馬蜂窩技術原創內容,更多干貨請訂閱公眾號:mfwtech
廣告是互聯網變現的重要手段之一,
以馬蜂窩旅游 App 為例,當用戶打開我們的應用時,有可能會在首屏或是資訊流、商品串列中看到推送的廣告,如果剛好對廣告內容感興趣,用戶就可能會點擊廣告了解更多資訊,進而完成這條廣告希望完成的后續操作,如下載廣告推薦的 App 等,
廣告監測平臺的任務就是持續、準確地收集用戶在瀏覽和點擊廣告這些事件中攜帶的資訊,包括來源、時間、設備、位置資訊等,并進行處理和分析,來為廣告主提供付費結算以及評估廣告投放效果的依據,
因此,一個可靠、準確的監測服務非常重要,為了更好地保障平臺和廣告主雙方的權益,以及為提升馬蜂窩旅游網的廣告服務效果提供支撐,我們也在不斷地探索適合的解決方案,加強廣告監測服務的能力,
Part.1 初期形態
初期我們的廣告監測并沒有形成完整的服務對外開放,因此實作方式及提供的能力也比較簡單,主要分為兩部分:一是基于客戶端打點,針對事件進行上報;另一部分是針對曝光、點擊鏈接做轉碼存檔,當請求到來后決議跳轉,
但是很快,這種方式的弊端就暴露出來,主要體現在以下幾個方面:
-
收數的準確性:資料轉發需要訪問中間件才能完成,增加了多段丟包的機率,在和第三方監測服務進行對比驗證時,Gap 差異較大;
-
資料的處理能力:收集的資料來自于各個業務系統,缺乏統一的資料標準,資料的多種屬性導致決議起來很復雜,增加了綜合資料二次利用的難度;
-
突發流量:當流量瞬時升高,就會遇到 Redis 記憶體消耗高、服務掉線頻繁的問題;
-
部署復雜:隨著不同設備、不同廣告位的變更,打點趨于復雜,甚至可能會覆寫不到;
-
開發效率:初期的廣告監測功能單一,例如對實時性條件的計算查詢等都需要額外開發,非常影響效率,
Part.2 基于 OpenResty 的架構實作
在這樣的背景下,我們打造了馬蜂窩廣告資料監測平臺 ADMonitor,希望逐步將其實作成一個穩定、可靠、高可用的廣告監測服務,
2.1 設計思路
為了解決老系統中的各種問題,我們引入了新的監測流程,主體流程設計為:
-
在新的監測服務 (ADMonitor) 上生成關于每種廣告獨有的監測鏈接,同時附在原有的客戶鏈接上;
-
所有從服務端下發的曝光鏈接和點擊鏈接并行依賴 ADMonitor 提供的服務;
-
客戶端針對曝光行為進行并行請求,點擊行為會優先跳轉到 ADMonitor,由 ADMonitor 來做二段跳轉,

通過以上方式,使監測服務完全依賴 ADMonitor,極大地增加了監測部署的靈活性及整體服務的性能;同時為了進一步驗證資料的準確性,我們保留了打點的方式進行對比,
2.2 技術選型
為了使上述流程落地,廣告監測的流量入口必須要具備高可用、高并發的能力,盡量減少非必要的網路請求,考慮到內部多個系統都需要流量,為了降低系統對接的人力成本,以及避免由于系統迭代對線上服務造成干擾,我們首先要做的就是把流量網關獨立出來,
