文章目錄
- 一、Pgpool-Ⅱ簡介
- 二、PostgreSQL主備部署
- 2.1 關閉防火墻(主備均操作)
- 2.2 關閉selinux(主備均操作)
- 2.3 作業系統限制(主備均操作)
- 2.4 關閉numa(主備均操作)
- 2.5 編譯安裝(主備均操作)
- 2.6 配置用戶、目錄及權限(主備均操作)
- 2.7 配置環境變數(主備均操作)
- 2.8 初始化資料庫(主備均操作)
- 2.9 修改pg_hba.conf檔案(主庫操作)
- 2.10 修改修改postgresql.conf組態檔(主庫操作)
- 2.11 啟動資料庫(主庫操作)
- 2.12 備庫洗掉data(備庫操作)
- 2.13 備端基礎備份(備庫操作)
- 2.14 備庫啟動資料庫服務(備庫操作)
- 2.15 驗證復制
- 三、Pgpool-Ⅱ部署
- 3.1 軟體安裝(主備均操作)
- 3.2 互信配置
- 3.3 配置Pgpool-Ⅱ(主備均執行)
- 3.4 創建pgpool_node_id(主備分別執行)
- 3.5 follow_primary_command(主備均執行)
- 3.6 enable_pool_hba(主備均操作)
- 3.7 Failover configuration(主備均執行)
- 3.8 pgpool_recovery安裝(主執行)
- 3.9 創建pgpool目錄(主備均執行)
- 3.10 啟動pgpool(主備均執行)
- 四、管理命令
- 4.1 查看集群配置資訊
- 4.2 查看集群節點資訊
- 4.3 查看節點數量
- 4.4 查看指定節點資訊
- 4.5 增加一個集群節點
- 4.6 脫離一個集群節點
- 4.7 提升一個備用節點為活動節點
- 4.8 恢復一個離線節點為集群節點
- 五、功能驗證及問題匯總
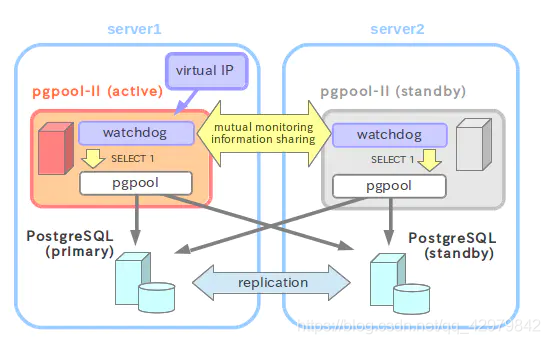
一、Pgpool-Ⅱ簡介
??Pgpool-II是位于PostgreSQL服務器和 PostgreSQL資料庫客戶端之間的代理軟體,它提供以下功能:
-
連接池(Connection Pooling)
??Pgpool II維護到PostgreSQL服務器的已建立的連接,并在出現具有相同屬性(即用戶名、資料庫、協議版本和其他連接引數)的新連接時重用這些連接,它減少了連接開銷,提高了系統的整體吞吐量, -
負載均衡(Load Balancing)
??如果復制了資料庫(因為在復制模式或本機復制模式下運行),則在任何服務器上執行SELECT查詢都將回傳相同的結果,Pgpool-II利用復制特性來減少每個PostgreSQL服務器上的負載,它通過在可用服務器之間分發SELECT查詢來實作這一點,從而提高系統的整體吞吐量,在理想情況下,讀取性能可以與PostgreSQL服務器的數量成比例地提高,負載平衡在許多用戶同時執行許多只讀查詢的情況下效果最好, -
自動故障轉移(Automatic failover)
??如果其中一臺資料庫服務器出現故障或無法訪問,則 Pgpool-II會將其分離,并將繼續使用其余的資料庫服務器進行操作,有一些復雜的功能可以幫助自動故障轉移,包括超時和重試, -
在線恢復(Online recovery)
??Pgpool-II可以通過執行一個命令來執行資料庫節點的聯機恢復,當聯機恢復與自動故障轉移一起使用時,可以通過故障轉移將分離的節點自動附加為備用節點,也可以同步并附加新的 PostgreSQL服務器, -
復制(Replication)
??Pgpool-II可以管理多個PostgreSQL 服務器,激活復制功能可以在兩個或多個PostgreSQL群集上創建實時備份,因此,如果其中一個群集發生故障,該服務可以繼續運行而不會中斷,Pgpool-II具有內置復制(本機復制),但是,用戶可以使用外部復制功能,包括PostgreSQL的流復制, -
超出限制連接(Limiting Exceeding Connections)
??PostgreSQL的最大并發連接數是有限制的,達到此數量時,新連接將被拒絕,但是,增加此最大連接數會增加資源消耗,并對整體系統性能產生負面影響,Pgpool-II也對最大連接數有限制,但是額外的連接將排隊,而不是立即回傳錯誤,但是,可以配置為在超過連接限制時回傳錯誤, -
看門狗(Watchdog)
??Watchdog可以協調多個Pgpool-II,創建強大的群集系統,并避免單點故障或大腦裂開,為了避免大腦分裂,您至少需要3個Pgpool-II節點,看門狗可以對其他執行lifecheck pgpool-II的節點,以檢測故障Pgpool-II,如果活動Pgpool-II發生故障,則備用 Pgpool-II可以提升為活動狀態,并接管虛擬IP, -
查詢快取(In Memory Query Cache)
??Watchdog在記憶體中查詢快取允許保存一對SELECT陳述句及其結果,如果出現相同的SELECT,則Pgpool-II從快取中回傳該值,由于不 涉及SQL決議和對PostgreSQL的訪問,因此在記憶體快取中使用非常快,另一方面,在某些情況下,它可能比正常路徑慢,因為它增加了存盤快取資料的開銷,
二、PostgreSQL主備部署
2.1 關閉防火墻(主備均操作)
