目錄
- Scrapy介紹
- Scrapy作業流程
- Scrapy入門
- pipline使用
Scrapy介紹
- 什么是Scrapy
Scrapy是一個為了爬取網站資料,提取結構性資料而撰寫的應用框架,我們只需要實作少量的代碼,就能夠快速的抓取
Scrapy使用了Twisted異步網路框架,可以加快我們的下載速度
官方檔案:http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html
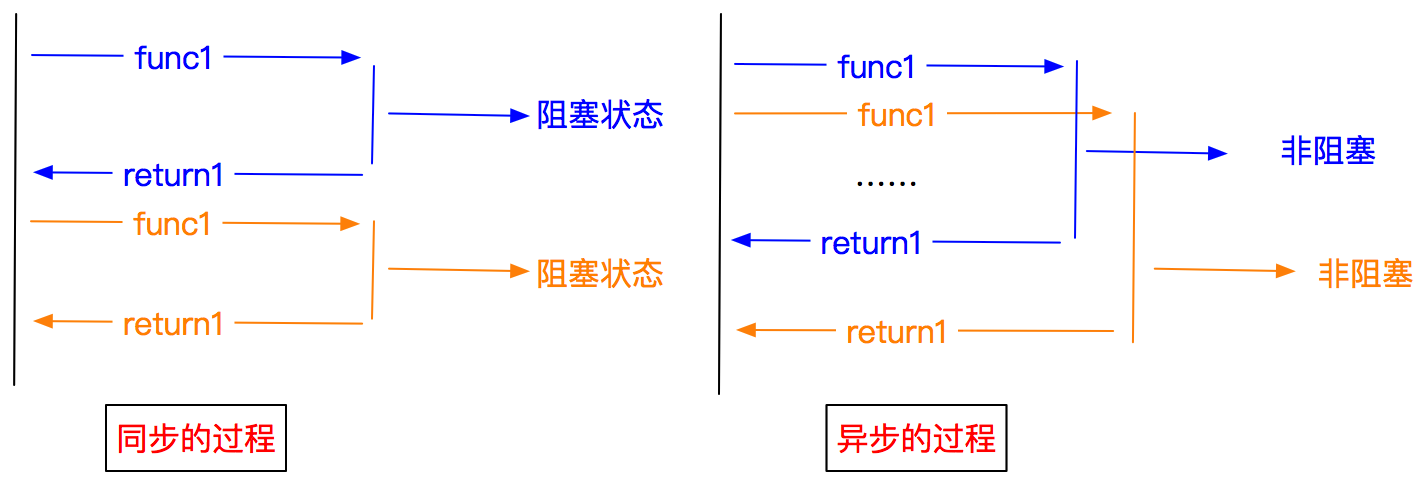
Scrapy的好處:可配置和擴展性高,框架是Twisted異步網路框架 - 異步和非阻塞的區別
異步:呼叫在發出之后,這個呼叫就直接回傳,不管有無結果
非阻塞:關注的是程式在等待呼叫結果時的狀態,指在不能立刻得到結果之前,該呼叫不會阻塞當前執行緒
Scrapy作業流程
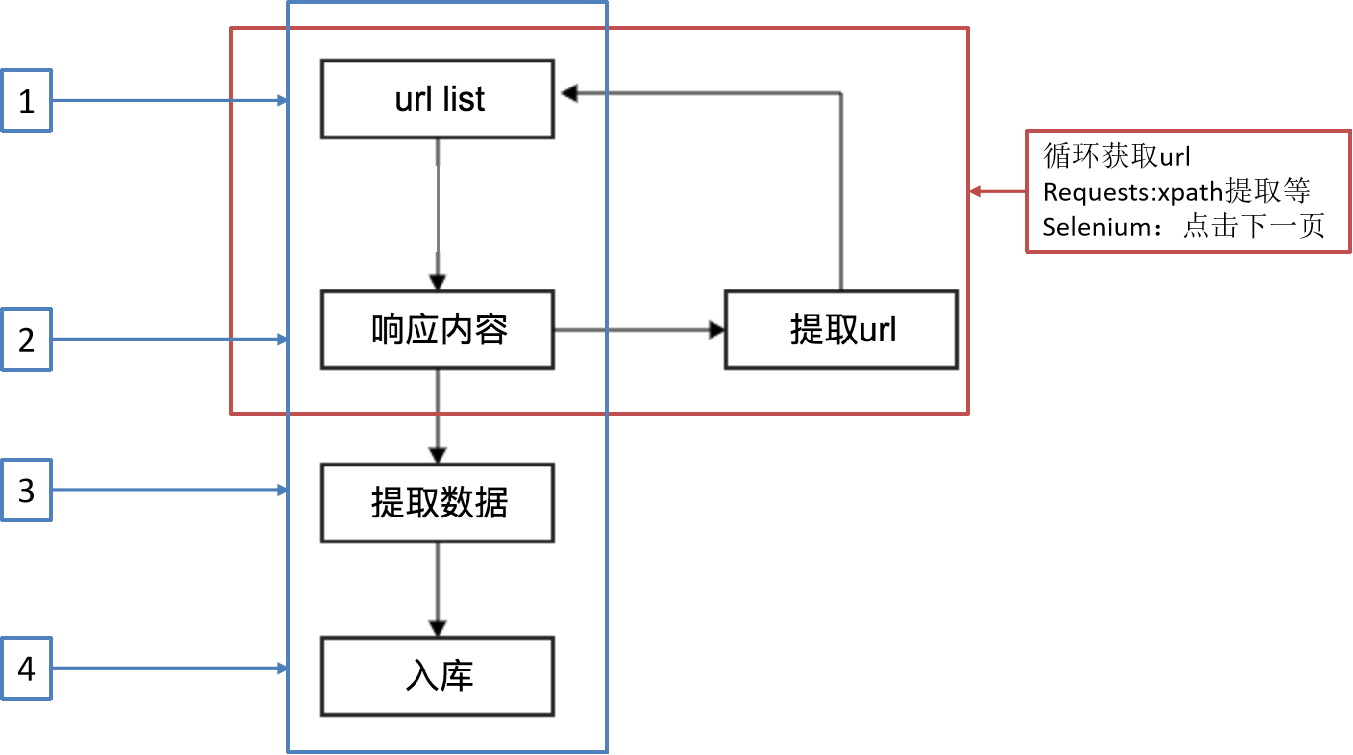
另一種爬蟲方式
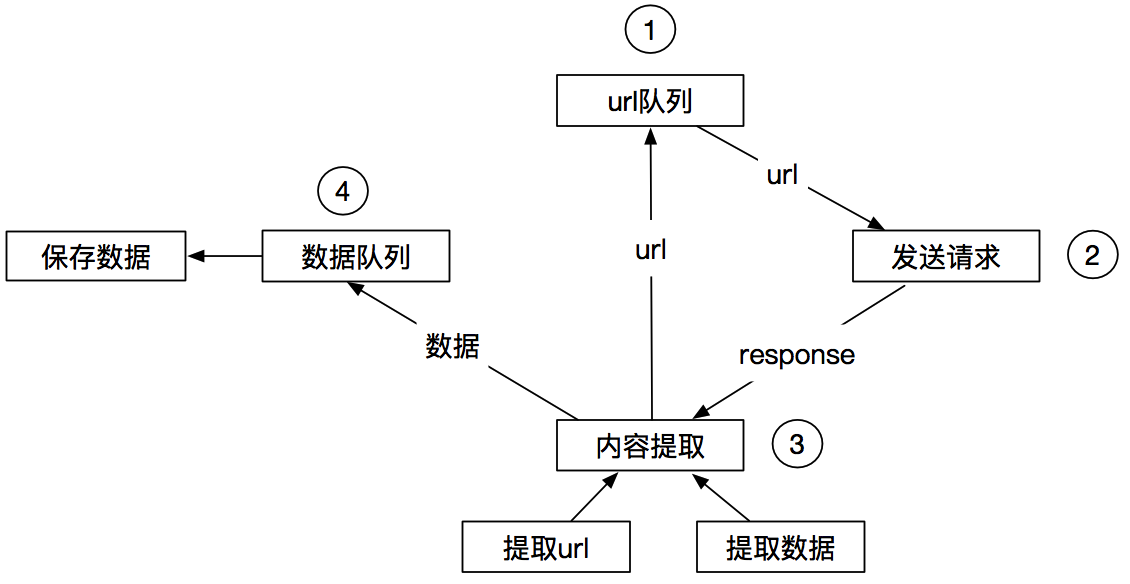
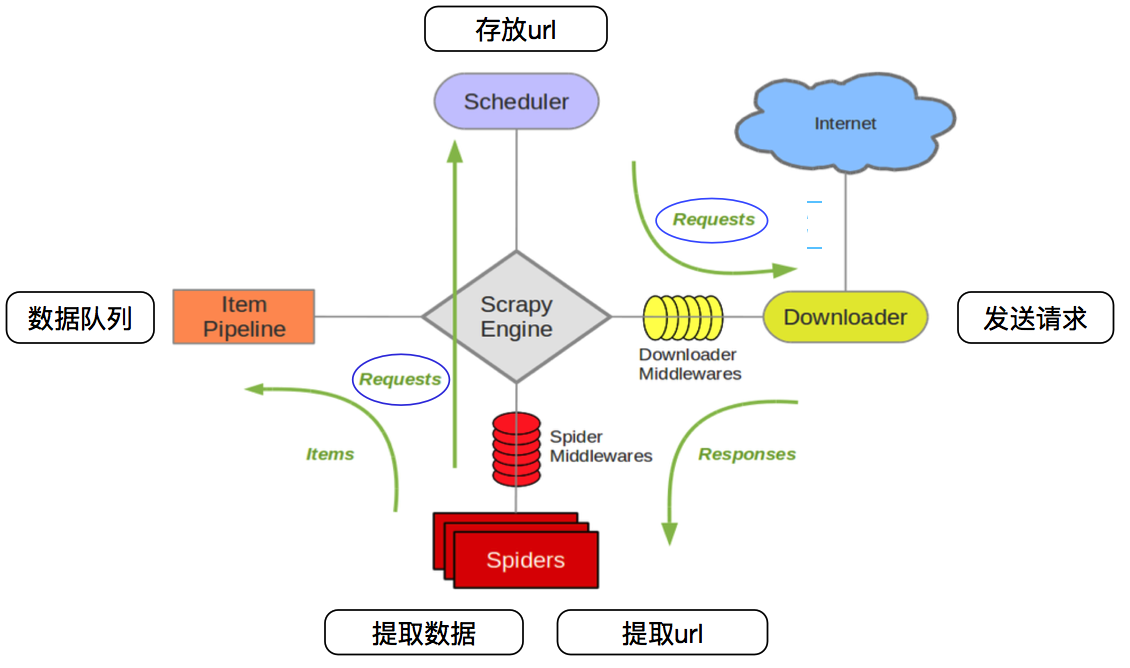
Scrapy作業流程:
引擎是整個框架的核心
調度器接收從引擎發過來的url,并入列
下載器 :下載網頁原始碼,回傳給爬蟲程式
專案管道負責資料處理
下載中間件處理引擎與下載器之間的請求
爬蟲中間件處理爬蟲程式回應和輸出結果以及新的請求
下載中間件和爬蟲中間件是負責引擎和下載器還有引擎和爬蟲程式之間的資料傳輸
| Scrapy engine(引擎) | 總指揮:負責資料和信號的在不同模塊間的傳遞 | scrapy已經實作 |
|---|---|---|