關于 C10K 編程相關的技術業內有很多解決方案,比如 OpenResty、JavaNetty、Golang、NodeJS 等,它們共同的特點是使用一個行程或執行緒可以同時處理多個請求,基于執行緒池、基于多協程、基于事件驅動+回呼、實作 I/O 非阻塞,
我們最終選擇基于 OpenResty 構建廣告監測平臺,主要是對以下方面的考慮:
第一,OpenResty 作業在網路的 7 層之上,依托于比 HAProxy 更為強大和靈活的正則規則,可以針對 HTTP 應用的域名、目錄結構做一些分流、轉發的策略,既能做負載又能做反向代理;
第二,OpenResty 具有 Lua協程+Nginx 事件驅動的「事件回圈回呼機制」,也就是 Openresty 的核心 Cosoket,對遠程后端諸如 MySQL、Memcached、Redis 等都可以實作同步寫代碼的方式實作非阻塞 I/O;
第三,依托于 LuaJit,即時編譯器會將頻繁執行的代碼編譯成機器碼快取起來,當下次呼叫時將直接執行機器碼,相比原生逐條執行虛擬機指令效率更高,而對于那些只執行一次的代碼仍然可以逐條執行,
2.3 架構實作
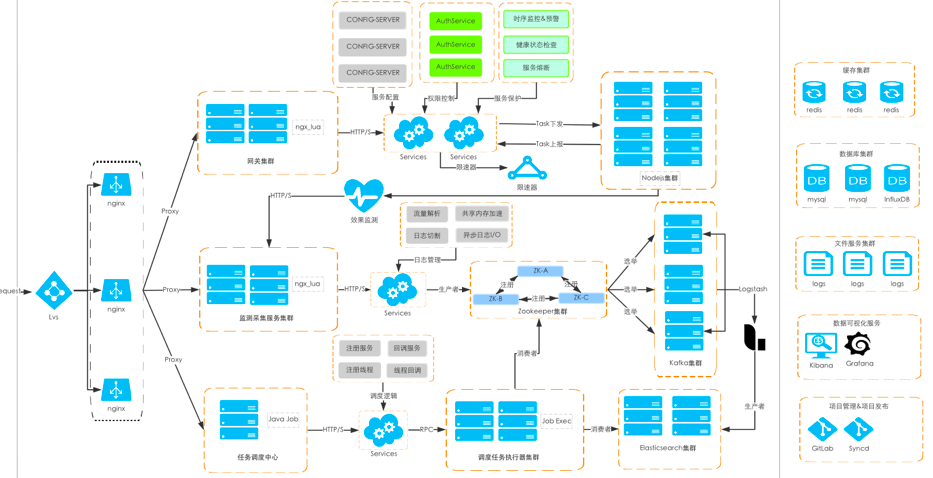
整體方案依托于 OpenResty 的處理機制,在服務器內部進行定制開發,主要劃分為資料收集、資料處理與資料歸檔三大部分,實作異步拆分請求與 I/O 通信,整體結構示意圖如下:
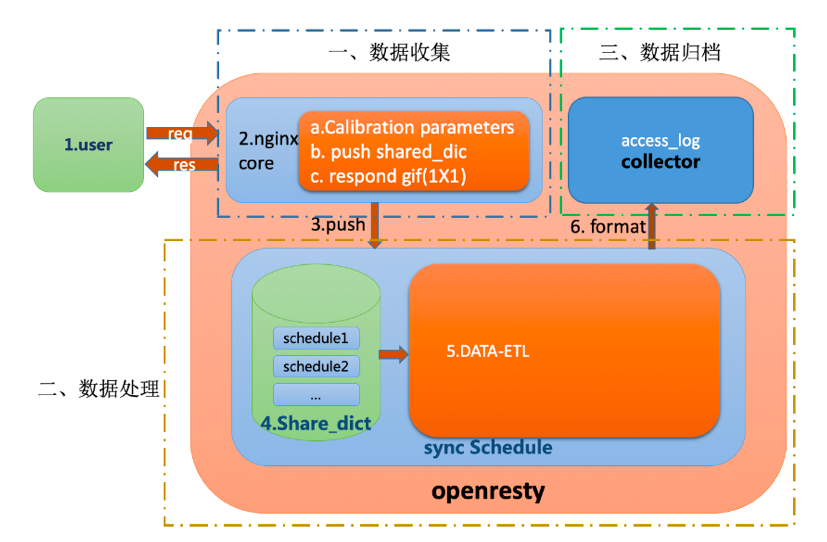
我們將多 Woker 日志資訊以雙端佇列的方式存入 Master 共享記憶體,開啟 Worker 的 Timer 毫秒級定時器,離線決議流量,
2.3.1 資料收集
收集部分也是主體承受流量壓力最大的部分,我們使用 Lua 來做整體檢參、過濾與推送,由于在我們的場景中,資料收集部分不需要考慮時序或對資料進行聚合處理,因此核心的推送介質選擇 Lua 共享記憶體即可,以 I/O 請求來代替訪問其他中間件所需要的網路服務,從而減少網路請求,滿足即時性的要求,如下所示:
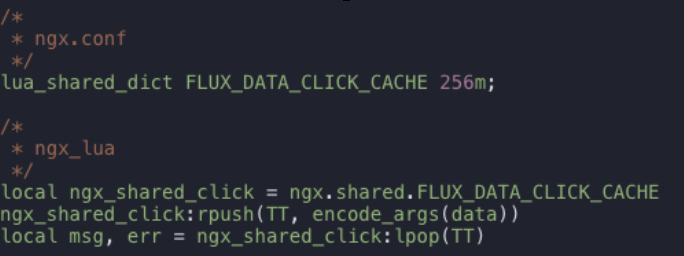
下面結合 OpenResty 配置,介紹一些我們對服務器節點進行的優化:
-
設定 lua 快取-lua_code_cache:
(1)開啟后會將 Lua 檔案快取到記憶體中,加速訪問,但修改 Lua 代碼需要 reload
(2)盡量避免全域變數的產生
(3)關閉后會依賴 Woker 行程中生成自己新的 LVM
-
設定 Resolver 對于網路請求、好的 DNS 節點或者自建的 DNS 節點在網路請求很高的情況下會很有幫助:
(1)增加公司的 DNS 服務節點與補償的公網節點
