可以在我的個人博客閱讀文章,排版會美觀一些:文章地址
1. 什么是索引
- 一種能幫助mysql提高查詢效率的資料結構:索引資料結構
- 索引優點:
- 大大提高資料查詢速度
- 索引缺點:
- 維護索引需要耗費資料庫資源
- 索引要占用磁盤空間
- 當對表的資料進行增刪改的時候,因為要維護索引,所以速度收到影響
- 結合索引的優缺點,得出結論:資料庫表并不是索引加的越多越好,而是僅為那些常用的搜索欄位建立索引效果才是最佳的!
2. 索引的分類
- 主鍵索引:
PRIMARY KEY- 設定為逐漸后,資料庫自動建立索引,innodb為聚簇索引,主鍵索引列值不能有空(Null)
- 單值索引:又叫單列索引、普通索引
- 即,一個索引只包含單個列,一個表可以有多個單列索引
- 唯一索引:
- 索引列的值必須唯一,但允許有空值(Null),但只允許有一個空值(Null)
- 復合索引:
- 即,一個索引可以包含多個列,多個列共同構成一個復合索引!
- eg:
SELECT id (name age) INDEX WHERE name AND age;
- 全文索引:Full Text (MySQL5.7之前,只有MYISAM存盤引擎支持全文索引)
- 全文索引型別為FULLTEXT,在定義索引的列上支持值的全文查找,允許在這些索引列中插入重復值和空值,全文索引可以在Char 、Varchar 上創建,
3. 索引的基本操作
3.1 主鍵索引創建
-- 建表陳述句:建表時,設定主鍵,自動創建主鍵索引
CREATE TABLE t_user (
id VARCHAR(20) PRIMARY KEY,
name VARCHAR(20)
);
-- 查看索引
SHOW INDEX FROM t_user;

3.2 單列索引創建(普通索引/單值索引)
-- 建表時創建單列索引:
-- 這種方式創建單列索引,其名稱默認為欄位名稱:name
CREATE TABLE t_user (
id VARCHAR(20) PRIMARY KEY,
name VARCHAR(20),
KEY(name)
);
-- 建表后創建單列索引:
-- 索引名稱為:name_index 格式---> 欄位名稱_index
CREATE INDEX name_index ON t_user(name)
-- 洗掉單列索引
DROPINDEX 索引名稱 ON 表名

3.3 唯一索引創建
-- 建表時創建唯一索引:
CREATE TABLE t_user2 (
id VARCHAR(20) PRIMARY KEY,
name VARCHAR(20),
UNIQUE(name)
);
-- 建表后創建唯一索引:
CREATE UNIQUE INDEX name_index ON t_user2(name);

3.4 復合索引創建
-- 建表時創建復合索引:
CREATE TABLE t_user3 (
id VARCHAR(20) PRIMARY KEY,
name VARCHAR(20),
age INT,
KEY(name,age)
);
-- 建表后創建復合索引:
CREATE INDEX name_age_index ON t_user3(name,age);
-- 復合索引查詢的2個原則
-- 1.最左前綴原則
-- eg: 創建復合索引時,欄位的順序為 name,age,birthday
-- 在查詢時能利用上索引的查詢條件為:
SELECT * FROM t_user3 WHERE name = ?
SELECT * FROM t_user3 WHERE name = ? AND age = ?
SELECT * FROM t_user3 WHERE name = ? AND birthday = ?
SELECT * FROM t_user3 WHERE name = ? AND age = ? AND birthday = ?
-- 而其他順序則不滿足最左前綴原則:
... WHERE name = ? AND birthday = ? AND age = ? -- 不滿足最左前綴原則
... WHERE name = ? AND birthday = ? -- 不滿足最左前綴原則
... WHERE birthday = ? AND age = ? AND name = ? -- 不滿足最左前綴原則
... WHERE age = ? AND birthday = ? -- 不滿足最左前綴原則
-- 2.MySQL 引擎在執行查詢時,為了更好地利用索引,在查詢程序中會動態調整查詢欄位的順序!
