CUDA計算
- 一、GPU硬體架構綜述
- 二、CUDA編程模型
- (1)邏輯層次上的執行流程
- (2)一些基礎CUDA代碼的認知
- 三、GPU記憶體
- 四、在GPU的計算部分如何運作?
- 流程粗略總結
- 五、常見GPU記憶體優化策略
- 1、最大化并行
- 2、極小化CPU與GPU資料傳輸
- 3、極大化使用共享記憶體
- 4、優化記憶體使用模式
- 5、程式注意性能可移植性
注明:由于編者知識有限,很多地方表述難免有欠妥當,僅供參考,這篇文章我會不定時更新
GPU并行計算引擎強大,可以大幅度加快計算速度,特別是稠密矩陣向量計算
一、GPU硬體架構綜述
GPU設備常見5個指標:
1、核心芯片:直接決定了顯卡性能的好壞
2、核心頻率:核心作業頻率,在同級別的芯片中,核心頻率高的則性能要強一些,提高核心頻率就是顯卡超頻的方法之一
3、顯存位寬:顯存在一個時鐘周期內所能傳送資料的位數,以 Bit 為單位
4、顯存頻率:默認情況下,該顯存在顯卡上作業時的頻率,以MHz(兆赫茲)為單位
5、顯存大小:主要是全域記憶體
參考資料:
詳解GPU的常見引數及其對顯卡的重要性
區分 DDR(記憶體)和 GDDR(顯存)
想深入了解記憶體部分的可以看這些文章:
記憶體系列一:快速讀懂記憶體條標簽
記憶體系列二:深入理解硬體原理
記憶體系列三:記憶體初始化淺析
本文GPU示例:費米架構(Fermi)
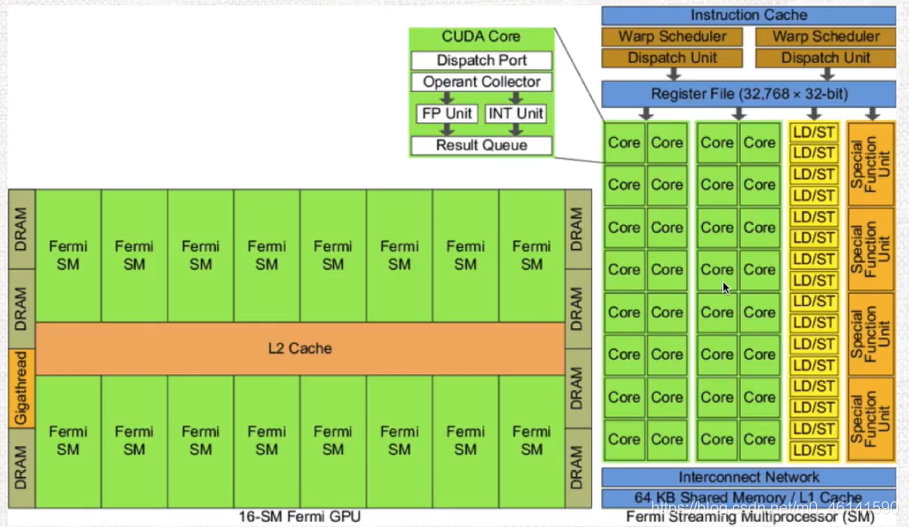
常見專業名詞解釋:
SPA:流處理器陣列(多個SM集合的Array)
TPC/GPC:流多處理器組成的塊
SM:流多處理器( 包含記憶體單元、作業調度單元、流處理器 )
Cache:高速快取(L1/L2/L3),一般不同級別速度不同,按優先級作用也不同
Core(SP): 流處理器,CUDA核心
Warp:執行緒束(基本執行單元)
在SM中重要的組成部分:
Warp Scheduler:執行緒調度器,可以按優先級執行Warp,切換Warp開銷極小
RF:暫存器
SFU:特殊功能單元
Warp:集合固定數目的執行緒(32個)為一個Warp,作為最基本的執行單位,里面的執行緒執行相同的命令
所以該架構組成:16個SM + L2 Cache,其中每個SM有30個CUDA核心通過L1 Cache互聯
參考資料:CUDA中grid、block、thread、warp與SM、SP的關系
你現在能看懂這副圖了嗎?