systemctl stop firewalld.service #停止防火墻
systemctl disable firewalld.service #禁止開機啟動
2.2 關閉selinux(主備均操作)
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
cat /etc/sysconfig/selinux
/usr/sbin/sestatus -v
2.3 作業系統限制(主備均操作)
設定swap磁區
echo "vm.swappiness = 1" >>/etc/sysctl.conf
sysctl -p
#通過sysctl -a 查看
PS :swappiness值在0-100之間,0盡力使用物理記憶體,100盡力使用swap磁區,
資源配置
cat /etc/security/limits.conf
...
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
...
關閉透明大頁面
echo never >> /sys/kernel/mm/transparent_hugepage/enabled
echo never >> /sys/kernel/mm/transparent_hugepage/defrag
打開noatime
每個檔案上都有以下上個時間:
ctime: 改變時間
mtime: 修改時間
atime: 訪問時間
通常Postgresql 并不使用這三個時間;
首先禁止的是:atime
mtime 和 ctime 有時還有些作用
設定 noatime 如下:vim /etc/fstab
/dev/vda1 / xfs noatime,errors=remount-ro 0 1
調整預讀
Linux 下塊設備通常都默認打開了預讀,可以使用下面的命令查看預讀的大小:
blockdev --getra /dev/sdf
注意,上面的命令中值的單位為扇區,即 512bytes. 在下面的示例中:
sudo blockdev --getra /dev/sda
回傳值為256,表示是256個扇區,即為128KB
設定預讀的命令如下:
blockdev --setra 4096 /dev/sdf
上面的設定并不會永久生效,機器重啟后就會失效,如果想要永久生效,應該
把命令放到自動腳本中
如果想讓全表掃描更快一些,可以把預讀調整大一些,如像上例那樣把預讀設定為2MB
調整IO調度器
linux 下通常有一下三種I/O調度器:
1.cfq: completely fair queuing,完全公平佇列,嘗試為所有的請求分配公平的I/O帶寬,注意時帶寬,而不是回應時間
2.deadline: 平衡所有的請求,避免某個請求被餓死,讓回應時間最優化
3.noop: 除了基本的塊合并及排序作業,其他基本里上什么都不做,
echo deadline > /sys/block/vda/queue/scheduler
2.4 關閉numa(主備均操作)
sed -i 's/GRUB_CMDLINE_LINUX.*/GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos\/root rd.lvm.lv=centos\/swap rhgb quiet numa=off"/g' /etc/default/grub
grub2-mkconfig -o /etc/grub2.cfg
cat /etc/grub2.cfg
reboot
cat /proc/cmdline
dmesg | grep -i numa
2.5 編譯安裝(主備均操作)
[root@db01 ~]# tar xf postgresql-12.4.tar.gz -C /var/soft/
[root@db01 ~]# ln -s /var/soft/postgresql-12.4/ /var/soft/postgresql
[root@db01 ~]# cd /var/soft/postgresql
[root@db01 ~]# ./configure --prefix=/usr/local/pgsql --with-perl --with-tcl --with-python --with-openssl --with-pam --without-ldap --with-libxml --with-libxslt --enable-thread-safety --with-wal-blocksize=16 --with-blocksize=16 --enable-dtrace --enable-debug
[root@db01 ~]# make && make install
報錯處理
問題1:
checking for dtrace... no
configure: error: dtrace not found
解決方法: yum install -y systemtap-sdt-devel.x86_64
問題2:
checking for flags to link embedded Perl... Can't locate ExtUtils/Embed.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .).
