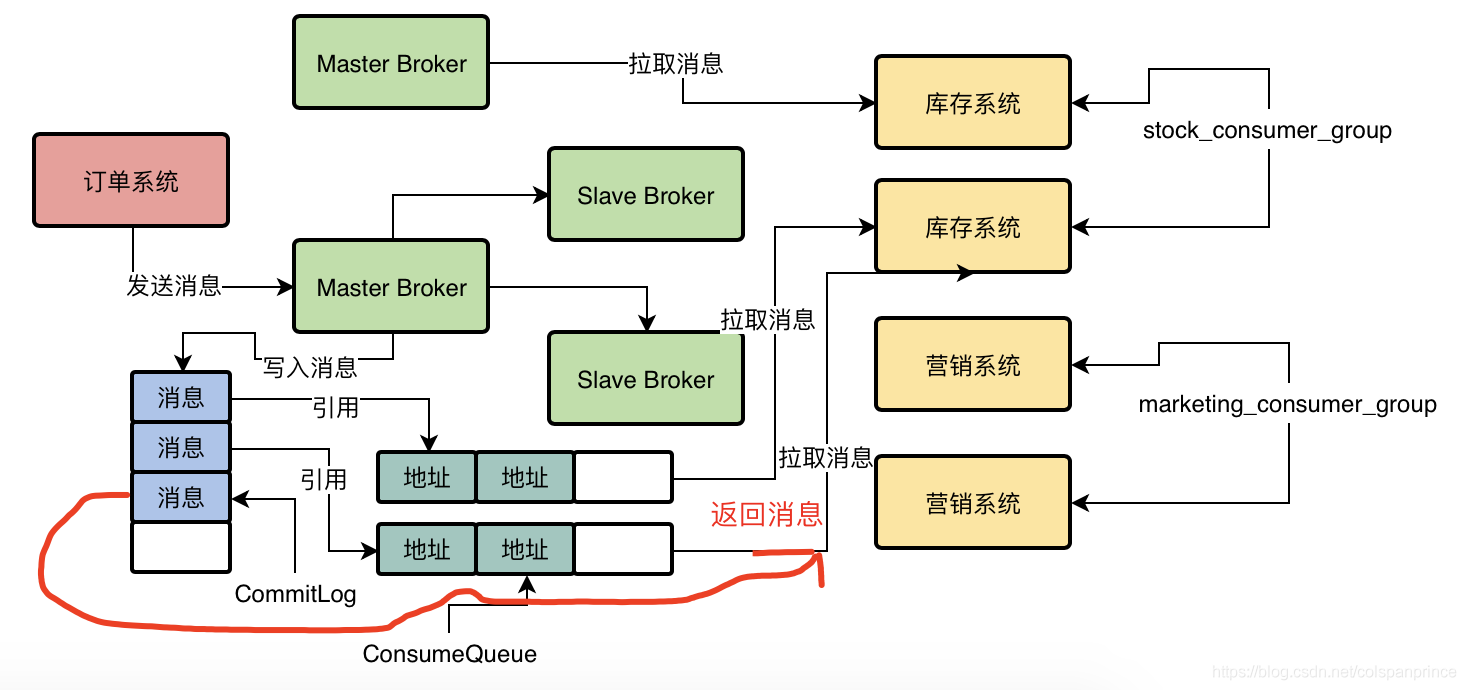
消費者機器獲取到這些訊息后,會呼叫我們的回呼函式,如圖所示,回傳消費狀態為成功
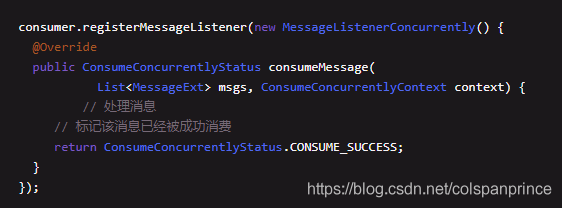
等我們處理完后,消費者機器會提交我們目前的消費進度到Broker機器上,然后Broker會存盤我們的消費進度
4、如果消費者組中有機器宕機了怎么辦
會重新給消費者機器分配它們要處理的MessageQueue
五、第五十七課 消費者是根據什么策略從Master或Slave上拉取訊息的
1、ConsumeQueue檔案也是基于os cache的
ConsumeQueue檔案很小,只有幾MB,所以它們基本都是放在os cache里的,以此保證消費的高性能
2、CommitLog檔案是基于os cache和硬碟一起讀的
CommitLog是先寫入os cache,再由os把cache中比較舊的資料寫入到硬碟,這個程序是不斷持續的,因此,如果讀取的是剛剛寫入的CommitLog資料,那么它們大概率還在os cache中,這樣性能就很快,如果讀的是較早的資料,那么就都在硬碟中的,這樣的效率就會變慢,因此,如果你的消費速度跟上了生產速度,那么基本都是從os cache中取的資料,否則大概率是從磁盤取的,
3、Master Broker什么時候會讓你從Slave Broker拿資料
Master broker會根據自身記憶體的大小,最多可以在os cache存放的資料量,你需要的資料量,來判斷出會不會對自己造成比較大的負擔,從而決定要不要讓你去Slave Broker上拉取資料,
比如你要8萬條資料,但Master Broker的os cache最多存3萬條,有5萬條就要從硬碟上拉取,這樣會影響Master Broker的性能,所以會讓你去Slave Broker上拉,
六、第六十一課 探索黑科技,基于mmap記憶體映射實作磁盤檔案的高性能讀寫