二、CUDA編程模型
GPU需要與CPU協同作業,所以GPU并行計算是指基于CPU+GPU的異構計算架構,它倆通過如圖所示的 PCI總線 連接在一起,CPU部分稱為 主機端(Host) ,GPU部分稱為 設備端(Device)

由于 CPU背景關系切換開銷大(行程或執行緒切換),適合控制密集型任務,比如復雜的邏輯運算,
所以推薦使用CPU+GPU的異構計算平臺,CPU負責邏輯復雜的串行程式,GPU負責資料密集型的并行計算程式
CUDA就是這樣一個模型,既包含Host程式,又包含Device程式

(1)邏輯層次上的執行流程
Host端向Device端串行通訊,讓Device端執行指定的核函式
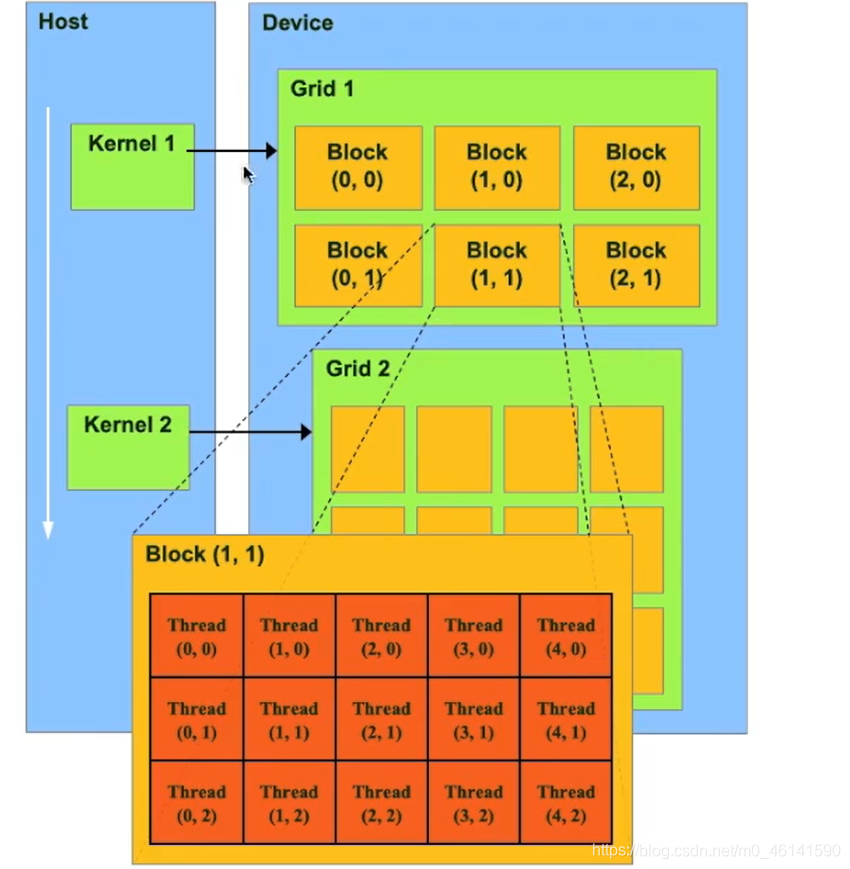
在Device端,執行一個核函式(kernel)會啟動很多thread,這些thread稱為一個網格(grid),同一個grid上thread共享相同的local Cache,同時grid可以分為很多執行緒塊(block),一個block包含很多thread,一般每32個thread一組稱為執行緒束(warp),
注意!warp才是執行計算的基本單位!
參考資料:對核函式(kernel)最通俗易懂的理解
