一、Redis集群介紹:
1、為什么需要Redis集群?
在講Redis集群架構之前,我們先簡單講下Redis單實體的架構,從最開始的一主N從,到讀寫分離,再到Sentinel哨兵機制,單實體的Redis快取足以應對大多數的使用場景,也能實作主從故障遷移,
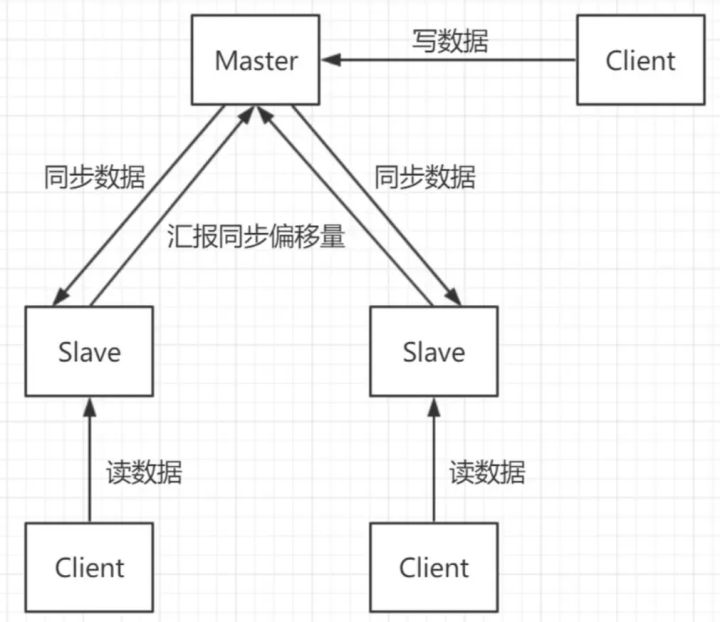
但是,在某些場景下,單實體存Redis快取會存在的幾個問題:
(1)寫并發:
Redis單實體讀寫分離可以解決讀操作的負載均衡,但對于寫操作,仍然是全部落在了master節點上面,在海量資料高并發場景,一個節點寫資料容易出現瓶頸,造成master節點的壓力上升,
(2)海量資料的存盤壓力:
單實體Redis本質上只有一臺Master作為存盤,如果面對海量資料的存盤,一臺Redis的服務器就應付不過來了,而且資料量太大意味著持久化成本高,嚴重時可能會阻塞服務器,造成服務請求成功率下降,降低服務的穩定性,
針對以上的問題,Redis集群提供了較為完善的方案,解決了存盤能力受到單機限制,寫操作無法負載均衡的問題,
2、什么是Redis集群?
Redis3.0加入了Redis的集群模式,實作了資料的分布式存盤,對資料進行分片,將不同的資料存盤在不同的master節點上面,從而解決了海量資料的存盤問題,
Redis集群采用去中心化的思想,沒有中心節點的說法,對于客戶端來說,整個集群可以看成一個整體,可以連接任意一個節點進行操作,就像操作單一Redis實體一樣,不需要任何代理中間件,當客戶端操作的key沒有分配到該node上時,Redis會回傳轉向指令,指向正確的node,
Redis也內置了高可用機制,支持N個master節點,每個master節點都可以掛載多個slave節點,當master節點掛掉時,集群會提升它的某個slave節點作為新的master節點,
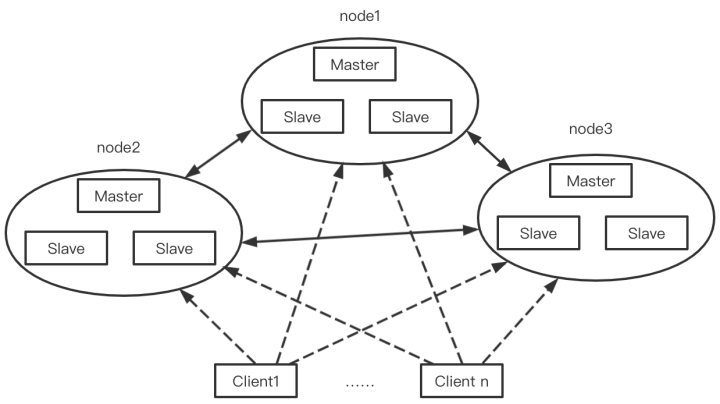
如上圖所示,Redis集群可以看成多個主從架構組合起來的,每一個主從架構可以看成一個節點(其中,只有master節點具有處理請求的能力,slave節點主要是用于節點的高可用)
二、Redis集群的資料分布演算法:哈希槽演算法
1、什么是哈希槽演算法?