-- 這時候再來看上面不滿足最左前綴原則的四種情況:
-- 不滿足最左前綴原則,但經過動態調整順序后,變為:name age birthday 可以利用復合索引!
... WHERE name = ? AND birthday = ? AND age = ?
-- 不滿足最左前綴原則,也不能動態調整(因為缺少age欄位),不可以利用復合索引!
... WHERE name = ? AND birthday = ?
-- 不滿足最左前綴原則,但經過動態調整順序后,變為:name age birthday 可以利用復合索引!
... WHERE birthday = ? AND age = ? AND name = ?
-- 不滿足最左前綴原則,也不能動態調整(因為缺少name欄位),不可以利用復合索引!
... WHERE age = ? AND birthday = ?

4. MySQL索引的資料結構(B+Tree)
-- 建表:
CREATE TABLE t_emp(
id INT PRIMARY KEY,
name VARCHAR(20),
age INT
);
-- 插入資料:插入時,主鍵無序
INSERT INTO t_emp VALUES(5,'d',22);
INSERT INTO t_emp VALUES(6,'d',22);
INSERT INTO t_emp VALUES(7,'3',21);
INSERT INTO t_emp VALUES(1,'a',23);
INSERT INTO t_emp VALUES(2,'b',26);
INSERT INTO t_emp VALUES(3,'c',27);
INSERT INTO t_emp VALUES(4,'a',32);
INSERT INTO t_emp VALUES(8,'f',53);
INSERT INTO t_emp VALUES(9,'b',13);
-- 查詢:自動排序,有序展示(因為主鍵是有主鍵索引的,因此會自動排序)
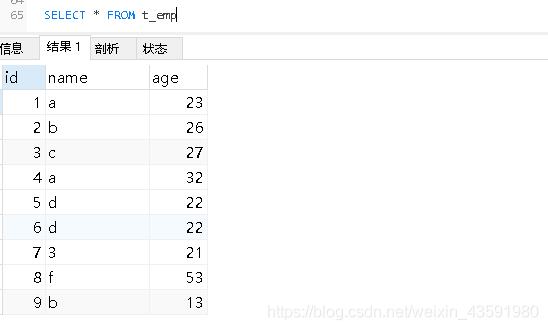
問題:為什么資料插入時,未按照主鍵順序,而查詢時卻是有序的呢?
- 原因:MySQL底層為主鍵自動創建索引,一旦創建了索引,就會進行排序!
- 實際上這些資料在MySQL底層的真正存盤結構變成了下面這種方式:

問題:為什么要排序呢?
- 因為排序之后查詢效率就快了,比如查詢
id = 3的資料,只需要按照順序去找即可,而如果不排序,就如同大海撈針,假如100W條資料,可能有時候需要隨機查詢100W次才找到這個資料,也可能運氣好上來第1次就查詢到了該資料,不確定性太高!
