CNN卷積神經網路之VGGNet
- 前言
- 網路結構
- 運用的方法
- 1.多尺度訓練
- 2.稠密和多裁剪影像評估對比
- 3.小卷積核和連續的卷積層*
- 4.dropout
- 5.尺寸大小和通道數
- 總結
前言
《Very Deep Convolutional Networks for Large-Scale Image Recognition》
論文地址: https://arxiv.org/abs/1409.1556.
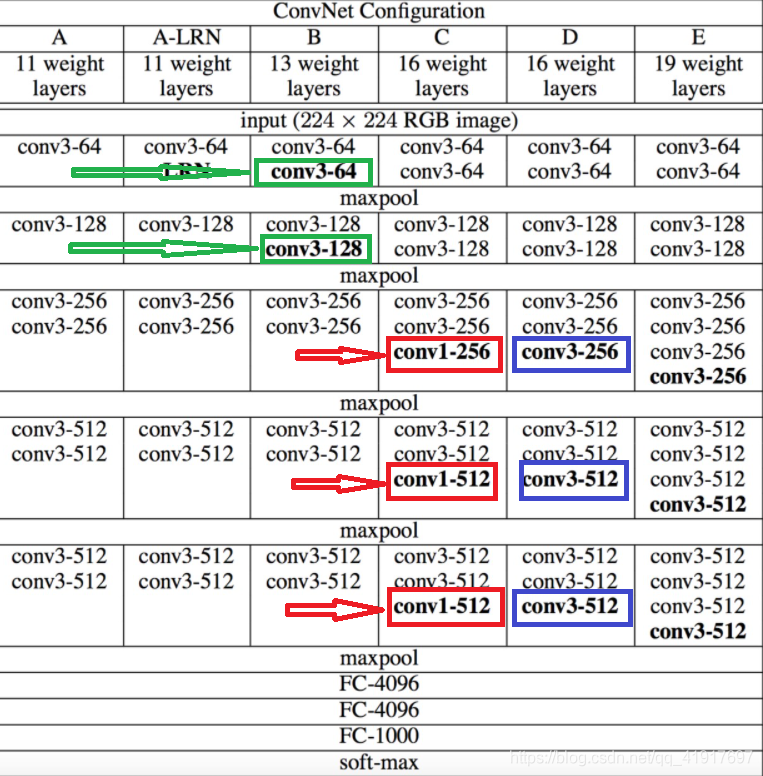
該網路是在ILSVRC 2014上的相關作業,ILSVRC2014比賽分類專案的第二名(第一名是GoogLeNet),2015年發表到ICLR,主要貢獻是使用很小的卷積核(3×3)構建各種深度的卷積神經網路結構,16-19層的網路深度能夠取得較好的識別精度, 這就是常用的VGG-16和VGG-19,
網路結構
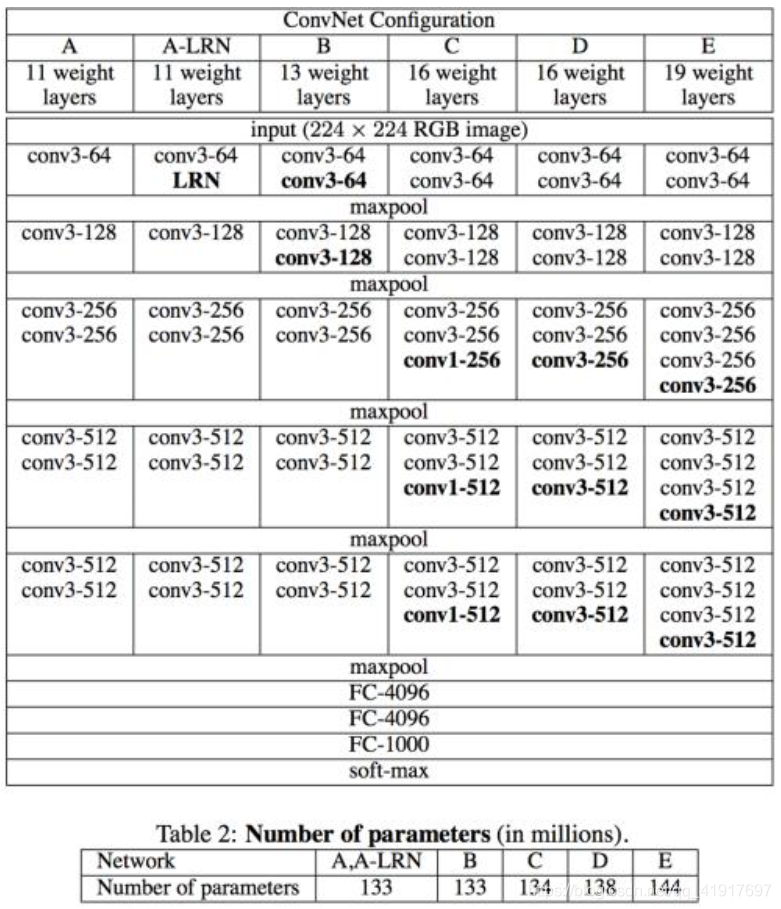
輸入是大小為224*224的RGB影像,預處理時計算出三個通道的平均值,在每個像素上減去平均值,全連接層后是Softmax,用來分類,所有隱藏層的conv層中間都使用ReLU作為激活函式,連續的卷積后面接最大池化,在FC層中間采用dropout層,防止過擬合,