前面講到,Redis集群通過分布式存盤的方式解決了單節點的海量資料存盤的問題,對于分布式存盤,需要考慮的重點就是如何將資料進行拆分到不同的Redis服務器上,常見的磁區演算法有hash演算法、一致性hash演算法,關于這些演算法這里就不多介紹,
- 普通hash演算法:將key使用hash演算法計算之后,按照節點數量來取余,即hash(key)%N,優點就是比較簡單,但是擴容或者摘除節點時需要重新根據映射關系計算,會導致資料重新遷移,
- 一致性hash演算法:為每一個節點分配一個token,構成一個哈希環;查找時先根據key計算hash值,然后順時針找到第一個大于等于該哈希值的token節點,優點是在加入和洗掉節點時只影響相鄰的兩個節點,缺點是加減節點會造成部分資料無法命中,所以一般用于快取,而且用于節點量大的情況下,擴容一般增加一倍節點保障資料負載均衡,
Redis集群采用的演算法是哈希槽磁區演算法,Redis集群中有16384個哈希槽(槽的范圍是 0 -16383,哈希槽),將不同的哈希槽分布在不同的Redis節點上面進行管理,也就是說每個Redis節點只負責一部分的哈希槽,在對資料進行操作的時候,集群會對使用CRC16演算法對key進行計算并對16384取模(slot = CRC16(key)%16383),得到的結果就是 Key-Value 所放入的槽,通過這個值,去找到對應的槽所對應的Redis節點,然后直接到這個對應的節點上進行存取操作,
使用哈希槽的好處就在于可以方便的添加或者移除節點,并且無論是添加洗掉或者修改某一個節點,都不會造成集群不可用的狀態,當需要增加節點時,只需要把其他節點的某些哈希槽挪到新節點就可以了;當需要移除節點時,只需要把移除節點上的哈希槽挪到其他節點就行了;哈希槽資料磁區演算法具有以下幾種特點:
- 解耦資料和節點之間的關系,簡化了擴容和收縮難度;
- 節點自身維護槽的映射關系,不需要客戶端代理服務維護槽磁區元資料
- 支持節點、槽、鍵之間的映射查詢,用于資料路由,在線伸縮等場景
槽的遷移與指派命令:CLUSTER ADDSLOTS 0 1 2 3 4 ... 5000
默認情況下,redis集群的讀和寫都是到master上去執行的,不支持slave節點讀和寫,跟Redis主從復制下讀寫分離不一樣,因為redis集群的核心的理念,主要是使用slave做資料的熱備,以及master故障時的主備切換,實作高可用的,Redis的讀寫分離,是為了橫向任意擴展slave節點去支撐更大的讀吞吐量,而redis集群架構下,本身master就是可以任意擴展的,如果想要支撐更大的讀或寫的吞吐量,都可以直接對master進行橫向擴展,
2、Redis中哈希槽相關的資料結構:
(1)clusterNode資料結構:保存節點的當前狀態,比如節點的創建時間,節點的名字,節點當前的配置紀元,節點的IP和地址,等等,