4.1 原理分析圖
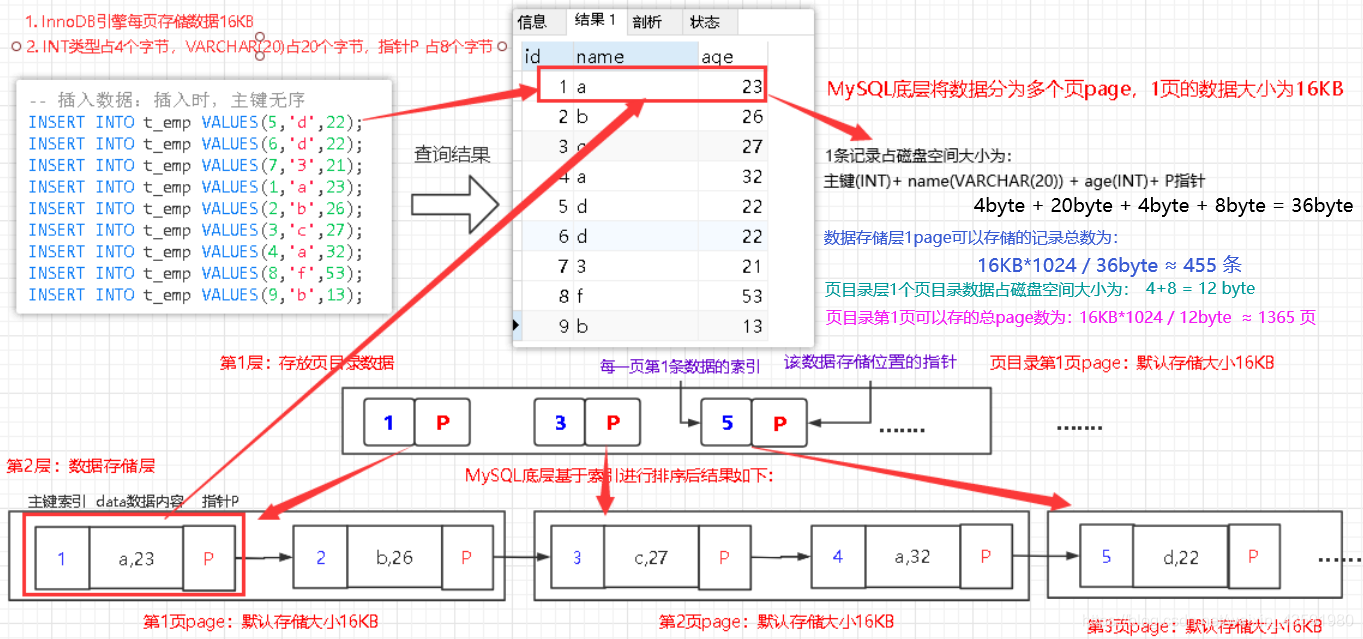
-
上圖這種分層
樹結構查詢效率較高,因為如果我需要查詢id=4的資料,只需要在頁目錄中匹配,大于3且小于5,則去3對應的page=2中查找資料,這樣就不需要從第1頁開始檢索資料了,大大提高了效率! -
從上圖可得出,在只有2層的結構下,1page 可以存盤記錄總數為
1365 * 455 ≈ 62萬條,而如果再加1層結構,來存盤page層分頁目錄資料的分頁層PAGE的話,那么1PAGE可以存盤總page數為:1365 * 1365 ≈ 186萬條page,而1PAGE存盤的總記錄數為1365 * 1365 * 455 ≈ 8.5 億條,因此,我們平時使用的話,2層結構就已經足夠了!實際上1個頁存盤的總資料樹可能大于理論估計的,因為我們分配name欄位的VARCHAR(20)占20個位元組,而實際上可能存盤的name資料并沒有20個位元組,可能更小!
三層結構實體如圖:
4.2 B+樹結構分析
上圖4.1 原理分析圖中這種索引結構稱之為B+樹資料結構,那么什么是B+樹呢?B樹和B+樹區別是什么呢?
詳情參考文章:https://www.cnblogs.com/lianzhilei/p/11250589.html
問題4.2.1 為什么InnoDB底層使用B+樹做索引而不用B樹?