BEGIN failed--compilation aborted.
no
configure: error: could not determine flags for linking embedded Perl.
This probably means that ExtUtils::Embed or ExtUtils::MakeMaker is not
installed.
解決方法:
yum install perl-ExtUtils-Embed -y
問題3:
checking build system type... x86_64-pc-linux-gnu
checking host system type... x86_64-pc-linux-gnu
checking which template to use... linux
checking whether NLS is wanted... no
checking for default port number... 5432
checking for dtrace... /usr/bin/dtrace
checking for block size... 16kB
checking for segment size... 1GB
checking for WAL block size... 16kB
checking for gcc... no
checking for cc... no
configure: error: in `/var/soft/postgresql':
configure: error: no acceptable C compiler found in $PATH
解決方法:
yum install gcc
問題4:
configure: error: readline library not found
If you have readline already installed, see config.log for details on the
failure. It is possible the compiler isn't looking in the proper directory.
Use --without-readline to disable readline support.
解決方法:
yum install readline readline-devel
問題5:
checking for inflate in -lz... no
configure: error: zlib library not found
If you have zlib already installed, see config.log for details on the
failure. It is possible the compiler isn't looking in the proper directory.
Use --without-zlib to disable zlib support.
解決方法:
yum install zlib zlib-devel
問題6:
checking for CRYPTO_new_ex_data in -lcrypto... no
configure: error: library 'crypto' is required for OpenSSL
解決方法:
yum install openssl openssl-devel
問題7:
checking for pam_start in -lpam... no
configure: error: library 'pam' is required for PAM
解決方法:
yum install pam pam-devel
問題8:
checking for xmlSaveToBuffer in -lxml2... no
configure: error: library 'xml2' (version >= 2.6.23) is required for XML support
解決方法:
yum install libxml2 libxml2-devel
問題9:
checking for xsltCleanupGlobals in -lxslt... no
configure: error: library 'xslt' is required for XSLT support
解決方法:
yum install libxslt libxslt-devel
問題10:
configure: error: Tcl shell not found
解決方法:
yum install tcl tcl-devel
問題11:
checking for ldap.h... no
configure: error: header file is required for LDAP
解決方法:
yum install openldap openldap-devel
問題12:
checking for Python.h... no
configure: error: header file <Python.h> is required for Python
解決方法:
yum install python python-devel
2.6 配置用戶、目錄及權限(主備均操作)
[root@db01 postgresql]# groupadd postgres
[root@db01 postgresql]# useradd postgres -g postgres
[root@db01 postgresql]# passwd postgres
[root@db01 postgresql]# mkdir -p /data/pgsql/data
[root@db01 postgresql]# chown -R postgres:postgres /data/pgsql/
[root@db01 postgresql]# chown -R postgres:postgres /usr/local/pgsql/
2.7 配置環境變數(主備均操作)
#修改環境變數
export LD_LIBRARY_PATH=/usr/local/pgsql/lib:$LD_LIBRARY_PATH
export PGDATA=/data/pgsql/data
export PGHOST=/tmp
export PGHOME=/usr/local/pgsql
export PATH=$PATH:$PGHOME/bin
#使其生效
source /etc/profile
2.8 初始化資料庫(主備均操作)
[root@db01 postgresql]# su - postgres
Last login: Sun Aug 30 22:11:36 CST 2020 on pts/2
[postgres@db01 ~]$ initdb
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are disabled.