(2)clusterState資料結構:記錄當前節點所認為的集群目前所處的狀態,

(3)節點的槽指派資訊:
clusterNode資料結構的slots屬性和numslot屬性記錄了節點負責處理那些槽:
slots屬性是一個二進制位陣列(bit array),這個陣列的長度為16384/8=2048個位元組,共包含16384個二進制位,Master節點用bit來標識對于某個槽自己是否擁有,時間復雜度為O(1)

(4)集群所有槽的指派資訊:
當收到集群中其他節點發送的資訊時,通過將節點槽的指派資訊保存在本地的clusterState.slots陣列里面,程式要檢查槽i是否已經被指派,又或者取得負責處理槽i的節點,只需要訪問clusterState.slots[i]的值即可,時間復雜度僅為O(1)
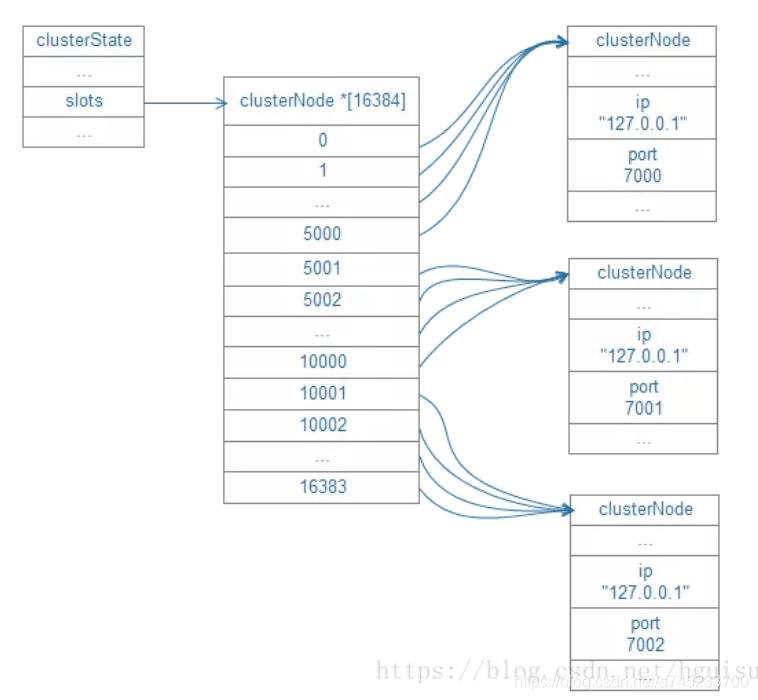
如上圖所示,ClusterState 中保存的 Slots 陣列中每個下標對應一個槽,每個槽資訊中對應一個 clusterNode 也就是快取的節點,這些節點會對應一個實際存在的 Redis 快取服務,包括 IP 和 Port 的資訊,Redis Cluster 的通訊機制實際上保證了每個節點都有其他節點和槽資料的對應關系,無論Redis 的客戶端訪問集群中的哪個節點都可以路由到對應的節點上,因為每個節點都有一份 ClusterState,它記錄了所有槽和節點的對應關系,
3、集群的請求重定向:
前面講到,Redis集群在客戶端層面沒有采用代理,并且無論Redis 的客戶端訪問集群中的哪個節點都可以路由到對應的節點上,下面來看看 Redis 客戶端是如何通過路由來呼叫快取節點的:
(1)MOVED請求:
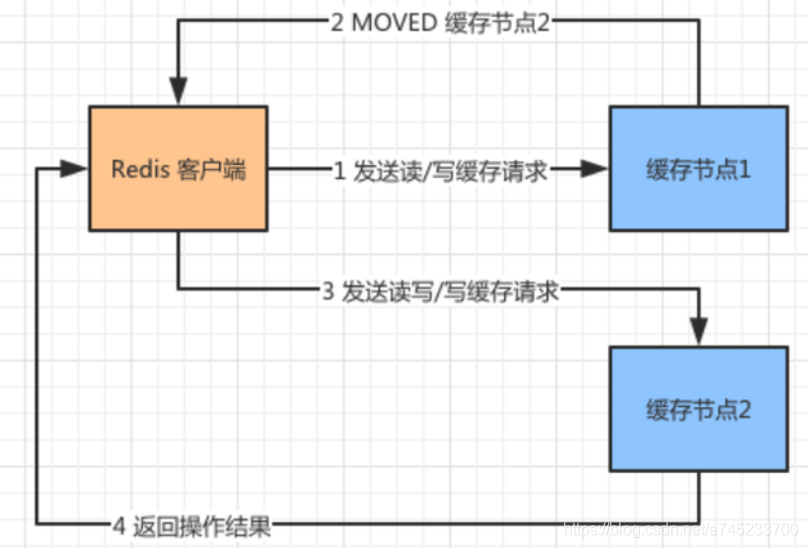
如上圖所示,Redis 客戶端通過 CRC16(key)%16383 計算出 Slot 的值,發現需要找“快取節點1”進行資料操作,但是由于快取資料遷移或者其他原因導致這個對應的 Slot 的資料被遷移到了“快取節點2”上面,那么這個時候 Redis 客戶端就無法從“快取節點1”中獲取資料了,但是由于“快取節點1”中保存了所有集群中快取節點的資訊,因此它知道這個 Slot 的資料在“快取節點2”中保存,因此向 Redis 客戶端發送了一個 MOVED 的重定向請求,這個請求告訴其應該訪問的“快取節點2”的地址,Redis 客戶端拿到這個地址,繼續訪問“快取節點2”并且拿到資料,
(2)ASK請求:
上面的例子說明了,資料 Slot 從“快取節點1”已經遷移到“快取節點2”了,那么客戶端可以直接找“快取節點2”要資料,那么如果兩個快取節點正在位元組點的資料遷移,此時客戶端請求會如何處理呢?