(2)使用 shared 來減少 Worker 查詢次數
-
設定 epoll (multi_accept/accept_mutex/worker_connections):
(1)設定 I/O 模型、防止驚群
(2)避免服務節點浪費資源做無用處理而影響整體流轉等
-
設定 keepalive:
(1)包含鏈接時長與請求上限等
配置優化一方面是要符合當前請求場景,另一方面要配合 Lua 發揮更好的性能,設定 Nginx 服務器引數基礎是根據不同作業系統環境進行調優,比如 Linux 中一切皆檔案、調整檔案打開數、設定 TCP Buckets、設定 TIME_WAIT 等,
2.3.2 資料處理
這部分流程是將收集到的資料先通過 ETL,之后創建內部的日志 location,結合 Lua 自定義 log_format,利用 Nginx 子請求特性離線完成資料落盤,同時保證資料延遲時長在毫秒級,
對被決議的資料處理要進行兩部分作業,一部分是 ETL,另一部分是 Count,
(1)ETL
![]()
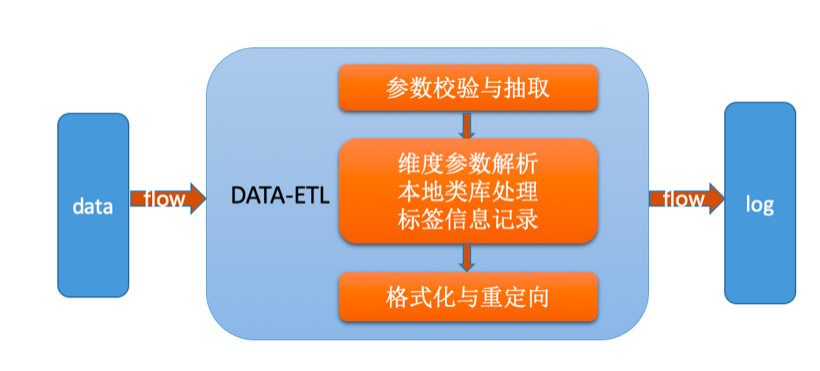
主要流程:
-
日志經過統一格式化之后,抽取包含實際意義引數部分進行資料決議
-
將抽取后的資料進行過濾,針對整體字符集、IP、設備、UA、相關標簽資訊等進行處理
-
將轉化后的資料進行重加載與日志重定向
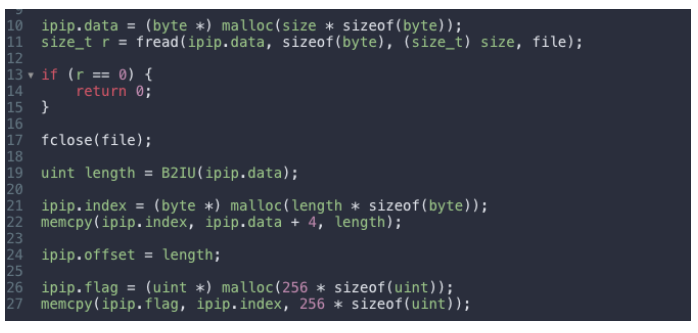
【例】Lua 利用 FFI 通過 IP 庫決議 "ip!"用 C 把 IP 庫拷貝到記憶體中,Lua 進行毫秒級查詢:
(2)Count
對于廣告資料來說,絕大部分業務需求都來自于資料統計,這里直接使用 Redis+FluxDB 存盤資料,以有下幾個關鍵的技術點:
-
RDS 結合 Lua 設定鏈接時間,配置鏈接池來增加鏈接復用
-
RDS 集群服務實作去中心化,分散節點壓力,增加 AOF與延時入庫保證可靠
-
FluxDB 保證資料日志時序性可查,聚合統計與實時報表表現較優
2.3.3 資料歸檔
資料歸檔需要對全量資料入表,這個程序中會涉及到對一些無效資料進行過濾處理,這里整體接入了公司的大資料體系,流程上分為在線處理和離線處理兩部分,能夠對資料回溯,使用的解決方案是在線 Flink、離線 Hive,其中需要關注:
-
ES 的索引與資料定期維護
-
Kafka 的消費情況
-
對于發生故障的機器使用自動腳本重啟與報警等
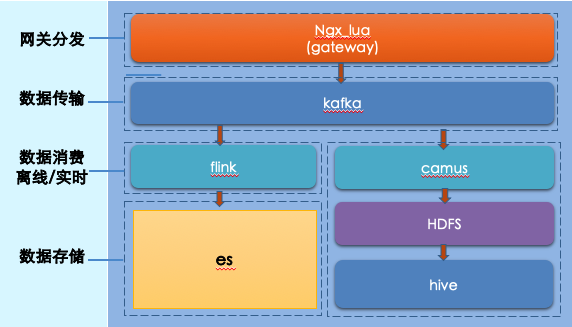
實時資料源:資料采集服務→ Filebeat → Kafka → Flink → ES
離線資料源:HDFS → Spark → Hive → ES
資料決議后的再利用:
決議后的資料已經擁有了重復利用的價值,我們的主要應用場景有兩大塊,