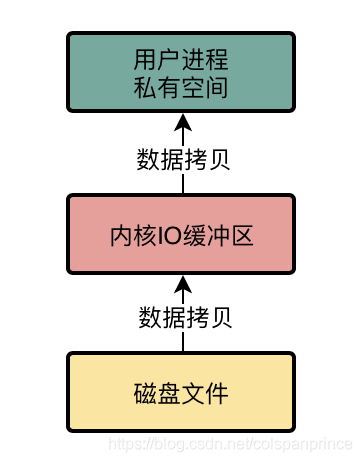
傳統IO方式讀取檔案資料,發生了2次資料拷貝
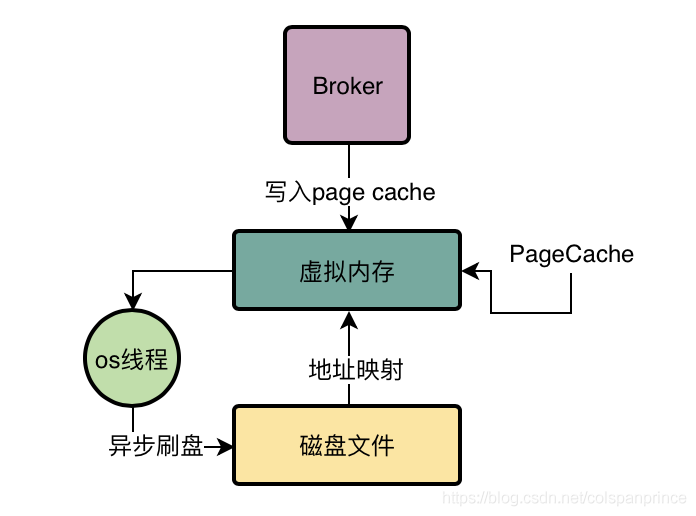
基于mmap+PageCache的讀寫,比如要寫入訊息到CommitLog檔案里,先把一個CommitLog檔案通過MappedByteBuffer的map()函式映射其地址到你的虛擬記憶體地址,然后對這個MappedByteBuffer執行寫入操作,寫入的時候會直接進入PageCache,然后過一段時間,由os的執行緒異步刷入磁盤中,這樣就只有一次拷貝程序,就是從PageCache拷入到磁盤空間而已
預熱映射機制+檔案預熱機制
七、階段性復習

思考題
1、Kafka和RabbitMQ有類似RocketMQ的分片機制嗎,它們是如何實作的?
2、基于Raft協議的主從復制,會對Leader Broker的TPS產生影響嗎?是不是必須所有場景都這么做?
3、消費者是跟少數幾臺Broker建立連接,還是跟所有Broker建立連接?
跟少數Broker建立長連接,只有要消費指定Topic下MessageQueue對應的Broker時,才會建立連接
4、Kafka和RabbitMQ支持主從架構的讀寫分離嗎?支持Slave Broker的讀取嗎?
5、比如資料剛剛到Master Broker,還沒到Slave Broker,導致Master Broker和Slave Broker資料不一致怎么辦?
會存在主從不同步
6、消費處理太慢,會導致你跟不上生產的速度,會導致后續都從硬碟上拉取資料,所以在處理訊息的時候,有什么要注意的?
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/259699.html
標籤:其他
下一篇:桌面客戶端開發框架技術選型