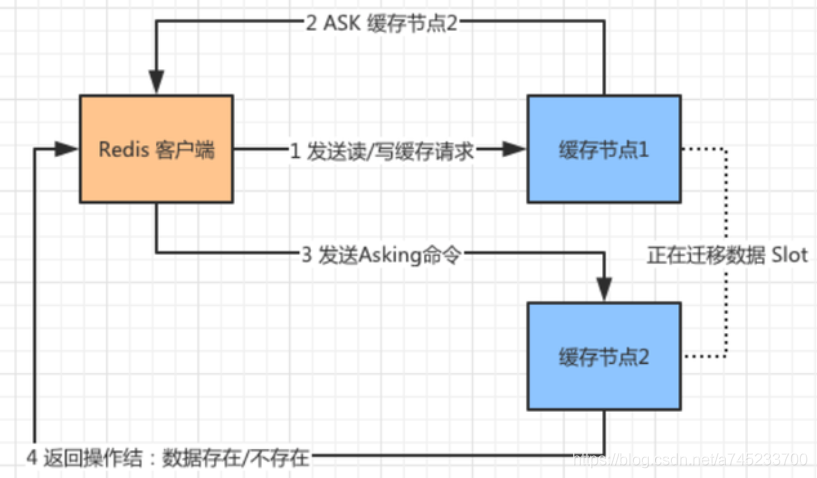
Redis 客戶端向“快取節點1”發出請求,此時“快取節點1”正向“快取節點 2”遷移資料,如果沒有命中對應的 Slot,它會回傳客戶端一個 ASK 重定向請求并且告訴“快取節點2”的地址,客戶端向“快取節點2”發送 Asking 命令,詢問需要的資料是否在“快取節點2”上,“快取節點2”接到訊息以后回傳資料是否存在的結果,
(3)頻繁重定向造成的網路開銷的處理:smart客戶端
① 什么是 smart客戶端:
在大部分情況下,可能都會出現一次請求重定向才能找到正確的節點,這個重定向程序顯然會增加集群的網路負擔和單次請求耗時,所以大部分的客戶端都是smart的,所謂 smart客戶端,就是指客戶端本地維護一份hashslot => node的映射表快取,大部分情況下,直接走本地快取就可以找到hashslot => node,不需要通過節點進行moved重定向,
② JedisCluster的作業原理:
- 在JedisCluster初始化的時候,就會隨機選擇一個node,初始化hashslot => node映射表,同時為每個節點創建一個JedisPool連接池,
- 每次基于JedisCluster執行操作時,首先會在本地計算key的hashslot,然后在本地映射表找到對應的節點node,
- 如果那個node正好還是持有那個hashslot,那么就ok;如果進行了reshard操作,可能hashslot已經不在那個node上了,就會回傳moved,
- 如果JedisCluter API發現對應的節點回傳moved,那么利用該節點回傳的元資料,更新本地的hashslot => node映射表快取
- 重復上面幾個步驟,直到找到對應的節點,如果重試超過5次,那么就報錯,JedisClusterMaxRedirectionException
③ hashslot遷移和ask重定向:
如果hashslot正在遷移,那么會回傳ask重定向給客戶端,客戶端接收到ask重定向之后,會重新定位到目標節點去執行,但是因為ask發生在hashslot遷移程序中,所以JedisCluster API收到ask是不會更新hashslot本地快取,
雖然ASK與MOVED都是對客戶端的重定向控制,但是有本質區別,ASK重定向說明集群正在進行slot資料遷移,客戶端無法知道遷移什么時候完成,因此只能是臨時性的重定向,客戶端不會更新slots快取,但是MOVED重定向說明鍵對應的槽已經明確指定到新的節點,客戶端需要更新slots快取,
三、Redis集群中節點的通信機制:goosip協議
redis集群的哈希槽演算法解決的是資料的存取問題,不同的哈希槽位于不同的節點上,而不同的節點維護著一份它所認為的當前集群的狀態,同時,Redis集群是去中心化的架構,那么,當集群的狀態發生變化時,比如新節點加入、slot遷移、節點宕機、slave提升為新Master等等,我們希望這些變化盡快被其他節點發現,Redis是如何進行處理的呢?也就是說,Redis不同節點之間是如何進行通信進行維護集群的同步狀態呢?
在Redis集群中,不同的節點之間采用gossip協議進行通信,節點之間通訊的目的是為了維護節點之間的元資料資訊,這些元資料就是每個節點包含哪些資料,是否出現故障,通過gossip協議,達到最終資料的一致性,
gossip協議,是基于流行病傳播方式的節點或者行程之間資訊交換的協議,原理就是在不同的節點間不斷地通信交換資訊,一段時間后,所有的節點就都有了整個集群的完整資訊,并且所有節點的狀態都會達成一致,每個節點可能知道所有其他節點,也可能僅知道幾個鄰居節點,但只要這些節可以通過網路連通,最終他們的狀態就會是一致的,Gossip協議最大的好處在于,即使集群節點的數量增加,每個節點的負載也不會增加很多,幾乎是恒定的,
Redis集群中節點的通信程序如下:
- 集群中每個節點都會單獨開一個TCP通道,用于節點間彼此通信,
- 每個節點在固定周期內通過待定的規則選擇幾個節點發送ping訊息