(2)一些基礎CUDA代碼的認知
我們需要提前設定好核函式所需要的資源
下圖是配置CUDA核函式計算的相關代碼

grid 和 block 都是 dim3 型別的變數,包含維度資訊,不同GPU架構下,維度會有所限制,
由于單個 SM 的資源有限,所以 block 中執行緒數有限,不易太多,目前強的設備可達1024個,

三、GPU記憶體
與 CPU 設計的三級快取( L1\L2\L3 Cache )類似,根據讀寫的頻率設立不同的記憶體分級,GPU是這樣做的:
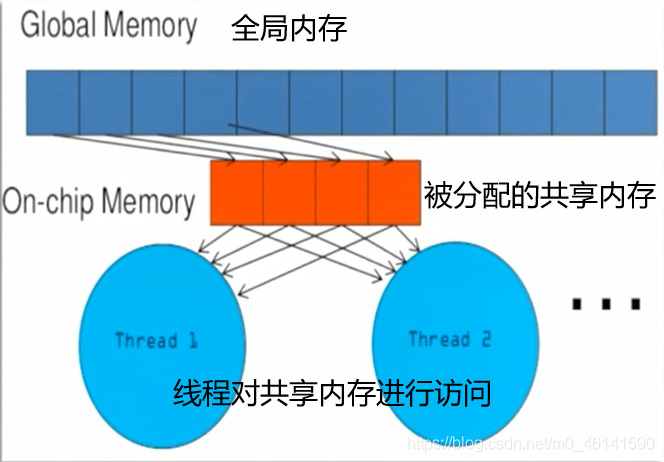
執行緒從全域記憶體讀資料到共享記憶體,共享記憶體生命周期與執行緒相同,在結束時才放回結果到全域記憶體,這樣可以大大提升訪問效率
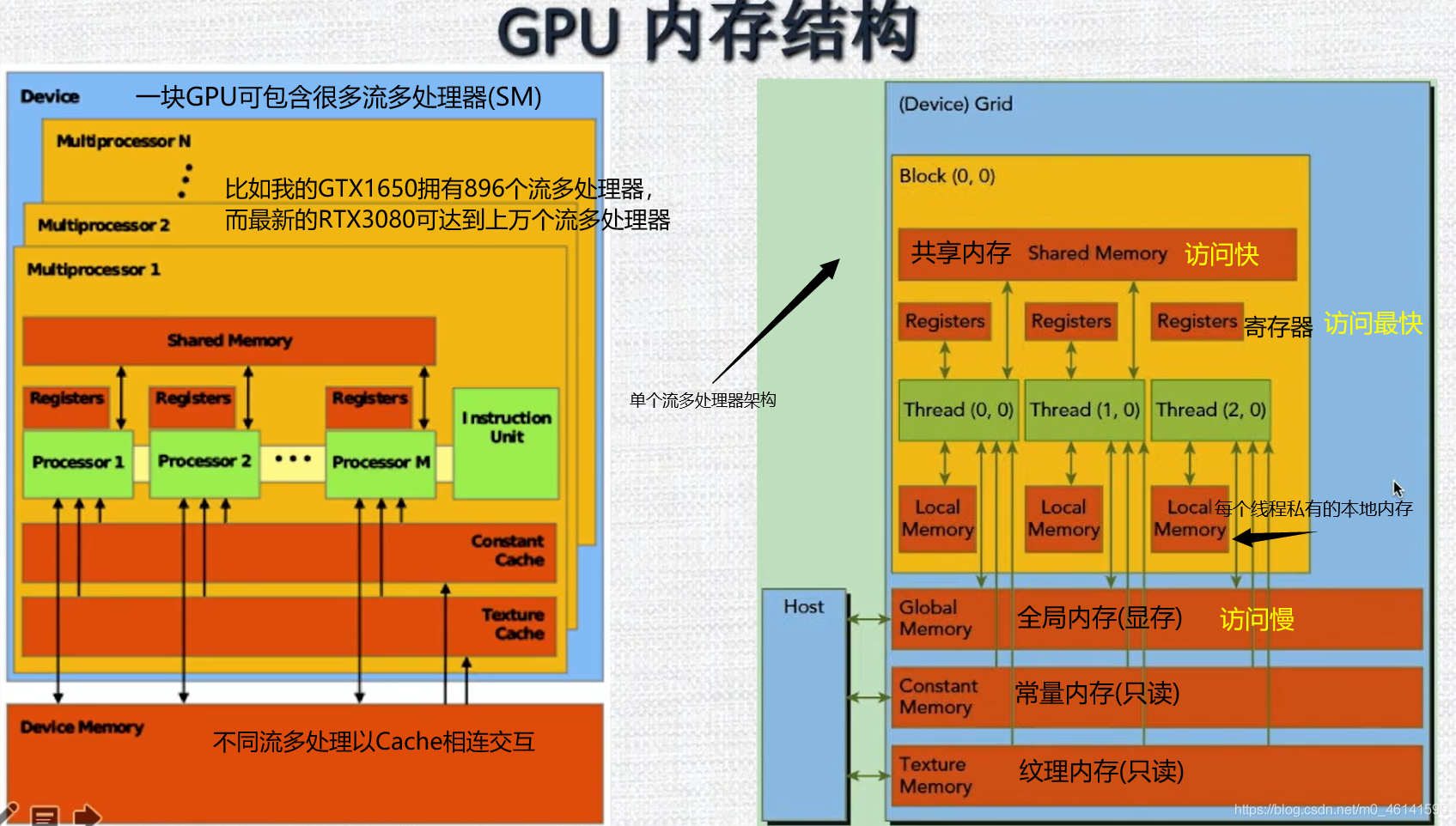
CUDA程式架構以及硬體映射
一個block只會由一個SM調度,block一旦被分配好SM,該block就會一直駐留在該SM中,直到執行結束,一個SM可以同時擁有多個block,
下圖顯示了 軟體邏輯層次 和 硬體層次 都是類似于這種三級結構:
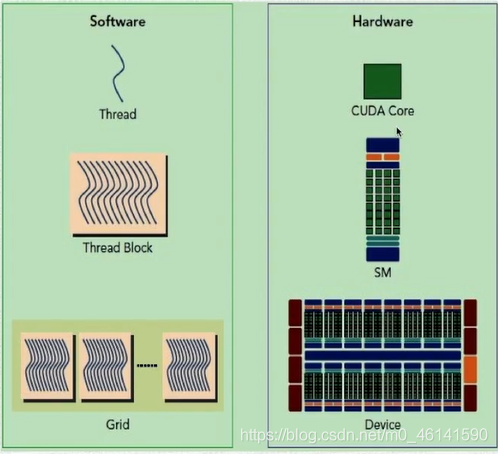
四、在GPU的計算部分如何運作?