VGG在訓練的時候先訓A的簡單網路,再復用A網路的權重來初始化后面的幾個復雜模型,可加快訓練,
運用的方法
1.多尺度訓練
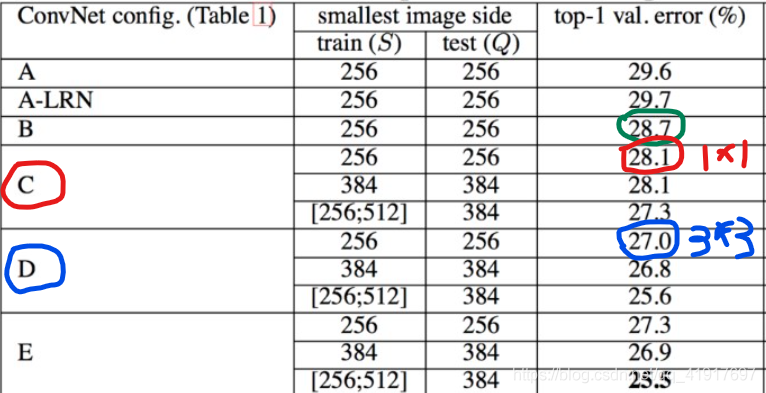
訓練采用多尺度訓練(Multi-scale),將原始影像縮放到不同尺寸 S,然后再隨機裁切224*224的圖片,并且對圖片進行水平翻轉和隨機RGB色差調整,
論文中使用了兩種方法:
(1) 固定最小邊的尺寸為256;
(2) 隨機從[256,512]的確定范圍內進行抽樣,這樣原始圖片尺寸不一,有利于訓練,這個方法叫做尺度抖動(scale jittering),有利于訓練集增強,
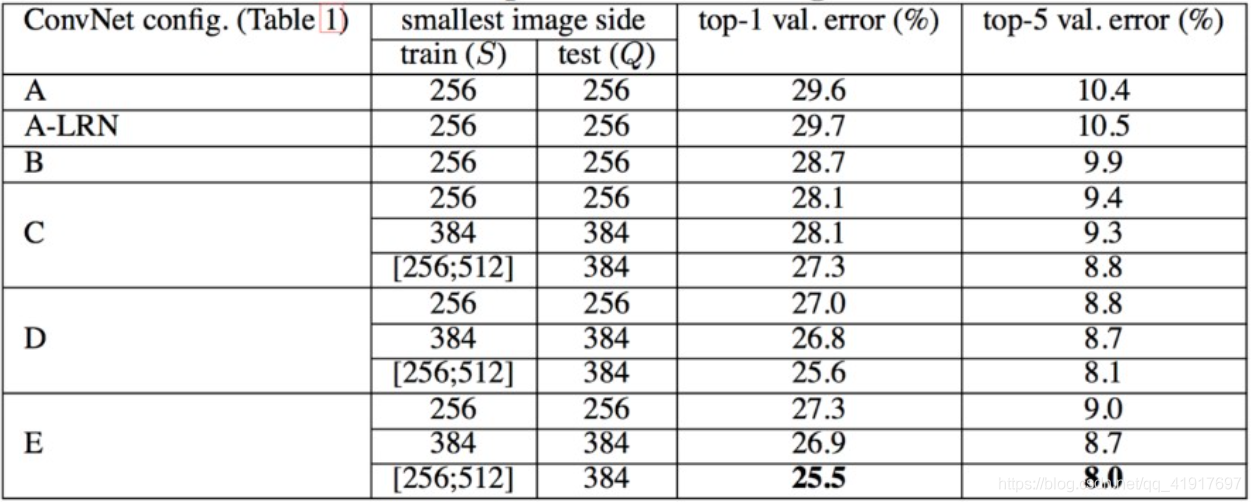
結論:網路的性能隨著網路的加深而提高,當網路層數達到19層時,使用VGG架構的錯誤率就不再隨著層數加深而提高了,訓練時的尺寸抖動的結果好于固定尺寸,
2.稠密和多裁剪影像評估對比
Dense(稠密評估),即指全連接層替換為卷積層(第一FC層轉換到7×7卷積層,最后兩個FC層轉換到1×1卷積層),最后得出一個預測的score map,再求平均,可參考 OverFeat的全卷積部分,