fixing permissions on existing directory /data/pgsql/data ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting default time zone ... Asia/Shanghai
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
initdb: warning: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
pg_ctl -D /data/pgsql/data -l logfile start
2.9 修改pg_hba.conf檔案(主庫操作)
local all all trust
# IPv4 local connections:
host all all 0.0.0.0/0 md5
# IPv6 local connections:
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 192.168.137.0/24 trust
2.10 修改修改postgresql.conf組態檔(主庫操作)
archive_mode = on
archive_command = 'cp "%p" "/data/pgsql/data/arch/%f"'
max_wal_senders = 10
max_replication_slots = 10
wal_level = logical
hot_standby = on
wal_log_hints = on
synchronous_commit = on
synchronous_standby_names = 'walreceiver'
logging_collector = on
log_filename = 'postgresql-%a.log'
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 0
2.11 啟動資料庫(主庫操作)
[postgres@db02 ~]$ pg_ctl -D /data/pgsql/data start
[postgres@db02 ~]$ psql
postgres=# CREATE ROLE pgpool WITH LOGIN;
postgres=# CREATE ROLE repl WITH REPLICATION LOGIN;
postgres=# \password pgpool
postgres=# \password repl
postgres=# \password postgres
# pgpool_status中顯示
postgres=# GRANT pg_monitor TO pgpool;
# 查看結果 replication_state
postgres=# \du
postgres=# exit
2.12 備庫洗掉data(備庫操作)
rm -rf /data/pgsql/data
2.13 備端基礎備份(備庫操作)
[postgres@db02 ~]$ cd /data/pgsql/
[postgres@db02 ~]$ pg_basebackup -h 192.168.137.129 -U repl -Xs -Fp -R -Pv -D data
2.14 備庫啟動資料庫服務(備庫操作)
[postgres@db02 ~]$ pg_ctl -D /data/pgsql/data start
2.15 驗證復制
#主庫
[postgres@db01 data]$ ps -ef | grep postgres
postgres 84008 1 0 16:54 ? 00:00:00 /usr/local/pgsql/bin/postgres -D /data/pgsql/data
postgres 84009 84008 0 16:54 ? 00:00:00 postgres: logger
postgres 84011 84008 0 16:54 ? 00:00:00 postgres: checkpointer
postgres 84012 84008 0 16:54 ? 00:00:00 postgres: background writer
postgres 84013 84008 0 16:54 ? 00:00:00 postgres: walwriter
postgres 84014 84008 0 16:54 ? 00:00:00 postgres: autovacuum launcher
postgres 84015 84008 0 16:54 ? 00:00:00 postgres: archiver last was 000000010000000000000019.00000028.backup
postgres 84016 84008 0 16:54 ? 00:00:00 postgres: stats collector
postgres 84017 84008 0 16:54 ? 00:00:00 postgres: logical replication launcher
postgres 85904 84008 0 17:09 ? 00:00:00 postgres: walsender repl 192.168.137.130(33968) streaming 0/1A000148
postgres=# select client_addr,sync_state from pg_stat_replication;
client_addr | sync_state
-----------------+------------
192.168.137.130 | sync
(1 row)
postgres=#
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)
#備庫
[postgres@db02 pgsql]$ ps -ef | grep postgres
postgres 91113 1 0 17:09 ? 00:00:00 /usr/local/pgsql/bin/postgres
postgres 91114 91113 0 17:09 ? 00:00:00 postgres: logger
postgres 91115 91113 0 17:09 ? 00:00:00 postgres: startup recovering 00000001000000000000001A