- 接收到ping訊息的節點用pong訊息作為回應
使用gossip協議的優點在于將元資料的更新分散在不同的節點上面,降低了壓力;但是缺點就是元資料的更新有延時,可能導致集群中的一些操作會有一些滯后,另外,由于 gossip 協議對服務器時間的要求較高,時間戳不準確會影響節點判斷訊息的有效性,而且節點數量增多后的網路開銷也會對服務器產生壓力,同時結點數太多,意味著達到最終一致性的時間也相對變長,因此官方推薦最大節點數為1000左右,
redis cluster架構下的每個redis都要開放兩個埠號,比如一個是6379,另一個就是加1w的埠號16379,
- 6379埠號就是redis服務器入口,
- 16379埠號是用來進行節點間通信的,也就是 cluster bus 的東西,cluster bus 的通信,用來進行故障檢測、配置更新、故障轉移授權,cluster bus 用的是一種叫gossip 協議的二進制協議
1、gossip協議的常見型別:
gossip協議常見的訊息型別包含: ping、pong、meet、fail等等,
(1)meet:主要用于通知新節點加入到集群中,通過「cluster meet ip port」命令,已有集群的節點會向新的節點發送邀請,加入現有集群,
(2)ping:用于交換節點的元資料,每個節點每秒會向集群中其他節點發送 ping 訊息,訊息中封裝了自身節點狀態還有其他部分節點的狀態資料,也包括自身所管理的槽資訊等等,
- 因為發送ping命令時要攜帶一些元資料,如果很頻繁,可能會加重網路負擔,因此,一般每個節點每秒會執行 10 次 ping,每次會選擇 5 個最久沒有通信的其它節點,
- 如果發現某個節點通信延時達到了 cluster_node_timeout / 2,那么立即發送 ping,避免資料交換延時過長導致資訊嚴重滯后,比如說,兩個節點之間都 10 分鐘沒有交換資料了,那么整個集群處于嚴重的元資料不一致的情況,就會有問題,所以 cluster_node_timeout 可以調節,如果調得比較大,那么會降低 ping 的頻率,
- 每次 ping,會帶上自己節點的資訊,還有就是帶上 1/10 其它節點的資訊,發送出去,進行交換,至少包含 3 個其它節點的資訊,最多包含 (總節點數 - 2)個其它節點的資訊,
(3)pong:ping和meet訊息的回應,同樣包含了自身節點的狀態和集群元資料資訊,
(4)fail:某個節點判斷另一個節點 fail 之后,向集群所有節點廣播該節點掛掉的訊息,其他節點收到訊息后標記已下線,
由于Redis集群的去中心化以及gossip通信機制,Redis集群中的節點只能保證最終一致性,例如當加入新節點時(meet),只有邀請節點和被邀請節點知道這件事,其余節點要等待 ping 訊息一層一層擴散,除了 Fail 是立即全網通知的,其他諸如新節點、節點重上線、從節點選舉成為主節點、槽變化等,都需要等待被通知到,也就是Gossip協議是最終一致性的協議,
2、meet命令的實作:
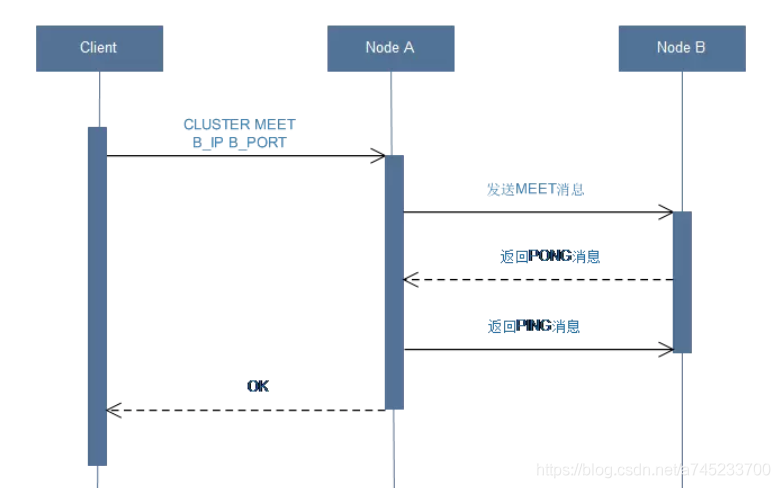
(1)節點A會為節點B創建一個clusterNode結構,并將該結構添加到自己的clusterState.nodes字典里面,
(2)節點A根據CLUSTER MEET命令給定的IP地址和埠號,向節點B發送一條MEET訊息,
(3)節點B接收到節點A發送的MEET訊息,節點B會為節點A創建一個clusterNode結構,并將該結構添加到自己的clusterState.nodes字典里面,
(4)節點B向節點A回傳一條PONG訊息,
(5)節點A將受到節點B回傳的PONG訊息,通過這條PONG訊息,節點A可以知道節點B已經成功的接收了自己發送的MEET訊息,
(6)之后,節點A將向節點B回傳一條PING訊息,
(7)節點B將接收到的節點A回傳的PING訊息,通過這條PING訊息節點B可以知道節點A已經成功的接收到了自己回傳的PONG訊息,握手完成,
(8)之后,節點A會將節點B的資訊通過Gossip協議傳播給集群中的其他節點,讓其他節點也與節點B進行握手,最終,經過一段時間后,節點B會被集群中的所有節點認識,