multi-crop(多裁剪影像評估),即對影像進行多樣本的隨機裁剪,將得到多張裁剪得到的影像輸入到網路中,最終對所有結果平均,
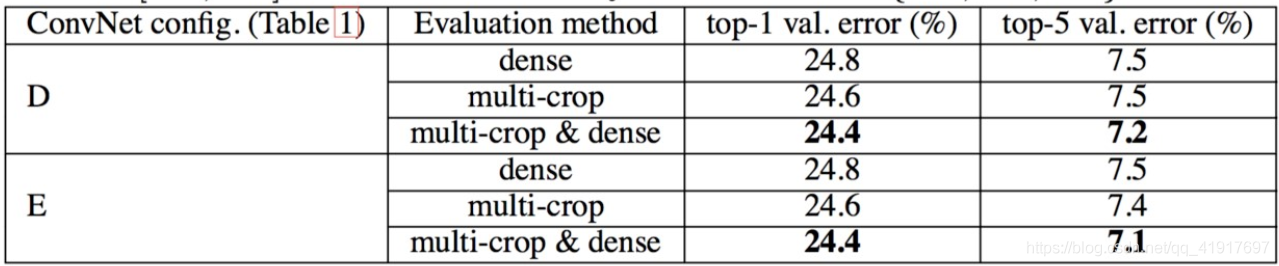
可以看出,多裁剪的結果是好于密集估計的,而且這兩種方法是互補的,它們的組合會更加好,
3.小卷積核和連續的卷積層*
VGGNet全部使用3x3(or 1x1)的卷積核和2x2的最大池化,兩個3x3卷積層的串聯相當于1個5x5的卷積層,3個3x3的卷積層串聯相當于1個7x7的卷積層,即3個3x3卷積層的感受野大小相當于1個7x7的卷積層,但是3個3x3的卷積層引數量只有7x7的一半左右,同時可以增加非線性,前者可以有3個非線性操作,而后者只有1個非線性操作,這樣使得學習能力更強,
使用1x1的卷積層來增加線性變換,輸出的通道數量上并沒有發生改變,
可見 1x1的卷積也是很有效的,但是沒有3x3的卷積效果好,因為3x3的網路可以學習到更大的空間特征,
4.dropout
并非首次提出,不在贅述,
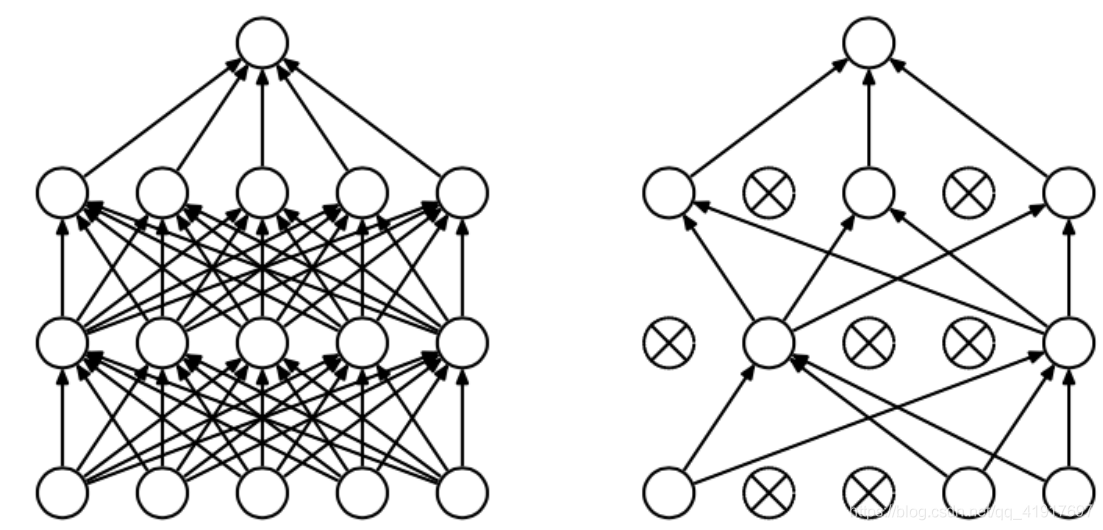
(1)達到了一種模型融合的作用,相當于對多種網路結構進行了優化,預測時又取了平均,因此可以較為有效地防止過擬合的發生,