B樹結構圖:
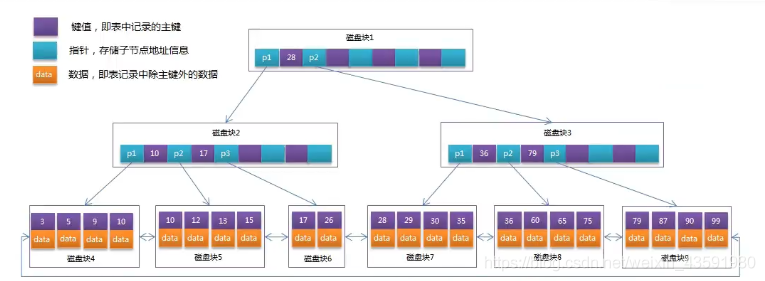
- 從上面的B樹結構圖中分析得出,B樹每個節點中不僅包含資料的key,還有data資料,而每個頁的存盤空間是有限的,如果data資料較大時,講會導致每個節點(即一個頁16KB)能存盤的key的數量較少,當存盤資料量很大時,會造成B樹的深度較大,增大查詢時的磁盤讀取I/O次數,進而影響查詢效率,(樹的深度影響I/O讀取次數)
- 在上一小節的B+樹結構圖分析中,所有資料記錄都是按照鍵值大小順序存放在同一層的葉子節點上,而非葉子節點上只能存盤key值資訊,這樣可以大大增加每個節點(即一個頁16KB)能存盤的key的數量,進而可以降低樹的高度,進而減少磁盤讀取I/O次數,提高查詢效率
- 所以B樹和B+樹的區別就在于:
- B+樹只有葉子節點存盤資料記錄
- B+樹非葉子節點只存盤鍵值資訊(B樹的非葉子也存資料記錄)
- 所有節點直接都有一個鏈指標
- InnoDB存盤引擎中,頁的大小為16KB,一般表的主鍵型別為INT(占用4個位元組) 或 BIGINT(占用8個位元組),指標型別也一般占4或8個位元組,也就是說,一個頁(B+樹中的一個節點)中大概可以存盤
16KB/(8B+8B)=1000個鍵值(只是估計值,方便計算而已),也就是說,一個深度為3的B+樹索引可以維護10^3 * 10^3 * 10^3 = 10億條記錄, - 實際情況中每個節點可能不能填充滿,因此在資料庫中,B+樹的高度一般是24層**,**MySQL的InnoDB存盤引擎在設計時是將根節點常駐在記憶體中(不需要動磁盤I/O)**的,也就是說**查找某個鍵值的行記錄最多只需要13次I/O操作!(每查詢一層都需要動用一次磁盤I/O)
5. 聚簇索引和非聚簇索引
5.1 聚簇索引和非聚簇索引分析
在表中,聚簇索引實際上就是指的是主鍵索引!如果表中沒有主鍵的話,則MySQL會根據該表生成一個RoleID,拿這個RoleId當做聚簇索引!
-
聚簇索引:
將資料存盤與索引放到一起,索引結構的葉子節點保存了每行的資料,例如:4.1小結分析圖中的data層一個單位就是聚簇索引存盤資料的例子,主鍵id 欄位就是聚簇索引,4.1小結分析圖就是基于主鍵索引(聚簇索引)構成的B+樹結構!聚簇索引不一定是主鍵索引,但是主鍵索引肯定是聚簇索引!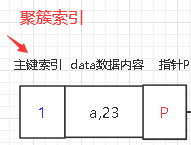
-
非聚簇索引:
將資料與索引分開存盤,索引結構的葉子節點指向了資料對應的位置(聚簇索引的值)!非聚簇索引檢索資料是在自己的 “樹” 上進行查找,例如我們根據表中的非聚簇索引name欄位去查找資料時,流程如下圖: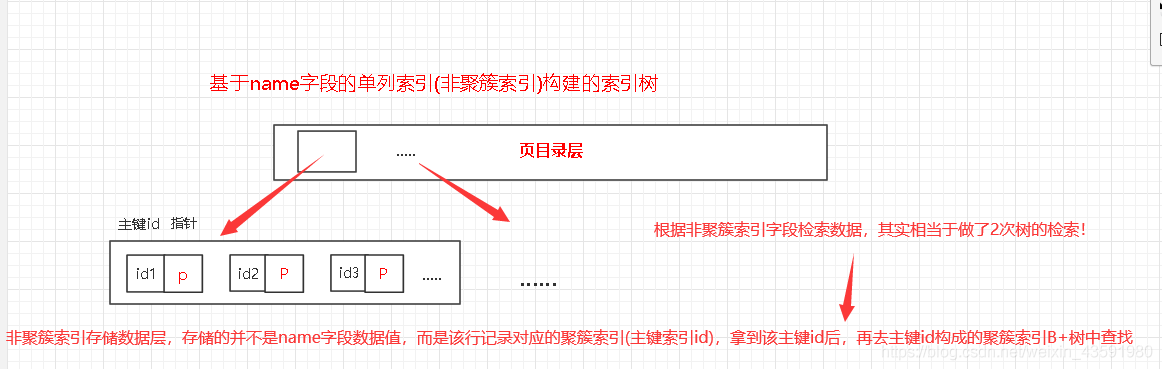
再看一張比較正規的分析圖:
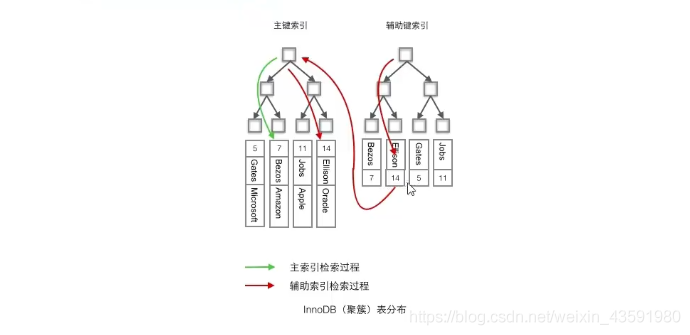
注意:在InnoDB中,在聚簇索引之上創建的索引稱之為輔助索引,例如:復合索引、單列索引、唯一索引,一個表中只能有1個聚簇索引,而其他索引都是輔助索引!輔助索引的葉子節點存盤的不再是行的物理位置,而是主鍵的值,輔助索引訪問資料總是需要二次查找的!
**問題5.1.1 **:為什么非聚簇索引(name欄位的單列索引)構成的樹,其葉子節點存盤聚簇索引(主鍵id),而不直接存盤行資料的物理地址呢?
換個方式問:非聚簇索引檢索資料時,檢索一次本樹再去聚簇索引樹中檢索一次,這樣二次檢索樹結構,那么為什么不直接在非聚簇索引樹葉子節點中存放行資料物理地址,這樣只需要檢索一次樹結構就拿到行資料呢?
這里畫個圖方便理解一些:
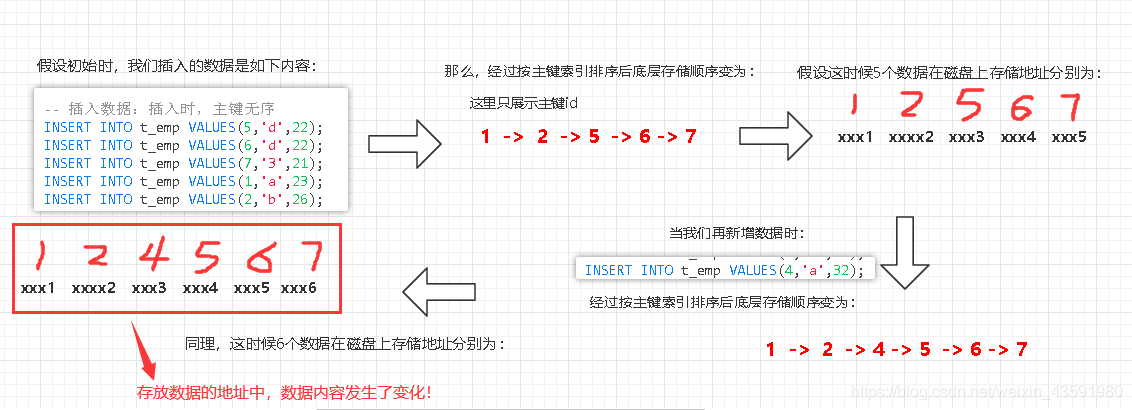
? 從上圖得出,在做新增資料時,因為底層是需要基于主鍵索引進行排序的,那么就可能導致原來某些資料對應的物理地址發生了變化,而這時候由于我們的非聚簇索引樹的葉子節點直接存盤了資料的物理地址,所以為了保證能獲取到資料,還需要同時對非聚簇索引樹葉子節點的地址進行一遍更新修改!