四、集群的擴容與收縮:
作為分布式部署的快取節點總會遇到快取擴容和快取故障的問題,這就會導致快取節點的上線和下線的問題,由于每個節點中保存著槽資料,因此當快取節點數出現變動時,這些槽資料會根據對應的虛擬槽演算法被遷移到其他的快取節點上,所以對于redis集群,集群伸縮主要在于槽和資料在節點之間移動,
1、擴容:
- (1)啟動新節點
- (2)使用cluster meet命令將新節點加入到集群
- (3)遷移槽和資料:添加新節點后,需要將一些槽和資料從舊節點遷移到新節點
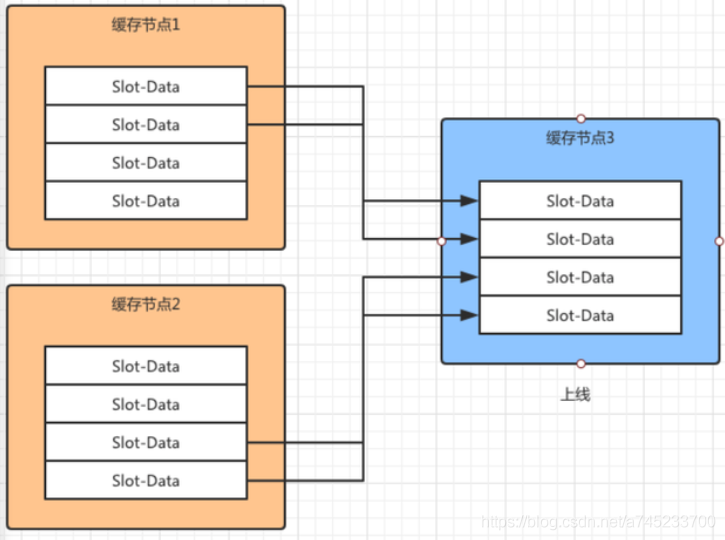
如上圖所示,集群中本來存在“快取節點1”和“快取節點2”,此時“快取節點3”上線了并且加入到集群中,此時根據虛擬槽的演算法,“快取節點1”和“快取節點2”中對應槽的資料會應該新節點的加入被遷移到“快取節點3”上面,
新節點加入到集群的時候,作為孤兒節點是沒有和其他節點進行通訊的,因此需要在集群中任意節點執行 cluster meet 命令讓新節點加入進來,假設新節點是 192.168.1.1 5002,老節點是 192.168.1.1 5003,那么運行以下命令將新節點加入到集群中,
192.168.1.1 5003> cluster meet 192.168.1.1 5002
這個是由老節點發起的,有點老成員歡迎新成員加入的意思,新節點剛剛建立沒有建立槽對應的資料,也就是說沒有快取任何資料,如果這個節點是主節點,需要對其進行槽資料的擴容;如果這個節點是從節點,就需要同步主節點上的資料,總之就是要同步資料,
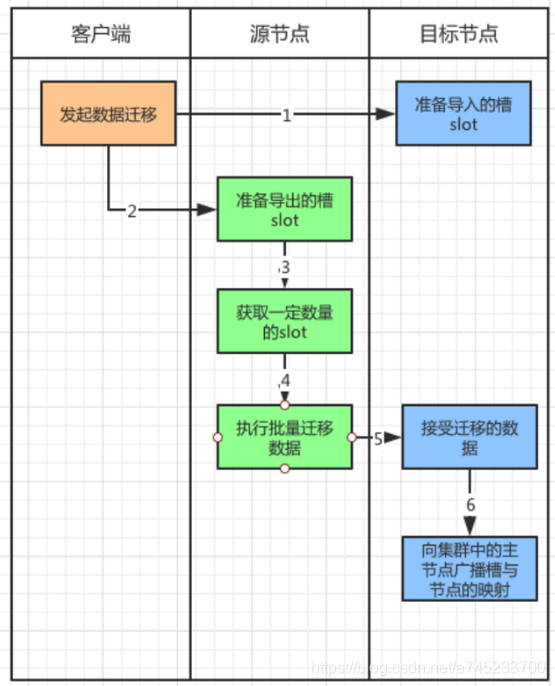
如上圖所示,由客戶端發起節點之間的槽資料遷移,資料從源節點往目標節點遷移,
- (1)客戶端對目標節點發起準備匯入槽資料的命令,讓目標節點準備好匯入槽資料,這里使用 cluster setslot {slot} importing {sourceNodeId} 命令,
- (2)之后對源節點發起送命令,讓源節點準備遷出對應的槽資料,使用命令 cluster setslot {slot} importing {sourceNodeId},
- (3)此時源節點準備遷移資料了,在遷移之前把要遷移的資料獲取出來,通過命令 cluster getkeysinslot {slot} {count},Count 表示遷移的 Slot 的個數,
- (4)然后在源節點上執行,migrate {targetIP} {targetPort} “” 0 {timeout} keys {keys} 命令,把獲取的鍵通過流水線批量遷移到目標節點,
- (5)重復 3 和 4 兩步不斷將資料遷移到目標節點,
- (6)完成資料遷移到目標節點以后,通過 cluster setslot {slot} node {targetNodeId} 命令通知對應的槽被分配到目標節點,并且廣播這個資訊給全網的其他主節點,更新自身的槽節點對應表,
2、收縮:
- 遷移槽,
- 忘記節點,通過命令 cluster forget {downNodeId} 通知其他的節點
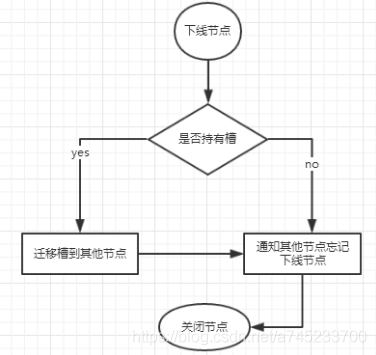
為了安全洗掉節點,Redis集群只能下線沒有負責槽的節點,因此如果要下線有負責槽的master節點,則需要先將它負責的槽遷移到其他節點,遷移的程序也與上線操作類似,不同的是下線的時候需要通知全網的其他節點忘記自己,此時通過命令 cluster forget {downNodeId} 通知其他的節點,
五、集群的故障檢測與故障轉恢復機制:
1、集群的故障檢測:
Redis集群的故障檢測是基于gossip協議的,集群中的每個節點都會定期地向集群中的其他節點發送PING訊息,以此交換各個節點狀態資訊,檢測各個節點狀態:在線狀態、疑似下線狀態PFAIL、已下線狀態FAIL,