postgres 91116 91113 0 17:09 ? 00:00:00 postgres: checkpointer
postgres 91117 91113 0 17:09 ? 00:00:00 postgres: background writer
postgres 91118 91113 0 17:09 ? 00:00:00 postgres: stats collector
postgres 91119 91113 0 17:09 ? 00:00:01 postgres: walreceiver streaming 0/1A000148
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
三、Pgpool-Ⅱ部署
3.1 軟體安裝(主備均操作)
yum localinstall pgpool-II-pg12*
chown postgres.postgres /etc/pgpool-II/*
3.2 互信配置
# 每個節點都執行
ssh-keygen -t rsa # 一路回車
# 將公鑰添加到認證檔案中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 并設定authorized_keys的訪問權限
chmod 600 ~/.ssh/authorized_keys
# 只要在一個節點執行即可
ssh db02 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
# 分發整合后的檔案到其它節點
scp ~/.ssh/authorized_keys db02:~/.ssh/
#各節點執行
ssh db01 date
ssh db02 date
3.3 配置Pgpool-Ⅱ(主備均執行)
配置密碼
[postgres@db01 pgpool-II]$ pg_md5 -p -m -u postgres postgres
password:
[postgres@db01 pgpool-II]$ cat pool_passwd
postgres:md53175bce1d3201d16594cebf9d7eb3f9d
[postgres@db01 pgpool-II]$ pg_md5 -p -m -u pgpool pgpool
password:
[postgres@db01 pgpool-II]$ cat /etc/pgpool-II/pool_passwd
postgres:md53175bce1d3201d16594cebf9d7eb3f9d
pgpool:md5f24aeb1c3b7d05d7eaf2cd648c307092
pgpool.conf
# [CONNECTIONS]
listen_addresses = '*'
port = 9999
socket_dir = '/data/pgpool'
## - Backend Connection Settings -
backend_hostname0 = 'db01'
backend_data_directory0 = '/data/pgsql/data'
backend_application_name0 = 'server1'
backend_flag0 = 'ALLOW_TO_FAILOVER'
backend_port0 = 5432
backend_weight0 = 1
backend_hostname1 = 'db02'
backend_data_directory1 = '/data/pgsql/data'
backend_application_name1 = 'server2'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_port1 = 5432
backend_weight1 = 0
## - Authentication -
enable_pool_hba = on
pool_passwd = 'pool_passwd'
# [LOGS]
logging_collector = on
log_directory = '/data/pgpool'
log_filename = 'pgpool-%Y-%m-%d_%H%M%S.log'
log_file_mode = 0600
log_truncate_on_rotation = on
log_rotation_age = 1d
log_rotation_size = 10MB
# [FILE LOCATIONS]
pid_file_name = '/data/pgpool/pgpool.pid'
## 此目錄用來存放 pgpool_status 檔案,此檔案保存集群狀態(重繪有問題時會造成show pool_status不正確)
logdir = '/data/pgpool'
# [NATIVE REPLICATION MODE]
sr_check_user = 'pgpool'
## 為''時查找 pool_passwd
sr_check_password = 'pgpool'
follow_primary_command = '/etc/pgpool-II/follow_primary.sh %d %h %p %D %m %H %M %P %r %R'
# [HEALTH CHECK GLOBAL PARAMETERS]
health_check_period = 5
health_check_timeout = 30
health_check_user = 'pgpool'
## 為''時查找 pool_passwd
health_check_password = 'pgpool'
health_check_max_retries = 3
# [FAILOVER AND FAILBACK]
failover_command = '/etc/pgpool-II/failover.sh %d %h %p %D %m %H %M %P %r %R %N %S'
# [ONLINE RECOVERY]
recovery_user = 'postgres'
recovery_password = 'postgres'
recovery_1st_stage_command = 'recovery_1st_stage'
# [WATCHDOG]
use_watchdog = on
hostname0 = 'db01'