| Scheduler(調度器) | 一個佇列,存放引擎發過來的request請求 | scrapy已經實作 |
| Downloader(下載器) | 下載把引擎發過來的requests請求,并回傳給引擎 | scrapy已經實作 |
| Spider(爬蟲) | 處理引擎發來的response,提取資料,提取url,并交給引擎 | 需要手寫 |
| Item Pipline(管道) | 處理引擎傳過來的資料,比如存盤 | 需要手寫 |
| Downloader Middlewares(下載中間件) | 可以自定義的下載擴展,比如設定代理 | 一般不用手寫 |
| Spider Middlewares(中間件) | 可以自定義requests請求和進行response過濾 | 一般不用手寫 |
Scrapy入門
1 創建一個scrapy專案
scrapy startproject mySpider
2 生成一個爬蟲
scrapy genspider demo "demo.cn"
3 提取資料:完善spider 使用xpath
4 保存資料:pipeline中保存資料
在命令列中運行爬蟲
scrapy crawl qb # qb爬蟲的名字
在代碼中運行爬蟲
scrapy genspider example example.com
example :爬蟲程式的名字
example.com :爬取的網站的域名
from scrapy import cmdline
cmdline.execute("scrapy crawl qb".split())
- settings檔案
是否遵守robots協議 一般給為False
ROBOTSTXT_OBEY = False
最大并發量 默認是16
Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
下載延遲為3秒
DOWNLOAD_DELAY = 3
請求報頭
DEFAULT_REQUEST_HEADERS = {
'User-Agent':'Mozilla/5.0',
'Accept':
'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
爬蟲中間件
SPIDER_MIDDLEWARES = {
'mySpider.middlewares.MyspiderSpiderMiddleware': 543,
}
下載中間件
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.MyspiderDownloaderMiddleware': 543,
}
管道
ITEM_PIPELINES = {
'mySpider.pipelines.MyspiderPipeline': 300,
}
pipline使用
從pipeline的字典形可以看出來,pipeline可以有多個,而且確實pipeline能夠定義多個
為什么需要多個pipeline:
1 可能會有多個spider,不同的pipeline處理不同的item的內容
2 一個spider的內容可以要做不同的操作,比如存入不同的資料庫中
注意:
1 pipeline的權重越小優先級越高
2 pipeline中process_item方法名不能修改為其他的名稱
在爬蟲檔案中要使用yield關鍵字把資料給管道
在settings檔案里面一定要開啟管道
open_spider() 爬蟲開始
close_spider() 爬蟲結束
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/260554.html
標籤:其他
上一篇:聊一聊Serverless