一是 OLAP,針對業務場景與資料表現分析訪問廣告的人群屬性標簽變化情況,包含地域,設備,人群分布占比與增長情況等;同時,針對未來人群庫存占比進行預測,最后影響到實際投放上,
另一部分是在 OLTP,主要場景為:
-
判定用戶是否屬于廣告受眾區域
-
決議 UA 資訊,獲取終端資訊,判斷是否屬于為低級爬蟲流量
-
設備號打標,從 Redis 獲取實時用戶畫像,進行實時標記等
2.4 OpenResty 其他應用場景
OpenResty 在我們的廣告資料監測服務全流程中均發揮著重要作用:
-
init_worker_by_lua階段:負責服務配置業務
-
access_by_lua階段:負責CC防護、權限準入、流量時序監控等業務
-
content_by_lua階段:負責實作限速器、分流器、WebAPI、流量采集等業務
-
log_by_lua階段:負責日志落盤等業務
重點解讀以下兩個應用的實作方式,
2.4.1 分流器業務
NodeJS 服務向 OpenResty 網關上報當前服務器 CPU 和記憶體使用情況;Lua 腳本呼叫 RedisCluster 獲取時間視窗內 NodeJS 集群使用情況后,計算出負載較高的 NodeJS 機器;OpenResty 對 NodeJS 集群流量進行熔斷、降級、限流等邏輯處理;將監控資料同步 InfluxDB,進行時序監測,
2.4.2 小型 WEB 防火墻
使用第三方開源 lua_resty_waf 類別庫實作,支持 IP 白名單和黑名單、URL 白名單、UA 過濾、CC 攻擊防護功能,我們在此基礎上增加了 WAF 對 InfluxDB 的支持,進行時序監控和服務預警,
2.5 小結
總結來看,基于 OpenResty 實作的廣告監測服務 ADMonitor 具備以下特點:
-
高可用:依賴 OpenResty 做 Gateway, 多節點做 HA
-
立即回傳:決議資料后利用 I/O 請求做資料異步處理,避免非必要的網路通信
-
解耦功能模塊:對請求、資料處理和轉發實作解耦,縮減單請求串行處理耗時
-
服務保障: 針對重要的資料結果利用第三方組件單獨存盤
完整的技術方案示意如下:
Part.3 總結
目前,ADMonitor 已經接入公司的廣告服務體系,總體運行情況比較理想:
1. 性能效果
-
達到了高吞吐、低延遲的標準
-
轉發成功率高,曝光計數成功率>99.9%,點擊成功率>99.8%
2. 業務效果
-
與主流第三方監測機構進行資料對比:曝光資料 GAP < 1%,點擊資料GAP < 3%
-
可提供實時檢索與聚合服務
未來我們將結合業務發展和服務場景不斷完善,期待和大家多多交流,
本文作者:江明輝,馬蜂窩旅游網品牌廣告資料服務端組研發工程師,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/25988.html
標籤:架構設計