當需要執行一個kernel時,會自動形成grid,其中的thread block會被分配到SM上,一個thread block只能在一個SM上被調度,SM中的warp調度器會調度thread block中的執行緒成束使用(一般是32個Thread),于此,SM可以并發地執行數百個執行緒,并發能力取決于SM所擁有的資源數
流程粗略總結
1、執行kernel,形成grid
2、調度、分配資源 (thread block分配到SM,等待warp scheduler 調度,SM準備資源)
3、形成warp (thread block中的執行緒以32個為一組被成束使用)
4、并發執行
需要注意的:
1、可能一個kernel的各個執行緒塊被分配到各個SM,所以grid只是邏輯層,SM才是真正執行的物理層
2、GPU規定warp中所有執行緒在同一周期執行相同的執行,warp分化會導致性能下降
3、保證每個warp執行命令相同(避免分支流向),記憶體和執行緒對齊,不要并發太多的執行緒束避免對SM資源的浪費
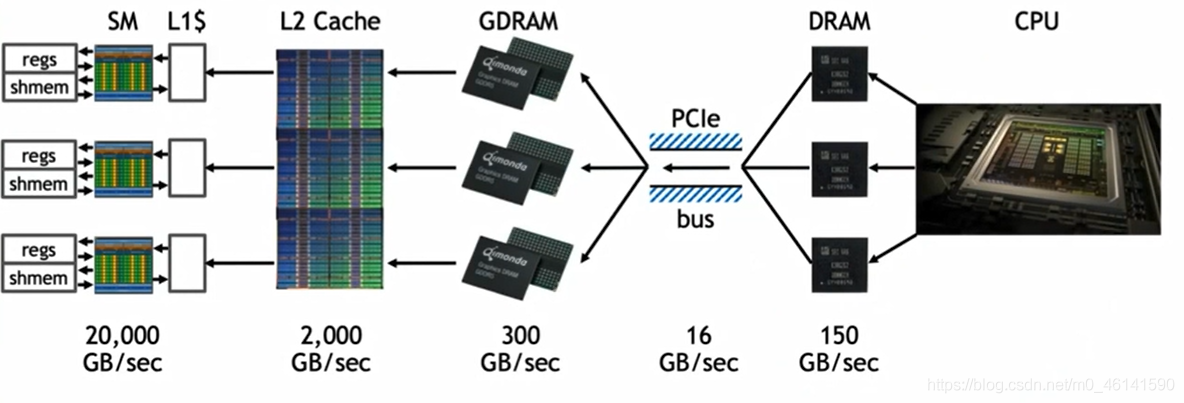
五、常見GPU記憶體優化策略
數量級 : 10G/s
GPU記憶體訪問帶寬,可達到3~4個數量級
瓶頸位于PCI總線,可能只有1個數量級
CPU記憶體訪問帶寬大概在2~3個數量級
1、最大化并行
演算法設計并行性多一些而不是串型
2、極小化CPU與GPU資料傳輸
降低CPU和GPU的記憶體傳輸,使用盡可能少的通訊次數
3、極大化使用共享記憶體
盡可能使用共享記憶體而不是全域記憶體
重點!GPU規約演算法
4、優化記憶體使用模式
全域記憶體:最好對齊訪問,在特定條件下做合并訪問
共享記憶體:避免bank資料的沖突
5、程式注意性能可移植性
盡量使用更多的計算而不是記憶體訪問,同時也可以保證在更強的GPU上運行程式性能的移植
對于多屏操作,建議顯示與純計算功能分到不同顯卡上運行,即便顯示所需要的資源很小
最后參考一段問答:
所以建議第一步是明確在硬體層面是否能盡可能最大化利用GPU資源了,再考慮計算性能的優化
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/259706.html
標籤:其他
上一篇:Spring簡單概述及介紹
下一篇:從零部署halo博客