? 同理,如果我們不做插入主鍵id為4這行記錄的操作,而是將其洗掉的話,這個流程可以自己思考一下!
? 也就是說:之所以不在非聚簇索引樹的葉子節點直接存放行資料的物理地址,是因為,存盤資料的物理地址會隨著資料庫表的CRUD操作而不斷變更,為了保證能獲取到資料,這時必須要對非聚簇索引樹相關葉子節點的地址進行一遍修改!而存主鍵,主鍵不會隨著CRUD操作發生變化,寧愿多查一次樹,也不要再修改一次樹的結構!
5.2 MySQL兩種引擎中的(非)聚簇索引
InnoDB中:
- InnoDB中使用的是聚簇索引,將主鍵組織到一顆B+樹中,而行資料就存盤在該B+樹的葉子節點上,若使用
WHERE id = 4這樣的條件查找主鍵,則按照B+樹的檢索演算法即可查找對應的葉子節點,之后獲得對應的行資料! - 若對使用單列索引(非聚簇索引)的name欄位進行搜索,則需要執行2個步驟:
- 第一步:在輔助索引B+樹中檢索name,到達其對應的葉子節點后獲得該欄位對應行記錄的主鍵id!
- 第二步:使用主鍵id在主索引B+樹中再次執行一次樹的檢索,最終到達對應的葉子節點并獲取到行記錄資料!
- 聚簇索引默認是主鍵,如果表中沒有定義主鍵,InnoDB會選擇一個唯一且非空的索引代替主鍵作為聚簇索引,而如果也沒有這樣的唯一非空索引,那么InnoDB就會隱式定義一個主鍵(類似于Oracle中的RowId)來做為聚簇索引,
- 如果已經設定了聚簇索引又希望再單獨設定聚簇索引,則必須先洗掉主鍵,然后添加我們想要的聚簇索引,最后再恢復主鍵即可!
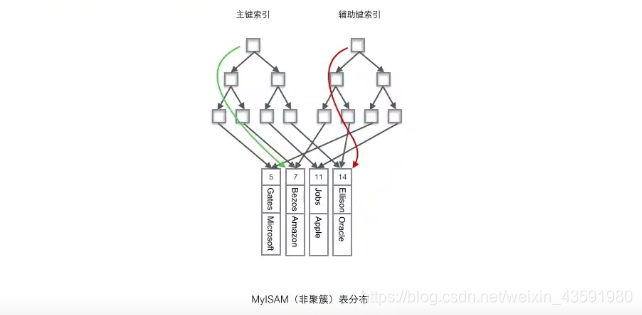
MYISAM中:
-
MYISAM使用的是非聚簇索引,非聚簇索引的兩顆B+樹看上去沒有什么不同,節點的結構完全一致,只是存盤的內容不同,主鍵索引B+樹的節點存盤了主鍵,輔助索引B+樹存盤量輔助鍵,
-
表資料存盤在獨立的地方,這兩顆B+樹的葉子節點都使用一個地址指標指向真正的表資料,對于表資料來說,這兩個鍵沒有任何差別,
-
由于索引樹是獨立的,通過輔助鍵檢索無需再次檢索主鍵索引樹!
5.3 聚簇索引和非聚簇索引的優/劣勢
問題:5.3.1 使用聚簇索引的優勢
問題:每次使用輔助索引檢索都需要經過2次B+樹查找,看上去聚簇索引的效率明顯要低于非聚簇索引,那么聚簇索引的優勢何在呢?