(1)主觀下線(pfail):當節點A檢測到與節點B的通訊時間超過了cluster-node-timeout 的時候,就會更新本地節點狀態,把節點B更新為主觀下線,
主觀下線并不能代表某個節點真的下線了,有可能是節點A與節點B之間的網路斷開了,但是其他的節點依舊可以和節點B進行通訊,
(2)客觀下線:
由于集群內的節點會不斷地與其他節點進行通訊,下線資訊也會通過 Gossip 訊息傳遍所有節點,因此集群內的節點會不斷收到下線報告,
當半數以上的主節點標記了節點B是主觀下線時,便會觸發客觀下線的流程(該流程只針對主節點,如果是從節點就會忽略),將主觀下線的報告保存到本地的 ClusterNode 的結構fail_reports鏈表中,并且對主觀下線報告的時效性進行檢查,如果超過 cluster-node-timeout*2 的時間,就忽略這個報告,否則就記錄報告內容,將其標記為客觀下線,
接著向集群廣播一條主節點B的Fail 訊息,所有收到訊息的節點都會標記節點B為客觀下線,
2、集群地故障恢復:
當故障節點下線后,如果是持有槽的主節點則需要在其從節點中找出一個替換它,從而保證高可用,此時下線主節點的所有從節點都擔負著恢復義務,這些從節點會定時監測主節點是否進入客觀下線狀態,如果是,則觸發故障恢復流程,故障恢復也就是選舉一個節點充當新的master,選舉的程序是基于Raft協議選舉方式來實作的,
2.1、從節點過濾:
檢查每個slave節點與master節點斷開連接的時間,如果超過了cluster-node-timeout * cluster-slave-validity-factor,那么就沒有資格切換成master
2.2、投票選舉:
(1)節點排序:
對通過過濾條件的所有從節點進行排序,按照priority、offset、run id排序,排序越靠前的節點,越優先進行選舉,
- priority的值越低,優先級越高
- offset越大,表示從master節點復制的資料越多,選舉時間越靠前,優先進行選舉
- 如果offset相同,run id越小,優先級越高
(2)更新配置紀元:
每個主節點會去更新配置紀元(clusterNode.configEpoch),這個值是不斷增加的整數,這個值記錄了每個節點的版本和整個集群的版本,每當發生重要事情的時候(例如:出現新節點,從節點精選)都會增加全域的配置紀元并且賦給相關的主節點,用來記錄這個事件,更新這個值目的是,保證所有主節點對這件“大事”保持一致,大家都統一成一個配置紀元,表示大家都知道這個“大事”了,
(3)發起選舉:
更新完配置紀元以后,從節點會向集群發起廣播選舉的訊息(CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST),要求所有收到這條訊息,并且具有投票權的主節點進行投票,每個從節點在一個紀元中只能發起一次選舉,
(4)選舉投票:
如果一個主節點具有投票權,并且這個主節點尚未投票給其他從節點,那么主節點將向要求投票的從節點回傳一條CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息,表示這個主節點支持從節點成為新的主節點,每個參與選舉的從節點都會接收CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK訊息,并根據自己收到了多少條這種訊息來統計自己獲得了多少主節點的支持,
如果超過(N/2 + 1)數量的master節點都投票給了某個從節點,那么選舉通過,這個從節點可以切換成master,如果在 cluster-node-timeout*2 的時間內從節點沒有獲得足夠數量的票數,本次選舉作廢,更新配置紀元,并進行第二輪選舉,直到選出新的主節點為止,
在第(1)步排序領先的從節點通常會獲得更多的票,因為它觸發選舉的時間更早一些,獲得票的機會更大
2.3、替換主節點:
當滿足投票條件的從節點被選出來以后,會觸發替換主節點的操作,洗掉原主節點負責的槽資料,把這些槽資料添加到自己節點上,并且廣播讓其他的節點都知道這件事情,新的主節點誕生了,
(1)被選中的從節點執行SLAVEOF NO ONE命令,使其成為新的主節點