wd_port0 = 9000
pgpool_port0 = 9999
hostname1 = 'db02'
wd_port1 = 9000
pgpool_port1 = 9999
wd_ipc_socket_dir = '/data/pgpool'
## - Virtual IP control Setting -
delegate_IP = '192.168.137.128'
if_up_cmd = '/sbin/ip addr add 192.168.137.128/24 dev ens32 label ens32:0'
if_down_cmd = '/sbin/ip addr del 192.168.137.128/24 dev ens32'
## - Behaivor on escalation Setting -
wd_escalation_command = '/etc/pgpool-II/escalation.sh'
## - Lifecheck Setting -
wd_lifecheck_method = 'heartbeat'
### -- heartbeat mode --
heartbeat_hostname0 = 'db01'
heartbeat_port0 = 9694
heartbeat_device0 = 'ens32'
heartbeat_hostname1 = 'db02'
heartbeat_port1 = 9694
heartbeat_device1 = 'ens32'
3.4 創建pgpool_node_id(主備分別執行)
echo 0 > /etc/pgpool-II/pgpool_node_id
echo 1 > /etc/pgpool-II/pgpool_node_id
3.5 follow_primary_command(主備均執行)
[postgres@db01 pgpool-II]$ echo 'pgpool:'`pg_md5 pgpool` >> /etc/pgpool-II/pcp.conf
[postgres@db01 pgpool-II]$ echo 'localhost:9898:pgpool:pgpool' > ~/.pcppass
[postgres@db01 pgpool-II]$ chmod 600 ~/.pcppass
3.6 enable_pool_hba(主備均操作)
[postgres@db01 pgpool-II]$ vi /etc/pgpool-II/pool_hba.conf
# 官方檔案為 scram-sha-256,改為md5
host all pgpool 0.0.0.0/0 md5
host all postgres 0.0.0.0/0 md5
3.7 Failover configuration(主備均執行)
[postgres@db01 pgpool-II]$ cd /etc/pgpool-II
#以下腳本需進行相應修改
[postgres@db01 pgpool-II]$ mv escalation.sh.sample escalation.sh
[postgres@db01 pgpool-II]$ mv failover.sh.sample failover.sh
[postgres@db01 pgpool-II]$ mv follow_primary.sh.sample follow_primary.sh
[postgres@db01 pgpool-II]$ mv pgpool_remote_start.sample /data/pgsql/data/pgpool_remote_start
[postgres@db01 pgpool-II]$ mv recovery_1st_stage.sample /data/pgsql/data/recovery_1st_stage
[postgres@db01 pgpool-II]$ mv recovery_2nd_stage.sample /data/pgsql/data/recovery_2nd_stage
3.8 pgpool_recovery安裝(主執行)
#獲取libdir
pg_config --pkglibdir
cp pgpool_recovery* /usr/local/pgsql/share/extension/
cp pgpool-recovery.sql /usr/local/pgsql/share/extension/
cp pgpool-recovery.so /usr/local/pgsql/lib/
psql -f pgpool-recovery.sql template1
3.9 創建pgpool目錄(主備均執行)
mkdir /data/pgpool
chown -R /data/pgpool
3.10 啟動pgpool(主備均執行)
system start pgpool
四、管理命令
4.1 查看集群配置資訊
pcp_pool_status -h 192.168.137.128 -p 9898 -U pgpool -v
4.2 查看集群節點資訊
pcp_watchdog_info -h 192.168.137.128 -p 9898 -U pgpool -v
4.3 查看節點數量
pcp_node_count -h 192.168.137.128 -p 9898 -U pgpool
4.4 查看指定節點資訊
pcp_node_info -h 192.168.137.128 -p 9898 -U pgpool -n 0 -v
4.5 增加一個集群節點
pcp_attach_node -h 192.168.137.128 -p 9898 -U pgpool -n 0 -v
4.6 脫離一個集群節點
pcp_detach_node -h 192.168.137.128 -p 9898 -U pgpool -n 0 -v
4.7 提升一個備用節點為活動節點
pcp_promote_node -h 192.168.137.128 -p 9898 -U pgpool -n 0 -v
4.8 恢復一個離線節點為集群節點
pcp_recovery_node -h 192.168.137.128 -p 9898 -U pgpool -n 0 -v
五、功能驗證及問題匯總
待更新
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/260025.html
標籤:其他
上一篇:Spring Boot入門
下一篇:Redis 安裝