-- 1.由于行資料和聚簇索引樹的葉子節點存盤在一起,同一頁中會有多條行資料,首次訪問資料頁中某條行記錄時,會把該資料頁資料加載到Buffer(快取器)中,當再次訪問該資料頁中其他記錄時,不必訪問磁盤而直接在記憶體中完成訪問,
-- 注:主鍵id和行資料一起被載入記憶體,找到對應的葉子節點就可以將行資料回傳了,如果按照主鍵id來組織資料,獲取資料效率更快!
-- 2.輔助索引的葉子節點,存盤主鍵的值,而不是行資料的存放地址,這樣做的好處是,因為葉子節點存放的是主鍵值,其占據的存盤空間小于存放行資料物理地址的儲存空間
問題:5.3.2 使用聚簇索引需要注意什么?
-- 當使用主鍵為聚簇索引時,而不要使用UUID方式,因為UUID的值太過離散,不適合排序,導致索引樹調整復雜度增加,消耗更多時間和資源,
-- 建議主鍵最好使用INT/BIGINT型別,且為自增,這樣便于排序且默認會在索引樹的末尾增加主鍵值,對索引樹的結構影響最小(下面主鍵自增的問題會解釋原因),而且主鍵占用的存盤空間越大,輔助索引中保存的主鍵值也會跟著增大,占用空間且影響IO操作讀取資料!
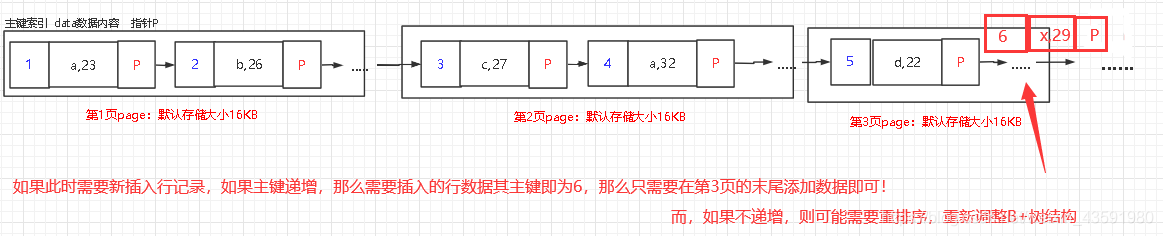
問題:5.3.3 為什么主鍵通常建議使用自增id?
-- 聚簇索引樹存放資料的物理地址(xx1,xx2,xx3,xxx5)與索引順序(1,2,3,5)是一致的,即:
-- 1.只要索引是相鄰的,那么在磁盤上索引對應的行資料存放地址也是相鄰的,
-- 2.如果主鍵是自增,那么當插入新資料時,只需要按照順序在磁盤上開辟新物理地址存盤新增行資料即可,
-- 3.而如果不是主鍵自增,那么當新插入資料后,會對索引進行重新排序(重新調整B+樹結構),磁盤上的物理存盤地址也需要重新分配要存盤的行資料!
問題:5.3.4 什么情況下無法利用索引呢?
-- 1. 查詢陳述句中使用LIKE關鍵字:(這種情況主要是針對于單列索引)
-- 在使用LIKE關鍵字查詢時,如果匹配字串的第一個字符為'%',則索引不會被使用,而'%'不在最左邊,而是在右邊,則索引會被使用到!
-- eg:
SELECT * FROM t_user WHERE name LIKE 'xx%' -- 可以利用上索引,這種情況下可以拿xx到索引樹上去匹配
SELECT * FROM t_user WHERE name LIKE '%xx%' -- 不可以利用上索引
SELECT * FROM t_user WHERE name LIKE '%xx' -- 不可以利用上索引
-- 2. 查詢陳述句中使用多列索引:(這種情況主要是針對于聚合索引)
-- 多索引是在表的多個欄位創建索引,只有查詢條件中使用了這些欄位中的第一個欄位,索引才會被使用,即:最左前綴原則,詳情查看3.4小結聚合索引中的介紹!
-- 3. 查詢陳述句中使用OR關鍵字:
-- 查詢條件中有OR關鍵字時,如果OR前后的兩個條件列都具有索引,則查詢中索引將被使用,而如果OR前后有一個或2個列不具有索引,那么查詢中索引將不被使用到!