(2)新的主節點會撤銷所有對已下線主節點的槽指派,并將這些槽全部指派給自己
(3)新的主節點對集群進行廣播PONG訊息,告知其他節點已經成為新的主節點
(4)新的主節點開始接收和處理槽相關的請求
備注:如果集群中某個節點的master和slave節點都宕機了,那么集群就會進入fail狀態,因為集群的slot映射不完整,如果集群超過半數以上的master掛掉,無論是否有slave,集群都會進入fail狀態,
六、Redis集群的搭建:
該部分可以參考這篇文章:https://juejin.cn/post/6922690589347545102#heading-1
Redis集群的搭建可以分為以下幾個部分:
1、啟動節點:將節點以集群模式啟動,讀取或者生成集群組態檔,此時節點是獨立的,
2、節點握手:節點通過gossip協議通信,將獨立的節點連成網路,主要使用meet命令,
3、槽指派:將16384個槽位分配給主節點,以達到分片保存資料庫鍵值對的效果,
七、Redis集群的運維:
1、資料遷移問題:
Redis集群可以進行節點的動態擴容縮容,這一程序目前還處于半自動狀態,需要人工介入,在擴縮容的時候,需要進行資料遷移,而 Redis為了保證遷移的一致性,遷移所有操作都是同步操作,執行遷移時,兩端的 Redis均會進入時長不等的阻塞狀態,對于小Key,該時間可以忽略不計,但如果一旦Key的記憶體使用過大,嚴重的時候會接觸發集群內的故障轉移,造成不必要的切換,
2、帶寬消耗問題:
Redis集群是無中心節點的集群架構,依靠Gossip協議協同自動化修復集群的狀態,但goosip有訊息延時和訊息冗余的問題,在集群節點數量過多的時候,goosip協議通信會消耗大量的帶寬,主要體現在以下幾個方面:
- 訊息發送頻率:跟cluster-node-timeout密切相關,當節點發現與其他節點的最后通信時間超過 cluster-node-timeout/2時會直接發送ping訊息
- 訊息資料量:每個訊息主要的資料占用包含:slots槽陣列(2kb)和整個集群1/10的狀態資料
- 節點部署的機器規模:機器的帶寬上限是固定的,因此相同規模的集群分布的機器越多,每臺機器劃分的節點越均勻,則整個集群內整體的可用帶寬越高
集群帶寬消耗主要分為:讀寫命令消耗+Gossip訊息消耗,因此搭建Redis集群需要根據業務資料規模和訊息通信成本做出合理規劃:
- 在滿足業務需求的情況下盡量避免大集群,同一個系統可以針對不同業務場景拆分使用若干個集群,
- 適度提供cluster-node-timeout降低訊息發送頻率,但是cluster-node-timeout還影響故障轉移的速度,因此需要根據自身業務場景兼顧二者平衡
- 如果條件允許盡量均勻部署在更多機器上,避免集中部署,如果有60個節點的集群部署在3臺機器上每臺20個節點,這是機器的帶寬消耗將非常嚴重
3、Pub/Sub廣播問題:
集群模式下內部對所有publish命令都會向所有節點進行廣播,加重帶寬負擔,所以集群應該避免頻繁使用Pub/sub功能
4、集群傾斜:
集群傾斜是指不同節點之間資料量和請求量出現明顯差異,這種情況將加大負載均衡和開發運維的難度,因此需要理解集群傾斜的原因
(1)資料傾斜:
- 節點和槽分配不均
- 不同槽對應鍵數量差異過大
- 集合物件包含大量元素
- 記憶體相關配置不一致
(2)請求傾斜:
合理設計鍵,熱點大集合物件做拆分或者使用hmget代替hgetall避免整體讀取
5、集群讀寫分離:
集群模式下讀寫分離成本比較高,直接擴展主節點數量來提高集群性能是更好的選擇,
參考文章:https://baijiahao.baidu.com/s?id=1663270958212268352&wfr=spider&for=pc
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/260393.html
標籤:其他
上一篇:python 全堆疊開發 Django_ billshop 商城_ 注冊功能的全部實作、含前后端和所有全功能驗證