(2)減少神經元之間復雜的共適應性,有些特征可能會依賴于固定關系的隱含節點的共同作用,而通過dropout的話,增加了神經網路的魯棒性,
5.尺寸大小和通道數
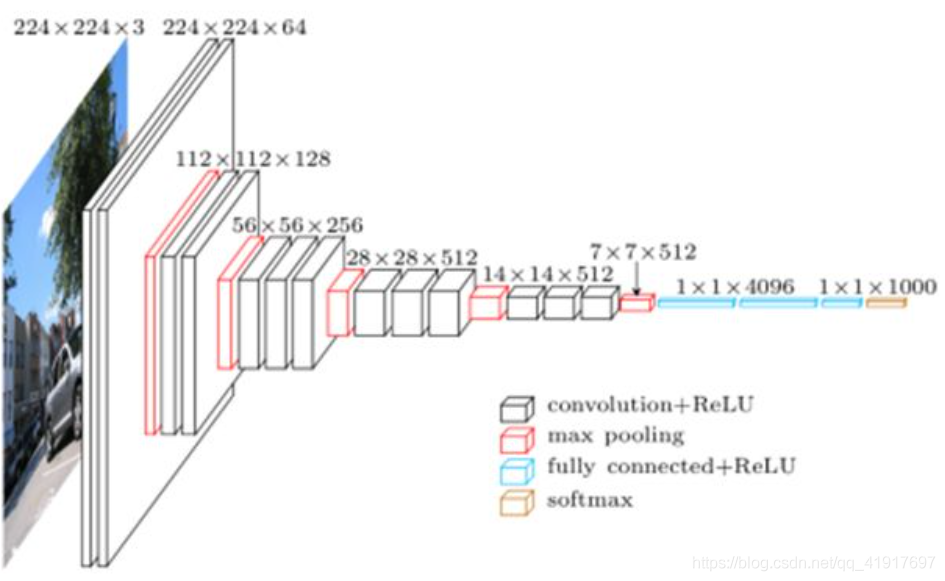
隨著層數的增加,影像尺寸越來越小,通道數成倍增加,
總結
1)在訓練時,可以使用多尺度抖動的訓練影像,其精度好于固定尺寸的訓練集,測驗時,使用多裁剪和密集評估(卷積層替換全連接層)相結合的方法,
2)VGG的結構非常簡潔規整,整個網路都使用了同樣大小的卷積核尺寸和最大池化尺寸,幾個小濾波器卷積層的組合比一個大濾波器卷積層好!!
3.驗證了通過不斷加深網路結構可以提升性能,
4.VGG耗費更多計算資源(卷積操作更多),并且使用了更多的引數(全連接層),有些研究稱:這些全連接層即使被去除,對于性能也沒有什么影響,這樣就顯著降低了引數數量,(有空我會親自驗證一下)
5.尺寸越來越小,通道數越來越大,
上一篇:CNN卷積神經網路之ZFNet與OverFeat.
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/260558.html
標籤:其他
上一篇:經典Promise面試題----手寫Promise詳細步驟(一)
下一篇:服務注冊與配置:Nacos