6. 什么是約束以及分類
約束:
-
作用:是為了保證資料的完整性而實作的摘自一套機制,即(約束是針對表中資料記錄的)
-
MySQL中的約束:
- 非空約束:NOT NULL 保證某列資料不能存盤NULL 值;
- 唯一約束:UNIQUE(欄位名) 保證所約束的欄位,資料必須是唯一的,允許資料是空值(Null),但只允許有一個空值(Null);
- 主鍵約束:PRIMARY KEY(欄位名)
主鍵約束= 非空約束 + 唯一約束保證某列資料不能為空且唯一; - 外鍵約束:FOREIGN KEY(欄位名) 保證一個表中某個欄位的資料匹配另一個表中的某個欄位,可以建立表與表直接的聯系;
- 自增約束:AUTO_INCREMENT 保證表中新插入資料時,某個欄位資料可以依次遞增;
- 默認約束:DEFALUT 保證表中新插入資料時,如果某個欄位未被賦值,則會有默認初始化值;
- 檢查性約束:CHECK 保證列中的資料必須符合指定的條件;
-
示例:
-
create table member( id int(10), phone int(15) unsigned zerofill, name varchar(30) not null, constraint uk_name unique(name), constraint pk_id primary key (id), constraint fk_dept_id foreign key (dept_id,欄位2) references dept(主表1)(dept_id) );
-
7. MySQL索引和約束的區別
- 索引的作用:索參考于快速定位特定資料,提高查詢效率的,
- 約束的作用:約束是為了保證資料的完整性,即約束是針對表中資料記錄的,
- 總結:約束是為了保證表資料的完整性,索引是為了提高查詢效率,兩者作用不一樣!種類也不太一樣!
MySQL索引相關面試題
1.MySQL索引分類,并對比區別?
答案參考:第2小結
2.復合索引查詢時,欄位排列的先后順序與創建索引時不同,能否成功利用索引查詢?
考察點:復合索引的最左前綴原則
-- 假設構成復合索引的欄位為 name,age,birthday
-- 則下面那種情況可以使用成功利用復合索引查詢?
... WHERE name = ? -- 可以利用
... WHERE name = ? AND age = ? -- 可以利用
... WHERE name = ? AND birthday = ? -- 可以利用
... WHERE name = ? AND age = ? AND birthday = ? -- 可以利用
... WHERE name = ? AND birthday = ? AND age = ? -- 不滿足最左前綴原則,但經過動態調整后可以利用
... WHERE birthday = ? AND age = ? AND name = ? -- 不滿足最左前綴原則,但經過動態調整后可以利用
... WHERE age = ? AND birthday = ? -- 不滿足最左前綴原則,不能動態調整,不能利用復合索引
3.MySQL索引的資料結構是什么?
MySQL索引資料結構: B + Tree
B+樹,聚簇索引~
4.MySQL中索引和約束的區別以及各自種類?
MySQL索引與約束
5.為什么InnoDB底層使用B+樹做索引而不用B樹?
答案參考: 4.2小結B+樹結構分析中的問題4.2.1
6.什么是聚簇索引和非聚簇索引
答案參考:5.1小結聚簇索引和非聚簇索引分析
7.為什么非聚簇索引構成的樹的葉子節點存盤聚簇索引(或主鍵),而不直接存盤資料的物理地址呢?
答案參考:5.1小結的問題5.1.1
8.使用聚簇索引需要注意什么?
答案參考:5.3小結的問題5.3.2
9.為什么主鍵通常建議使用自增id?
答案參考:5.3小結的問題5.3.3
10.什么情況下無法利用索引呢?
答案參考:5.3小結的問題5.3.4
11.聚簇索引相對于非聚簇索引的優勢是什么?
答案參考:5.3小結的問題5.3.1
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/260639.html
標籤:其他
下一篇:Mybatis注解開發(超詳細)